







Release notes¶
This page contains the release notes for Catalyst.
Release 0.16.0 (development release)¶
New features since last release
The
local-randomunitary folding option formitigate_with_zne()is now implemented, reproducing Mitiq’sfold_gates_at_random: every gate is foldedfloor((scale_factor-1)/2)times, then a random subset is folded once more (without replacement) to reachscale_factor * ngates. Non-integer scale factors are now also accepted forlocal-random. Themitigation.zneoperation’snumFoldsoperand is now always a floating-point tensor; the integer folding methods require integral values and convert the count internally. (#2956)
Improvements 🛠
The
ResourceAnalysispass has received a new compiler hint to more accurately estimate quantum resources in the presence of conditional operations (scf.ifandscf.index_switch). The operations in question can be annotated with either acatalyst.estimated_probabilityorcatalyst.estimated_probabilitiesattribute, respectively, to indicate the expected probability distribution over the branches. The counted resources are then scaled proportionally and summed. (#3059)A new runtime transport layer for remote/local executors is introduced. (#3043)
A new remote/local executor infrastructure has been added to Catalyst, enabling qnode kernels to be dispatched to a separate executor process.
executordialect models the session lifecycle through an!executor.sessionhandle that is threaded fromexecutor.openthroughsend_binary,launch,call, andclose. (#2909)--convert-executor-to-llvmpass that lowers eachexecutorop to a call into the__catalyst__executor__*C-ABI runtime, marshalling string endpoints, memref descriptors, and per-argument metadata. (#2910)Host-side runtime (
rt_executor) that backs those symbols. It opens a TCP connection to the executor and uses LLVM’s ORC v2 EPC as the wire protocol to ship cross-compiled kernel objects into the remote JIT. (#2915)
A
BufferizableOpInterfaceimplementation is now added forcatalyst.launch_kerneloperation and it is now bufferizable. (#3024)quantum.extractcanonicalization now looks through aquantum.insertat a distinct static index, rewriting the extract to read from the register feeding the insert and sinking the bypassed insert below the gates acting on the extracted qubits. This removes the false data dependency between wires that act on different qubits of the same register and leaves extracts grouped above the gates and inserts below them. (#2965)Adds a
catalyst::symbolic_arrayoperation and integrates it with the newqp.capture.symbolic_arrayfunction. (#2982)The
decompose-loweringpass now supports applying a selection of the available decomposition rules via thetarget_rulesparameter. The pass also no longer applies theinline,cseandcanonicalizepasses to avoid unnecessary IR mutations. Instead, decomposition rules are deterministically inlined by a custom function (inlineis non-deterministic, using an estimated benefit and threshold as criteria for inlining). Decomposition rules are no longer removed after thedecompose-loweringpass, which allows them to be used by subsequent passes, namelygraph-decomposition. Instead, rules are removed by thesymbol-dcepass at the end of theQuantumCompilationStage. (#2973)The new
pennylane.core.Operator2can now be lowered to MLIR with program capture for operators without non-lowerable arguments.Operator2classes are now lowered to specialized operations where applicable, unlocking compilation and execution for these cases.qp.specsand theResourceAnalysispass now support thequantum::OperatorOpandqref::OperatorOpinstructions. (#2979) (#2969) (#2980) (#2990) (#2993) (#2998) (#2981)The
ResourceAnalysispass now reports each loop body and each subroutine as its own entry instead of folding their gate counts into the caller. Loops with constant bounds appear asfor_loop_<N>with their trip count. Loops with dynamic bounds appear asdyn_for_loop_<N>with a stable identifier, and totals across the call graph are computed on demand. (#2782) (#2900)The
ResourceAnalysispass now supports IR in reference semantics natively, rather than requiring a conversion step. (#2923)The
resource-analysispass JSON output now includesdepthfor worst-case PBC layer depth (any_commuting_depth/qubit_disjoint_depth) per function and lifted loop entry. (#2967)ResourceAnalysisnow uses a single JSON serializer owned byResourceResult, removing duplicate serialization logic and keeping its output consistent. (#3007)The
ResourceAnalysispass now counts quantum, measurement, and allocation ops through dialect-agnostic MLIR OpInterfaces instead of hard-coded check. New dialects can opt in by implementing these interfaces without changing the analysis. (#3025)The
--adjoint-loweringpass no longer turns statically bounded for loops into dynamically bounded ones. In this way they remain analyzable by functionality likeqp.specs. (#2959)The
--decompose-loweringpass can now handle decomposition rule functions whose quantum register argument is at an arbitrary position in the argument list. (#2836)PPRs and PPMs can now be lowered properly into MLIR directly in the non-capture workflow. (#2816)
The
--decompose-loweringpass can now handle null decomposition rules, which are rule functions that do not have any quantum values as arguments or results. Gates with null decomposition rules are simply removed. (#2855)The
--partition-layerspass now supports adisjoint-qubitoption to group PBC ops into the same layer only when they act on disjoint qubits. By default, commuting ops on overlapping qubits may still be merged into one layer. (#2858)The
ppm_specs()now report circuit depth asdepth(layer count) anddepth_type(0= commuting ops on overlapping qubits may share a layer;1= only ops with disjoint qubit support may share a layer). The Python API acceptsonly_disjoint_qubit=Trueto runppm-specs{disjoint-qubit=true}. AOTppm_specsno longer requires an explicit pipeline and no longer mixes MLIR into the JSON output. (#2863)The
depthfield reported byppm_specs()is now the worst-case depth acrossscf.ifandscf.index_switchbranches (taking the maximum over all branches) and across statically-boundedscf.forloops (multiplied by the trip count). Previously, branches were counted sequentially and PBC ops insidescf.forproduced an error.scf.whileand dynamically-boundedscf.forstill produce an error. (#2876) (#2877) (#2879)Global toggles,
compile_without_static_conditionalsandcompile_without_static_loopshave been added to control the capture behaviour forcatalyst/pennylanecondandfor_loopinstructions. Setting the toggle toTruewill automatically remove the respective construct from the captured program (i.e., evaluate it in Python) whenever the predicate or bounds are static. (#2912)For example, consider the following circuit with a statically defined
forloop bound.import pennylane as qp import catalyst catalyst.compile_without_static_loops = True @qp.qjit @qp.qnode(qp.device("lightning.qubit", wires=2)) def f(): @qp.for_loop(0, 2) def loop(i): qp.H(i) loop() return qp.state()
Using the
catalyst.compile_without_static_loopstoggle, Catalyst will evaluate thefor_loopin Python, which unrolls thefor_loop. This can be verified by printing thejaxprrepresentation of the circuit.>>> print(f.jaxpr) ... b:AbstractQreg() = qalloc 2:i64[] c:AbstractQbit() = qextract b 0:i64[] d:AbstractQbit() = qinst[ adjoint=False ctrl_len=0 op=Hadamard params_len=0 qubits_len=1 ] c e:AbstractQbit() = qextract b 1:i64[] f:AbstractQbit() = qinst[ adjoint=False ctrl_len=0 op=Hadamard params_len=0 qubits_len=1 ] ...
The
--decompose-loweringpass can now handle cases where the decomposed gate act on qubit values extracted from different quantum register SSA values, as long as all these quantum register values trace back to the same allocation. (#2861)The
--adjoint-loweringpass can now handle adjoint operations containing control flow operations that have multiple quantum operands, of either quantum register or qubit type. (#2868)The
--decompose-loweringpass now uses theDecomposableGateinterface, allowing it to support many new gate operations, includingquantum.paulirot. (#2893) (#3040)Exclude more packages from AutoGraph conversion, since converting code unintentionally can lead to tracing errors. (#2891)
Dynamically allocated wires can now be used in quantum adjoints. (#2720)
Dynamic shapes with
qp.condare now supported withqjit(capture=True): (#2740)The
catalyst.custom_calloperation now accepts an optionalbackend_configattribute, which allows backend-specific configuration to be attached to custom calls. (#3037)Introduced compile-time python-decompositions, allowing compiler passes to lower decomposition rules instantiated with static data (ex. pauli strings). Using this, the
graph-decompositionpass can now decomposequantum.paulirotoperations using the decomposition rule defined in PennyLane. (#2769)Added
CZsupport toto-pprpass. (#3009)
Breaking changes 💔
Removes the non-graph decomposition fallback when
capture=Trueis enabled. (#3058)Python 3.11 is no longer supported. Catalyst now requires Python 3.12 or newer. (#2974)
Catalyst’s xDSL dependencies have been updated to
xdsl0.63.0 andxdsl-jax0.5.2. (#2840)Removes support for
Transform.plxpr_transformfrom theqp.qjit(capture=True)capture pipeline. All transforms must now have a MLIR or XDSL implementation and a correspondingpass_name.Support for
qjitintegration withcudaqhas been removed in order to feasbily drop support for Python 3.11. (#2984)
Deprecations 👋
Bug fixes 🐛
Fixed a bug where the
ResourceAnalysispass only analyzed functions directly contained in the top-level module. Functions inside nested modules, such as kernels called throughcatalyst.launch_kernel, are now included in the output. (#2961)Fixed a bug in
DecompRuleInterpreter.cleanupby replacing fragile string-based operator checks with strict type-based checking. (#2873)Fixed support of region-based adjoint (
qp.adjoint(qfunc)()) when used in conjunction with dynamic qubit allocation. (#2933)For instance, the following would previously fail:
def fun(w): with qp.allocate(1) as qs: qp.S(qs[0]) qp.X(w) @qp.qjit(capture=True) @qp.qnode(qp.device("null.qubit", wires=1)) def circuit(): qp.adjoint(fun)(0) return qp.probs()
with the error message:
catalyst.utils.exceptions.CompileError: catalyst failed with error code 1: Failed to run pipeline: QuantumCompilationStage Compilation failed: circuit:31:9: error: Unhandled operation in adjoint region circuit:31:9: note: see current operation: "quantum.dealloc"(%13) : (!quantum.reg) -> ()
Fixed a bug where using
keep_intermediate=Truewithtarget="mlir"resulted in an empty workspace folder being created and the files printed outside in the main directory. (#2807)Fixed a bug that passed incorrect SSA values to the final register deallocation when translating from the
qecpto thequantumdialect. This bug prevented deallocation of unneeded registers after magic state injection. (#2897)Fix memory bugs in the PBC passes. (#2918)
Fixed incorrect
depthinppm_specs()when aquantum.extractappeared after a PBC op but read from a register not updated by that op. Layer grouping now checks data dependencies through insert to extract chains instead of textual op ordering. (#2884)Fixed the assembly format for
quantum.adjointwhen it has no quantum operands/results. (#2938)
Internal changes ⚙️
The
dimargument of thequantum.pcphaseoperation has been changed to a static integer attribute (previously a dynamic float operand). This allows, among other things, the decomposition graph to distinguish pcphase gates with differentdimvalues, since they need different decomposition rules. (#3034)The
condPLxPR primitive’s lowering rule no longer expects aTrueLiteral for the predicate of the default else branch. (#3018)Add the
DecomposableGateop interface to allow generic handling of operations in thegraph-decompositionpass. This allows arbitrary operations implementing the interface to be registered to and decomposed by the graph. This also allows the use of python-decompositions for any operator pre-registered in the frontend graph. The graph solver now supports the newgraphOpIds provided by the interface, as well as the legacy pathway withname,numWiresetc. (#2983) (#3022) (#3039)The
graph-decompositionpass eliminates three redundant IR manipulations: the cloning, removal, and re-insertion of user rules. This optimization is particularly beneficial when the pass is executed multiple times within the compilation pipeline. (#2977)from_plxprno longer depends on theTransform.plxpr_transformproperty. (#3004)Update tests to not use global capture toggle where possible. (#2964)
The
/benchmarkGitHub comment trigger can now accept additional arguments and has been renamed to!benchmark. (#2947)The frontend now generates MLIR in reference semantics when capture is enabled. (#2663) (#2664) (#2672) (#2694) (#2717) (#2720) (#2740) (#2757) (#2781) (#2834) (#2911)
A new pass
--convert-to-reference-semanticshas been added. The pass takes in MLIR in value semanticsquantumdialect, and converts them to reference semanticsqrefdialect. (#2920) (#2930) (#2931) (#2937) (#2945) (#2948)Removed the internal
mlir_specsfunction which was the old backend forqp.specs(). The resource analysis pass replaces its use. (#2841)Fixed
KeyErrorin autograph when usingqp.prodas a decorator with PennyLane >= 0.45. (#2844)Update RC nightly builds to read version number from the
_version.pyfile (#2797)Fix build failures when using clang with GCC ≤ 13 libstdc++ by replacing
std::views::filter/std::views::transformwithstd::copy_if/std::transform(#2801)A new, experimental compiler pass
convert-qecp-to-quantumhas been added to lower operations from the QEC Physical (qecp) dialect into the Quantum (quantum) dialect. (#2822) (#2809) (#2824) (#2835) (#2839) (#2849) (#2927) (#2955)The experimental compiler pass
convert-qecl-to-qecphas been extended to lower transversal gate operations from the QEC Logical (qecl) dialect into the QEC Physical (qecp) dialect. (#2776) (#2871) (#2922)The experimental compiler pass
convert-quantum-to-qeclhas been extended to lower thequantum.custom "T"gate to theqecllayer as a subroutine using a magic state (or conjugate magic state in the case of the adjoint). (#2870) (#2921)The reference semantics Pauli Product Measurement operation
pbc.ref.ppmwas added. (#2773)Part of the new, experimental QEC pipeline, the
convert-qecp-to-llvmcompiler pass has been added to lower operations and types in the QEC physical dialect to the LLVM dialect. (#2780) (#2772)The strategy to decode physical measurements in the
convert-qecl-to-qecppass has been updated to perform the decoding directly in the IR rather than offloading to a pre-compiled runtime function. (#2813)Resolved a bug in the QEC-cycle subroutine within the
convert-qecl-to-qecppass where the SSA values of thescf.yieldop were incorrectly returned instead of thescf.forop results. Also, theqec_codepass option is now given as astrrather than aQecCodeobject to ensure compatibility with Catalyst’s compiler infrastructure. (#2837)The constructors of xDSL ops that accept index attributes have been updated to ensure that the resulting attribute has the correct type. These ops include
quantum.{extract, insert},qecl.{extract_block, insert_block, measure, <gates>}, andqecp.{extract_block, insert_block, extract, insert}. (#2846)A new, experimental compiler pipeline
qec_pipelinehas been added to theftqc.pipelinesmodule. (#2852)The reference semantics MBQC operations have been moved from the
qrefdialect to thembqcdialect. They are now accessible asmbqc.ref.measure_in_basisandmbqc.ref.graph_state_prep. (#2829)A new operation has been added to the Quantum dialects to represent generic and high-level quantum operators, including operators with frontend-end specific data. (#2883) (#2943) (#2951)
In order to support T gates and π/8 PPRs in the experimental QEC pipeline, the following new operations have been added:
qecl.fabricate, which fabricates a logical codeblock in a specified initial state (typically a magic state). (#2865)qecl.dealloc_cb, which deallocates a single logical codeblock. (#2866)qecp.alloc_cb, which allocates a single physical codeblock. (#2867)qecp.dealloc_cb, which deallocates a single physical codeblock. (#2867)qecp.t, which performs a T gate on a single physical qubit. (#2888)
The experimental
convert-qecl-to-qecppass has been extended to support loweringqecl.fabricate [magic]to a subroutine that prepares a magic state through a simple, non-fault tolerant encoding. (#2894)The experimental QEC pipeline now supports compilation and execution of circuits that only include a single wire (a previously unsupported edge-case). (#2897)
The experimental QEC pipeline now only generates subroutines for operations present in the compiled circuit, rather than generating all QEC subroutines. (#2929)
More conservative casting to tracer arrays in conditionals to preserve constant (static) values better. This can be useful for optimizations that depend on values being static. (#2892)
The experimental QEC pipeline now supports the following control-flow operations:
The experimental QEC pipeline now supports programs that sample wires, where before it only supported sampling mid-circuit measurements. (#2941)
The QEC pipeline also now supports
qp.expval,qp.varandqp.probsmeasurement processes when used in conjunction with themeasurements-from-samplespass. (#2958)Rename the pipeline names in the default pipeline specification (e.g.
quantum-compilation-pipeline) to match the-stagenaming convention used when invoking them from the command line (e.g.quantum-compilation-stage). #3002
Documentation 📝
A broken link was removed in the Compiler Core documentation page. The link referred to where precompiled decomposition rules were implemented, which has since been refactored. (#2913)
The documentation for
QJIT.mlirandQJIT.mlir_optwas updated with type hints and docstrings that better reflect the compilation-dependent nature of the properties. (#2975)The MLIR Plugins documentation has been updated to fix a number of typos and formatting issues, and to improve overall readability. (#3005)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Ali Asadi, Joey Carter, Yushao Chen, Lillian Frederiksen, Sengthai Heng, David Ittah, JiaRung Jian, Jacob Kitchen, Korbinian Kottmann, Christina Lee, Joseph Lee, Rylan Malarchick, Mehrdad Malekmohammadi, River McCubbin, Shuli Shu, Paul Haochen Wang, Jake Zaia, Hongsheng Zheng.
Release 0.15.0 (current release)¶
New features since last release
Combining
GlobalPhaseoperations into one single operation is now possible with thecatalyst.passes.combine_global_phases()MLIR compilation pass. (#2604)import pennylane as qp import catalyst @qp.qjit(capture=True) @catalyst.passes.combine_global_phases @qp.qnode(qp.device("lightning.qubit", wires=5)) def circuit(): qp.GlobalPhase(0) qp.GlobalPhase(1) qp.GlobalPhase(2) qp.GlobalPhase(3) qp.GlobalPhase(4) return qp.state()
>>> print(qp.specs(circuit, level=1)().resources.gate_counts) {'GlobalPhase': 1}
Additionally, there was a previous implementation of this pass using xDSL but it has been removed.
Executing circuits that are compiled with
pennylane.transforms.to_ppr(),pennylane.transforms.commute_ppr(),pennylane.transforms.ppr_to_ppm(),pennylane.transforms.merge_ppr_ppm(),pennylane.transforms.reduce_t_depth(), andpennylane.transforms.decompose_arbitrary_ppr()is now possible with thelightning.qubitdevice and with program capture enabled (@qjit(capture=True)). (#2348) (#2389) (#2390) (#2413) (#2414) (#2424) (#2443) (#2460) (#2639)Previously, circuits compiled with these transforms were only inspectable via
qp.specsandcatalyst.draw_graph(). Now, such circuits can be executed.import pennylane as qp @qp.qjit(capture=True) @qp.transforms.decompose_arbitrary_ppr @qp.transforms.to_ppr @qp.qnode(qp.device("lightning.qubit", wires=3)) def circuit(): qp.PauliRot(0.123, pauli_word="XXY", wires=[0, 1, 2]) qp.pauli_measure("XYZ", wires=[0, 1, 2]) return qp.probs([0, 1])
>>> print(circuit()) [0.5 0. 0. 0.5]
Support for
PauliRotandPauliMeasureexecution on thenull.qubitdevice has been added, which enables mock execution and runtime resource tracking for those operations. (#2627)For
qjit‘d workflows, PennyLane’sspecs()function for inspecting circuit resources now leverages a performant MLIR resource analysis pass (resource-analysis) that counts quantum operations across thequantum,qec, andmbqcdialects. The analysis is implemented as a cacheable MLIR analysis class (ResourceAnalysis) that other transformation passes can query viagetAnalysis<ResourceAnalysis>(), avoiding redundant recomputation. (#2479) (#2534) (#2675) (#2695) (#2755)This pass can be invoked from the Catalyst CLI as follows:
quantum-opt --resource-analysis='output-json=true' input.mlir quantum-opt --resource-analysis -mlir-pass-statistics input.mlir
For more usage information, check out the documentation for
pennylane.specs().A new high-performance MLIR graph-based decomposition framework is now available that closely mimics PennyLane’s Python implementation (
pennylane.decomposition.enable_graph()). (#2531) (#2539) (#2552) (#2568) (#2578) (#2619) (#2658) (#2660) (#2711) (#2713) (#2722) (#2795) (#2749) (#2765)In PennyLane v0.41, we introduced a more performant, versatile, and modular decomposition system that allows you to define multiple decomposition rules per operator and have PennyLane determine the best overall set of decomposition rules to reach a given target gate set (see
pennylane.decomposition.enable_graph()for more information). We have been working on integration with Catalyst so that users can leverage the power ofqjitcompilation with this new decomposition system.With this release, we have made major steps towards full feature parity with PennyLane’s Python implementation, though there are still differences. For ease of development and ensuring a smooth transition, Catalyst’s most up-to-date implementation of this decomposition system is accessible via a new
catalyst.passes.graph_decomposition()decorator, though the more familiarqp.decomposetransform is the longterm goal for using graph-based decompositions with Catalyst.The
catalyst.passes.graph_decomposition()pass decorator has several capabilities that matchpennylane.transforms.decompose()(withpennylane.decomposition.enable_graph()), including:Multiple instances of
catalyst.passes.graph_decomposition()can be applied to QNodes.Weighted target gate sets are supported.
Users can create custom decomposition rules with
catalyst.jax_primitives.decomposition_rule()and add them toalt_decompsorfixed_decomps. These rules must be called withinqjit‘d workflows in order to properly register them as valid decomposition rules.
Additionally,
catalyst.passes.graph_decomposition()leverages the new MLIR resource analysis pass to quickly calculate the most resource-efficient set of decomposition rules.Below is a comprehensive example:
import pennylane as qp import pennylane.numpy as np from catalyst import qjit from catalyst.jax_primitives import decomposition_rule from catalyst.passes import cancel_inverses, graph_decomposition, merge_rotations @decomposition_rule(op_type=qp.PauliX) def x_to_rx(wire: int): qp.RX(np.pi, wire) @decomposition_rule(op_type=qp.PauliY) def y_to_ry(wire: int): qp.RY(np.pi, wire) @decomposition_rule(op_type=qp.Hadamard) def h_to_rx_ry(wire: int): qp.RX(np.pi / 2, wire) qp.RY(np.pi / 2, wire) @qjit(capture=True) @graph_decomposition(gate_set={qp.Rot}) @merge_rotations @graph_decomposition( gate_set={qp.RX: 1.0, qp.RY: 1.0, qp.Rot: 5.0}, fixed_decomps={qp.PauliX: x_to_rx, qp.PauliY: y_to_ry}, alt_decomps={qp.H: [h_to_rx_ry]}, ) @cancel_inverses @qp.qnode(qp.device("lightning.qubit", wires=2)) def circuit(x: float, y: float): qp.H(0) qp.H(0) qp.RX(x, wires=0) qp.PauliX(0) qp.RY(y, wires=0) qp.PauliY(0) qp.RY(x + y, wires=0) # register custom decomposition rules, required when using the decomposition_rule decorator x_to_rx(int) y_to_ry(int) h_to_rx_ry(int) return qp.state()
>>> print(qp.specs(circuit, level="device")(1.23, 4.56).resources.gate_types) {'Rot': 2}
A new implementation of the dynamic-one-shot MCM method is now available. This implementation is entirely in MLIR, which vastly improves the robustness and performance of Catalyst workflows that use this MCM method in addition to being compatible with PennyLane’s program capture (
@qjit(capture=True)). (#2458) (#2573) (#2786)import pennylane as qp import catalyst dev = qp.device("lightning.qubit", wires=2) @qp.qjit(capture=True) @qp.qnode(dev, shots=10, mcm_method="one-shot") def circuit(): qp.Hadamard(wires=0) m_0 = qp.measure(0) m_1 = qp.measure(1) return qp.sample([m_0, m_1]), qp.expval(m_0), qp.counts(wires=0, all_outcomes=True)
>>> print(circuit()) (Array([[0, 0], [0, 0], [1, 0], [1, 0], [0, 0], [1, 0], [1, 0], [0, 0], [0, 0], [1, 0]], dtype=int64), Array(0.5, dtype=float64), (Array([0, 1], dtype=int64), Array([5, 5], dtype=int64)))
Note that although the dynamic-one-shot transform is motivated from the context of mid-circuit measurements, this method also supports terminal measurement processes that are performed on wires (e.g.,
probs).A new MLIR pass called
split-to-single-termshas been added for QNode functions containing Hamiltonian expectation values. It facilitates execution on devices that don’t natively support expectation values of sums of observables by splitting them into individual leaf observable expectation values. (#2441)Consider the following example:
import pennylane as qp from catalyst import qjit from catalyst.passes import apply_pass @qjit @apply_pass("split-to-single-terms") @qp.qnode(qp.device("lightning.qubit", wires=3)) def circuit(): # Hamiltonian H = Z(0) @ X(1) + 2*Y(2) return qp.expval(qp.Z(0) @ qp.X(1) + 2 * qp.Y(2))
The pass transforms the function by splitting the Hamiltonian into individual observables:
Before:
func @circ1(%arg0) -> (tensor<f64>) {qnode} { // ... quantum ops ... // Z(0) @ X(1) %obs0 = quantum.namedobs %qubit0[ PauliZ] : !quantum.obs %obs1 = quantum.namedobs %qubit1[ PauliX] : !quantum.obs %T0 = quantum.tensor %obs0, %obs1 : !quantum.obs // Y(2) %obs2 = quantum.namedobs %qubit2[ PauliY] : !quantum.obs %H0 = quantum.hamiltonian(%8 : tensor<1xf64>) %obs2 : !quantum.obs %H = quantum.hamiltonian(%coeffs_2xf64) %T0, %H0 : !quantum.obs %result = quantum.expval %H : f64 // H = c_0 * (Z @ X) + c_1 * Y // ... to tensor ... %tensor_result = tensor.from_elements %result : tensor<f64> return %tensor_result }
After:
func @circ1.quantum() -> (tensor<f64>, tensor<f64>) {qnode} { // ... quantum ops ... %expval0 = quantum.expval %T0 : f64 %expval1 = quantum.expval %obs2 : f64 // ... to tensor ... %tensor0 = tensor.from_elements %expval0 : tensor<f64> %tensor1 = tensor.from_elements %expval1 : tensor<f64> return %tensor0, %tensor1 } func @circ1(%arg0) -> (tensor<f64>, tensor<f64>) { // ... setup ... %call:2 = call @circ1.quantum() // Extract coefficients and compute weighted sum %result = c0 * %call#0 + c1 * %call#1 return %result }
A new MLIR pass called
split-non-commutinghas been added for QNode functions that measure non-commuting observables. It facilitates execution on devices that don’t natively support measuring multiple non-commuting observables simultaneously by splitting them into separate circuit executions. The pass supports agrouping_strategyoption: the default (None) assigns each observable to its own group, while"wires"groups observables on non-overlapping wires into the same execution, reducing the total number of generated circuits. Duplicate observables are measured only once and their results are reused. (#2437) (#2657)Relationship to ``split-to-single-terms``: The
split-non-commutingpass internally runssplit-to-single-termsfirst when processing Hamiltonian expectation values. Thesplit-to-single-termspass decomposes a Hamiltonian (sum of observables) into individual leaf observables and computes the weighted sum in post-processing by running the circuit once. By contrast,split-non-commutinggoes further: it splits non-commuting observables into multiple groups and runs the circuit once per groupConsider the following example:
import pennylane as qp from catalyst import qjit @qjit @qp.transform(pass_name="split-non-commuting")(grouping_strategy="wires") @qp.qnode(qp.device("lightning.qubit", wires=3)) def circuit(): # Hamiltonian H = Z(0) + 2 * X(0) + 3 * Identity return qp.expval(qp.Z(0) + 2 * qp.X(0) + 3 * qp.Identity(2))
The pass first runs
split-to-single-termsto decompose the Hamiltonian, then splits non-commuting observables into separate groups. Shots are distributed among groups using integer division (rounded down); e.g., 100 shots with 3 groups yields 33 shots per group.Before:
func @circ1(%arg0) -> (tensor<f64>) {qnode} { %shots = arith.constant 100 quantum.device shots(%shots) // ... quantum ops ... %H = quantum.hamiltonian(%coeffs) %T0, %obs2 : !quantum.obs %result = quantum.expval %H : f64 return %tensor_result }
After:
func @circ1() -> (tensor<f64>) { %r0, %r1 = call @circ1.quantum.group.0() // expval(Z), 1.0 %r2 = call @circ1.quantum.group.1() // expval(X) // Weighted sum: 1 * r0 + 3 * r1 + 2 * r2 return %result } func @circ1.quantum.group.0() -> (tensor<f64>, tensor<f64>) {qnode} { // ... quantum ops ... %shots = arith.constant 100 %num_group = arith.constant 3 : i64 // Shots are divided among groups via integer division (rounded down) %new_shots = arith.divsi %shots, %num_group quantum.device shots(%new_shots) %obs = quantum.namedobs %out_qubits[ PauliZ] : !quantum.obs %r0 = quantum.expval %obs // expval(Identity) be simplified to one %one = arith.constant dense<1.000000e+00> return %r0, %one } func @circ1.quantum.group.1() -> tensor<f64> {qnode} { // ... quantum ops, single expval ... }
A new
CompilationPassclass has been added that abstracts away compiler-level details for seamless compilation pass creation. Used in tandem withcompiler_transform(), compilation passes can be created entirely in Python (leveraging xDSL) and used on QNodes within aqjit()’d workflow. (#2211)
Improvements 🛠
The
diagonalize-final-measurementspass received the following new features and improvements:It is now available as a builtin pass accessible from the Catalyst frontend as
catalyst.passes.diagonalize_measurements(). (#2630)It now accepts the optional keyword argument
supported_base_obs. The kwargto_eigvalsis also now included in the call signature for compatibility with the tape transform, but this kwarg is unused and can only take its default value,False. (#2517)These pass options can be applied as follows:
import pennylane as qp import catalyst dev = qp.device("null.qubit", wires=4) @qp.qjit(target="mlir", keep_intermediate=True) @catalyst.passes.diagonalize_measurements(supported_base_obs=('PauliX',)) @qp.qnode(dev, shots=1000) def circuit(): qp.CRX(0.1, wires=[0, 1]) return qp.expval(qp.X(0))
>>> circuit() Array(0., dtype=float64)
It now includes an observable-commutativity check and raises an error if non-commuting terms are encountered. The check is applied to each QNode in the IR. If the measurement contains only Pauli or Hadamard observables, the qubit-wise commutativity (QWC) check is applied. Otherwise, the more strict non-overlapping observable check is applied. (#2538) (#2633)
A
capturekeyword argument has been added to the@qjitdecorator for per-function control over PennyLane’s program capture frontend. This allows selective use of the new capture-based compilation pathway without affecting the globalqp.capture.enabled()state. The parameter accepts"global"(default, defer to global state),True(force capture on), orFalse(force capture off). This enables safe testing and gradual migration to the capture system. (#2457)The quantum kernel abstraction in Catalyst’s IR (a nested module operation with its own transform schedule and entry point and subroutine functions representing a PennyLane QNode) has been documented and equipped with additional verification. Transformation passes scheduled from the frontend must ensure, and can rely on, the presence of the
quantum.nodeattribute to indicate which functions in the module represent a separate quantum execution (with device initialization, shots configuration, and set of measurement processes). (#2483) (#2497) (#2597)The
parity_synth()pass can now be invoked from thepassesmodule. (#2553) (#2784) (#2804)import pennylane as qp import catalyst dev = qp.device("lightning.qubit", wires=2) @qp.qjit(capture=True) @catalyst.passes.parity_synth @qp.qnode(dev) def circuit(x: float, y: float, z: float): qp.CNOT((0, 1)) qp.RZ(x, 1) qp.CNOT((0, 1)) qp.RX(y, 1) qp.CNOT((1, 0)) qp.RZ(z, 1) qp.CNOT((1, 0)) return qp.state()
>>> qp.specs(circuit)(0.1, 0.2, 0.3).resources.gate_counts {'RX': 1, 'RZ': 2, 'CNOT': 2}
Note as well that this compilation pass used to be named
parity_synth_pass.Resource tracking with
pennylane.specs()onnull.qubitis now able to track measurements and observables. (#2446)ResourceAnalysisandRegisterDecompRuleResourcepasses now record the number of classical parameters for each gate alongside the wire count. The operation key format changes from"GateName(nWires)"to"GateName(nWires,nParams)". (#2755)Dynamic wire allocation can now be used in circuits whose terminal measurements are not state-based (
StateMP). This was originally disallowed due to a bug with dynamic wire allocation and terminal measurements. (#2427)A warning is issued when
pennylane.transforms.gridsynth()is called with epsilon smaller than1e-6due to potential precision error. (#2625)The following features are now supported with
qjit(capture=True):Dynamic shapes with
qp.for_loopandqp.while_loop(#2603) (#2651)The
abstracted_axesargument inqjit(#2655)StatePrepkwargspad_withandnormalize(#2620)qp.value_and_grad(#2587)Device preprocessing. (#2557)
Currently, preprocessing transforms that do not have a native MLIR or xDSL implementation will be replaced with empty transforms.
the new
qp.templates.Subroutineclass and the associatedqp.capture.subroutineupstreamed fromcatalyst.jax_primitives.subroutine. (#2396) (#2493)stopping_conditioninqp.transforms.decompose(with bothpennylane.decomposition.enable_graph()andpennylane.decomposition.disable_graph()) (#2486)
The default
mcm_methodfor the finite-shots setting (dynamic one-shot) no longer silently falls back to single-branch statistics in most cases. Instead, an error message is raised pointing out alternatives, like explicitly selecting single-branch statistics. (#2398)Importantly, single-branch statistics only explores one branch of the MCM decision tree, meaning program outputs are typically probabilistic and statistics produced by measurement processes are conditional on the selected decision tree path.
Graph decomposition with qjit now accepts
num_work_wires, and lowers and decomposes correctly with thedecompose-loweringMLIR pass and withqp.transforms.decompose. (#2470)The tape transform
catalyst_decompose()now accepts the optional keyword argumentstarget_gates,num_work_wires,fixed_decomps, andalt_decomps, which all are passed to the used PennyLane decomposition functionqp.devices.preprocess.decomposeand used if the graph-based decomposition system is enabled. (#2501)Two new verifiers were added to the
quantum.paulirotoperation. They verify that the Pauli word length and the number of qubit operands are the same, and that all of the Pauli words are legal. (#2405)The
quantum.adjointMLIR operation can now take in multiple quantum values, allowing both qubits and registers as opposed to constraining the operand to be a single quantum register. (#2590) (#2610)The adjoint lowering pass now supports
switchoperation as well. Previously, usingqp.adjointon a circuit containing aswitchwould raise aCompileError. The MLIR--adjoint-loweringpass has been updated to support this usage. (#2691)catalyst.python_interface.utils.get_constant_from_ssacan now extract constant values cast usingarith.index_cast. (#2542)Several improvements have been made to the
measurements_from_samplespass:It no longer results in
nans and cryptic error messages whenshotsaren’t set. Instead, an informative error message is raised. (#2456)A performance issue that was caused by the unrolling of a
forloop for QNodes returningprobshas been fixed. (#2611)It now diagonalizes observables automatically before converting to samples in the computational basis, removing the need to apply a diagonalization pass separately. This behaviour matches the behaviour of the tape transform
measurements_from_samplesin PennyLane, providing a smoother experience when switching to aqjitworkflow. (#2617)It has been refactored to follow the conventions for a QNode transform as they are described in
catalyst.python_interface.transforms.qnode-transform-guide.md. (#2605)A more informative error message is now raised it encounters a program with dynamic shots. (#2616)
It has been extended to support tensor product observables. (#2656)
All passes in
catalyst.passes.builtin_passes.pyhave been refactored to bepennylane.transforms.core.Transformobjects. This allows them to be used as standard transforms, enabling full compatibility withpennylane.CompilePipeline(). (#2722)catalyst.from_plxpr.register_transformsas a way to register MLIR passes from Python has been removed in favour of the new unified transforms API. MLIR passes can be accessed from Python usingqp.transform(pass_name="some-pass-name"). (#2509) (#2680)
Breaking changes 💔
(Compiler integrators only) The versions of StableHLO/LLVM/Enzyme used by Catalyst have been updated. (#2415) (#2416) (#2444) (#2445) (#2478)
The StableHLO version has been updated to v1.13.7.
The LLVM version has been updated to commit 8f26458.
The Enzyme version has been updated to v0.0.238.
Support for NumPy 1.x has been dropped following its end-of-life. NumPy 2.0 or higher is now required. (#2407)
Catalyst’s xDSL dependencies have been updated to
xdsl0.59.0 andxdsl-jax0.5.0. (#2591)The
catalyst.python_interface.transforms.parity_synth_passtransform has been renamed tocatalyst.python_interface.transforms.parity_synth. (#2553)The
-disentangle-CNOTand-disentangle-SWAPCatalyst CLI commands have been renamed to-disentangle-cnotand-disentangle-swap(all lower-case). (#2546)catalyst.python_interface.inspection.drawandcatalyst.python_interface.inspection.generate_mlir_graphno longer accept QNodes as the input. Now, the input must always be aQJITobject. (#2542)catalyst.jax_primitives.subroutinehas been moved topennylane.capture.subroutine. (#2396)The
StableHLOdialect has been removed from Catalyst’s Python interface module. Downstream users should now import StableHLO dialect definitions fromxdsl_jax.dialects.stablehloinstead. (#2588)The QEC (Quantum Error Correction) dialect has been renamed to PBC (Pauli-Based Computation) across the entire codebase. This includes the MLIR dialect (
qec.*->pbc.*), C++ namespaces (catalyst::qec->catalyst::pbc), Python bindings, compiler passes (e.g.,lower-qec-init-ops->lower-pbc-init-ops,convert-qec-to-llvm->convert-qec-to-llvm), qubit type (!quantum.bit<qec>->!quantum.bit<pbc>), and all associated file and directory names. The rename better reflects the dialect’s purpose as a representation for Pauli-Based Computation rather than general quantum error correction. (#2482) (#2485)When an integer
argnumsis provided tocatalyst.vjp, a singleton dimension is now squeezed out. This brings the behaviour in line with that ofcatalyst.gradandcatalyst.jacobian. (#2279)The inlining pass has been removed from the default compilation pipeline. (#2473)
Deprecations 👋
Bug fixes 🐛
Fixed a bug where
postselect_modewas not propagated through higher-order ops and control flow when tracing withqjit(). (#2787)Fixed a bug where the
path_to_pluginnever be forwarded inapply_pass_plugin(). The plugin path is now registered with the compiler during tracing. (#2790)Fixed a bug where the
work_wire_typeargument ofqp.ctrlwas silently dropped inside@qjitfunctions. The parameter is now threaded throughcatalyst.ctrl,CtrlCallable,HybridCtrl, andctrl_distribute, with the default value being"borrowed". (#2710)Fixed a bug in the
split-multiple-tapespass where the post-split classical wrapper kept thequantum.nodeattribute. Downstream, theresource-analysispass then misidentified the empty wrapper as an additional qnode, causing an empty column inqp.specsat MLIR levels. (#2793)Fixed a bug where multiple
quantum.extractoperations from the same index were being created when there are multiple computational basis observables, named observables or Hermitian observables on that same wire index, when PennyLane’s program capture is not enabled. (#2641) (#2646) (#2693)pennylane.adjoint()can now be used on subroutines with classical arguments. (#2590)Fixed a bug where the
catalystCLI tool would emit text when called with--emit-bytecode. (#2596)Fixed a bug where input array arguments could be mutated during execution when copied inputs were updated in-place. Entry-point arguments are now treated as non-writable during bufferization, preserving the expected immutability of user inputs. (#2562)
Fixed a bug in the
split_non_commutingpass where deadNamedObsOps were left behind after erasing composite obs (TensorOp,HamiltonianOp). (#2567)Fix a bug where
draw_graphfailed to render measurements containing scalar products of observables. (#2545)Fixed a bug where a passed callback function (such as
specsordraw_graph) would be triggered one extra time for the initial pass level (#2528)Fix a bug in the bind call function for
PCPhasewhere the signature did not match what was expected injax_primitives.ctrl_qubitswas missing from positional arguments in the previous signature. (#2467)Fixed a bug in
CATALYST_XDSL_UNIVERSEto correctly define the available dialects and transforms, allowing tools likexdsl-optto work with Catalyst’s custom Python dialects. (#2471)Fixed a bug with symbolic
adjointsupport for control flow operation. This means operators who are the target ofqp.adjointbut require decomposition can have decompositions with control flow in them, which would previously raise an error.adjointon functions is unaffected. (#2667)Fixed a bug with the
parity_synthpass that caused failure when the QNode being transformed contained operations with regions. (#2408)Fixed a bug with
replace_irfor certain stages when used with gradients. (#2436)Fixed a bug with differentiating multiple (expectation value) QNode results with the adjoint-differentiation method. (#2428)
Fixed a bug with the angle conversion when lowering
pbc.pprandpbc.ppr.arbitraryoperations to__catalyst__qis__PauliRotruntime calls. The PPR rotation angle is now correctly multiplied by 2 to match the PauliRot convention (PauliRot(φ) == PPR(φ/2)). (#2414)Fixed the
catalystCLI tool silently listening to stdin when run without an input file, even when given flags like--list-passesthat should override this behaviour. (#2447)Fixed a bug with incorrect lowering of PPMs (Pauli product measurements) into CAPI calls when the PPM is in the negative basis. (#2422)
Fixed a bug with incorrect decomposition of negative PPR (Pauli Product Rotation) operations in the
decompose-clifford-ppranddecompose-non-clifford-pprpasses. The rotation sign is now correctly flipped when decomposing negative rotation kinds (e.g.,-π/4from adjoint gates likeT†orS†) to PPM (Pauli Product Measurement) operations. (#2454)Fixed the
GlobalPhasediscrepancies when executinggridsynthin the PPR basis. (#2433)Fixed a bug with
GlobalPhasewhen loweringCNOTgates into PPR/PPM operations. (#2459)Fixed a bug where the Catalyst measurement primitive returning a boolean type as the measurement result was incorrectly replacing the PennyLane measurement primitive, whose measurement result is integer type, during plxpr conversion. (#2582)
Fixed a bug where the xDSL string-output path in
Compiler.runwould emit empty result attributes on void functions, triggering an assertion in MLIR’s FuncToLLVM lowering. The empty attributes are now removed in-place so the generic printer omits them. (#2805)
Internal changes ⚙️
An end-to-end pipeline for OQD (Open Quantum Design) has been added to Catalyst. The pipeline supports compilation to LLVM IR using the
QJITconstructor withlink=False, enabling integration with ARTIQ’s cross-compilation toolchain. The generated LLVM IR can be used with the internalcompile_to_artiq()function from the third-party OQD repository to produce ARTIQ binaries. (#2299)See
frontend/test/test_oqd/oqd/test_oqd_artiq_llvmir.pyfor more details. For example:import os import numpy as np import pennylane as qp from catalyst import qjit from catalyst.third_party.oqd import OQDDevice, OQDDevicePipeline OQD_PIPELINES = OQDDevicePipeline( os.path.join("calibration_data", "device.toml"), os.path.join("calibration_data", "qubit.toml"), os.path.join("calibration_data", "gate.toml"), os.path.join("device_db", "device_db.json"), ) oqd_dev = OQDDevice( backend="default", shots=4, wires=1 ) qp.capture.enable() # Compile to LLVM IR only @qp.qnode(oqd_dev) def circuit(): x = np.pi / 2 qp.RX(x, wires=0) return qp.counts(wires=0) compiled_circuit = QJIT(circuit, CompileOptions(link=False, pipelines=OQD_PIPELINES)) # Compile to ARTIQ ELF artiq_config = { "kernel_ld": "/path/to/kernel.ld", "llc_path": "/path/to/llc", "lld_path": "/path/to/ld.lld", } output_elf_path = compile_to_artiq(compiled_circuit, artiq_config) # Output: # LLVM IR file written to: /path/to/circuit.ll # [ARTIQ] Generated ELF: /path/to/circuit.elf
Mid-circuit measurements (
qp.measure) are now supported on the OQD backend. Aqp.measurecall is lowered to an OpenAPL’sMeasurePulsefor fluorescence detection, which is executed by the trapped-ion hardware at runtime. (#2508)To enable mid-circuit measurement, add a
[[detection_beam]]section and ameasurement_durationfield to thegate.tomlcalibration file:For example:
measurement_duration = 1e-4 # seconds [[detection_beam]] rabi = 62831853071.79586 transition = "downstate_estate" detuning = 0.0 polarization = [1, 0, 0] wavevector = [0, 1, 0]
The following circuit will produce an OpenAPL program with a
MeasurePulse:oqd_dev = OQDDevice(backend="default", wires=1, openapl_file_name="out.json") @qjit(pipelines=OQD_PIPELINES) @qp.set_shots(10) @qp.qnode(oqd_dev) def circuit(): qp.measure(wires=0) return qp.counts(wires=0)
In addition, the MS gate beam lookup for this measurement testbench was redesigned: sideband beam parameters are now read directly from the calibration database instead of being computed from per-qubit phonon offsets.
The compiler pipeline definitions now have a single source of truth. Previously, pipeline and pass sequences were duplicated between the frontend (
frontend/catalyst/pipelines.py) and the compiler (mlir/lib/Driver/Pipelines.cpp). Now, there is a unique definition that lives inmlir/include/Driver/DefaultPipelines.hand is exposed to the frontend via adefault_pipelinesnanobind extension module. This module is built during the MLIR compilation phase and discovered at runtime. (#2259) (#2733)An experimental lookup table (LUT) decoder has been added to the
runtime. This initial implementation is optimized for the [[7,1,3]] Steane code using hardcoded Quantum Error Correction (QEC) data. While the architecture supports future extension to general LUT decoding via compiler-provided information, please note that LUT decoders scale exponentially with code size and are intended for small-scale QEC codes only. (#2724)Additional integration tests have been added for the pass-by-pass version of
qp.specs. (#2690)Unnecessary registrations were removed for the various gradient primitives in
from_plxprwhen we are able to just inherit the base behaviour fromPlxprInterpreter. (#2706)The legacy frontend no longer registers
qp.allocate()andqp.deallocate()onto the qjit device capabilities, since dynamic qubit allocation is only implemented for the capture frontend. (#2696)Refactors
draw_graphimplementation to improve maintainability. (#2659)Bumped
blackversion to 26.3.1 to eliminate the vulnerability reported by dependabot. (#2650)Updated Catalyst’s Catch2 dependency to v3.11.0. (#2634)
rtio.rpcoperation is added to the RTIO dialect for OQD. It represents a host RPC call triggered by the kernel, optionally carrying runtime arguments and supporting both synchronous and async modes. The op is lowered to rpc_send / rpc_recv LLVM calls (the ARTIQ RPC wire protocol). It is required by both AWG control (program_awg, awg_close) and measurement result collection (set_dataset, transfer_data). (#2577)Added an optimized pathway to the xDSL
ApplyTransformSequencePassso that it can schedule consecutive MLIR passes together rather than individually. This minimizes the number of round-trips between xDSL and MLIR, improving performance when several consecutive MLIR passes are used when there are also xDSL passes in the pipeline. (#2592)draw_graphnow raises a more informative error when attempting to visualize an unsupported empty external function. (#2559)Catalyst internally uses the new unified transforms API rather than
PassPipelineWrapper. (#2525) (#2614) (#2647)Added an
EmptyPassMLIR pass that does not transform the program for debugging and standing in for unimplemented transforms. (#2575)The QNode lowering to MLIR now supports providing multiple named transform pipelines. (#2556)
Both the MLIR and xDSL
ApplyTransformSequencePassimplementations have been updated to support interpreting multipletransform.named_sequenceoperations for a single transformer module. (#2550)Updated nightly RC builds to be triggered by Lightning. (#2491)
Updated integration tests to match changes to the PennyLane
qp.specsfrontend made in https://github.com/PennyLaneAI/pennylane/pull/9088 and https://github.com/PennyLaneAI/pennylane/pull/9091. (#2513) (#2533)The
prepareoperation from the PBC dialect in MLIR now implicitly allocates new qubits rather than requiring existing ones. This better suits our purposes for further lowering the PBC dialect. (#2520)Standardized the
QJITDevice.preprocesssignature to align with the base PennyLane Device API.Removed the redundant
ctx(EvaluationContext) argument from the preprocessing and decomposition pipelines. The parameter was unused and its removal simplifies the tracing data flow.Decoupled
shotsfrom theQJITDevice.preprocesssignature. Catalyst-specific shot configurations are now handled viaexecution_config.device_optionsto maintain API compatibility. (#2524)
A new dialect
QRefwas created. This dialect is very similar to the existingQuantumdialect, but it is in reference semantics, whereas the existingQuantumdialect is in value semantics. (#2320) (#2590) (#2492) (#2674) (#2642) (#2692) (#2721) (#2723) (#2758)Unlike qubit (or qreg) SSA values in the
Quantumdialect, a qubit (or qreg) reference SSA value in theQRefdialect is allowed to be used multiple times. The operands of gates and observables will be these qubit (or qreg) reference values.For example, in the following circuit, gates and observable ops take in the qubit reference they’re acting on, and do not produce new qubit values.
func.func @expval_circuit() -> f64 { %a = qref.alloc(2) : !qref.reg<2> %q0 = qref.get %a[0] : !qref.reg<2> -> !qref.bit %q1 = qref.get %a[1] : !qref.reg<2> -> !qref.bit qref.custom "Hadamard"() %q0 : !qref.bit qref.custom "CNOT"() %q0, %q1 : !qref.bit, !qref.bit qref.custom "Hadamard"() %q0 : !qref.bit %obs = qref.namedobs %q1 [ PauliX] : !quantum.obs %expval = quantum.expval %obs : f64 qref.dealloc %a : !qref.reg<2> return %expval : f64 }
Notice that qubit reference values are reusable.
An MLIR program in the
QRefdialect can be converted to theQuantumdialect with the new pass--convert-to-value-semantics, optionally followed by--canonicalizefor removing pairs of neighboring inversequantum.extractandquantum.insertoperations.Apart from those in the
Quantumdialect, reference semantics operations for their value semantics counterparts in theMBQCdialect were also added.A new pass
--verify-no-quantum-use-after-freewas added to the newQRefdialect, to verify that there are no uses of quantum values after they have been deallocated. (#2674)Removed the
conditionoperand frompbc.ppm(Pauli Product Measurement) operations. Conditional PPR decompositions in thedecompose-clifford-pprpass now emit the measurement logic inside anscf.ifregion rather than propagating the condition to inner PPM ops. (#2511)The operands and assembly format of several PBC operations have been updated for clarity and improved functionality. (#2637)
A
QJIT’scompilemethod can now be used to run MLIR compilation without having to generate LLVM IR and object code. Use withCompileOptions(lower_to_llvm=False, link=False). (#2599)Update
mlir_specsto account for newmarkerfunctionality in PennyLane. (#2464)Updated the integration tests for
qp.specsto get coverage for new features (#2448)The xDSL
Quantumdialect has been split into multiple files to structure operations and attributes more concretely. (#2434)catalyst.python_interface.xdsl_universe.XDSL_UNIVERSEhas been renamed toCATALYST_XDSL_UNIVERSE. (#2435)The private helper
_extract_passesofqfunc.pyusesBoundTransform.tape_transforminstead of the deprecatedBoundTransform.transform.jax_tracer.pyandtracing.pyalso updated accordingly. (#2440)Autograph is no longer applied to decomposition rules based on whether it’s applied to the workflow itself. Operator developers now need to manually apply autograph to decomposition rules when needed. (#2421)
The quantum dialect MLIR and TableGen source has been refactored to place type and attribute definitions in separate file scopes. (#2329)
Improve speed and reliability of xDSL inspection functionality by only running the necessary compilation steps if the QJIT object does not already have an MLIR representation. (#2598)
Added lowering of
pbc.ppm,pbc.ppr, andquantum.paulirotto the runtime CAPI and QuantumDevice C++ API. (#2348) (#2413) (#2683)A new compiler pass,
unroll-conditional-ppr-ppm, has been added to convert conditional or multiplexed Pauli-product rotations and measurements into their basic versions nested inside conditionals (from the SCF dialect). Note that this is not needed for the standard execution pipeline. (#2390)Increased format size for the
--mlir-timingflag, displaying more decimals for better timing precision. (#2423)Added global phase tracking to the
to-pprcompiler pass. When converting quantum gates to Pauli Product Rotations (PPR), the pass now emitsquantum.gphaseoperations to preserve global phase correctness. (#2419)The upstream MLIR
Testdialect is now available via thecatalystcommand line tool. (#2417)A new compiler pass
lower-pbc-init-opshas been added to lower PBC initialization operations to Quantum dialect operations. This pass convertspbc.preparetoquantum.customandpbc.fabricatetoquantum.alloc_qb+quantum.custom, enabling runtime execution of PBC state preparation operations. (#2424)A new MLIR op,
MCMObsOp, is defined as a pseudo-observable of mid-circuit measurements for use in measurement processes. It is also registered in xDSL. (#2458) (#2536)An experimental QEC Logical MLIR dialect has been added. An equivalent xDSL dialect has also been added for compatibility with the Python interface to Catalyst. (#2512) (#2535) (#2543) (#2544) (#2547) (#2549) (#2665)
An experimental QEC Physical MLIR dialect has been added. An equivalent xDSL dialect has also been added for compatibility with the Python interface to Catalyst. (#2519) (#2537) (#2563) (#2571) (#2572) (#2574) (#2576) (#2673) (#2768)
An experimental pass has been added to convert
qecl.noiseoperations in the QEC Logical layer to subroutine calls in the QEC Physical layer. (#2678)A new, experimental compiler pass
convert-quantum-to-qeclhas been added to lower operations from thequantumdialect into the QEC Logical (qecl) dialect. (#2589)An experimental compiler pass
inject-noise-to-qeclhas been added to inject noise operations into the QEC Logical (qecl) layer to validate QEC protocols under development. (#2705)A new, experimental compiler pass
convert-qecl-to-qecphas been added to lower operations from the QEC Logical (qecl) dialect into the QEC Physical (qecp) dialect. (#2697) (#2714) (#2716) (#2737) (#2731) (#2735) (#2754)A number of deprecation warnings have been fixed in the compiler python interface. (#2621)
Python
dataclassobjects can now be converted to MLIR dictionary attributes, allowing them to be used as xDSL pass options, for example. (#2719)
Documentation 📝
A new AI policy document is now applied across the PennyLaneAI organization for all AI contributions. (#2488)
The PennyLane import alias has been updated to
qpin our source code and documentation. (#2764) (#2763) (#2748) (#2746) (#2745) (#2744) (#2743) (#2742) (#2741) (#2739) (#2738) (#2736) (#2715)The “Compatibility with PennyLane transforms” section of the Sharp bits and debugging tips document has been updated to describe potential oddities that can be encountered when composing PennyLane transforms together. Additionally, some sharp bits listed were removed, as they are no longer sharp bits. (#2662)
Docstrings for
disentangle_cnot()anddisentangle_swap()have been improved by using updated features for inspection and by calling them from the PennyLane frontend. (#2546) (#2804)Typos and rendering issues in various docstrings in the
catalyst.passesmodule were fixed. (#2649)The Unified Compiler Cookbook has been updated to be compatible with the latest versions of PennyLane and Catalyst. (#2406)
The changelog and
builtin_passes.pyhave been updated to link to https://pennylane.ai/compilation/pauli-based-computation instead. (#2409)Infrastructure has been put in place for features that are accessible from both PennyLane and Catalyst to have a single source of truth for documentation, which will provide a better overall experience when consulting our documentation. (#2481) (#2629)
Several entry-points were added to
setup.pyfor the Pauli-based computation compilation passes and thedraw_graph()function. This allows for the ability to use Catalyst features from PennyLane directly (related: (#9020)) and for the documentation of those features to be accessible to both Catalyst and PennyLane, creating a single source of truth for such features.In addition, the documentation for all Pauli-based computation transforms has been updated to be more user-focused by showing examples with
specs()and by calling the transforms from the PennyLane frontend.
Contributors ✍️
This release contains contributions from (in alphabetical order): Ali Asadi, Joey Carter, Yushao Chen, Isaac De Vlugt, Marcus Edwards, Lillian Frederiksen, Sengthai Heng, David Ittah, Jeffrey Kam, Joseph Lee, Mehrdad Malekmohammadi, River McCubbin, Mudit Pandey, Andrija Paurevic, David D.W. Ren, Shuli Shu, Paul Haochen Wang, David Wierichs, Jake Zaia, Hongsheng Zheng.
Release 0.14.1¶
Bug fixes
The
gastpackage is now an explicit dependency in Catalyst. Thegastpackage was previously pulled in transitively bydiastatic-malt, butdiastatic-malt==2.15.3droppedgastas a dependency, which caused an error when importing Catalyst. #2565
Contributors
This release contains contributions from (in alphabetical order):
David Ittah, Haochen Paul Wang.
Release 0.14.0¶
New features since last release
Programs compiled with
qjitcan now be visualized withdraw_graph(), allowing for sequentially analyzing impacts of compilation passes on structured and dynamic programs. (#2213) (#2214) (#2218) (#2229) (#2231) (#2234) (#2243) (#2246) (#2260) (#2285) (#2287) (#2298) (#2290) (#2340) (#2357) (#2309) (#2363) (#2380)Consider the following circuit:
import pennylane as qml import catalyst @qml.qjit(autograph=True) @catalyst.passes.cancel_inverses @catalyst.passes.merge_rotations @qml.qnode(qml.device("null.qubit", wires=3)) def circuit(x, y): qml.X(0) qml.Y(1) qml.H(x) qml.GlobalPhase(1.0) for i in range(3): qml.S(0) qml.RX(0.1, wires=1) qml.RX(0.2, wires=1) if i == 3: qml.T(0) else: qml.H(0) qml.H(0) qml.H(x) return qml.expval(qml.Z(y))
The circuit structure (
forloop and conditional branches) along with the dynamicism (variablesxandy) can be succinctly represented withdraw_graph().>>> x, y = 1, 0 >>> fig, ax = catalyst.draw_graph(circuit)(x, y) >>> fig.savefig('path_to_file.png', dpi=300, bbox_inches="tight")
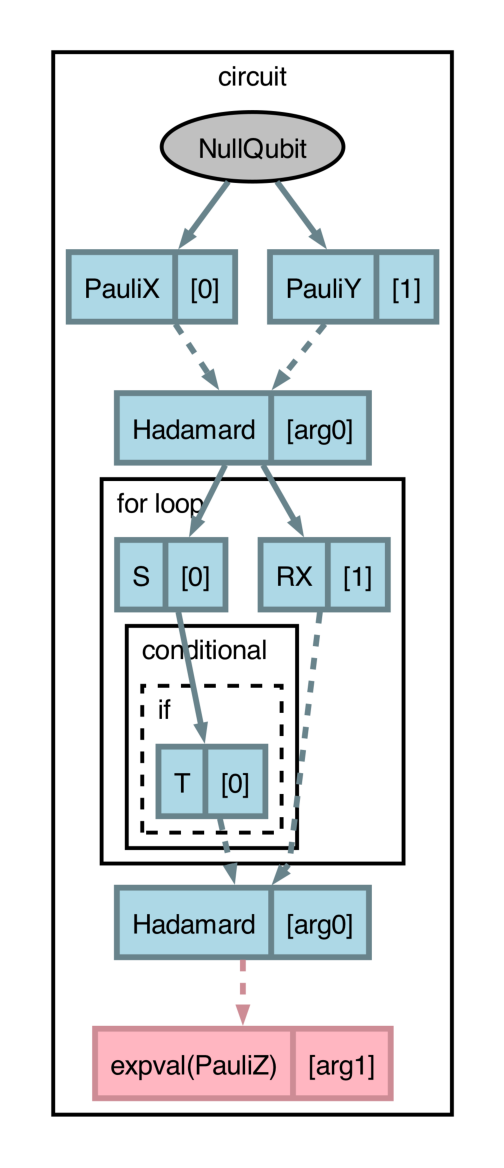
The output of
draw_graph()is amatplotlib.figure.Figure, allowing for natural manipulations like increasing resolution, size, etc.By default, all compilation passes specified will be applied and visualized. However,
draw_graph()can be used with thelevelargument to inspect compilation pass impacts, where thelevelvalue denotes the cumulative set of applied compilation transforms (in the order they appear) to be applied and visualized. Withlevel=1, drawing the above circuit will apply themerge_rotationtransform only:>>> fig, ax = catalyst.draw_graph(circuit, level=1)(x, y) >>> fig.savefig('path_to_file.png', dpi=300, bbox_inches="tight")
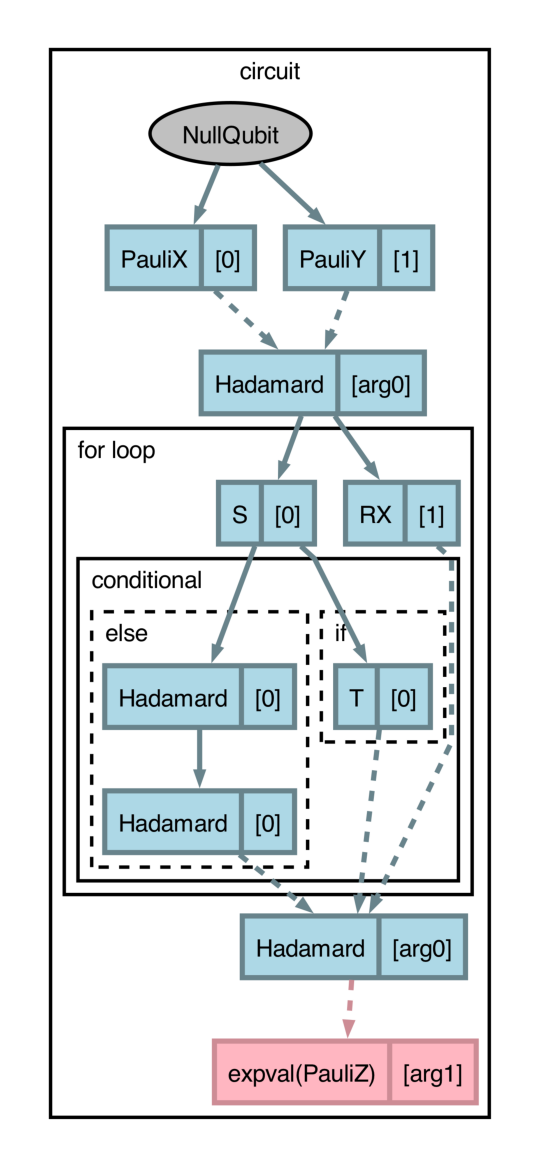
The
draw_graph()function visualizes aqjit-compiled QNode in a similar manner as view-op-graph does in MLIR, which leverages Graphviz to show data-flow in the compiled IR. As such, use ofdraw_graph()requires installation of Graphviz and the pydot software package. Please consult the links provided for installation instructions. Additionally, it is recommended to usedraw_graph()with PennyLane’s program capture enabled (seeqml.capture.enable).The Ross-Sellinger Gridsynth algorithm for discretizing
RZandPhaseShiftgates has been added to Catalyst withgridsynth(), allowing for Clifford+T workloads to benefit more from just-in-time compilation withqjit. (#2140) (#2166) (#2292)The
gridsynth()compilation pass discretizesRZandPhaseShiftgates to either the Clifford+T basis or to the Pauli-product-rotation (PPR) basis, complimenting existing transforms likepennylane.transforms.clifford_t_decomposition()and Pauli-based-computation compilation passes. This pass is also callable from the PennyLane frontend viapennylane.transforms.gridsynth().A new statevector simulator called
lightning.amdgpuhas been added for optimized performance on AMD GPUs, and is compatible with Catalyst. (#2283)The
lightning.amdgpudevice is a specific instantiation of thelightning.kokkosbackend, supporting the same features and operations aslightning.kokkos, with pre-compiled wheels forlightning.amdgpuavailable on PyPI for easy installation to use on MI300 series AMD GPUs.This device can be used within
qjit‘d workflows exactly as other devices compatible with Catalyst:@qml.qjit @qml.qnode(qml.device('lightning.amdgpu', wires=2)) def circuit(): qml.Hadamard(0) return qml.state()
>>> circuit() [0.70710678+0.j 0. +0.j 0.70710678+0.j 0. +0.j]
See the Lightning-AMDGPU documentation for more details and installation instructions.
A new control-flow operation has been added called
catalyst.switch(), which is aqjit-compatible index-switch style control flow decorator. Switches allow for more efficient, non-recursive lowering of distinct cases and can simplify control flow among multiple branches. (#2171)from catalyst import qjit, switch @qjit @qml.qnode(qml.device("lightning.qubit", wires=1)) def my_circuit(i, theta): @switch(i) # initialize a switch on variable i def my_switch(angle): # this is the default branch (required) qml.RX(angle, wires=0) @my_switch.branch(1) # create a branch with case i = 1 def my_branch(angle): qml.RY(angle, wires=0) @my_switch.branch(4) # create a branch with case i = 4 def my_branch_4(angle): qml.H(0) my_switch(theta) # must invoke the switch return qml.probs()
Catalyst can now compile circuits that are directly expressed in terms of Pauli product rotation (PPR) and Pauli product measurement (PPM) operations:
PauliRotandpauli_measure(), respectively. This is only supported with PennyLane program capture enabled (pennylane.capture.enable()). This support enables research and development spurred from A Game of Surface Codes (arXiv1808.02892). (#2145) (#2233) (#2284) (#2296) (#2336) (#2360)PauliRotandpauli_measure()can be manipulated with Catalyst’s existing passes for PPR-PPM compilation only when PennyLane program capture is enabled. This includespennylane.transforms.to_ppr(),pennylane.transforms.commute_ppr(),pennylane.transforms.merge_ppr_ppm(),pennylane.transforms.ppr_to_ppm(),pennylane.transforms.reduce_t_depth(),pennylane.transforms.decompose_arbitrary_ppr()andpennylane.transforms.ppm_compilation(). Note that these transforms must be called from the PennyLane frontend, not fromcatalyst.passes.import pennylane as qml import jax.numpy as jnp import catalyst qml.capture.enable() pipelines=[('pip', ["quantum-compilation-stage"])] @qml.qjit(pipelines=pipelines, target="mlir") @qml.transforms.ppm_compilation @qml.qnode(qml.device("null.qubit", wires=4)) def circuit(): # equivalent to a Hadamard gate qml.PauliRot(jnp.pi / 2, pauli_word="Z", wires=0) qml.PauliRot(jnp.pi / 2, pauli_word="X", wires=0) qml.PauliRot(jnp.pi / 2, pauli_word="Z", wires=0) # equivalent to a CNOT gate qml.PauliRot(jnp.pi / 2, pauli_word="ZX", wires=[0, 1]) qml.PauliRot(-jnp.pi / 2, pauli_word="Z", wires=[0]) qml.PauliRot(-jnp.pi / 2, pauli_word="X", wires=[1]) # equivalent to a T gate qml.PauliRot(jnp.pi / 4, pauli_word="Z", wires=0) ppm = qml.pauli_measure(pauli_word="ZXY", wires=[1, 2, 0]) return
>>> print(circuit.mlir_opt) ... %3 = qec.fabricate magic : !quantum.bit %mres, %out_qubits:2 = qec.ppm ["X", "Z"] %1, %3 : i1, !quantum.bit, !quantum.bit %mres_0, %out_qubits_1 = qec.select.ppm(%mres, ["Y"], ["X"]) %out_qubits#1 : i1, !quantum.bit %4 = qec.ppr ["X"](2) %out_qubits#0 cond(%mres_0) : !quantum.bit quantum.dealloc_qb %out_qubits_1 : !quantum.bit %5 = quantum.extract %0[ 2] : !quantum.reg -> !quantum.bit %mres_2, %out_qubits_3:3 = qec.ppm ["Z", "Y", "X"] %4, %2, %5 : i1, !quantum.bit, !quantum.bit, !quantum.bit ...
A new transform called
decompose_arbitrary_ppr()pass has been added, which decomposes abitrary-angle Pauli-product rotations (PPRs) as outlined in Figure 13(d) from arXiv:2211.15465. (#2304) (#2354)An arbitrary-angle PPR is defined as a PPR whose angle of rotation is not \(\tfrac{\pi}{2}\), \(\tfrac{\pi}{4}\), or \(\tfrac{\pi}{8}\). The
decompose_arbitrary_ppr()compilation pass will decompose an arbitrary-angle PPR into a collection of non-arbitrary PPRs, Pauli-product measurements (PPMs), and a single-qubit arbitrary PPR in theZbasis.For compatibility with
pennylane.specs(), it is recommended to use this transform with PennyLane program capture enabled and by calling it from the PennyLane frontend (pennylane.transforms.decompose_arbitrary_ppr()), not fromcatalyst.passes.import pennylane as qml qml.capture.enable() @qml.qjit(target="mlir") @qml.transforms.decompose_arbitrary_ppr @qml.transforms.to_ppr @qml.qnode(qml.device("null.qubit", wires=3)) def circuit(): qml.PauliRot(0.1, pauli_word="XY", wires=[0, 1]) return
>>> print(qml.specs(circuit, level=3)()) Device: null.qubit Device wires: 3 Shots: Shots(total=None) Level: 3 Resource specifications: Total wire allocations: 4 Total gates: 6 Circuit depth: Not computed Gate types: qec.prepare: 1 PPM: 2 PPR-pi/2: 2 PPR-Phi: 1 Measurements: No measurements.


Improvements 🛠
An informative error is now raised if a transform is applied inside of a
qjit‘d QNode when PennyLane’s program capture is enabled. (#2256)@qml.qjit @qml.qnode(qml.device('lightning.qubit', wires=1)) @qml.transforms.cancel_inverses def c(): qml.X(0) qml.X(0) return qml.probs()
>>> c() NotImplementedError: transforms cannot currently be applied inside a QNode.
qml.PCPhasecan now beqjit-compiled and executed with PennyLane’s program capture enabled. (#2226)The new graph-based decomposition framework (enabled with
pennylane.decomposition.enable_graph()) has Autograph feature parity with PennyLane when PennyLane’s program capture is enabled. When compiling withqml.qjit(autograph=True), the decomposition rules returned by the graph-based framework are now correctly compiled using Autograph. This ensures compatibility and deeper optimization for dynamically generated decomposition rules. (#2161)The decomposition of
qml.MultiRZoperations with an arbitrary number of wires is now supported at the MLIR level with graph-based decompositions enabled and PennyLane’s program capture enabled. (#2160)Catalyst can now use the new
pass_nameproperty of pennylane transform objects. Passes can now be created usingqml.transform(pass_name=pass_name)instead ofPassPipelineWrapper. This allows for better integration of Catalyst transforms with the PennyLane frontend. (#2149Compilation passes registered in PennyLane via
@qml.transformcan now take in optional keyword arguments when used withqjit()and when PennyLane’s program capture is enabled. (#2154)Pytree inputs can now be used when PennyLane’s program capture is enabled. (#2165)
The
ppr-to-mbqcpass now supports loweringqec.ppr.arbitraryoperations (Pauli Product Rotations with arbitrary angles) to MBQC-style gate sequences. The lowering follows the same pattern as fixed-angle PPR operations: conjugation gates to map Paulis to the Z-basis, a CNOT ladder to accumulate parity, an RZ gate with angle2θ(whereθis the PPR angle), and reverse operations to restore the original basis. (#2373)qml.gradandqml.jacobiancan now be used withqjitwhen PennyLane’s program capture is enabled. (#2078)A new
"changed"option has been added to thekeep_intermediateparameter ofqjit(). This option saves intermediate IR files after each pass, but only when the IR is actually modified by the pass. Additionally, intermediate IR files are now organized into subdirectories for each compilation stage when usingkeep_intermediate="changed"orkeep_intermediate="pass". These changes culminate in better IR file management. (#2186)Resource tracking with
pennylane.specs()now includesqml.StatePrepoperations and accounts for dynamic wire allocation (pennylane.allocate()). (#2230) (#2203)When saving the IR that each compilation pass generates, the
apply-transform-sequencepass is now counted as a single pass instead of potentially many passes. (#1978)A new option called
use_namelochas been added toqjit()that embeds variable names from Python into the compiler IR, which can make it easier to read when debugging programs. (#2054)Dynamically allocated wires (
pennylane.allocate()) can now be passed into control flow blocks and subroutines. (#2130) (#2268)The
--adjoint-loweringpass can now handle Pauli-product rotation (PPR) operations. (#2227)Catalyst now supports Pauli product rotations (PPR) with arbitrary or dynamic angles in the QEC dialect. This will allow
pennylane.PauliRotwith arbitrary or dynamic angles (angles not known at compile time) to be lowered to the QEC dialect. This is implemented as a newqec.ppr.arbitraryoperation, which takes a Pauli-product and an arbitrary or dynamic angle as input. (#2232) (#2233)For example:
%const = arith.constant 0.124 : f64 %1:2 = qec.ppr.arbitrary ["X", "Z"](%const) %q1, %q2 : !quantum.bit, !quantum.bit %2:2 = qec.ppr.arbitrary ["X", "Z"](%const) %1#0, %1#1 cond(%c0) : !quantum.bit, !quantum.bit
Catalyst now features a unified compilation framework, which will enable users and developers to design and implement compilation passes in Python in addition to C++, acting on the same Catalyst IR. The Python interface relies on the
xDSL library <https://xdsl.dev/>to represent and manipulate programs (analogous to the MLIR library in C++). As a result, transformations can be quickly prototyped, easily debugged, and dynamically integrated into Catalyst without changes to the compiled Catalyst package. (#2199)This new module is available under the
catalyst.python_interfacenamespace, and will feature more user-friendly functionality for writingqjit-compatible compilation passes in upcoming releases.This functionality was originally developed as part of the PennyLane package, and has been migrated here. For earlier development notes to the feature, please refer to the PennyLane release notes.
Here is a list of what’s included with this change:
Added the
PauliRotOp,PCPhaseOp, andPPRotationArbitraryOpoperations to the xDSL quantum dialect. (#2307) (#8621)An xDSL
Universecontaining all custom xDSL dialects and passes has been registered as an entry point, allowing usage of PennyLane’s dialects and passes with xDSL’s command-line tools. (#2208)A new
catalyst.python_interface.inspection.mlir_specsfunction has been added to facilitate PennyLane’s new pass-by-passpennylane.specs()feature withqjit. This function returns information gathered by parsing the xDSL-generated MLIR from a given QJIT object, such as gate counts, measurements, or qubit allocations. (#2238) (#2303) (#2315)Added an experimental
outline_state_evolution_passxDSL pass tocatalyst.python_interface.transforms, which moves all quantum gate operations to a private callable. (#8367)A new experimental
split_non_commuting_passcompiler pass has been added tocatalyst.python_interface.transforms. This pass splits quantum functions that measure observables on the same wires into multiple function executions, where each execution measures observables on different wires (using the"wires"grouping strategy). The original function is replaced with calls to these generated functions, and the results are combined appropriately. (#8531)Users can now apply xDSL passes without the need to pass the
pass_pluginsargument to theqjitdecorator. (#8572) (#8573) (#2169) (#2183)The
catalyst.python_interface.transforms.convert_to_mbqc_formalism_pass()now supportsIndexSwitchOpin the IR and ignores regions that have no body. (#8632)The
convert_to_mbqc_formalismcompilation pass now outlines the operations to represent a gate in the MBQC formalism into subroutines in order to reduce the IR size for large programs. (#8619)The
catalyst.python_interface.Compiler.run()method now accepts a string as input, which is parsed and transformed with xDSL. (#8587)An
is_xdsl_passfunction has been added to thecatalyst.python_interface.pass_apimodule. This function checks if a pass name corresponds to an xDSL implemented pass. (#8572)A new
catalyst.python_interface.utilssubmodule has been added, containing general-purpose utilities for working with xDSL. This includes a function that extracts the concrete value of scalar, constant SSA values. (#8514)The
catalyst.python_interface.visualizationmodule has been renamed tocatalyst.python_interface.inspection, and various utility functions within this module have been streamlined. (#2237)The experimental xDSL
measurements_from_samples_pass()pass has been updated to supportshotsdefined by anarith.constantoperation. (#8460)Removed the
catalyst.python_interface.dialects.transformmodule in favor of using thexdsl.dialects.transformmodule directly. (#2261)Added a “Unified Compiler Cookbook” RST file, along with tutorials, to
catalyst.python_interface.doc, which provides a quickstart guide for getting started with xDSL and its integration with PennyLane and Catalyst. (#8571)xDSL passes are now automatically detected when using the
qjitdecorator. This removes the need to pass thepass_pluginsargument to theqjitdecorator. (#2169) (#2183)The
mlir_optproperty now correctly handles xDSL passes by automatically detecting when the Python compiler is being used and routing through it appropriately. (#2190)A new experimental
parity_synth_passcompiler pass has been added tocatalyst.python_interface.transforms. This pass groupsCNOTandRZoperators into phase polynomials and re-synthesizes them intoCNOTandRZoperators again. (#2294)The
catalyst.python_interface.pass_api.PassDispatchernow has a more lightweight implementation. (#2324)The global xDSL pass registry is now explicitly refreshed before compiling workflows decorated with
catalyst.qjit(). (#2322)
Breaking changes 💔
The standard Catalyst pipelines have been restructured, such that default and user QNode passes are run together in the first pipeline. For this purpose, the old
quantum-compilation-pipelineandenforce-runtime-invariants-pipelinehave been merged into a singlequantum-compilation-pipeline, while a newgradient-lowering-pipelinehas been split out from the oldquantum-compilation-pipeline. (#2186)The
pipelineand"passes"postfixes in the compilation stage names have been changed tostagefor clarity. (#2230)The JAX version used by Catalyst has been updated to 0.7.0. (#2131)
(Compiler integrators only) The versions of LLVM/Enzyme/stablehlo used by Catalyst have been updated. (#2122) (#2174) (#2175) (#2181)
The LLVM version has been updated to commit 113f01a.
The stablehlo version has been updated to commit 0a4440a.
The Enzyme version has been updated to v0.0.203.
The
remove-chained-self-inversepass has been renamed tocancel-inversesto better conform with the name of the corresponding transform in PennyLane. (#2201)The
to-pprpass now automatically runs canonicalization patterns after converting quantum operations to Pauli Product Rotation (PPR) form. This removes identity Pauli rotations (e.g.,["I", "I", "I"]) automatically, simplifying the resulting IR. (#2367)
Deprecations 👋
No deprecations have been made in this release.
Bug fixes 🐛
Fixed a bug in the
catalyst.passes.merge_ppr_ppm()that was causing an iteration out-of-bound error. (#2359)Updated the type support for callbacks allowing for the use of unsigned integers. (#2330)
Fixed a bug in the
gradient.value_and_gradverifier that incorrectly validated gradient result types by matching from the tail of callee arguments, ignoringdiffArgIndices. This caused false verification errors when differentiating a subset of arguments with different types. (#2349)Fixed a bug in the
catalyst.python_interface.pass_api.TranformInterpreterPasspass that prevented pass options from being used correctly. (#2289)The experimental xDSL
diagonalize_measurements()pass has been updated to fix a bug that included the wrong SSA value for final qubit insertion and deallocation at the end of the circuit. A clear error is now also raised when there are observables with overlapping wires. (#8383)Fixed a bug in the constructor of the xDSL Quantum dialect’s
QubitUnitaryOpthat prevented an instance from being constructed. (#8456)Fixed a bug where the
qec.pprop attributerotation_kindwas not correctly constrained to be one of±1,±2,±4, or±8. Also, for the identity Pauli product, therotation_kindwas correctly set to1, instead of0. (#2344)Running the Catalyst compiler from the command line no longer misses the
detensorize-function-boundaryandsymbol-dcepasses. (#2266)Fixed an issue where a heap-to-stack allocation conversion pass was causing SIGSEGV issues during program execution at runtime. (#2172)
Fixed an issue with capturing unutilized abstracted adjoint and controlled rules by the graph in the new decomposition framework. (#2160)
Fixed the translation of PennyLane control flow (
qml.for_loop) to Catalyst control flow for edge cases where theconstswere being reordered. (#2128) (#2133)Fixed the translation of
QubitUnitaryandGlobalPhaseoperations to Catalyst when they are modified byadjointorctrl. (##2158)Fixed an issue with the translation of a workflow with different transforms applied to different QNodes, which was causing transforms to act beyond the code they are intended to be applied to. (#2167)
Fixed canonicalization of redundant
quantum.insertandquantum.extractpairs. When extracting a qubit immediately after inserting it at the same index, the operations can be cancelled out while properly updating remaining uses of the register. (#2162)For an example:
// Before canonicalization %1 = quantum.insert %0[%idx], %qubit1 : !quantum.reg, !quantum.bit %2 = quantum.extract %1[%idx] : !quantum.reg -> !quantum.bit ... %3 = quantum.insert %1[%i0], %qubit2 : !quantum.reg, !quantum.bit %4 = quantum.extract %1[%i1] : !quantum.reg -> !quantum.bit // ... use %1 // ... use %4 // After canonicalization // %2 directly uses %qubit1 // %3 and %4 updated to use %0 instead of %1 %3 = quantum.insert %0[%i0], %qubit2 : !quantum.reg, !quantum.bit %4 = quantum.extract %0[%i1] : !quantum.reg -> !quantum.bit // ... use %qubit1 // ... use %4
Fixed an issue with
commute_ppr()andmerge_ppr_ppm()where they were incorrectly moving operations. This also improves the compilation time by reducing the sort function by explicitly passing the operations that need to be sorted. (#2200)Fixed a bug that was causing compilation passes to not apply when using
mcm_method="one-shot". (#2198)Fixed a bug where
qml.StatePrepandqml.BasisStatemight be pushed after other gates, overwriting their effects. (#2239)Fixed a bug where
quantum.num_qubitsoperations were not properly removed during classical processing of gradient transforms. This fix enables automatic qubit management (i.e., creating a device and not providing thewiresargument) to be used with gradients. (#2262)Fixed a but with
commute_ppr()that was incorrectly modifying operands of PPRs that live in different blocks of MLIR. (#2267)The
--inline-nested-modulepass no longer renames external function declarations. This pass inlines the QNode MLIR modules into the global QJIT MLIR module. If a QNode module contains function declarations to external APIs, the names of these declarations must stay unchanged. This change enables quantum compilation passes to generate calls to external APIs. (#2244)Fixed a bug where Catalyst was incorrectly raising an error about a missing shots parameter on devices that support analytical execution. (#2281)
Fixed a bug where
qml.vjpandqml.jvpwere not working with Autograph. (#2345)Fixed incorrect detection of tracer wires in the frontend. Previously, NumPy integers would be detected as dynamic wires leading to unnecessary instructions in the program IR. (#2361)
Internal changes ⚙️
The jaxpr transform
pl_map_wireshas been removed along with its test. (#2220)DecompRuleInterpreternow solves the graph and adds decompositions rules in thecleanupmethod instead of during the first call tointerpret_measurement. (#2312)Updated references to
TransformProgramwith the newpennylane.CompilePipelineclass. (#2314)xDSL and xDSL-JAX are now dependencies of Catalyst. (#2282)
Python 3.14 is now officially supported. Added the forward capability with Python 3.14. (#2271)
The RTIO dialect is added to bypass the compilation flow from OpenAPL to ARTIQ’s LLVM IR. It is introduced to bridge the gap between the ion dialect and ARTIQ’s LLVM IR. The design philosophy of the RTIO dialect is primarily event-based. Every operation is asynchronous; sync behaviour occurs only via
rtio.syncorwait operandin event operation. And we now support the compiling from the ion dialect to the RTIO dilalect. (#2185) (#2204)Integration tests for
qml.specshave been updated to match the new output format introduced in PennyLane v0.44. (#2255)Resource tracking now writes out at device destruction time instead of qubit deallocation time. The written resources will be the total amount of resources collected throughout the lifetime of the execution. For executions that split work between multiple functions (e.g., with the
split-non-commutingpass), this ensures that resource tracking outputs the total resources used for all splits. (#2219)Replaced the deprecated
shape_dtype_to_ir_typefunction with theRankedTensorType.getmethod. (#2159)Updates to PennyLane’s use of a single transform primitive with a
transformkwarg. (#2177)The pytest tests are now run with
strict=Trueby default. (#2180)Refactored Catalyst’s pass registering so that it’s no longer necessary to manually add new passes at
registerAllCatalystPasses. (#1984)Split
from_plxpr.pyinto two files. (#2142)Re-worked
DataViewto avoid an axis of size0possibly triggering a segfault via an underflow error, as discovered in this comment. (#1621)Decoupled the ION dialect from the quantum dialect to support the new RTIO compilation flow. The ion dialect now uses its own
!ion.qubittype instead of depending on!quantum.bit. Conversion between qubits of quantum and ion dialects is handled via unrealized conversion casts. (#2163)For an example, quantum qubits are converted to ion qubits as follows:
%qreg = quantum.alloc(1) : !quantum.reg %q0 = quantum.extract %qreg[0] : !quantum.reg -> !quantum.bit // Convert quantum.bit to ion.qubit %ion_qubit_0 = builtin.unrealized_conversion_cast %q0 : !quantum.bit to !ion.qubit // Use in ion dialect operations %pp = ion.parallelprotocol(%ion_qubit_0) : !ion.qubit { ^bb0(%arg1: !ion.qubit): // ... ion operations ... }
Added support for
ppr-to-ppmas an individual MLIR pass and Python binding for the qec dialect. (#2189)Added a canonicalization pattern for
qec.pprto remove any PPRs consisting only of identities. (#2192)Renamed the
annotate-functionpass toannotate-invalid-gradient-functionsand moved it to the gradient dialect and thelower-gradientscompilation stage. (#2241)Added support for PPRs and arbitrary-angle PPRs to the
merge_rotations()pass. This pass now merges PPRs with equivalent angles, and cancels PPRs with opposite angles, or angles that sum to identity when the angles are known. The pass also supports conditions on PPRs, merging when conditions are identical and not merging otherwise. (#2224) (#2245) (#2254) (#2258) (#2311)Refactored QEC tablegen files to separate QEC operations into a new
QECOp.tdfile (#2253Removed the
getRotationKindandsetRotationKindmethods from the QEC interfaceQECOpInterfaceto simplify the interface. (#2250)A new
PauliFramedialect has been added. This dialect includes a set of abstractions and operations for interacting with an external Pauli frame tracking library. (#2188)A new
to-pauli-framecompilation pass has been added, which applies the Pauli frame tracking protocols to a Clifford+T program. (#2269)Adding the measurement type into the MLIR assembly format for
qec.ppmandqec.select.ppm(#2347)Remove duplicate code for canonicalization and verification of Pauli Product Rotation operations. (#2313)
Documentation 📝
A note was made in the Sharp Bits page for the behaviour of
qml.transforms.decomposewhen graph-based decompositions are enabled withpennylane.decomposition.enable_graph(). It clarifies that non-deterministic graph solutions may lead to non-executable programs if intermediate gates are not executable by Catalyst. (#2377)Clarifications were made in the Sharp Bits page for the behaviour of
qml.allocatewhen used with Catalyst. In particular, returning any terminal measurement besidesqml.probswhenqml.allocateis used within aqjit‘d workflow is not supported. (#2317) (#2358)A typo in the code example for
ppr_to_ppm()has been corrected. (#2136)Fixed a rendering issue in
catalyst.qjitandcatalyst.CompileOptionsdocstrings. (#2156)Updated the MLIR Plugins documentation stating that plugins require adding passes via
--pass-pipeline. (#2168)Typos in the docstrings for
PPRotationArbitraryOpandPPRRotationOphave been corrected. (#2297)The
--save-ir-after-eachcommand line option documentation has been updated to explain thechangedvalue. (#2355)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Ali Asadi, Joey Carter, Yushao Chen, Isaac De Vlugt, Sengthai Heng, David Ittah, Jeffrey Kam, Christina Lee, Joseph Lee, Mehrdad Malekmohammadi, River McCubbin, Lee J. O’Riordan, Mudit Pandey, Andrija Paurevic, Roberto Turrado, Paul Haochen Wang, David Wierichs, Jake Zaia, Hongsheng Zheng.
Release 0.13.0¶
New features since last release
Catalyst now supports
qml.specs, meaning that users can use theqml.specsfunction to track the exact resources of programs compiled withqjit()! This new feature is currently only supported when usinglevel="device". (#2033) (#2055)This is made possible by leveraging resource-tracking capabilities using the
null.qubitdevice under the hood, which gathers circuit information via mock execution. This makes getting exact resources from large circuits extremely performant. For example, the circuit below has 100 qubits and its device-level resources can be calculated in around 1 minute!from functools import partial gateset = {qml.H, qml.S, qml.CNOT, qml.T, qml.RX, qml.RY, qml.RZ} @qml.qjit @partial(qml.transforms.decompose, gate_set=gateset) @qml.qnode(qml.device("null.qubit", wires=100)) def circuit(): qml.QFT(wires=range(100)) qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) qml.OutAdder(x_wires=range(10), y_wires=range(10, 20), output_wires=range(20, 31)) return qml.expval(qml.Z(0) @ qml.Z(1)) circ_specs = qml.specs(circuit, level="device")()
>>> print(circ_specs['resources']) num_wires: 100 num_gates: 138134 depth: 90142 shots: Shots(total=None) gate_types: {'CNOT': 55313, 'RZ': 82698, 'Hadamard': 123} gate_sizes: {2: 55313, 1: 82821}
Note that there are certain limitations to
specssupport. For example,whileloops might not terminate when executing on thenull.qubitdevice due to the quantum execution being mocked out.The graph-based decomposition system, enabled with the global toggle
qml.decomposition.enable_graph(), is now supported with Catalyst with PennyLane program capture enabled (qml.capture.enable()). This providesqjit()compatibility to defining custom decomposition rules and access to the many decomposition rules for templates and operators in PennyLane that have been added over the past few release cycles. (#1820) (#2099) (#2091) (#2029) (#2001) (#2115)qml.decomposition.enable_graph() qml.capture.enable() @qml.register_resources({qml.H: 2, qml.CZ: 1}) def my_cnot1(wires): qml.H(wires=wires[1]) qml.CZ(wires=wires) qml.H(wires=wires[1]) @qml.qjit @partial( qml.transforms.decompose, gate_set={"H", "CZ", "GlobalPhase"}, alt_decomps={qml.CNOT: [my_cnot1]}, ) @qml.qnode(qml.device("lightning.qubit", wires=2)) def circuit(): qml.H(0) qml.CNOT(wires=[0, 1]) return qml.state()
>>> circuit() Array([0.70710678+0.j, 0. +0.j, 0. +0.j, 0.70710678+0.j], dtype=complex128)
Similar to PennyLane’s behaviour, this feature will fall back to the old system whenever the graph cannot find decomposition rules for all unsupported operators in the program, and a
UserWarningis raised.For more information, please consult the PennyLane decomposition module.
Catalyst now supports dynamic wire allocation with
qml.allocate()andqml.deallocate()when program capture is enabled, unlockingqjit-able applications like decompositions of gates that require temporary auxiliary wires and logical patterns in subroutines that benefit from having dynamic wire management. (#2002) (#2075)Two new functions,
qml.allocate()andqml.deallocate(), have been added to PennyLane to support dynamic wire allocation. With Catalyst, these features can be accessed onlightning.qubit,lightning.kokkos, andlightning.gpu.Dynamic wire allocation refers to the allocation of wires in the middle of a circuit, as opposed to the static allocation during device initialization. For example:
qml.capture.enable() @qjit @qml.qnode(qml.device("lightning.qubit", wires=2)) # 2 initial qubits def circuit(): qml.X(0) # |10> with qml.allocate(1) as q: # |10> and |0>, 1 dynamically allocated qubit qml.X(q[0]) # |10> and |1> qml.CNOT(wires=[q[0], 1]) # |11> and |1> return qml.probs(wires=[0, 1])
>>> print(circuit()) [0. 0. 0. 1.]
In the above program, 2 qubits are allocated during device initialization, and 1 additional qubit is allocated inside the circuit with
qml.allocate(1).For more information on what
qml.allocate()andqml.deallocate()do, please consult the PennyLane v0.43 release notes.There are some notable differences between the behaviour of these features with
qjitversus without. For details, please see the relevant sections in the Catalyst sharp bits page.A new quantum compilation pass called
reduce_t_depth()has been added, which reduces the depth and count of non-Clifford Pauli product rotations (PPRs) in circuits. This compilation pass works by commuting non-Clifford PPRs (those requiring aT-state to implement) in adjacent layers and merging compatible ones. More details can be found in Figure 6 of A Game of Surface Codes. (#1975) (#2048) (#2085)The impact of the
reduce_t_depth()pass can be measured usingppm_specs()to compare the circuit depth before and after applying the pass. Consider the following circuit:import pennylane as qml from catalyst import qjit, measure pips = [("pipe", ["enforce-runtime-invariants-pipeline"])] no_reduce_T = { "to_ppr": {}, "commute_ppr": {}, "merge_ppr_ppm": {}, } reduce_T = { "to_ppr": {}, "commute_ppr": {}, "merge_ppr_ppm": {}, "reduce_t_depth": {} } for pipeline in [reduce_T, no_reduce_T]: @qjit(pipelines=pips, target="mlir", circuit_transform_pipeline=pipeline) @qml.qnode(qml.device("null.qubit", wires=3)) def circuit(): n = 3 for i in range(n): qml.H(wires=i) qml.S(wires=i) qml.CNOT(wires=[i, (i + 1) % n]) qml.T(wires=i) qml.H(wires=i) qml.T(wires=i) return [measure(wires=i) for i in range(n)] print(ppm_specs(circuit))
{'circuit_0': {'depth_pi8_ppr': 3, 'depth_ppm': 1, 'logical_qubits': 3, 'max_weight_pi8': 3, 'num_of_ppm': 3, 'pi8_ppr': 6}} {'circuit_0': {'depth_pi8_ppr': 4, 'depth_ppm': 1, 'logical_qubits': 3, 'max_weight_pi8': 3, 'num_of_ppm': 3, 'pi8_ppr': 6}}
After performing the
to_ppr(),commute_ppr(), andmerge_ppr_ppm()passes, the circuit contains a depth of four of non-Clifford PPRs (depth_pi8_ppr). Subsequently applying thereduce_t_depth()pass will move PPRs around via commutation, resulting in a circuit with a smaller PPR depth of three.Catalyst now handles more types of hybrid workflows by supporting returning classical and MCM values with the dynamic one-shot MCM method. (#2004) (#2090)
For example, the code below will generate 10 values, with an equal probability of 42 and 43 appearing.
import pennylane as qml from catalyst import qjit, measure @qjit(autograph=True) @qml.qnode(qml.device("lightning.qubit", wires=1), mcm_method="one-shot", shots=10) def circuit(): qml.Hadamard(wires=0) m = measure(0) if m: return 42, m else: return 43, m
>>> print(circuit()) (Array([42, 43, 42, 42, 43, 42, 42, 43, 42, 42], dtype=int64), Array([ True, False, True, True, False, True, True, False, True, True], dtype=bool))
The default mid-circuit measurement method in catalyst has been changed from
"single-branch-statistics"to"one-shot"when mcms are present in the program, which provides a more sensible experience overall when using finite shots. [#2017] [#2019]The main differentiator is that
"one-shot"explores all branches of the decision tree when probabilistic elements are present in the program, such as mid-circuit measurements, device noise, or other sources of randomness. The cost is that simulation / device execution is repeatedshotsnumber of times.Catalyst now provides native support for
qml.SingleExcitation,qml.DoubleExcitation, andqml.PCPhaseon compatible devices (e.g., Lightning simulators). This enhancement avoids unnecessary gate decomposition, leading to reduced compilation time and improved overall performance. (#1980) (#1987)
Improvements 🛠
Adjoint differentiation is used by default when executing on lightning devices, which significantly reduces gradient computation time. (#1961)
The
ppm_specs()function now tracks the non-Clifford and Clifford PPR depth and the overall PPM depth. (#2014)For example:
from catalyst import qjit, measure from catalyst.passes import to_ppr, commute_ppr, reduce_t_depth, merge_ppr_ppm pips = [("pipe", ["enforce-runtime-invariants-pipeline"])] circuit_transforms = { "to_ppr": {}, "commute_ppr": {}, "merge_ppr_ppm": {}, } @qjit(pipelines=pips, target="mlir", circuit_transform_pipeline=circuit_transforms) @qml.qnode(qml.device("null.qubit", wires=3)) def circuit(): n = 3 for i in range(n): qml.H(wires=i) qml.S(wires=i) qml.CNOT(wires=[i, (i + 1) % n]) qml.T(wires=i) qml.H(wires=i) qml.T(wires=i) return [measure(wires=i) for i in range(n)]
>>> print(ppm_specs(circuit)) {'circuit_0': {'depth_pi8_ppr': 3, 'depth_ppm': 1, 'logical_qubits': 3, 'max_weight_pi8': 3, 'num_of_ppm': 3, 'pi8_ppr': 6}}
pennylane.QubitUnitaryis no longer favoured in the decomposition of controlled operators when the operator is not natively supported by the device, but the device supportspennylane.QubitUnitary. Instead, conversion topennylane.QubitUnitaryonly happens if the operator does not define another decomposition. The previous behaviour was the cause of performance issues when dealing with large controlled operators, as their matrix representation could be embedded as dense constant data into the program. The performance difference can span multiple orders of magnitude. (#2100)Conditional operators, such as
cond()orpennylane.cond(), now allow the target and branch functions to use arguments in their call signature. Previously, one had to supply all values via closure, but this is now done automatically under the hood. (#2096)Improvements have been made to the
catalyst.from_plxpr.from_plxprfeature set. (#1844) (#1850) (#1903) (#1896) (#1889) (#1973) (#1983) (#2041)It now supports:
qml.adjointandqml.ctrloperations and transforms,operator arithmetic observables and
qml.Hermitianobservables,qml.for_loop,qml.condandqml.while_loopoutside of QNodes,qml.condwithelifbranches,dynamic-value shots and dynamically-settable shots,
and the
qml.countsmeasurement process.
Parallelization is now considered in the IR. As part of that, Catalyst can represent parallel layers, compute depth, and optimize depth.
Two change were made as part of this overall improvement to the IR:
A new pass, accessible with
--partition-layersin the Catalyst CLI, has been added to group PPR and PPM operations intoqec.layeroperations based on qubit interactivity and commutativity, enabling circuit analysis and potential support for parallel execution. (#1951)The
qec.layerandqec.yieldoperations have been added to the QEC dialect to represent a group of QEC operations. The main use case is to analyze the depth of a circuit. Also, this is a preliminary step towards supporting parallel execution of QEC layers. (#1917)
Utility functions for modifying an existing compilation pipeline have been added to the
pipelinesmodule. (#1941)These functions provide a simple interface to insert passes and stages into a compilation pipeline. The available functions are
insert_pass_after,insert_pass_before,insert_stage_after, andinsert_stage_before. For example,>>> from catalyst.pipelines import insert_pass_after >>> pipeline = ["pass1", "pass2"] >>> insert_pass_after(pipeline, "new_pass", ref_pass="pass1") >>> pipeline ['pass1', 'new_pass', 'pass2']
A new pass called
detensorize-function-boundaryhas been added, which removes scalar tensors across function boundaries and enables thesymbol-dcepass to remove dead functions, reducing the number of instructions for compilation and thus improving performance. (#1904)The error message for unsupported mid-circuit measurements in measurement processes when using
mcm_method="single-branch-statistics"has been improved. (#2105)Catalyst’s native control flow functions (
for_loop(),while_loop()andcond()) now raise an error if used with PennyLane program capture (i.e.,qml.capture.enable()is present). (#1945)The Catalyst CLI now prints the Catalyst version when invoked with
catalyst --versionorquantum-opt --version. (#1922)A runtime error is now raised when the qubits provided to a quantum gate are not distinct (i.e. overlap). (#2006).
The Pauli product optimization pass that commutes Clifford rotations (\(\frac{\pi}{4}\)) past non-Clifford rotations (\(\frac{\pi}{8}\)) now also supports \(\frac{\pi}{2}\) angles. (#1966)
The default value for the
decompose_methodparameter in theppr_to_ppm()compilation pass is now"pauli-corrected", an improved decomposition of non-Clifford PPRs into two PPMs, instead of two PPMs, and a Clifford correction. This decomposition is based on Figure 13(a) in arXiv:2211.15465. (#2043) (#2047)In the Pauli-based compilation pipeline, identity operations (
qml.Identity) are now accepted in the input program converted to a corresponding PPR gate. Additionally, internal validation was improved across PPR/PPM passes. (#2058)Using the
keep_intermediate='pass'option now prints the whole module scope of a program to the intermediate files instead of just the pass scope. (#2051)
Breaking changes 💔
The
get_ppm_specsfunction has been renamed toppm_specs(). (#2031)The
shotsproperty has been removed fromOQDDevice. The number of shots for a QNode execution is now set directly on the QNode viaqml.qnode(..., shots=N), or via the decoratorqml.set_shots. (#1988)The JAX version used by Catalyst has been updated to 0.6.2. (#1897)
(Device implementers only) The
ReleaseAllQubitsdevice interface function has been replaced withReleaseQubits. (#1996)Instead of releasing all currently active qubits, the new interface function
ReleaseQubitsexplicitly takes in an array of qubit IDs to be released.For devices without dynamic allocation support it is expected that this function only succeed if the ID array contains the same values as those produced by the initial
AllocateQubitscall, otherwise the device is encouraged to raise an error.(Compiler integrators only) The version of LLVM and Enzyme used by Catalyst has been updated and the
mlir-hlodependency has been replaced withstablehlo. (#1916) (#1921)The LLVM version has been updated to commit f8cb798.
The stablehlo version has been updated to commit 69d6dae.
The Enzyme version has been updated to v0.0.186.
Deprecations 👋
Usage of the
Device.shotsproperty, along with settingdevice(..., shots=...), has been deprecated. Please set the shots at the QNode level withqml.qnode(..., shots=...)or using the decoratorqml.set_shots. (#1952)
Bug fixes 🐛
Fixed an issue with PennyLane program capture and static argnums on the QNode where the same lowering was being used no matter if the static arguments changed. The lowering to MLIR is no longer cached if there are static argnums. (#2053)
Fixed a bug where applying a quantum transform after a QNode could produce incorrect results or errors in certain cases. This resolves issues related to transforms operating on QNodes with classical outputs and improves compatibility with measurement transforms. (#2081)
Fixed a bug with incorrect type promotion on conditional branches, which was giving inconsistent output types from qjit’d QNodes. (#1977)
Snake case keyword arguments supplied to
apply_pass()are now correctly converted to the kebab case used for pass options in MLIR. (#1954).For example:
@qjit(target="mlir") @catalyst.passes.apply_pass("some-pass", "an-option", maxValue=1, multi_word_option=1) @qml.qnode(qml.device("null.qubit", wires=1)) def example(): return qml.state()
The pass application instruction will look like the following in MLIR:
%0 = transform.apply_registered_pass "some-pass" with options = {"an-option" = true, "maxValue" = 1 : i64, "multi-word-option" = 1 : i64}Fixed incorrect handling of partitioned shots in the decomposition pass of
measurements_from_samples. (#1981)Fixed a compiler error that occurred when
qml.prodwas used together with other operator transforms (e.g.,qml.adjoint) when Autograph was enabled. (#1910) (#2083)A bug in the
NullQubit::ReleaseQubit()method that prevented the deallocation of individual qubits on the"null.qubit"device has been fixed. (#1926)Stacked Python decorators for built-in Catalyst passes are now applied in the correct order when PennyLane program capture is enabled. (#2027)
Various issues in the OQC device plugin have been fixed:
Fixed a mistake in the gate sequence generated by the
ppr_to_ppmcompilation pass whendecompose_method="auto-corrected"is used. (#2043)static_argnumsis now correctly propagated when tracing the target functions of certain transformations and decorators, like the one used in the dynamic-one-shot mcm method. (#2056)Fixed a bug where deallocating the auxiliary qubit in
ppr_to_ppmwithdecompose_method="clifford-corrected"was deallocating the wrong auxiliary qubit. (#2039)
Internal changes ⚙️
The NullQubit device now provides the resource-tracking filename to allow for cleanup. (#1861)
The type of the
number_original_argattribute inCustomCallOphas been changed from a dense array to an integer. (#2022)QregManagerhas been renamed toQubitHandlerand has been extended to manage converting PLxPR wire indices into Catalyst JAXPR qubits. This is especially useful for lowering subroutines that take in qubits as arguments, like in decomposition rules. (#1820)The error message for using a quantum subroutine that was defined outside of a QNode scope has been improved. (#1932)
The usage of
qml.transforms.dynamic_one_shot.parse_native_mid_circuit_measurementsin Catalyst’sdynamic_one_shotimplementation was updated to use its new call signature. (#1953)When capture is enabled with
qml.capture.enable(),@qml.qjit(autograph=True)will use PennyLane’s autograph implementation instead of Catalyst’s. (#1960)The
extract_backend_infohelper function for theQJITDeviceno longer has a redundantcapabilitiesargument. (#1956)A warning is now raised when subroutines are used without PennyLane program capture enabled (
qml.capture.enable()). (#1930)Import paths for noise transforms have been updated from
pennylane.transformstopennylane.noise. (#1918) (#2020)Conversion patterns for the single-qubit
quantum.alloc_qbandquantum.dealloc_qboperations have been added for lowering to the LLVM dialect. These conversion patterns allow for execution of programs containing these operations. (#1920)The default compilation pipeline is now available as
catalyst.pipelines.default_pipeline(). The functioncatalyst.pipelines.get_stages()has also been removed, as it was not used and duplicated theCompileOptions.get_stages()method. (#1941)A new built-in compilation pipeline for experimental MBQC workloads called
catalyst.ftqc.mbqc_pipeline()has been added. (#1942)The output of this function can be used directly as input to the
pipelinesargument ofqjit(). For example:from catalyst.ftqc import mbqc_pipeline @qjit(pipelines=mbqc_pipeline()) @qml.qnode(dev) def workload(): ...
The
mbqc.graph_state_prepoperation has been added to the MBQC dialect. This operation prepares a graph state with arbitrary qubit connectivity, specified by an input adjacency-matrix operand, for use in MBQC workloads. (#1965)catalyst.accelerate,catalyst.debug.callback, andcatalyst.pure_callback,catalyst.debug.print, andcatalyst.debug.print_memrefnow work when PennyLane program capture is enabled withqml.capture.enable(). (#1902)The merge rotation pass in Catalyst (
merge_rotations()) now also considersqml.Rotandqml.CRot. (#1955)Catalyst now supports array-backed registers, meaning that
quantum.insertoperations can be configured to allow for the insertion of a qubit into an arbitrary position within a register. (#2000)This feature is disabled by default. To enable it, configure the pass pipeline to set the
use-array-backed-registersoption of theconvert-quantum-to-llvmpass totrue. For example:catalyst --tool=opt --pass-pipeline="builtin.module(convert-quantum-to-llvm{use-array-backed-registers=true})" <input file>The
NoMemoryEffecttrait has been removed from thequantum.allocoperation, which allowed for supporting the dynamic wire allocation feature. (#2044)Validation in the
ppm_specsfunction has been improved to prevent duplicate unnecessary duplication in the pipeline configuration. (#2049)A new compilation pass called
ppr_to_mbqc()has been added to lowerqec.pprandqec.ppminstructions into MBQC-style instructions. (#2057)This pass is part of a bottom-of-stack MBQC execution pathway, with a small separation between the PPR/PPM and MBQC layers to enable end-to-end compilation on a mocked backend.
import pennylane as qml from catalyst import qjit, measure from catalyst.passes import ppr_to_mbqc, to_ppr pipeline = [("pipe", ["enforce-runtime-invariants-pipeline"])] @qjit(target="mlir", pipelines=pipeline) @ppr_to_mbqc @to_ppr @qml.qnode(qml.device("lightning.qubit", wires=2)) def circuit(): qml.CNOT(wires=[0, 1]) qml.T(0) return measure(0) print(circuit.mlir_opt)
... %out_qubits = quantum.custom "Hadamard"() %2 : !quantum.bit %out_qubits_2:2 = quantum.custom "CNOT"() %out_qubits, %1 : !quantum.bit, !quantum.bit %out_qubits_3 = quantum.custom "RZ"(%cst_1) %out_qubits_2#1 : !quantum.bit %out_qubits_4:2 = quantum.custom "CNOT"() %out_qubits_2#0, %out_qubits_3 : !quantum.bit, !quantum.bit %out_qubits_5 = quantum.custom "Hadamard"() %out_qubits_4#0 : !quantum.bit %out_qubits_6 = quantum.custom "RZ"(%cst_0) %out_qubits_4#1 : !quantum.bit %out_qubits_7 = quantum.custom "Hadamard"() %out_qubits_5 : !quantum.bit %out_qubits_8 = quantum.custom "RZ"(%cst_0) %out_qubits_7 : !quantum.bit %out_qubits_9 = quantum.custom "Hadamard"() %out_qubits_8 : !quantum.bit %out_qubits_10 = quantum.custom "RZ"(%cst) %out_qubits_6 : !quantum.bit %mres, %out_qubit = quantum.measure %out_qubits_10 : i1, !quantum.bit ...
Note that in an MBQC gate set, the
RotXZXgate cannot yet be executed on available backends.A new jax primitive
qdealloc_qb_pis available for single qubit deallocations, which may be useful for the development of new features. (#2005)
Documentation 📝
Typos were fixed and supplemental information was added to the docstrings for
ppm_compilaion,to_ppr,commute_ppr,ppr_to_ppm,merge_ppr_ppm, andppm_specs. (#2050)The Catalyst Command Line Interface documentation incorrectly stated that the
catalystexecutable is available in thecatalyst/bin/directory relative to the environment’s installation directory when installed viapip. The documentation has been updated to point to the correct location, which is thebin/directory relative to the environment’s installation directory. (#2030)A handful of typos were fixed in the sharp bits page and transforms API. (#2046)
Links to demos were updated and corrected to point to relevant, up-to-date demos. (#2042)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Ali Asadi, Joey Carter, Yushao Chen, Isaac De Vlugt, Sengthai Heng, David Ittah, Jeffrey Kam, Christina Lee, Joseph Lee, Andrija Paurevic, Justin Pickering, Ritu Thombre, Roberto Turrado, Paul Haochen Wang, Jake Zaia, Hongsheng Zheng.
Release 0.12.0¶
New features since last release
A new compilation pass called
ppm_compilation()has been added to Catalyst to transform Clifford+T gates into Pauli Product Measurements (PPMs) using just one transform, allowing for exploring representations of programs in a new paradigm in logical quantum compilation. (#1750)Based on arXiv:1808.02892, this new compilation pass simplifies circuit transformations and optimizations by combining multiple sub-passes into a single compilation pass, where Clifford+T gates are compiled down to Pauli product rotations (PPRs, \(\exp(-iP_{\{x, y, z\}} \theta)\)) and PPMs:
to_ppr(): converts Clifford+T gates into PPRs.commute_ppr(): commutes PPRs past non-Clifford PPRs.merge_ppr_ppm(): merges Clifford PPRs into PPMs.ppr_to_ppm(): decomposes both non-Clifford PPRs (\(\theta = \tfrac{\pi}{8}\)), consuming a magic state in the process, and Clifford PPRs (\(\theta = \tfrac{\pi}{4}\)) into PPMs. (#1664)
import pennylane as qml from catalyst.passes import ppm_compilation pipeline = [("pipe", ["enforce-runtime-invariants-pipeline"])] @qml.qjit(pipelines=pipeline, target="mlir") @ppm_compilation(decompose_method="clifford-corrected", avoid_y_measure=True, max_pauli_size=2) @qml.qnode(qml.device("null.qubit", wires=2)) def circuit(): qml.CNOT([0, 1]) qml.CNOT([1, 0]) qml.adjoint(qml.T)(0) qml.T(1) return catalyst.measure(0), catalyst.measure(1)
>>> print(circuit.mlir_opt) ... %m, %out:3 = qec.ppm ["Z", "Z", "Z"] %1, %2, %4 : !quantum.bit, !quantum.bit, !quantum.bit %m_0, %out_1:2 = qec.ppm ["Z", "Y"] %3, %out#2 : !quantum.bit, !quantum.bit %m_2, %out_3 = qec.ppm ["X"] %out_1#1 : !quantum.bit %m_4, %out_5 = qec.select.ppm(%m, ["X"], ["Z"]) %out_1#0 : !quantum.bit %5 = arith.xori %m_0, %m_2 : i1 %6:2 = qec.ppr ["Z", "Z"](2) %out#0, %out#1 cond(%5) : !quantum.bit, !quantum.bit quantum.dealloc_qb %out_5 : !quantum.bit quantum.dealloc_qb %out_3 : !quantum.bit %7 = quantum.alloc_qb : !quantum.bit %8 = qec.fabricate magic_conj : !quantum.bit %m_6, %out_7:2 = qec.ppm ["Z", "Z"] %6#1, %8 : !quantum.bit, !quantum.bit %m_8, %out_9:2 = qec.ppm ["Z", "Y"] %7, %out_7#1 : !quantum.bit, !quantum.bit %m_10, %out_11 = qec.ppm ["X"] %out_9#1 : !quantum.bit %m_12, %out_13 = qec.select.ppm(%m_6, ["X"], ["Z"]) %out_9#0 : !quantum.bit %9 = arith.xori %m_8, %m_10 : i1 %10 = qec.ppr ["Z"](2) %out_7#0 cond(%9) : !quantum.bit quantum.dealloc_qb %out_13 : !quantum.bit quantum.dealloc_qb %out_11 : !quantum.bit %m_14, %out_15:2 = qec.ppm ["Z", "Z"] %6#0, %10 : !quantum.bit, !quantum.bit %from_elements = tensor.from_elements %m_14 : tensor<i1> %m_16, %out_17 = qec.ppm ["Z"] %out_15#1 : !quantum.bit ...
A new function called
get_ppm_specs()has been added for acquiring statistics after PPM compilation. (#1794)After compiling a workflow with any combination of
to_ppr(),commute_ppr(),merge_ppr_ppm(),ppr_to_ppm(), orppm_compilation(), useget_ppm_specs()to track useful statistics of the compiled workflow, including:num_pi4_gates: number of Clifford PPRsnum_pi8_gates: number of non-Clifford PPRsnum_pi2_gates: number of classical PPRsmax_weight_pi4: maximum weight of Clifford PPRsmax_weight_pi8: maximum weight of non-Clifford PPRsmax_weight_pi2: maximum weight of classical PPRsnum_logical_qubits: number of logical qubitsnum_of_ppm: number of PPMs
from catalyst.passes import get_ppm_specs, to_ppr, merge_ppr_ppm, commute_ppr pipe = [("pipe", ["enforce-runtime-invariants-pipeline"])] @qjit(pipelines=pipe, target="mlir", autograph=True) def test_convert_clifford_to_ppr_workflow(): device = qml.device("lightning.qubit", wires=2) @merge_ppr_ppm @commute_ppr(max_pauli_size=2) @to_ppr @qml.qnode(device) def f(): qml.CNOT([0, 2]) qml.T(0) return measure(0), measure(1) @merge_ppr_ppm(max_pauli_size=1) @commute_ppr @to_ppr @qml.qnode(device) def g(): qml.CNOT([0, 2]) qml.T(0) qml.T(1) qml.CNOT([0, 1]) for i in range(10): qml.Hadamard(0) return measure(0), measure(1) return f(), g()
>>> ppm_specs = get_ppm_specs(test_convert_clifford_to_ppr_workflow) >>> print(ppm_specs) { 'f_0': {'max_weight_pi8': 1, 'num_logical_qubits': 2, 'num_of_ppm': 2, 'num_pi8_gates': 1}, 'g_0': {'max_weight_pi4': 2, 'max_weight_pi8': 1, 'num_logical_qubits': 2, 'num_of_ppm': 2, 'num_pi4_gates': 36, 'num_pi8_gates': 2} }
Catalyst now supports
qml.Snapshot, which captures quantum states at any point in a circuit. (#1741)For example, the code below is capturing two snapshot’d states, all within a qjit’d circuit:
NUM_QUBITS = 2 dev = qml.device("lightning.qubit", wires=NUM_QUBITS) @qjit @qml.qnode(dev) def circuit(): wires = list(range(NUM_QUBITS)) qml.Snapshot("Initial state") for wire in wires: qml.Hadamard(wires=wire) qml.Snapshot("After applying Hadamard gates") return qml.probs() results = circuit() snapshots, *results = circuit() >>> print(snapshots) [Array([1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=complex128), Array([0.5+0.j, 0.5+0.j, 0.5+0.j, 0.5+0.j], dtype=complex128)] >>> print(results) Array([0.25, 0.25, 0.25, 0.25], dtype=float64)
>>> print(results) ([Array([1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=complex128), Array([0.5+0.j, 0.5+0.j, 0.5+0.j, 0.5+0.j], dtype=complex128)], Array([0.25, 0.25, 0.25, 0.25], dtype=float64))
Catalyst now supports automatic qubit management, meaning that the number of wires does not need to be specified during device initialization. (#1788)
@qjit def workflow(): dev = qml.device("lightning.qubit") # no wires here! @qml.qnode(dev) def circuit(): qml.PauliX(wires=2) return qml.probs() return circuit() print(workflow())
[0. 1. 0. 0. 0. 0. 0. 0.]While this feature adds a lot of convenience, it may also reduce performance on devices where reallocating resources can be expensive, such as statevector simulators.
Two new peephole-optimization compilation passes called
disentangle_cnot()anddisentangle_swap()have been added. Each compilation pass replacesSWAPorCNOTinstructions with other equivalent elementary gates. (#1823)As an example,
disentangle_cnot()applied to the circuit below will replace theCNOTgate with anXgate.dev = qml.device("lightning.qubit", wires=2) @qml.qjit(keep_intermediate=True) @catalyst.passes.disentangle_cnot @qml.qnode(dev) def circuit(): # first qubit in |1> qml.X(0) # second qubit in |0> # current state : |10> qml.CNOT([0,1]) # state after CNOT : |11> return qml.state()
>>> from catalyst.debug import get_compilation_stage >>> print(get_compilation_stage(circuit, stage="QuantumCompilationPass")) ... %out_qubits = quantum.custom "PauliX"() %1 : !quantum.bit %2 = quantum.extract %0[ 1] : !quantum.reg -> !quantum.bit %out_qubits_0 = quantum.custom "PauliX"() %2 : !quantum.bit ...
Improvements 🛠
The
qml.measureoperation for mid-circuit measurements can now be used in qjit-compiled circuits with program capture enabled. (#1766)Note that the simulation behaviour of mid-circuit measurements can differ between PennyLane and Catalyst, depending on the chosen
mcm_method. Please see the Functionality differences from PennyLane section in the sharp bits and debugging tips page for additional information.The behaviour of measurement processes executed on
null.qubitwith qjit is now more consistent with their behaviour onnull.qubitwithout qjit. (#1598)Previously, measurement processes like
qml.sample,qml.counts,qml.probs, etc., returned values from uninitialized memory when executed onnull.qubitwith qjit. This change ensures that measurement processes onnull.qubitalways return the value 0 or the result corresponding to the ‘0’ state, depending on the context.The package name of the Catalyst distribution has been updated to be consistent with PyPA standards, from
PennyLane-Catalysttopennylane_catalyst. This change is not expected to affect users as tools in the Python ecosystem (e.g.pip) already handle both versions through normalization. (#1817)The
commute_ppr()andmerge_ppr_ppm()passes now accept an optionalmax_pauli_sizeargument, which limits the size of the Pauli strings generated by the passes through commutation or absorption rules. (#1719)The
to_ppr()pass is now more efficient by adding support for the direct conversion of Pauli gates (qml.X,qml.Y,qml.Z), the adjoint ofqml.Sgate, and the adjoint of theqml.Tgate. (#1738)The
keep_intermediateargument in theqjitdecorator now accepts a new value that allows for saving intermediate files after each pass. The updated possible options for this argument are:Falseor0orNone: No intermediate files are kept.Trueor1or"pipeline": Intermediate files are saved after each pipeline.2or"pass": Intermediate files are saved after each pass.
The default value is
False. (#1791)The
static_argnumskeyword argument in theqjitdecorator is now compatible with PennyLane program capture enabled (qml.capture.enable). (#1810)Catalyst is compatible with the new
qml.set_shotstransform introduced in PennyLane v0.42. (#1784)null.qubitcan now support an optionaltrack_resourceskeyword argument, which allows it to record which gates are executed. (#1619)import json import glob dev = qml.device("null.qubit", wires=2, track_resources=True) @qml.qjit @qml.qnode(dev) def circuit(): for _ in range(5): qml.H(0) qml.CNOT([0, 1]) return qml.probs() circuit() pattern = "./__pennylane_resources_data_*" filepath = glob.glob(pattern)[0] with open(filepath) as f: resources = json.loads(f.read())
>>> print(resources) {'num_qubits': 2, 'num_gates': 6, 'gate_types': {'CNOT': 1, 'Hadamard': 5}}
Breaking changes 💔
Support for Mac x86 has been removed. This includes Macs running on Intel processors. (#1716)
This is because JAX has also dropped support for it since 0.5.0, with the rationale being that such machines are becoming increasingly scarce.
If support for Mac x86 platforms is still desired, please install Catalyst v0.11.0, PennyLane v0.41.0, PennyLane-Lightning v0.41.0, and JAX v0.4.28.
(Device Developers Only) The
QuantumDeviceinterface in the Catalyst Runtime plugin system has been modified, which requires recompiling plugins for binary compatibility. (#1680)As announced in the 0.10.0 release, the
shotsargument has been removed from theSampleandCountsmethods in the interface, since it unnecessarily duplicated this information. Additionally,shotswill no longer be supplied by Catalyst through thekwargsparameter of the device constructor. The shot value must now be obtained through theSetDeviceShotsmethod.Further, the documentation for the interface has been overhauled and now describes the expected behaviour of each method in detail. A quality of life improvement is that optional methods are now clearly marked as such and also come with a default implementation in the base class, so device plugins need only override the methods they wish to support.
Finally, the
PrintStateand theOne/Zeroutility functions have been removed, since they did not serve a convincing purpose.(Frontend Developers Only) Some Catalyst primitives for JAX have been renamed, and the qubit deallocation primitive has been split into deallocation and a separate device release primitive. (#1720)
qunitary_pis nowunitary_p(unchanged)qmeasure_pis nowmeasure_p(unchanged)qdevice_pis nowdevice_init_p(unchanged)qdealloc_pno longer releases the device, thus it can be used at any point of a quantum execution scopedevice_release_pis a new primitive that must be used to mark the end of a quantum execution scope, which will release the quantum device
Catalyst has removed the
experimental_capturekeyword from theqjitdecorator in favour of unified behaviour with PennyLane. (#1657)Instead of enabling program capture with Catalyst via
qjit(experimental_capture=True), program capture can be enabled via the global toggleqml.capture.enable():import pennylane as qml from catalyst import qjit dev = qml.device("lightning.qubit", wires=2) qml.capture.enable() @qjit @qml.qnode(dev) def circuit(x): qml.Hadamard(0) qml.CNOT([0, 1]) return qml.expval(qml.Z(0)) circuit(0.1)
Disabling program capture can be done with
qml.capture.disable().The
ppr_to_ppmpass functionality has been moved to a new pass calledmerge_ppr_ppm. Theppr_to_ppmfunctionality now handles direct decomposition of PPRs into PPMs. (#1688)The version of JAX used by Catalyst has been updated to v0.6.0. (#1652) (#1729)
Several internal changes were made for this update.
LAPACK kernels are updated to adhere to the new JAX lowering rules for external functions. (#1685)
The trace stack is removed and replaced with a tracing context manager. (#1662)
A new
debug_infoargument is added toJaxpr, themake_jaxprfunctions, andjax.extend.linear_util.wrap_init. (#1670) (#1671) (#1681)
The version of LLVM, mlir-hlo, and Enzyme used by Catalyst has been updated to track those in JAX v0.6.0. (#1752)
The LLVM version has been updated to commit a8513158. The mlir-hlo version has been updated to commit e30c22d1. The Enzyme version has been updated to v0.0.180.
(Device developers only) Device parameters which are forwarded by the Catalyst runtime to plugin devices as a string may not contain nested dictionaries. Previously, these would be parsed incorrectly, and instead will now raise an error. (#1843) (#1846)
Deprecations 👋
Python 3.10 is now deprecated and will not be supported in Catalyst v0.13. Please upgrade to a newer Python version.
Bug fixes 🐛
Fixed Boolean arguments/results not working with the debugging functions
debug.get_cmainanddebug.compile_executable. (#1687)Fixed AutoGraph fallback for valid iteration targets with constant data but no length, for example
itertools.product(range(2), repeat=2). (#1665)Catalyst now correctly supports
qml.StatePrep()andqml.BasisState()operations in the experimental PennyLane program capture pipeline. (#1631)make allnow correctly compiles the standalone plugin with the same compiler used to compile LLVM and MLIR. (#1768)Stacked Python decorators for built-in Catalyst passes are now applied in the correct order. (#1798)
MLIR plugins can now be specified via lists and tuples, not just sets. (#1812)
Fixed the conversion of PLxPR to JAXPR with quantum primitives when using control flow. (#1809)
Fixed a bug in the internal simplification of qubit chains in the compiler, which manifested in certain transformations like
cancel_inversesand led to incorrect results. (#1840)Fixes the conversion of PLxPR to JAXPR with quantum primitives when using dynamic wires. (#1842)
Internal changes ⚙️
The clang-format and clang-tidy versions used by Catalyst have been updated to v20. (#1721)
The Sphinx version has been updated to v8.1. (#1734)
Integration with PennyLane’s experimental Python compiler based on xDSL has been added. This allows developers and users to write xDSL transformations that can be used with Catalyst. (#1715)
An xDSL MLIR plugin has been added to denote whether to use xDSL to execute compilation passes. (#1707)
The function
dataclass.replaceis now used to updateExecutionConfigandMCMConfigrather than mutating properties. (#1814)A function has been added that allows developers to register an equivalent MLIR transform for a given PLxPR transform. (#1705)
Overriding the
num_wiresproperty ofHybridOpis no longer happening when the operator can exist onAnyWires. This allows the deprecation ofWiresEnumin PennyLane. (#1667) (#1676)Catalyst now includes an experimental
mbqcdialect for representing measurement-based quantum-computing protocols in MLIR. (#1663) (#1679)The Catalyst Runtime C-API now includes a stub for the experimental
mbqc.measure_in_basisoperation,__catalyst__mbqc__measure_in_basis(), allowing for mock execution of MBQC workloads containing parameterized arbitrary-basis measurements. (#1674)This runtime stub is currently for mock execution only and should be treated as a placeholder operation. Internally, it functions just as a computational-basis measurement instruction.
Support for quantum subroutines was added. This feature is expected to improve compilation times for large quantum programs. (#1774) (#1828)
PennyLane’s arbitrary-basis measurement operations, such as
qml.ftqc.measure_arbitrary_basis, are now qjit-compatible with PennyLane program capture enabled. (#1645) (#1710)The utility function
EnsureFunctionDeclarationhas been refactored into theUtilsof the Catalyst dialect instead of being duplicated in each individual dialect. (#1683)The assembly format for some MLIR operations now includes
adjoint. (#1695)Improved the definition of
YieldOpin the quantum dialect by removingAnyTypeOf. (#1696)The assembly format of
MeasureOpin theQuantumdialect andMeasureInBasisOpin theMBQCdialect now contains thepostselectattribute. (#1732)The bufferization of custom Catalyst dialects has been migrated to the new one-shot bufferization interface in MLIR. The new MLIR bufferization interface is required by JAX v0.4.29 or higher. (#1027) (#1686) (#1708) (#1740) (#1751) (#1769)
The redundant
OptionalAttrhas been removed from theadjointargument in theQuantumOps.tdTableGen file. (#1746)ValueRangehas been replaced withTypeRangefor creatingCustomOpinIonsDecompositionPatterns.cppto match the build constructors. (#1749)The unused helper function
genArgMapFunctionin the--lower-gradientspass has been removed. (#1753)Base components of
QFuncPLxPRInterpreterhave been moved into a base class calledSubroutineInterpreter. This is intended to reduce code duplication. (#1787)An argument (
openapl_file_name) has been added to theOQDDeviceconstructor to specify the name of the output OpenAPL file. (#1763)The OQD device TOML file has been modified to only include gates that are decomposable to the OQD device target gate set. (#1763)
The
quantum-to-ionpass has been renamed togates-to-pulses. (#1818)The runtime CAPI function
__catalyst__rt__num_qubitsnow has a corresponding JAX primitivenum_qubits_pand quantum dialect operationNumQubitsOp. (#1793)For measurements whose shapes depend on the number of qubits, they now properly retrieve the number of qubits through this new operation when it is dynamic.
The PPR/PPM pass names have been renamed from snake-case to kebab-case in MLIR to align with MLIR conventions. Class names and tests were updated accordingly. Example:
--to_ppris now--to-ppr. (#1802)A new internal python module called
catalyst.from_plxprhas been created to better organize the code for plxpr integration. (#1813)A new
from_plxpr.QregManagerhas been created to handle converting plxpr wire index semantics into catalyst qubit value semantics. (#1813)
Documentation 📝
The header (logo+title) images in the README and in the overview on ReadTheDocs have been updated, reflecting that Catalyst is now beyond beta 🎉! (#1718)
The API section in the documentation has been simplified. The Catalyst ‘Runtime Device Interface’ page has been updated to point directly to the documented
QuantumDevicestruct, and the ‘QIR C-API’ page has been removed due to limited utility. (#1739)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Runor Agbaire, Joey Carter, Isaac De Vlugt, Sengthai Heng, David Ittah, Tzung-Han Juang, Christina Lee, Mehrdad Malekmohammadi, Anton Naim Ibrahim, Erick Ochoa Lopez, Ritu Thombre, Raul Torres, Paul Haochen Wang, Jake Zaia.
Release 0.11.0¶
New features since last release
A novel optimization technique is implemented in Catalyst that performs quantum peephole optimizations across loop boundaries. The technique has been added to the existing optimizations
cancel_inversesandmerge_rotationsto increase their effectiveness in structured programs. (#1476)A frequently occurring pattern is operations at the beginning and end of a loop that cancel each other out. With loop boundary analysis, the
cancel_inversesoptimization can eliminate these redundant operations and thus reduce quantum circuit depth.For example,
dev = qml.device("lightning.qubit", wires=2) @qml.qjit @catalyst.passes.cancel_inverses @qml.qnode(dev) def circuit(): for i in range(3): qml.Hadamard(0) qml.CNOT([0, 1]) qml.Hadamard(0) return qml.expval(qml.Z(0))
Here, the Hadamard gate pairs which are consecutive across two iterations are eliminated, leaving behind only two unpaired Hadamard gates, from the first and last iteration, without unrolling the for loop. For more details on loop-boundary optimization, see the PennyLane Compilation entry.
A new intermediate representation and compilation framework has been added to Catalyst to describe and manipulate programs in the Pauli product measurement (PPM) representation. As part of this framework, three new passes are now available to convert Clifford + T gates to Pauli product measurements as described in arXiv:1808.02892. (#1499) (#1551) (#1563) (#1564) (#1577)
Note that programs in the PPM representation cannot yet be executed on available backends. The passes currently exist for analysis, but PPM programs may become executable in the future when a suitable backend is available.
The following new compilation passes can be accessed from the
passesmodule or inpipeline():catalyst.passes.to_ppr: Clifford + T gates are converted into Pauli product rotations (PPRs) (\(\exp{iP \theta}\), where \(P\) is a tensor product of Pauli operators):Hgate → 3 rotations with \(P_1 = Z, P_2 = X, P_3 = Z\) and \(\theta = \tfrac{\pi}{4}\)Sgate → 1 rotation with \(P = Z\) and \(\theta = \tfrac{\pi}{4}\)Tgate → 1 rotation with \(P = Z\) and \(\theta = \tfrac{\pi}{8}\)CNOTgate → 3 rotations with \(P_1 = (Z \otimes X), P_2 = (-Z \otimes \mathbb{1}), P_3 = (-\mathbb{1} \otimes X)\) and \(\theta = \tfrac{\pi}{4}\)
catalyst.passes.commute_ppr: Commute Clifford PPR operations (PPRs with \(\theta = \tfrac{\pi}{4}\)) to the end of the circuit, past non-Clifford PPRs (PPRs with \(\theta = \tfrac{\pi}{8}\))catalyst.passes.ppr_to_ppm: Absorb Clifford PPRs into terminal Pauli product measurements (PPMs).
For more information on PPMs, please refer to our Pauli-based computation documentation page.
Catalyst now supports qubit number-invariant compilation. That is, programs can be compiled without specifying the number of qubits to allocate ahead of time. Instead, the device can be supplied with a dynamic program variable as the number of wires. (#1549) (#1553) (#1565) (#1574)
For example, the following toy workflow is now supported, where the number of qubits,
n, is provided as an argument to a qjit’d function:import catalyst import pennylane as qml @catalyst.qjit(autograph=True) def f(n): device = qml.device("lightning.qubit", wires=n, shots=10) @qml.qnode(device) def circuit(): for i in range(n): qml.RX(1.5, wires=i) return qml.counts() return circuit()
>>> f(3) (Array([0, 1, 2, 3, 4, 5, 6, 7], dtype=int64), Array([0, 0, 3, 2, 3, 1, 1, 0], dtype=int64)) >>> f(4) (Array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], dtype=int64), Array([0, 0, 1, 1, 2, 0, 0, 0, 0, 0, 1, 1, 2, 1, 0, 1], dtype=int64))
Catalyst better integrates with PennyLane program capture, supporting PennyLane-native control flow operations and providing more efficient transform handling when both Catalyst and PennyLane support a transform. (#1468) (#1509) (#1521) (#1544) (#1561) (#1567) (#1578)
Using PennyLane’s program capture mechanism involves setting
experimental_capture=Truein the qjit decorator. With this present, the following control flow functions in PennyLane are now usable with qjit:Support for
qml.cond:import pennylane as qml from catalyst import qjit dev = qml.device("lightning.qubit", wires=1) @qjit(experimental_capture=True) @qml.qnode(dev) def circuit(x: float): def ansatz_true(): qml.RX(x, wires=0) qml.Hadamard(wires=0) def ansatz_false(): qml.RY(x, wires=0) qml.cond(x > 1.4, ansatz_true, ansatz_false)() return qml.expval(qml.Z(0))
>>> circuit(0.1) Array(0.99500417, dtype=float64)
Support for
qml.for_loop:dev = qml.device("lightning.qubit", wires=2) @qjit(experimental_capture=True) @qml.qnode(dev) def circuit(x: float): @qml.for_loop(10) def loop(i): qml.H(wires=1) qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) loop() return qml.expval(qml.Z(0))
>>> circuit(0.1) Array(0.97986841, dtype=float64)
Support for
qml.while_loop:@qjit(experimental_capture=True) @qml.qnode(dev) def circuit(x: float): f = lambda c: c < 5 @qml.while_loop(f) def loop(c): qml.H(wires=1) qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) return c + 1 loop(0) return qml.expval(qml.Z(0))
>>> circuit(0.1) Array(0.97526892, dtype=float64)
Additionally, Catalyst can now apply its own compilation passes when equivalent transforms are provided by PennyLane (e.g.,
cancel_inversesandmerge_rotations). In cases where Catalyst does not have its own analogous implementation of a transform available in PennyLane, the transform will be expanded according to rules provided by PennyLane.For example, consider this workflow that contains two PennyLane transforms:
cancel_inversesandsingle_qubit_fusion. Catalyst has its own implementation ofcancel_inversesin thepassesmodule, and will smartly invoke its implementation intead. Conversely, Catalyst does not have its own implementation ofsingle_qubit_fusion, and will therefore resort to PennyLane’s implementation of the transform.dev = qml.device("lightning.qubit", wires=1) @qjit(experimental_capture=True) def func(r1, r2): @qml.transforms.cancel_inverses @qml.transforms.single_qubit_fusion @qml.qnode(dev) def circuit(r1, r2): qml.Rot(*r1, wires=0) qml.Rot(*r2, wires=0) qml.RZ(r1[0], wires=0) qml.RZ(r2[0], wires=0) qml.Hadamard(wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliZ(0)) return circuit(r1, r2)
>>> r1 = jnp.array([0.1, 0.2, 0.3]) >>> r2 = jnp.array([0.4, 0.5, 0.6]) >>> func(r1, r2) Array(0.7872403, dtype=float64)
Improvements 🛠
Several changes have been made to reduce compile time:
Catalyst now decomposes non-differentiable gates when differentiating through workflows. Additionally, with
diff_method=parameter-shift, circuits are now verified to be fully compatible with Catalyst’s parameter-shift implementation before compilation. (#1562) (#1568) (#1569) (#1604)Gates that are constant, such as when all parameters are Python or NumPy data types, are not decomposed when this is allowable. For the adjoint differentiation method, this is allowable for the
StatePrep,BasisState, andQubitUnitaryoperations. For the parameter-shift method, this is allowable for all operations.An
mlir_optproperty has been added toqjitto access the optimized MLIR representation of a compiled function. This is the representation of the program after running everything in the MLIR stage of the entire pipeline. (#1579) (#1637)from catalyst import qjit @qjit def f(x): return x**2
>>> f(2) Array(4, dtype=int64) >>> print(f.mlir_opt) module @f { llvm.func @__catalyst__rt__finalize() llvm.func @__catalyst__rt__initialize(!llvm.ptr) llvm.func @_mlir_memref_to_llvm_alloc(i64) -> !llvm.ptr llvm.func @jit_f(%arg0: !llvm.ptr, %arg1: !llvm.ptr, %arg2: i64) -> !llvm.struct<(ptr, ptr, i64)> attributes {llvm.copy_memref, llvm.emit_c_interface} ... llvm.func @teardown() { llvm.call @__catalyst__rt__finalize() : () -> () llvm.return } }
The error messages that indicate invalid
scale_factorsincatalyst.mitigate_with_znehave been improved to be formatted properly. (#1603)
Bug fixes 🐛
Fixed the
argnumsparameter ofgradandvalue_and_gradbeing ignored. (#1478)All dialects are loaded preemptively. This allows third-party plugins to load their dialects. (#1584)
Fixed an issue where Catalyst could give incorrect results for circuits containing
qml.StatePrep. (#1491)Fixed an issue where using autograph in conjunction with catalyst passes caused a crash. (#1541)
Fixed an issue where using autograph in conjunction with catalyst pipeline caused a crash. (#1576)
Fixed an issue where using chained catalyst passes decorators caused a crash. (#1576)
Specialized handling for
pipelines was added. (#1599)Fixed an issue where using autograph with control/adjoint functions used on operator objects caused a crash. (#1605)
Fixed an issue where using pytrees inside a loop with autograph caused falling back to Python. (#1601)
For example, the following example will now be captured and executed properly with Autograph enabled:
from catalyst import qjit
def updateList(x):
return [x[0]+1, x[1]+2]
@qjit(autograph=True)
def fn(x):
for i in range(4):
x = updateList(x)
return x
>>> fn([1, 2])
[Array(5, dtype=int64), Array(10, dtype=int64)]
Closure variables are now supported with
gradandvalue_and_grad. (#1613)
Internal changes ⚙️
Pattern rewriting in the
quantum-to-ionlowering pass has been changed to use MLIR’s dialect conversion infrastructure. (#1442)Updated the call signature for the plxpr
qnode_primprimitive. (#1538)Update deprecated access to
QNode.execute_kwargs["mcm_config"]. Insteadpostselect_modeandmcm_methodshould be accessed instead. (#1452)from_plxprnow uses theqml.capture.PlxprInterpreterclass for reduced code duplication. (#1398)Improved the error message for invalid measurement in
adjoin()orctrl()region. (#1425)Replaced
ValueRangewithResultRangeandValuewithOpResultto better align with the semantics of**QubitResult()functions likegetNonCtrlQubitResults(). This change ensures clearer intent and usage. Also, thematchAndRewritefunction has improved by usingreplaceAllUsesWithinstead of aforloop. (#1426)Several changes for experimental support of trapped-ion OQD devices have been made, including:
The
get_c_interfacemethod has been added to the OQD device, which enables retrieval of the C++ implementation of the device from Python. This allowsqjitto accept an instance of the device and connect to its runtime. (#1420)The ion dialect has been improved to reduce redundant code generated, a string attribute
labelhas been added to Level, and the levels of a transition have changed fromLevelAttrtostring. (#1471)The region of a
ParallelProtocolOpis now always terminated with aion::YieldOpwith explicitly yielded SSA values. This ensures the op is well-formed, and improves readability. (#1475)Added a new pass called
convert-ion-to-llvmwhich lowers the Ion dialect to llvm dialect. This pass introduces oqd device specific stubs that will be implemented in oqd runtime including:@ __catalyst__oqd__pulse,@ __catalyst__oqd__ParallelProtocol. (#1466)The OQD device can now generate OpenAPL JSON specs during runtime. The oqd stubs
@ __catalyst__oqd__pulse, and@ __catalyst__oqd__ParallelProtocol, which are called in the llvm dialect after the aforementioned lowering ((#1466)), are defined to produce JSON specs that OpenAPL expects. (#1516)The OQD device has been moved from
frontend/catalyst/third_party/oqdtoruntime/lib/backend/oqd. An overall switch,ENABLE_OQD, is added to control the OQD build system from a single entry point. The switch isOFFby default, and OQD can be built from source viamake all ENABLE_OQD=ON, ormake runtime ENABLE_OQD=ON. (#1508)Ion dialect now supports phonon modes using
ion.modesoperation. (#1517)Rotation angles are normalized to avoid negative duration for pulses during ion dialect lowering. (#1517)
Catalyst now generates OpenAPL programs for Pennylane circuits of up to two qubits using the OQD device. (#1517)
The end-to-end compilation pipeline for OQD devices is available as an API function. (#1545)
The source code has been updated to comply with changes requested by black v25.1.0 (#1490)
Reverted
StaticCustomOpin favour of adding helper functionsisStatic(),getStaticParams()to theCustomOpwhich preserves the same functionality. More specifically, this reverts [#1387] and [#1396], modifies [#1489]. (#1558) (#1555)Updated the C++ standard in mlir layer from 17 to 20. (#1229)
Documentation 📝
Added more details to JAX integration documentation regarding the use of
.atwith multiple indices. (#1595)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Joey Carter, Yushao Chen, Isaac De Vlugt, Zach Goldthorpe, Sengthai Heng, David Ittah, Rohan Nolan Lasrado, Christina Lee, Mehrdad Malekmohammadi, Erick Ochoa Lopez, Andrija Paurevic, Raul Torres, Paul Haochen Wang.
Release 0.10.0¶
New features since last release
Catalyst can now load and apply local MLIR plugins from the PennyLane frontend. (#1287) (#1317) (#1361) (#1370)
Custom compilation passes and dialects in MLIR can be specified for use in Catalyst via a shared object (
*.soor*.dylibon macOS) that implements the pass. Details on creating your own plugin can be found in our compiler plugin documentation. At a high level, there are three ways to use a plugin once it’s properly specified:apply_pass()can be used on QNodes when there is a Python entry point defined for the plugin. In that case, the plugin and pass should both be specified and separated by a period.@catalyst.passes.apply_pass("plugin_name.pass_name") @qml.qnode(qml.device("lightning.qubit", wires=1)) def qnode(): return qml.state() @qml.qjit def module(): return qnode()
apply_pass_plugin()can be used on QNodes when the plugin did not define an entry point. In that case the full filesystem path must be specified in addition to the pass name.from pathlib import Path @catalyst.passes.apply_pass_plugin(Path("path_to_plugin"), "pass_name") @qml.qnode(qml.device("lightning.qubit", wires=1)) def qnode(): return qml.state() @qml.qjit def module(): return qnode()
Alternatively, one or more dialect and pass plugins can be specified in advance in the
qjit()decorator, via thepass_pluginsanddialect_pluginskeyword arguments. Theapply_pass()function can then be used without specifying the plugin.from pathlib import Path plugin = Path("shared_object_file.so") @catalyst.passes.apply_pass("pass_name") @qml.qnode(qml.device("lightning.qubit", wires=0)) def qnode(): qml.Hadamard(wires=0) return qml.state() @qml.qjit(pass_plugins=[plugin], dialect_plugins=[plugin]) def module(): return qnode()
For more information on usage, visit our compiler plugin documentation.
Improvements 🛠
The Catalyst CLI, a command line interface for debugging and dissecting different stages of compilation, is now available under the
catalystcommand after installing Catalyst with pip. Even though the tool was first introduced inv0.9, it was not yet included in binary distributions of Catalyst (wheels). The full usage instructions are available in the Catalyst CLI documentation. (#1285) (#1368) (#1405)Lightning devices now support finite-shot expectation values of
qml.Hermitianwhen used with Catalyst. (#451)The PennyLane state preparation template
qml.CosineWindowis now compatible with Catalyst. (#1166)A development distribution of Python with dynamic linking support (
libpython.so) is no longer needed in order to usecompile_executable()to generate standalone executables of compiled programs. (#1305)In Catalyst
v0.9the output of the compiler instrumentation (instrumentation()) had inadvertently been made more verbose by printing timing information for each run of each pass. This change has been reverted. Instead, theqjit()optionverbose=Truewill now instruct the instrumentation to produce this more detailed output. (#1343)Two additional circuit optimizations have been added to Catalyst:
disentangle-CNOTanddisentangle-SWAP. The optimizations are available via thepassesmodule. (#1154) (#1407)The optimizations use a finite state machine to propagate limited qubit state information through the circuit to turn CNOT and SWAP gates into cheaper instructions. The pass is based on the work by J. Liu, L. Bello, and H. Zhou, Relaxed Peephole Optimization: A Novel Compiler Optimization for Quantum Circuits, 2020, arXiv:2012.07711.
Breaking changes 💔
The minimum supported PennyLane version has been updated to
v0.40; backwards compatibility in either direction is not maintained. (#1308)(Device Developers Only) The way the
shotsparameter is initialized in C++ device backends is changing. (#1310)The previous method of including the shot number in the
kwargsargument of the device constructor is deprecated and will be removed in the next release (v0.11). Instead, the shots value will be specified exclusively via the existingSetDeviceShotsfunction called at the beginning of a quantum execution. Device developers are encouraged to update their device implementations between this and the next release while both methods are supported.Similarly, the
SampleandCountsfunctions (and theirPartial*equivalents) will no longer provide ashotsargument, since they are redundant. The signature of these functions will update in the next release.(Device Developers Only) The
toml-based device schemas have been integrated with PennyLane and updated to a new versionschema = 3. (#1275)Devices with existing TOML
schema = 2will not be compatible with the current release of Catalyst until updated. A summary of the most importation changes is listed here:operators.gates.nativerenamed tooperators.gatesoperators.gates.decompandoperators.gates.matrixare removed and no longer necessaryconditionproperty is renamed toconditionsEntries in the
measurement_processessection now expect the full PennyLane class name as opposed to the deprecatedmp.return_typeshorthand (e.g.ExpectationMPinstead ofExpval).The
mid_circuit_measurementsfield has been replaced withsupported_mcm_methods, which expects a list of mcm methods that the device is able to work with (or empty if unsupported).A new field has been added,
overlapping_observables, which indicates whether a device supports multiple measurements during one execution on overlapping wires.The
optionssection has been removed. Instead, the Python device class should define adevice_kwargsfield holding the name and values of C++ device constructor kwargs.
See the Custom Devices page for the most up-to-date information on integrating your device with Catalyst and PennyLane.
Bug fixes 🐛
Fixed a bug introduced in Catalyst
v0.8that breaks nested invocations ofqml.adjointandqml.ctrl(e.g.qml.adjoint(qml.adjoint(qml.H(0)))). (#1301)Fixed a bug in
compile_executable()when using non-64bit arrays as input to the compiled function, due to incorrectly computed stride information. (#1338)Fixed a bug in catalyst cli where using
checkpoint-stagewould causesave-ir-after-eachto not work properly. (#1405)
Internal changes ⚙️
Starting with Python 3.12, Catalyst’s binary distributions (wheels) will now follow Python’s Stable ABI, eliminating the need for a separate wheel per minor Python version. To enable this, the following changes have made:
Stable ABI wheels are now generated for Python 3.12 and up. (#1357) (#1385)
Pybind11 has been replaced with nanobind for C++/Python bindings across all components. (#1173) (#1293) (#1391) (#624)
Nanobind has been developed as a natural successor to the pybind11 library and offers a number of advantages like its ability to target Python’s Stable ABI.
Python C-API calls have been replaced with functions from Python’s Limited API. (#1354)
The
QuantumExtensionmodule for MLIR Python bindings, which relies on pybind11, has been removed. The module was never included in the distributed wheels and could not be converted to nanobind easily due to its dependency on upstream MLIR code. Pybind11 does not support the Python Stable ABI. (#1187)
Catalyst no longer depends on or pins the
scipypackage. Instead, OpenBLAS is sourced directly from scipy-openblas32 or Accelerate is used. (#1322) (#1328)The Catalyst plugin for the
lightning.qubitdevice has been migrated from the Catalyst repo to the Lightning repository. This reduces the size of Catalyst’s binary distributions and the build time of the project, by avoiding re-compilation of the lightning source code. (#1227) (#1307) (#1312)The AutoGraph exception mechanism (
allowlistparameter) has been streamlined to only be used in places where it’s required. (#1332) (#1337)Each QNode now has its own transformation schedule. Instead of relying on the name of the QNode, each QNode now has a transformation module, which denotes the transformation schedule, embedded in its MLIR representation. (#1323)
The
apply_registered_pass_pprimitive has been removed and the API for scheduling passes to run using the transform dialect has been refactored. In particular, passes are appended to a tuple as they are being registered and they will be run in order. If there are no local passes, the globalpass_pipelineis scheduled. Furthermore, this commit also reworks the caching mechanism for primitives, which is important as qnodes and functions are primitives and now that we can apply passes to them, they are distinct based on which passes have been scheduled to run on them. (#1317)The Catalyst infrastructure has been upgraded to support a dynamic
shotsparameter for quantum execution. Previously, this value had to be a static compile-time constant, and could not be changed once the program was compiled. Upcoming UI changes will make the feature accessible to users. (#1360)Several changes for experimental support of trapped-ion OQD devices have been made, including:
An experimental
iondialect has been added for Catalyst programs targeting OQD trapped-ion quantum devices. (#1260) (#1372)The
iondialect defines the set of physical properties of the device, such as the ion species and their atomic energy levels, as well as the operations to manipulate the qubits in the trapped-ion system, such as laser pulse durations, polarizations, detuning frequencies, etc.A new pass,
--quantum-to-ion, has also been added to convert logical gate-based circuits in the Catalystquantumdialect to laser pulse operations in theiondialect. This pass accepts logical quantum gates from the set{RX, RY, MS}, whereMSis the Mølmer–Sørensen gate. Doing so enables the insertion of physical device parameters into the IR, which will be necessary when lowering to OQD’s backend calls. The physical parameters, which are typically obtained from hardware-calibration runs, are read in from TOML files during the--quantum-to-ionconversion. The TOML filepaths are taken in as pass options.A plugin and device backend for OQD trapped-ion quantum devices has been added. (#1355) (#1403)
An MLIR transformation has been added to decompose
{T, S, Z, Hadamard, RZ, PhaseShift, CNOT}gates into the set{RX, RY, MS}. (#1226)
Support for OQD devices is still under development, therefore OQD modules are currently not included in binary distributions (wheels) of Catalyst.
The Catalyst IR has been extended to support literal values as opposed to SSA Values for static parameters of quantum gates by adding a new gate called
StaticCustomOp, with eventual lowering to the regularCustomOpoperation. (#1387) (#1396)Code readability in the
catalyst.pipelinesmodule has been improved, in particular for pipelines with conditionally included passes. (#1194)
Documentation 📝
A new tutorial going through how to write a new MLIR pass is available. The tutorial writes an empty pass that prints
hello world. The code for the tutorial is located in a separate github branch. (#872)The
verboseparameter ofqjit()was incorrectly listed asverbosityin the API documentation. This is now fixed. (#1440)Added more details to catalyst-cli documentation specifying available options for checkpoint-stage and default pipelines (#1405)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Astral Cai, Joey Carter, David Ittah, Erick Ochoa Lopez, Mehrdad Malekmohammadi, William Maxwell, Romain Moyard, Shuli Shu, Ritu Thombre, Raul Torres, Paul Haochen Wang.
Release 0.9.0¶
New features
Catalyst now supports the specification of shot-vectors when used with
qml.samplemeasurements on thelightning.qubitdevice. (#1051)Shot-vectors allow shots to be specified as a list of shots,
[20, 1, 100], or as a tuple of the form((num_shots, repetitions), ...)such that((20, 3), (1, 100))is equivalent toshots=[20, 20, 20, 1, 1, ..., 1].This can result in more efficient quantum execution, as a single job representing the total number of shots is executed on the quantum device, with the measurement post-processing then coarse-grained with respect to the shot-vector.
For example,
dev = qml.device("lightning.qubit", wires=1, shots=((5, 2), 7)) @qjit @qml.qnode(dev) def circuit(): qml.Hadamard(0) return qml.sample()
>>> circuit() (Array([[0], [1], [0], [1], [1]], dtype=int64), Array([[0], [1], [1], [0], [1]], dtype=int64), Array([[1], [0], [1], [1], [0], [1], [0]], dtype=int64))
Note that other measurement types, such as
expvalandprobs, currently do not support shot-vectors.A new function
catalyst.pipelineallows the quantum-circuit-transformation pass pipeline for QNodes within a qjit-compiled workflow to be configured. (#1131) (#1240)import pennylane as qml from catalyst import pipeline, qjit my_passes = { "cancel_inverses": {}, "my_circuit_transformation_pass": {"my-option" : "my-option-value"}, } dev = qml.device("lightning.qubit", wires=2) @pipeline(my_passes) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)) @qjit def fn(x): return jnp.sin(circuit(x ** 2))
pipelinecan also be used to specify different pass pipelines for different parts of the same qjit-compiled workflow:my_pipeline = { "cancel_inverses": {}, "my_circuit_transformation_pass": {"my-option" : "my-option-value"}, } my_other_pipeline = {"cancel_inverses": {}} @qjit def fn(x): circuit_pipeline = pipeline(my_pipeline)(circuit) circuit_other = pipeline(my_other_pipeline)(circuit) return jnp.abs(circuit_pipeline(x) - circuit_other(x))
The pass pipeline order and options can be configured globally for a qjit-compiled function, by using the
circuit_transform_pipelineargument of theqjit()decorator.my_passes = { "cancel_inverses": {}, "my_circuit_transformation_pass": {"my-option" : "my-option-value"}, } @qjit(circuit_transform_pipeline=my_passes) def fn(x): return jnp.sin(circuit(x ** 2))
Global and local (via
@pipeline) configurations can coexist, however local pass pipelines will always take precedence over global pass pipelines.The available MLIR passes are listed and documented in the passes module documentation.
A peephole merge rotations pass, which acts similarly to the Python-based PennyLane merge rotations transform, is now available in MLIR and can be applied to QNodes within a qjit-compiled function. (#1162) (#1205) (#1206)
The
merge_rotationspass can be provided to thecatalyst.pipelinedecorator:from catalyst import pipeline, qjit my_passes = { "merge_rotations": {} } dev = qml.device("lightning.qubit", wires=1) @qjit @pipeline(my_passes) @qml.qnode(dev) def g(x: float): qml.RX(x, wires=0) qml.RX(x, wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliX(0))
It can also be applied directly to qjit-compiled QNodes via the
catalyst.passes.merge_rotationsPython decorator:from catalyst.passes import merge_rotations @qjit @merge_rotations @qml.qnode(dev) def g(x: float): qml.RX(x, wires=0) qml.RX(x, wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliX(0))
Static arguments of a qjit-compiled function can now be indicated by name via a
static_argnamesargument to theqjitdecorator. (#1158)Specified static argument names will be treated as compile-time static values, allowing any hashable Python object to be passed to this function argument during compilation.
>>> @qjit(static_argnames="y") ... def f(x, y): ... print(f"Compiling with y={y}") ... return x + y >>> f(0.5, 0.3) Compiling with y=0.3
The function will only be re-compiled if the hash values of the static arguments change. Otherwise, re-using previous static argument values will result in no re-compilation:
Array(0.8, dtype=float64) >>> f(0.1, 0.3) # no re-compilation occurs Array(0.4, dtype=float64) >>> f(0.1, 0.4) # y changes, re-compilation Compiling with y=0.4 Array(0.5, dtype=float64)
Catalyst Autograph now supports updating a single index or a slice of JAX arrays using Python’s array assignment operator syntax. (#769) (#1143)
Using operator assignment syntax in favor of
at...opexpressions is now possible for the following operations:x[i] += yin favor ofx.at[i].add(y)x[i] -= yin favor ofx.at[i].add(-y)x[i] *= yin favor ofx.at[i].multiply(y)x[i] /= yin favor ofx.at[i].divide(y)x[i] **= yin favor ofx.at[i].power(y)
@qjit(autograph=True) def f(x): first_dim = x.shape[0] result = jnp.copy(x) for i in range(first_dim): result[i] *= 2 # This is now supported return result
>>> f(jnp.array([1, 2, 3])) Array([2, 4, 6], dtype=int64)
Catalyst now has a standalone compiler tool called
catalyst-clithat quantum-compiles MLIR input files into an object file independent of the Python frontend. (#1208) (#1255)This compiler tool combines three stages of compilation:
quantum-opt: Performs the MLIR-level optimizations and lowers the input dialect to the LLVM dialect.mlir-translate: Translates the input in the LLVM dialect into LLVM IR.llc: Performs lower-level optimizations and creates the object file.
catalyst-cliruns all three stages under the hood by default, but it also has the ability to run each stage individually. For example:# Creates both the optimized IR and an object file catalyst-cli input.mlir -o output.o # Only performs MLIR optimizations catalyst-cli --tool=opt input.mlir -o llvm-dialect.mlir # Only lowers LLVM dialect MLIR input to LLVM IR catalyst-cli --tool=translate llvm-dialect.mlir -o llvm-ir.ll # Only performs lower-level optimizations and creates object file catalyst-cli --tool=llc llvm-ir.ll -o output.o
Note that
catalyst-cliis only available when Catalyst is built from source, and is not included when installing Catalyst via pip or from wheels.Experimental integration of the PennyLane capture module is available. It currently only supports quantum gates, without control flow. (#1109)
To trigger the PennyLane pipeline for capturing the program as a Jaxpr, simply set
experimental_capture=Truein the qjit decorator.import pennylane as qml from catalyst import qjit dev = qml.device("lightning.qubit", wires=1) @qjit(experimental_capture=True) @qml.qnode(dev) def circuit(): qml.Hadamard(0) qml.CNOT([0, 1]) return qml.expval(qml.Z(0))
Improvements
Multiple
qml.samplecalls can now be returned from the same program, and can be structured using Python containers. For example, a program can return a dictionary of the formreturn {"first": qml.sample(), "second": qml.sample()}. (#1051)Catalyst now ships with
null.qubit, a Catalyst runtime plugin that mocks out all functions in the QuantumDevice interface. This device is provided as a convenience for testing and benchmarking purposes. (#1179)qml.device("null.qubit", wires=1) @qml.qjit @qml.qnode(dev) def g(x): qml.RX(x, wires=0) return qml.probs(wires=[0])
Setting the
seedargument in theqjitdecorator will now seed sampled results, in addition to mid-circuit measurement results. (#1164)dev = qml.device("lightning.qubit", wires=1, shots=10) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) m = catalyst.measure(0) if m: qml.Hadamard(0) return qml.sample() @qml.qjit(seed=37, autograph=True) def workflow(x): return jnp.squeeze(jnp.stack([circuit(x) for i in range(4)]))
>>> workflow(1.8) Array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 0, 0, 1, 1, 0, 0, 1, 0], [0, 0, 1, 0, 1, 1, 0, 0, 1, 1], [1, 1, 1, 0, 0, 1, 1, 0, 1, 1]], dtype=int64) >>> workflow(1.8) Array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 0, 0, 1, 1, 0, 0, 1, 0], [0, 0, 1, 0, 1, 1, 0, 0, 1, 1], [1, 1, 1, 0, 0, 1, 1, 0, 1, 1]], dtype=int64)
Note that statistical measurement processes such as
expval,var, andprobsare currently not affected by seeding when shot noise is present.The
cancel_inversesMLIR compilation pass (-remove-chained-self-inverse) now supports cancelling all Hermitian gates, as well as adjoints of arbitrary unitary operations. (#1136) (#1186) (#1211)For the full list of supported Hermitian gates please see the
cancel_inversesdocumentation incatalyst.passes.Support is expanded for backend devices that exclusively return samples in the measurement basis. Pre- and post-processing now allows
qjitto be used on these devices withqml.expval,qml.varandqml.probsmeasurements in addition toqml.sample, using themeasurements_from_samplestransform. (#1106)Scalar tensors are eliminated from control flow operations in the program, and are replaced with bare scalars instead. This improves compilation time and memory usage at runtime by avoiding heap allocations and reducing the amount of instructions. (#1075)
Compiling QNodes to asynchronous functions will no longer print to
stderrin case of an error. (#645)Gradient computations have been made more efficient, as calling gradients twice (with the same gradient parameters) will now only lower to a single MLIR function. (#1172)
qml.sample()andqml.counts()onlightning.qubit/kokkoscan now be seeded withqjit(seed=...). (#1164) (#1248)The compiler pass
-remove-chained-self-inversecan now also cancel adjoints of arbitrary unitary operations (in addition to the named Hermitian gates). (#1186) (#1211)Add Lightning-GPU support to Catalyst docs and update tests. (#1254)
Breaking changes
The
static_sizefield in theAbstractQregclass has been removed. (#1113)This reverts a previous breaking change.
Nesting QNodes within one another now raises an error. (#1176)
The
debug.compile_from_mlirfunction has been removed; please usedebug.replace_irinstead. (#1181)The
compiler.last_compiler_outputfunction has been removed; please usecompiler.get_output_of("last", workspace)instead. (#1208)
Bug fixes
Fixes a bug where the second execution of a function with abstracted axes is failing. (#1247)
Fixes a bug in
catalyst.mitigate_with_znethat would lead to incorrectly extrapolated results. (#1213)Fixes a bug preventing the target of
qml.adjointandqml.ctrlcalls from being transformed by AutoGraph. (#1212)Resolves a bug where
mitigate_with_znedoes not work properly with shots and devices supporting only counts and samples (e.g., Qrack). (#1165)Resolves a bug in the
vmapfunction when passing shapeless values to the target. (#1150)Fixes a bug that resulted in an error message when using
qml.condon callables with arguments. (#1151)Fixes a bug that prevented taking the gradient of nested accelerate callbacks. (#1156)
Fixes some small issues with scatter lowering: (#1216) (#1217)
Registers the func dialect as a requirement for running the scatter lowering pass.
Emits error if
%input,%updateand%resultare not of length 1 instead of segfaulting.
Fixes a performance issue with
catalyst.vmap, where the root cause was in the lowering of the scatter operation. (#1214)Fixes a bug where conditional-ed single gates cannot be used in qjit, e.g.
qml.cond(x > 1, qml.Hadamard)(wires=0). (#1232)
Internal changes
Removes deprecated PennyLane code across the frontend. (#1168)
Updates Enzyme to version
v0.0.149. (#1142)Adjoint canonicalization is now available in MLIR for
CustomOpandMultiRZOp. It can be used with the--canonicalizepass inquantum-opt. (#1205)Removes the
MemMemCpyOptPassin llvm O2 (applied for Enzyme), which reduces bugs when running gradient-like functions. (#1063)Bufferization of
gradient.ForwardOpandgradient.ReverseOpnow requires three steps:gradient-preprocessing,gradient-bufferize, andgradient-postprocessing.gradient-bufferizehas a new rewrite forgradient.ReturnOp. (#1139)A new MLIR pass
detensorize-scfis added that works in conjunction with the existinglinalg-detensorizepass to detensorize input programs. The IR generated by JAX wraps all values in the program in tensors, including scalars, leading to unnecessary memory allocations for programs compiled to CPU via the MLIR-to-LLVM pipeline. (#1075)Importing Catalyst will now pollute less of JAX’s global variables by using
LoweringParameters. (#1152)Cached primitive lowerings is used instead of a custom cache structure. (#1159)
Functions with multiple tapes are now split with a new mlir pass
--split-multiple-tapes, with one tape per function. The reset routine that makes a measurement between tapes and inserts an X gate if measured one is no longer used. (#1017) (#1130)Prefer creating new
qml.devices.ExecutionConfigobjects over using the globalqml.devices.DefaultExecutionConfig. Doing so helps avoid unexpected bugs and test failures in case theDefaultExecutionConfigobject becomes modified from its original state. (#1137)Remove the old
QJITDeviceAPI. (#1138)The device-capability loading mechanism has been moved into the
QJITDeviceconstructor. (#1141)Several functions related to device capabilities have been refactored. (#1149)
In particular, the signatures of
get_device_capability,catalyst_decompose,catalyst_acceptance, andQJITDevice.__init__have changed, and thepennylane_operation_setfunction has been removed entirely.Catalyst now generates nested modules denoting quantum programs. (#1144)
Similar to MLIR’s
gpu.launch_kernelfunction, Catalyst, now supports acall_function_in_module. This allows Catalyst to call functions in modules and have modules denote a quantum kernel. This will allow for device-specific optimizations and compilation pipelines.At the moment, no one is using this. This is just the necessary scaffolding to support device-specific transformations. As such, the module will be inlined to preserve current semantics. However, in the future, we will explore lowering this nested module into other IRs/binary formats and lowering
call_function_in_moduleto something that can dispatch calls to another runtime/VM.
Contributors
This release contains contributions from (in alphabetical order):
Joey Carter, Spencer Comin, Amintor Dusko, Lillian M.A. Frederiksen, Sengthai Heng, David Ittah, Mehrdad Malekmohammadi, Vincent Michaud-Rioux, Romain Moyard, Erick Ochoa Lopez, Daniel Strano, Raul Torres, Paul Haochen Wang.
Release 0.8.0¶
New features
JAX-compatible functions that run on classical accelerators, such as GPUs, via
catalyst.acceleratenow support autodifferentiation. (#920)For example,
from catalyst import qjit, grad @qjit @grad def f(x): expm = catalyst.accelerate(jax.scipy.linalg.expm) return jnp.sum(expm(jnp.sin(x)) ** 2)
>>> x = jnp.array([[0.1, 0.2], [0.3, 0.4]]) >>> f(x) Array([[2.80120452, 1.67518663], [1.61605839, 4.42856163]], dtype=float64)
Assertions can now be raised at runtime via the
catalyst.debug_assertfunction. (#925)Python-based exceptions (via
raise) and assertions (viaassert) will always be evaluated at program capture time, before certain runtime information may be available.Use
debug_assertto instead raise assertions at runtime, including assertions that depend on values of dynamic variables.For example,
from catalyst import debug_assert @qjit def f(x): debug_assert(x < 5, "x was greater than 5") return x * 8
>>> f(4) Array(32, dtype=int64) >>> f(6) RuntimeError: x was greater than 5
Assertions can be disabled globally for a qjit-compiled function via the
disable_assertionskeyword argument:@qjit(disable_assertions=True) def g(x): debug_assert(x < 5, "x was greater than 5") return x * 8
>>> g(6) Array(48, dtype=int64)
Mid-circuit measurement results when using
lightning.qubitandlightning.kokkoscan now be seeded via the newseedargument of theqjitdecorator. (#936)The seed argument accepts an unsigned 32-bit integer, which is used to initialize the pseudo-random state at the beginning of each execution of the compiled function. Therefor, different
qjitobjects with the same seed (including repeated calls to the sameqjit) will always return the same sequence of mid-circuit measurement results.dev = qml.device("lightning.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) m = measure(0) if m: qml.Hadamard(0) return qml.probs() @qjit(seed=37, autograph=True) def workflow(x): return jnp.stack([circuit(x) for i in range(4)])
Repeatedly calling the
workflowfunction above will always result in the same values:>>> workflow(1.8) Array([[1. , 0. ], [1. , 0. ], [1. , 0. ], [0.5, 0.5]], dtype=float64) >>> workflow(1.8) Array([[1. , 0. ], [1. , 0. ], [1. , 0. ], [0.5, 0.5]], dtype=float64)
Note that setting the seed will not avoid shot-noise stochasticity in terminal measurement statistics such as
sampleorexpval:dev = qml.device("lightning.qubit", wires=1, shots=10) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) m = measure(0) if m: qml.Hadamard(0) return qml.expval(qml.PauliZ(0)) @qjit(seed=37, autograph=True) def workflow(x): return jnp.stack([circuit(x) for i in range(4)])
>>> workflow(1.8) Array([1. , 1. , 1. , 0.4], dtype=float64) >>> workflow(1.8) Array([ 1. , 1. , 1. , -0.2], dtype=float64)
Exponential fitting is now a supported method of zero-noise extrapolation when performing error mitigation in Catalyst using
mitigate_with_zne. (#953)This new functionality fits the data from noise-scaled circuits with an exponential function, and returns the zero-noise value:
from pennylane.transforms import exponential_extrapolate from catalyst import mitigate_with_zne dev = qml.device("lightning.qubit", wires=2, shots=100000) @qml.qnode(dev) def circuit(weights): qml.StronglyEntanglingLayers(weights, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) @qjit def workflow(weights, s): zne_circuit = mitigate_with_zne(circuit, scale_factors=s, extrapolate=exponential_extrapolate) return zne_circuit(weights)
>>> weights = jnp.ones([3, 2, 3]) >>> scale_factors = jnp.array([1, 2, 3]) >>> workflow(weights, scale_factors) Array(-0.19946598, dtype=float64)
A new module is available,
catalyst.passes, which provides Python decorators for enabling and configuring Catalyst MLIR compiler passes. (#911) (#1037)The first pass available is
catalyst.passes.cancel_inverses, which enables the-removed-chained-self-inverseMLIR pass that cancels two neighbouring Hadamard gates.from catalyst.debug import get_compilation_stage from catalyst.passes import cancel_inverses dev = qml.device("lightning.qubit", wires=1) @qml.qnode(dev) def circuit(x: float): qml.RX(x, wires=0) qml.Hadamard(wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliZ(0)) @qjit(keep_intermediate=True) def workflow(x): optimized_circuit = cancel_inverses(circuit) return circuit(x), optimized_circuit(x)
Catalyst now has debug functions
get_compilation_stageandreplace_irto acquire and recompile the IR from a given pipeline pass for functions compiled withkeep_intermediate=True. (#981)For example, consider the following function:
@qjit(keep_intermediate=True) def f(x): return x**2
>>> f(2.0) 4.0
Here we use
get_compilation_stageto acquire the IR, and then modify%2 = arith.mulf %in, %in_0 : f64to turn the square function into a cubic one viareplace_ir:from catalyst.debug import get_compilation_stage, replace_ir old_ir = get_compilation_stage(f, "HLOLoweringPass") new_ir = old_ir.replace( "%2 = arith.mulf %in, %in_0 : f64\n", "%t = arith.mulf %in, %in_0 : f64\n %2 = arith.mulf %t, %in_0 : f64\n" ) replace_ir(f, "HLOLoweringPass", new_ir)
The recompilation starts after the given checkpoint stage:
>>> f(2.0) 8.0
Either function can also be used independently of each other. Note that
get_compilation_stagereplaces theprint_compilation_stagefunction; please see the Breaking Changes section for more details.Catalyst now supports generating executables from compiled functions for the native host architecture using
catalyst.debug.compile_executable. (#1003)>>> @qjit ... def f(x): ... y = x * x ... catalyst.debug.print_memref(y) ... return y >>> f(5) MemRef: base@ = 0x31ac22580 rank = 0 offset = 0 sizes = [] strides = [] data = 25 Array(25, dtype=int64)
We can use
compile_executableto compile this function to a binary:>>> from catalyst.debug import compile_executable >>> binary = compile_executable(f, 5) >>> print(binary) /path/to/executable
Executing this function from a shell environment:
$ /path/to/executable MemRef: base@ = 0x64fc9dd5ffc0 rank = 0 offset = 0 sizes = [] strides = [] data = 25
Improvements
Catalyst has been updated to work with JAX v0.4.28 (exact version match required). (#931) (#995)
Catalyst now supports keyword arguments for qjit-compiled functions. (#1004)
>>> @qjit ... @grad ... def f(x, y): ... return x * y >>> f(3., y=2.) Array(2., dtype=float64)
Note that the
static_argnumsargument to theqjitdecorator is not supported when passing argument values as keyword arguments.Support has been added for the
jax.numpy.argsortfunction within qjit-compiled functions. (#901)Autograph now supports in-place array assignments with static slices. (#843)
For example,
@qjit(autograph=True) def f(x, y): y[1:10:2] = x return y
>>> f(jnp.ones(5), jnp.zeros(10)) Array([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.], dtype=float64)
Autograph now works when
qjitis applied to a function decorated withvmap,cond,for_looporwhile_loop. Previously, stacking the autograph-enabled qjit decorator directly on top of other Catalyst decorators would lead to errors. (#835) (#938) (#942)from catalyst import vmap, qjit dev = qml.device("lightning.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
>>> x = jnp.array([0.1, 0.2, 0.3]) >>> qjit(vmap(circuit), autograph=True)(x) Array([0.99500417, 0.98006658, 0.95533649], dtype=float64)
Runtime memory usage, and compilation complexity, has been reduced by eliminating some scalar tensors from the IR. This has been done by adding a
linalg-detensorizepass at the end of the HLO lowering pipeline. (#1010)Program verification is extended to confirm that the measurements included in QNodes are compatible with the specified device and settings. (#945) (#962)
>>> dev = qml.device("lightning.qubit", wires=2, shots=None) >>> @qjit ... @qml.qnode(dev) ... def circuit(params): ... qml.RX(params[0], wires=0) ... qml.RX(params[1], wires=1) ... return { ... "sample": qml.sample(wires=[0, 1]), ... "expval": qml.expval(qml.PauliZ(0)) ... } >>> circuit([0.1, 0.2]) CompileError: Sample-based measurements like sample(wires=[0, 1]) cannot work with shots=None. Please specify a finite number of shots.
On devices that support it, initial state preparation routines
qml.StatePrepandqml.BasisStateare no longer decomposed when using Catalyst, improving compilation and runtime performance. (#955) (#1047) (#1062) (#1073)Improved type validation and error messaging has been added to both the
catalyst.jvpandcatalyst.vjpfunctions to ensure that the (co)tangent and parameter types are compatible. (#1020) (#1030) (#1031)For example, providing an integer tangent for a function with float64 parameters will result in an error:
>>> f = lambda x: (2 * x, x * x) >>> f_jvp = lambda x: catalyst.jvp(f, params=(x,), tangents=(1,)) >>> qjit(f_jvp)(0.5) TypeError: function params and tangents arguments to catalyst.jvp do not match; dtypes must be equal. Got function params dtype float64 and so expected tangent dtype float64, but got tangent dtype int64 instead.
Ensuring that the types match will resolve the error:
>>> f_jvp = lambda x: catalyst.jvp(f, params=(x,), tangents=(1.0,)) >>> qjit(f_jvp)(0.5) ((Array(1., dtype=float64), Array(0.25, dtype=float64)), (Array(2., dtype=float64), Array(1., dtype=float64)))
Add a script for setting up a Frontend-Only Development Environment that does not require compilation, as it uses the TestPyPI wheel shared libraries. (#1022)
Breaking changes
The
argnumkeyword argument in thegrad,jacobian,value_and_grad,vjp, andjvpfunctions has been renamed toargnumsto better match JAX. (#1036)Return values of qjit-compiled functions that were previously
numpy.ndarrayare now of typejax.Arrayinstead. This should have minimal impact, but code that depends on the output of qjit-compiled function being NumPy arrays will need to be updated. (#895)The
print_compilation_stagefunction has been renamedget_compilation_stage. It no longer prints the IR to the standard output, instead it simply returns the IR as a string. (#981)>>> @qjit(keep_intermediate=True) ... def func(x: float): ... return x >>> print(get_compilation_stage(func, "HLOLoweringPass")) module @func { func.func public @jit_func(%arg0: tensor<f64>) -> tensor<f64> attributes {llvm.emit_c_interface} { return %arg0 : tensor<f64> } func.func @setup() { quantum.init return } func.func @teardown() { quantum.finalize return } }
Support for TOML files in Schema 1 has been disabled. (#960)
The
mitigate_with_znefunction no longer accepts adegreeparameter for polynomial fitting and instead accepts a callable to perform extrapolation. Any qjit-compatible extrapolation function is valid. Keyword arguments can be passed to this function using theextrapolate_kwargskeyword argument inmitigate_with_zne. (#806)The QuantumDevice API has now added the functions
SetStateandSetBasisStatefor simulators that may benefit from instructions that directly set the state. Implementing these methods is optional, and device support can be indicated via theinitial_state_prepflag in the TOML configuration file. (#955)
Bug fixes
Catalyst no longer silently converts complex parameters to floats where floats are expected, instead an error is raised. (#1008)
Fixes a bug where dynamic one-shot did not work when no mid-circuit measurements are present and when the return type is an iterable. (#1060)
Fixes a bug finding the quantum function jaxpr when using quantum primitives with dynamic one-shot (#1041)
Fix a bug where LegacyDevice number of shots is not correctly extracted when using the legacyDeviceFacade. (#1035)
Catalyst no longer generates a
QubitUnitaryoperation during decomposition if a device doesn’t support it. Instead, the operation that would lead to aQubitUnitaryis either decomposed or raises an error. (#1002)Correctly errors out when user uses
qml.density_matrix(#1118)Catalyst now preserves output PyTrees in QNodes executed with
mcm_method="one-shot". (#957)For example:
dev = qml.device("lightning.qubit", wires=1, shots=20) @qml.qjit @qml.qnode(dev, mcm_method="one-shot") def func(x): qml.RX(x, wires=0) m_0 = catalyst.measure(0, postselect=1) return {"hi": qml.expval(qml.Z(0))}
>>> func(0.9) {'hi': Array(-1., dtype=float64)}
Fixes a bug where scatter did not work correctly with list indices. (#982)
A = jnp.ones([3, 3]) * 2 def update(A): A = A.at[[0, 1], :].set(jnp.ones([2, 3]), indices_are_sorted=True, unique_indices=True) return A
>>> update [[1. 1. 1.] [1. 1. 1.] [2. 2. 2.]]
Static arguments can now be passed through a QNode when specified with the
static_argnumskeyword argument. (#932)dev = qml.device("lightning.qubit", wires=1) @qjit(static_argnums=(1,)) @qml.qnode(dev) def circuit(x, c): print("Inside QNode:", c) qml.RY(c, 0) qml.RX(x, 0) return qml.expval(qml.PauliZ(0))
When executing the qjit-compiled function above,
cwill be a static variable with value known at compile time:>>> circuit(0.5, 0.5) "Inside QNode: 0.5" Array(0.77015115, dtype=float64)
Changing the value of
cwill result in re-compilation:>>> circuit(0.5, 0.8) "Inside QNode: 0.8" Array(0.61141766, dtype=float64)
Fixes a bug where Catalyst would fail to apply quantum transforms and preserve QNode configuration settings when Autograph was enabled. (#900)
pure_callbackwill no longer cause a crash in the compiler if the return type signature is declared incorrectly and the callback function is differentiated. (#916)Instead, this is caught early and a useful error message returned:
@catalyst.pure_callback def callback_fn(x) -> jax.ShapeDtypeStruct((2,), jnp.float32): return np.array([np.sin(x), np.cos(x)]) callback_fn.fwd(lambda x: (callback_fn(x), x)) callback_fn.bwd(lambda x, dy: (jnp.array([jnp.cos(x), -jnp.sin(x)]) @ dy,)) @qjit @catalyst.grad def f(x): return jnp.sum(callback_fn(jnp.sin(x)))
>>> f(0.54) TypeError: Callback callback_fn expected type ShapedArray(float32[2]) but observed ShapedArray(float64[2]) in its return value
AutoGraph will now correctly convert conditional statements where the condition is a non-boolean static value. (#944)
Internally, statically known non-boolean predicates (such as
1) will be converted tobool:@qml.qjit(autograph=True) def workflow(x): n = 1 if n: y = x ** 2 else: y = x return y
value_and_gradwill now correctly differentiate functions with multiple arguments. Previously, attempting to differentiate functions with multiple arguments, or pass theargnumsargument, would result in an error. (#1034)@qjit def g(x, y, z): def f(x, y, z): return x * y ** 2 * jnp.sin(z) return catalyst.value_and_grad(f, argnums=[1, 2])(x, y, z)
>>> g(0.4, 0.2, 0.6) (Array(0.00903428, dtype=float64), (Array(0.0903428, dtype=float64), Array(0.01320537, dtype=float64)))
A bug is fixed in
catalyst.debug.get_cmainto support multi-dimensional arrays as function inputs. (#1003)Bug fixed when parameter annotations return strings. (#1078)
In certain cases,
jax.scipy.linalg.expmmay return incorrect numerical results when used within a qjit-compiled function. A warning will now be raised whenjax.scipy.linalg.expmis used to inform of this issue.In the meantime, we strongly recommend the catalyst.accelerate function within qjit-compiled function to call
jax.scipy.linalg.expmdirectly.@qjit def f(A): B = catalyst.accelerate(jax.scipy.linalg.expm)(A) return B
Note that this PR doesn’t actually fix the aforementioned numerical errors, and just raises a warning. (#1082)
Documentation
A page has been added to the documentation, listing devices that are Catalyst compatible. (#966)
Internal changes
Adds
catalyst.from_plxpr.from_plxprfor converting a PennyLane variant jaxpr into a Catalyst variant jaxpr. (#837)Catalyst now uses Enzyme
v0.0.130(#898)When memrefs have no identity layout, memrefs copy operations are replaced by the linalg copy operation. It does not use a runtime function but instead lowers to scf and standard dialects. It also ensures a better compatibility with Enzyme. (#917)
LLVM’s O2 optimization pipeline and Enzyme’s AD transformations are now only run in the presence of gradients, significantly improving compilation times for programs without derivatives. Similarly, LLVM’s coroutine lowering passes only run when
async_qnodesis enabled in the QJIT decorator. (#968)The function
inactive_callbackwas renamed__catalyst_inactive_callback. (#899)The function
__catalyst_inactive_callbackhas the nofree attribute. (#898)catalyst.dynamic_one_shotusespostselect_mode="pad-invalid-samples"in favour ofinterface="jax"when processing results. (#956)Callbacks now have nicer identifiers in their MLIR representation. The identifiers include the name of the Python function being called back into. (#919)
Fix tracing of
SProdoperations to bring Catalyst in line with PennyLane v0.38. (#935)After some changes in PennyLane,
Sprod.terms()returns the terms as leaves instead of a tree. This means that we need to manually trace each term and finally multiply it with the coefficients to create a Hamiltonian.The function
mitigate_with_zneaccomodates afoldinginput argument for specifying the type of circuit folding technique to be used by the error-mitigation routine (onlyglobalvalue is supported to date.) (#946)Catalyst’s implementation of Lightning Kokkos plugin has been removed in favor of Lightning’s one. (#974)
The
validate_device_capabilitiesfunction is considered obsolete. Hence, it has been removed. (#1045)
Contributors
This release contains contributions from (in alphabetical order):
Joey Carter, Alessandro Cosentino, Lillian M. A. Frederiksen, David Ittah, Josh Izaac, Christina Lee, Kunwar Maheep Singh, Mehrdad Malekmohammadi, Romain Moyard, Erick Ochoa Lopez, Mudit Pandey, Nate Stemen, Raul Torres, Tzung-Han Juang, Paul Haochen Wang,
Release 0.7.0¶
New features
Add support for accelerating classical processing via JAX with
catalyst.accelerate. (#805)Classical code that can be just-in-time compiled with JAX can now be seamlessly executed on GPUs or other accelerators with
catalyst.accelerate, right inside of QJIT-compiled functions.@accelerate(dev=jax.devices("gpu")[0]) def classical_fn(x): return jnp.sin(x) ** 2 @qjit def hybrid_fn(x): y = classical_fn(jnp.sqrt(x)) # will be executed on a GPU return jnp.cos(y)
Available devices can be retrieved via
jax.devices(). If not provided, the default value ofjax.devices()[0]as determined by JAX will be used.Catalyst callback functions, such as
pure_callback,debug.callback, anddebug.print, now all support auto-differentiation. (#706) (#782) (#822) (#834) (#882) (#907)When using callbacks that do not return any values, such as
catalyst.debug.callbackandcatalyst.debug.print, these functions are marked as ‘inactive’ and do not contribute to or affect the derivative of the function:import logging log = logging.getLogger(__name__) log.setLevel(logging.INFO) @qml.qjit @catalyst.grad def f(x): y = jnp.cos(x) catalyst.debug.print("Debug print: y = {0:.4f}", y) catalyst.debug.callback(lambda _: log.info("Value of y = %s", _))(y) return y ** 2
>>> f(0.54) INFO:__main__:Value of y = 0.8577086813638242 Debug print: y = 0.8577 array(-0.88195781)
Callbacks that do return values and may affect the qjit-compiled functions computation, such as
pure_callback, may have custom derivatives manually registered with the Catalyst compiler in order to support differentiation.This can be done via the
pure_callback.fwdandpure_callback.bwdmethods, to specify how the forwards and backwards pass (the vector-Jacobian product) of the callback should be computed:@catalyst.pure_callback def callback_fn(x) -> float: return np.sin(x[0]) * x[1] @callback_fn.fwd def callback_fn_fwd(x): # returns the evaluated function as well as residual # values that may be useful for the backwards pass return callback_fn(x), x @callback_fn.bwd def callback_fn_vjp(res, dy): # Accepts residuals from the forward pass, as well # as (one or more) cotangent vectors dy, and returns # a tuple of VJPs corresponding to each input parameter. def vjp(x, dy) -> (jax.ShapeDtypeStruct((2,), jnp.float64),): return (np.array([np.cos(x[0]) * dy * x[1], np.sin(x[0]) * dy]),) # The VJP function can also be a pure callback return catalyst.pure_callback(vjp)(res, dy) @qml.qjit @catalyst.grad def f(x): y = jnp.array([jnp.cos(x[0]), x[1]]) return jnp.sin(callback_fn(y))
>>> x = jnp.array([0.1, 0.2]) >>> f(x) array([-0.01071923, 0.82698717])
Catalyst now supports the ‘dynamic one shot’ method for simulating circuits with mid-circuit measurements, which compared to other methods, may be advantageous for circuits with many mid-circuit measurements executed for few shots. (#5617) (#798)
The dynamic one shot method evaluates dynamic circuits by executing them one shot at a time via
catalyst.vmap, sampling a dynamic execution path for each shot. This method only works for a QNode executing with finite shots, and it requires the device to support mid-circuit measurements natively.This new mode can be specified by using the
mcm_methodargument of the QNode:dev = qml.device("lightning.qubit", wires=5, shots=20) @qml.qjit(autograph=True) @qml.qnode(dev, mcm_method="one-shot") def circuit(x): for i in range(10): qml.RX(x, 0) m = catalyst.measure(0) if m: qml.RY(x ** 2, 1) x = jnp.sin(x) return qml.expval(qml.Z(1))
Catalyst’s existing method for simulating mid-circuit measurements remains available via
mcm_method="single-branch-statistics".When using
mcm_method="one-shot", thepostselect_modekeyword argument can also be used to specify whether the returned result should includeshots-number of postselected measurements ("fill-shots"), or whether results should include all results, including invalid postselections ("hw_like"):@qml.qjit @qml.qnode(dev, mcm_method="one-shot", postselect_mode="hw-like") def func(x): qml.RX(x, wires=0) m_0 = catalyst.measure(0, postselect=1) return qml.sample(wires=0)
>>> res = func(0.9) >>> res array([-2147483648, -2147483648, 1, -2147483648, -2147483648, -2147483648, -2147483648, 1, -2147483648, -2147483648, -2147483648, -2147483648, 1, -2147483648, -2147483648, -2147483648, -2147483648, -2147483648, -2147483648, -2147483648]) >>> jnp.delete(res, jnp.where(res == np.iinfo(np.int32).min)[0]) Array([1, 1, 1], dtype=int64)
Note that invalid shots will not be discarded, but will be replaced by
np.iinfo(np.int32).min. They will not be used for processing final results (like expectation values), but they will appear in the output of QNodes that return samples directly.For more details, see the dynamic quantum circuit documentation.
Catalyst now has support for returning
qml.sample(m)wheremis the result of a mid-circuit measurement. (#731)When used with
mcm_method="one-shot", this will return an array with one measurement result for each shot:dev = qml.device("lightning.qubit", wires=2, shots=10) @qml.qjit @qml.qnode(dev, mcm_method="one-shot") def func(x): qml.RX(x, wires=0) m = catalyst.measure(0) qml.RX(x ** 2, wires=0) return qml.sample(m), qml.expval(qml.PauliZ(0))
>>> func(0.9) (array([0, 1, 0, 0, 0, 0, 1, 0, 0, 0]), array(0.4))
In
mcm_method="single-branch-statistics"mode, it will be equivalent to returningmdirectly from the quantum function — that is, it will return a single boolean corresponding to the measurement in the branch selected:@qml.qjit @qml.qnode(dev, mcm_method="single-branch-statistics") def func(x): qml.RX(x, wires=0) m = catalyst.measure(0) qml.RX(x ** 2, wires=0) return qml.sample(m), qml.expval(qml.PauliZ(0))
>>> func(0.9) (array(False), array(0.8))
A new function,
catalyst.value_and_grad, returns both the result of a function and its gradient with a single forward and backwards pass. (#804) (#859)This can be more efficient, and reduce overall quantum executions, compared to separately executing the function and then computing its gradient.
For example:
dev = qml.device("lightning.qubit", wires=3) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) qml.RX(x, wires=2) return qml.probs() @qml.qjit @catalyst.value_and_grad def cost(x): return jnp.sum(jnp.cos(circuit(x)))
>>> cost(0.543) (array(7.64695856), array(0.33413963))
Autograph now supports single index JAX array assignments (#717)
When using Autograph, syntax of the form
x[i] = ywhereiis a single integer will now be automatically converted to the JAX equivalent ofx = x.at(i).set(y):@qml.qjit(autograph=True) def f(array): result = jnp.ones(array.shape, dtype=array.dtype) for i, x in enumerate(array): result[i] = result[i] + x * 3 return result
>>> f(jnp.array([-0.1, 0.12, 0.43, 0.54])) array([0.7 , 1.36, 2.29, 2.62])
Catalyst now supports dynamically-shaped arrays in control-flow primitives. Arrays with dynamic shapes can now be used with
for_loop,while_loop, andcondprimitives. (#775) (#777) (#830)@qjit def f(shape): a = jnp.ones([shape], dtype=float) @for_loop(0, 10, 2) def loop(i, a): return a + i return loop(a)
>>> f(3) array([21., 21., 21.])
Support has been added for disabling Autograph for specific functions. (#705) (#710)
The decorator
catalyst.disable_autographallows one to disable Autograph from auto-converting specific external functions when called within a qjit-compiled function withautograph=True:def approximate_e(n): num = 1. fac = 1. for i in range(1, n + 1): fac *= i num += 1. / fac return num @qml.qjit(autograph=True) def g(x: float, N: int): for i in range(N): x = x + catalyst.disable_autograph(approximate_e)(10) / x ** i return x
>>> g(0.1, 10) array(4.02997319)
Note that for Autograph to be disabled, the decorated function must be defined outside the qjit-compiled function. If it is defined within the qjit-compiled function, it will continue to be converted with Autograph.
In addition, Autograph can also be disabled for all externally defined functions within a qjit-compiled function via the context manager syntax:
@qml.qjit(autograph=True) def g(x: float, N: int): for i in range(N): with catalyst.disable_autograph: x = x + approximate_e(10) / x ** i return x
Support for including a list of (sub)modules to be allowlisted for autograph conversion. (#725)
Although library code is not meant to be targeted by Autograph conversion, it sometimes make sense to enable it for specific submodules that might benefit from such conversion:
@qjit(autograph=True, autograph_include=["excluded_module.submodule"]) def f(x): return excluded_module.submodule.func(x)
For example, this might be useful if importing functionality from PennyLane (such as a transform or decomposition), and would like to have Autograph capture and convert associated control flow.
Controlled operations that do not have a matrix representation defined are now supported via applying PennyLane’s decomposition. (#831)
@qjit @qml.qnode(qml.device("lightning.qubit", wires=2)) def circuit(): qml.Hadamard(0) qml.ctrl(qml.TrotterProduct(H, time=2.4, order=2), control=[1]) return qml.state()
Catalyst has now officially support on Linux aarch64, with pre-built binaries available on PyPI; simply
pip install pennylane-catalyston Linux aarch64 systems. (#767)
Improvements
Validation is now performed for observables and operations to ensure that provided circuits are compatible with the devices for execution. (#626) (#783)
dev = qml.device("lightning.qubit", wires=2, shots=10000) @qjit @qml.qnode(dev) def circuit(x): qml.Hadamard(wires=0) qml.CRX(x, wires=[0, 1]) return qml.var(qml.PauliZ(1))
>>> circuit(0.43) DifferentiableCompileError: Variance returns are forbidden in gradients
Catalyst’s adjoint and ctrl methods are now fully compatible with the PennyLane equivalent when applied to a single Operator. This should lead to improved compatibility with PennyLane library code, as well when reusing quantum functions with both Catalyst and PennyLane. (#768) (#771) (#802)
Controlled operations defined via specialized classes (like
ToffoliorControlledQubitUnitary) are now implemented as controlled versions of their base operation if the device supports it. In particular,MultiControlledXis no longer executed as aQubitUnitarywith Lightning. (#792)The Catalyst frontend now supports Python logging through PennyLane’s
qml.loggingmodule. For more details, please see the logging documentation. (#660)Catalyst now performs a stricter validation of the wire requirements for devices. In particular, only integer, continuous wire labels starting at 0 are allowed. (#784)
Catalyst no longer disallows quantum circuits with 0 qubits. (#784)
Added support for
IsingZZas a native gate in Catalyst. Previously, the IsingZZ gate would be decomposed into a CNOT and RZ gates, even if a device supported it. (#730)All decorators in Catalyst, including
vmap,qjit,mitigate_with_zne, as well as gradient decoratorsgrad,jacobian,jvp, andvjp, can now be used both with and without keyword arguments as a decorator without the need forfunctools.partial: (#758) (#761) (#762) (#763)@qjit @grad(method="fd") def fn1(x): return x ** 2 @qjit(autograph=True) @grad def fn2(x): return jnp.sin(x)
>>> fn1(0.43) array(0.8600001) >>> fn2(0.12) array(0.99280864)
The built-in instrumentation with
detailedoutput will no longer report the cumulative time for MLIR pipelines, since the cumulative time was being reported as just another step alongside individual timings for each pipeline. (#772)Raise a better error message when no shots are specified and
qml.sampleorqml.countsis used. (#786)The finite difference method for differentiation is now always allowed, even on functions with mid-circuit measurements, callbacks without custom derivates, or other operations that cannot be differentiated via traditional autodiff. (#789)
A
non_commuting_observablesflag has been added to the device TOML schema, indicating whether or not the device supports measuring non-commuting observables. Iffalse, non-commuting measurements will be split into multiple executions. (#821)The underlying PennyLane
Operationobjects forcond,for_loop, andwhile_loopcan now be accessed directly viabody_function.operation. (#711)This can be beneficial when, among other things, writing transforms without using the queuing mechanism:
@qml.transform def my_quantum_transform(tape): ops = tape.operations.copy() @for_loop(0, 4, 1) def f(i, sum): qml.Hadamard(0) return sum+1 res = f(0) ops.append(f.operation) # This is now supported! def post_processing_fn(results): return results modified_tape = qml.tape.QuantumTape(ops, tape.measurements) print(res) print(modified_tape.operations) return [modified_tape], post_processing_fn @qml.qjit @my_quantum_transform @qml.qnode(qml.device("lightning.qubit", wires=2)) def main(): qml.Hadamard(0) return qml.probs()
>>> main() Traced<ShapedArray(int64[], weak_type=True)>with<DynamicJaxprTrace(level=2/1)> [Hadamard(wires=[0]), ForLoop(tapes=[[Hadamard(wires=[0])]])] (array([0.5, 0. , 0.5, 0. ]),)
Breaking changes
Binary distributions for Linux are now based on
manylinux_2_28instead ofmanylinux_2014. As a result, Catalyst will only be compatible on systems withglibcversions2.28and above (e.g., Ubuntu 20.04 and above). (#663)
Bug fixes
Functions that have been annotated with return type annotations will now correctly compile with
@qjit. (#751)An issue in the Lightning backend for the Catalyst runtime has been fixed that would only compute approximate probabilities when implementing mid-circuit measurements. As a result, low shot numbers would lead to unexpected behaviours or projections on zero probability states. Probabilities for mid-circuit measurements are now always computed analytically. (#801)
The Catalyst runtime now raises an error if a qubit is accessed out of bounds from the allocated register. (#784)
jax.scipy.linalg.expmis now supported within qjit-compiled functions. (#733) (#752)This required correctly linking openblas routines necessary for
jax.scipy.linalg.expm. In this bug fix, four openblas routines were newly linked and are now discoverable bystablehlo.custom_call@<blas_routine>. They areblas_dtrsm,blas_ztrsm,lapack_dgetrf,lapack_zgetrf.Fixes a bug where QNodes that contained
QubitUnitarywith a complex matrix would error during gradient computation. (#778)Callbacks can now return types which can be flattened and unflattened. (#812)
catalyst.qjitandcatalyst.gradnow work correctly on functions that have been wrapped withfunctools.partial. (#820)
Internal changes
Catalyst uses the
collapsemethod of Lightning simulators inMeasureto select a state vector branch and normalize. (#801)Measurement process primitives for Catalyst’s JAXPR representation now have a standardized call signature so that
shotsandshapecan both be provided as keyword arguments. (#790)The
QCtrlclass in Catalyst has been renamed toHybridCtrl, indicating its capability to contain a nested scope of both quantum and classical operations. Usingctrlon a single operation will now directly dispatch to the equivalent PennyLane class. (#771)The
Adjointclass in Catalyst has been renamed toHybridAdjoint, indicating its capability to contain a nested scope of both quantum and classical operations. Usingadjointon a single operation will now directly dispatch to the equivalent PennyLane class. (#768) (#802)Add support to use a locally cloned PennyLane Lightning repository with the runtime. (#732)
The
qjit_device.pyandpreprocessing.pymodules have been refactored into the sub-packagecatalyst.device. (#721)The
ag_autograph.pyandautograph.pymodules have been refactored into the sub-packagecatalyst.autograph. (#722)Callback refactoring. This refactoring creates the classes
FlatCallableandMemrefCallable. (#742)The
FlatCallableclass is aCallablethat is initialized by providing some parameters and kwparameters that match the the expected shapes that will be received at the callsite. Instead of taking shaped*argsand**kwargs, it receives flattened arguments. The flattened arguments are unflattened with the shapes with which the function was initialized. TheFlatCallablereturn values will allways be flattened before returning to the caller.The
MemrefCallableis a subclass ofFlatCallable. It takes a result type parameter during initialization that corresponds to the expected return type. This class is expected to be called only from the Catalyst runtime. It expects all arguments to bevoid*to memrefs. Thesevoid*are casted to MemrefStructDescriptors using ctypes, numpy arrays, and finally jax arrays. These flat jax arrays are then sent to theFlatCallable.MemrefCallableis again expected to be called only from within the Catalyst runtime. And the return values match those expected by Catalyst runtime.This separation allows for a better separation of concerns, provides a nicer interface and allows for multiple
MemrefCallableto be defined for a single callback, which is necessary for custom gradient ofpure_callbacks.A new
catalyst::gradient::GradientOpInterfaceis available when querying the gradient method in the mlir c++ api. (#800)catalyst::gradient::GradOp,ValueAndGradOp,JVPOp, andVJPOpnow inherits traits in this newGradientOpInterface. The supported attributes are nowgetMethod(),getCallee(),getDiffArgIndices(),getDiffArgIndicesAttr(),getFiniteDiffParam(), andgetFiniteDiffParamAttr().There are operations that could potentially be used as
GradOp,ValueAndGradOp,JVPOporVJPOp. When trying to get the gradient method, instead of doingauto gradOp = dyn_cast<GradOp>(op); auto jvpOp = dyn_cast<JVPOp>(op); auto vjpOp = dyn_cast<VJPOp>(op); llvm::StringRef MethodName; if (gradOp) MethodName = gradOp.getMethod(); else if (jvpOp) MethodName = jvpOp.getMethod(); else if (vjpOp) MethodName = vjpOp.getMethod();
to identify which op it actually is and protect against segfaults (calling
nullptr.getMethod()), in the new interface we just doauto gradOpInterface = cast<GradientOpInterface>(op); llvm::StringRef MethodName = gradOpInterface.getMethod();
Another advantage is that any concrete gradient operation object can behave like a
GradientOpInterface:GradOp op; // or ValueAndGradOp op, ... auto foo = [](GradientOpInterface op){ llvm::errs() << op.getCallee(); }; foo(op); // this works!
Finally, concrete op specific methods can still be called by “reinterpret”-casting the interface back to a concrete op (provided the concrete op type is correct):
auto foo = [](GradientOpInterface op){ size_t numGradients = cast<ValueAndGradOp>(&op)->getGradients().size(); }; ValueAndGradOp op; foo(op); // this works!
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, Lillian M.A. Frederiksen, David Ittah, Christina Lee, Erick Ochoa, Haochen Paul Wang, Lee James O’Riordan, Mehrdad Malekmohammadi, Vincent Michaud-Rioux, Mudit Pandey, Raul Torres, Sergei Mironov, Tzung-Han Juang.
Release 0.6.0¶
New features
Catalyst now supports externally hosted callbacks with parameters and return values within qjit-compiled code. This provides the ability to insert native Python code into any qjit-compiled function, allowing for the capability to include subroutines that do not yet support qjit-compilation and enhancing the debugging experience. (#540) (#596) (#610) (#650) (#649) (#661) (#686) (#689)
The following two callback functions are available:
catalyst.pure_callbacksupports callbacks of pure functions. That is, functions with no side-effects that accept parameters and return values. However, the return type and shape of the function must be known in advance, and is provided as a type signature.@pure_callback def callback_fn(x) -> float: # here we call non-JAX compatible code, such # as standard NumPy return np.sin(x) @qjit def fn(x): return jnp.cos(callback_fn(x ** 2))
>>> fn(0.654) array(0.9151995)
catalyst.debug.callbacksupports callbacks of functions with no return values. This makes it an easy entry point for debugging, for example via printing or logging at runtime.@catalyst.debug.callback def callback_fn(y): print("Value of y =", y) @qjit def fn(x): y = jnp.sin(x) callback_fn(y) return y ** 2
>>> fn(0.54) Value of y = 0.5141359916531132 array(0.26433582) >>> fn(1.52) Value of y = 0.998710143975583 array(0.99742195)
Note that callbacks do not currently support differentiation, and cannot be used inside functions that
catalyst.gradis applied to.More flexible runtime printing through support for format strings. (#621)
The
catalyst.debug.printfunction has been updated to support Python-like format strings:@qjit def cir(a, b, c): debug.print("{c} {b} {a}", a=a, b=b, c=c)
>>> cir(1, 2, 3) 3 2 1
Note that previous functionality of the print function to print out memory reference information of variables has been moved to
catalyst.debug.print_memref.Catalyst now supports QNodes that execute on Oxford Quantum Circuits (OQC) superconducting hardware, via OQC Cloud. (#578) (#579) (#691)
To use OQC Cloud with Catalyst, simply ensure your credentials are set as environment variables, and load the
oqc.clouddevice to be used within your qjit-compiled workflows.import os os.environ["OQC_EMAIL"] = "your_email" os.environ["OQC_PASSWORD"] = "your_password" os.environ["OQC_URL"] = "oqc_url" dev = qml.device("oqc.cloud", backend="lucy", shots=2012, wires=2) @qjit @qml.qnode(dev) def circuit(a: float): qml.Hadamard(0) qml.CNOT(wires=[0, 1]) qml.RX(wires=0) return qml.counts(wires=[0, 1]) print(circuit(0.2))
Catalyst now ships with an instrumentation feature allowing to explore what steps are run during compilation and execution, and for how long. (#528) (#597)
Instrumentation can be enabled from the frontend with the
catalyst.debug.instrumentationcontext manager:>>> @qjit ... def expensive_function(a, b): ... return a + b >>> with debug.instrumentation("session_name", detailed=False): ... expensive_function(1, 2) [DIAGNOSTICS] Running capture walltime: 3.299 ms cputime: 3.294 ms programsize: 0 lines [DIAGNOSTICS] Running generate_ir walltime: 4.228 ms cputime: 4.225 ms programsize: 14 lines [DIAGNOSTICS] Running compile walltime: 57.182 ms cputime: 12.109 ms programsize: 121 lines [DIAGNOSTICS] Running run walltime: 1.075 ms cputime: 1.072 ms
The results will be appended to the provided file if the
filenameattribute is set, and printed to the console otherwise. The flagdetaileddetermines whether individual steps in the compiler and runtime are instrumented, or whether only high-level steps like “program capture” and “compilation” are reported.Measurements currently include wall time, CPU time, and (intermediate) program size.
Improvements
AutoGraph now supports return statements inside conditionals in qjit-compiled functions. (#583)
For example, the following pattern is now supported, as long as all return values have the same type:
@qjit(autograph=True) def fn(x): if x > 0: return jnp.sin(x) return jnp.cos(x)
>>> fn(0.1) array(0.09983342) >>> fn(-0.1) array(0.99500417)
This support extends to quantum circuits:
dev = qml.device("lightning.qubit", wires=1) @qjit(autograph=True) @qml.qnode(dev) def f(x: float): qml.RX(x, wires=0) m = catalyst.measure(0) if not m: return m, qml.expval(qml.PauliZ(0)) qml.RX(x ** 2, wires=0) return m, qml.expval(qml.PauliZ(0))
>>> f(1.4) (array(False), array(1.)) >>> f(1.4) (array(True), array(0.37945176))
Note that returning results with different types or shapes within the same function, such as different observables or differently shaped arrays, is not possible.
Errors are now raised at compile time if the gradient of an unsupported function is requested. (#204)
At the moment,
CompileErrorexceptions will be raised if at compile time it is found that code reachable from the gradient operation contains either a mid-circuit measurement, a callback, or a JAX-style custom call (which happens through the mitigation operation as well as certain JAX operations).Catalyst now supports devices built from the new PennyLane device API. (#565) (#598) (#599) (#636) (#638) (#664) (#687)
When using the new device API, Catalyst will discard the preprocessing from the original device, replacing it with Catalyst-specific preprocessing based on the TOML file provided by the device. Catalyst also requires that provided devices specify their wires upfront.
A new compiler optimization that removes redundant chains of self inverse operations has been added. This is done within a new MLIR pass called
remove-chained-self-inverse. Currently we only match redundant Hadamard operations, but the list of supported operations can be expanded. (#630)The
catalyst.measureoperation is now more lenient in the accepted type for thewiresparameter. In addition to a scalar, a 1D array is also accepted as long as it only contains one element. (#623)For example, the following is now supported:
catalyst.measure(wires=jnp.array([0]))
The compilation & execution of
@qjitcompiled functions can now be aborted using an interrupt signal (SIGINT). This includes usingCTRL-Cfrom a command line and theInterruptbutton in a Jupyter Notebook. (#642)The Catalyst Amazon Braket support has been updated to work with the latest version of the Amazon Braket PennyLane plugin (v1.25.0) and Amazon Braket Python SDK (v1.73.3) (#620) (#672) (#673)
Note that with this update, all declared qubits in a submitted program will always be measured, even if specific qubits were never used.
An updated quantum device specification format, TOML schema v2, is now supported by Catalyst. This allows device authors to specify properties such as native quantum control support, gate invertibility, and differentiability on a per-operation level. (#554)
For more details on the new TOML schema, please refer to the custom devices documentation.
An exception is now raised when OpenBLAS cannot be found by Catalyst during compilation. (#643)
Breaking changes
qml.sampleandqml.countsnow produce integer arrays for the sample array and basis state array when used without observables. (#648)The endianness of counts in Catalyst now matches the convention of PennyLane. (#601)
catalyst.debug.printno longer supports thememrefkeyword argument. Please usecatalyst.debug.print_memrefinstead. (#621)
Bug fixes
The QNode argument
diff_method=Noneis now supported for QNodes within a qjit-compiled function. (#658)A bug has been fixed where the C++ compiler driver was incorrectly being triggered twice. (#594)
Programs with
jnp.reshapeno longer fail. (#592)A bug in the quantum adjoint routine in the compiler has been fixed, which didn’t take into account control wires on operations in all instances. (#591)
A bug in the test suite causing stochastic autograph test failures has been fixed. (#652)
Running Catalyst tests should no longer raise
ResourceWarningfrom the use oftempfile.TemporaryDirectory. (#676)Raises an exception if the user has an incompatible CUDA Quantum version installed. (#707)
Internal changes
The deprecated
@qfuncdecorator, in use mainly by the LIT test suite, has been removed. (#679)Catalyst now publishes a revision string under
catalyst.__revision__, in addition to the existingcatalyst.__version__string. The revision contains the Git commit hash of the repository at the time of packaging, or for editable installations the active commit hash at the time of package import. (#560)The Python interpreter is now a shared resource across the runtime. (#615)
This change allows any part of the runtime to start executing Python code through pybind.
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah, Romain Moyard, Sergei Mironov, Erick Ochoa Lopez, Lee James O’Riordan, Muzammiluddin Syed.
Release 0.5.0¶
New features
Catalyst now provides a QJIT compatible
catalyst.vmapfunction, which makes it even easier to modify functions to map over inputs with additional batch dimensions. (#497) (#569)When working with tensor/array frameworks in Python, it can be important to ensure that code is written to minimize usage of Python for loops (which can be slow and inefficient), and instead push as much of the computation through to the array manipulation library, by taking advantage of extra batch dimensions.
For example, consider the following QNode:
dev = qml.device("lightning.qubit", wires=1) @qml.qnode(dev) def circuit(x, y): qml.RX(jnp.pi * x[0] + y, wires=0) qml.RY(x[1] ** 2, wires=0) qml.RX(x[1] * x[2], wires=0) return qml.expval(qml.PauliZ(0))
>>> circuit(jnp.array([0.1, 0.2, 0.3]), jnp.pi) Array(-0.93005586, dtype=float64)
We can use
catalyst.vmapto introduce additional batch dimensions to our input arguments, without needing to use a Python for loop:>>> x = jnp.array([[0.1, 0.2, 0.3], ... [0.4, 0.5, 0.6], ... [0.7, 0.8, 0.9]]) >>> y = jnp.array([jnp.pi, jnp.pi / 2, jnp.pi / 4]) >>> qjit(vmap(cost))(x, y) array([-0.93005586, -0.97165424, -0.6987465 ])
catalyst.vmap()has been implemented to match the same behaviour ofjax.vmap, so should be a drop-in replacement in most cases. Under-the-hood, it is automatically inserting Catalyst-compatible for loops, which will be compiled and executed outside of Python for increased performance.Catalyst now supports compiling and executing QJIT-compiled QNodes using the CUDA Quantum compiler toolchain. (#477) (#536) (#547)
Simply import the CUDA Quantum
@cudaqjitdecorator to use this functionality:from catalyst.cuda import cudaqjit
Or, if using Catalyst from PennyLane, simply specify
@qml.qjit(compiler="cuda_quantum").The following devices are available when compiling with CUDA Quantum:
softwareq.qpp: a modern C++ state-vector simulatornvidia.custatevec: The NVIDIA CuStateVec GPU simulator (with support for multi-gpu)nvidia.cutensornet: The NVIDIA CuTensorNet GPU simulator (with support for matrix product state)
For example:
dev = qml.device("softwareq.qpp", wires=2) @cudaqjit @qml.qnode(dev) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliY(0))
>>> circuit(jnp.array([0.5, 1.4])) -0.47244976756708373
Note that CUDA Quantum compilation currently does not have feature parity with Catalyst compilation; in particular, AutoGraph, control flow, differentiation, and various measurement statistics (such as probabilities and variance) are not yet supported. Classical code support is also limited.
Catalyst now supports just-in-time compilation of static (compile-time constant) arguments. (#476) (#550)
The
@qjitdecorator takes a new argumentstatic_argnums, which specifies positional arguments of the decorated function should be treated as compile-time static arguments.This allows any hashable Python object to be passed to the function during compilation; the function will only be re-compiled if the hash value of the static arguments change. Otherwise, re-using previous static argument values will result in no re-compilation.
@qjit(static_argnums=(1,)) def f(x, y): print(f"Compiling with y={y}") return x + y
>>> f(0.5, 0.3) Compiling with y=0.3 array(0.8) >>> f(0.1, 0.3) # no re-compilation occurs array(0.4) >>> f(0.1, 0.4) # y changes, re-compilation Compiling with y=0.4 array(0.5)
This functionality can be used to support passing arbitrary Python objects to QJIT-compiled functions, as long as they are hashable:
from dataclasses import dataclass @dataclass class MyClass: val: int def __hash__(self): return hash(str(self)) @qjit(static_argnums=(1,)) def f(x: int, y: MyClass): return x + y.val
>>> f(1, MyClass(5)) array(6) >>> f(1, MyClass(6)) # re-compilation array(7) >>> f(2, MyClass(5)) # no re-compilation array(7)
Mid-circuit measurements now support post-selection and qubit reset when used with the Lightning simulators. (#491) (#507)
To specify post-selection, simply pass the
postselectargument to thecatalyst.measurefunction:dev = qml.device("lightning.qubit", wires=1) @qjit @qml.qnode(dev) def f(): qml.Hadamard(0) m = measure(0, postselect=1) return qml.expval(qml.PauliZ(0))
Likewise, to reset a wire after mid-circuit measurement, simply specify
reset=True:dev = qml.device("lightning.qubit", wires=1) @qjit @qml.qnode(dev) def f(): qml.Hadamard(0) m = measure(0, reset=True) return qml.expval(qml.PauliZ(0))
Improvements
Catalyst now supports Python 3.12 (#532)
The JAX version used by Catalyst has been updated to
v0.4.23. (#428)Catalyst now supports the
qml.GlobalPhaseoperation. (#563)Native support for
qml.PSWAPandqml.ISWAPgates on Amazon Braket devices has been added. (#458)Specifically, a circuit like
dev = qml.device("braket.local.qubit", wires=2, shots=100) @qjit @qml.qnode(dev) def f(x: float): qml.Hadamard(0) qml.PSWAP(x, wires=[0, 1]) qml.ISWAP(wires=[1, 0]) return qml.probs()
Add support for
GlobalPhasegate in the runtime. (#563)would no longer decompose the
PSWAPandISWAPgates.The
qml.BlockEncodeoperator is now supported with Catalyst. (#483)Catalyst no longer relies on a TensorFlow installation for its AutoGraph functionality. Instead, the standalone
diastatic-maltpackage is used and automatically installed as a dependency. (#401)The
@qjitdecorator will remember previously compiled functions when the PyTree metadata of arguments changes, in addition to also remembering compiled functions when static arguments change. (#522)The following example will no longer trigger a third compilation:
@qjit def func(x): print("compiling") return x
>>> func([1,]); # list compiling >>> func((2,)); # tuple compiling >>> func([3,]); # list
Note however that in order to keep overheads low, changing the argument type or shape (in a promotion incompatible way) may override a previously stored function (with identical PyTree metadata and static argument values):
@qjit def func(x): print("compiling") return x
>>> func(jnp.array(1)); # scalar compiling >>> func(jnp.array([2.])); # 1-D array compiling >>> func(jnp.array(3)); # scalar compiling
Catalyst gradient functions (
grad,jacobian,vjp, andjvp) now support being applied to functions that use (nested) container types as inputs and outputs. This includes lists and dictionaries, as well as any data structure implementing the PyTree protocol. (#500) (#501) (#508) (#549)dev = qml.device("lightning.qubit", wires=1) @qml.qnode(dev) def circuit(phi, psi): qml.RY(phi, wires=0) qml.RX(psi, wires=0) return [{"expval0": qml.expval(qml.PauliZ(0))}, qml.expval(qml.PauliZ(0))] psi = 0.1 phi = 0.2
>>> qjit(jacobian(circuit, argnum=[0, 1]))(psi, phi) [{'expval0': (array(-0.0978434), array(-0.19767681))}, (array(-0.0978434), array(-0.19767681))]
Support has been added for linear algebra functions which depend on computing the eigenvalues of symmetric matrices, such as
np.sqrt_matrix(). (#488)For example, you can compile
qml.math.sqrt_matrix:@qml.qjit def workflow(A): B = qml.math.sqrt_matrix(A) return B @ A
Internally, this involves support for lowering the eigenvectors/values computation lapack method
lapack_dsyevdviastablehlo.custom_call.Additional debugging functions are now available in the
catalyst.debugdirectory. (#529) (#522)This includes:
filter_static_args(args, static_argnums)to remove static values from arguments using the provided index list.get_cmain(fn, *args)to return a C program that calls a jitted function with the provided arguments.print_compilation_stage(fn, stage)to print one of the recorded compilation stages for a JIT-compiled function.
For more details, please see the
catalyst.debugdocumentation.Remove redundant copies of TOML files for
lightning.kokkosandlightning.qubit. (#472)lightning.kokkosandlightning.qubitnow ship with their own TOML file. As such, we use the TOML file provided by them.Capturing quantum circuits with many gates prior to compilation is now quadratically faster (up to a factor), by removing
qextract_pandqinst_pfrom forced-order primitives. (#469)Update
AllocateQubitandAllocateQubitsinLightningKokkosSimulatorto preserve the current state-vector before qubit re-allocations in the runtime dynamic qubits management. (#479)The PennyLane custom compiler entry point name convention has changed, necessitating a change to the Catalyst entry points. (#493)
Breaking changes
Catalyst gradient functions now match the Jax convention for the returned axes of gradients, Jacobians, VJPs, and JVPs. As a result, the returned tensor shape from various Catalyst gradient functions may differ compared to previous versions of Catalyst. (#500) (#501) (#508)
The Catalyst Python frontend has been partially refactored. The impact on user-facing functionality is minimal, but the location of certain classes and methods used by the package may have changed. (#529) (#522)
The following changes have been made:
Some debug methods and features on the QJIT class have been turned into free functions and moved to the
catalyst.debugmodule, which will now appear in the public documention. This includes compiling a program from IR, obtaining a C program to invoke a compiled function from, and printing fine-grained MLIR compilation stages.The
compilation_pipelines.pymodule has been renamed tojit.py, and certain functionality has been moved out (see following items).A new module
compiled_functions.pynow manages low-level access to compiled functions.A new module
tracing/type_signatures.pyhandles functionality related managing arguments and type signatures during the tracing process.The
contexts.pymodule has been moved fromutilsto the newtracingsub-module.
Internal changes
Changes to the runtime QIR API and dependencies, to avoid symbol conflicts with other libraries that utilize QIR. (#464) (#470)
The existing Catalyst runtime implements QIR as a library that can be linked against a QIR module. This works great when Catalyst is the only implementor of QIR, however it may generate symbol conflicts when used alongside other QIR implementations.
To avoid this, two changes were necessary:
The Catalyst runtime now has a different API from QIR instructions.
The runtime has been modified such that QIR instructions are lowered to functions where the
__quantum__part of the function name is replaced with__catalyst__. This prevents the possibility of symbol conflicts with other libraries that implement QIR as a library.The Catalyst runtime no longer depends on QIR runner’s stdlib.
We no longer depend nor link against QIR runner’s stdlib. By linking against QIR runner’s stdlib, some definitions persisted that may be different than ones used by third party implementors. To prevent symbol conflicts QIR runner’s stdlib was removed and is no longer linked against. As a result, the following functions are now defined and implemented in Catalyst’s runtime:
int64_t __catalyst__rt__array_get_size_1d(QirArray *)int8_t *__catalyst__rt__array_get_element_ptr_1d(QirArray *, int64_t)
and the following functions were removed since the frontend does not generate them
QirString *__catalyst__rt__qubit_to_string(QUBIT *)QirString *__catalyst__rt__result_to_string(RESULT *)
Fix an issue when no qubit number was specified for the
qinstprimitive. The primitive now correctly deduces the number of qubits when no gate parameters are present. This change is not user facing. (#496)
Bug fixes
Fixed a bug where differentiation of sliced arrays would result in an error. (#552)
def f(x): return jax.numpy.sum(x[::2]) x = jax.numpy.array([0.1, 0.2, 0.3, 0.4])
>>> catalyst.qjit(catalyst.grad(f))(x) [1. 0. 1. 0.]
Fixed a bug where quantum control applied to a subcircuit was not correctly mapping wires, and the wires in the nested region remained unchanged. (#555)
Catalyst will no longer print a warning that recompilation is triggered when a
@qjitdecorated function with no arguments is invoke without having been compiled first, for example via the use oftarget="mlir". (#522)Fixes a bug in the configuration of dynamic shaped arrays that would cause certain program to error with
TypeError: cannot unpack non-iterable ShapedArray object. (#526)This is fixed by replacing the code which updates the
JAX_DYNAMIC_SHAPESoption with atransient_jax_config()context manager which temporarily sets the value ofJAX_DYNAMIC_SHAPESto True and then restores the original configuration value following the yield. The context manager is used bytrace_to_jaxpr()andlower_jaxpr_to_mlir().Exceptions encountered in the runtime when using the
@qjitoptionasync_qnodes=Tuewill now be properly propagated to the frontend. (#447) (#510)This is done by:
changeing
llvm.calltollvm.invokesetting async runtime tokens and values to be errors
deallocating live tokens and values
Fixes a bug when computing gradients with the indexing/slicing, by fixing the scatter operation lowering when
updatedWindowsDimis empty. (#475)Fix the issue in
LightningKokkos::AllocateQubitswith allocating too many qubit IDs on qubit re-allocation. (#473)Fixed an issue where wires was incorrectly set as
<Wires = [<WiresEnum.AnyWires: -1>]>when usingcatalyst.adjointandcatalyst.ctrl, by adding awiresproperty to these operations. (#480)Fix the issue with multiple lapack symbol definitions in the compiled program by updating the
stablehlo.custom_callconversion pass. (#488)
Contributors
This release contains contributions from (in alphabetical order):
Mikhail Andrenkov, Ali Asadi, David Ittah, Tzung-Han Juang, Erick Ochoa Lopez, Romain Moyard, Raul Torres, Haochen Paul Wang.
Release 0.4.1¶
Improvements
Catalyst wheels are now packaged with OpenMP and ZStd, which avoids installing additional requirements separately in order to use pre-packaged Catalyst binaries. (#457) (#478)
Note that OpenMP support for the
lightning.kokkosbackend has been disabled on macOS x86_64, due to memory issues in the computation of Lightning’s adjoint-jacobian in the presence of multiple OMP threads.
Bug fixes
Resolve an infinite recursion in the decomposition of the
Controlledoperator whenever computing a Unitary matrix for the operator fails. (#468)Resolve a failure to generate gradient code for specific input circuits. (#439)
In this case,
jnp.modwas used to compute wire values in a for loop, which prevented the gradient architecture from fully separating quantum and classical code. The following program is now supported:@qjit @grad @qml.qnode(dev) def f(x): def cnot_loop(j): qml.CNOT(wires=[j, jnp.mod((j + 1), 4)]) for_loop(0, 4, 1)(cnot_loop)() return qml.expval(qml.PauliZ(0))
Resolve unpredictable behaviour when importing libraries that share Catalyst’s LLVM dependency (e.g. TensorFlow). In some cases, both packages exporting the same symbols from their shared libraries can lead to process crashes and other unpredictable behaviour, since the wrong functions can be called if both libraries are loaded in the current process. The fix involves building shared libraries with hidden (macOS) or protected (linux) symbol visibility by default, exporting only what is necessary. (#465)
Resolve a failure to find the SciPy OpenBLAS library when running Catalyst, due to a different SciPy version being used to build Catalyst than to run it. (#471)
Resolve a memory leak in the runtime stemming from missing calls to device destructors at the end of programs. (#446)
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah.
Release 0.4.0¶
New features
Catalyst is now accessible directly within the PennyLane user interface, once Catalyst is installed, allowing easy access to Catalyst just-in-time functionality.
Through the use of the
qml.qjitdecorator, entire workflows can be JIT compiled down to a machine binary on first-function execution, including both quantum and classical processing. Subsequent calls to the compiled function will execute the previously-compiled binary, resulting in significant performance improvements.import pennylane as qml dev = qml.device("lightning.qubit", wires=2) @qml.qjit @qml.qnode(dev) def circuit(theta): qml.Hadamard(wires=0) qml.RX(theta, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(wires=1))
>>> circuit(0.5) # the first call, compilation occurs here array(0.) >>> circuit(0.5) # the precompiled quantum function is called array(0.)
Currently, PennyLane supports the Catalyst hybrid compiler with the
qml.qjitdecorator, which directly aliases Catalyst’scatalyst.qjit.In addition to the above
qml.qjitintegration, the following native PennyLane functions can now be used with theqjitdecorator:qml.adjoint,qml.ctrl,qml.grad,qml.jacobian,qml.vjp,qml.jvp, andqml.adjoint,qml.while_loop,qml.for_loop,qml.cond. These will alias to the corresponding Catalyst functions when used within aqjitcontext.For more details on these functions, please refer to the PennyLane compiler documentation and compiler module documentation.
Just-in-time compiled functions now support asynchronuous execution of QNodes. (#374) (#381) (#420) (#424) (#433)
Simply specify
async_qnodes=Truewhen using the@qjitdecorator to enable the async execution of QNodes. Currently, asynchronous execution is only supported bylightning.qubitandlightning.kokkos.Asynchronous execution will be most beneficial for just-in-time compiled functions that contain — or generate — multiple QNodes.
For example,
dev = qml.device("lightning.qubit", wires=2) @qml.qnode(device=dev) def circuit(params): qml.RX(params[0], wires=0) qml.RY(params[1], wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(wires=0)) @qjit(async_qnodes=True) def multiple_qnodes(params): x = jnp.sin(params) y = jnp.cos(params) z = jnp.array([circuit(x), circuit(y)]) # will be executed in parallel return circuit(z)
>>> func(jnp.array([1.0, 2.0])) 1.0
Here, the first two circuit executions will occur in parallel across multiple threads, as their execution can occur indepdently.
Preliminary support for PennyLane transforms has been added. (#280)
@qjit @qml.transforms.split_non_commuting @qml.qnode(dev) def circuit(x): qml.RX(x,wires=0) return [qml.expval(qml.PauliY(0)), qml.expval(qml.PauliZ(0))]
>>> circuit(0.4) [array(-0.51413599), array(0.85770868)]
Currently, most PennyLane transforms will work with Catalyst as long as:
The circuit does not include any Catalyst-specific features, such as Catalyst control flow or measurement,
The QNode returns only lists of measurement processes,
AutoGraph is disabled, and
The transformation does not require or depend on the numeric value of dynamic variables.
Catalyst now supports just-in-time compilation of dynamically-shaped arrays. (#366) (#386) (#390) (#411)
The
@qjitdecorator can now be used to compile functions that accepts or contain tensors whose dimensions are not known at compile time; runtime execution with different shapes is supported without recompilation.In addition, standard tensor initialization functions
jax.numpy.ones,jnp.zeros, andjnp.emptynow accept dynamic variables (where the value is only known at runtime).@qjit def func(size: int): return jax.numpy.ones([size, size], dtype=float)
>>> func(3) [[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]]
When passing tensors as arguments to compiled functions, the
abstracted_axeskeyword argument to the@qjitdecorator can be used to specify which axes of the input arguments should be treated as abstract (and thus avoid recompilation).For example, without specifying
abstracted_axes, the followingsumfunction would recompile each time an array of different size is passed as an argument:>>> @qjit >>> def sum_fn(x): >>> return jnp.sum(x) >>> sum_fn(jnp.array([1])) # Compilation happens here. >>> sum_fn(jnp.array([1, 1])) # And here!
By passing
abstracted_axes, we can specify that the first axes of the first argument is to be treated as dynamic during initial compilation:>>> @qjit(abstracted_axes={0: "n"}) >>> def sum_fn(x): >>> return jnp.sum(x) >>> sum_fn(jnp.array([1])) # Compilation happens here. >>> sum_fn(jnp.array([1, 1])) # No need to recompile.
Note that support for dynamic arrays in control-flow primitives (such as loops), is not yet supported.
Error mitigation using the zero-noise extrapolation method is now available through the
catalyst.mitigate_with_znetransform. (#324) (#414)For example, given a noisy device (such as noisy hardware available through Amazon Braket):
dev = qml.device("noisy.device", wires=2) @qml.qnode(device=dev) def circuit(x, n): @for_loop(0, n, 1) def loop_rx(i): qml.RX(x, wires=0) loop_rx() qml.Hadamard(wires=0) qml.RZ(x, wires=0) loop_rx() qml.RZ(x, wires=0) qml.CNOT(wires=[1, 0]) qml.Hadamard(wires=1) return qml.expval(qml.PauliY(wires=0)) @qjit def mitigated_circuit(args, n): s = jax.numpy.array([1, 2, 3]) return mitigate_with_zne(circuit, scale_factors=s)(args, n)
>>> mitigated_circuit(0.2, 5) 0.5655341100116512
In addition, a mitigation dialect has been added to the MLIR layer of Catalyst. It contains a Zero Noise Extrapolation (ZNE) operation, with a lowering to a global folded circuit.
Improvements
The three backend devices provided with Catalyst,
lightning.qubit,lightning.kokkos, andbraket.aws, are now dynamically loaded at runtime. (#343) (#400)This takes advantage of the new backend plugin system provided in Catalyst v0.3.2, and allows the devices to be packaged separately from the runtime CAPI. Provided backend devices are now loaded at runtime, instead of being linked at compile time.
For more details on the backend plugin system, see the custom devices documentation.
Finite-shot measurement statistics (
expval,var, andprobs) are now supported for thelightning.qubitandlightning.kokkosdevices. Previously, exact statistics were returned even when finite shots were specified. (#392) (#410)>>> dev = qml.device("lightning.qubit", wires=2, shots=100) >>> @qjit >>> @qml.qnode(dev) >>> def circuit(x): >>> qml.RX(x, wires=0) >>> return qml.probs(wires=0) >>> circuit(0.54) array([0.94, 0.06]) >>> circuit(0.54) array([0.93, 0.07])
Catalyst gradient functions
grad,jacobian,jvp, andvjpcan now be invoked from outside a@qjitcontext. (#375)This simplifies the process of writing functions where compilation can be turned on and off easily by adding or removing the decorator. The functions dispatch to their JAX equivalents when the compilation is turned off.
dev = qml.device("lightning.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
>>> grad(circuit)(0.54) # dispatches to jax.grad Array(-0.51413599, dtype=float64, weak_type=True) >>> qjit(grad(circuit))(0.54). # differentiates using Catalyst array(-0.51413599)
New
lightning.qubitconfiguration options are now supported via theqml.deviceloader, including Markov Chain Monte Carlo sampling support. (#369)dev = qml.device("lightning.qubit", wires=2, shots=1000, mcmc=True) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
>>> circuit(0.54) array(0.856)
Improvements have been made to the runtime and quantum MLIR dialect in order to support asynchronous execution.
The runtime now supports multiple active devices managed via a device pool. The new
RTDevicedata-class andRTDeviceStatusalong with thethread_localdevice instance pointer enable the runtime to better scope the lifetime of device instances concurrently. With these changes, one can create multiple active devices and execute multiple programs in a multithreaded environment. (#381)The ability to dynamically release devices has been added via
DeviceReleaseOpin the Quantum MLIR dialect. This is lowered to the__quantum__rt__device_release()runtime instruction, which updates the status of the device instance fromActivetoInactive. The runtime will reuse this deactivated instance instead of creating a new one automatically at runtime in a multi-QNode workflow when another device with identical specifications is requested. (#381)The
DeviceOpdefinition in the Quantum MLIR dialect has been updated to lower a tuple of device information('lib', 'name', 'kwargs')to a single device initialization call__quantum__rt__device_init(int8_t *, int8_t *, int8_t *). This allows the runtime to initialize device instances without keeping partial information of the device (#396)
The quantum adjoint compiler routine has been extended to support function calls that affect the quantum state within an adjoint region. Note that the function may only provide a single result consisting of the quantum register. By itself this provides no user-facing changes, but compiler pass developers may now generate quantum adjoint operations around a block of code containing function calls as well as quantum operations and control flow operations. (#353)
The allocation and deallocation operations in MLIR (
AllocOp,DeallocOp) now follow simple value semantics for qubit register values, instead of modelling memory in the MLIR trait system. Similarly, the frontend generates proper value semantics by deallocating the final register value.The change enables functions at the MLIR level to accept and return quantum register values, which would otherwise not be correctly identified as aliases of existing register values by the bufferization system. (#360)
Breaking changes
Third party devices must now provide a configuration TOML file, in order to specify their supported operations, measurements, and features for Catalyst compatibility. For more information please visit the Custom Devices section in our documentation. (#369)
Bug fixes
Resolves a bug in the compiler’s differentiation engine that results in a segmentation fault when attempting to differentiate non-differentiable quantum operations. The fix ensures that all existing quantum operation types are removed during gradient passes that extract classical code from a QNode function. It also adds a verification step that will raise an error if a gradient pass cannot successfully eliminate all quantum operations for such functions. (#397)
Resolves a bug that caused unpredictable behaviour when printing string values with the
debug.printfunction. The issue was caused by non-null-terminated strings. (#418)
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah, Romain Moyard, Sergei Mironov, Erick Ochoa Lopez, Shuli Shu.
Release 0.3.2¶
New features
The experimental AutoGraph feature now supports Python
whileloops, allowing native Python loops to be captured and compiled with Catalyst. (#318)dev = qml.device("lightning.qubit", wires=4) @qjit(autograph=True) @qml.qnode(dev) def circuit(n: int, x: float): i = 0 while i < n: qml.RX(x, wires=i) i += 1 return qml.expval(qml.PauliZ(0))
>>> circuit(4, 0.32) array(0.94923542)
This feature extends the existing AutoGraph support for Python
forloops andifstatements introduced in v0.3. Note that TensorFlow must be installed for AutoGraph support.For more details, please see the AutoGraph guide.
In addition to loops and conditional branches, AutoGraph now supports native Python
and,orandnotoperators in Boolean expressions. (#325)dev = qml.device("lightning.qubit", wires=1) @qjit(autograph=True) @qml.qnode(dev) def circuit(x: float): if x >= 0 and x < jnp.pi: qml.RX(x, wires=0) return qml.probs()
>>> circuit(0.43) array([0.95448287, 0.04551713]) >>> circuit(4.54) array([1., 0.])
Note that logical Boolean operators will only be captured by AutoGraph if all operands are dynamic variables (that is, a value known only at runtime, such as a measurement result or function argument). For other use cases, it is recommended to use the
jax.numpy.logical_*set of functions where appropriate.Debug compiled programs and print dynamic values at runtime with
debug.print(#279) (#356)You can now print arbitrary values from your running program, whether they are arrays, constants, strings, or abitrary Python objects. Note that while non-array Python objects will be printed at runtime, their string representation is captured at compile time, and thus will always be the same regardless of program inputs. The output for arrays optionally includes a descriptor for how the data is stored in memory (“memref”).
@qjit def func(x: float): debug.print(x, memref=True) debug.print("exit")
>>> func(jnp.array(0.43)) MemRef: base@ = 0x5629ff2b6680 rank = 0 offset = 0 sizes = [] strides = [] data = 0.43 exit
Catalyst now officially supports macOS X86_64 devices, with macOS binary wheels available for both AARCH64 and X86_64. (#347) (#313)
It is now possible to dynamically load third-party Catalyst compatible devices directly into a pre-installed Catalyst runtime on Linux. (#327)
To take advantage of this, third-party devices must implement the
Catalyst::Runtime::QuantumDeviceinterface, in addition to defining the following method:extern "C" Catalyst::Runtime::QuantumDevice* getCustomDevice() { return new CustomDevice(); }
This support can also be integrated into existing PennyLane Python devices that inherit from the
QuantumDeviceclass, by defining theget_c_interfacestatic method.For more details, see the custom devices documentation.
Improvements
Return values of conditional functions no longer need to be of exactly the same type. Type promotion is automatically applied to branch return values if their types don’t match. (#333)
@qjit def func(i: int, f: float): @cond(i < 3) def cond_fn(): return i @cond_fn.otherwise def otherwise(): return f return cond_fn()
>>> func(1, 4.0) array(1.0)
Automatic type promotion across conditional branches also works with AutoGraph:
@qjit(autograph=True) def func(i: int, f: float): if i < 3: i = i else: i = f return i
>>> func(1, 4.0) array(1.0)
AutoGraph now supports converting functions even when they are invoked through functional wrappers such as
adjoint,ctrl,grad,jacobian, etc. (#336)For example, the following should now succeed:
def inner(n): for i in range(n): qml.T(i) @qjit(autograph=True) @qml.qnode(dev) def f(n: int): adjoint(inner)(n) return qml.state()
To prepare for Catalyst’s frontend being integrated with PennyLane, the appropriate plugin entry point interface has been added to Catalyst. (#331)
For any compiler packages seeking to be registered in PennyLane, the
entry_pointsmetadata under the the group namepennylane.compilersmust be added, with the following entry points:context: Path to the compilation evaluation context manager. This context manager should have the methodcontext.is_tracing(), which returns True if called within a program that is being traced or captured.ops: Path to the compiler operations module. This operations module may contain compiler specific versions of PennyLane operations. Within a JIT context, PennyLane operations may dispatch to these.qjit: Path to the JIT compiler decorator provided by the compiler. This decorator should have the signatureqjit(fn, *args, **kwargs), wherefnis the function to be compiled.
The compiler driver diagnostic output has been improved, and now includes failing IR as well as the names of failing passes. (#349)
The scatter operation in the Catalyst dialect now uses an SCF for loop to avoid ballooning the compiled code. (#307)
The
CopyGlobalMemRefPasspass of our MLIR processing pipeline now supports dynamically shaped arrays. (#348)The Catalyst utility dialect is now included in the Catalyst MLIR C-API. (#345)
Fix an issue with the AutoGraph conversion system that would prevent the fallback to Python from working correctly in certain instances. (#352)
The following type of code is now supported:
@qjit(autograph=True) def f(): l = jnp.array([1, 2]) for _ in range(2): l = jnp.kron(l, l) return l
Catalyst now supports
jax.numpy.polyfitinside a qjitted function. (#367)Catalyst now supports custom calls (including the one from HLO). We added support in MLIR (operation, bufferization and lowering). In the
lib_custom_calls, developers then implement their custom calls and use external functions directly (e.g. Lapack). The OpenBlas library is taken from Scipy and linked in Catalyst, therefore any function from it can be used. (#367)
Breaking changes
The axis ordering for
catalyst.jacobianis updated to matchjax.jacobian. Assuming we have parameters of shape[a,b]and results of shape[c,d], the returned Jacobian will now have shape[c, d, a, b]instead of[a, b, c, d]. (#283)
Bug fixes
An upstream change in the PennyLane-Lightning project was addressed to prevent compilation issues in the
StateVectorLQubitDynamicclass in the runtime. The issue was introduced in #499. (#322)The
requirements.txtfile to build Catalyst from source has been updated with a minimum pip version,>=22.3. Previous versions of pip are unable to perform editable installs when the system-wide site-packages are read-only, even when the--userflag is provided. (#311)The frontend has been updated to make it compatible with PennyLane
MeasurementProcessobjects now being PyTrees in PennyLane version 0.33. (#315)
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah, Sergei Mironov, Romain Moyard, Erick Ochoa Lopez.
Release 0.3.1¶
New features
The experimental AutoGraph feature, now supports Python
forloops, allowing native Python loops to be captured and compiled with Catalyst. (#258)dev = qml.device("lightning.qubit", wires=n) @qjit(autograph=True) @qml.qnode(dev) def f(n): for i in range(n): qml.Hadamard(wires=i) return qml.expval(qml.PauliZ(0))
This feature extends the existing AutoGraph support for Python
ifstatements introduced in v0.3. Note that TensorFlow must be installed for AutoGraph support.The quantum control operation can now be used in conjunction with Catalyst control flow, such as loops and conditionals, via the new
catalyst.ctrlfunction. (#282)Similar in behaviour to the
qml.ctrlcontrol modifier from PennyLane,catalyst.ctrlcan additionally wrap around quantum functions which contain control flow, such as the Catalystcond,for_loop, andwhile_loopprimitives.@qjit @qml.qnode(qml.device("lightning.qubit", wires=4)) def circuit(x): @for_loop(0, 3, 1) def repeat_rx(i): qml.RX(x / 2, wires=i) catalyst.ctrl(repeat_rx, control=3)() return qml.expval(qml.PauliZ(0))
>>> circuit(0.2) array(1.)
Catalyst now supports JAX’s
array.at[index]notation for array element assignment and updating. (#273)@qjit def add_multiply(l: jax.core.ShapedArray((3,), dtype=float), idx: int): res = l.at[idx].multiply(3) res2 = l.at[idx].add(2) return res + res2 res = add_multiply(jnp.array([0, 1, 2]), 2)
>>> res [0, 2, 10]
For more details on available methods, see the JAX documentation.
Improvements
The Lightning backend device has been updated to work with the new PL-Lightning monorepo. (#259) (#277)
A new compiler driver has been implemented in C++. This improves compile-time performance by avoiding round-tripping, which is when the entire program being compiled is dumped to a textual form and re-parsed by another tool.
This is also a requirement for providing custom metadata at the LLVM level, which is necessary for better integration with tools like Enzyme. Finally, this makes it more natural to improve error messages originating from C++ when compared to the prior subprocess-based approach. (#216)
Support the
braket.devices.Devicesenum class ands3_destination_folderdevice options for AWS Braket remote devices. (#278)Improvements have been made to the build process, including avoiding unnecessary processes such as removing
optand downloading the wheel. (#298)Remove a linker warning about duplicate
rpaths when Catalyst wheels are installed on macOS. (#314)
Bug fixes
Fix incompatibilities with GCC on Linux introduced in v0.3.0 when compiling user programs. Due to these, Catalyst v0.3.0 only works when clang is installed in the user environment.
Remove undocumented package dependency on the zlib/zstd compression library. (#308)
Fix filesystem issue when compiling multiple functions with the same name and
keep_intermediate=True. (#306)Add support for applying the
adjointoperation toQubitUnitarygates.QubitUnitarywas not able to beadjointed when the variable holding the unitary matrix might change. This can happen, for instance, inside of a for loop. To solve this issue, the unitary matrix gets stored in the array list via push and pops. The unitary matrix is later reconstructed from the array list andQubitUnitarycan be executed in theadjointed context. (#304) (#310)
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah, Erick Ochoa Lopez, Jacob Mai Peng, Sergei Mironov, Romain Moyard.
Release 0.3.0¶
New features
Catalyst now officially supports macOS ARM devices, such as Apple M1/M2 machines, with macOS binary wheels available on PyPI. For more details on the changes involved to support macOS, please see the improvements section. (#229) (#232) (#233) (#234)
Write Catalyst-compatible programs with native Python conditional statements. (#235)
AutoGraph is a new, experimental, feature that automatically converts Python conditional statements like
if,else, andelif, into their equivalent functional forms provided by Catalyst (such ascatalyst.cond).This feature is currently opt-in, and requires setting the
autograph=Trueflag in theqjitdecorator:dev = qml.device("lightning.qubit", wires=1) @qjit(autograph=True) @qml.qnode(dev) def f(x): if x < 0.5: qml.RY(jnp.sin(x), wires=0) else: qml.RX(jnp.cos(x), wires=0) return qml.expval(qml.PauliZ(0))
The implementation is based on the AutoGraph module from TensorFlow, and requires a working TensorFlow installation be available. In addition, Python loops (
forandwhile) are not yet supported, and do not work in AutoGraph mode.Note that there are some caveats when using this feature especially around the use of global variables or object mutation inside of methods. A functional style is always recommended when using
qjitor AutoGraph.The quantum adjoint operation can now be used in conjunction with Catalyst control flow, such as loops and conditionals. For this purpose a new instruction,
catalyst.adjoint, has been added. (#220)catalyst.adjointcan wrap around quantum functions which contain the Catalystcond,for_loop, andwhile_loopprimitives. Previously, the usage ofqml.adjointon functions with these primitives would result in decomposition errors. Note that a future release of Catalyst will merge the behaviour ofcatalyst.adjointintoqml.adjointfor convenience.dev = qml.device("lightning.qubit", wires=3) @qjit @qml.qnode(dev) def circuit(x): @for_loop(0, 3, 1) def repeat_rx(i): qml.RX(x / 2, wires=i) adjoint(repeat_rx)() return qml.expval(qml.PauliZ(0))
>>> circuit(0.2) array(0.99500417)
Additionally, the ability to natively represent the adjoint construct in Catalyst’s program representation (IR) was added.
QJIT-compiled programs now support (nested) container types as inputs and outputs of compiled functions. This includes lists and dictionaries, as well as any data structure implementing the PyTree protocol. (#215) (#221)
For example, a program that accepts and returns a mix of dictionaries, lists, and tuples:
@qjit def workflow(params1, params2): res1 = params1["a"][0][0] + params2[1] return {"y1": jnp.sin(res1), "y2": jnp.cos(res1)}
>>> params1 = {"a": [[0.1], 0.2]} >>> params2 = (0.6, 0.8) >>> workflow(params1, params2) array(0.78332691)
Compile-time backpropagation of arbitrary hybrid programs is now supported, via integration with Enzyme AD. (#158) (#193) (#224) (#225) (#239) (#244)
This allows
catalyst.gradto differentiate hybrid functions that contain both classical pre-processing (inside & outside of QNodes), QNodes, as well as classical post-processing (outside of QNodes) via a combination of backpropagation and quantum gradient methods.The new default for the differentiation
methodattribute incatalyst.gradhas been changed to"auto", which performs Enzyme-based reverse mode AD on classical code, in conjunction with the quantumdiff_methodspecified on each QNode:dev = qml.device("lightning.qubit", wires=1) @qml.qnode(dev, diff_method="parameter-shift") def circuit(theta): qml.RX(jnp.exp(theta ** 2) / jnp.cos(theta / 4), wires=0) return qml.expval(qml.PauliZ(wires=0))
>>> grad = qjit(catalyst.grad(circuit, method="auto")) >>> grad(jnp.pi) array(0.05938718)
The reworked differentiation pipeline means you can now compute exact derivatives of programs with both classical pre- and post-processing, as shown below:
@qml.qnode(qml.device("lightning.qubit", wires=1), diff_method="adjoint") def circuit(theta): qml.RX(jnp.exp(theta ** 2) / jnp.cos(theta / 4), wires=0) return qml.expval(qml.PauliZ(wires=0)) def loss(theta): return jnp.pi / jnp.tanh(circuit(theta)) @qjit def grad_loss(theta): return catalyst.grad(loss)(theta)
>>> grad_loss(1.0) array(-1.90958669)
You can also use multiple QNodes with different differentiation methods:
@qml.qnode(qml.device("lightning.qubit", wires=1), diff_method="parameter-shift") def circuit_A(params): qml.RX(jnp.exp(params[0] ** 2) / jnp.cos(params[1] / 4), wires=0) return qml.probs() @qml.qnode(qml.device("lightning.qubit", wires=1), diff_method="adjoint") def circuit_B(params): qml.RX(jnp.exp(params[1] ** 2) / jnp.cos(params[0] / 4), wires=0) return qml.expval(qml.PauliZ(wires=0)) def loss(params): return jnp.prod(circuit_A(params)) + circuit_B(params) @qjit def grad_loss(theta): return catalyst.grad(loss)(theta)
>>> grad_loss(jnp.array([1.0, 2.0])) array([ 0.57367285, 44.4911605 ])
And you can differentiate purely classical functions as well:
def square(x: float): return x ** 2 @qjit def dsquare(x: float): return catalyst.grad(square)(x)
>>> dsquare(2.3) array(4.6)
Note that the current implementation of reverse mode AD is restricted to 1st order derivatives, but you can still use
catalyst.grad(method="fd")is still available to perform a finite differences approximation of any differentiable function.Add support for the new PennyLane arithmetic operators. (#250)
PennyLane is in the process of replacing
HamiltonianandTensorobservables with a set of general arithmetic operators. These consist of Prod, Sum and SProd.By default, using dunder methods (eg.
+,-,@,*) to combine operators with scalars or other operators will createHamiltonianandTensorobjects. However, these two methods will be deprecated in coming releases of PennyLane.To enable the new arithmetic operators, one can use
Prod,Sum, andSproddirectly or activate them by calling enable_new_opmath at the beginning of your PennyLane program.dev = qml.device("lightning.qubit", wires=2) @qjit @qml.qnode(dev) def circuit(x: float, y: float): qml.RX(x, wires=0) qml.RX(y, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(0.2 * qml.PauliX(wires=0) - 0.4 * qml.PauliY(wires=1))
>>> qml.operation.enable_new_opmath() >>> qml.operation.active_new_opmath() True >>> circuit(np.pi / 4, np.pi / 2) array(0.28284271)
Improvements
Better support for Hamiltonian observables:
Allow Hamiltonian observables with integer coefficients. (#248)
For example, compiling the following circuit wasn’t previously allowed, but is now supported in Catalyst:
dev = qml.device("lightning.qubit", wires=2) @qjit @qml.qnode(dev) def circuit(x: float, y: float): qml.RX(x, wires=0) qml.RY(y, wires=1) coeffs = [1, 2] obs = [qml.PauliZ(0), qml.PauliZ(1)] return qml.expval(qml.Hamiltonian(coeffs, obs))
Allow nested Hamiltonian observables. (#255)
@qjit @qml.qnode(qml.device("lightning.qubit", wires=3)) def circuit(x, y, coeffs1, coeffs2): qml.RX(x, wires=0) qml.RX(y, wires=1) qml.RY(x + y, wires=2) obs = [ qml.PauliX(0) @ qml.PauliZ(1), qml.Hamiltonian(coeffs1, [qml.PauliZ(0) @ qml.Hadamard(2)]), ] return qml.var(qml.Hamiltonian(coeffs2, obs))
Various performance improvements:
The execution and compile time of programs has been reduced, by generating more efficient code and avoiding unnecessary optimizations. Specifically, a scalarization procedure was added to the MLIR pass pipeline, and LLVM IR compilation is now invoked with optimization level 0. (#217)
The execution time of compiled functions has been improved in the frontend. (#213)
Specifically, the following changes have been made, which leads to a small but measurable improvement when using larger matrices as inputs, or functions with many inputs:
only loading the user program library once per compilation,
generating return value types only once per compilation,
avoiding unnecessary type promotion, and
avoiding unnecessary array copies.
Peak memory utilization of a JIT compiled program has been reduced, by allowing tensors to be scheduled for deallocation. Previously, the tensors were not deallocated until the end of the call to the JIT compiled function. (#201)
Various improvements have been made to enable Catalyst to compile on macOS:
Remove unnecessary
reinterpret_castfromObsManager. Removal of thesereinterpret_castallows compilation of the runtime to succeed in macOS. macOS uses an ILP32 mode for Aarch64 where they use the full 64 bit mode but with 32 bit Integer, Long, and Pointers. This patch also changes a test file to prevent a mismatch in machines which compile using ILP32 mode. (#229)Allow runtime to be compiled on macOS. Substitute
nprocwith a call toos.cpu_count()and use correct flags forld.64. (#232)Improve portability on the frontend to be available on macOS. Use
.dylib, remove unnecessary flags, and address behaviour difference in flags. (#233)Small compatibility changes in order for all integration tests to succeed on macOS. (#234)
Dialects can compile with older versions of clang by avoiding type mismatches. (#228)
The runtime is now built against
qir-stdlibpre-build artifacts. (#236)Small improvements have been made to the CI/CD, including fixing the Enzyme cache, generalize caches to other operating systems, fix build wheel recipe, and remove references to QIR in runtime’s Makefile. (#243) (#247)
Breaking changes
Support for Python 3.8 has been removed. (#231)
The default differentiation method on
gradandjacobianis reverse-mode automatic differentiation instead of finite differences. When a QNode does not have adiff_methodspecified, it will default to using the parameter shift method instead of finite-differences. (#244) (#271)The JAX version used by Catalyst has been updated to
v0.4.14, the minimum PennyLane version required is nowv0.32. (#264)Due to the change allowing Python container objects as inputs to QJIT-compiled functions, Python lists are no longer automatically converted to JAX arrays. (#231)
This means that indexing on lists when the index is not static will cause a
TracerIntegerConversionError, consistent with JAX’s behaviour.That is, the following example is no longer support:
@qjit def f(x: list, index: int): return x[index]
However, if the parameter
xabove is a JAX or NumPy array, the compilation will continue to succeed.The
catalyst.gradfunction has been renamed tocatalyst.jacobianand supports differentiation of functions that return multiple or non-scalar outputs. A newcatalyst.gradfunction has been added that enforces that it is differentiating a function with a single scalar return value. (#254)
Bug fixes
Fixed an issue preventing the differentiation of
qml.probswith the parameter-shift method. (#211)Fixed the incorrect return value data-type with functions returning
qml.counts. (#221)Fix segmentation fault when differentiating a function where a quantum measurement is used multiple times by the same operation. (#242)
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah, Erick Ochoa Lopez, Jacob Mai Peng, Romain Moyard, Sergei Mironov.
Release 0.2.1¶
Bug fixes
Add missing OpenQASM backend in binary distribution, which relies on the latest version of the AWS Braket plugin for PennyLane to resolve dependency issues between the plugin, Catalyst, and PennyLane. The Lightning-Kokkos backend with Serial and OpenMP modes is also added to the binary distribution. #198
Return a list of decompositions when calling the decomposition method for control operations. This allows Catalyst to be compatible with upstream PennyLane. #241
Improvements
When using OpenQASM-based devices the string representation of the circuit is printed on exception. #199
Use
pybind11::moduleinterface library instead ofpybind11::embedin the runtime for OpenQasm backend to avoid linking to the python library at compile time. #200
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah.
Release 0.2.0¶
New features
Catalyst programs can now be used inside of a larger JAX workflow which uses JIT compilation, automatic differentiation, and other JAX transforms. #96 #123 #167 #192
For example, call a Catalyst qjit-compiled function from within a JAX jit-compiled function:
dev = qml.device("lightning.qubit", wires=1) @qjit @qml.qnode(dev) def circuit(x): qml.RX(jnp.pi * x[0], wires=0) qml.RY(x[1] ** 2, wires=0) qml.RX(x[1] * x[2], wires=0) return qml.probs(wires=0) @jax.jit def cost_fn(weights): x = jnp.sin(weights) return jnp.sum(jnp.cos(circuit(x)) ** 2)
>>> cost_fn(jnp.array([0.1, 0.2, 0.3])) Array(1.32269195, dtype=float64)
Catalyst-compiled functions can now also be automatically differentiated via JAX, both in forward and reverse mode to first-order,
>>> jax.grad(cost_fn)(jnp.array([0.1, 0.2, 0.3])) Array([0.49249037, 0.05197949, 0.02991883], dtype=float64)
as well as vectorized using
jax.vmap:>>> jax.vmap(cost_fn)(jnp.array([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]])) Array([1.32269195, 1.53905377], dtype=float64)
In particular, this allows for a reduction in boilerplate when using JAX-compatible optimizers such as
jaxopt:>>> opt = jaxopt.GradientDescent(cost_fn) >>> params = jnp.array([0.1, 0.2, 0.3]) >>> (final_params, _) = jax.jit(opt.run)(params) >>> final_params Array([-0.00320799, 0.03475223, 0.29362844], dtype=float64)
Note that, in general, best performance will be seen when the Catalyst
@qjitdecorator is used to JIT the entire hybrid workflow. However, there may be cases where you may want to delegate only the quantum part of your workflow to Catalyst, and let JAX handle classical components (for example, due to missing a feature or compatibility issue in Catalyst).Support for Amazon Braket devices provided via the PennyLane-Braket plugin. #118 #139 #179 #180
This enables quantum subprograms within a JIT-compiled Catalyst workflow to execute on Braket simulator and hardware devices, including remote cloud-based simulators such as SV1.
def circuit(x, y): qml.RX(y * x, wires=0) qml.RX(x * 2, wires=1) return qml.expval(qml.PauliY(0) @ qml.PauliZ(1)) @qjit def workflow(x: float, y: float): device = qml.device("braket.local.qubit", backend="braket_sv", wires=2) g = qml.qnode(device)(circuit) h = catalyst.grad(g) return h(x, y) workflow(1.0, 2.0)
For a list of available devices, please see the PennyLane-Braket documentation.
Internally, the quantum instructions are generating OpenQASM3 kernels at runtime; these are then executed on both local (
braket.local.qubit) and remote (braket.aws.qubit) devices backed by Amazon Braket Python SDK,with measurement results then propagated back to the frontend.
Note that at initial release, not all Catalyst features are supported with Braket. In particular, dynamic circuit features, such as mid-circuit measurements, will not work with Braket devices.
Catalyst conditional functions defined via
@catalyst.condnow support an arbitrary number of ‘else if’ chains. #104dev = qml.device("lightning.qubit", wires=1) @qjit @qml.qnode(dev) def circuit(x): @catalyst.cond(x > 2.7) def cond_fn(): qml.RX(x, wires=0) @cond_fn.else_if(x > 1.4) def cond_elif(): qml.RY(x, wires=0) @cond_fn.otherwise def cond_else(): qml.RX(x ** 2, wires=0) cond_fn() return qml.probs(wires=0)
Iterating in reverse is now supported with constant negative step sizes via
catalyst.for_loop. #129dev = qml.device("lightning.qubit", wires=1) @qjit @qml.qnode(dev) def circuit(n): @catalyst.for_loop(n, 0, -1) def loop_fn(_): qml.PauliX(0) loop_fn() return measure(0)
Additional gradient transforms for computing the vector-Jacobian product (VJP) and Jacobian-vector product (JVP) are now available in Catalyst. #98
Use
catalyst.vjpto compute the forward-pass value and VJP:@qjit def vjp(params, cotangent): def f(x): y = [jnp.sin(x[0]), x[1] ** 2, x[0] * x[1]] return jnp.stack(y) return catalyst.vjp(f, [params], [cotangent])
>>> x = jnp.array([0.1, 0.2]) >>> dy = jnp.array([-0.5, 0.1, 0.3]) >>> vjp(x, dy) [array([0.09983342, 0.04 , 0.02 ]), array([-0.43750208, 0.07000001])]
Use
catalyst.jvpto compute the forward-pass value and JVP:@qjit def jvp(params, tangent): def f(x): y = [jnp.sin(x[0]), x[1] ** 2, x[0] * x[1]] return jnp.stack(y) return catalyst.jvp(f, [params], [tangent])
>>> x = jnp.array([0.1, 0.2]) >>> tangent = jnp.array([0.3, 0.6]) >>> jvp(x, tangent) [array([0.09983342, 0.04 , 0.02 ]), array([0.29850125, 0.24000006, 0.12 ])]
Support for multiple backend devices within a single qjit-compiled function is now available. #86 #89
For example, if you compile the Catalyst runtime with
lightning.kokkossupport (via the compilation flagENABLE_LIGHTNING_KOKKOS=ON), you can uselightning.qubitandlightning.kokkoswithin a singular workflow:dev1 = qml.device("lightning.qubit", wires=1) dev2 = qml.device("lightning.kokkos", wires=1) @qml.qnode(dev1) def circuit1(x): qml.RX(jnp.pi * x[0], wires=0) qml.RY(x[1] ** 2, wires=0) qml.RX(x[1] * x[2], wires=0) return qml.var(qml.PauliZ(0)) @qml.qnode(dev2) def circuit2(x): @catalyst.cond(x > 2.7) def cond_fn(): qml.RX(x, wires=0) @cond_fn.otherwise def cond_else(): qml.RX(x ** 2, wires=0) cond_fn() return qml.probs(wires=0) @qjit def cost(x): return circuit2(circuit1(x))
>>> x = jnp.array([0.54, 0.31]) >>> cost(x) array([0.80842369, 0.19157631])
Support for returning the variance of Hamiltonians, Hermitian matrices, and Tensors via
qml.varhas been added. #124dev = qml.device("lightning.qubit", wires=2) @qjit @qml.qnode(dev) def circuit(x): qml.RX(jnp.pi * x[0], wires=0) qml.RY(x[1] ** 2, wires=1) qml.CNOT(wires=[0, 1]) qml.RX(x[1] * x[2], wires=0) return qml.var(qml.PauliZ(0) @ qml.PauliX(1))
>>> x = jnp.array([0.54, 0.31]) >>> circuit(x) array(0.98851544)
Breaking changes
The
catalyst.gradfunction now supports using the differentiation method defined on the QNode (via thediff_methodargument) rather than applying a global differentiation method. #163As part of this change, the
methodargument now accepts the following options:method="auto": Quantum components of the hybrid function are differentiated according to the corresponding QNodediff_method, while the classical computation is differentiated using traditional auto-diff.With this strategy, Catalyst only currently supports QNodes with
diff_method="param-shift" anddiff_method=”adjoint”`.method="fd": First-order finite-differences for the entire hybrid function. Thediff_methodargument for each QNode is ignored.
This is an intermediate step towards differentiating functions that internally call multiple QNodes, and towards supporting differentiation of classical postprocessing.
Improvements
Catalyst has been upgraded to work with JAX v0.4.13. #143 #185
Add a Backprop operation for using autodifferentiation (AD) at the LLVM level with Enzyme AD. The Backprop operations has a bufferization pattern and a lowering to LLVM. #107 #116
Error handling has been improved. The runtime now throws more descriptive and unified expressions for runtime errors and assertions. #92
In preparation for easier debugging, the compiler has been refactored to allow easy prototyping of new compilation pipelines. #38
In the future, this will allow the ability to generate MLIR or LLVM-IR by loading input from a string or file, rather than generating it from Python.
As part of this refactor, the following changes were made:
Passes are now classes. This allows developers/users looking to change flags to inherit from these passes and change the flags.
Passes are now passed as arguments to the compiler. Custom passes can just be passed to the compiler as an argument, as long as they implement a run method which takes an input and the output of this method can be fed to the next pass.
Improved Python compatibility by providing a stable signature for user generated functions. #106
Handle C++ exceptions without unwinding the whole stack. #99
Reduce the number of classical invocations by counting the number of gate parameters in the
argmapfunction. #136Prior to this, the computation of hybrid gradients executed all of the classical code being differentiated in a
pcountfunction that solely counted the number of gate parameters in the quantum circuit. This was soargmapand other downstream functions could allocate memrefs large enough to store all gate parameters.Now, instead of counting the number of parameters separately, a dynamically-resizable array is used in the
argmapfunction directly to store the gate parameters. This removes one invocation of all of the classical code being differentiated.Use Tablegen to define MLIR passes instead of C++ to reduce overhead of adding new passes. #157
Perform constant folding on wire indices for
quantum.insertandquantum.extractops, used when writing (resp. reading) qubits to (resp. from) quantum registers. #161Represent known named observables as members of an MLIR Enum rather than a raw integer. This improves IR readability. #165
Bug fixes
Fix a bug in the mapping from logical to concrete qubits for mid-circuit measurements. #80
Fix a bug in the way gradient result type is inferred. #84
Fix a memory regression and reduce memory footprint by removing unnecessary temporary buffers. #100
Provide a new abstraction to the
QuantumDeviceinterface in the runtime calledDataView. C++ implementations of the interface can iterate through and directly store results into theDataViewindependent of the underlying memory layout. This can eliminate redundant buffer copies at the interface boundaries, which has been applied to existing devices. #109Reduce memory utilization by transferring ownership of buffers from the runtime to Python instead of copying them. This includes adding a compiler pass that copies global buffers into the heap as global buffers cannot be transferred to Python. #112
Temporary fix of use-after-free and dependency of uninitialized memory. #121
Fix file renaming within pass pipelines. #126
Fix the issue with the
do_queuedeprecation warnings in PennyLane. #146Fix the issue with gradients failing to work with hybrid functions that contain constant
jnp.arrayobjects. This will enable PennyLane operators that have data in the form of ajnp.array, such as a Hamiltonian, to be included in a qjit-compiled function. #152An example of a newly supported workflow:
coeffs = jnp.array([0.1, 0.2]) terms = [qml.PauliX(0) @ qml.PauliZ(1), qml.PauliZ(0)] H = qml.Hamiltonian(coeffs, terms) @qjit @qml.qnode(qml.device("lightning.qubit", wires=2)) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(H) params = jnp.array([0.3, 0.4]) jax.grad(circuit)(params)
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah, Erick Ochoa Lopez, Jacob Mai Peng, Romain Moyard, Sergei Mironov.
Release 0.1.2¶
New features
Add an option to print verbose messages explaining the compilation process. #68
Allow
catalyst.gradto be used on any traceable function (within a qjit context). This means the operation is no longer restricted to acting onqml.qnodes only. #75
Improvements
Work in progress on a Lightning-Kokkos backend:
Bring feature parity to the Lightning-Kokkos backend simulator. #55
Add support for variance measurements for all observables. #70
Build the runtime against qir-stdlib v0.1.0. #58
Replace input-checking assertions with exceptions. #67
Perform function inlining to improve optimizations and memory management within the compiler. #72
Breaking changes
Bug fixes
Several fixes to address memory leaks in the compiled program:
Fix memory leaks from data that flows back into the Python environment. #54
Fix memory leaks resulting from partial bufferization at the MLIR level. This fix makes the necessary changes to reintroduce the
-buffer-deallocationpass into the MLIR pass pipeline. The pass guarantees that all allocations contained within a function (that is allocations that are not returned from a function) are also deallocated. #61Lift heap allocations for quantum op results from the runtime into the MLIR compiler core. This allows all memref buffers to be memory managed in MLIR using the MLIR bufferization infrastructure. #63
Eliminate all memory leaks by tracking memory allocations at runtime. The memory allocations which are still alive when the compiled function terminates, will be freed in the finalization / teardown function. #78
Fix returning complex scalars from the compiled function. #77
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, David Ittah, Erick Ochoa Lopez, Sergei Mironov.
Release 0.1.1¶
New features
Adds support for interpreting control flow operations. #31
Improvements
Adds fallback compiler drivers to increase reliability during linking phase. Also adds support for a CATALYST_CC environment variable for manual specification of the compiler driver used for linking. #30
Breaking changes
Bug fixes
Fixes the Catalyst image path in the readme to properly render on PyPI.
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, Erick Ochoa Lopez.
Release 0.1.0¶
Initial public release.
Contributors
This release contains contributions from (in alphabetical order):
Ali Asadi, Sam Banning, David Ittah, Josh Izaac, Erick Ochoa Lopez, Sergei Mironov, Isidor Schoch.