







Templates¶
PennyLane provides a growing library of pre-coded templates of common variational circuit architectures that can be used to easily build, evaluate, and train more complex models. In the literature, such architectures are commonly known as an ansatz. Templates can be used to embed data into quantum states, to define trainable layers of quantum gates, to prepare quantum states as the first operation in a circuit, or simply as general subroutines that a circuit is built from.
The following is a gallery of built-in templates provided by PennyLane.
Embedding templates¶
Embeddings encode input features into the quantum state of the circuit. Hence, they usually take a data sample such as a feature vector as an argument. Embeddings can also depend on trainable parameters, and they may be constructed from repeated layers.
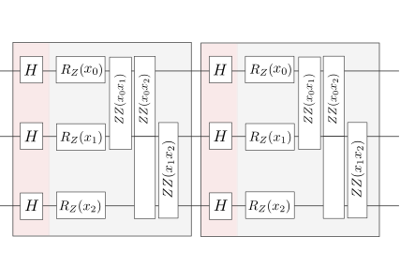
Layer templates¶
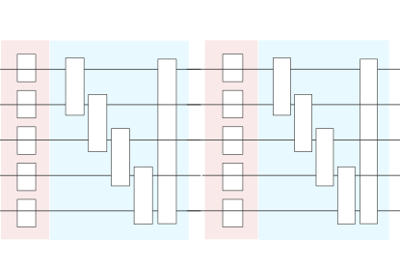
Layer architectures define sequences of trainable gates that are repeated like the layers in a
neural network. Note that arbitrary templates or operations can also be repeated using the
layer() function.
State Preparations¶
State preparation templates transform the zero state \(|0\dots 0 \rangle\) to another initial state. In contrast to embeddings that can in principle be used anywhere in a circuit, state preparation is typically used as the first operation.

Arithmetic templates¶
Quantum arithmetic templates enable in-place and out-place modular operations such as addition, multiplication and exponentiation.

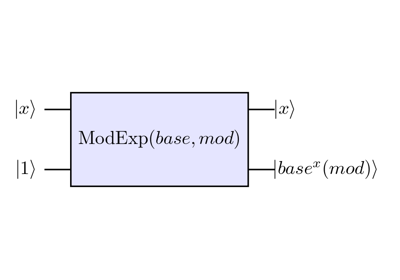
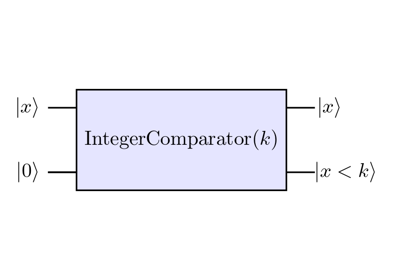
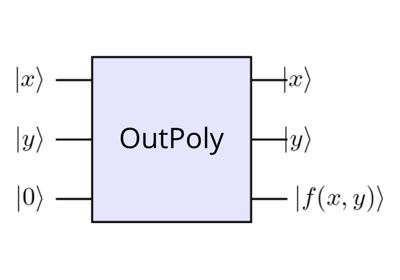
Quantum Chemistry templates¶
Quantum chemistry templates define various quantum circuits used in variational algorithms like VQE to perform quantum chemistry simulations.


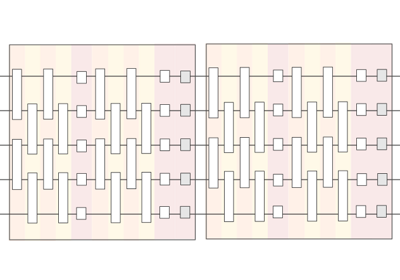
Tensor networks¶
Tensor-network templates create quantum circuit architectures where circuit blocks can be broadcast with the shape and connectivity of tensor networks.
Swap networks¶
Swap network templates perform qubit routing with linear cost, providing a quadratic advantage in circuit depth for carrying out all pair-wise interactions between qubits.
Other subroutines¶
Other useful templates which do not belong to the previous categories can be found here.












Parameter initializations¶
Templates that take a weight parameter tensor usually provide methods that return the shape of this tensor. The shape can for example be used to construct random weights at the beginning of training.
import pennylane as qp
from pennylane.templates import BasicEntanglerLayers
from pennylane import numpy as np
n_wires = 3
dev = qp.device('default.qubit', wires=n_wires)
@qp.qnode(dev)
def circuit(weights):
BasicEntanglerLayers(weights=weights, wires=range(n_wires))
return qp.expval(qp.PauliZ(0))
shape = BasicEntanglerLayers.shape(n_layers=2, n_wires=n_wires)
np.random.seed(42) # to make the result reproducible
weights = np.random.random(size=shape)
>>> circuit(weights)
tensor(0.72588592, requires_grad=True)
If a template takes more than one weight tensor, the shape method returns a list of shape tuples.
Custom templates¶
Creating a custom template can be as simple as defining a function that creates operations and does not have a return statement:
from pennylane import numpy as np
def MyTemplate(a, b, wires):
c = np.sin(a) + b
qp.RX(c, wires=wires[0])
n_wires = 3
dev = qp.device('default.qubit', wires=n_wires)
@qp.qnode(dev)
def circuit(a, b):
MyTemplate(a, b, wires=range(n_wires))
return qp.expval(qp.PauliZ(0))
>>> circuit(2, 3)
-0.7195065654396784
Note
Make sure that classical processing is compatible with the autodifferentiation library you are using. For example,
if MyTemplate is to be used with the torch framework, we would have to change np.sin to torch.sin.
PennyLane’s math library contains some advanced functionality for
framework-agnostic processing.
As suggested by the camel-case naming, built-in templates in PennyLane are classes. Classes are more complex data structures than functions, since they can define properties and methods of templates (such as gradient recipes or matrix representations). Consult the Contributing operators page to learn how to code up your own template class, and how to add it to the PennyLane template library.
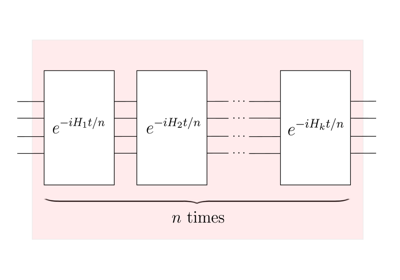
Layering Function¶
The layer function creates a new template by repeatedly applying a sequence of quantum
gates to a set of wires. You can import this function both via
qp.layer and qp.templates.layer.
|
Repeatedly applies a unitary a given number of times. |