







Release notes¶
This page contains the release notes for PennyLane.
Release 0.45.1 (current release)¶
Bug fixes 🐛
Pin
autogradto <1.9 to avoid a breaking change in theautogradpackage that was introduced in version 1.9. (#9731)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Yushao Chen, Andrija Paurevic.
Release 0.45.0¶
New features since last release
Sum of Slaters State Preparation 🆘
A new state preparation method called
SumOfSlatersPrepis now available. This state preparation routine introduced in Fomichev et al., PRX Quantum 5, 040339 (see the associated demo) is a state-of-the-art technique for algorithms that require a high-quality initial state, like in ground-state energy estimation algorithms of chemical systems. (#8964) (#8997) (#9228) (#9323)Consider this sparse state on three qubits, specified by normalized coefficients and statevector indices pointing to the populated computational basis states:
import pennylane as qp import numpy as np coefficients = np.array([1, -1j, 1j, 1]) / np.sqrt(4) indices = (0, 1, 2, 4) num_wires = 3 wires = list(range(num_wires))
The
SumOfSlatersPrepoperation requires thecoefficients,indices, andwiresas input. It efficiently prepares sparse states using auxiliary wires,QROMs, reversible bit encodings, and a dense-state preparation on a smaller subspace. Its implementation can be inspected by using PennyLane’s graph-based decomposition algorithm (enable_graph()) with the following gate set and five auxiliary wires (work_wires).qp.decomposition.enable_graph() gate_set = {"QROM", "TemporaryAND", "Adjoint(TemporaryAND)", "StatePrep", "CNOT", "X"} num_work_wires = 5 @qp.decompose(gate_set=gate_set, num_work_wires=num_work_wires) @qp.qnode(qp.device("lightning.qubit", wires=num_work_wires+num_wires)) def circuit(): qp.SumOfSlatersPrep(coefficients, wires, indices) return qp.state()
>>> print(qp.draw(circuit, show_matrices=False, max_length=180)()) 0: ────────────────╭QROM(M0)──X─╭●────────────●╮────╭●────────────●╮──X─╭●───────────────●╮─────────────┤ State 1: ────────────────├QROM(M0)──X─├●────────────●┤──X─├●────────────●┤──X─├●───────────────●┤──X──────────┤ State 2: ────────────────├QROM(M0)────│──╭●─────●╮───│──X─│──╭●─────●╮───│────│──╭●────────●╮───│──X──────────┤ State <DynamicWire>: ─╭Allocate─╭|Ψ⟩─├QROM(M0)────│──│───────│───│────│──│──╭X───│───│────│──│──╭X──────│───│─╭Deallocate─┤ State <DynamicWire>: ─├Allocate─╰|Ψ⟩─├QROM(M0)────│──│──╭X───│───│────│──│──│────│───│────│──│──│──╭X───│───│─├Deallocate─┤ State <DynamicWire>: ─├Allocate──────╰QROM(M0)────│──│──│────│───│────│──│──│────│───│────│──│──│──│────│───│─├Deallocate─┤ State <DynamicWire>: ─├Allocate───────────────────╰⊕─├●─│───●┤──⊕╯────╰⊕─├●─│───●┤──⊕╯────╰⊕─├●─│──│───●┤──⊕╯─├Deallocate─┤ State <DynamicWire>: ─╰Allocate──────────────────────╰⊕─╰●──⊕╯───────────╰⊕─╰●──⊕╯───────────╰⊕─╰●─╰●──⊕╯─────╰Deallocate─┤ State
The smaller dense state preparation is represented by
|Ψ⟩, which is on two wires, and the<DynamicWire>labels represent dynamically allocated wires (withallocate()) used in its decomposition.
Workflow Inspection 🔍
When using
specs()withqjit()andlevel="all", you can now display the returnedCircuitSpecsas a table, allowing you to easily see how circuit resources evolve with each stage of compilation. In addition,specs()now supports settinglevel="user"for workflows compiled withqjit(), returning circuit specifications after all user-specified transforms have been applied. (#9088) (#9307) (#9426)@qp.qjit @qp.transforms.merge_rotations @qp.transforms.cancel_inverses @qp.qnode(qp.device("lightning.qubit", wires=2)) def circuit(): qp.RX(1.23,0) qp.RX(1.23,0) qp.X(0) qp.H(0) qp.H(0) return qp.probs()
>>> print(qp.specs(circuit, level="all")()) Device: lightning.qubit Device wires: 2 Shots: Shots(total=None) Levels: - 0: Before MLIR Passes - 1: cancel-inverses - 2: merge-rotations ↓Metric Level→ | 0 | 1 | 2 --------------------------------- Wire allocations | 2 | 2 | 2 Total gates | 5 | 3 | 2 Gate counts: | - Hadamard | 2 | 0 | 0 - PauliX | 1 | 1 | 1 - RX | 2 | 2 | 1 Measurements: | - probs(all wires) | 1 | 1 | 1
We can also observe the specifications after all user-applied transforms using
level="user":>>> print(qp.specs(circuit, level="user")()) Device: lightning.qubit Device wires: 2 Shots: Shots(total=None) Level: merge-rotations Wire allocations: 2 Total gates: 2 Gate counts: - PauliX: 1 - RX: 1 Measurements: - probs(all wires): 1 Depth: Not computed
When inspecting a circuit via the
levelargument inspecs()ordraw(), markers placed in aCompilePipeline(withmarker()) are now accessible exclusively via theirlabel, making it much easier to track levels of compilation without having to track shifting integerlevelvalues. In addition, markers can now be added directly to aCompilePipelinewith theadd_markermethod, and printing aCompilePipelinenow legibly distinguishes transforms and markers. (#8990) (#9007) (#9076) (#9102)pipeline = qp.CompilePipeline() pipeline.add_marker("no-transforms") pipeline += qp.transforms.cancel_inverses @qp.marker("after-cancel-inverses") @pipeline @qp.qnode(qp.device("default.qubit")) def circuit(): qp.X(0) qp.H(0) qp.H(0) return qp.probs()
The new string representation of
CompilePipelineallows you to inspect the transforms and markers:>>> print(circuit.compile_pipeline) CompilePipeline( ├─▶ no-transforms [1] cancel_inverses() └─▶ after-cancel-inverses )
As usual, marker labels can be used as an argument to
levelinspecs()anddraw(), showing the cumulative result of compilation up to the provided marker:>>> print(qp.draw(circuit, level="no-transforms")()) # or level=0 0: ──X──H──H─┤ Probs >>> print(qp.draw(circuit, level="after-cancel-inverses")()) # or level=1 0: ──X─┤ Probs
specs()now includes PPR and PPM weights in its output, allowing for better categorization of PPMs and PPRs in workflows compiled withqjit. (#8983)@qp.qjit @qp.transforms.to_ppr @qp.qnode(qp.device("null.qubit", wires=2)) def circuit(): qp.H(0) qp.CNOT([0, 1]) m = qp.measure(0) qp.T(0) return qp.expval(qp.Z(0))
>>> print(qp.specs(circuit, level="user")()) Device: null.qubit Device wires: 2 Shots: Shots(total=None) Level: to-ppr Wire allocations: 2 Total gates: 11 Gate counts: - GlobalPhase: 3 - PPM-w1: 1 - PPR-pi/4-w1: 5 - PPR-pi/4-w2: 1 - PPR-pi/8-w1: 1 Measurements: - expval(PauliZ): 1 Depth: Not computed
specs()has been upgraded with significantly faster processing of large workflows with many gates and/or measurements forqjit()compiled workflows in pass-by-pass mode. This is achieved using Catalyst’sResourceAnalysispass behind the scenes, improving upon the former implementation. For more details, check out the Catalyst v0.15 release notes. (#9279)specs()now returns measurement information forqjit()workloads when usinglevel="device". (#8988)When using pass-by-pass
specs()with Catalyst, the output will no longer display a"Before Tape Transforms"level if no tape transforms have been applied. In particular, for scenarios where no tape transforms are present, the"Before MLIR passes"level becomes level0. In scenarios with at least one tape transform, level0corresponds to"Before Tape Transforms"and"Before MLIR passes"is the level after all tape transforms but before the first MLIR pass. (#9091) (#9166)
QSVT Angle Solver 📐
A new angle solver has been added to find QSVT phase angles faster for large-degree polynomials. This can be accessed by setting
angle_solver="iterative-optax"inqsvt()andpoly_to_angles(), where the benefits are seen when when repeatedly evaluating the same-degree polynomial with different coefficients. Note that this requiresoptaxto be installed. (#8685) (#9435)poly = np.array([0, 1.0, 0, -1/2, 0, 1/3]) qsvt_angles = qp.poly_to_angles(poly, "QSVT", angle_solver="iterative-optax")
>>> print(qsvt_angles) [-4.74724627 1.51868559 0.57952342 0.57952342 1.51868559 -0.03485729]
Decomposition Inspection and Pre-defined Gate Sets 📠
New tools dedicated to accessible inspectability of PennyLane’s graph-based decomposition system (enabled with enable_graph())
are now available! With this release, you can query the solutions of the graph-based system to
understand how PennyLane decomposed a circuit, why specific rules where chosen over others, and more.
It is now possible to assign custom names to decomposition rules using the
nameargument inqp.register_resources, making it easier to identify specific decomposition rules. (#9257)import pennylane as qp qp.decomposition.enable_graph() @qp.register_resources({qp.CNOT: 1, qp.H: 2}, name='my_cz_rule') def cz_to_h_cnot(wires): qp.H(wires[1]) qp.CNOT(wires) qp.H(wires[1])
>>> cz_to_h_cnot.name 'my_cz_rule'
A new function called
inspect_decomps()allows for the visualization and inspection of all possible decomposition paths the graph system can take for a concrete operator instance. (#9322) (#9359) (#9427)For each decomposition rule applicable to the operator instance, the output includes its name, circuit diagram, gate count, and wire allocation (if any):
>>> qp.inspect_decomps(qp.CRX(0.5, wires=[0, 1])) Decomposition 0 (name: _crx_to_rx_cz) 0: ───────────╭●────────────╭●─┤ 1: ──RX(0.25)─╰Z──RX(-0.25)─╰Z─┤ Gate Count: {RX: 2, CZ: 2} Decomposition 1 (name: _crx_to_rz_ry) 0: ─────────────────────╭●────────────╭●────────────┤ 1: ──RZ(1.57)──RY(0.25)─╰X──RY(-0.25)─╰X──RZ(-1.57)─┤ Gate Count: {RZ: 2, RY: 2, CNOT: 2} Decomposition 2 (name: _crx_to_h_crz) 0: ────╭●───────────┤ 1: ──H─╰RZ(0.50)──H─┤ Gate Count: {Hadamard: 2, CRZ: 1} Decomposition 3 (name: _crx_to_ppr) 0: ───────────╭RZX(-0.25)─┤ 1: ──RX(0.25)─╰RZX(-0.25)─┤ Gate Count: {PauliRot(pauli_word=ZX): 1, PauliRot(pauli_word=X): 1}
By default,
inspect_decomps()displays all available decomposition rules for an operator. Alternatively, a single decomposition rule can be inspected by passing its name:>>> qp.inspect_decomps(qp.CRX(0.5, wires=[0, 1]), "_crx_to_h_crz") Decomposition 0 (name: _crx_to_h_crz) 0: ────╭●───────────┤ 1: ──H─╰RZ(0.50)──H─┤ Gate Count: {Hadamard: 2, CRZ: 1}
A new function called
decomp_inspector()is available for verifying how the decomposition graph chooses decomposition rules for each operator instance in a circuit. (#9359) (#9436)The
decomp_inspector()acts as a transform that can be applied on a QNode as a decorator. It returns an object that allows for interactively querying a given operator to identify which decomposition rules were considered and which one was chosen.Consider the following example where we want to efficiently decompose a
MultiRZinto single-qubit rotations andCNOTs:qp.decomposition.enable_graph() gate_sets = {"CNOT", "RX", "RY", "RZ", "Identity", "GlobalPhase", "MidMeasureMP"} @qp.decomp_inspector(gate_set=gate_sets, num_work_wires=2) @qp.qnode(qp.device("default.qubit")) def circuit(): qp.ctrl(qp.MultiRZ(0.5, [0, 1]), control=[3, 4, 5]) return qp.probs() inspector = circuit()
We can then call the
inspector‘sinspect_decompsmethod and provide theMultiRZinstance of interest to see which decomposition rules were considered.>>> inspector.inspect_decomps(qp.ctrl(qp.MultiRZ(0.5, [0, 1]), control=[3, 4, 5]), num_work_wires=2) CHOSEN: Decomposition 0 (name: flip_zero_ctrl_values(_ctrl_single_work_wire)) <DynamicWire>: ──Allocate─╭X─╭●─────────────╭X──Deallocate─┤ 3: ───────────├●─│──────────────├●─────────────┤ 4: ───────────├●─│──────────────├●─────────────┤ 5: ───────────╰●─│──────────────╰●─────────────┤ 0: ──────────────├MultiRZ(0.50)────────────────┤ 1: ──────────────╰MultiRZ(0.50)────────────────┤ First-Level Expansion Gates: {MultiControlledX(num_control_wires=3, num_work_wires=0, num_zero_control_values=0, work_wire_type=borrowed): 2, Controlled(MultiRZ(num_wires=2), num_control_wires=1, num_work_wires=0, num_zero_control_values=0, work_wire_type=borrowed): 1} Wire Allocations: {'zero': 1} Full Expansion Gates: {RZ: 58, CNOT: 34, GlobalPhase: 64, RY: 18, RX: 8, MidMeasure: 2} Weighted Cost: 120.0 Decomposition 1 (name: to_controlled_qubit_unitary) Not applicable (provided operator instance does not meet all conditions for this rule). Decomposition 2 (name: controlled(_multi_rz_decomposition)) 0: ─╭X─╭RZ(0.50)─╭X─┤ 1: ─├●─│─────────├●─┤ 3: ─├●─├●────────├●─┤ 4: ─├●─├●────────├●─┤ 5: ─╰●─╰●────────╰●─┤ First-Level Expansion Gates: {Controlled(RZ, num_control_wires=3, num_work_wires=0, num_zero_control_values=0, work_wire_type=borrowed): 1, MultiControlledX(num_control_wires=4, num_work_wires=0, num_zero_control_values=0, work_wire_type=borrowed): 2} Full Expansion Gates: {GlobalPhase: 76, RX: 16, MidMeasure: 4, RY: 24, RZ: 80, CNOT: 72} Weighted Cost: 196.0
For each decomposition rule applicable to the controlled
MultiRZoperator instance, the inspector provides a summary of its weighted cost, wire allocations, and the “Full Expansion” (the final gate counts produced after decomposing all the way down to the target gate set).Similar to the
qp.decomposetransform, thedecomp_inspector()provides the ability to inject new decomposition rules via the keyword argumentsfixed_decompsandalt_decomps. For more details on the inspection capabilities please consult the documentation fordecomp_inspector().The
list_decomps()function now returns an object that is easier to interact with, including better legibility when printing the entire set of available decomposition rules and when printing individual ones. Additionally, the object returned supports accessing a specific rule by index or by name. (#9260)>>> collection = qp.list_decomps(qp.CRX) >>> print(collection) Available Decomposition Rules: 0: _crx_to_rx_cz 1: _crx_to_rz_ry 2: _crx_to_h_crz 3: _crx_to_ppr >>> collection[0] DecompositionRule(name=_crx_to_rx_cz) >>> collection['_crx_to_ppr'] DecompositionRule(name=_crx_to_ppr) >>> print(qp.draw(collection[0])(0.5, wires=[0, 1])) 0: ───────────╭●────────────╭●─┤ 1: ──RX(0.25)─╰Z──RX(-0.25)─╰Z─┤
A new
gate_setsmodule contains pre-defined gate sets that can be plugged into thegate_setargument of thedecompose()transform. These pre-defined gate sets can be easily accessed and integrated into decompositions workflows. Key gate sets include: (#8915) (#9045) (#9259) (#9417)qp.gate_sets.CLIFFORD_Twhich contains the Clifford+T gate set andqp.gate_sets.CLIFFORD_T_PLUS_RZwith an additionalRZgate.qp.gate_sets.ROTATIONS_PLUS_CNOTwhich contains single-qubit rotations andCNOT.qp.gate_sets.IDENTITYwhich contains theIdentityand theGlobalPhasegates.
Here is an example using the
ROTATIONS_PLUS_CNOTgate set to decompose a controlledMultiRZgate:qp.decomposition.enable_graph() @qp.decompose(gate_set=qp.gate_sets.ROTATIONS_PLUS_CNOT, num_work_wires=2) @qp.qnode(qp.device("default.qubit")) def circuit(): qp.ctrl(qp.MultiRZ(0.5, [0, 1]), control=[3, 4, 5]) return qp.expval(qp.Z(0))
>>> print(qp.specs(circuit, level="device")().resources.gate_counts) {'RZ': 54, 'RY': 14, 'GlobalPhase': 52, 'CNOT': 36, 'CRZ': 4, 'CRY': 4, 'C(GlobalPhase)': 4, 'Toffoli': 2}
Resource Estimation Templates 📏
New lightweight representations of the
HybridQRAM,SelectOnlyQRAM,BasisEmbedding, andBasisStatetemplates have been added for fast and efficient resource estimation. These are available in theestimatormodule as:qp.estimator.HybridQRAM,qp.estimator.SelectOnlyQRAM,qp.estimator.BasisEmbedding, andqp.estimator.BasisState. (#8828) (#8826) (#9415) (#9449)import pennylane.estimator as qre data = [[0, 1, 0], [1, 1, 1], [1, 1, 0], [0, 0, 0], [0, 1, 0], [1, 1, 1], [1, 1, 0], [0, 0, 0]] bitstring_size = 3 k = 2 num_control_wires = 3 num_work_wires = 1 + 1 + 3 * (1 << (num_control_wires - k) - 1) reg = qp.registers( { "control": num_control_wires, "target": bitstring_size, "work": num_work_wires } ) dev = qp.device("null.qubit") @qp.qnode(dev) def hybrid_qram(): # prepare an address, e.g., |010> (index 2) qp.BasisEmbedding(2, wires=reg["control"]) qp.HybridQRAM( data, control_wires=reg["control"], target_wires=reg["target"], work_wires=reg["work"], k=k ) return qp.probs(wires=reg["target"])
>>> qre.estimate(hybrid_qram)() --- Resources: --- Total wires: 12 algorithmic wires: 11 allocated wires: 1 zero state: 1 any state: 0 Total gates : 2.797E+3 'Toffoli': 142, 'T': 2.112E+3, 'CNOT': 262, 'X': 65, 'Hadamard': 216
Improvements 🛠
Decompositions 🍏
qp.transforms.decomposeis now conveniently accessible from the top level asqp.decompose. (#9011)It is now possible to locally add decomposition rules to an operator via a
qp.decomposition.local_decompscontext manager. These rules will only be available within the context. (#8955) (#8998)@qp.register_resources({qp.CNOT: 1, qp.H: 2}) def custom_decomp(wires): qp.H(wires[1]) qp.CNOT(wires) qp.H(wires[1])
>>> with qp.decomposition.local_decomps(): >>> qp.add_decomps(qp.CZ, custom_decomp) >>> print(qp.list_decomps(qp.CZ)) Available Decomposition Rules: 0: _cz_to_cps 1: _cz_to_cnot 2: _cz_to_ppr 3: my_cz_rule >>> print(qp.list_decomps(qp.CZ)) Available Decomposition Rules: 0: _cz_to_cps 1: _cz_to_cnot 2: _cz_to_ppr
The following gate decompositions have been optimized for resource efficiency:
The
QROMdecomposition now has a more efficient allocation of work wires. (#9131)CSWAPis now decomposed more efficiently, usingchange_op_basis()with twoCNOTgates and a singleToffoligate. (#8887)
Several new decomposition rules have been added that can be accessed with
enable_graph():MultiControlledXhas a new decomposition into a pair ofTemporaryANDgates and oneCNOT. It takes two control wires and at least onezeroedwork wire that has been passed explicitly. (#9291)TemporaryANDcan now be decomposed into the equivalent (although slightly more expensive)Toffoligate. Note that this decomposition only is valid ifTemporaryANDis used as intended - on zeroed input target qubits or zeroed output target qubits forAdjoint(TemporaryAND). (#9303) (#9424)A new decomposition of
Evolutionintoqp.PauliRothas been added which is compatible with the new graph-based decomposition system. Similarly, a decomposition ofqp.RZintoqp.PhaseShift, including a global phase, has been added. (#9001) (#9049)
The graph-based decompositions system, enabled via
enable_graph(), now additionally supports the customadjointmethod of qutrit operators such asQutritUnitary,ControlledQutritUnitary, andTRZ. (#9056)The custom
adjointmethod of qutrit operators are implemented as decomposition rules compatible with the new graph-based decomposition system. (#9056)Now, when the new graph-based decomposition system is enabled, the
decompose()transform no longer tries to find a decomposition for an operator that meets a providedstopping_condition, even if it is not in the definedgate_set. (#9036)A
strictkeyword argument was added to thedecompose()transform that, when set toFalse, allows the decomposition graph to treat operators without a decomposition as part of the gate set. This prevents the decomposition graph from erroring out by keeping these operators in the circuit. (#9025)The inspectibility of general symbolic decomposition rules is improved. The string representation of a decomposition rule is by default its source code. Now for symbolic decomposition rules that wrap a base decomposition rule, the source code for the base decomposition rule is also displayed when printing this rule. (#9305)
Allowed the passing of
num_work_wires,alt_decompsandfixed_decompsto the device preprocessing functiondecompose(), which are then passed through to the graph-based decomposition system. (#9094)The decomposition of
BasisStateis now compatible withqjitandjax.jitfor static wires and/or states. Additionally, the parametric decomposition for traced states withoutqjitwas updated to use powers ofXrather thanRX. (#9069) (#9124) (#9339)The decompositions of
TemporaryAND,MultiRZ, andDiagonalQubitUnitaryare now compatible with Catalyst. (#9157)The
sk_decomposition()now accepts"Adjoint(T)"and"Adjoint(S)"in thebasis_setas a now-preferred alternative to the old"T*"and"S*"convention for gate adjoints. (#9231)Some decomposition rules for
MultiControlledX(e.g.,_mcx_two_borrowed_workersand_mcx_one_borrowed_worker) became identical for instances of this operator on less than 6 wires. To prevent this, stricter conditions have been applied on these decompositions. (#9324)Some wire reusage was removed in
Selectthat was not consistent with the approach to work wires elsewhere in PennyLane, and that was not taken into account in the resource functions for the graph-based decomposition system (leading to decompositions not being resolved correctly). Also simplified the resource calculation of one decomposition ofSelect. (#9222)The decomposition of
QSVThas been updated to be consistent with or without the graph-based decomposition system enabled. (#8994)When the new graph-based decomposition system is enabled, the
decompose()transform no longer raises duplicate warnings about operators that cannot be decomposed. (#9025)A new
DecompositionWarningis now raised instead of a generalUserWarningif the decomposition graph is unable to find a solution for an operator. (#9001)With the new graph-based decomposition system enabled, internal use of the
decompose()transform no longer raises warnings when the graph is unable to find a decomposition for an operator in the following scenarios: (#9001)circuit execution in the
null.qubitdevice.compilation with
qp.compile.gradient transforms within the
expand_transformofhadamard_gradandparam_shift.
In these cases the operators will be treated as supported.
Disentangling Transforms 🧶
The
disentangle_cnot()anddisentangle_swap()are now callable from PennyLane, not just from Catalyst’spassesmodule. These compilation passes simplify rendundantCNOTandSWAPgates. (#9133)Both compilation passes are designed to recognize patterns that include
CNOTandSWAPgates that are redundant. In the case ofdisentangle_cnot(),CNOTgates are replaced when the control wire is preceded by anXgate (and the control wire is guaranteed to be in the \(\vert 1 \rangle\) state). This is illustrated in the example below, where noCNOTgates remain after the compilation pass is applied.import pennylane as qp dev = qp.device("lightning.qubit", wires=2) @qp.qjit(capture=True) @qp.transforms.disentangle_cnot @qp.qnode(dev) def circuit(): qp.X(0) qp.CNOT([0, 1]) return qp.state()
>>> print(qp.specs(circuit, level=1)().resources.gate_counts) {'PauliX': 2}
Drawing ✏️
The
draw_graph()function is now accessible from PennyLane, not just from Catalyst. This function allows for compact graphical inspection ofqjit-compiled circuits, preserving structured control flow. (#9020)Like with
draw(),draw_mpl(), andspecs(),draw_graph()can be given alevelto inspect how compilation passes affect the circuit.import pennylane as qp @qp.qjit(capture=True, autograph=True) @qp.transforms.merge_rotations @qp.transforms.cancel_inverses @qp.qnode(qp.device("null.qubit", wires=3)) def circuit(x): for i in range(10): w = i % 3 qp.H(w) qp.H(w) qp.CNOT((i % 3, (i + 1) % 3)) qp.RX(0.1, wires=w) qp.RX(0.2, wires=w) if x > 1.2: qp.Toffoli((0, 1, 2)) else: qp.RZ(0.1, wires=2) qp.RZ(0.1, wires=2) return qp.expval(qp.X(0))
After all optimizations are applied (
level=2), we can still see the structure of the circuit.>>> fig, ax = qp.draw_graph(circuit, level=2)(0.1) >>> fig.savefig('path_to_file.png', dpi=300, bbox_inches="tight")
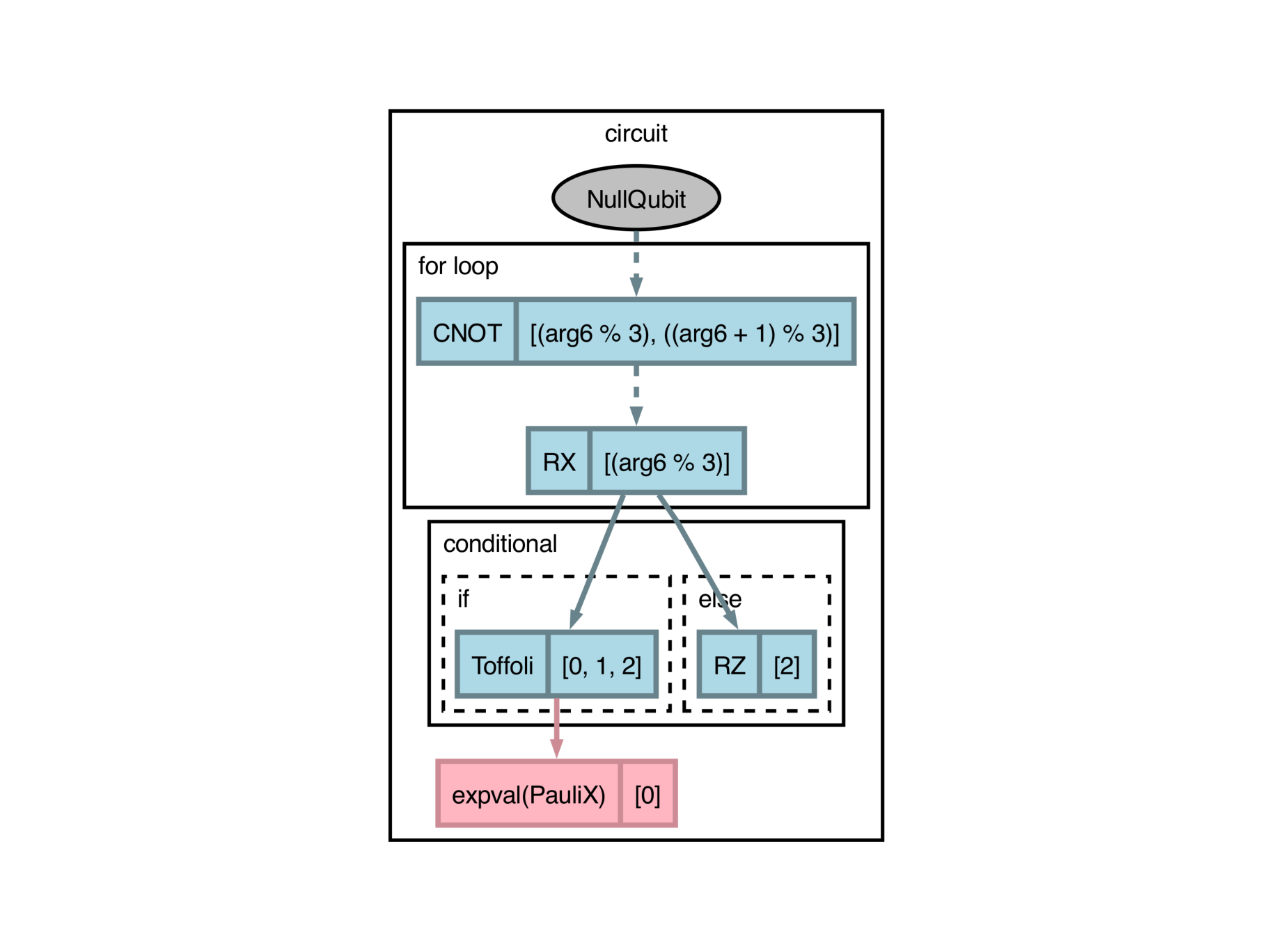
A new function called
label()has been added, which allows for attaching custom labels to operator instances for circuit drawing. (#9078)@qp.qnode(qp.device("default.qubit")) def circuit(): qp.drawer.label(qp.H(0), "my-h") qp.CNOT([0, 1]) return qp.probs()
>>> print(qp.draw(circuit)()) 0: ──H("my-h")─╭●─┤ Probs 1: ────────────╰X─┤ Probs
In addition to this change, the
mark()was added to mark an operator as an input-encoding gate forcircuit_spectrum(), andqnode_spectrum().

Program Capture 📥
With program capture enabled and using
for_loopandwhile_loop, constant closure variables with dynamic shapes can be used as such multiple times, no longer leading to leaked-tracer errors. (#9275) (#9335)A more informative error is raised if something that is not a measurement process is returned from a QNode when program capture is turned on. (#9072)
qp.condconverts non-boolean predicates to boolean immediately during capture time instead offrom_plxprdoing this, allowing for easier maintenance and organization offrom_plxpr. (#9336)qp.for_loopwith negative step sizes is now handled immediately during capture time instead of handling this withinfrom_plxpr, allowing for easier maintenance and organization offrom_plxpr. (#9299)With program capture, dynamic-shaped arrays returned from
qp.for_loopandqp.while_loopcan now be combined with other dynamic-shaped arrays returned fromqp.for_loopandqp.while_loop. (#9245)qp.vjpandqp.jvpare now compatible with program capture. (#8736) (#8788) (#9019)A
qp.capture.subroutinehas been added for jitting quantum subroutines with program capture. (#8912)qp.countsof mid-circuit measurement results is now compatible with program capture. (#9022)Program capture support for
StatePrepandBasisStatehas been enhanced to acceptstatearguments oflistortupletypes. (#9338)
Catalyst Compatibility 🤝
BasisEmbeddingis now captured asBasisStatefor compatibility with Catalyst and program capture. (#9183)The
dynamic_one_shotandsplit_to_single_termstransforms are now compatible withqp.qjit. (#9129)BBQRAM,HybridQRAM,SelectOnlyQRAMandQROMnow accept their classical data as a 2-dimensional array data type, which increases compatibility with Catalyst. (#8791)There is now one single source of truth for documentation of Catalyst passes while still maintaining accessibility from both PennyLane and Catalyst. This includes the following transforms:
to_ppr(),commute_ppr(),merge_ppr_ppm(),ppr_to_ppm(),reduce_t_depth(),decompose_arbitrary_ppr(),ppm_compilation(), andparity_synth(). (#9020) (#9395) (#9444)The source code for these passes in PennyLane has been removed as part of this change. However, all transforms listed above can still be accessed from the
pennylane.transformsmodule as before (if Catalyst is installed:pip install pennylane-catalyst).qp.math.givens_decompositionandqp.BasisRotationare now compatible withqjitwhencaptureis disabled. (#9155)qp.value_and_gradis now available to simultaneously calculate the results and gradients in Catalyst. (#8814)Catalyst version information has been added to
about(). (#9050)
Other improvements
Support has been added to
assert_validfor decompositions that include mid-circuit measurements alongside better verification for the length of compared iterables. (#9378)A convenience function called
ceil_log2()has been added, which computes the ceiling of the base-2 logarithm of its input and casts the result to anint. It is equivalent toint(np.ceil(np.log2(n))). (#8972) (#9069)A new function called
binary_decimals()has been added to enable easy translation of rotation angles to the binary representation of their decimals. This is important for discretization steps, for example via phase gradient decompositions. (#9117)The
binary_finite_reduced_row_echelon()function was moved to a new file and now includes further linear algebraic functionalities over \(\mathbb{Z}_2\). (#8982)binary_is_independent()computes whether a vector is linearly independent of a basis of binary vectors over \(\mathbb{Z}_2\).binary_matrix_rank()computes the rank over \(\mathbb{Z}_2\) of a binary matrix.binary_solve_linear_system()solves a linear system of the form \(A\cdot x=b\) with binary matrix \(A\) and binary coefficient vector \(b\) over \(\mathbb{Z}_2\).binary_select_basis()selects linearly independent columns out of a collection of binary column vectors. The result forms a basis for the columnspace of the input. The columns that are not selected are returned as well.
A
PauliSentence.pruneandFermiSentence.prunemethod has been added, which removes terms with coefficients below a provided threshold. (#9278)Replaced the O(n²) incremental
@=operator chaining inqp.pauli.string_to_pauli_wordandqp.pauli.binary_to_pauliwith a singleqp.prod(*tuple_of_ops)call, collecting operators via generator expressions. These operators are now much faster for large Pauli strings. (#9271)Operations using
PauliSentenceare now much faster due to additional memorization inPauliWord.__hash__(#9261)ZX-related transforms are now compatible with
pyzxv0.10.0. (#9179)The
to_zxtransform is now compatible with the new graph-based decomposition system. (#8994)A new function called
qp.decomposition.reconstructhas been added, which reconstructs the original operator instance from(*op.data, op.wires, **op.resource_params). This enablesqjit-compatible symbolic decomposition rules that do not need to take an instance of the base operator as input. (#9188)The output of the
qp.while_loopcondition is now automatically converted to abool. (#9184)A function for setting up transform inputs, including setting default values and basic validation, can now be provided to
qp.transformviasetup_inputs. (#8732)The
unitary_to_rot()transform now recursively decomposesQubitUnitaryoperations. This fixed a bug where two-qubit unitaries would decompose incorrectly to two single-qubit unitaries rather than their rotation decomposition. (#9144)Operations involving
FermiWordobjects are now significantly faster due to various performance enhancements made to the class. (#9283)MottonenStatePreparationnow supports parameter broadcasting in its decomposition. (#9148)Circuits containing
GlobalPhaseare now trainable without removing theGlobalPhase. (#8950)Quantum functions defining quantum operations can now be passed to the
compute_op,target_opanduncompute_oparguments ofchange_op_basis(). (#9163)The
qp.estimator.Resourcesclass now has a better string representation in Jupyter Notebooks. (#8880)matrix()can now also be applied to a sequence of operators. (#8861)A
qp.workflow.get_compile_pipeline(qnode, level)(*args, **kwargs)function has been added to extract theCompilePipelineof a given QNode at a specific level. (#8979) (#9425)No unnecessary classical registers will be created now when using
qp.to_openqasmwithmeasure_all=False. (#9033)Both
"subroutines"and"custom_gates"are now always initialized in the QASM interpreter, resulting in more robust behaviour with PennyLane’s QASM interpreter. (#9201)Applying
qp.ctrlonSnapshotno longer produces aControlled(Snapshot). Instead, it now returns the originalSnapshot. (#9001)The
default.qubitdevice now supports parameter-broadcastedGlobalPhaseoperations. (#9148)Global phases are now supported in
from_qasm3so that QASM including thegphaseinstruction can be interpreted. (#9247)
Labs: a place for unified and rapid prototyping of research software 🧪
Added a new
labs.estimator_betafor experimental development of resource estimation tools. Added various classes and functions tolabs.estimator_betato support advanced qubit management for resource estimation. Removed existing resource estimation functionality from thelabs.resource_estimationmodule. (#8996) (#8868)Allocate, allows users to allocate qubits in a resource decomposition.Deallocate, allows users to deallocate qubits in a resource decomposition.MarkClean, allows users to mark the state of qubits as the zero state in a circuit.MarkQubits, allows users to mark the state of qubits in a circuit.estimate_wires_from_circuit, estimates the number of additional qubits required from a circuit.estimate_wires_from_resources, estimates the number of additional qubits required from aResourcesobject.
A new
labs.estimator_beta.estimate()function has been created, which extends the functionality ofqp.estimator.estimate()to utilize the advanced qubit management features for resource estimation. (#9139)Created a new
LabsQROMresource operator in labs and added multiple alternate decompositions in labs forMultiControlledXthat utilize the new qubit management features. (#9258)mcx_many_clean_aux_resource_decomp(), uses multiple clean qubits to decompose.mcx_one_clean_aux_resource_decomp(), uses only one clean qubit to decompose.mcx_one_dirty_aux_resource_decomp(), uses only one dirty qubit to decompose.
Added alternate decompositions for
CHandHadamardoperations inlabs.estimator_betato get optimal numbers. (#9178)Added comparator decompositions for
RegisterEqualityandOutOfPlaceIntegerComparatorinlabs.estimator_beta(#9220)Added alternate controlled decompositions for
PauliRotandSelectPauliRotoperations inlabs.estimator_betato get optimal numbers. (#9186)Added resource templates for state preparation operators, which include
LabsMottonenStatePreparation,LabsCosineWindow, andLabsSumOfSlatersPrep. (#9202)Added various alternate resource decomposition functions for operators which make use of the phase gradient trick to accurately track auxiliary qubits using the new qubit management features. (#9391)
Added custom phase gradient decomposition rules for
RZandSelectPauliRot.Their outputs can be passed as
fixed_decompsinqp.decomposeand are necessary for efficient discretization strategies in application algorithms. (#9115)The integration test for computing perturbation error of a compressed double-factorized (CDF) Hamiltonian in
labs.trotter_erroris upgraded to use a more realistic molecular geometry and a more reliable reference error. (#8790)
Breaking changes 💔
The
num_x_wiresandnum_work_wiresarguments were added to theresource_keysandresource_paramsofSemiAdder. (#9293)With this breaking change, please note the following:
Decomposition rules for
SemiAddernow require those arguments.When registering a resource function (
qp.register_resources) to a decomposition rule of an operator that containsSemiAdder, the resource representation ofSemiAddermust also receive these new arguments.These changes are relevant only with
enable_graph().
All
Operatorclasses are now queued by default, unless they implement a customqueuemethod that changes this behaviour. (#8131) (#9029) (#9423)This change also affects operators commonly used for operator math:
BasisStateProjector
Note, however, that all
Operatorclasses that are used to construct new operators are de-queued, so the following example does not illustrate the changed behaviour (i.e., creatingBremovesAfrom the queue in the example below):import pennylane as qp import numpy as np coeff = np.array([0.2, 0.1]) @qp.qnode(qp.device("lightning.qubit", wires=3)) def expval(x: float): qp.RX(x, 1) A = qp.Hamiltonian(coeff, [qp.Y(1), qp.X(0)]) B = A @ qp.Z(2) return qp.expval(B)
>>> print(qp.draw(expval)(0.4)) 0: ───────────┤ ╭<𝓗(0.20,0.10)> 1: ──RX(0.40)─┤ ├<𝓗(0.20,0.10)> 2: ───────────┤ ╰<𝓗(0.20,0.10)>
However, if we convert an operator
Ato numerical data, from which a new operatorBis constructed, the chain of operator dependencies is broken and de-queuing will not work as previously expected:coeff = np.array([0.2, 0.1]) @qp.qnode(qp.device("lightning.qubit", wires=3)) def expval(x: float): qp.RX(x, 1) A = qp.Hamiltonian(coeff, [qp.Y(1), qp.X(0)]) numerical_data = A.matrix() B = qp.Hermitian(numerical_data, wires=[2, 0]) return qp.expval(B)
>>> print(qp.draw(expval, show_matrices=False)(0.4)) 0: ───────────╭𝓗(0.20,0.10)─┤ ╭<𝓗(M0)> 1: ──RX(0.40)─╰𝓗(0.20,0.10)─┤ │ 2: ─────────────────────────┤ ╰<𝓗(M0)>
As we can see, the
Hamiltonianinstance assigned toAremained in the queue. In cases where such a conversion to numerical data is unavoidable, perform the conversion outside of the quantum circuit.Support for NumPy 1.x has been dropped following its end-of-life. NumPy 2.0 or higher is now required. (#8914) (#8954) (#9017) (#9167)
compute_qfunc_decompositionandhas_qfunc_decompositionhave been removed fromOperatorand all subclasses that implemented them. The graph decomposition system (enable_graph()) should be used when capture is enabled. (#8922)The
pennylane.devices.preprocess.mid_circuit_measurements()transform has been removed. Instead, the device should determine which MCM method to use, and explicitly includedynamic_one_shot()ordefer_measurements()in its preprocess transforms if necessary. SeeDefaultQubit.setup_execution_configandDefaultQubit.preprocess_transformsfor an example. (#8926)The
custom_decompskeyword argument toqp.devicehas been removed. Instead, with the graph decomposition system (enable_graph()), new decomposition rules can be defined as quantum functions with registered resources. Seepennylane.decompositionfor more details. (#8928)As an example, consider the case of running the following circuit, where we wish to convert
CNOTgates intoHadamardandCZgates.def circuit(): qp.CNOT(wires=[0, 1]) return qp.expval(qp.X(1))
Instead of defining the
CNOTdecomposition as follows withcustom_decomps,def custom_cnot(wires): return [ qp.Hadamard(wires=wires[1]), qp.CZ(wires=[wires[0], wires[1]]), qp.Hadamard(wires=wires[1]) ] dev = qp.device('default.qubit', wires=2, custom_decomps={"CNOT" : custom_cnot}) qnode = qp.QNode(circuit, dev)
the same result would now be obtained using:
@qp.decomposition.register_resources({qp.H: 2, qp.CZ: 1}) def _custom_cnot_decomposition(wires, **_): qp.Hadamard(wires=wires[1]) qp.CZ(wires=[wires[0], wires[1]]) qp.Hadamard(wires=wires[1]) qp.decomposition.add_decomps(qp.CNOT, _custom_cnot_decomposition) qp.decomposition.enable_graph() @qp.transforms.decompose(gate_set={qp.CZ, qp.H}) def circuit(): qp.CNOT(wires=[0, 1]) return qp.expval(qp.X(1)) dev = qp.device('default.qubit', wires=2) qnode = qp.QNode(circuit, dev)
>>> print(qp.draw(qnode, level="device")()) 0: ────╭●────┤ 1: ──H─╰Z──H─┤ <X>
The
pennylane.operation.Operator.is_hermitian()property has been removed and replaced withpennylane.operation.Operator.is_verified_hermitian(), as it better reflects the functionality of this property. Alternatively, consider using thepennylane.is_hermitian()function instead as it provides a more reliable check for hermiticity. Please be aware that it comes with a higher computational cost. (#8919)Passing a function to the
gate_setargument inpennylane.decompose()has been removed. Thegate_setargument expects a static iterable of operator type and/or operator names, and the function should be passed to thestopping_conditionargument instead. (#8919)argnumhas been renamedargnumsinqp.grad,qp.jacobian,qp.jvp, andqp.vjpto better match Catalyst and JAX. (#8919)Access to the following functions and classes from the
pennylane.resourcesmodule has been removed. Instead, these functions must be imported from thepennylane.estimatormodule. (#8919)qp.estimator.estimate_shotsin favor ofqp.resources.estimate_shotsqp.estimator.estimate_errorin favor ofqp.resources.estimate_errorqp.estimator.FirstQuantizationin favor ofqp.resources.FirstQuantizationqp.estimator.DoubleFactorizationin favor ofqp.resources.DoubleFactorization
Deprecations 👋
The
pennylane.workflow.get_transform_program()function has been deprecated and will be removed in v0.46. Instead, please use the improvedpennylane.workflow.get_compile_pipeline()to retrieve the compilation pipeline of a QNode. (#9077)The
idkeyword argument to several classes has been renamed or removed entirely, and those changes will be official in v0.46. (#8951) (#9051)The
idkeyword argument toMeasureNodeandPrepareNodehas been renamed tonode_uid.The
idkeyword argument toMidMeasurehas been renamed tomeas_uid.The
idkeyword argument toMeasurementProcesswill be removed.The
idkeyword argument toOperatorhas been deprecated and will be removed.
The
idargument previously served two purposes: (1) adding custom labels to operator instances which were rendered in circuit drawings and (2) tagging encoding gates for Fourier spectrum analysis.These are now handled by dedicated functions:
Use
label()to attach a custom label to an operator instance for circuit drawing:# Legacy method (deprecated): qp.RX(0.5, wires=0, id="my-rx") # New method: qp.drawer.label(qp.RX(0.5, wires=0), "my-rx")
Use
mark()to mark an operator as an input-encoding gate forcircuit_spectrum(), andqnode_spectrum():# Legacy method (deprecated): qp.RX(0.5, wires=0, id="x0") # New method: qp.fourier.mark(qp.RX(0.5, wires=0), "x0")
Setting
_queue_category=Nonein an operator class in order to deactivate its instances being queued has been deprecated. Implement a customqueuemethod for the respective class instead. Operator classes that used to have_queue_category=Nonehave been updated to_queue_category="_ops", so that they are queued now. (#8131)The
BoundTransform.transformproperty has been deprecated. UseBoundTransform.tape_transforminstead. (#8985)expand()and related functions (expand_tape(),expand_tape_state_prep(), andcreate_expand_trainable_multipar()) have been deprecated and will be removed in v0.46. Instead, please use theqp.transforms.decomposetransform for decomposing circuits. (#8943) (#9438)Providing a value of
Nonetoaux_wireofqp.gradients.hadamard_gradwithmode="reversed"ormode="standard"has been deprecated and will no longer be supported in v0.46. Anaux_wirewill no longer be automatically assigned. (#8905)The
qp.transforms.create_expand_fnfunction has been deprecated and will be removed in v0.46. Instead, please use theqp.transforms.decomposefunction for decomposing circuits. (#8941) (#8977) (#9006)The
transform_programproperty of QNodes has been renamed tocompile_pipeline. The deprecated access throughtransform_programwill be removed in PennyLane v0.46. (#8906) (#8945)
Internal changes ⚙️
Read and write permissions have been added to all GitHub Actions workflows. (#9377)
The
doctestgroup has been added in thepyproject.tomlto easily maintain dependencies of the documentation tests workflow. (#9237)Documentation tests have been added for various modules such as the decomposition, measurements and devices modules. (#9004) (#9206) (#8653) (#9062) (#9236)
A new
qp.templates.Subroutineclass has been added as a layer of abstraction for quantum functions. These objects can now return classical values or mid circuit measurements, and are compatible with Program Capture Catalyst. AnyOperatorwith a single definition in terms of its implementation, a more complicated call signature, and that exists at a higher, algorithmic layer of abstraction could switch to using this class instead ofOperator/Operation. (#8929) (#9080) (#9096) (#9070) (#9097) (#9138) (#9119) (#9151) (#9172) (#9180) (#9177) (#9191) (#9176)from pennylane.templates import Subroutine @Subroutine def MyTemplate(x, y, wires): qp.RX(x, wires[0]) qp.RY(y, wires[0]) @qp.qnode(qp.device('default.qubit')) def c(): MyTemplate(0.1, 0.2, 0) return qp.state()
>>> print(qp.draw(c)()) 0: ──MyTemplate(0.10,0.20)─┤ State
Decomposition rules have been re-written for
qjitcompatibility, so that they can be lowered to Catalyst/MLIR. Rules for the followingSymbolicOpshave been re-written:qp.pytrees.PyTreeStructureis now frozen and hashable.PyTreeStructure.childrenshould now be a tuple instead of a list. (#9080)Pass-by-pass
specs()now usesBoundTransform.tape_transformrather than the deprecatedBoundTransform.transform. Additionally, several internal comments have been updated to bringspecsin line with the newCompilePipelineclass. (#9012)When using
specs()with Catalyst and with multiple levels, with thesplit-non-commutingMLIR pass applied, the returnedCircuitSpecsobject will include a list ofSpecsResourcesobjects for the associatedlevel. (#9120)Largely unused PLxPR code was recently removed in Lightning. Consequently, tests from PennyLane that are no longer relevant have been removed. (#9345)
Patched
jax._src.pjit._infer_params_internalfor dynamic shapes to correctly handle the concatenation of closure variables and arguments before return. (#9250)Docker files and workflow have been removed given that the PennyLane Docker image is no longer being built and managed in the repo. (#9273)
The requirements file has been removed from the
docsfolder. (#9242)A transform’s
setup_inputsis no longer called twice when applied on aQNode. (#9189)The
pyzxdependency has been upper bounded topyzx<0.10to ensure compatibility. (#9175)The internal
PassPipelineWrapperin Catalyst was removed in favour of PennyLane’s new unified transforms API. Consequently, usage ofPassPipelineWrapperhas been removed in PennyLane. (#9123)Updated the
diastatic-maltdependency to versionv2.15.3. (#9154)A workflow was created to sync the
mainbranch tomasterand later on deleted, aftermasterbranch was deleted. (#9127) (#9316)Removed
pytest-benchmarkfrom thepyproject.tomldevdependency group. Benchmarking is no longer internally performed in our test suite. (#7900)References to the
masterbranch have been changed to the new default branchmain. (#9128)Update nightly RC builds to not be a schedule triggered in Pennylane anymore. Instead, it will be triggered in the order Lightning —> Catalyst —> Pennylane. (#9092)
Duplicate transforms found in both
ftqc/catalyst_pass_aliases.pyandtransforms/decompositions/pauli_based_computation.pyhave been removed. (#9090)PennyLane has been updated to use a uv lockfile for package dependency tracking. Added
UV_SYSTEM_PYTHONto the repository’s nightly sync workflows. Removed stable dependency folder and files. (#8755) (#9110) (#9218)sybilhas been added to thedevdependency group inpyproject.toml. (#9060)Seeded a test
tests/measurements/test_classical_shadow.py::TestClassicalShadow::test_return_distributionto fix stochastic failures by adding aseedparameter to the circuit helper functions and the test method. (#8981)Standardized the tolerances of several stochastic tests to use a 3-sigma rule based on theoretical variance and number of shots, reducing spurious failures. This includes
TestHamiltonianSamples::test_multi_wires,TestSampling::test_complex_hamiltonian, andTestBroadcastingPRNG::test_nonsample_measure. Bumpedrng_salttov0.45.0. (#8959) (#8958) (#8938) (#8908) (#8963)The test helper
get_devicehas been updated to correctly seed Lightning devices. (#8942)Updated internal dependencies:
autoray(to 0.8.4) andtach(to 0.32.2). (#8911) (#8962) (#9030)The
torchdependency has been relaxed from==2.9.0to~=2.9.0to allow for compatible patch updates. (#8911)Internal calls to the
decomposetransform have been updated to provide atarget_gatesargument so that they are compatible with the new graph-based decomposition system. (#8939)A
qp.decomposition.toggle_graph_ctxcontext manager has been added to temporarily enable or disable graph-based decompositions in a thread-safe way. The fixtures"enable_graph_decomposition","disable_graph_decomposition", and"enable_and_disable_graph_decomp"have been updated to use this method so that they are thread-safe. (#8966)Specialized gate kernels have been added for
RX,RY,RZ, andHadamardin thedefault.qubitdevice. These bypass generic einsum/tensordot dispatches and use direct contractions for NumPy states, with correct fallbacks for autodiff interfaces (Autograd, Torch, JAX). (#9075)
Documentation 📝
The README has been updated to better introduce PennyLane. (#9370)
The
qmlalias as inimport pennylane as qmlhas been updated toqpin our source code and documentation. (#9310) (#9317) (#9320) (#9315) (#9312) (#9314) (#9319) (#9313) (#9326) (#9333) (#9331) (#9329) (#9280) (#9327) (#9330) (#9325) (#9358) (#9281) (#9360) (#9376) (#9375) (#9384) (#9397)Docstrings for several optimization transforms have been improved by showing the drawing of the circuit after the transform has been applied as opposed to just the numeric simulation result, making it clearer that they can be applied to both QNodes and quantum functions, and clarifying discrepancies when using with qjit where applicable. The improved transform docstrings include
cancel_inverses,commute_controlled,merge_amplitude_embedding,merge_rotations,pattern_matching_optimization,remove_barrier,single_qubit_fusion,undo_swaps,combine_global_phases,compile,decompose,transpile, andunitary_to_rot. (#9381) (#9441)A new AI policy document is now applied across the PennyLaneAI organization for all AI contributions. (#9079)
Wide-spread changes have been made to our documentation to recommend using program capture with
qjitonly, and enabling it viaqjit(capture=True)instead of the global toggle (qp.capture.enable()). (#9059)TensorFlow related documentation has been updated to clarify that maintenance support has been dropped since PennyLane v0.44. (#9362)
The
pennylane.transformsmodule has been reorganized to allow for easier indexing through available transforms in PennyLane. (#9130)The docstrings for
cancel_inverses(),merge_rotations(), andcombine_global_phases()now has a “Usage with qjit” section to outline what the transform does when used with Catalyst. (#9134) (#9386)Docstring examples in the Pauli-based computation module have been updated to reflect the QEC-to-PBC dialect rename in Catalyst. References to
qec.fabricateandqec.prepareare nowpbc.fabricateandpbc.prepare. (#9071)Two warning notes have been removed from the
gridsynth()docstring as we now issue a warning when users provide epsilon smaller than1e-6, and simulation of PPRs is now possible. (#9221)The documentation of the QASM interpreter class has been updated to include
Raiseserror sections for its methods. (#9244)A typo causing a rendering issue in the docstring for
QNodehas been fixed. (#8652)A typo in the docstring for
ControlledOpwas fixed and theControlleddocstring recommends usingctrlinstead. (#7154)A note has been added to the documentation of
estimate()to clarify that an error will be raised if aResourceOperatoris encountered that does not have a resource decomposition defined and it is not in the providedgate_set. (#9230)The documentation of the
shadow_expval()measurement has been refined to clarify the role of theseedkeyword argument and include instructions for achieving reproducible results with this argument. (#9216)The definition of the
pipelineargument forcompile()was clarified in its documentation. (#9159)A typo in the type of a parameter in the docstring of
BasicEntanglerLayershas been fixed. (#9046)Infrastructure has been put in place for features that should be accessible from both PennyLane and Catalyst to have a single source of truth for documentation, which will provide a better overall experience when consulting our documentation. (#9020)
The process for Catalyst frontend features to be automatically accessible from PennyLane, while ensuring that such features’ documentation is properly sourced from Catalyst and hosted on PennyLane’s documentation, has been outlined in the documentation development guide under the section titled “Making Catalyst functionality callable from PennyLane”. Related work in Catalyst can be found in (#2409).
Though the documentation for this function is now solely in the Catalyst repository, a correction was made in the output of the code example for
decompose_arbitrary_ppr()while the documentation still resided in the PennyLane repository. (#9116)Fixed the docstring of
FermiSentencethat incorrectly claims that it is immutable. (#9278)Fixed a typo in the documentation for
qre.SelectPauli. (#9373)Broken documentation links to external demos and tutorials have been fixed by replacing hardcoded URLs with proper
:doc:cross references. (#9356)The description of NumPy array slicing used to get the subspace of a density matrix is now more clear in the docs of
_phase_shift. (#9246) (#9432)
Bug fixes 🐛
SProd.is_verified_hermitiancan now be calculated with abstract (jax tracer) coefficients. (#9446)Fixed a bug where
specs()would fail in multi-threaded or multi-processed settings. (#9420)Fixed a bug where
ParametrizedHamiltonian,HardwareHamiltonian, andParametrizedEvolutiondid not follow PennyLane’s queuing convention. They have been updated to de-queue their input operators and queue themselves like other PennyLane gate objects (that derive fromOperator). (#9423)Fixed a bug where the Pytree structure of the following operators were inconsistent with the structure of their data:
Pow,QPE,GQSP,estimator.qpe_resources.FirstQuantization, andestimator.qpe_resources.DoubleFactorization. (#9378)Fixed a bug where
Reflectiondid not queue all operators of its decomposition. (#9378)Fixed a bug where
Hermitiandid not queue its decomposition. (#9378)Fixed a bug in the decomposition of
Adjoint(TemporaryAND)where control values were ignored. (#9303)Fixed a bug where
debug_state,debug_probs, anddebug_expvalall mutated the circuit they participated in, leading to incorrect results. (#9344)MultiControlledXis now compatible withqjit. An issue withjax.jittracing for controlled single-qubit unitary decompositions inpennylane.ops.op_math.decompositions.controlled_decompositionshas been fixed by ensuring consistent return types across conditional branches and casting wires to JAX-friendly types during tracing. (#9306)Fixed a warning of casting complex values to reals within
qp.math.givens_decomposition. (#9155)Fixed a bug with program capture when a transform is applied to a QNode with a dynamic number of shots and return
qp.sample. (#9342)Fixed wire overlap validation in
QROMandSelectto support JAX-traced wires, enablingqp.QROMto be used withqjitwhen wires are passed as dynamic arguments. (#9282)Fixed an issue with Catalyst and
qp.for_loopandqp.while_loop, where it was defaulting toallow_array_resizing=Trueinstead ofallow_array_resizing=False. (#9251)Fixed a bug where the
work_wire_typeargument ofctrl()was silently dropped when the call was delegated to the active compiler (qjit()). The parameter is now forwarded to the compiler’sctrlimplementation. (#9328)Workflows with program capture that involve dynamic device wires will now raise a
NotImplementedErrorrather than providing incorrect results. (#9248)Fixed a bug in
estimatorwhere theResourcesUndefinedErrorwas being returned as a class type rather than an instance, preventing the intended diagnostic message from being displayed. (#9229)Fixed a bug where the data file
transforms/sign_expand/sign_expand_data.jsonwas not included in the source distribution, causing errors when usingqp.transforms.sign_expandin a production environment. (#9210)Fixed a bug where
qp.math.givens_decompositionmodified the input in place when usingqjit. (#9155)Fixed a bug where the hashable parameters of a
CompressedResourceOpin the graph-based decomposition system were sensitive to the insertion order of keyword arguments/hyperparameters. (#9137)Jacobian-level caching is now unconditionally enabled for the
autogradinterface, preventing redundant derivative tape executions during the backward pass. (#9081)Fixed a bug where
qp.transforms.transpilewould fail whenqp.GlobalPhasegates were present in a circuit. (#9041)Fixed a bug where
LinearCombinationdid not correctly de-queue the constituents of an operator product via the dunder method__matmul__. (#9029)Fixed
map_wiresandequal()withControlledinstances to handle thework_wire_typecorrectly withinmap_wires. Also fixedControlled.map_wiresto preservework_wires. (#9010)The tolerance used in determining whether the norm of the probabilities is sufficiently close to 1 in
default.qubithas been increased to1e-6. (#9014)A bug was fixed that prevents decompositions in the graph-based system from using nested operator products while reporting their resources accurately. (#8773)
decomp_int_to_powers_of_twonow adheres to standard 64-bit C integer bounds, fixing runtime warnings associated with integer overflow. (#8993)CompilePipelineno longer automatically pushes final transforms to the end of the pipeline as it’s being built. (#8995)The error message was improved for when the number of inputs to a
qp.for_loop-decorated function is not one greater than the number of outputs. (#8984)Fixed a bug that
qp.QubitDensityMatrixwas applied indefault.mixeddevice usingqp.math.partial_traceincorrectly. This would cause wrong results as described in this issue. (#8933)Fixed an issue when binding a transform when the first positional arg is a
Sequence, but not aSequenceof tapes. (#8920)Fixed a bug with
qp.estimator.templates.QSVTwhich allows users to instantiate the class without providing wires. This is now consistent with the standard in the estimator module. (#8949)Fixed a bug where decomposition raises an error for
Powoperators when the exponent is batched. (#8969)Fixed a bug where the
DecomposeInterpretercannot be applied on a QNode with the new graph-based decomposition system enabled. (#8965)Fixed a bug where
qp.equalraises an error forSProdwith abstract scalar parameters andExpwith abstract coefficients. (#8965)Fixed various issues found with decomposition rules for
QubitUnitary,BasisRotation,StronglyEntanglingLayers. (#8965)The
decomposetransform no longer warns about being unable to decomposeBarrierandSnapshot. (#9001)When the new graph-based decomposition system is enabled,
Expno longer decomposes to nothing when the exponent is the identity. Instead, aPauliRotis always produced, which in this case decomposes to aGlobalPhase. (#9001)Fixed a bug where the graph-based decomposition system was unable to find a decomposition for a
ControlledQubitUnitarywith more than two target wires. (#9036)Fixed a discontinuity in the gradient of the single-qubit unitary decompositions. (#9036)
Fixed a
MemoryErrorindefault.cliffordwhen preparing aBasisStatewith a large number of wires. (#9018)Fixed a bug where a controlled
ChangeOpBasiswas sometimes decomposed inefficiently when the graph-based system is enabled. (#9161)Fixed a bug where the decomposition graph was unable to find trivial decompositions of
qp.X(0) ** 1andqp.X(0) ** 0. (#9152)Fixed various small bugs within
pennylane.estimator, including: (#9194)The resource decompositions for
estimator.QubitUnitaryandestimator.OutMultiplierso that they match the results from literatureIncorrect wire mapping when converting
QuantumPhaseEstimationtoestimator.QPEAdded support for mapping
BarrierandSnapShottoestimator.Identity
Fixed a bug in the
C(SemiAdder)decomposition where incorrect results were produced for a specific wire configuration. (#9270)Fixed a bug where the
DecompositionGraphwould underestimate the minimum number of work wires required to solve for a particular operator. This occurred when rules with lower wire requirements existed but were unreachable within the provided gate set. (#9298)Fixed a bug that prevented instances of controlled composite operators such as
Controlled(2.0 * qp.X(0))from being unpickled. (#9366)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso, Ali Asadi, Astral Cai, Yushao Chen, Isaac De Vlugt, Diksha Dhawan, Olivia Di Matteo, Marcus Edwards, Lillian Frederiksen, Diego Guala, Sengthai Heng, Jacob Kitchen, Korbinian Kottmann, Christina Lee, Joseph Lee, Anton Naim Ibrahim, Oumarou Oumarou, Mudit Pandey, Andrija Paurevic, Alex Preciado, David D.W. Ren, Gabriela Sanchez Diaz, Omkar Sarkar, Jay Soni, Nate Stemen, David Wierichs, Fuyuan Xia, Jake Zaia, Hong-Sheng Zheng.
Release 0.44.1¶
Bug fixes 🐛
The
gastpackage is now an explicit dependency in PennyLane. Thegastpackage was previously pulled in transitively bydiastatic-malt, butdiastatic-malt==2.15.3droppedgastas a dependency, which caused an error when importing PennyLane. (#9160)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Yushao Chen, Andrija Paurević, David Wierichs
Release 0.44.0¶
New features since last release
Quantum Random Access Memory (QRAM) 💾
Three implementations of QRAM are now available in PennyLane, including Bucket Brigade QRAM (
BBQRAM), a Select-Only QRAM (SelectOnlyQRAM), and a Hybrid QRAM (HybridQRAM) that combines behaviour from bothBBQRAMandSelectOnlyQRAM. The choice of QRAM implementation depends on the application, ranging from width versus depth tradeoffs to noise resilience. (#8670) (#8679) (#8680) (#8801)Irrespective of the specific implementation, QRAM encodes bitstrings, \(b_i\), corresponding to a given entry, \(i\), of a data set of length \(N\), and can do so in superposition: \(\text{QRAM} \sum_i c_i \vert i \rangle \vert 0 \rangle = \sum_i c_i \vert i \rangle \vert b_i \rangle\). Here, the first register representing \(\vert i \rangle\) is called the
control_wiresregister (often referred to as the “address” register in literature), and the second register containing \(\vert b_i \rangle\) is called thetarget_wiresregister (where the \(i^{\text{th}}\) entry of the data set is loaded).Each QRAM implementation available in this release can be briefly described as follows:
BBQRAM: a bucket-brigade style QRAM implementation that is also resilient to noise.SelectOnlyQRAM: a QRAM implementation that comprises a series ofMultiControlledXgates.HybridQRAM: a QRAM implementation that combinesBBQRAMandSelectOnlyQRAMin a manner that allows for tradeoffs between depth and width.
An example of using
BBQRAMto read data into a target register is given below, where the data set in question is given by a list ofbitstringsand we wish to read its second entry ("110"):import pennylane as qml bitstrings = ["010", "111", "110", "000"] bitstring_size = 3 num_control_wires = 2 # len(bitstrings) = 4 = 2**2 num_work_wires = 1 + 3 * ((1 << num_control_wires) - 1) # 10 reg = qml.registers( { "control": num_control_wires, "target": bitstring_size, "work_wires": num_work_wires } ) dev = qml.device("default.qubit") @qml.qnode(dev) def bb_quantum(): # prepare an address, e.g., |10> (index 2) qml.BasisEmbedding(2, wires=reg["control"]) qml.BBQRAM( bitstrings, control_wires=reg["control"], target_wires=reg["target"], work_wires=reg["work_wires"], ) return qml.probs(wires=reg["target"])
>>> import numpy as np >>> print(np.round(bb_quantum())) [0. 0. 0. 0. 0. 0. 1. 0.]
Note that
"110"in binary is equal to 6 in decimal, which is the position of the only non-zero entry in thetarget_wiresregister.For more information on each implementation of QRAM in this release, check out their respective documentation pages:
BBQRAM,SelectOnlyQRAM, and:class:~.HybridQRAM.A lightweight representation of the
BBQRAMtemplate calledqml.estimator.BBQRAMhas been added for fast and efficient resource estimation. (#8825)Like with other existing lightweight representations of PennyLane operations, leveraging
qml.estimator.BBQRAMfor fast resource estimation can be done in two ways:Using
qml.estimator.BBQRAMdirectly inside of a function and then callingestimate:import pennylane.estimator as qre def circuit(): qre.CNOT() qre.QFT(num_wires=4) qre.BBQRAM(num_bitstrings=30, size_bitstring=8, num_wires=100) qre.Hadamard()
>>> print(qre.estimate(circuit)()) --- Resources: --- Total wires: 100 algorithmic wires: 100 allocated wires: 0 zero state: 0 any state: 0 Total gates : 4.504E+3 'Toffoli': 1.096E+3, 'T': 792, 'CNOT': 2.475E+3, 'Z': 120, 'Hadamard': 21
On a simulatable circuit with detailed information:
bitstrings = ["010", "111", "110", "000"] bitstring_size = 3 num_control_wires = 2 # len(bistrings) = 4 = 2**2 num_work_wires = 1 + 3 * ((1 << num_control_wires) - 1) # 10 reg = qml.registers( { "control": num_control_wires, "target": bitstring_size, "work_wires": num_work_wires } ) dev = qml.device("default.qubit") @qml.qnode(dev) def bb_quantum(): # prepare an address, e.g., |10> (index 2) qml.BasisEmbedding(2, wires=reg["control"]) qml.BBQRAM( bitstrings, control_wires=reg["control"], target_wires=reg["target"], work_wires=reg["work_wires"], ) return qml.probs(wires=reg["target"])
>>> print(qre.estimate(bb_quantum)()) --- Resources: --- Total wires: 15 algorithmic wires: 15 allocated wires: 0 zero state: 0 any state: 0 Total gates : 181 'Toffoli': 40, 'CNOT': 128, 'X': 1, 'Z': 6, 'Hadamard': 6
Quantum Automatic Differentiation 🤖
The Hadamard test gradient method (
diff_method="hadamard") in PennyLane now has an"auto"mode, which automatically chooses the most efficient mode of differentiation. (#8640) (#8875)The Hadamard test gradient method is a hardware-compatible differentiation method that can differentiate a broad range of parameterized gates. Using the
"auto"mode withdiff_method="hadamard"will result in an automatic selection of the method (either"standard","reversed","direct", or"reversed-direct") which results in the fewest total executions. This takes into account the number of observables, the number of generators, the number of measurements, and the presence of available auxiliary wires. For more details on how"auto"works, consult the section titled “Variants of the standard hadamard gradient” in the documentation for the Hadamard test gradient (qml.gradients.hadamard_grad).The
"auto"method can be accessed by specifying it ingradient_kwargsin the QNode when usingdiff_method="hadamard":dev = qml.device('default.qubit') @qml.qnode(dev, diff_method="hadamard", gradient_kwargs={"mode": "auto"}) def circuit(x): qml.evolve(qml.X(0) @ qml.X(1) + qml.Z(0) @ qml.Z(1) + qml.H(0), x) return qml.expval(qml.Z(0) @ qml.Z(1) + qml.Y(0))
>>> print(qml.grad(circuit)(qml.numpy.array(0.5))) 0.7342549405478683
Theoretical information on how each mode works can be found in arXiv:2408.05406.
Instantaneous Quantum Polynomial Circuits 💨
A new template for defining an Instantaneous Quantum Polynomial (
IQP) circuit has been added, as well as an associatedResourceOperatorfor resource estimation in theestimatormodule. These new features facilitate the simulation and resource estimation of large-scale generative quantum machine learning tasks. (#8748) (#8807) (#8749) (#8882)While
IQPcircuits belong to a class of circuits that are believed to be hard to sample from using classical algorithms, Recio-Armengol et al. showed in a recent paper titled Train on classical, deploy on quantum that such circuits can still be optimized efficiently.Here is a simple example showing how to define an
IQPcircuit and how to estimate the required quantum resources using theestimate()function:import pennylane as qml import pennylane.estimator as qre pattern = [[[0]],[[1]],[[0,1]]] @qml.qnode(qml.device('lightning.qubit', wires=2)) def circuit(): qml.IQP( weights=[1., 2., 3.], num_wires=2, pattern=pattern, spin_sym=False, ) return qml.state()
>>> res = qre.estimate(circuit)() >>> print(res) --- Resources: --- Total wires: 2 algorithmic wires: 2 allocated wires: 0 zero state: 0 any state: 0 Total gates : 138 'T': 132, 'CNOT': 2, 'Hadamard': 4
The expectation values of Pauli-Z type observables for parameterized
IQPcircuits can be efficiently evaluated with thepennylane.qnn.iqp_expval()function. This estimator function is based on a randomized method allowing for the efficient optimization of circuits with thousands of qubits and millions of gates.from pennylane.qnn import iqp_expval import jax num_wires = 2 ops = np.array([[0, 1], [1, 0], [1, 1]]) # binary array representing ops Z1, Z0, Z0Z1 n_samples = 1000 key = jax.random.PRNGKey(42) weights = np.ones(len(pattern)) pattern = [[[0]], [[1]], [[0, 1]]] expvals, stds = iqp_expval(ops, weights, pattern, num_wires, n_samples, key)
>>> print(expvals, stds) [0.14506625 0.17813912 0.18971463] [0.02614436 0.02615901 0.02615425]
For more theoretical details, check out our Fast optimization of instantaneous quantum polynomial circuits demo.
Arbitrary State Preparation 😎
A new template
MultiplexerStatePreparationis now available, allowing for the preparation of arbitrary states usingSelectPauliRotoperations. (#8581)Using
MultiplexerStatePreparationis analogous to using other state preparation techniques in PennyLane.probs_vector = np.array([0.5, 0., 0.25, 0.25]) dev = qml.device("default.qubit", wires = 2) wires = [0, 1] @qml.qnode(dev) def circuit(): qml.MultiplexerStatePreparation(np.sqrt(probs_vector), wires) return qml.probs(wires)
>>> np.round(circuit(), 2) array([0.5 , 0. , 0.25, 0.25])
For theoretical details, see arXiv:0208112.
Pauli-based computation 💻
New tools dedicated to fault-tolerant quantum computing (FTQC) research based on the Pauli-based computation (PBC) framework are now available! With this release, you can express, compile, and inspect workflows written in terms of Pauli product rotations (PPRs) and Pauli product measurements (PPMs), which are the building blocks for the PBC framework.
Writing circuits in terms of Pauli product measurements (PPMs) in PennyLane is now possible with the new
pauli_measure()function. Using this function in tandem withPauliRotto represent PPRs unlocks surface-code FTQC research spurred from A Game of Surface Codes. (#8461) (#8631) (#8623) (#8663) (#8692)The new
pauli_measure()function is currently only for analysis on thenull.qubitdevice, which allows for circuit inspection withspecs()anddraw().Using
pauli_measure()in a circuit is similar toqml.measure(a mid-circuit measurement), but requires that apauli_wordbe specified for the measurement basis:import pennylane as qml dev = qml.device("null.qubit", wires=3) @qml.qnode(dev) def circuit(): qml.Hadamard(0) qml.Hadamard(2) qml.PauliRot(np.pi / 4, pauli_word="XYZ", wires=[0, 1, 2]) ppm = qml.pauli_measure(pauli_word="XY", wires=[0, 2]) qml.cond(ppm, qml.X)(wires=1) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──H─╭RXYZ(0.79)─╭┤↗X├────┤ <Z> 1: ────├RXYZ(0.79)─│──────X─┤ 2: ──H─╰RXYZ(0.79)─╰┤↗Y├──║─┤ ╚════╝
You can use the
specs()function to easily determine the circuit’s resources. In this case, in addition to other gates, we can see that the circuit includes one PPR and one PPM operation (represented by thePauliRotandPauliMeasuregate types, respectively):>>> print(qml.specs(circuit)()['resources']) Total wire allocations: 3 Total gates: 5 Circuit depth: 4 Gate types: Hadamard: 2 PauliRot: 1 PauliMeasure: 1 Conditional(PauliX): 1 Measurements: expval(PauliZ): 1
Several
qjit-compatible compilation passes designed for Pauli-based computation are now available with this release, and are designed to work directly withpauli_measure()andPauliRotoperations. (#8609) (#8764) (#8762)The compilation passes included in this release are:
gridsynth(): This pass decomposes \(Z\)-basis rotations andPhaseShiftgates to either the Clifford+T basis or to other PPRs.@qml.qjit @qml.transforms.gridsynth @qml.qnode(qml.device("lightning.qubit", wires=1)) def circuit(x): qml.Hadamard(0) qml.RZ(x, 0) qml.PhaseShift(x * 0.2, 0) return qml.state()
>>> circuit(1.1) [0.60284353-0.36960984j 0.5076425 +0.4922066j ]
Seven transforms for compiling Clifford+T gates, PPRs, and/or PPMs, including
to_ppr(),commute_ppr(),merge_ppr_ppm(),ppr_to_ppm(),ppm_compilation(),reduce_t_depth(), anddecompose_arbitrary_ppr().@qml.qjit(target="mlir") @qml.transforms.to_ppr @qml.qnode(qml.device("null.qubit", wires=2)) def circuit(): qml.H(0) qml.CNOT([0, 1]) qml.T(0) return qml.expval(qml.Z(0))
>>> print(qml.specs(circuit, level=2)()) ... Resource specifications: Total wire allocations: 2 Total gates: 7 Circuit depth: Not computed Gate types: PPR-pi/4: 6 PPR-pi/8: 1 ...
Directly decomposing Clifford+T gates and other small gates into PPRs is possible using the
decompose()transform with graph-based decompositions enabled (enable_graph()). This allows direct decomposition of certain operators without the need to use approximate methods such as those found in theclifford_t_decomposition()transform, which can sometimes be less efficient. (#8700) (#8704) (#8857)The following operations have newly added decomposition rules in terms of PPRs (
PauliRot):To access these decompositions, simply specify a target gate set including
PauliRotandGlobalPhase. The following example illustrates how theCNOTgate can be represented in terms of three \(\tfrac{\pi}{2}\) PPRs (IX,ZIandZX) acting on two wires:from functools import partial qml.decomposition.enable_graph() @partial(qml.transforms.decompose, gate_set={qml.PauliRot, qml.GlobalPhase}) @qml.qnode(qml.device("null.qubit", wires=2)) def circuit(): qml.CNOT([0, 1]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──RZ(-1.57)─╭RZX(1.57)─╭GlobalPhase(0.79)───────────┤ <Z> 1: ──RX(-1.57)─╰RZX(1.57)─╰GlobalPhase(0.79)──RZ(3.14)─┤
Flexible and modular compilation pipelines 🦋
Defining large and complex compilation pipelines in intuitive, modular, and flexible ways is now possible with the new
CompilePipelineclass. (#8735) (#8750) (#8731) (#8817) (#8703) (#8730) (#8751) (#8774) (#8781) (#8834)The
CompilePipelineclass allows you to chain together multiple transforms to create custom circuit optimization pipelines with ease. For example,CompilePipelineobjects can compound:>>> pipeline = qml.CompilePipeline(qml.transforms.commute_controlled, qml.transforms.cancel_inverses) >>> qml.CompilePipeline(pipeline, qml.transforms.merge_rotations) CompilePipeline(commute_controlled, cancel_inverses, merge_rotations)
They can be added together with
+:>>> pipeline += qml.transforms.merge_rotations >>> pipeline CompilePipeline(commute_controlled, cancel_inverses, merge_rotations)
They can be multiplied by scalars via
*to repeat compilation passes a predetermined number of times:>>> pipeline += 2 * qml.transforms.cancel_inverses(recursive=True) >>> pipeline CompilePipeline(commute_controlled, cancel_inverses, merge_rotations, cancel_inverses, cancel_inverses)
Finally, they can be modified via
listoperations likeappend,extend, andinsert:>>> pipeline.insert(0, qml.transforms.remove_barrier) >>> pipeline CompilePipeline(remove_barrier, commute_controlled, cancel_inverses, merge_rotations, cancel_inverses, cancel_inverses)
By applying a created
pipelinedirectly on a quantum function as a decorator, each compilation pass therein will be applied to the circuit:import pennylane as qml pipeline = qml.transforms.merge_rotations + qml.transforms.cancel_inverses(recursive=True) @pipeline @qml.qnode(qml.device("default.qubit")) def circuit(): qml.H(0) qml.H(0) qml.RX(0.5, 1) qml.RX(0.2, 1) return qml.expval(qml.Z(0) @ qml.Z(1))
>>> print(qml.draw(circuit)()) 0: ───────────┤ ╭<Z@Z> 1: ──RX(0.70)─┤ ╰<Z@Z>
Analyzing algorithms quickly and easily with resource estimation 📖
A new
algo_error()function has been added to compute algorithm-specific errors from quantum circuits. This provides a dedicated entry point for retrieving error information that was previously accessible throughspecs(). (#8787)The function works with QNodes and returns a dictionary of error types and their computed values:
import pennylane as qml Hamiltonian = qml.dot([1.0, 0.5], [qml.X(0), qml.Y(0)]) dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.TrotterProduct(Hamiltonian, time=1.0, n=4, order=2) return qml.state()
>>> qml.resource.algo_error(circuit)() {'SpectralNormError': SpectralNormError(0.25)}
Fast resource estimation is now available for many algorithms, including:
The Generalized Quantum Signal Processing (GQSP) algorithm and its time evolution via the
qml.estimator.GQSPandqml.estimator.GQSPTimeEvolutionresource operations. (#8675)The Qubitization algorithm via two new resource operators:
qml.estimator.Reflectionandqml.estimator.Qubitization. (#8675)The Quantum Signal Processing (QSP) and Quantum Singular Value Transformation (QSVT) algorithms via two new resource operators:
qml.estimator.QSP. (#8733)The unary iteration implementation of QPE via the new
qml.estimator.UnaryIterationQPEsubroutine, which makes it possible to reduceTandToffoligate counts in exchange for using additional qubits. (#8708)Trotterization for Pauli Hamiltonians, using the new
qml.estimator.PauliHamiltonianresource Hamiltonian class and the newqml.estimator.TrotterPauliresource operator. (#8546) (#8761)>>> import pennylane.estimator as qre >>> pauli_terms = {"X": 10, "XX": 5, "XXXX": 3, "YY": 5, "ZZ":5, "Z": 2} >>> pauli_ham = qre.PauliHamiltonian(num_qubits=10, pauli_terms=pauli_terms) >>> res = qre.estimate(qre.TrotterPauli(pauli_ham, num_steps=1, order=2)) >>> res.total_gates 2844
The
PauliHamiltonianobject also makes it easy to access the total number of terms (Pauli words) in the Hamiltonians with thePauliHamiltonian.num_termsproperty:>>> pauli_ham.num_terms 30
Linear combination of unitaries (LCU) representations of
qml.estimator.PauliHamiltonianHamiltonians via the newqml.estimator.SelectPaulioperator. (#8675)
The new
resource_keykeyword argument of theResourceConfig.set_precisionmethod makes it possible to set precisions for a larger variety ofResourceOperators in theestimatormodule, includingphase_grad_precisionandcoeff_precisionforTrotterVibronicandTrotterVibrational,rotation_precisionforGQSPandQSPandpoly_approx_precisionforGQSPTimeEvolution. (#8561)>>> vibration_ham = qre.VibrationalHamiltonian(num_modes=2, grid_size=4, taylor_degree=2) >>> trotter = qre.TrotterVibrational(vibration_ham, num_steps=10, order=2) >>> config = qre.ResourceConfig() >>> qre.estimate(trotter, config = config).total_gates 123867.0 >>> config.set_precision(qre.TrotterVibrational, precision=1e-10, resource_key='phase_grad_precision') >>> qre.estimate(trotter, config = config).total_gates 124497.0
Seamless inspection for compiled programs 👓
Analyzing resources throughout each step of a compilation pipeline can now be done on
qjit‘d workflows withspecs(), providing a pass-by-pass overview of quantum circuit resources. (#8606) (#8860)Consider the following
qjit’d circuit with two compilation passes applied:@qml.qjit @qml.transforms.merge_rotations @qml.transforms.cancel_inverses @qml.qnode(qml.device('lightning.qubit', wires=2)) def circuit(): qml.RX(1.23, wires=0) qml.RX(1.23, wires=0) qml.X(0) qml.X(0) qml.CNOT([0, 1]) return qml.probs()
The supplied
leveltospecs()can be an individualintvalue or an iterable of multiple levels. Additionally, the strings"all"and"all-mlir"are allowed, returning circuit resources for all user-applied transforms and MLIR passes, or all user-applied MLIR passes only, respectively.>>> print(qml.specs(circuit, level=[2, 3])()) Device: lightning.qubit Device wires: 2 Shots: Shots(total=None) Level: ['cancel-inverses (MLIR-1)', 'merge-rotations (MLIR-2)'] Resource specifications: Level = cancel-inverses (MLIR-1): Total wire allocations: 2 Total gates: 3 Circuit depth: Not computed Gate types: RX: 2 CNOT: 1 Measurements: probs(all wires): 1 ------------------------------------------------------------ Level = merge-rotations (MLIR-2): Total wire allocations: 2 Total gates: 2 Circuit depth: Not computed Gate types: RX: 1 CNOT: 1 Measurements: probs(all wires): 1
A new
marker()function allows for easy inspection at particular points in a set of applied compilation passes withspecs()anddraw()instead of having to incrementlevelby integer amounts. (#8684)The
marker()function works like a transform in PennyLane, and can be deployed as a decorator on top of QNodes:@qml.marker(level="rotations-merged") @qml.transforms.merge_rotations @qml.marker(level="my-level") @qml.transforms.cancel_inverses @qml.transforms.decompose(gate_set={qml.RX}) @qml.qnode(qml.device('lightning.qubit')) def circuit(): qml.RX(0.2,0) qml.X(0) qml.X(0) qml.RX(0.2, 0) return qml.state()
The string supplied to
marker()can then be used as an argument tolevelindrawandspecs, showing the cumulative result of applying transforms up to the marker:>>> print(qml.draw(circuit, level="my-level")()) 0: ──RX(0.20)──RX(3.14)──RX(3.14)──RX(0.20)─┤ State >>> print(qml.draw(circuit, level="rotations-merged")()) 0: ──RX(6.68)─┤ State
Note that
marker()is currently not compatible with programs compiled withqjit().
Improvements 🛠
Resource estimation
It is now easier to access the total gates and wires in resource estimates with the
total_wiresandtotal_gatesproperties in theqml.estimator.Resourcesclass. (#8761)import pennylane.estimator as qre def circuit(): qml.X(0) qml.Z(0) qml.Y(1)
>>> resources = qre.estimate(circuit)() >>> resources.total_gates 3 >>> resources.total_wires 2
The
QROMtemplate now uses fewer resources when argument values arerestored=Trueandsel_swap_depth=1. (#8761)The resource decomposition of
PauliRotnow matches the optimal resources when thepauli_stringargument isXXorYY. (#8562)It is now possible to estimate the resources for quantum circuits that contain or decompose into any of the following symbolic operators:
ChangeOpBasis,Prod,Controlled,ControlledOp,Pow, and/orAdjoint. (#8464)Qualtran call graphs built via
qml.to_bloqnow provide faster resource counting by using PennyLane’s resource estimation module. To use the previous behaviour based on PennyLane decompositions, setcall_graph='decomposition'. (#8390)The old behaviour was the following:
>>> qml.to_bloq(qml.QFT(wires=range(5)), map_ops=False, call_graph='decomposition').call_graph()[1] {Hadamard(): 5, ZPowGate(exponent=-0.15915494309189535, eps=1e-11): 10, ZPowGate(exponent=-0.15915494309189535, eps=5e-12): 10, ZPowGate(exponent=0.15915494309189535, eps=5e-12): 10, CNOT(): 20, TwoBitSwap(): 2 }
The new behaviour is now this:
>>> qml.to_bloq(qml.QFT(wires=range(5)), map_ops=False).call_graph()[1] {Hadamard(): 5, CNOT(): 26, TGate(is_adjoint=False): 1320}
The
CDFHamiltonian,THCHamiltonian,
VibrationalHamiltonian, andVibronicHamiltonianclasses have been modified to take the 1-norm of the Hamiltonian as an optional argument. (#8697)Input validation has been added to various operators and functions in the
estimatormodule to raise more informative errors. (#8835)The
ResourcesUndefinedErrorhas been removed from theadjoint,ctrl, andpowresource decomposition methods ofResourceOperatorto avoid using errors as control flow. (#8598) (#8811)
Decompositions
The graph-based decomposition system now supports basis-changing Clifford gates and decomposing
RX,RYandRZrotations into each other. (#8569)A new decomposition has been added for the Controlled
SemiAdder, which reduces the number of gates in its decomposition by controlling fewer gates. (#8423)A new
gate_setmethod has been added toDeviceCapabilitiesthat makes it easy to produce a set of gate names that are directly compatible with the given device. (#8522)>>> dev = qml.device('lightning.qubit') >>> dev.capabilities.gate_set() {'Adjoint(CNOT)', 'Adjoint(CRX)', 'Adjoint(CRY)', 'Adjoint(CRZ)', 'Adjoint(CRot)', ...
It is now possible to minimize the number of work wires in decompositions by activating the new graph-based decomposition system (
enable_graph()) and settingminimize_work_wires=Truein thedecompose()transform. The decomposition system will select decomposition rules that minimize the maximum number of simultaneously allocated work wires. (#8729) (#8734)A new decomposition rule has been added to
QubitUnitarywhich reduces the number of CNOTs used to decompose certain two-qubitQubitUnitaryoperations. (#8717)Operator decompositions now only need to be defined in the graph decomposition system, as
Operator.decompositionwill fallback to the first entry inqml.list_decompsif theOperator.compute_decompositionmethod is not overridden. (#8686)The
BasisRotationgraph decomposition can now scale to larger workflows withqjitas it has been re-written in aqjitfriendly way using PennyLane control flow. (#8560) (#8608) (#8620)The graph-based decompositions system enabled via
enable_graph()now additionally supports many existing templates. (#8520) (#8515) (#8516) (#8555) (#8558) (#8538) (#8534) (#8582) (#8543) (#8554) (#8616) (#8602) (#8600) (#8601) (#8595) (#8586) (#8614)The supported templates with this release include:
A new decomposition has been added to
Toffoli. This decomposition uses one work wire andTemporaryANDoperators to reduce the resources needed. (#8549)The
pauli_decompose()now supports decomposing scipy’s sparse matrices, allowing for efficient decomposition of large matrices that cannot fit in memory when written as dense arrays. (#8612)import scipy import numpy as np arr = np.array([[0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0]]) sparse = scipy.sparse.csr_array(arr)
>>> qml.pauli_decompose(sparse) 1.0 * (I(0) @ X(1) @ X(2))
The graph-based decomposition system now supports decomposition rules that contain mid-circuit measurements. (#8079)
A new decomposition has been added to the adjoint of
TemporaryANDthat relies on mid-circuit measurements and does not require anyTgates. (#8633)The decompositions for several templates have been updated to use
ChangeOpBasis, which makes their decompositions more resource-efficient by eliminating unnecessary controlled operations. The templates includePhaseAdder,TemporaryAND,QSVT, andSelectPauliRot. (#8490) (#8577) (#8721)The
clifford_t_decomposition()transform now uses the Ross-Selinger algorithm (method="gridsynth") as the default method for decomposing single-qubit Pauli rotation gates in the Clifford+T basis. The Solovay-Kitaev algorithm (method="sk") was used as default in previous releases. (#8862)
Other improvements
Quantum compilation passes in MLIR and xDSL can now be applied using the core PennyLane transform infrastructure, instead of using Catalyst-specific tools. This is made possible by a new argument in
transform()andTransformcalledpass_name, which accepts a string corresponding to the name of the compilation pass. Thepass_nameargument ensures that the given compilation pass will be used whenqjitis applied to a workflow, where the pass is performed in MLIR or xDSL. (#8539) (#8810)my_transform = qml.transform(pass_name="cancel-inverses") @qml.qjit @my_transform @qml.qnode(qml.device('lightning.qubit', wires=4)) def circuit(): qml.X(0) qml.X(0) return qml.expval(qml.Z(0))
For additional details see the “Transforms with Catalyst” section in
transform().When program capture is enabled,
qml.adjointandqml.ctrlcan now be called on operators that were constructed ahead of time and used as closure variables. (#8816)The constant to convert the length unit Bohr to Angstrom in
qml.qchemhas been updated to use scipy constants, leading to more consistent and standardized conversion. (#8537)Transform decorator arguments can now be defined without
@partial, leading to a simpler interface. (#8730) (#8754)For example, the following two usages are equivalent:
@partial(qml.transforms.decompose, gate_set={qml.RX, qml.CNOT}) @qml.qnode(qml.device('default.qubit', wires=2)) def circuit(): qml.Hadamard(wires=0) qml.CZ(wires=[0,1]) return qml.expval(qml.Z(0))
@qml.transforms.decompose(gate_set={qml.RX, qml.CNOT}) @qml.qnode(qml.device('default.qubit', wires=2)) def circuit(): qml.Hadamard(wires=0) qml.CZ(wires=[0,1]) return qml.expval(qml.Z(0))
TransformContainerhas been renamed toBoundTransform. The old name is still available in the same location. (#8753)More programs can be captured because
qml.for_loopnow falls back to a standard Pythonforloop if capturing a condensed, structured loop fails with program capture enabled. (#8615)qml.condwill now use standard Python logic if all predicates have concrete values, leading to shorter, more efficient jaxpr programs. Nested control flow primitives will no longer be captured as they are not needed. (#8634)Added a keyword argument
recursivetoqml.transforms.cancel_inversesthat enables recursive cancellation of nested pairs of mutually inverse gates. This allows the transform to cancel larger blocks of inverse gates without having to scan the circuit from scratch. By default, the recursive cancellation is enabled (recursive=True). To obtain the previous behaviour, disable it by settingrecursive=False. (#8483)qml.while_loopandqml.for_loopcan now lazily dispatch to Catalyst when called, instead of dispatching upon creation. (#8786)qml.gradandqml.jacobiannow lazily dispatch to Catalyst and program capture, allowing forqml.qjit(qml.grad(c))andqml.qjit(qml.jacobian(c))to work. (#8382)Both the generic and transform-specific application behavior of a
qml.transforms.core.TransformDispatchercan now be overwritten withTransformDispatcher.generic_registerandmy_transform.register, leading to easier customization of transforms. (#7797)With capture enabled, measurements can now be performed on
Operatorinstances passed as closure variables from outside the workflow scope. This makes it possible to define observables outside of a QNode and still measure them inside the QNode. (#8504)Wires can now be specified via the
rangefunction with program capture enabled and Autograph activated via@qml.qjit(autograph=True). (#8500)The
decompose()transform no longer raises an error if bothgate_setandstopping_conditionare provided, or ifgate_setis a dictionary, when the new graph-based decomposition system is disabled. (#8532)The
SelectTHCresource operation is upgraded to allow for a trade-off between the number of qubits and T-gates. This provides more flexibility in optimizing algorithms. (#8682)Added a custom solver to
qml.transforms.intermediate_reps.rowcolfor linear systems over \(\mathbb{Z}_2\) based on Gauss-Jordan elimination. This removes the need to install thegaloispackage for this single function and provides a performance improvement. (#8771)qml.measurecan now be used as a frontend forcatalyst.measure. (#8782)qml.condwill also accept a partial of an operator type as the true function without a false function when capture is enabled. (#8776)Solovay-Kitaev decomposition using the
clifford_t_decomposition()transform withmethod="sk"or directly viask_decomposition()now raises a more informativeRuntimeErrorwhen used with JAX-JIT orqjit(). (#8489)
Labs: a place for unified and rapid prototyping of research software 🧪
A new transform
qml.labs.transforms.select_pauli_rot_phase_gradienthas been added. This transform may reduce the number ofTgates in circuits withSelectPauliRotrotations by implementing them with a phase gradient resource state and semi-in-place addition (SemiAdder). (#8738)import pennylane as qml from pennylane.labs.transforms import select_pauli_rot_phase_gradient import numpy as np @qml.qnode(qml.device("default.qubit")) def select_pauli_rot_circ(phis): # prepare phase gradient state for i, w in enumerate([6,7,8,9]): qml.H(w) qml.PhaseShift(-np.pi / 2**i, w) for wire in [0,1]: qml.Hadamard(wire) qml.SelectPauliRot(phis, [0,1], 13, rot_axis="X") return qml.probs(13) phase_grad = select_pauli_rot_phase_gradient(select_pauli_rot_circ, angle_wires=[2,3,4,5], phase_grad_wires=[6,7,8,9], work_wires=[10,11,12], ) phis = [ (1 / 2 + 1 / 4 + 1 / 8) * 2 * np.pi, (1 / 2 + 1 / 4 + 0 / 8) * 2 * np.pi, (1 / 2 + 0 / 4 + 1 / 8) * 2 * np.pi, (0 / 2 + 1 / 4 + 1 / 8) * 2 * np.pi, ] clifford_T = qml.clifford_t_decomposition(select_pauli_rot_circ) clifford_T_phase_gradient = qml.clifford_t_decomposition(phase_grad)
>>> qml.specs(clifford_T)(phis).resources.gate_types['T'] 128 >>> qml.specs(clifford_T_phase_gradient)(phis).resources.gate_types['T'] 84
Breaking changes 💔
The
TransformProgramclass has been renamed toCompilePipeline. For backward compatibility, theTransformProgramclass can still be accessed frompennylane.transforms.core. For naming consistency, uses of the term “transform program” have been updated to “compile pipeline” across the codebase. Correspondingly, the modulepennylane.transforms.core.transform_programhas been renamed topennylane.transforms.core.compile_pipeline, and the old name is no longer available. (#8735)The class to dispatch transforms, the
TransformDispatcherclass, has been renamed toTransformand is now available asqml.transform. For backward compatibility, theTransformDispatcherclass can still be accessed frompennylane.transforms.core. (#8756)The
final_transformproperty of theBoundTransformhas been renamed tois_final_transformto better follow the naming convention for boolean properties. Thetransformproperty of theTransformandBoundTransformhas been renamed totape_transformto avoid ambiguity. (#8756)The output format of
specs()has been restructured into a dataclass to streamline the outputs. Some legacy information has been removed from the output, such as gradient and interface information. (#8713)Consider the following circuit:
dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.X(0) qml.Y(1) qml.Z(2) return qml.state()
The new
specs()output format is:>>> qml.specs(circuit)() Device: default.qubit Device wires: None Shots: Shots(total=None) Level: gradient Resource specifications: Total wire allocations: 3 Total gates: 3 Circuit depth: 1 Gate types: PauliX: 1 PauliY: 1 PauliZ: 1 Measurements: state(all wires): 1
Whereas previously,
specs()provided:>>> qml.specs(circuit)() {'resources': Resources(num_wires=3, num_gates=3, gate_types=defaultdict(<class 'int'>, {'PauliX': 1, 'PauliY': 1, 'PauliZ': 1}), gate_sizes=defaultdict(<class 'int'>, {1: 3}), depth=1, shots=Shots(total_shots=None, shot_vector=())), 'errors': {}, 'num_observables': 1, 'num_trainable_params': 0, 'num_device_wires': 3, 'num_tape_wires': 3, 'device_name': 'default.qubit', 'level': 'gradient', 'gradient_options': {}, 'interface': 'auto', 'diff_method': 'best', 'gradient_fn': 'backprop'}
The value
level=Noneis no longer a valid argument in the following:get_transform_program(),construct_batch(),draw(),draw_mpl(), andspecs(). Please uselevel='device'instead to apply all transforms. (#8477)The
max_work_wiresargument of thedecompose()transform has been renamed tonum_work_wires. This change is only relevant with graph-based decompositions (enabled viaenable_graph()). (#8769)QuantumScript.to_openqasmhas been removed. Please useto_openqasm()instead. This removes duplicated functionality for converting a circuit to OpenQASM code. (#8499)Providing
num_stepstoevolve(),exp(),Evolution, andExphas been disallowed. Instead, useTrotterProductfor approximate methods, providing thenparameter to perform the Suzuki-Trotter product approximation of a Hamiltonian with the specified number of Trotter steps. (#8474)As a concrete example, consider the following case:
>>> coeffs = [0.5, -0.6] >>> ops = [qml.X(0), qml.X(0) @ qml.Y(1)] >>> H_flat = qml.dot(coeffs, ops)
Instead of computing the Suzuki-Trotter product approximation as:
>>> qml.evolve(H_flat, num_steps=2).decomposition() [RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1]), RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1])]
The same result would now be obtained using
TrotterProductas follows:>>> decomp_ops = qml.adjoint(qml.TrotterProduct(H_flat, time=1.0, n=2)).decomposition() >>> [simp_op for op in decomp_ops for simp_op in map(qml.simplify, op.decomposition())] [RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1]), RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1])]
Access to
add_noise,insertand noise mitigation transforms from thepennylane.transformsmodule has been removed. Instead, these functions should be imported from thepennylane.noisemodule. (#8477)qml.qnn.cost.SquaredErrorLosshas been removed. Instead, this hybrid workflow can be accomplished with a function such asloss = lambda *args: (circuit(*args) - target)**2. (#8477)Some unnecessary methods of the
CircuitGraphclass have been removed: (#8477)print_contentswas removed in favor ofprint(obj)observables_in_orderwas removed in favor ofobservablesoperations_in_orderwas removed in favor ofoperationsancestors_in_order(obj)was removed in favor ofancestors(obj, sort=True)descendants_in_order(obj)was removed in favor ofdescendants(obj, sort=True)
pennylane.devices.DefaultExecutionConfighas been removed. Instead, useExecutionConfig()to create a default execution configuration. (#8470)Specifying the
work_wire_typeargument inctrl()and other controlled operators as"clean"or"dirty"is disallowed. Use"zeroed"to indicate that the work wires are initially in the \(|0\rangle\) state, and"borrowed"to indicate that the work wires can be in any arbitrary state. In both cases, the work wires are assumed to be restored to their original state upon completing the decomposition. (#8470)QuantumScript.shapeandQuantumScript.numeric_typeare removed. The correspondingMeasurementProcessattributes and methods should be used instead. (#8468)MeasurementProcess.expandhas been removed.qml.tape.QuantumScript(mp.obs.diagonalizing_gates(), [type(mp)(eigvals=mp.obs.eigvals(), wires=mp.obs.wires)])should be used instead. (#8468)The
qml.QNode.add_transformmethod is removed. Instead, please useQNode.transform_program.push_back(transform_container=transform_container). (#8468)The
dynamic_one_shot()transform can no longer be applied directly on a QNode. Instead, specify the mid-circuit measurement method in QNode:@qml.qnode(..., mcm_method="one-shot"). (8781)The
qml.compiler.python_compilersubmodule has been removed from PennyLane. It has been migrated to Catalyst, available ascatalyst.python_interface. (#8662)qml.transforms.map_wiresno longer supports transforming jaxpr directly. (#8683)qml.cond, theQNode, transforms,qml.grad, andqml.jacobianno longer treat all keyword arguments as static arguments. They are instead treated as dynamic, numerical inputs, matching the behaviour of JAX and Catalyst. (#8290)
Deprecations 👋
Maintenance support of NumPy<2.0 is deprecated as of v0.44 and will be completely dropped in v0.45. Future versions of PennyLane will only work with NumPy>=2.0. We recommend upgrading your version of NumPy to benefit from enhanced support and features. (#8578) (#8497)
Passing a function to the
gate_setargument in thedecompose()transform is deprecated. Thegate_setargument expects a static iterable of operator type and/or operator names, and the function should be passed to thestopping_conditionargument instead. (#8533)The example below illustrates how you can provide a function as the
stopping_conditionin addition to providing agate_set. The decomposition of each operator will halt upon reaching the gates in thegate_setor when thestopping_conditionis satisfied.import pennylane as qml @qml.transforms.decompose(gate_set={"H", "T", "CNOT"}, stopping_condition=lambda op: len(op.wires) <= 2) @qml.qnode(qml.device("default.qubit")) def circuit(): qml.Hadamard(wires=[0]) qml.Toffoli(wires=[0,1,2]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──H────────╭●───────────╭●────╭●──T──╭●─┤ <Z> 1: ────╭●─────│─────╭●─────│───T─╰X──T†─╰X─┤ 2: ──H─╰X──T†─╰X──T─╰X──T†─╰X──T──H────────┤
Access to the following functions and classes from the
resourcesmodule are deprecated. Instead, these functions must be imported from theestimatormodule. (#8484)qml.estimator.estimate_shotsrather thanqml.resources.estimate_shotsqml.estimator.estimate_errorrather thanqml.resources.estimate_errorqml.estimator.FirstQuantizationrather thanqml.resources.FirstQuantizationqml.estimator.DoubleFactorizationrather thanqml.resources.DoubleFactorization
The
argnumparameter has been renamed toargnumsforgrad,jacobian,jvp()andvjp()to better adhere to conventions in JAX and Catalyst. (#8496) (#8481)The
custom_decompskeyword argument toqml.devicehas been deprecated and will be removed in 0.45. Instead, withenable_graph(), new decomposition rules can be defined as quantum functions with registered resources. Seepennylane.decompositionfor more details.qml.measure,qml.measurements.MidMeasureMP,qml.measurements.MeasurementValue, andqml.measurements.get_mcm_predicatesare now located inqml.ops.mid_measure.MidMeasureMPhas been renamed toMidMeasure.qml.measurements.find_post_processed_mcmsis nowqml.devices.qubit.simulate._find_post_processed_mcms, and is being made private, as it is a utility for tree-traversal mid-circuit measurements. (#8466)The
pennylane.operation.Operator.is_hermitianproperty has been deprecated and renamed topennylane.operation.Operator.is_verified_hermitianas it better reflects the functionality of this property. Access throughpennylane.operation.Operator.is_hermitianis deprecated and will be removed in v0.45. Alternatively, consider using theis_hermitian()function instead for a thorough verification of hermiticity, at a higher computational cost. (#8494)The
pennylane.devices.preprocess.mid_circuit_measurements()transform is deprecated. Instead, the device should determine which MCM method to use, and explicitly include relevant preprocessing transforms if necessary. (#8467)
Internal changes ⚙️
The
_grad.pyfile has been split into multiple files within a folder for improved source code organization. (#8800)The
pyproject.tomlhas been updated with project dependencies to replace the requirements files. Workflows have also been updated to use installations frompyproject.toml. (8702)Some error handling has been updated in tests, to adjust to Python 3.14;
get_type_stradded a special branch to handleUnion. The import ofnetworkxis softened to not occur on import of PennyLane to work around a bug in Python 3.14.1. (#8568) (#8737)The
jaxversion has been updated to0.7.1for thecapturemodule. (#8715) (#8701)Improved error handling when using PennyLane’s experimental program capture functionality with an incompatible JAX version. (#8723)
The
autoraypackage version has been updated to0.8.2. (#8674)Updated the schedule of nightly TestPyPI uploads to occur at the end of all weekdays rather than the beginning of all weekdays. (#8672)
A github workflow was added to bump Catalyst and Lightning versions in the release candidate (RC) branch, create a new release tag and draft release, tag the RC branch, and create a PR to merge the RC branch into master. (#8352)
Added
MCM_METHODandPOSTSELECT_MODEStrEnumobjects to improve validation and handling ofMCMConfigcreation. (#8596)In program capture, transforms now have a single transform primitive with a
transformparam that stores theTransform. Before, each transform had its own primitive stored on theTransform._primitiveprivate property. (#8576) (#8639)Updated documentation check workflow to run on pull requests on
v[0-9]+\.[0-9]+\.[0-9]+-docsbranches. (#8590)When program capture is enabled, there is no longer caching of the jaxpr on the QNode. (#8629)
The
gradandjacobianprimitives now store the function underfn. There is also now a singlejacobian_pprimitive for use in program capture. (#8357)The versions for
pylint,isortandblackinformat.ymlhave been updated. (#8506)Reclassified
registersas a tertiary module for use withtach. (#8513)The
LegacyDeviceFacadewas refactored to implementsetup_execution_configandpreprocess_transformsseparately as opposed to implementing a singlepreprocessmethod. Additionally, themid_circuit_measurementstransform has been removed from the preprocess transform program. Instead, the best mcm method is chosen insetup_execution_config. By default, thecapabilitiesdictionary is queried for the"supports_mid_measure"property. If the underlying device defines a TOML file, thesupported_mcm_methodsfield in the TOML file is used as the source of truth. (#8469) (#8486) (#8495)The various private functions of the
qml.estimator.FirstQuantizationclass have been modified to avoid usingnumpy.matrixas this function is deprecated. (#8523)The
ftqcmodule now includes dummy transforms for several Catalyst/MLIR passes (to-ppr,commute-ppr,merge-ppr-ppm,decompose-clifford-ppr,decompose-non-clifford-ppr,ppr-to-ppm,ppr-to-mbqcandreduce-t-depth), to allow them to be captured as primitives in PLxPR and mapped to the MLIR passes in Catalyst. This enables using the passes with the unified compiler and program capture. (#8519) (#8544)Added a
skip_decomp_matrix_checkargument topennylane.ops.functions.assert_valid()that allows the test to skip the matrix check part of testing a decomposition rule but still verify that the resource function is correct. (#8687)Simplified the decomposition pipeline for the
estimatormodule.qml.estimator.estimate()was updated to call the base class’ssymbolic_resource_decompmethod directly. (#8641)Disabled autograph for the
PauliRotdecomposition rule, as it should not be used. (#8765)
Documentation 📝
Minor corrections in the docstring code examples for
QAOAEmbeddingandParticleConservingU1were made. (#8895)A note was made in the documentation of
qml.transforms.decomposefor its behaviour when graph-based decompositions are enabled withqjitpresent. It clarifies that, when used withqjit, non-deterministic graph solutions may lead to non-executable programs if intermediate gates are not executable by Catalyst. (#8894)The code example in the documentation for
qml.decomposition.register_resourceshas been updated to adhere to renamed keyword arguments and default behaviour ofnum_work_wires. (#8550)A note clarifying that the factors of a
ChangeOpBasisare iterated in reverse order has been added to the documentation ofChangeOpBasis. (#8757)The documentation of
qml.transforms.rz_phase_gradienthas been updated with respect to the sign convention of phase gradient states, how it prepares the phase gradient state in the code example, and the verification of the code example result. (#8536)The docstring for
qml.devicehas been updated to include a section on custom decompositions, and a warning about the removal of thecustom_decompskwarg in v0.45. Additionally, the Building a plugin page now includes instructions on using thedecompose()transform for device-level decompositions. The documentation for Compiling circuits has also been updated with a warning message aboutcustom_decompsfuture removal. (#8492) (#8564)The documentation for
GeneralizedAmplitudeDampinghas been updated to match the standard convention in literature for the definition of the Kraus matrices. (#8707)Improved documentation in the
pennylane.transformsmodule and added documentation testing. (#8557)Updated various docstring examples in the
fouriermodule to be compatible with the new documentation testing approach. (#8635)The
estimatormodule documentation has been revised for clarity. (#8827) (#8829) (#8830) (#8832) (#8892)
Bug fixes 🐛
Fixed the difference between the output dimensions of the dynamic one-shot and single-branch-statistics mid-circuit measurement methods. (#8856)
Fixed a bug in
qml.estimator.QubitizeTHCwhere specified arguments forPrepareandSelectresource operators were being ignored in favor of default ones. [(#8858)] (https://github.com/PennyLaneAI/pennylane/pull/8858)Fixed a bug in
torch.vmapthat produced an error when it was used with native parameter broadcasting andqml.RZ. (#8760)Fixed various incorrect decomposition rules. (#8812)
Fixed a bug where
_double_factorization_compressed\ ``ofpennylane/qchem/factorization.pyused to useXforZ`` parameter initialization. (#8689)Fixed some numerical stability issues of
apply_uniform_rotation_daggerby using a fixed floating-point number tolerance fromnp.finfo. (#8780)Fixed handling of floating-point errors in the norm of the state when applying mid-circuit measurements. (#8741)
Updated
interface-unit-tests.ymlto use the input parameterpytest_additional_argswhen running pytest. (#8705)Fixed a bug in
resolve_work_wire_typewhich incorrectly returned a value ofzeroedifboth work_wiresandbase_work_wireswere empty, causing an incorrect work wire type. (#8718)Fixed the warnings-as-errors CI action which was failing due to an incompatibility between
pytest-xdistandpytest-benchmark. Disabling the benchmark package allows the tests to be collected and executed. (#8699)Added a missing
expand_transformtoparam_shift_hessianto pre-decompose operations until they are supported. (#8698)Fixed a bug in the
default.mixeddevice where certain diagonal operations were incorrectly reshaped during application when using parameter broadcasting. (#8593)If
allocation.Allocateorallocation.Deallocateinstructions are encountered with graph-based decompositions enabled, they are now ignored instead of raising a warning. (#8553)Fixed a bug in
clifford_t_decompositionwithmethod="gridsynth"andqjit, where using a cached decomposition with the same parameter caused an error. (#8535)Fixed a bug in
SemiAdderwhere the results were incorrect when morework_wiresthan required were passed. (#8423)Fixed a bug where the deferred-measurement method was used silently even if
mcm_method="one-shot"was explicitly requested, when a device that extends theLegacyDevicedoes not declare support for mid-circuit measurements. (#8486)Fixed a bug where a
KeyErrorwas raised when querying the decomposition rule for an operator in the gate set from aDecompGraphSolution. (#8526)Fixed a bug where mid-circuit measurements were generating incomplete QASM. (#8556)
Fixed a bug where
specs()incorrectly computed the circuit depth in the presence of classically controlled operators. (#8668)Fixed a bug where an error was raised when trying to decompose a nested composite operator with capture and the new graph system enabled. (#8695)
Fixed a bug where the
change_op_basis()function could not be captured when theuncompute_opargument is left out. (#8695)Fixed a bug in the
rs_decomposition()function where valid solution candidates were being rejected. (#8625)Fixed a bug where decomposition rules were sometimes incorrectly disregarded by the
DecompositionGraphwhen a higher level decomposition rule uses dynamically allocated work wires viaqml.allocate. (#8725)Fixed a bug where
ChangeOpBasiswas not correctly reconstructed usingqml.pytrees.unflatten(*qml.pytrees.flatten(op)). (#8721)Fixed a bug where
qml.estimator.SelectTHC,qml.estimator.QubitizeTHC, andqml.estimator.PrepTHCwere not accounting for auxiliary wires correctly. (#8719)Fixed a bug where the associated
expand_transformdoes not stay with the originalTransformin aCompilePipelineduring manipulations of theCompilePipeline. (#8774)Fixed a bug where an error was raised when
to_openqasmis used withqml.decomposition.enable_graph(). (#8809)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Runor Agbaire, Guillermo Alonso, Utkarsh Azad, Joseph Bowles, Astral Cai, Yushao Chen, Isaac De Vlugt, Diksha Dhawan, Marcus Edwards, Lillian Frederiksen, Diego Guala, Sengthai Heng, Austin Huang, Soran Jahangiri, Jeffrey Kam, Jacob Kitchen, Christina Lee, Joseph Lee, Anton Naim Ibrahim, Lee J. O’Riordan, Mudit Pandey, Gabriela Sanchez Diaz, Shuli Shu, Jay Soni, Nate Stemen, Theodoros Trochatos, Leo Wei, David Wierichs, Shifan Xu, Hongsheng Zheng, Zinan Zhou.
Release 0.43.3¶
Bug fixes 🐛
The
gastpackage is now an explicit dependency in PennyLane. Thegastpackage was previously pulled in transitively bydiastatic-malt, butdiastatic-malt==2.15.3droppedgastas a dependency, which caused an error when importing PennyLane. (#9160)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Yushao Chen, Andrija Paurević, David Wierichs
Release 0.43.2¶
Bug fixes 🐛
PennyLane’s code has been updated to be compatible with NumPy 2.4 resolving deprecation related errors and warning messages. (#8808)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Yushao Chen, Andrija Paurevic.
Release 0.43.1¶
Bug fixes 🐛
Fixed a bug in the output of
to_openqasm(), where thecregdeclaration for mid-circuit measurements was missing a semicolon and leading to invalid QASM. (#8556)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Yushao Chen, Marcus Edwards, Nate Stemen.
Release 0.43.0¶
New features since last release
A brand new resource estimation module 📖
A new toolkit dedicated to resource estimation is now available in the estimator module!
The functionality therein is designed to rapidly and flexibly estimate the quantum resources
required to execute programs written at different levels of abstraction.
This new module includes the following features:
A new
estimate()function allows users to estimate the quantum resources required to execute a circuit or operation with respect to a given gate set and configuration. (#8203) (#8205) (#8275) (#8227) (#8279) (#8288) (#8311) (#8313) (#8360)The
estimate()function can be used on circuits written at different levels of detail to get high-level estimates of gate counts and additional wires fast. For workflows that are already defined in detail, like executable QNodes, theestimate()function works as follows:import pennylane as qml import pennylane.estimator as qre dev = qml.device("null.qubit") @qml.qnode(dev) def circ(): for w in range(2): qml.Hadamard(wires=w) qml.CNOT(wires=[0,1]) qml.RX(1.23*np.pi, wires=0) qml.RY(1.23*np.pi, wires=1) qml.QFT(wires=[0, 1, 2]) return qml.state()
>>> res = qre.estimate(circ)() >>> print(res) --- Resources: --- Total wires: 3 algorithmic wires: 3 allocated wires: 0 zero state: 0 any state: 0 Total gates : 408 'T': 396, 'CNOT': 9, 'Hadamard': 3
If exact argument values and other details to operators are unknown or not available,
estimate()can also be used on new lightweight representations of PennyLane operations that require minimal information to obtain high-level estimates. As part of this release, many operations in PennyLane now have a corresponding lightweight version that inherits from a new class calledResourceOperator, which can be found in theestimatormodule.For example, the lightweight representation of
QFTisqre.QFT. By simply specifying the number of wires it acts on, we can obtain resource estimates:>>> qft = qre.QFT(num_wires=3) >>> res = qre.estimate(qft) >>> print(res) --- Resources: --- Total wires: 3 algorithmic wires: 3 allocated wires: 0 zero state: 0 any state: 0 Total gates : 408 'T': 396, 'CNOT': 9, 'Hadamard': 3
One can create a circuit comprising these operations with similar syntax as defining a QNode, but with far less detail. Here is an example of a circuit with 50 (logical) algorithmic qubits, which includes a
QROMStatePreparationacting on 48 qubits. Defining this state preparation for execution would require a state vector of length \(2^{48}\) (seeqml.QROMStatePreparation), but we are able to estimate the required resources with only metadata, bypassing this computational barrier. Even at this scale, the resource estimate is computed in a fraction of a second!def my_circuit(): qre.QROMStatePreparation(num_state_qubits=48) for w in range(2): qre.Hadamard(wires=w) qre.QROM(num_bitstrings=32, size_bitstring=8, restored=False) qre.CNOT(wires=[0,1]) qre.RX(wires=0) qre.RY(wires=1) qre.QFT(num_wires=30) return
>>> res = qre.estimate(my_circuit)() >>> print(res) --- Resources: --- Total wires: 129 algorithmic wires: 50 allocated wires: 79 zero state: 71 any state: 8 Total gates : 2.702E+16 'Toffoli': 1.126E+15, 'T': 5.751E+4, 'CNOT': 2.027E+16, 'X': 2.252E+15, 'Z': 32, 'S': 64, 'Hadamard': 3.378E+15
Here is a summary of the lightweight operations made available in this release. A complete list can be found in the
estimatormodule.Identity,GlobalPhase, and various non-parametric operators and single-qubit parametric operators. (#8240) (#8242) (#8302)Various controlled single and multi qubit operators. (#8243)
Controlled, andAdjointas symbolic operators. (#8252) (#8349)Pow,Prod,ChangeOpBasis, and parametric multi-qubit operators. (#8255)Templates including
SemiAdder,QFT,AQFT,BasisRotation,Select,QROM,SelectPauliRot,QubitUnitary,ControlledSequence,QPE,IterativeQPE,MPSPrep,QROMStatePreparation,UniformStatePrep,AliasSampling,IntegerComparator,SingleQubitComparator,TwoQubitComparator,RegisterComparator,SelectTHC,PrepTHC, andQubitizeTHC. (#8300) (#8305) (#8309)
For defining your own customized lightweight resource operations that integrate with features in the
estimatormodule, check out the documentation forResourceOperator.Users can define customized configurations to be used during resource estimation using the new
ResourceConfigclass. This enables the seamless analysis of tradeoffs between resources required and quantities like individual gate precisions or different gate decompositions. (#8259)In the following example, a
ResourceConfigis used to modify the default precision of single qubit rotations, andTcounts are compared between different configurations.def my_circuit(): qre.RX(wires=0) qre.RY(wires=1) qre.RZ(wires=2) return my_rc = qre.ResourceConfig() res1 = qre.estimate(my_circuit, config=my_rc)() my_rc.set_single_qubit_rot_precision(1e-2) res2 = qre.estimate(my_circuit, config=my_rc)()
>>> t1 = res1.gate_counts['T'] >>> t2 = res2.gate_counts['T'] >>> print(t1, t2) 132 51
Hamiltonians are often both expensive to compute and to analyze, but the amount of information required to estimate the resources of Hamiltonian simulation can be surprisingly small in comparison. The
CDFHamiltonian,THCHamiltonian,VibronicHamiltonian, andVibrationalHamiltonianclasses were added to store the metadata of the Hamiltonian of a quantum system pertaining to resource estimation. In addition, several resource templates were added that are related to the Suzuki-Trotter method for Hamiltonian simulation, includingTrotterProduct,TrotterCDF,TrotterTHC,TrotterVibronic, andTrotterVibrational. (#8303)Here’s a simple example of resource estimation for the simulation of a
CDFHamiltonian, where we only need to specify two integer arguments (num_orbitalsandnum_fragments) to get resource estimates:>>> cdf_ham = qre.CDFHamiltonian(num_orbitals=4, num_fragments=4) >>> res = qre.estimate(qre.TrotterCDF(cdf_ham, num_steps=1, order=2)) >>> print(res) --- Resources: --- Total wires: 8 algorithmic wires: 8 allocated wires: 0 zero state: 0 any state: 0 Total gates : 2.238E+4 'T': 2.075E+4, 'CNOT': 448, 'Z': 336, 'S': 504, 'Hadamard': 336
In addition to the
ResourceOperatorclass mentioned above, the scalability of the resource estimation functionality in this release is owed to the following new internal classes:Resources: A container for counts and other metadata of quantum resources. (#8205)GateCount: A class to represent a gate and its number of occurrences in a circuit or decomposition.CompressedResourceOp: A lightweight class corresponding to an operator type alongside its parameters. (#8227)The
WireResourceManager,Allocate, andDeallocateclasses, which were added to manage and track wire usage during resource estimation and withinResourceOperatordefinitions. (#8203)
The resource estimation tools in the estimator module were originally prototyped in the
labs module. Check it out too for the latest cutting-edge research functionality!
Dynamic wire allocation 🎁
Wires can now be dynamically allocated and deallocated in quantum functions with the
allocate()anddeallocate()functions. These features unlock many important applications that rely on smart and efficient handling of wires, such as decompositions of gates that require auxiliary wires and logical patterns in subroutines that benefit from having dynamic wire management.(#7718) (#8151) (#8163) (#8179) (#8198) (#8381)
The
allocate()function can accept three arguments that dictate how dynamically allocated wires are handled:num_wires: the number of wires to dynamically allocate.state = "zero"/"any": the initial state that the dynamically allocated wires are requested to be in. Currently, supported values are"zero"(initialize in the all-zero state) or"any"(any arbitrary state).restored = True/False: a user-guarantee that the allocated wires will be restored to their original state (True) or not (False) when those wires are deallocated.
The recommended way to safely allocate and deallocate wires is to use
allocate()as a context manager:import pennylane as qml @qml.qnode(qml.device("default.qubit")) def circuit(): qml.H(0) qml.H(1) with qml.allocate(2, state="zero", restored=False) as new_wires: qml.H(new_wires[0]) qml.H(new_wires[1]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──H───────────────────────┤ <Z> 1: ──H───────────────────────┤ <DynamicWire>: ─╭Allocate──H─╭Deallocate─┤ <DynamicWire>: ─╰Allocate──H─╰Deallocate─┤
As illustrated, using
allocate()as a context manager ensures that allocation and safe deallocation are controlled within a localized scope. Equivalenty,allocate()can be used in-line along withdeallocate()for manual handling:new_wires = qml.allocate(2, state="zero", restored=False) qml.H(new_wires[0]) qml.H(new_wires[1]) qml.deallocate(new_wires)
For more complex dynamic allocation in circuits, PennyLane will resolve the dynamic allocation calls in the most resource-efficient manner before sending the program to the device. Consider the following circuit, which contains two dynamic allocations within a
forloop.@qml.qnode(qml.device("default.qubit"), mcm_method="tree-traversal") def circuit(): qml.H(0) for i in range(2): with qml.allocate(1, state="zero", restored=True) as new_qubit1: with qml.allocate(1, state="any", restored=False) as new_qubit2: m0 = qml.measure(new_qubit1[0], reset=True) qml.cond(m0 == 1, qml.Z)(new_qubit2[0]) qml.CNOT((0, new_qubit2[0])) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──H─────────────────────╭●───────────────────────╭●─────────────┤ <Z> <DynamicWire>: ──Allocate──┤↗│ │0⟩────│──────────Deallocate────│──────────────┤ <DynamicWire>: ──Allocate───║────────Z─╰X─────────Deallocate────│──────────────┤ <DynamicWire>: ─────────────║────────║──Allocate──┤↗│ │0⟩──────│───Deallocate─┤ <DynamicWire>: ─────────────║────────║──Allocate───║──────────Z─╰X──Deallocate─┤ ╚════════╝ ╚══════════╝
The user-level circuit drawing shows four separate allocations and deallocations (two per loop iteration). However, the circuit that the device receives gets automatically compiled to only use two additional wires (wires labelled
1and2in the diagram below). This is due to the fact thatnew_qubit1andnew_qubit2can both be reused after they’ve been deallocated in the first iteration of theforloop:>>> print(qml.draw(circuit, level="device")()) 0: ──H───────────╭●──────────────╭●─┤ <Z> 1: ──┤↗│ │0⟩────│───┤↗│ │0⟩────│──┤ 2: ───║────────Z─╰X───║────────Z─╰X─┤ ╚════════╝ ╚════════╝
Additionally,
allocate()anddeallocate()work withqjit()with some restrictions.
Resource tracking with Catalyst 🧾
Users can now use the
specs()function to track the exact resources of programs compiled withqjit()!
This new feature is currently only supported when usinglevel="device". (#8202)from functools import partial gateset = {qml.H, qml.S, qml.CNOT, qml.T, qml.RX, qml.RY, qml.RZ} @qml.qjit @partial(qml.transforms.decompose, gate_set=gateset) @qml.qnode(qml.device("null.qubit", wires=100)) def circuit(): qml.QFT(wires=range(100)) qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) qml.OutAdder( x_wires=range(10), y_wires=range(10,20), output_wires=range(20,31) ) return qml.expval(qml.Z(0) @ qml.Z(1)) circ_specs = qml.specs(circuit, level="device")()
>>> print(circ_specs['resources']) num_wires: 100 num_gates: 138134 depth: 90142 shots: Shots(total=None) gate_types: {'CNOT': 55313, 'RZ': 82698, 'Hadamard': 123} gate_sizes: {2: 55313, 1: 82821}
The
specs()function now accepts acompute_depthkeyword argument, which is set toTrueby default. Since depth computation is usually the most expensive resource to calculate, making it optional can increase the performance ofspecs()when depth is not a desired resource to calculate. (#7998) (#8042)
ZX Calculus transforms 🍪
A new set of transforms enable ZX calculus-based circuit optimization. These transforms make it easy to implement advanced compilation techniques that use the ZX calculus graphical language to reduce T-gate counts of Clifford + T circuits, optimize phase polynomials, and reduce the number of gates in non-Clifford circuits. (#8025) (#8029) (#8088) (#7747) (#8201)
These transforms include:
optimize_t_count(): reduces the number ofTgates in a Clifford + T circuit by applying a sequence of passes that combine ZX-based commutation and cancellation rules and the Third Order Duplicate and Destroy (TODD) algorithm.todd(): reduces the number ofTgates in a Clifford + T circuit by using the TODD algorithm.reduce_non_clifford(): reduces the number of non-Clifford gates in a circuit by applying a combination of phase gadgetization strategies and Clifford gate simplification rules.push_hadamards(): reduces the number of large phase-polynomial blocks in a phase-polynomial + Hadamard circuit by pushing Hadamard gates as far as possible to one side.
As an example, consider the following circuit:
import pennylane as qml dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.T(0) qml.CNOT([0, 1]) qml.S(0) qml.T(0) qml.T(1) qml.CNOT([0, 2]) qml.T(1) return qml.state()
>>> print(qml.draw(circuit)()) 0: ──T─╭●──S──T─╭●────┤ State 1: ────╰X──T────│───T─┤ State 2: ─────────────╰X────┤ State
We can apply the holistic
optimize_t_count()compilation pass to reduce the number ofTgates. In this case, allTgates can be removed!>>> print(qml.draw(qml.transforms.zx.optimize_t_count(circuit))()) 0: ──Z─╭●────╭●─┤ State 1: ────╰X──S─│──┤ State 2: ──────────╰X─┤ State
Change operator bases 🍴
Users can now benefit from an optimization of the controlled compute-uncompute pattern with the new
change_op_basis()function andChangeOpBasisclass. Operators arranged in a compute-uncompute pattern (U V U†, which is equivalent to changing the basis in whichVis expressed) can be efficiently controlled, as the only the central (target) operatorVneeds to be controlled, and notUorU†. (#8023) (#8070)These new features leverage the graph-based decomposition system, enabled with
enable_graph(). To illustrate their use, consider the following example. The compute-uncompute pattern is composed of aQFT, followed by aPhaseAdder, and finally an inverseQFT.from functools import partial qml.decomposition.enable_graph() dev = qml.device("default.qubit") @partial(qml.transforms.decompose, max_expansion=1) @qml.qnode(dev) def circuit(): qml.H(0) qml.CNOT([1,2]) qml.ctrl( qml.change_op_basis(qml.QFT([1,2]), qml.PhaseAdder(1, x_wires=[1,2])), control=0 ) return qml.state()
When this circuit is decomposed, the
QFTandAdjoint(QFT)are not controlled, resulting in a much more resource-efficient decomposition:>>> print(qml.draw(circuit)()) 0: ──H──────╭●────────────────┤ State 1: ─╭●─╭QFT─├PhaseAdder─╭QFT†─┤ State 2: ─╰X─╰QFT─╰PhaseAdder─╰QFT†─┤ State
The decompositions for several templates have been updated to use
ChangeOpBasis, which makes their decompositions more resource efficient by eliminating unnecessary controlled operations. The templates includeAdder,Multiplier,OutAdder,OutMultiplier,PrepSelPrep. (#8207)Here, the optimization is demonstrated when
Adderis controlled:qml.decomposition.enable_graph() dev = qml.device("default.qubit") @partial(qml.transforms.decompose, max_expansion=2) @qml.qnode(dev) def circuit(): qml.ctrl(qml.Adder(10, x_wires=[1,2,3,4]), control=0) return qml.state()
>>> print(qml.draw(circuit)()) 0: ──────╭●────────────────┤ State 1: ─╭QFT─├PhaseAdder─╭QFT†─┤ State 2: ─├QFT─├PhaseAdder─├QFT†─┤ State 3: ─├QFT─├PhaseAdder─├QFT†─┤ State 4: ─╰QFT─╰PhaseAdder─╰QFT†─┤ State
Quantum optimizers compatible with QJIT 🫖
Leveraging
qjit()to optimize hybrid workflows with the momentum quantum natural gradient optimizer is now possible withMomentumQNGOptimizerQJIT. This provides better scaling than its non-JIT-compatible counterpart. (#7606)The v0.42 release saw the addition of the
QNGOptimizerQJIToptimizer, which is aqml.qjit-compatible analogue toQNGOptimizer. In this release, we’ve added theMomentumQNGOptimizerQJIToptimizer, which is theqml.qjit-compatible analogue toMomentumQNGOptimizer. Both optimizers have an Optax-like interface:import jax.numpy as jnp dev = qml.device("lightning.qubit", wires=2) @qml.qnode(dev) def circuit(params): qml.RX(params[0], wires=0) qml.RY(params[1], wires=1) return qml.expval(qml.Z(0) + qml.X(1)) opt = qml.MomentumQNGOptimizerQJIT(stepsize=0.1, momentum=0.2) @qml.qjit def update_step_qjit(i, args): params, state = args return opt.step(circuit, params, state) @qml.qjit def optimization_qjit(params, iters): state = opt.init(params) args = (params, state) params, state = qml.for_loop(iters)(update_step_qjit)(args) return params
Quantum just-in-time compilation works exceptionally well with repeatedly executing the same function in a
forloop. As you can see, \(10^5\) iterations takes seconds:>>> import time >>> params = jnp.array([0.1, 0.2]) >>> iters = 100_000 >>> start = time.process_time() >>> optimization_qjit(params=params, iters=iters) Array([ 3.14159265, -1.57079633], dtype=float64) >>> time.process_time() - start 21.319525
Improvements 🛠
Resource-efficient decompositions
With
enable_graph(), dynamically allocated wires withallocate()are now supported in decomposition rules. This provides a smoother overall experience when decomposing operators in a way that requires auxiliary/work wires. (#7861) (#8228)Support for
allocate()unlocks the following features:The
decompose()transform now accepts amax_work_wiresargument that allows the user to specify the number of work wires available for dynamic allocation during decomposition. (#7963) (#7980) (#8103) (#8236)Decomposition rules were added for the
MultiControlledXthat dynamically allocate work wires if none were explicitly specified via thework_wiresargument. (#8024)
Several templates now have decompositions that can be accessed within the graph-based decomposition system (
enable_graph()), allowing workflows that include these templates to be decomposed in a resource-efficient and performant manner. (#7779) (#7908) (#7941) (#7943) (#8075) (#8002)The included templates are:
Adder,ControlledSequence,ModExp,MottonenStatePreparation,MPSPrep,Multiplier,OutAdder,OutMultiplier,OutPoly,PrepSelPrep,Prod,Reflection,StatePrep,TrotterProduct,QROM,GroverOperator,UCCSD,StronglyEntanglingLayers,GQSP,FermionicSingleExcitation,FermionicDoubleExcitation,QROM,ArbitraryStatePreparation,CosineWindow,AmplitudeAmplification,Permute,AQFT,FlipSign,FABLE,Qubitization, andSuperposition.Two additions were made to
Select, significantly improving its decomposition:A new keyword argument
partialhas been added, which allows for simplifications in the decomposition ofSelectunder the assumption that the state of the control wires has no overlap with computational basis states that are not used bySelect.A new decomposition rule has been added to
Select. It achieves cost reductions by adding onework_wire. This decomposition is useful to perform efficientQROMdecompositions.
The decomposition of
BasisRotationhas been optimized to skip redundant phase shift gates with angle \(\pm \pi\) for real-valued (orthogonal) rotation matrices. This uses the fact that either one or zeroPhaseShiftgates are required in case the matrix has a determinant equal to \(\pm 1\). (#7765)The
decompose()transform is now able to decompose classically controlled operations (i.e., operations nested insidecond). (#8145)from functools import partial dev = qml.device('default.qubit') @partial(qml.transforms.decompose, gate_set={qml.RY, qml.RZ, qml.measurements.MidMeasureMP}) @qml.qnode(dev) def circuit(): m0 = qml.measure(0) qml.cond(m0 == 0, qml.Rot)(qml.numpy.pi / 2, qml.numpy.pi / 2, qml.numpy.pi / 2, wires=1) return qml.expval(qml.X(0))
>>> print(qml.draw(circuit, level=0)()) 0: ──┤↗├──────────────────────┤ <X> 1: ───║───Rot(1.57,1.57,1.57)─┤ ╚═══╝ >>> print(qml.draw(circuit, level=1)()) 0: ──┤↗├───────────────────────────────┤ <X> 1: ───║───RZ(1.57)──RY(1.57)──RZ(1.57)─┤ ╚═══╩═════════╩═════════╝
Various decompositions of
MultiControlledXnow utilizeTemporaryANDin place ofToffoligates, leading to more resource-efficient decompositions. (#8172)Controlled(Identity)is now directly decomposed to a single Identity operator instead of going through a numeric decomposition algorithm. (#8388)The internal assignment of basis states in
Superpositionwas improved, resulting in its decomposition being more performant and efficient. (#7880)has_decomp()andlist_decomps()now take operator instances as arguments instead of types. (#8286)>>> qml.decomposition.has_decomp(qml.MultiControlledX) True >>> qml.decomposition.list_decomps(qml.Select) [<pennylane.decomposition.decomposition_rule.DecompositionRule at 0x126f99ed0>, <pennylane.decomposition.decomposition_rule.DecompositionRule at 0x127002fd0>, <pennylane.decomposition.decomposition_rule.DecompositionRule at 0x127034bd0>]
With the graph-based decomposition system enabled (
enable_graph()), if a decomposition cannot be found for an operator in the circuit in terms of the target gates, it no longer raises an error. Instead, a warning is raised, andop.decomposition()(the current default method for decomposing gates) is used as a fallback, while the rest of the circuit is still decomposed with the new graph-based system. Additionally, a special warning message is raised if the circuit contains aGlobalPhase, reminding the user thatGlobalPhaseis not assumed to have a decomposition under the new system. (#8156)decompose()anddecompose()now have a unified internal implementation to promote feature parity in preparation for the graph-based decomposition system to be the default decomposition method in PennyLane. (#8193)A new class called
DecompGraphSolutionhas been added to store the solution of a decomposition graph. An instance of this class is returned from thesolvemethod of theDecompositionGraphclass. (#8031)
OpenQASM-PennyLane interoperability
The
from_qasm3()function can now convert OpenQASM 3.0 circuits that contain subroutines, constants, all remaining stdlib gates, qubit registers, and built-in mathematical functions. (#7651) (#7653) (#7676) (#7677) (#7679) (#7690) (#7767)to_openqasm()now supports mid-circuit measurements and conditionals of unprocessed measurement values. (#8210)
Setting shots
The number of
shotscan now be specified directly in QNodes as a standard keyword argument. (#8073)@qml.qnode(qml.device("default.qubit"), shots=1000) def circuit(): qml.H(0) return qml.expval(qml.Z(0))
>>> circuit.shots Shots(total_shots=1000, shot_vector=(ShotCopies(1000 shots x 1),)) >>> circuit() np.float64(-0.004)
Setting the
shotsvalue in a QNode is equivalent to decorating withset_shots(). However, decorating withset_shots()overrides QNodeshots:>>> new_circ = qml.set_shots(circuit, shots=123) >>> new_circ.shots Shots(total_shots=123, shot_vector=(ShotCopies(123 shots x 1),))
The
set_shots()transform can now be directly applied to a QNode without the need forfunctools.partial, providing a more user-friendly syntax and negating having to import thefunctoolspackage. (#7876) (#7919)@qml.set_shots(shots=1000) # or @qml.set_shots(1000) @qml.qnode(dev) def circuit(): qml.H(0) return qml.expval(qml.Z(0))
>>> circuit() 0.002
Clifford + T decomposition
The
clifford_t_decomposition()transform withmethod="gridsynth"is now compatible with quantum just-in-time compilation via theqjit()decorator. (#7711)@qml.qjit @partial(qml.transforms.clifford_t_decomposition, method="gridsynth") @qml.qnode(qml.device("lightning.qubit", wires=1)) def circuit(): qml.RX(np.pi/3, wires=0) qml.RY(np.pi/4, wires=0) return qml.state()
>>> circuit() Array([0.80011651+0.19132132j, 0.33140586-0.4619306j ], dtype=complex128)
The
clifford_t_decomposition()transform can now decompose circuits with mid-circuit measurements, including Catalyst’s measurement operations. It also now handlesRZandPhaseShiftoperations where angles are odd multiples of \(\pm \tfrac{\pi}{4}\) more efficiently when usingmethod="gridsynth". (#7793) (#7942)The
rs_decomposition()method now gives decompositions with exact global phase information. (#7793)Users can now specify a relative threshold value for the permissible operator norm error (
epsilon) that triggers rebuilding of the cache in theclifford_t_decomposition(), via newcache_eps_rtolkeyword argument. (#8056)
Transforms
New transforms called
match_relative_phase_toffoli()andmatch_controlled_iX_gate()have been added, which compile certain patterns to efficient Clifford + T equivalents. (#7748)@qml.qnode(qml.device("default.qubit", wires=4)) def circuit(): qml.CCZ(wires=[0, 1, 3]) qml.ctrl(qml.S(wires=[1]), control=[0]) qml.ctrl(qml.S(wires=[2]), control=[0, 1]) qml.MultiControlledX(wires=[0, 1, 2, 3]) return qml.expval(qml.Z(0))
>>> new_circuit = qml.transforms.match_relative_phase_toffoli(circuit) >>> print(qml.draw(new_circuit, level=1)()) 0: ─────────────────╭●───────────╭●───────────────────────────┤ <Z> 1: ─────────────────│─────╭●─────│─────╭●─────────────────────┤ 2: ───────╭●────────│─────│──────│─────│────────────╭●────────┤ 3: ──H──T─╰X──T†──H─╰X──T─╰X──T†─╰X──T─╰X──T†──H──T─╰X──T†──H─┤
New intermediate representations (IRs) called
parity_matrix()andphase_polynomial()are available in PennyLane. These IRs are used in compilation passes to optimizeCNOTand phase polynomial circuits, respectively. Additionally, therowcol()has been added, which uses the parity matrix as its IR forCNOTrouting under constraint connectivity. (#8171) (#8443)The example below showcases the use of
parity_matrix(), which acts on circuits containing onlyCNOTgates.dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def circuit(): qml.CNOT((3, 2)) qml.CNOT((0, 2)) qml.CNOT((2, 1)) qml.CNOT((3, 2)) qml.CNOT((3, 0)) qml.CNOT((0, 2)) return qml.state()
Upon transforming the above circuit with
parity_matrix(), the output is the parity matrix.>>> P = qml.transforms.parity_matrix(circuit, wire_order=range(4))() >>> print(P) array([[1, 0, 0, 1], [1, 1, 1, 1], [0, 0, 1, 1], [0, 0, 0, 1]])
The
phase_polynomial()transform functions similarly, operating on circuits containining onlyCNOTandRZgates and returning the parity matrix, the parity table, and corresponding angles for each parity.@qml.qnode(dev) def circuit(): qml.CNOT((1, 0)) qml.RZ(1, 0) qml.CNOT((2, 0)) qml.RZ(2, 0) qml.CNOT((0, 1)) qml.CNOT((3, 1)) qml.RZ(3, 1) return qml.state()
>>> pmat, ptab, angles = qml.transforms.phase_polynomial(circuit, wire_order=range(4))() >>> pmat [[1 1 1 0] [1 0 1 1] [0 0 1 0] [0 0 0 1]] >>> ptab [[1 1 1] [1 1 0] [0 1 1] [0 0 1]] >>> angles [1 2 3]
A new transform called
rz_phase_gradient()has been added, which lets you realize arbitrary angleRZrotations with a phase gradient resource state and semi-in-place addition (SemiAdder). This can be a crucial subroutine in FTQC when sufficient auxiliary wires are available, as it saves onTgates compared to other discretization schemes. (#8213)A new keyword argument called
shot_disthas been added to thesplit_non_commuting()transform. This allows for more customization and efficiency when calculating expectation values across the non-commuting groups of observables that make up aHamiltonian/LinearCombination. (#7988)Given a QNode that returns a sample-based measurement (e.g.,
expval) of aHamiltonian/LinearCombinationwith finiteshots, the current default behaviour ofsplit_non_commuting()will performshotsexecutions for each group of commuting terms. With theshot_distargument, this behaviour can be changed:"uniform": evenly distributes the number ofshotsacross all groups of commuting terms"weighted": distributes the number ofshotsaccording to weights proportional to the L1 norm of the coefficients in each group"weighted_random": same as"weighted", but the numbers ofshotsare sampled from a multinomial distributionor a user-defined function implementing a custom shot distribution strategy
To show an example about how this works, let’s start by defining a simple Hamiltonian:
ham = qml.Hamiltonian( coeffs=[10, 0.1, 20, 100, 0.2], observables=[ qml.X(0) @ qml.Y(1), qml.Z(0) @ qml.Z(2), qml.Y(1), qml.X(1) @ qml.X(2), qml.Z(0) @ qml.Z(1) @ qml.Z(2) ] )
This Hamiltonian can be split into 3 non-commuting groups of mutually commuting terms. With
shot_dist = "weighted", for example, the number of shots will be divided according to the L1 norm of each group’s coefficients:from functools import partial from pennylane.transforms import split_non_commuting dev = qml.device("default.qubit") @partial(split_non_commuting, shot_dist="weighted") @qml.qnode(dev, shots=10000) def circuit(): return qml.expval(ham) with qml.Tracker(dev) as tracker: circuit()
>>> print(tracker.history["shots"]) [2303, 23, 7674]
The
fold_global()transform has been refactored to collect operators into a list directly rather than relying on queuing. (#8296)
Choi matrix functionality
A new function called
choi_matrix()is available, which computes the Choi matrix of a quantum channel. This is a useful tool in quantum information science and to check circuit identities involving non-unitary operations. (#7951)>>> import numpy as np >>> Ks = [np.sqrt(0.3) * qml.CNOT((0, 1)), np.sqrt(1-0.3) * qml.X(0)] >>> Ks = [qml.matrix(op, wire_order=range(2)) for op in Ks] >>> Lambda = qml.math.choi_matrix(Ks) >>> np.trace(Lambda), np.trace(Lambda @ Lambda) (np.float64(1.0), np.float64(0.58))
Other improvements
snapshots()can now be used withmcm_method="one-shot"andmcm_method="tree-traversal". (#8140)This improvement is particularly useful for extracting the state in finite-shot workflows:
@qml.qnode(qml.device("default.qubit"), mcm_method="one-shot", shots=1) def circuit(): qml.RY(1.23, 0) m0 = qml.measure(0) qml.cond(m0 == 0, qml.H)(0) qml.Snapshot("state", measurement=qml.state()) return qml.expval(qml.X(0))
>>> qml.snapshots(circuit)() {'state': array([0.+0.j, 1.+0.j]), 'execution_results': np.float64(-1.0)}
Here, the state is projected onto the corresponding state resulting from the MCM.
The printing and drawing of
TemporaryAND, also known asqml.Elbow, and its adjoint have been improved to be more legible and consistent with how it’s depicted in circuits in the literature. (#8017) (#8432)import pennylane as qml @qml.draw @qml.qnode(qml.device("lightning.qubit", wires=4)) def node(): qml.TemporaryAND([0, 1, 2], control_values=[1, 0]) qml.CNOT([2, 3]) qml.adjoint(qml.TemporaryAND([0, 1, 2], control_values=[1, 0])) return qml.expval(qml.Z(3))
print(node()) 0: ─╭●─────●╮─┤ 1: ─├○─────○┤─┤ 2: ─╰──╭●───╯─┤ 3: ────╰X─────┤ <Z>
With
enable_graph(), theUserWarningthat is raised when a decomposition cannot be found for an operator in the circuit is now more generic, not making any assumptions about how the unresolved operations will be applied or used in the decompose transformation. (#8361)The
sample()function can now receive an optionaldtypeparameter which sets the type and precision of the samples returned by this measurement process. (#8189) (#8271)DefaultQubitwill now default to the tree-traversal MCM method whenmcm_method="device". (#7885)DefaultQubitnow determines themcm_methodinDevice.setup_execution_config, making it easier to tell whichmcm_methodwill be used. This also allowsdefer_measurementsanddynamic_one_shotto be applied at different locations in the preprocessing program. (#8184)The default implementation of
Device.setup_execution_confignow choses"device"as the defaultmcm_methodif it is available, as specified by the device TOML file. (#7968)ExecutionConfigandMCMConfigfrompennylane.devicesare now frozen dataclasses whose fields should be updated withdataclass.replace. (#7697) (#8046)An error is no longer raised when non-integer wire labels are used in QNodes using
mcm_method="deferred". (#7934)@qml.qnode(qml.device("default.qubit"), mcm_method="deferred") def circuit(): m = qml.measure("a") qml.cond(m == 0, qml.X)("aux") return qml.expval(qml.Z("a"))
>>> print(qml.draw(circuit)()) a: ──┤↗├────┤ <Z> aux: ───║───X─┤ ╚═══╝
qml.transforms.core.TransformContainernow holds onto aTransformDispatcher,args, andkwargs, instead of the transform’s defining function and unpacked properties. It can still be constructed via the old signature, as well. (#8306)A warning is now raised when circuits are executed without Catalyst and with
qml.capture.enable()present. (#8291)The QNode primitive in the experimental program capture module now captures the unprocessed
ExecutionConfig, instead of one processed by the device. This allows for better integration with Catalyst. (#8258)qml.countscan now be captured with program capture. Circuits returningcountsstill cannot be interpreted or executed with program capture. (#8229)Templates are now compatible with program capture. (#8211)
PennyLane
autographsupports standard Python for index assignment (arr[i] = x) and updating array elements (arr[i] += x) instead ofjax.numpyform (i.e.,arr = arr.at[i].set(x)andarr.at[i].add(x)). (#8027) (#8076)import jax.numpy as jnp qml.capture.enable() @qml.qnode(qml.device("default.qubit", wires=3)) def circuit(val): angles = jnp.zeros(3) angles[0:3] += val for i, angle in enumerate(angles): qml.RX(angle, i) return qml.expval(qml.Z(0)), qml.expval(qml.Z(1)), qml.expval(qml.Z(2))
>>> circuit(jnp.pi) (Array(-1, dtype=float32), Array(-1, dtype=float32), Array(-1, dtype=float32))
Logical operations (
and,orandnot) are now supported with PennyLaneautograph. (#8006)qml.capture.enable() @qml.qnode(qml.device("default.qubit", wires=1)) def circuit(param): if param >= 0 and param <= 1: qml.H(0) return qml.state()
>>> circuit(0.5) Array([0.70710677+0.j, 0.70710677+0.j], dtype=complex64)
With program capture, the
true_fncan now be a subclass ofOperatorwhen nofalse_fnis provided. For example,qml.cond(condition, qml.X)(0)is now valid code. (#8060) (#8101)With program capture, an error is now raised if the conditional predicate in, say, an
ifstatement is not a scalar. (#8066)Program capture can now handle dynamic shots, shot vectors, and shots set with
set_shots(). (#7652)The error message raised when using unified-compiler transforms with
qjit()has been updated with suggested fixes. (#7916)Two new
drawandgenerate_mlir_graphfunctions have been introduced in theqml.compiler.python_compiler.visualizationmodule to visualize circuits with the new unified compiler framework when xDSL and/or Catalyst compilation passes are applied. (#8040) (#8180) (#8091)The
catalyst,qec, and`stablehloxDSL dialects have been added to the unified compiler framework, containing data structures that support core compiler functionality and quantum error correction and extending the existing StableHLO dialect with missing upstream operations. (#7901) (#7985) (#8036) (#8084) (#8113)The
QuantumxDSL dialect now has more strict constraints for operands and results. (#8083)A callback mechanism has been added to
qml.compiler.python_compilersubmodule to inspect the intermediate representation of the program between multiple compilation passes. (#7964)A
QuantumParserclass has been added to theqml.compiler.python_compilersubmodule that automatically loads relevant dialects. (#7888)Two new operations have been added to the
Quantumdialect of the unified compiler:A compilation pass written called
qml.compiler.python_compiler.transforms.MeasurementsFromSamplesPasshas been added for integration with the unified compiler framework. This pass replaces all terminal measurements in a program with a singlesample()measurement, and adds postprocessing instructions to recover the original measurement. (#7620)A combine-global-phase pass has been added to the unified compiler framework. Note that the current implementation can only combine all the global phase operations at the last global phase operation in the same region. In other words, global phase operations inside a control flow region can’t be combined with those in their parent region. (#7675)
The matrix factorization using
givens_decomposition()has been optimized to factor out the redundant sign in the diagonal phase matrix for the real-valued (orthogonal) rotation matrices. For example, in case the determinant of a matrix is \(-1\), only a single element of the phase matrix is required. (#7765)A new device preprocess transform,
~.devices.preprocess.no_analytic, is available for hardware devices and hardware-like simulators. It validates that all executions are shot-based. (#8037)PennyLane is now compatible with
quimb == 1.11.2after a bug affectingdefault.tensorwas fixed. (#7931)A new
resolve_dynamic_wires()transform can allocate concrete wire values for dynamic wire allocation. (#7678) (#8184) (#8406)
Labs: a place for unified and rapid prototyping of research software 🧪
Labs Resource Estimation
State-of-the-art resource estimates have been added to existing templates:
ResourceSelectPauliRot,ResourceQubitUnitary,ResourceSingleQubitComparator,ResourceTwoQubitComparator,ResourceIntegerComparator,ResourceRegisterComparator,ResourceUniformStatePrep,ResourceAliasSampling,ResourceQFT,ResourceAQFT, andResourceTrotterProduct. (#7786) (#7857) (#7883) (#7920) (#7910)Users can now do resource estimation on QPE and iterative QPE with
ResourceQPEandResourceIterativeQPE, respectively. Additionally, aResourceControlledSequencetemplate has been added that allows estimating resources on controlled sequences of resource operators. (#8053)estimate_resourceshas been renamed toestimateto make the function name concise and clearer thanlabs.resource_estimation.estimate_resources. (#8232)A new
ResourceConfigclass has been added to help track the configuration for errors, precisions and custom decompositions for the resource estimation pipeline. (#8195)The symbolic
ResourceOperatorshave been updated to use hyperparameters from theconfigdictionary. (#8181)An internal
dequeue()method has been added to theResourceOperatorclass to simplify the instantiation of resource operators which require resource operators as input. (#7974)ResourceOperatorinstances can now be compared with==. (#8155)A mapper function called
map_to_resource_op()has been added to map PennyLane operators toResourceOperatorequivalents. (#8146) (#8162)Several Labs test files have been renamed to prevent conflict with names in mainline PennyLane tests. (#8264)
A queueing issue in the
ResourceOperatortests has been fixed. (#8204)
Labs Trotter Error Estimation
Parallelization support for
effective_hamiltonianhas been added to improve performance. (#8081) (#8257)New
SparseFragmentandSparseStateclasses have been created to allow the use of sparse matrices for Hamiltonian Fragments when estimating Trotter error. (#7971)The
perturbation_error()function has been updated to sum over expectation values instead of states. (#8226)The docstring in
perturbation_errorhas been updated to use the correct positional argument name. (#8174)
Labs Removals
The module
qml.labs.zxopthas been removed. Its functionalities are now available in the submodulezx. The same functions are available, but their signature may have changed.Instead of
qml.labs.zxopt.full_optimize, useoptimize_t_count()Instead of
qml.labs.zxopt.full_reduce, usereduce_non_clifford()Instead of
qml.labs.zxopt.todd, usetodd()Instead of
qml.labs.zxopt.basic_optimization, usepush_hadamards()(#8177)
Breaking changes 💔
autorayhas been pinned to v0.8.0 for PennyLane v0.43.0 to prevent potential bugs due to breaking changes in autoray releases. (#8412)Previous to this change, the
autoraypackage was upper-bounded inpyproject.tomlto unblock CI failures due to breaking changes inv0.8.0. Then, it was unpinned by fixing source code that was broken by the release. (#8110) (#8147) (#8159) (#8160)Using
postselect_mode="fill-shots"withmcm_method="one-shot"or"tree-traversal"has been disallowed withdefault.qubit, as it produces incorrect results where the correlation between measurements is not preserved. (#8411)qml.workflow.construct_batch.expand_fn_transformhas been deleted as it was no longer getting used. (#8344)get_canonical_interface_namehas been removed in favour of overridingEnum._missing_in
Interface. (#8223)If you would like to get the canonical interface you can simply use the
Enum:>>> from pennylane.math.interface_utils import Interface >>> Interface("torch") <Interface.TORCH: 'torch'> >>> Interface("jax-jit") <Interface.JAX_JIT: 'jax-jit'>
PrepSelPrephas been made more reliable by deriving the attributescoeffsand `opsfrom the propertylcuinstead of storing them independently. In addition, it is now more consistent with other PennyLane operators, dequeuing its inputlcu. (#8169)MidMeasureMPnow inherits fromOperatorinstead ofMeasurementProcess, which resolves problems caused by it always acting like an operator. (#8166)With the deprecation of the
shotskwarg inqml.device,DefaultQubit.eval_jaxprdoes not useself.shotsfrom the device anymore; instead, it takesshotsas a keyword argument, and the QNode primitive should process theshotsand calleval_jaxpraccordingly. (#8161)The methods
operation()andoperation()no longer queue any operators. This improves the consistency of the queuing behaviour for the operators. (#8136)qml.sampleno longer has singleton dimensions squeezed out for single shots or single wires. This cuts down on the complexity of post-processing due to having to handle single shot and single wire cases separately. The return shape will now always be(shots, num_wires). (#7944) (#8118)For a simple qnode:
@qml.qnode(qml.device('default.qubit')) def circuit(): return qml.sample(wires=0)
Before the change, we had:
>>> qml.set_shots(circuit, shots=1)() 0
and now we have:
>>> qml.set_shots(circuit, shots=1)() array([[0]])
Previous behavior can be recovered by squeezing the output:
>>> qml.math.squeeze(qml.set_shots(circuit, shots=1)()) array(0)
Functions involving an execution configuration will now default to
Noneinstead ofpennylane.devices.DefaultExecutionConfigand have to be handled accordingly. This prevents the potential mutation of a global object. (#7697)This means that functions like,
def some_func(..., execution_config = DefaultExecutionConfig): ...
should be written as follows,
def some_func(..., execution_config: ExecutionConfig | None = None): if execution_config is None: execution_config = ExecutionConfig()
The
HilbertSchmidtandLocalHilbertSchmidttemplates have been updated and their UI has been remarkably simplified. They now accept an operation or a list of operations as
unitaries. (#7933)In past versions of PennyLane, these templates required providing the
UandVunitaries as aqml.tape.QuantumTapeand a quantum function, respectively, along with separate parameters and wires.With this release, each template has been improved to accept one or more operators as unitaries. The wires and parameters of the approximate unitary
Vare inferred from the inputs, according to the order provided.>>> U = qml.Hadamard(0) >>> V = qml.RZ(0.1, wires=1) >>> qml.HilbertSchmidt(V, U) HilbertSchmidt(0.1, wires=[0, 1])
Support for Python 3.10 has been removed and support for Python 3.13 has been added. (#7935)
To make the codebase more organized and easier to maintain, custom exceptions were moved into
exceptions.py, and a documentation page for them was added in the internals. (#7856)The boolean functions provided in
qml.operationhave been deprecated. See the deprecations page for equivalent code to use instead. These includenot_tape,has_gen,has_grad_method,has_multipar,has_nopar,has_unitary_gen,is_measurement,defines_diagonalizing_gates, andgen_is_multi_term_hamiltonian. (#7924)To prevent code duplication, access to
lie_closure,structure_constantsandcenterviaqml.paulihas been removed. The functions now live in theliealgmodule and top level import and usage is advised. (#7928) (#7994)import pennylane.liealg from pennylane.liealg import lie_closure, structure_constants, center
qml.operation.Observableand the correspondingObservable.comparehave been removed, as PennyLane now depends on the more generalOperatorinterface instead. TheOperator.is_hermitianproperty can instead be used to check whether or not it is highly likely that the operator instance is Hermitian. (#7927)qml.operation.WiresEnum,qml.operation.AllWires, andqml.operation.AnyWireshave been removed. To indicate that an operator can act on any number of wires,Operator.num_wires = Noneshould be used instead. This is the default and does not need to be overwritten unless the operator developer wants to validate that the correct number of wires is passed. (#7911)The
qml.QNode.get_gradient_fn()function has been removed. Instead, useqml.workflow.get_best_diff_method()to obtain the differentiation method. (#7907)Top-level access to
DeviceError,PennyLaneDeprecationWarning,QuantumFunctionErrorandExperimentalWarninghas been removed. Please import these objects from the newpennylane.exceptionsmodule. (#7874)To improve code reliability,
qml.cut_circuit_mcno longer accepts ashotskeyword
argument. The shots should instead be set on the tape itself. (#7882)expand_tape()has been moved to its own file, and made available atqml.tape. (#8296)
Deprecations 👋
PennyLane and Lightning will no longer ship wheels for Intel MacOS platforms for v0.44 and newer. Additionally, MacOS ARM wheels will require a minimum OS version of 14.0 for continued use with v0.44 and newer. This change is needed to account for MacOS officially deprecating support for Intel CPUs in the OS (see their blog post for more details).
Setting shots on a device through the
shotskeyword argument (e.g.,qml.device("default.qubit", wires=2, shots=1000)) and in QNode calls (e.g.,qml.QNode(circuit, dev)(shots=1000)) has been deprecated. Please use theset_shots()transform to set the number of shots for a QNode instead. This is done to reduce confusion and code complexity by having a centralized way to set shots. (#7979) (#8161) (#7906)dev = qml.device("default.qubit", wires=2) @qml.set_shots(1000) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.Z(0))
Support for using TensorFlow with PennyLane has been deprecated and will be dropped in Pennylane v0.44. Future versions of PennyLane are not guaranteed to work with TensorFlow. Instead, we recommend using the JAX or PyTorch interfaces for machine learning applications to benefit from enhanced support and features. Please consult the following demos for more usage information: Turning quantum nodes into Torch Layers and How to optimize a QML model using JAX and Optax. (#7989) (#8106)
pennylane.devices.DefaultExecutionConfighas been deprecated and will be removed in v0.44. Instead, useqml.devices.ExecutionConfig()to create a default execution configuration. This helps prevent unintended changes in a workflow’s behaviour that could be caused by using a global, mutable object. (#7987)Specifying the
work_wire_typeargument inqml.ctrland other controlled operators as"clean"or"dirty"has been deprecated. Use"zeroed"to indicate that the work wires are initially in the \(|0\rangle\) state, and"borrowed"to indicate that the work wires can be in any arbitrary state instead. In both cases, the work wires are restored to their original state upon completing the decomposition. This is done to standardize how work wires are called in PennyLane. (#7993)Providing the Trotter number kwarg
num_stepstopennylane.evolve(),pennylane.exp(),pennylane.ops.Evolution, andpennylane.ops.Exphas been deprecated and will be removed in a future release. Instead, useTrotterProductfor approximate methods, providing thenparameter to perform the Suzuki-Trotter product approximation of a Hamiltonian with the specified number of Trotter steps. This change resolves the ambiguity that arises when usingnum_stepson devices that support analytic evolution (e.g.,default.qubit). (#7954) (#7977)As a concrete example, consider the following case:
coeffs = [0.5, -0.6] ops = [qml.X(0), qml.X(0) @ qml.Y(1)] H_flat = qml.dot(coeffs, ops)
Instead of computing the Suzuki-Trotter product approximation as:
>>> qml.evolve(H_flat, num_steps=2).decomposition() [RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1]), RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1])]
The same result can be obtained using
TrotterProductas follows:>>> decomp_ops = qml.adjoint(qml.TrotterProduct(H_flat, time=1.0, n=2)).decomposition() >>> [simp_op for op in decomp_ops for simp_op in map(qml.simplify, op.decomposition())] [RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1]), RX(0.5, wires=[0]), PauliRot(-0.6, XY, wires=[0, 1])]
MeasurementProcess.expandhas been deprecated. The relevant method can be replaced withqml.tape.QuantumScript(mp.obs.diagonalizing_gates(), [type(mp)(eigvals=mp.obs.eigvals(), wires=mp.obs.wires)]). This improves the code design by removing an unused method with undesired dependencies (i.e. circular dependency). (#7953)QuantumScript.shapeandQuantumScript.numeric_typehave been deprecated and will be removed in version v0.44. Instead, the corresponding.shapeor.numeric_typeof theMeasurementProcessclass should be used. (#7950)Some unnecessary methods of the
qml.CircuitGraphclass have been deprecated and will be removed in version v0.44: (#7904)print_contentsin favor ofprint(obj)observables_in_orderin favor ofobservablesoperations_in_orderin favor ofoperationsancestors_in_orderin favor ofancestors(obj, sort=True)descendants_in_orderin favor ofdescendants(obj, sort=True)
The
QuantumScript.to_openqasmmethod has been deprecated and will be removed in version v0.44. Instead, theqml.to_openqasmfunction should be used. This change makes the code cleaner by separating out methods that interface with external libraries from PennyLane’s internal functionality. (#7909)The
level=Noneargument in thepennylane.workflow.get_transform_program(),pennylane.workflow.construct_batch(),qml.draw,qml.draw_mpl, andqml.specstransforms has been deprecated and will be removed in v0.44. Please uselevel='device'instead to apply the noise model at the device level. This reduces ambiguity by making it clear that the default is to apply all transforms to the QNode. (#7886) (#8364)qml.qnn.cost.SquaredErrorLosshas been deprecated and will be removed in version v0.44. Instead, this hybrid workflow can be accomplished with a function likeloss = lambda *args: (circuit(*args) - target)**2. (#7527)Access to
add_noise,insertand noise mitigation transforms from thetransformsmodule has been deprecated. Instead, these functions should be imported from thenoisemodule, which is a more appropriate location for them. (#7854)The
qml.QNode.add_transformmethod has been deprecated and will be removed in v0.44. Instead, please useQNode.transform_program.push_back(transform_container=transform_container). (#7855) (#8266)
Internal changes ⚙️
GitHub actions and workflows (
interface-unit-tests.yml,tests-labs.yml,unit-test.yml,upload-nightly-release.ymlandupload.yml) have been updated to useubuntu-24.04runners. (#8371)measurementsis now a “core” module in thetachspecification. (#7945)Enforce various modules to follow modular architecture via
tach. (#7847)CI workflows to test documentation using
sybilhave been added. (#8324) (#8328) (#8329) (#8330) (#8331) (#8386)The
templates/subroutinesnow hasarithmetic,qchem, andtime_evolutionsubmodules. (#8333)test_horizontal_cartan_subalgebra.pynow uses our fixtureseedfor reproducibility and CI stability. (#8304)The
qml.compiler.python_compilersubmodule has been restructured to be more cohesive. (#8273)default.tensornow supports graph decomposition (qml.decomposition.enable_graph()) during preprocessing. (#8253)Legacy interface names from tests have been removed (e.g.,
interface="jax-python"orinterface="pytorch") (#8249)qml.devices.preprocess.decomposenow works in graph decomposition mode when a gateset is provided.default.qubitandnull.qubitcan now use graph decomposition mode. (#8225) (#8265) (#8260)Usage of the
pytest.mark.capturemarker from tests in thetests/python_compilerdirectory has been removed. (#8234)pylinthas been updated to v3.3.8 in our CI andrequirements-dev.txt(#8216)Links in the
README.mdhave been updated. (#8165)The
autographguide to now reflects new capabilities. (#8132)strict=Trueis now used tozipusage in source code. (#8164) (#8182) (#8183)The
autographkeyword argument has been removed from theQNodeconstructor. To enable autograph conversion, use theqjitdecorator together with theqml.capture.disable_autographcontext manager.The ability to disable
autographconversion has been added by using the newqml.capture.disable_autographdecorator or context manager. Additionally, theautographkeyword argument has been removed from theQNodeconstructor. To enable autograph conversion, use theqjitdecorator together with theqml.capture.disable_autographcontext manager. (#8102) (#8104)Roundtrip testing and module verification to the Python compiler is now done in
run_filecheckandrun_filecheck_qjitfixtures. (#8049)Various type hints have been improved internally. (#8086) (#8284)
The
condprimitive with program capture no longer stores missing false branches asNone, instead storing them as jaxprs with no output. (#8080)Unnecessary execution tests along with accuracy validation in
tests/ops/functions/test_map_wires.pywere removed due to stochastic failures. (#8032)A new
all-tests-passedgatekeeper job has been added tointerface-unit-tests.ymlto ensure all test jobs complete successfully before triggering downstream actions. This reduces the need to maintain a long list of required checks in GitHub settings. Also added the previously missingcapture-jax-testsjob to the list of required test jobs, ensuring this test suite is properly enforced in CI. (#7996)DefaultQubitLegacy(test suite only) has been equipped with seeded sampling. This allows for reproducible sampling results of legacy classical shadow across CI. (#7903)DefaultQubitLegacy(test suite only) no longer provides a customized classical shadow implementation. (#7895)Capture does not block
wires=0anymore. This allows Catalyst to work with zero-wire devices. Note thatwires=Noneis still not allowed. (#7978)The readability of
dynamic_one_shotpostprocessing has been improved to allow for further modification. (#7962) (#8041)PennyLane’s top-level
__init__.pyfile has been updated with imports to improve Python language server support for finding PennyLane submodules. (#7959)Type hints in the
measurementsmodule have been improved. (#7938)The codebase has been refactored to adopt modern type hint syntax for Python 3.11+. (#7860) (#7982)
Pre-commit hooks have been updated to add gitleaks for security purposes. (#7922)
A new fixture called
run_filecheck_qjithas been added, which can be used to runFileCheckon integration tests for theqml.compiler.python_compilersubmodule. (#7888)The minimum supported
pytestversion has been updated to8.4.1. (#7853)The
pennylane.iomodule is now a tertiary module. (#7877)Tests for the
split_to_single_termstransformation are now seeded. (#7851)The
rc_sync.ymlfile has been updated to work with the latestpyproject.tomlchanges. (#7808) (#7818)LinearCombinationinstances can now be created with_primitive.implwhen capture is enabled and tracing is active. (#7893)The
TensorLiketype is now compatible with static type checkers. (#7905)The supported version of xDSL has been updated to
0.49. (#7923) (#7932) (#8120)The JAX version used in tests to has been updated to
0.6.2(#7925)An
xdsl_extrasmodule has been added to the unified compiler framework to house additional utilities and functionality not available upstream in xDSL. (#8067) (#8120)Two new xDSL passes have been added to the unified compiler framework:
decompose-graph-state, which decomposesmbqc.graph_state_prepoperations into their corresponding set of quantum operations for execution on state simulators, andnull-decompose-graph-state, which replacesmbqc.graph_state_prepoperations with single quantum-register allocation operations for execution on null devices. (#8090)The
mbqcxDSL dialect has been added to the unified compiler framework, which is used to represent measurement-based quantum-computing instructions in the xDSL framework. (#7815) (#8059)A compilation pass written with xDSL called
qml.compiler.python_compiler.transforms.ConvertToMBQCFormalismPasshas been added for the experimental unified compiler framework. This pass converts all gates in the MBQC gate set (Hadamard,S,RZ,RotXZXandCNOT) to the textbook MBQC formalism. (#7870) (#8254)A
dialectssubmodule has been added toqml.compiler.python_compilerwhich now houses all the xDSL dialects we create. Additionally, theMBQCDialectandQuantumDialectdialects have been renamed toMBQCandQuantum. (#7897)The measurement-plane attribute of the unified compiler
mbqcdialect now uses the “opaque syntax” format when printing in the generic IR format. This enables usage of this attribute when IR needs to be passed from xDSL to Catalyst. (#7957)A
diagonalize_mcmsoption has been added to theftqc.decomposition.convert_to_mbqc_formalismtape transform that, when set, maps arbitrary-basis mid-circuit measurements into corresponding diagonalizing gates and Z-basis mid-circuit measurements. (#8105)The
mbqc.graph_state_prepoperation is now integrated into theconvert_to_mbqc_formalismpass. (#8153) (#8301) (#8314) (#8362)A
graph_state_utilssubmodule has been added topython_compiler.transforms.mbqcfor common utilities for MBQC workflows. (#8219) (#8273)Support for
pubchempyhas been updated to1.0.5in the unit tests forqml.qchem.mol_data. (#8224)A nightly RC builds script has been added to
.github/workflows. (#8148)The test files for
estimatorwere renamed to avoid a dual definition error with thelabsmodule. (#8261)
Documentation 📝
The program capture sharp bits page has been updated to include a warning about the experimental nature of the feature. (#8448)
The installation page has been updated to include currently supported Python versions and installation instructions. (#8369)
The documentation of
qml.probsandqml.Hermitianhas been updated with a warning to avoid using them together as the output might be different than expected. Furthermore, a warning is raised if a user attempts to useqml.probswith a Hermitian observable. (#8235)“
>>>“ and “...“ have been removed from “.. code-block::“ directives in docstrings to facilitate docstring testing and fit best practices. (#8319)Three more examples of the deprecated usage of
qml.device(..., shots=...)have been updated in the documentation. (#8298)The documentation of
qml.devicehas been updated to reflect the usage ofset_shots(). (#8294)The “Simplifying Operators” section in the Compiling circuits page has been pushed further down the page to show more relevant sections first. (#8233)
ancillahas been renamed toauxiliaryin internal documentation. (#8005)Small typos in the docstring for
qml.noise.partial_wireshave been corrected. (#8052)The theoretical background section of
BasisRotationhas been extended to explain the underlying Lie group/algebra homomorphism between the (dense) rotation matrix and the performed operations on the target qubits. (#7765)The code examples in the documentation of
specs()have been updated to replace keyword arguments withgradient_kwargsin the QNode definition. (#8003)The documentation for
Operator.powandOperator.adjointhave been updated to clarify optional developer-facing use cases. (#7999)The docstring of the
is_hermitianoperator property has been updated to better describe its behaviour. (#7946)The docstrings of all optimizers have been improved for consistency and legibility. (#7891)
The code example in the documentation for
split_non_commuting()has been updated to give the correct output. (#7892)The \(\LaTeX\) rendering in the documentation for
qml.TrotterProductandqml.trotterizehas been corrected. (#8014)The docstring of
ClassicalShadow.entropyhas been updated to trim out the outdated part of an explanation about the different choices of thealphaparameter. (#8100)A warning has been added to the interfaces documentation under the Pytorch section to explain that all Pytorch floating-point inputs are promoted to
torch.float64. (#8124)The Dynamic Quantum Circuits page has been updated to include the latest device-dependent mid-circuit measurement method defaults. (#8149) (#8444)
A syntax rendering issue in the DefaultQubit documentation has been fixed to correctly display the
max_workersparameter. (#8289)
Bug fixes 🐛
Fixed a bug in
default.qubitwhere the device wasn’t properly validating themcm_methodkeyword argument. (#8343)An error is now raised if postselection is requested for a zero-probability mid-circuit measurement outcome with finite shots and
DefaultQubitwhenmcm_method="deferred"andpostselect_mode="fill-shots", as this previously led to invalid results. (#8389)Applying a transform to a
QNodewith capture enabled now returns aQNode. This allows autograph to transform the user function when transforms are applied to theQNode. (#8307)qml.compiler.python_compiler.transforms.MergeRotationsPassnow takes theadjointproperty of merged operations correctly into account. (#8429)Promoting NumPy data to autograd no longer occurs in
qml.qchem.molecular_hamiltonian. (#8410)Fixed compatibility with JAX and PyTorch input parameters in
SpecialUnitarywhen large numbers of wires are used. (#8209)With
qml.capture.enable(), AutoGraph will now be correctly applied to functions containing control flow that are then wrapped inadjoint()orctrl(). (#8215)Fixed a bug that was causing parameter broadcasting on
default.mixedwith diagonal gates in the computational basis to raise an error. (#8251)qml.ctrl(qml.Barrier(), control_wires)now just returns the originalBarrieroperation, but placed in the circuit where thectrlhappens. (#8238)JIT compilation of
MottonenStatePrepcan now accept statically defined state-vector arrays. (#8222)Pauli arithmetic operations (e.g.,
op.simplify()) can now handle abstract/runtime coefficients when participating in a jitted function. (#8190)Operators queued with
pennylane.apply()no longer get dequeued by subsequent dequeuing operations (e.g.,pennylane.adjoint()). (#8078)Fixed a bug in the decomposition rules of
Selectwith the graph-based decomposition system that broke the decompositions if the targetopsof theSelectoperator were parametrized. This enables the graph-based decomposition system withSelectbeing provided parametrized targetops. (#8186)ExpandEvolutionnow have improved decompositions, allowing them to handle more situations more robustly. In particular, the generator is simplified prior to decomposition. Now, more time evolution operators can be supported on devices that do not natively support them. (#8133)A scalar product of a norm one scalar and an operator now decomposes into a
GlobalPhaseand the operator. For example,-1 * qml.X(0)now decomposes into[qml.GlobalPhase(-np.pi), qml.X(0)]. This improves the decomposition ofSelectwhen there are complicated targetops. (#8133)Fixed a bug that made the queueing behaviour of
qml.PauliWord.operationandqmle.PauliSentence.operationdepndent on the global state of a program due to a caching issue. (#8135)A more informative error is raised when extremely deep circuits are attempted to be drawn. (#8139)
An error is now raised if sequences of classically processed mid-circuit measurements are used as input to
pennylane.counts()orpennylane.probs()(e.g.,qml.counts([2*qml.measure(0), qml.measure(1)])) (#8109)Simplifying operators raised to integer powers no longer causes recursion errors. (#8044)
Fixed a GPU selection issue in
qml.mathwith PyTorch when multiple GPUs are present. (#8008)The
for_loop()function with capture enabled can now properly handle cases whenstart == stop. (#8026)Plxpr primitives now only return dynamically shaped arrays if their outputs actually have dynamic shapes. (#8004)
Fixed an issue with the tree-traversal MCM method and non-sequential wire orders that produced incorrect results. (#7991)
Fixed a bug in
matrix()where an operator’s constituent gates in its decomposition were incorrectly queued, causing extraneous gates to appear in the circuit. (#7976)An error is now raised if an
endstatement is found in a measurement conditioned branch in a QASM string being imported into PennyLane. (#7872)Fixed issue related to
to_zx()adding the support forToffoliandCCZgates conversion into their ZX-graph representation. (#7899)Fixed
qml.workflow.get_best_diff_methodto correctly align withexecuteandconstruct_batchlogic in
the workflow module for internal consistency. (#7898)Issues were resolved with AutoGraph transforming internal PennyLane library code in addition to user-level code, which was causing downstream errors in Catalyst. (#7889)
Fixed a bug that caused calls to
QNode.update(e.g.,circuit.update(...)(shots=10)) to update the shots value as ifset_shotshad been applied, causing unnecessary warnings to appear. (#7881)Fixed attributes and types in the quantum dialect in the unified compiler framework that now allows for types to be inferred correctly when parsing. (#7825)
Fixed a bug in
SemiAdderthat was causing failures when inputs were defined with a single wire. (#7940) (#8437)Fixed a bug where
qml.prod,qml.matrix, andqml.condapplied on a quantum function was not dequeueing operators passed as arguments to the function. (#8094) (#8119) (#8078)Fixed a bug where a copy of
ShadowExpvalMPwas incorrect for a multi-term composite observable. (#8078)Fixed a bug where
cancel_inverses(),merge_rotations(),single_qubit_fusion(),commute_controlled(), andclifford_t_decomposition()were giving incorrect results when acting on (#8297) (8297)When using
mcm_method="tree-traversal"withqml.samples, the data type of the returned values is nowint. This change ensures consistency with the output of other MCM methods. (#8274)The labels for operators that have multiple matrix-valued parameters (e.g. those from
Operator) can now also be drawn correctly (e.g. withqml.draw).
(#8432)Fixed a bug with
~.estimator.resource_mapping._map_to_resource_op()where it was incorrectly mapping the~.TrotterProducttemplate. (#8425)Fixed bugs in the
estimatormodule pertaining to tracking resource operator names, as well as the handling of decompositions and measurement operators by the mapper used by theestimate()function. (#8384)Fixed a bug where
rs_decomposition()logic to streamline queuing conditions were applied incorrectly. (#8441)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Runor Agbaire, Guillermo Alonso, Ali Asadi, Utkarsh Azad, Astral Cai, Joey Carter, Yushao Chen, Isaac De Vlugt, Diksha Dhawan, Gabriela Sanchez Diaz, Marcus Edwards, Lillian Frederiksen, Pietropaolo Frisoni, Simone Gasperini, Diego Guala, Sengthai Heng Austin Huang, David Ittah, Soran Jahangiri, Korbinian Kottmann, Elton Law, Mehrdad Malekmohammadi, Pablo Antonio Moreno Casares, Anton Naim Ibrahim, Erick Ochoa, Lee James O’Riordan, Mudit Pandey, Andrija Paurevic, Justin Pickering, Alex Preciado, Shuli Shu, Jay Soni, Paul Haochen Wang, David Wierichs, Jake Zaia.
Release 0.42.3¶
Bug fixes 🐛
Set
autoraypackage upper-bound inpyproject.tomldue to breaking changes introduced inv0.8.0. (#8111)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Andrija Paurevic.
Release 0.42.2¶
Bug fixes 🐛
Fixed a recursion error when simplifying operators that are raised to integer powers. For example,
>>> class DummyOp(qml.operation.Operator): ... pass >>> (DummyOp(0) ** 2).simplify() DummyOp(0) @ DummyOp(0)
Previously, this would fail with a recursion error. (#8061) (#8064)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Christina Lee, Andrija Paurevic.
Release 0.42.1¶
Bug fixes 🐛
A warning is raised if PennyLane is imported and a version of JAX greater than 0.6.2 is installed. (#7949)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Andrija Paurevic
Release 0.42.0¶
New features since last release
State-of-the-art templates and decompositions 🐝
A new decomposition using unary iteration has been added to
Select. This state-of-the-art decomposition reduces theT-count significantly, and uses \(c-1\) auxiliary wires, where \(c\) is the number of control wires of theSelectoperator. (#7623) (#7744) (#7842)Unary iteration leverages auxiliary wires to store intermediate values for reuse among the different multi-controlled operators, avoiding unnecessary recomputation and leading to more efficient decompositions to elementary gates. This decomposition uses a template called
TemporaryAND, which was also added in this release (see the next changelog entry).This decomposition rule for
Selectis available when the graph-based decomposition system is enabled viaenable_graph():import pennylane as qml from functools import partial qml.decomposition.enable_graph()
To demonstrate the resource-efficiency of this new decomposition, let’s use
decompose()to decompose an instance ofSelectusing the new unary iterator decomposition rule, and further decompose these gates into the Clifford+T gate set usingclifford_t_decomposition()so that we can count the number ofTgates required:reg = qml.registers({"targ": 2, "control": 2, "work": 1}) targ, control, work = (reg[k] for k in reg.keys()) dev = qml.device('default.qubit') ops = [qml.X(targ[0]), qml.X(targ[1]), qml.Y(targ[0]), qml.SWAP(targ)] @qml.clifford_t_decomposition @partial(qml.transforms.decompose, gate_set={ qml.X, qml.CNOT, qml.TemporaryAND, "Adjoint(TemporaryAND)", "CY", "CSWAP" } ) @qml.qnode(dev) def circuit(): qml.Select(ops, control=control, work_wires=work) return qml.state()
>>> unary_specs = qml.specs(circuit)() >>> print(unary_specs['resources'].gate_types["T"]) 16 >>> print(unary_specs['resources'].gate_types["Adjoint(T)"]) 13
Go check out the Unary iterator decomposition section in the
Selectdocumentation for more information!A new template called
TemporaryANDhas been added.TemporaryANDenables more efficient circuit decompositions, such as the newest decomposition of theSelecttemplate. (#7472)The
TemporaryANDoperation is a three-qubit gate equivalent to a logicalANDoperation (or a reversibleToffoli): it assumes that the target qubit is initialized in the|0〉state, whileAdjoint(TemporaryAND)assumes the target qubit will be output into the|0〉state. For more details, see Fig. 4 in arXiv:1805.03662.from functools import partial dev = qml.device("default.qubit") @partial(qml.set_shots, shots=1) @qml.qnode(dev) def circuit(): # |0000⟩ qml.X(0) # |1000⟩ qml.X(1) # |1100⟩ # The target wire is in state |0>, so we can apply TemporaryAND qml.TemporaryAND([0, 1, 2]) # |1110⟩ qml.CNOT([2, 3]) # |1111⟩ # The target wire will be in state |0> after adjoint(TemporaryAND) gate is applied # so we can apply adjoint(TemporaryAND) qml.adjoint(qml.TemporaryAND([0, 1, 2])) # |1101⟩ return qml.sample(wires=[0, 1, 2, 3])
>>> print(circuit()) [1 1 0 1]
A new template called
SemiAdderhas been added, which provides state-of-the-art resource-efficiency (fewerTgates) when performing addition on a quantum computer. (#7494)Based on arXiv:1709.06648,
SemiAdderperforms the plain addition of two integers in the computational basis. Here is an example of performing3 + 4 = 7with 5 additional work wires:from functools import partial x = 3 y = 4 wires = qml.registers({"x": 3, "y": 6, "work": 5}) dev = qml.device("default.qubit") @partial(qml.set_shots, shots=1) @qml.qnode(dev) def circuit(): qml.BasisEmbedding(x, wires=wires["x"]) qml.BasisEmbedding(y, wires=wires["y"]) qml.SemiAdder(wires["x"], wires["y"], wires["work"]) return qml.sample(wires=wires["y"])
>>> print(circuit()) [0 0 0 1 1 1]
The result
[0 0 0 1 1 1]is the binary representation of7.A new template called
SelectPauliRotis available, which applies a sequence of uniformly controlled rotations on a target qubit. This operator appears frequently in unitary decompositions and block-encoding techniques. (#7206) (#7617)As input,
SelectPauliRotrequires theanglesof rotation to be applied to the target qubit for each control register configuration, as well as thecontrol_wires, thetarget_wire, and the axis of rotation (rot_axis) for which each rotation is performed (the default is the"Z"axis).import numpy as np angles = np.array([1.0, 2.0, 3.0, 4.0]) wires = qml.registers({"control": 2, "target": 1}) dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circuit(): qml.SelectPauliRot( angles, control_wires=wires["control"], target_wire=wires["target"], rot_axis="Z" ) return qml.state()
>>> print(qml.draw(circuit, level="device")()) 0: ─────────────────────────╭●───────────────╭●─┤ ╭State 1: ───────────╭●────────────│──╭●────────────│──┤ ├State 2: ──RZ(2.50)─╰X──RZ(-0.50)─╰X─╰X──RZ(-1.00)─╰X─┤ ╰State
The decompositions of
SingleExcitation,SingleExcitationMinusandSingleExcitationPlushave been made more efficient by reducing the number of rotations gates andCNOT,CZ, andCYgates (where applicable). This leads to lower circuit depth when decomposing these gates. (#7771)
QSVT & QSP angle solver for large polynomials 🕸️
Effortlessly perform QSVT and QSP with polynomials of large degrees, using our new iterative angle solver.
A new iterative angle solver for QSVT and QSP is available in the
poly_to_anglesfunction, designed for angle computation for polynomials with degrees larger than 1000. (6694)Simply set
angle_solver="iterative"in thepoly_to_anglesfunction to use it.import numpy as np # P(x) = x - 0.5 x^3 + 0.25 x^5 poly = np.array([0, 1.0, 0, -1/2, 0, 1/4]) qsvt_angles = qml.poly_to_angles(poly, "QSVT", angle_solver="iterative")
>>> print(qsvt_angles) [-4.72195208 1.59759022 1.12953398 1.12953403 1.59759046 -0.00956271]
This functionality can also be accessed directly from
qml.qsvtwith the same keyword argument:# P(x) = -x + 0.5 x^3 + 0.5 x^5 poly = np.array([0, -1, 0, 0.5, 0, 0.5]) hamiltonian = qml.dot([0.3, 0.7], [qml.Z(1), qml.X(1) @ qml.Z(2)]) dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.qsvt( hamiltonian, poly, encoding_wires=[0], block_encoding="prepselprep", angle_solver="iterative" ) return qml.state() matrix = qml.matrix(circuit, wire_order=[0, 1, 2])()
>>> print(matrix[:4, :4].real) [[-0.16253996 0. -0.37925991 0. ] [ 0. -0.16253996 0. 0.37925991] [-0.37925991 0. 0.16253996 0. ] [ 0. 0.37925991 0. 0.16253996]]
Qualtran integration 🔗
It’s now possible to convert PennyLane circuits and operators to Qualtran circuits and Bloqs with the new
qml.to_bloqfunction. This function translates PennyLane circuits (qfuncs or QNodes) and operations into equivalent Qualtran bloqs, enabling a new way to estimate the resource requirements of PennyLane quantum circuits via Qualtran’s abstractions and tools. (#7197) (#7604) (#7536) (#7814)qml.to_bloqcan be used in the following ways:Wrap PennyLane circuits and operations to give them Qualtran features, like obtaining bloq_counts and drawing a call_graph, but preserve PennyLane’s definition of the circuit/operator. This is done by setting
map_opstoFalse, which instead wraps operations as aToBloq:>>> def circuit(): ... qml.X(0) ... qml.Y(1) ... qml.Z(2) ... >>> cbloq = qml.to_bloq(circuit, map_ops=False) >>> type(cbloq) pennylane.io.qualtran_io.ToBloq >>> cbloq.bloq_counts() {XGate(): 1, ZGate(): 1, YGate(): 1}
Use smart default mapping of PennyLane circuits and operations to Qualtran Bloqs by setting
map_ops=True(the default value):>>> PL_op = qml.X(0) >>> qualtran_op = qml.to_bloq(PL_op) >>> type(qualtran_op) qualtran.bloqs.basic_gates.x_basis.XGate
Use custom user-defined mapping of PennyLane circuits and operations to Qualtran Bloqs by setting a
custom_mappingdictionary:from qualtran.bloqs.basic_gates import XGate def circuit(): qml.QubitUnitary([[0, 1],[1, 0]], wires=0) qml.QubitUnitary([[0, 1],[1, 0]], wires=0) qml.QubitUnitary([[0, 1],[1, 0]], wires=0)
>>> PL_op = qml.QubitUnitary([[0, 1],[1, 0]], wires=0) >>> qualtran_op = XGate() >>> custom_map = {PL_op: qualtran_op} >>> bloq = qml.to_bloq(circuit, custom_mapping=custom_map) >>> bloq.bloq_counts() {XGate(): 3}
Resource-efficient Clifford-T decompositions 🍃
The Ross-Selinger algorithm, also known as Gridsynth, can now be accessed in
clifford_t_decomposition()by settingmethod="gridsynth". This is a newer Clifford-T decomposition method that can produce orders of magnitude fewer gates than usingmethod="sk"(Solovay-Kitaev algorithm). (#7588) (#7641) (#7611) (#7711) (#7770) (#7791)In the following example, decomposing with
method="gridsynth"instead ofmethod="sk"gives a significant reduction in overall gate counts, specifically theTcount:@qml.qnode(qml.device("lightning.qubit", wires=2)) def circuit(): qml.RX(0.12, 0) qml.CNOT([0, 1]) qml.RY(0.34, 0) return qml.expval(qml.Z(0))
We can inspect the gate counts resulting from both decomposition methods with
specs():>>> gridsynth_circuit = qml.clifford_t_decomposition(circuit, method="gridsynth") >>> sk_circuit = qml.clifford_t_decomposition(circuit, method="sk") >>> gridsynth_specs = qml.specs(gridsynth_circuit)()["resources"] >>> sk_specs = qml.specs(sk_circuit)()["resources"] >>> print(gridsynth_specs.num_gates, sk_specs.num_gates) 239 47942 >>> print(gridsynth_specs.gate_types['T'], sk_specs.gate_types['T']) 90 8044
OpenQASM 🤝 PennyLane
PennyLane now offers improved support for OpenQASM 2.0 & 3.0.
Use the new
qml.from_qasm3function to convert your OpenQASM 3.0 circuits into quantum functions which can then be loaded into QNodes and executed. (#7495) (#7486) (#7488) (#7593) (#7498) (#7469) (#7543) (#7783) (#7789) (#7802)import pennylane as qml dev = qml.device("default.qubit", wires=[0, 1, 2]) @qml.qnode(dev) def my_circuit(): qml.from_qasm3( """ qubit q0; qubit q1; qubit q2; float theta = 0.2; int power = 2; ry(theta / 2) q0; rx(theta) q1; pow(power) @ x q0; def random(qubit q) -> bit { bit b = "0"; h q; measure q -> b; return b; } bit m = random(q2); if (m) { int i = 0; while (i < 5) { i = i + 1; rz(i) q1; break; } } """, {'q0': 0, 'q1': 1, 'q2': 2}, )() return qml.expval(qml.Z(0))
>>> print(qml.draw(my_circuit)()) 0: ──RY(0.10)──X²────────────┤ <Z> 1: ──RX(0.20)───────RZ(1.00)─┤ 2: ──H─────────┤↗├──║────────┤ ╚═══╝
Some gates and operations in OpenQASM 3.0 programs are not currently supported. For more details, please consult the documentation for
qml.from_qasm3and ensure that you have installedopenqasm3and'openqasm3[parser]'in your environment by following the OpenQASM 3.0 installation instructions.The new
qml.to_openqasmfunction enables conversion of PennyLane circuits to OpenQASM 2.0 programs. (#7393)Consider this simple circuit in PennyLane:
from functools import partial dev = qml.device("default.qubit", wires=2) @partial(qml.set_shots, shots=100) @qml.qnode(dev) def circuit(theta, phi): qml.RX(theta, wires=0) qml.CNOT(wires=[0,1]) qml.RZ(phi, wires=1) return qml.sample()
This can be easily converted to OpenQASM 2.0 with
qml.to_openqasm:>>> openqasm_circ = qml.to_openqasm(circuit)(1.2, 0.9) >>> print(openqasm_circ) OPENQASM 2.0; include "qelib1.inc"; qreg q[2]; creg c[2]; rx(1.2) q[0]; cx q[0],q[1]; rz(0.9) q[1]; measure q[0] -> c[0]; measure q[1] -> c[1];
Improvements 🛠
A quantum optimizer that works with QJIT
Leveraging quantum just-in-time compilation to optimize parameterized hybrid workflows with the quantum natural gradient optimizer is now possible with the new
QNGOptimizerQJIToptimizer. (#7452)The
QNGOptimizerQJIToptimizer offers ajax.jit- andqml.qjit-compatible analogue to the existingQNGOptimizerwith an Optax-like interface:import jax.numpy as jnp @qml.qjit(autograph=True) def workflow(): dev = qml.device("lightning.qubit", wires=2) @qml.qnode(dev) def circuit(params): qml.RX(params[0], wires=0) qml.RY(params[1], wires=1) return qml.expval(qml.Z(0) + qml.X(1)) opt = qml.QNGOptimizerQJIT(stepsize=0.2) params = jnp.array([0.1, 0.2]) state = opt.init(params) for _ in range(100): params, state = opt.step(circuit, params, state) return params
>>> workflow() Array([ 3.14159265, -1.57079633], dtype=float64)
Resource-efficient decompositions 🔎
With graph-based decomposition enabled via
enable_graph(), thedecompose()transform now supports weighting gates in the targetgate_set, allowing for preferential treatment of certain gates in a targetgate_setover others. (#7389)Gates specified in
gate_setcan be given a numerical weight associated with their effective cost to have in a circuit:Gate weights that are greater than 1 indicate a greater cost (less preferred).
Gate weights that are less than 1 indicate a lower cost (more preferred).
Consider the following toy example, where
CZgates are highly preferred to decompose into, butHandCRZgates are quite costly.from functools import partial qml.decomposition.enable_graph() @partial( qml.transforms.decompose, gate_set={ qml.Toffoli: 1.23, qml.RX: 4.56, qml.CZ: 0.01, qml.H: 420, qml.CRZ: 100 } ) @qml.qnode(qml.device("default.qubit")) def circuit(): qml.CRX(0.1, wires=[0, 1]) qml.Toffoli(wires=[0, 1, 2]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ───────────╭●────────────╭●─╭●─┤ <Z> 1: ──RX(0.05)─╰Z──RX(-0.05)─╰Z─├●─┤ 2: ────────────────────────────╰X─┤
By reducing the
HandCRZweights, the circuit decomposition changes:qml.decomposition.enable_graph() @partial( qml.transforms.decompose, gate_set={ qml.Toffoli: 1.23, qml.RX: 4.56, qml.CZ: 0.01, qml.H: 0.1, qml.CRZ: 0.1 } ) @qml.qnode(qml.device("default.qubit")) def circuit(): qml.CRX(0.1, wires=[0, 1]) qml.Toffoli(wires=[0, 1, 2]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ────╭●───────────╭●─┤ <Z> 1: ──H─╰RZ(0.10)──H─├●─┤ 2: ─────────────────╰X─┤
Decomposition rules that can be accessed with the new graph-based decomposition system have been implemented for the following operators:
With graph-based decomposition enabled with
enable_graph(), a new decomposition rule that uses a single work wire for decomposing multi-controlled operators can be accessed. (#7383)With graph-based decomposition enabled with
enable_graph(), a new decorator calledregister_condition()can be used to bind a condition to a decomposition rule denoting when it is applicable. (#7439)The condition should be a function that takes the resource parameters of an operator as arguments and returns
TrueorFalsebased on whether these parameters satisfy the condition for when this rule can be applied.Here is an example of adding a decomposition rule to
QubitUnitary, where the condition for which this decomposition rule applies is when the number of wiresQubitUnitaryacts on is exactly one:from pennylane.math.decomposition import zyz_rotation_angles qml.decomposition.enable_graph() # The parameters must be consistent with ``qml.QubitUnitary.resource_keys`` def _zyz_condition(num_wires): return num_wires == 1 @qml.register_condition(_zyz_condition) @qml.register_resources({qml.RZ: 2, qml.RY: 1, qml.GlobalPhase: 1}) def zyz_decomposition(U, wires, **__): # Assumes that U is a 2x2 unitary matrix phi, theta, omega, phase = zyz_rotation_angles(U, return_global_phase=True) qml.RZ(phi, wires=wires[0]) qml.RY(theta, wires=wires[0]) qml.RZ(omega, wires=wires[0]) qml.GlobalPhase(-phase) # This decomposition will be ignored for `QubitUnitary` on more than one wire. qml.add_decomps(qml.QubitUnitary, zyz_decomposition)
Symbolic operator types (e.g.,
Adjoint,Controlled, andPow) can now be specified as strings in various parts of the new graph-based decomposition system:The
gate_setargument of thedecompose()transform now supports adding symbolic operators in the target gate set. (#7331)from functools import partial qml.decomposition.enable_graph() @partial(qml.transforms.decompose, gate_set={"T", "Adjoint(T)", "H", "CNOT"}) @qml.qnode(qml.device("default.qubit")) def circuit(): qml.Toffoli(wires=[0, 1, 2])
>>> print(qml.draw(circuit)()) 0: ───────────╭●───────────╭●────╭●──T──╭●─┤ 1: ────╭●─────│─────╭●─────│───T─╰X──T†─╰X─┤ 2: ──H─╰X──T†─╰X──T─╰X──T†─╰X──T──H────────┤
Symbolic operator types can now be given as strings to the
op_typeargument ofadd_decomps(), or as keys of the dictionaries passed to thealt_decompsandfixed_decompsarguments of thedecompose()transform, allowing custom decomposition rules to be defined and registered for symbolic operators. (#7347) (#7352) (#7362) (#7499)@qml.register_resources({qml.RY: 1}) def my_adjoint_ry(phi, wires, **_): qml.RY(-phi, wires=wires) @qml.register_resources({qml.RX: 1}) def my_adjoint_rx(phi, wires, **__): qml.RX(-phi, wires) # Registers a decomposition rule for the adjoint of RY globally qml.add_decomps("Adjoint(RY)", my_adjoint_ry) @partial( qml.transforms.decompose, gate_set={"RX", "RY", "CNOT"}, fixed_decomps={"Adjoint(RX)": my_adjoint_rx} ) @qml.qnode(qml.device("default.qubit")) def circuit(): qml.adjoint(qml.RX(0.5, wires=[0])) qml.CNOT(wires=[0, 1]) qml.adjoint(qml.RY(0.5, wires=[1])) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──RX(-0.50)─╭●────────────┤ <Z> 1: ────────────╰X──RY(-0.50)─┤
A
work_wire_typeargument has been added toctrl()andControlledQubitUnitaryfor more fine-grained control over the type of work wire used in their decompositions. (#7612)The
decompose()transform now accepts astopping_conditionargument with graph-based decomposition enabled, which must be a function that returnsTrueif an operator does not need to be decomposed (it meets the requirements as described instopping_condition). See the documentation for more details. (#7531)Two-qubit
QubitUnitarygates no longer decompose into fundamental rotation gates; it now decomposes into single-qubitQubitUnitarygates. This allows the graph-based decomposition system to further decompose single-qubit unitary gates more flexibly using different rotations. (#7211)A new decomposition for two-qubit unitaries has been implemented in
two_qubit_decomposition(). It ensures the correctness of the decomposition in some edge cases but uses 3 CNOT gates even if 2 CNOTs would suffice theoretically. (#7474)The
gate_setargument ofdecompose()now accepts"X","Y","Z","H","I"as aliases for"PauliX","PauliY","PauliZ","Hadamard", and"Identity". These aliases are also recognized as part of symbolic operators. For example,"Adjoint(H)"is now accepted as an alias for"Adjoint(Hadamard)". (#7331)
Setting shots 🔁
A new QNode transform called
set_shots()has been added to set or update the number of shots to be performed, overriding shots specified in the device. (#7337) (#7358) (#7415) (#7500) (#7627)The
set_shots()transform can be used as a decorator:@partial(qml.set_shots, shots=2) @qml.qnode(qml.device("default.qubit", wires=1)) def circuit(): qml.RX(1.23, wires=0) return qml.sample(qml.Z(0))
>>> circuit() array([1., -1.])
Or, it can be used in-line to update a circuit’s
shots:>>> new_circ = qml.set_shots(circuit, shots=(4, 10)) # shot vector >>> new_circ() (array([-1., 1., -1., 1.]), array([ 1., 1., 1., -1., 1., 1., -1., -1., 1., 1.]))
QChem
The
qchemmodule has been upgraded with new functions to construct a vibrational Hamiltonian in the Christiansen representation. (#7491) (#7596) (#7785)The new functions
christiansen_hamiltonian()andqml.qchem.christiansen_bosonic()can be used to create the qubit and bosonic form of the Christiansen Hamiltonian, respectively. These functions need input parameters that can be easily obtained by using thechristiansen_integrals()andvibrational_pes()functions. Similarly, a Christiansen dipole operator can be created by using thechristiansen_dipole()andchristiansen_integrals_dipole()functions.import numpy as np symbols = ['H', 'F'] geometry = np.array([[0.0, 0.0, -0.40277116], [0.0, 0.0, 1.40277116]]) mol = qml.qchem.Molecule(symbols, geometry) pes = qml.qchem.vibrational_pes(mol, optimize=False) ham = qml.qchem.vibrational.christiansen_hamiltonian(pes, n_states = 4)
>>> ham ( 0.08527499987546708 * I(0) + -0.0051774006335491545 * Z(0) + 0.0009697024705108074 * (X(0) @ X(1)) + 0.0009697024705108074 * (Y(0) @ Y(1)) + 0.0002321787923591865 * (X(0) @ X(2)) + 0.0002321787923591865 * (Y(0) @ Y(2)) + 0.0008190498635406456 * (X(0) @ X(3)) + 0.0008190498635406456 * (Y(0) @ Y(3)) + -0.015699890427524253 * Z(1) + 0.002790002362847834 * (X(1) @ X(2)) + 0.002790002362847834 * (Y(1) @ Y(2)) + 0.000687929225764568 * (X(1) @ X(3)) + 0.000687929225764568 * (Y(1) @ Y(3)) + -0.026572392417060237 * Z(2) + 0.005239546276220405 * (X(2) @ X(3)) + 0.005239546276220405 * (Y(2) @ Y(3)) + -0.037825316397333435 * Z(3) )
Experimental FTQC module
Commutation rules for a Clifford gate set (
qml.H,qml.S,qml.CNOT) have been added to theftqc.pauli_trackermodule, accessible via thecommute_clifford_opfunction. (#7444)Offline byproduct correction support has been added to the
ftqcmodule. (#7447)The
ftqcmodulemeasure_arbitrary_basis,measure_xandmeasure_yfunctions can now be captured when program capture is enabled. (#7219) (#7368)Functions called
pauli_to_xz,xz_to_pauliandpauli_prodthat are related toxz-encoding have been added to theftqcmodule. (#7433)A new transform called
convert_to_mbqc_formalismhas been added to theftqcmodule to convert a circuit already expressed in a limited, compatible gate set into the MBQC formalism. Circuits can be converted to the relevant gate set with theconvert_to_mbqc_gatesettransform. (#7355) (#7586)The
RotXZXoperation has been added to theftqcmodule to support the definition of a universal gate set that can be translated to the MBQC formalism. (#7271)
Other improvements
qml.evolvenow errors out if the first argument is not a valid type. (#7768)qml.PauliErrornow accepts Pauli strings that include the identity operator. (#7760)Caching with finite shots now always warns about the lack of expected noise. (#7644)
cachenow defaults to"auto"withqml.execute, matching the behavior ofQNodeand increasing the performance of usingqml.executefor standard executions. (#7644)qml.gradandqml.jacobiancan now handle inputs with dynamic shapes being captured into plxpr. (#7544)The drawing of
GlobalPhase,ctrl(GlobalPhase),Identityandctrl(Identity)operations has been improved. The labels are grouped together as in other multi-qubit operations, and the drawing no longer depends on the wires ofGlobalPhaseorIdentity. Control nodes of controlled global phases and identities no longer receive the operator label, which is in line with other controlled operations. (#7457)The decomposition of
PCPhaseis now significantly more efficient for more than 2 qubits. (#7166)The decomposition of
IntegerComparatoris now significantly more efficient. (#7636)QubitUnitarynow supports a decomposition that is compatible with an arbitrary number of qubits. This represents a fundamental improvement over the previous implementation, which was limited to two-qubit systems. (#7277)Setting up the configuration of a workflow, including the determination of the best diff method, is now done after user transforms have been applied. This allows transforms to update the shots and change measurement processes with fewer issues. (#7358) (#7461)
The decomposition of
DiagonalQubitUnitaryhas been updated from a recursive decomposition into a smallerDiagonalQubitUnitaryand aSelectPauliRotoperation. This is a known decomposition from Theorem 7 in Shende et al. that contains fewer gates. (#7370)An experimental integration for a Python compiler using xDSL has been introduced. This is similar to Catalyst’s MLIR dialects, but it is coded in Python instead of C++. Compiler passes written using xDSL can be registered as compatible passes via the
@compiler_transformdecorator. (#7509) (#7357) (#7367) (#7462) (#7470) (#7510) (#7590) (#7706)An xDSL pass called
qml.compiler.python_compiler.transforms.MergeRotationsPasshas been added for applyingmerge_rotationsto an xDSL module for the experimental xDSL Python compiler integration. (#7364) (#7595) (#7664)An xDSL pass called
qml.compiler.python_compiler.transforms.IterativeCancelInversesPasshas been added for applyingcancel_inversesiteratively to an xDSL module for the experimental xDSL Python compiler integration. This pass is optimized to cancel self-inverse operations iteratively. (#7363) (#7595)PennyLane now supports
jax == 0.6.0and0.5.3. (#6919) (#7299)The alias for
Identity(I) is now accessible fromqml.ops. (#7200)A new
allocationmodule containingallocateanddeallocateinstructions has been added for requesting dynamic wires. This is currently experimental and not integrated into any execution pipelines. (#7704) (#7710)Computing the angles for uniformly controlled rotations, used in
MottonenStatePreparationandSelectPauliRotnow takes much less computational effort and memory. (#7377)Classical shadows with mixed quantum states are now computed with a dedicated method that uses an iterative algorithm similar to the handling of shadows with state vectors. This makes shadows with density matrices much more performant. (#7458)
Two new functions called
convert_to_su2()andconvert_to_su4()have been added toqml.math, which convert unitary matrices to SU(2) or SU(4), respectively, and optionally a global phase. (#7211)Operator.num_wiresnow defaults toNoneto indicate that the operator can be on any number of wires. (#7312)Shots can now be overridden for specific
qml.Snapshotinstances via ashotskeyword argument. (#7326)from functools import partial dev = qml.device("default.qubit", wires=2) @partial(qml.set_shots, shots=10) @qml.qnode(dev) def circuit(): qml.Snapshot("sample", measurement=qml.sample(qml.X(0)), shots=5) return qml.sample(qml.X(0))
>>> qml.snapshots(circuit)() {'sample': array([-1., -1., -1., -1., -1.]), 'execution_results': array([ 1., -1., -1., -1., -1., 1., -1., -1., 1., -1.])}
PennyLane no longer validates that an operation has at least one wire, as having this check reduced performance by requiring the abstract interface to maintain a list of special implementations. (#7327)
Two new device-developer transforms have been added to
devices.preprocess:measurements_from_counts()andmeasurements_from_samples(). These transforms modify the tape to instead contain acountsorsamplemeasurement process, deriving the original measurements from the raw counts/samples in post-processing. This allows expanded measurement support for devices that only support counts/samples at execution, like real hardware devices. (#7317)The Sphinx version was updated to 8.1. (7212)
The
setup.pypackage build and install has been migrated topyproject.toml. (#7375)GitHub actions and workflows (
rtd.yml,readthedocs.yml, anddocs.yml) have been updated to useubuntu-24.04runners. (#7396)The requirements and pyproject files have been updated to include other packages.
(#7417)Documentation checks have been updated to remove duplicate docstring references. (#7453)
The performance of
qml.clifford_t_decompositionhas been improved by introducing caching support and changing the default basis set ofqml.ops.sk_decompositionto(H, S, T), resulting in shorter decomposition sequences. (#7454)The decomposition of
qml.BasisStatewith capture and the graph-based decomposition systems enabled is more efficient. (#7722)
Labs: a place for unified and rapid prototyping of research software 🧪
The imports of dependencies introduced by
labsfunctionalities have been modified such that these dependencies only have to be installed for the functions that use them, not to uselabsfunctionalities in general. This decouples the various submodules, and even functions within the same submodule, from each other. (#7650)A new module called
qml.labs.intermediate_repshas been added to provide functionality to compute intermediate representations for particular circuits. Theparity_matrixfunction computes the parity matrix intermediate representation forCNOTcircuits, and thephase_polynomialfunction computes the phase polynomial intermediate representation for{CNOT, RZ}circuits. These efficient intermediate representations are important for CNOT routing algorithms and other quantum compilation routines. (#7229) (#7333) (#7629)The
pennylane.labs.vibrationalmodule has been upgraded to use features from theconcurrencymodule to perform multiprocess and multithreaded execution. (#7401)A
rowcolfunction is now available inqml.labs.intermediate_reps. Given the parity matrix of aCNOTcircuit and a qubit connectivity graph, it synthesizes a possible implementation of the parity matrix that respects the connectivity. (#7394)qml.labs.QubitManager,qml.labs.AllocWires, andqml.labs.FreeWiresclasses have been added to track and manage auxiliary qubits. (#7404)A new function called
qml.labs.map_to_resource_ophas been added to map PennyLane Operations to their resource equivalents. (#7434)A new class called
qml.labs.Resourceshas been added to store and track the quantum resources from a circuit. (#7406)A new class called
qml.labs.CompressedResourceOpclass has been added to store information about the operator type and parameters for the purposes of resource estimation. (#7408)A base class called
qml.labs.ResourceOperatorhas been added which will be used to implement all quantum operators for resource estimation. (#7399) (#7526) (#7540) (#7541) (#7584) (#7549)A new function called
qml.labs.estimate_resourceshas been added which will be used to perform resource estimation on circuits,qml.labs.ResourceOperator, andqml.labs.Resourcesobjects. (#7407)A new class called
qml.labs.resource_estimation.CompactHamiltonianhas been added to unblock the need to pass a full Hamiltonian for the purposes of resource estimation. In addition, similar templates calledqml.labs.resource_estimation.ResourceTrotterCDFandqml.labs.resource_estimation.ResourceTrotterTHChave been added, which will be used to perform resource estimation for trotterization of CDF and THC Hamiltonians, respectively. (#7705)A new template called
qml.labs.ResourceQubitizehas been added which can be used to perform resource estimation for qubitization of the THC Hamiltonian. (#7730)Two new templates called
qml.labs.resource_estimation.ResourceTrotterVibrationalandqml.labs.resource_estimation.ResourceTrotterVibronichave been added to perform resource estimation for trotterization of vibrational and vibronic Hamiltonians, respectively. (#7720)Several new templates for various algorithms required for supporting compact Hamiltonian development and resource estimation have been added:
qml.ResourceOutOfPlaceSquare,qml.ResourcePhaseGradient,qml.ResourceOutMultiplier,qml.ResourceSemiAdder,qml.ResourceBasisRotation,qml.ResourceSelect, andqml.ResourceQROM. (#7725)A new module called
qml.labs.zxopthas been added to provide access to the basic optimization passes from pyzx for PennyLane circuits. (#7471)basic_optimizationperforms peephole optimizations on the circuit and is a useful subroutine for other optimization passes.full_optimizeoptimizes (Clifford + T) circuits.full_reducecan optimize arbitrary PennyLane circuits and follows the pipeline described in the pyzx docs.toddperforms Third Order Duplicate and Destroy (TODD) via phase polynomials and reduces T gate counts.
New functionality has been added to create and manipulate product formulas in the
trotter_errormodule. (#7224)ProductFormula <pennylane.labs.trotter_error.ProductFormulaallows users to create custom product formulas.bch_expansion <pennylane.labs.trotter_error.bch_expansion()computes the Baker-Campbell-Hausdorff expansion of a product formula.effective_hamiltonian <pennylane.labs.trotter_error.effective_hamiltonian()computes the effective Hamiltonian of a product formula.
The
perturbation_errorhas been optimized for better performance by grouping commutators by linearity and by using a task-based executor to parallelize the computationally heavy parts of the algorithm. (#7681) (#7790)Missing table descriptions for
qml.FromBloq,qml.qchem.two_particle, andqml.ParticleConservingU2have been fixed. (#7628)
Breaking changes 💔
Support for gradient keyword arguments as QNode keyword arguments has been removed. Instead please use the new
gradient_kwargskeyword argument accordingly. (#7648)The default value of
cacheis now"auto"withqml.execute. LikeQNode,"auto"only turns on caching whenmax_diff > 1. (#7644)The
return_typeproperty ofMeasurementProcesshas been removed. Please useisinstancefor type checking instead. (#7322)The
KerasLayerclass inqml.qnn.kerashas been removed because Keras 2 is no longer actively maintained. Please consider using a different machine learning framework, like PyTorch or JAX. (#7320)The
qml.gradients.hamiltonian_gradfunction has been removed because this gradient recipe is no longer required with the new operator arithmetic system. (#7302)Accessing terms of a tensor product (e.g.,
op = X(0) @ X(1)) viaop.obshas been removed. (#7324)The
mcm_methodkeyword argument inqml.executehas been removed. (#7301)The
inner_transformandconfigkeyword arguments inqml.executehave been removed. (#7300)Sum.ops,Sum.coeffs,Prod.opsandProd.coeffshave been removed. (#7304)Specifying
pipeline=Nonewithqml.compilehas been removed. (#7307)The
control_wiresargument inqml.ControlledQubitUnitaryhas been removed. Furthermore, theControlledQubitUnitaryno longer acceptsQubitUnitaryobjects as arguments as itsbase. (#7305)qml.tape.TapeErrorhas been removed. (#7205)
Deprecations 👋
Here’s a list of deprecations made this release. For a more detailed breakdown of deprecations and alternative code to use instead, please consult the deprecations and removals page.
Python 3.10 support is deprecated and support will be removed in v0.43. Please upgrade to Python 3.11 or newer.
Support for Mac x86 has been removed. This includes Macs running on Intel processors. This is because JAX has also dropped support for it since 0.5.0, with the rationale being that such machines are becoming increasingly scarce. If support for Mac x86 platforms is still desired, please install Catalyst v0.11.0, PennyLane v0.41.0, PennyLane-Lightning v0.41.0, and JAX v0.4.28.
Top-level access to
DeviceError,PennyLaneDeprecationWarning,QuantumFunctionErrorandExperimentalWarninghave been deprecated and will be removed in v0.43. Please import them from the newexceptionsmodule. (#7292) (#7477) (#7508) (#7603)qml.operation.Observableand the correspondingObservable.comparehave been deprecated, as PennyLane now depends on the more generalOperatorinterface instead. TheOperator.is_hermitianproperty can instead be used to check whether or not it is highly likely that the operator instance is Hermitian. (#7316)The boolean functions provided in
qml.operationare deprecated. See the deprecations page for equivalent code to use instead. These includenot_tape,has_gen,has_grad_method,has_multipar,has_nopar,has_unitary_gen,is_measurement,defines_diagonalizing_gates, andgen_is_multi_term_hamiltonian. (#7319)qml.operation.WiresEnum,qml.operation.AllWires, andqml.operation.AnyWiresare deprecated. To indicate that an operator can act on any number of wires,Operator.num_wires = Noneshould be used instead. This is the default and does not need to be overwritten unless the operator developer wants to add wire number validation. (#7313)The
qml.QNode.get_gradient_fn()method is now deprecated. Instead, useget_best_diff_method()to obtain the differentiation method. (#7323)
Internal changes ⚙️
Jits the
givens_matrixcomputation fromBasisRotationwhen it is within a jit context, which significantly reduces the program size and compilation time of workflows. (#7823)Private code in the
TransformProgramhas been moved to theCotransformCacheclass. (#7750)Type hinting in the
workflowmodule has been improved. (#7745)mitiqhas been unpinned in the CI. (#7742)The
qml.measurements.Shotsclass can now handle abstract numbers of shots. (#7729)The
jaxandtensorflowdependencies fordocbuilds have been updated. (#7667)Pennylanehas been renamed topennylanein thepyproject.tomlfile to match the expected binary distribution format naming conventions. (#7689)The
qml.compiler.python_compilersubmodule has been restructured. (#7645)Program capture code has been moved closer to where it is used. (#7608)
Tests using
OpenFermionintests/qchemno longer fail with NumPy>=2.0.0. (#7626)The
givens_decompositionfunction and private helpers fromqchemhave been moved to themathmodule. (#7545)Module dependencies in
pennylaneusingtachhave been enforced. (#7185) (#7416) (#7418) (#7429) (#7430) (#7437) (#7504) (#7538) (#7542) (#7667) (#7743)With program capture enabled, MCM method validation now happens on execution rather than setup. (#7475)
A
.git-blame-ignore-revsfile has been added to the PennyLane repository. This file will allow specifying commits that should be ignored in the output ofgit blame. For example, this can be useful when a single commit includes bulk reformatting. (#7507)A
.gitattributesfile has been added to standardize LF as the end-of-line character for the PennyLane repository. (#7502)DefaultQubitnow implementspreprocess_transformsandsetup_execution_configinstead ofpreprocess. (#7468)A subset of
pylinterrors have been fixed in thetestsfolder. (#7446)Excessively expensive test cases that do not add value in
tests/templates/test_subroutines/have been reduced or removed. (#7436)pytest-timeoutis no longer used in the PennyLane CI/CD pipeline. (#7451)A
RuntimeWarningraised when using versions of JAX > 0.4.28 has been removed. (#7398)Wheel releases for PennyLane now follow the
PyPA binary-distribution format <https://packaging.python.org/en/latest/specifications/binary-distribution-format/>_guidelines more closely. (#7382)null.qubitcan now support an optionaltrack_resourcesargument which allows it to record which gates are executed. (#7226) (#7372) (#7392) (#7813)A new internal module,
qml.concurrency, is added to support internal use of multiprocess and multithreaded execution of workloads. This also migrates the use ofconcurrent.futuresindefault.qubitto this new design. (#7303)Test suites in
tests/transforms/test_defer_measurement.pynow use analytic mocker devices to test numeric results. (#7329)A new
pennylane.exceptionsmodule has been added for custom errors and warnings. (#7205) (#7292)Several
__init__.pyfiles inmath,ops,qaoa,tapeandtemplateshave been cleaned up to be explicit in what they import. (#7200)The
Trackerclass has been moved into thedevicesmodule. (#7281)Functions that calculate rotation angles for unitary decompositions have been moved into an internal module called
qml.math.decomposition. (#7211)Fixed a failing integration test for
qml.QDriftwhich multiplied the operators of the decomposition incorrectly to evolve the state. (#7621)The decomposition test in
assert_validno longer checks the matrix of the decomposition if the operator does not define a matrix representation. (#7655)
Documentation 📝
The documentation for mid-circuit measurements using the Tree Traversal algorithm has been updated to reflect supported devices and usage in analytic simulations (see the Dynamic quantum circuits page). (#7691)
The functions in
qml.qchem.vibrationalhave been updated to include additional information about the theory and input arguments. (#6918)The usage examples for
qml.decomposition.DecompositionGraphhave been updated. (#7692)The entry in the Program capture sharp bits has been updated to include additional supported lightning devices (
lightning.kokkosandlightning.gpu). (#7674)The circuit drawings for
qml.Selectandqml.SelectPauliRothave been updated to include two commonly used symbols for Select-applying, or -multiplexing, an operator. (#7464)The entry in the Program capture sharp bits page for transforms has been updated; non-native transforms being applied to QNodes wherein operators have dynamic wires can lead to incorrect results. (#7426)
In the Compiling circuits page, in the “Decomposition in stages” section, circuit drawings now render in a way that’s easier to read. (#7419)
The entry in the Program capture sharp bits page for using program capture with Catalyst has been updated. Instead of using
qjit(experimental_capture=True), Catalyst is now compatible with the global togglesqml.capture.enable()andqml.capture.disable()for enabling and disabling program capture. (#7298)The simulation technique table in the Dynamic quantum circuits page has been updated to correct an error regarding analytic mode support for the
tree-traversalmethod;tree-traversalsupports analytic mode. (#7490)A warning has been added to the documentation for
qml.snapshotsandqml.Snapshot, clarifying that compilation transforms may move operations across aSnapshot. (#7746)In the Documentation page, references to the outdated Sphinx and unsupported Python versions have been updated. This helps ensure contributors follow current standards and avoid compatibility issues. (#7479)
The documentation of
qml.pulse.drivehas been updated and corrected. (#7459)The API list in the documentation has been alphabetized to ensure consistent ordering. (#7792)
Bug fixes 🐛
Fixes
SelectPauliRot._flattenandTemporaryAND._primitve_bind_call. (#7843)Fixes a bug where normalization in
qml.StatePrepwithnormalize=Truewas skipped ifvalidate_normis set toFalse. (#7835)The
cancel_inverses()transform no longer changes the order of operations that don’t have shared wires, providing a deterministic output. (#7328)Fixed broken support of
qml.matrixfor aQNodewhen using mixed Torch GPU & CPU data for parametric tensors. (#7775)Fixed
CircuitGraph.iterate_parametrized_layers, and thusmetric_tensor, when the same operation occurs multiple times in the circuit. (#7757)Fixed a bug with transforms that require the classical Jacobian applied to QNodes, where only some arguments are trainable and an intermediate transform does not preserve trainability information. (#7345)
The
qml.ftqc.ParametricMidMeasureMPclass was unable to accept data fromjax.numpy.arrayinputs when specifying the angle, due to the given hashing policy. The implementation was updated to ensure correct hashing behavior forfloat,numpy.array, andjax.numpy.arrayinputs. (#7693)A bug in
qml.draw_mplfor circuits with work wires has been fixed. The previously inconsistent mapping for these wires has been resolved, ensuring accurate assignment during drawing. (#7668)A bug in
ops.op_math.Prod.simplify()has been fixed that led to global phases being discarded in special cases. Concretely, this problem occurs when Pauli factors combine into the identity up to a global phase and there is no Pauli representation of the product operator. (#7671)The behaviour of the
qml.FlipSignoperation has been fixed: passing an integermas the wires argument is now interpreted as a single wire (i.e.wires=[m]). This is different from the previous interpretation ofwires=range(m). Also, theqml.FlipSign.wiresattribute is now returning the correctWiresobject as for all other operations in PennyLane. (#7647)qml.equalnow works withqml.PauliErrors. (#7618)The
qml.transforms.cancel_inversestransform can now be used withjax.jit. (#7487)qml.StatePrepno longer validates the norm of statevectors. (#7615)The
qml.PhaseShiftoperation is now working correctly with a batch size of 1. (#7622)qml.metric_tensorcan now be calculated with Catalyst present. (#7528)The mapping to standard wires (consecutive integers) of
qml.tape.QuantumScripthas been fixed to correctly consider work wires that are not used otherwise in the circuit. (#7581)Fixed a bug where certain transforms with a native program capture implementation give incorrect results when dynamic wires were present in the circuit. The affected transforms were:
The
Operator.powmethod has been fixed to raise to the power of 2 the qutrit operators~.TShift,~.TClock, and~.TAdd. (#7505)The queuing behavior of the controlled of a controlled operation has been fixed. (#7532)
A new decomposition was implemented for two-qubit
QubitUnitaryoperators intwo_qubit_decompositionbased on a type-AI Cartan decomposition. It fixes previously faulty edge cases for unitaries that require 2 or 3 CNOT gates. Now, 3 CNOTs are used for both cases, using one more CNOT than theoretically required in the former case. (#7474)Fixed a bug in
to_openfermionwhere identity qubit-to-wires mapping was not obeyed. (#7332)Fixed a bug in the validation of
SelectPauliRotthat prevents parameter broadcasting. (#7377)Usage of NumPy in
default.mixedsource code has been converted toqml.mathto avoid unnecessary dependency on NumPy and to fix a bug that caused an error when usingdefault.mixedwith PyTorch and GPUs. (#7384)With program capture enabled (
qml.capture.enable()),QSVTno longer treats abstract values as metadata. (#7360)A fix was made to
default.qubitto allow for usingqml.Snapshotwith defer-measurements (mcm_method="deferred"). (#7335)Fixed the repr for empty
ProdandSuminstances to better communicate the existence of an empty instance. (#7346)Fixed a bug where circuit execution fails with
BlockEncodeinitialized with sparse matrices. (#7285)An informative error message has been added if
qml.condis used with an abstract condition with jitting ondefault.qubitwhen program capture is enabled. (#7314)Fixed a bug where using a
StatePrepoperation withbatch_size=1did not work withdefault.mixed. (#7280)Gradient transforms can now be used in conjunction with batch transforms with all interfaces. (#7287)
Fixed a bug where the global phase was not being added in the
QubitUnitarydecomposition.
(#7244) (#7270)Using finite differences with program capture without x64 mode enabled now raises a warning. (#7282)
When the
mcm_methodis specified to the"device", thedefer_measurementstransform will no longer be applied. Instead, the device will be responsible for all MCM handling. (#7243)Fixed coverage of
qml.liealg.CIIandqml.liealg.AIII. (#7291)Fixed a bug where the phase is used as the wire label for a
qml.GlobalPhasewhen capture is enabled. (#7211)Fixed a bug that caused
CountsMP.process_countsto return results in the computational basis, even if an observable was specified. (#7342)Fixed a bug that caused
SamplesMP.process_countsused with an observable to return a list of eigenvalues for each individual operation in the observable, instead of the overall result. (#7342)Fixed a bug where
two_qubit_decompositionprovides an incorrect decomposition for some special matrices. (#7340)Fixed a bug where the powers of
qml.ISWAPandqml.SISWAPwere decomposed incorrectly. (#7361)Returning
MeasurementValues from theftqcmodule’s parametric mid-circuit measurements (measure_arbitrary_basis,measure_xandmeasure_y) no longer raises an error in circuits usingdiagonalize_mcms. (#7387)Fixed a bug where the
single_qubit_fusion()transform produces a tape that is off from the original tape by a global phase. (#7619)Fixed a bug where an error is raised from the decomposition graph when the resource params of an operator contains lists. (#7722)
Fixed a bug with the new
Selectdecomposition based on unary iteration. There was an erroneousprintstatement. (#7842)Fixes a bug where an operation wrapped in
partial_wiresdoes not get queued. (#7830)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso-Linaje, Ali Asadi, Utkarsh Azad, Astral Cai, Yushao Chen, Diksha Dhawan, Marcus Edwards, Lillian Frederiksen, Pietropaolo Frisoni, Simone Gasperini, Soran Jahangiri, Korbinian Kottmann, Christina Lee, Joseph Lee, Austin Huang, Anton Naim Ibrahim, Erick Ochoa Lopez, William Maxwell, Luis Alfredo Nuñez Meneses, Oumarou Oumarou, Lee J. O’Riordan, Mudit Pandey, Andrija Paurevic, Justin Pickering, Shuli Shu, Jay Soni, Kalman Szenes, Marc Vandelle, David Wierichs, Jake Zaia
Release 0.41.1¶
Bug fixes 🐛
A warning is raised if PennyLane is imported and a version of JAX greater than 0.4.28 is installed. (#7369)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Pietropaolo Frisoni
Release 0.41.0¶
New features since last release
Resource-efficient Decompositions 🔎
A new, experimental graph-based decomposition system is now available in PennyLane, offering more resource-efficiency and versatility. (#6950) (#6951) (#6952) (#7028) (#7045) (#7058) (#7064) (#7149) (#7184) (#7223) (#7263)
PennyLane’s new experimental graph decomposition system offers a resource-efficient and versatile alternative to the current system. This is done by traversing an internal graph structure that is weighted by the resources (e.g., gate counts) required to decompose down to a given set of gates.
The graph-based system is experimental and is disabled by default, but it can be enabled by adding
qml.decomposition.enable_graph() to the top of your
program. Conversely, qml.decomposition.disable_graph()
disables the new system from being active.
With qml.decomposition.enable_graph(), the following
new features are available:
Operators in PennyLane can now accommodate multiple decompositions, which can be queried with the new
qml.list_decompsfunction:>>> import pennylane as qml >>> qml.decomposition.enable_graph() >>> qml.list_decomps(qml.CRX) [<pennylane.decomposition.decomposition_rule.DecompositionRule at 0x136da9de0>, <pennylane.decomposition.decomposition_rule.DecompositionRule at 0x136da9db0>, <pennylane.decomposition.decomposition_rule.DecompositionRule at 0x136da9f00>] >>> decomp_rule = qml.list_decomps(qml.CRX)[0] >>> print(decomp_rule, "\n") @register_resources(_crx_to_rx_cz_resources) def _crx_to_rx_cz(phi: TensorLike, wires: WiresLike, **__): qml.RX(phi / 2, wires=wires[1]) qml.CZ(wires=wires) qml.RX(-phi / 2, wires=wires[1]) qml.CZ(wires=wires) >>> print(qml.draw(decomp_rule)(0.5, wires=[0, 1])) 0: ───────────╭●────────────╭●─┤ 1: ──RX(0.25)─╰Z──RX(-0.25)─╰Z─┤
When an operator within a circuit needs to be decomposed (e.g., when
qml.transforms.decomposeis present), the chosen decomposition rule is that which is most resource efficient (results in the smallest gate count).New decomposition rules can be globally added to operators in PennyLane with the new
qml.add_decompsfunction. Creating a valid decomposition rule requires:Defining a quantum function that represents the decomposition.
Adding resource requirements (gate counts) to the above quantum function by decorating it with the new
qml.register_resourcesfunction, which requires a dictionary mapping operator types present in the quantum function to their number of occurrences.
qml.decomposition.enable_graph() @qml.register_resources({qml.H: 2, qml.CZ: 1}) def my_cnot(wires): qml.H(wires=wires[1]) qml.CZ(wires=wires) qml.H(wires=wires[1]) qml.add_decomps(qml.CNOT, my_cnot)
This newly added rule for
qml.CNOTcan be verified as being available to use:>>> my_new_rule = qml.list_decomps(qml.CNOT)[-1] >>> print(my_new_rule) @qml.register_resources({qml.H: 2, qml.CZ: 1}) def my_cnot(wires): qml.H(wires=wires[1]) qml.CZ(wires=wires) qml.H(wires=wires[1])
Operators with dynamic resource requirements must be declared in a resource estimate using the new
qml.resource_repfunction. For each operator class, the set of parameters that affects the type of gates and their number of occurrences in its decompositions is given by theresource_keysattribute.>>> qml.MultiRZ.resource_keys {'num_wires'}
The output of
resource_keysindicates that custom decompositions for the operator should be registered to a resource function (as opposed to a static dictionary) that accepts those exact arguments and returns a dictionary. Consider this dummy example of a fictitious decomposition rule comprising threeqml.MultiRZgates:qml.decomposition.enable_graph() def resource_fn(num_wires): return { qml.resource_rep(qml.MultiRZ, num_wires=num_wires - 1): 1, qml.resource_rep(qml.MultiRZ, num_wires=3): 2 } @qml.register_resources(resource_fn) def my_decomp(theta, wires): qml.MultiRZ(theta, wires=wires[:3]) qml.MultiRZ(theta, wires=wires[1:]) qml.MultiRZ(theta, wires=wires[:3])
More information for defining complex decomposition rules can be found in the documentation for
qml.register_resources.The
qml.transforms.decomposetransform works when the new decompositions system is enabled and offers the ability to inject new decomposition rules for operators in QNodes. (#6966)With the graph-based system enabled, the
qml.transforms.decomposetransform offers the ability to inject new decomposition rules via two new keyword arguments:fixed_decomps: decomposition rules provided to this keyword argument will be used by the new system, bypassing all other decomposition rules that may exist for the relevant operators.alt_decomps: decomposition rules provided to this keyword argument are alternative decomposition rules that the new system may choose if they’re the most resource efficient.
Each keyword argument must be assigned a dictionary that maps operator types to decomposition rules. Here is an example of both keyword arguments in use:
qml.decomposition.enable_graph() @qml.register_resources({qml.CNOT: 2, qml.RX: 1}) def my_isingxx(phi, wires, **__): qml.CNOT(wires=wires) qml.RX(phi, wires=[wires[0]]) qml.CNOT(wires=wires) @qml.register_resources({qml.H: 2, qml.CZ: 1}) def my_cnot(wires, **__): qml.H(wires=wires[1]) qml.CZ(wires=wires) qml.H(wires=wires[1]) @partial( qml.transforms.decompose, gate_set={"RX", "RZ", "CZ", "GlobalPhase"}, alt_decomps={qml.CNOT: my_cnot}, fixed_decomps={qml.IsingXX: my_isingxx}, ) @qml.qnode(qml.device("default.qubit")) def circuit(): qml.CNOT(wires=[0, 1]) qml.IsingXX(0.5, wires=[0, 1]) return qml.state()
>>> circuit() array([ 9.68912422e-01+2.66934210e-16j, -1.57009246e-16+3.14018492e-16j, 8.83177008e-17-2.94392336e-17j, 5.44955495e-18-2.47403959e-01j])
More details about what
fixed_decompsandalt_decompsdo can be found in the usage details section in theqml.transforms.decomposedocumentation.
Capturing and Representing Hybrid Programs 📥
Quantum operations, classical processing, structured control flow, and dynamicism can be efficiently
expressed with program capture (enabled with qml.capture.enable).
In the last several releases of PennyLane, we have been working on a new and experimental feature called
program capture, which allows for compactly expressing details about hybrid workflows while
also providing a smoother integration with just-in-time compilation frameworks like
Catalyst (via the qjit()
decorator) and JAX-jit.
Internally, program capture is supported by representing hybrid programs via a new intermediate representation
(IR) called plxpr, rather than a quantum tape. The plxpr IR is an adaptation of JAX’s jaxpr
IR.
There are some quirks and restrictions to be aware of, which are outlined in the Program capture sharp bits
page. But with this release, many of the core features of PennyLane—and more!—are available with program
capture enabled by adding qml.capture.enable() to the top of your program:
QNodes can now contain mid-circuit measurements (MCMs) and classical processing on MCMs with
mcm_method = "deferred"when program capture is enabled. (#6838) (#6937) (#6961)With
mcm_method = "deferred", workflows with mid-circuit measurements can be executed with program capture enabled. Additionally, program capture unlocks the ability to classically process MCM values and use MCM values as gate parameters.import jax import jax.numpy as jnp jax.config.update("jax_enable_x64", True) qml.capture.enable() @qml.qnode(qml.device("default.qubit", wires=3), mcm_method="deferred") def f(x): m0 = qml.measure(0) m1 = qml.measure(0) # classical processing on m0 and m1 a = jnp.sin(0.5 * jnp.pi * m0) phi = a - (m1 + 1) ** 4 qml.s_prod(x, qml.RX(phi, 0)) return qml.expval(qml.Z(0))
>>> f(0.1) Array(0.00540302, dtype=float64)
Note that with capture enabled, automatic qubit management is not supported on devices; the number of wires given to the device must coincide with how many MCMs are present in the circuit, since deferred measurements add one auxiliary qubit per MCM.
Quantum circuits can now be differentiated on
default.qubitandlightning.qubitwithdiff_method="finite-diff","adjoint", and"backprop"when program capture is enabled. (#6853) (#6875) (#7019)qml.capture.enable() @qml.qnode(qml.device("default.qubit", wires=3), diff_method="adjoint") def f(phi): qml.RX(phi, 0) return qml.expval(qml.Z(0))
>>> qml.grad(f)(jnp.array(0.1)) Array(-0.09983342, dtype=float64, weak_type=True)
QNode arguments can now be assigned as static. In turn, PennyLane can now determine when plxpr needs to be reconstructed based on dynamic and static arguments, providing efficiency for repeated circuit executions. (#6923)
Specifying static arguments can be done at the QNode level with the
static_argnumskeyword argument. Its values (integers) indicate which arguments are to be treated as static. By default, all QNode arguments are dynamic.Consider the following example, where the first argument is indicated to be static:
qml.capture.enable() @qml.qnode(qml.device("default.qubit", wires=1), static_argnums=0) def f(x, y): print("I constructed plxpr") qml.RX(x, 0) qml.RY(y, 0) return qml.expval(qml.Z(0))
When the value of
xchanges, PennyLane must (re)construct the plxpr representation of the program for the program to execute. In this example, the act of (re)constructing plxpr is indicated by theprintstatement executing. However, if the value ofychanges (a dynamic argument), PennyLane does not need to reconstruct the plxpr representation of the program:>>> f(0.1, 0.2) I constructed plxpr 0.97517043 >>> f(0.1, 0.3) 0.9505638 >>> f(0.2, 0.3) I constructed plxpr 0.93629336
All PennyLane transforms that return one device execution are compatible with program capture, including those without a plxpr-native implementation. (#6916) (#6922) (#6925) (#6945) (#6946) (#6957) (#6977) (#7020) (#7199) (#7247)
The following transforms now have native support for program capture (i.e., they directly transform
plxpr) and can be used as you would normally use a transform in PennyLane:Other transforms without a plxpr-native implementation are also supported by internally converting the tape implementation. As an example, here is a custom tape transform that shifts every
qml.RXgate to the end of the circuit:qml.capture.enable() @qml.transform def shift_rx_to_end(tape): """Transform that moves all RX gates to the end of the operations list.""" new_ops, rxs = [], [] for op in tape.operations: if isinstance(op, qml.RX): rxs.append(op) else: new_ops.append(op) operations = new_ops + rxs new_tape = tape.copy(operations=operations) return [new_tape], lambda res: res[0] @shift_rx_to_end @qml.qnode(qml.device("default.qubit", wires=1)) def circuit1(): qml.RX(0.1, wires=0) qml.H(wires=0) return qml.state() @qml.qnode(qml.device("default.qubit", wires=1)) def circuit2(): qml.H(wires=0) qml.RX(0.1, wires=0) return qml.state()
>>> circuit1() == circuit2() Array([ True, True], dtype=bool)
There are some exceptions to getting transforms without a plxpr-native implementation to work with capture enabled:
Transforms that return multiple device executions cannot be converted.
Transforms that return non-trivial post-processing functions cannot be converted.
Transforms will fail to execute if the transformed quantum function or QNode contains:
qml.condwith dynamic parameters as predicates.qml.for_loopwith dynamic parameters forstart,stop, orstep.qml.while_loop.
Python control flow (
if/else,for,while) is now supported when program capture is enabled. (#6837) (#6931)One of the strengths of program capture is preserving a program’s structure, eliminating the need to unroll control flow operations. In previous releases, this could only be accomplished by using
qml.for_loop,qml.cond, andqml.while_loop. With this release, standard Python control flow operations are now supported with program capture:qml.capture.enable() dev = qml.device("default.qubit", wires=[0, 1, 2]) @qml.qnode(dev) def circuit(num_loops: int): for i in range(num_loops): if i % 2 == 0: qml.H(i) else: qml.RX(1, i) return qml.state()
>>> print(qml.draw(circuit)(num_loops=3)) 0: ──H────────┤ State 1: ──RX(1.00)─┤ State 2: ──H────────┤ State >>> circuit(3) Array([0.43879125+0.j , 0.43879125+0.j , 0. -0.23971277j, 0. -0.23971277j, 0.43879125+0.j , 0.43879125+0.j , 0. -0.23971277j, 0. -0.23971277j], dtype=complex64)
This is enabled internally by diastatic-malt, which is our home-brewed implementation of Autograph.
Support for this can be disabled by setting
autograph=Falseat the QNode level (by default,autograph=True).
End-to-end Sparse Execution 🌌
Sparse data structures in compressed-sparse-row (csr) format are now supported end-to-end in PennyLane, resulting in faster execution for large sparse objects. (#6883) (#7139) (#7191)
Sparse-array input and execution are now supported on
default.qubitandlightning.qubitwith a variety of templates, preserving sparsity throughout the entire simulation.Specifically, the following templates now support sparse data structures:
Controlledoperations (#6994)
import scipy import numpy as np sparse_state = scipy.sparse.csr_array([0, 1, 0, 0]) mat = np.kron(np.identity(2**12), qml.X.compute_matrix()) sparse_mat = scipy.sparse.csr_array(mat) sparse_x = scipy.sparse.csr_array(qml.X.compute_matrix()) dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.StatePrep(sparse_state, wires=range(2)) for i in range(10): qml.H(i) qml.CNOT(wires=[i, i + 1]) qml.QubitUnitary(sparse_mat, wires=range(13)) qml.ctrl(qml.QubitUnitary(sparse_x, wires=0), control=1) return qml.state()
>>> circuit() array([ 0. +0.j, 0.03125+0.j, 0. +0.j, ..., -0.03125+0.j, 0. +0.j, 0. +0.j])
Operators that have a
sparse_matrixmethod can now choose a sparse-matrix format and the order of their wires. Availablescipysparse-matrix formats include'bsr','csr','csc','coo','dia','dok', and'lil'. (#6995)>>> op = qml.CNOT([0,1]) >>> type(op.sparse_matrix(format='dok')) scipy.sparse._dok.dok_matrix >>> type(op.sparse_matrix(format='csc')) scipy.sparse._csc.csc_matrix >>> print(op.sparse_matrix(wire_order=[1,0])) (0, 0) 1.0 (1, 3) 1.0 (2, 2) 1.0 (3, 1) 1.0 >>> print(op.sparse_matrix(wire_order=[0,1])) (0, 0) 1 (1, 1) 1 (2, 3) 1 (3, 2) 1
Sparse functionality is now available in
qml.math:
QROM State Preparation 📖
A new state-of-the-art state preparation technique based on QROM is now available with the
qml.QROMStatePreparationtemplate. (#6974)Using
qml.QROMStatePreparationis analogous to using other state preparation techniques in PennyLane.state_vector = np.array([0.5, -0.5, 0.5, 0.5]) dev = qml.device("default.qubit") wires = qml.registers({"work_wires": 1, "prec_wires": 3, "state_wires": 2}) @qml.qnode(dev) def circuit(): qml.QROMStatePreparation( state_vector, wires["state_wires"], wires["prec_wires"], wires["work_wires"] ) return qml.state()
>>> print(circuit()[:4].real) [ 0.5 -0.5 0.5 0.5]
Dynamical Lie Algebras 🕓
The new qml.liealg module provides a variety of Lie algebra functionality:
Compute the dynamical Lie algebra from a set of generators with
qml.lie_closure.
This function accepts and outputs matrices whenmatrix=True.import pennylane as qml from pennylane import X, Y, Z, I n = 2 gens = [qml.X(0), qml.X(0) @ qml.X(1), qml.Y(1)] dla = qml.lie_closure(gens)
>>> dla [X(0), X(0) @ X(1), Y(1), X(0) @ Z(1)]
Compute the structure constants that make up the adjoint representation of a Lie algebra using
qml.structure_constants.
This function accepts and outputs matrices whenmatrix=True.>>> adjoint_rep = qml.structure_constants(dla) >>> adjoint_rep.shape (4, 4, 4)
The center of a Lie algebra, which is the collection of operators that commute with all other operators in the DLA, can be found with
qml.center.>>> qml.center(dla) [X(0)]
Cartan decompositions,
g = k + m, can be performed withqml.liealg.cartan_decomp.
These use involution functions that return a boolean value. A variety of typically encountered involution functions are included in the module, such aseven_odd_involution, concurrence_involution, A, AI, AII, AIII, BD, BDI, DIII, C, CI, CII.from pennylane.liealg import concurrence_involution k, m = qml.liealg.cartan_decomp(dla, concurrence_involution)
>>> k, m ([Y(1)], [X(0), X(0) @ X(1), X(0) @ Z(1)])
The vertical subspace
kandmfulfill the commutation relations[k, m] ⊆ m,[k, k] ⊆ kand[m, m] ⊆ kthat make them a proper Cartan decomposition. These can be verified using the functionqml.liealg.check_cartan_decomp.>>> qml.liealg.check_cartan_decomp(k, m) True
The horizontal Cartan subalgebra
aofmcan be computed withqml.liealg.horizontal_cartan_subalgebra.from pennylane.liealg import horizontal_cartan_subalgebra newg, k, mtilde, a, new_adj = horizontal_cartan_subalgebra(k, m, return_adjvec=True)
>>> newg.shape, k.shape, mtilde.shape, a.shape, new_adj.shape ((4, 4), (1, 4), (1, 4), (2, 4), (4, 4, 4))
newgis ordered such that the elements arenewg = k + mtilde + a, wheremtildeis the remainder ofmwithouta. A Cartan subalgebra is an Abelian subalgebra ofm, and we can confirm that all elements inaare mutually commuting viaqml.liealg.check_abelian.>>> qml.liealg.check_abelian(a) True
The following functions have also been added:
qml.liealg.check_commutation_relation(A, B, C)checks if all commutators betweenAandBmap to a subspace ofC, i.e.[A, B] ⊆ C.qml.liealg.adjvec_to_opandqml.liealg.op_to_adjvecallow transforming operators within a Lie algebra to and from their adjoint vector representations.qml.liealg.change_basis_ad_repallows the transformation of an adjoint representation tensor according to a basis transformation on the underlying Lie algebra, without re-computing the representation.qml.pauli.trace_inner_productcan handle batches of dense matrices.
(#6811) (#6861) (#6935) (#7026) (#7054) (#7129)
Qualtran Integration 🔗
It’s now possible to use Qualtran bloqs in PennyLane with the new
qml.FromBloqclass. (#7148)qml.FromBloqtranslates Qualtran bloqs into equivalent PennyLane operators. It requires two inputs:bloq: an initialized Qualtran Bloqwires: the wires the operator acts on
The following example applies a PennyLane Operator and Qualtran Bloq in the same circuit:
>>> from qualtran.bloqs.basic_gates import CNOT >>> dev = qml.device("default.qubit") >>> @qml.qnode(dev) ... def circuit(): ... qml.X(wires=0) ... qml.FromBloq(CNOT(), wires=[0, 1]) ... return qml.state() >>> circuit() array([0.+0.j, 0.+0.j, 0.+0.j, 1.+0.j])
A new function called
qml.bloq_registersis available to help determine the required wires for complex QualtranBloqswith multiple registers. (#7148)Given a Qualtran Bloq, this function returns a dictionary of register names and wires.
>>> from qualtran.bloqs.phase_estimation import RectangularWindowState, TextbookQPE >>> from qualtran.bloqs.basic_gates import ZPowGate >>> textbook_qpe = TextbookQPE(ZPowGate(exponent=2 * 0.234), RectangularWindowState(3)) >>> registers = qml.bloq_registers(textbook_qpe) >>> registers {'q': Wires([0]), 'qpe_reg': Wires([1, 2, 3])}
In the following example, we use these registers to measure the correct qubits in quantum phase estimation:
dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.FromBloq(textbook_qpe, wires=range(textbook_qpe.signature.n_qubits())) return qml.probs(wires=registers['qpe_reg'])
>>> print(qml.draw(circuit)()) 0: ─╭FromBloq─┤ 1: ─├FromBloq─┤ ╭Probs 2: ─├FromBloq─┤ ├Probs 3: ─╰FromBloq─┤ ╰Probs
Hadamard Gradient Variants and Improvements 🌈
Variants of the Hadamard gradient outlined in arXiv:2408.05406 have been added as new differentiation methods:
diff_method="reversed-hadamard","direct-hamadard", and"reversed-direct-hadamard“. (#7046) (#7198)The three variants of the Hadamard gradient added in this release offer tradeoffs that could be advantageous in certain cases:
"reversed-hadamard": the observable being measured and the generators of the unitary operations in the circuit are reversed; the generators are now the observables, and the Pauli decomposition of the observables are now gates in the circuit."direct-hadamard": the additional auxiliary qubit needed in the standard Hadamard gradient is exchanged for additional circuit executions."reversed-direct-hadamard": a combination of the “direct” and “reversed” modes, where the role of the observable and the generators of the unitary operations in the circuit swap, and the additional auxiliary qubit is exchanged for additional circuit executions.
Using them in your code is just like any other differentiation method in PennyLane:
import pennylane as qml dev = qml.device("default.qubit") @qml.qnode(dev, diff_method="reversed-hadamard") def circuit(x): qml.RX(x, 0) return qml.expval(qml.Z(0))
>>> qml.grad(circuit)(qml.numpy.array(0.5)) np.float64(-0.47942553860420284)
More information on how these three new gradient methods work can be found in arXiv:2408.05406.
The Hadamard gradient method and its variants can now differentiate any operator with a generator defined, and can accept circuits with non-commuting measurements. (#6928)
Improvements 🛠
QNode execution configuration
QNodes now have an
updatemethod that allows for re-configuring settings likediff_method,mcm_method, and more. This allows for easier on-the-fly adjustments to workflows. (#6803)After constructing a QNode,
import pennylane as qml @qml.qnode(device=qml.device("default.qubit")) def circuit(): qml.H(0) qml.CNOT([0,1]) return qml.probs()
its settings can be modified with
update, which returns a newQNodeobject (note: any arguments not specified inupdatewill retain their original value). Here is an example of updating a QNode’sdiff_method:>>> print(circuit.diff_method) best >>> new_circuit = circuit.update(diff_method="parameter-shift") >>> print(new_circuit.diff_method) 'parameter-shift'
A new helper function called
qml.workflow.construct_execution_config(qnode)(*args,**kwargs)is now available, which allows users to construct an execution configuration from a given QNode instance. (#6901)@qml.qnode(qml.device("default.qubit", wires=1)) def circuit(x): qml.RX(x, 0) return qml.expval(qml.Z(0))
>>> config = qml.workflow.construct_execution_config(circuit)(1) >>> print(config) ExecutionConfig(grad_on_execution=False, use_device_gradient=True, use_device_jacobian_product=False, gradient_method='backprop', gradient_keyword_arguments={}, device_options={'max_workers': None, 'prng_key': None, 'rng': Generator(PCG64) at 0x15F6BB680}, interface=<Interface.NUMPY: 'numpy'>, derivative_order=1, mcm_config=MCMConfig(mcm_method=None, postselect_mode=None), convert_to_numpy=True)
QNodes now store their
ExecutionConfiginstead ofqnode_kwargs. (#6991)
Decompositions
The
qml.QROMtemplate has been upgraded to decompose more efficiently whenwork_wiresare not used. #6967)The decomposition of a single-qubit
qml.QubitUnitarynow includes the global phase. (#7143)The decompositions of
qml.SX,qml.Xandqml.Yuseqml.GlobalPhaseinstead ofqml.PhaseShift. (#7073)A new decomposition for multi-controlled global phases that uses one less controlled phase shift has been added. (#6936)
qml.ops.sk_decompositionhas been improved to produce less gates for certain edge cases. This greatly impacts the performance ofqml.clifford_t_decomposition, which should now give less extraneousqml.Tgates. (#6855)qml.MPSPrepnow has a gate decomposition. This enables its use with any device. Additionally, theright_canonicalize_mpsfunction has also been added to transform an MPS into its right-canonical form. (#6896)The
qml.clifford_t_decompositionhas been improved to use less gates when decomposingqml.PhaseShift. (#6842)An empty basis set in
qml.compileis now recognized as valid, resulting in decomposition of all operators that can be decomposed. (#6821)The
assert_validmethod now validates that an operator’s decomposition does not contain the operator itself, instead of checking that it does not contain any operators of the same class as the operator. (#7099)
Improved drawing
qml.draw_mplcan now split deep circuits over multiple figures via amax_lengthkeyword argument. (#7128)qml.drawnow re-displays wire labels at the start of each partitioned chunk when using themax_lengthkeyword argument. (#7250)qml.drawandqml.draw_mplcan now reuse lines for different classical wires, saving whitespace without changing the represented circuit. (#7163)qml.PrepSelPrepnow has a concise representation when drawn withqml.draworqml.draw_mpl. (#7164)
Device improvements
Devices can now configure whether or not ML framework data is sent to them via an
ExecutionConfig.convert_to_numpyparameter. End-to-end jitting ondefault.qubitis used if the user specified ajax.random.PRNGKeyas a seed. (#6899) (#6788) (#6869)The
reference.qubitdevice now enforcessum(probs)==1insample_state. (#7076)The
default.mixeddevice now adheres to the newer device API introduced in v0.33. This means thatdefault.mixednow supports not having to specify the number of wires, more predictable behaviour with interfaces, support forqml.Snapshot, and more. (#6684)null.qubitcan now execute jaxpr. (#6924)
Experimental FTQC module
A template class,
qml.ftqc.GraphStatePrep, has been added for the Graph state construction. (#6985) (#7092)A new utility module
qml.ftqc.utilsis provided, with support for functionality such as dynamic qubit recycling. (#7075)A new class,
qml.ftqc.QubitGraph, is now available for representing a qubit memory-addressing model for mappings between logical and physical qubits. This representation allows for nesting of lower-level qubits with arbitrary depth to allow easy insertion of arbitrarily many levels of abstractions between logical qubits and physical qubits. (#6962)A
Latticeclass and agenerate_latticemethod has been added to theqml.ftqcmodule. Thegenerate_latticemethod is to generate 1D, 2D, 3D grid graphs with the given geometric parameters. (#6958)Measurement functions
measure_x,measure_yandmeasure_arbitrary_basisare added in the experimentalftqcmodule. These functions apply a mid-circuit measurement and return aMeasurementValue. They are analogous toqml.measurefor the computational basis, but instead measure in the X-basis, Y-basis, or an arbitrary basis, respectively. Functionqml.ftqc.measure_zis also added as an alias forqml.measure. (#6953)The function
cond_measurehas been added to the experimentalftqcmodule to apply a mid-circuit measurement with a measurement basis conditional on the function input. (#7037)A
ParametrizedMidMeasureclass has been added to represent a mid-circuit measurement in an arbitrary measurement basis in the XY, YZ or ZX plane. SubclassesXMidMeasureMPandYMidMeasureMPrepresent X-basis and Y-basis measurements. These classes are part of the experimentalftqcmodule. (#6938) (#6953)A
diagonalize_mcmstransform has been added that diagonalizes anyParametrizedMidMeasure, for devices that only natively support mid-circuit measurements in the computational basis. (#6938) (#7037)
Program capture and dynamic shapes
Workflows that create dynamically shaped arrays via
jnp.ones,jnp.zeros,jnp.arange, andjnp.fullcan now be captured. #6865)Workflows wherein the sizes of dynamically shaped arrays are updated in a
qml.while_looporqml.for_loopare now capturable. (#7084) (#7098)Workflows containing
qml.condinstances that return arrays with dynamic shapes can now be captured. (#6888) (#7080)A
qml.capture.pause()context manager has been added for pausing program capture in an error-safe way. (#6911)The requested
diff_methodis now validated when program capture is enabled. (#6852)A
qml.capture.register_custom_staging_rulehas been added for handling higher-order primitives that return new dynamically shaped arrays. (#7086)Support has been improved for when wires are specified as
jax.numpy.ndarrayif program capture is enabled. (#7108)qml.cond,qml.adjoint,qml.ctrl, and QNodes can now handle accepting dynamically shaped arrays with the abstract shape matching another argument. (#7059)A new
qml.capture.eval_jaxprfunction has been implemented. This is a variant ofjax.core.eval_jaxprthat can handle the creation of arrays with dynamic shapes. (#7052)A new, experimental
Operatormethod calledcompute_qfunc_decompositionhas been added to represent decompositions with structure (e.g., control flow). This method is only used when capture is enabled withqml.capture.enable(). (#6859) (#6881) (#7022) (#6917) (#7081)The higher order primitives in program capture can now accept inputs with abstract shapes. (#6786)
Execution interpreters and
qml.capture.eval_jaxprcan now handle jaxpjitprimitives when dynamic shapes are being used. (#7078) (#7117)Device preprocessing is now being performed in the execution pipeline for program capture. (#7057) (#7089) (#7131) (#7135)
Other improvements
The
poly_to_anglesfunction has been improved to correctly work with different interfaces and no longer manipulate the input angles tensor internally. (#6979)Dynamic one-shot workloads are now faster for
null.qubitby removing a redundantfunctools.lru_cachecall that was capturing allSampleMPobjects in a workload. (#7077)The coefficients of observables now have improved differentiability. (#6598)
An informative error is now raised when a QNode with
diff_method=Noneis differentiated. (#6770)qml.gradients.finite_diff_jvphas been added to compute the jvp of an arbitrary numeric function. (#6853)The qchem functions that accept a string input have been updated to consistently work with both lower-case and upper-case inputs. (#7186)
PSWAP.matrix()andPSWAP.eigvals()now support parameter broadcasting. (#7179) (#7228)Device.eval_jaxprnow accepts anexecution_configkeyword argument. (#6991)merge_rotationsnow correctly simplifies mergedqml.Rotoperators whose angles yield the identity operator. (#7011)The
qml.measurements.NullMeasurementmeasurement process has been added to allow for profiling problems without the overheads associated with performing measurements. (#6989)The
pauli_repproperty is now accessible forAdjointoperators when there is a Pauli representation. (#6871)qml.pauli.PauliVSpaceis now iterable. (#7054)qml.qchem.tapernow handles wire ordering for the tapered observables more robustly. (#6954)A
RuntimeWarningis now raised byqml.QNodeandqml.executeif executing JAX workflows and the installed version of JAX is greater than0.4.28. (#6864)The
rng_saltversion has been bumped tov0.40.0. (#6854)
Labs: a place for unified and rapid prototyping of research software 🧪
pennylane.labs.dla.lie_closure_densehas been removed and integrated intoqml.lie_closureusing the newdensekeyword. (#6811)pennylane.labs.dla.structure_constants_densehas been removed and integrated intoqml.structure_constantsusing the newmatrixkeyword. (#6861)ResourceOperator.resource_paramshas been changed to a property. (#6973)ResourceOperatorimplementations for theModExp,PhaseAdder,Multiplier,ControlledSequence,AmplitudeAmplification,QROM,SuperPosition,MottonenStatePreparation,StatePrep,BasisStatetemplates have been added. (#6638)pennylane.labs.khaneja_glaser_involutionhas been removed,pennylane.labs.check_commutationhas moved toqml.liealg.check_commutation_relation.pennylane.labs.check_cartan_decomphas moved toqml.liealg.check_cartan_decomp. All involution functions have been moved toqml.liealg.pennylane.labs.adjvec_to_ophas moved toqml.liealg.adjvec_to_op.pennylane.labs.op_to_adjvechas moved toqml.liealg.op_to_adjvec.pennylane.labs.change_basis_ad_rephas moved toqml.liealg.change_basis_ad_rep.pennylane.labs.cartan_subalgebrahas moved toqml.liealg.horizontal_cartan_subalgebra. (#7026) (#7054)New classes called
HOStateandVibronicHOhave been added for representing harmonic oscillator states. (#7035)Base classes for Trotter error estimation on Realspace Hamiltonians have been added:
RealspaceOperator,RealspaceSum,RealspaceCoeffs, andRealspaceMatrix(#7034)Functions for Trotter error estimation and Hamiltonian fragment generation have been added:
trotter_error,perturbation_error,vibrational_fragments,vibronic_fragments, andgeneric_fragments. (#7036)As an example we compute the perturbation error of a vibrational Hamiltonian. First we generate random harmonic frequencies and Taylor coefficients to initialize the vibrational Hamiltonian.
>>> from pennylane.labs.trotter_error import HOState, vibrational_fragments, perturbation_error >>> import numpy as np >>> n_modes = 2 >>> r_state = np.random.RandomState(42) >>> freqs = r_state.random(n_modes) >>> taylor_coeffs = [ >>> np.array(0), >>> r_state.random(size=(n_modes, )), >>> r_state.random(size=(n_modes, n_modes)), >>> r_state.random(size=(n_modes, n_modes, n_modes)) >>> ]
We call
vibrational_fragmentsto get the harmonic and anharmonic fragments of the vibrational Hamiltonian.>>> frags = vibrational_fragments(n_modes, freqs, taylor_coeffs)
We build state vectors in the harmonic oscillator basis with the
HOStateclass.>>> gridpoints = 5 >>> state1 = HOState(n_modes, gridpoints, {(0, 0): 1}) >>> state2 = HOState(n_modes, gridpoints, {(1, 1): 1})
Finally, we compute the error by calling
perturbation_error.>>> perturbation_error(frags, [state1, state2]) [(-0.9189251160920879+0j), (-4.797716682426851+0j)]
Function
qml.labs.trotter_error.vibronic_fragmentsnow returnsRealspaceMatrixobjects with the correct number of electronic states. (#7251)
Breaking changes 💔
Executing
qml.specsis now much more efficient with the removal of accessingnum_diagonalizing_gates. The calculation of this quantity is extremely expensive, and the definition is ambiguous for non-commuting observables. (#7047)qml.gradients.gradient_transform.choose_trainable_paramshas been renamed tochoose_trainable_param_indicesto better reflect what it actually does. (#6928)qml.MultiControlledXno longer accepts strings as control values. (#6835)The
control_wiresargument inqml.MultiControlledXhas been removed. (#6832) (#6862)qml.executenow has a collection of keyword-only arguments. (#6598)The
decomp_depthargument inqml.transforms.set_decompositionhas been removed. (#6824)The
max_expansionargument inqml.devices.preprocess.decomposehas been removed. (#6824)The
tapeandqtapeproperties ofQNodehave been removed. Instead, use theqml.workflow.construct_tapefunction. (#6825)The
gradient_fnkeyword argument inqml.executehas been removed. Instead, it has been replaced withdiff_method. (#6830)The
QNode.get_best_methodandQNode.best_method_strmethods have been removed. Instead, use theqml.workflow.get_best_diff_methodfunction. (#6823)The
output_dimproperty ofqml.tape.QuantumScripthas been removed. Instead, use methodshapeofQuantumScriptorMeasurementProcessto get the same information. (#6829)The
qsvt_legacymethod, along with its private helper_qsp_to_qsvt, has been removed. (#6827)
Deprecations 👋
The
qml.qnn.KerasLayerclass has been deprecated because Keras 2 is no longer actively maintained. Please consider using a different machine learning framework instead ofTensorFlow/Keras 2, like Pytorch or JAX. (#7097)Specifying
pipeline=Nonewithqml.compileis now deprecated. A sequence of transforms should now always be specified. (#7004)qml.ControlledQubitUnitarywill stop acceptingqml.QubitUnitaryobjects as arguments as itsbase. Instead, useqml.ctrlto construct a controlledqml.QubitUnitary. A follow-up PR fixed accidental double-queuing when usingqml.ctrlwithQubitUnitary. (#6840) (#6926)The
control_wiresargument inqml.ControlledQubitUnitaryhas been deprecated. Instead, use thewiresargument as the second positional argument. (#6839)The
mcm_methodkeyword inqml.executehas been deprecated. Instead, use themcm_methodandpostselect_modearguments. (#6807)Specifying gradient keyword arguments as any additional keyword argument to the qnode is deprecated and will be removed in v0.42. The gradient keyword arguments should be passed to the new keyword argument
gradient_kwargsvia an explicit dictionary. This change will improve QNode argument validation. (#6828)The
qml.gradients.hamiltonian_gradfunction has been deprecated. This gradient recipe is not required with the new operator arithmetic system. (#6849)The
inner_transform_programandconfigkeyword arguments inqml.executehave been deprecated. If more detailed control over the execution is required, useqml.workflow.runwith these arguments instead. (#6822) (#6879)The property
MeasurementProcess.return_typehas been deprecated. If observable type checking is needed, please use directisinstance; if other text information is needed, please use class name, or another internal temporary private member_shortname. (#6841) (#6906) (#6910)Pauli module level imports of
lie_closure,structure_constants, andcenterare deprecated, as functionality has moved to the newliealgmodule. (#6935)
Internal changes ⚙️
An informative error message has been added if Autograph is employed on a function that has a
lambdaloop condition inqml.while_loop. (#7178)Logic in
qml.drawer.tape_texthas been cleaned. (#7133)An intermediate caching to
null.qubitzero-value generation has been added to improve memory consumption for larger workloads. (#7155)All use of
ABCfor intermediate variables has been renamed to preserve the label for the Python abstract base classabc.ABC. (#7156)The error message when device wires are not specified when program capture is enabled is more clear. (#7130)
Logic in
_capture_qnode.pyhas been cleaned. (#7115)The test for
qml.math.quantum._denman_beavers_iterationshas been improved such that tested random matrices are guaranteed positive. (#7071)The
matrix_powerdispatch for thescipyinterface has been replaced with an in-place implementation. (#7055)Support has been added to
CollectOpsandMeasfor handling QNode primitives. (#6922)Change some
scipyimports from submodules to whole module to reduce memory footprint of importing pennylane. (#7040)NotImplementedErrors have been added forgradandjacobianinCollectOpsandMeas. (#7041)Quantum transform interpreters now perform argument validation and will no longer check if the equation in the
jaxpris a transform primitive. (#7023)qml.for_loopandqml.while_loophave been moved from thecompilermodule to a newcontrol_flowmodule. (#7017)qml.capture.run_autographis now idempotent. This meansrun_autograph(fn) = run_autograph(run_autograph(fn)). (#7001)Minor changes to
DQInterpreterhave been made for speedups with program capture execution. (#6984)no-memberpylint issues from JAX are now globally silenced (#6987)pylint=3.3.4errors in our source code have been fixed. (#6980) (#6988)QNode.get_gradient_fnhas been removed from the source code. (#6898)The source code has been updated use
black==25.1.0. (#6897)The
InterfaceEnumobject has been improved to prevent direct comparisons tostrobjects. (#6877)A
QmlPrimitiveclass has been added that inheritsjax.core.Primitiveto a newqml.capture.custom_primitivesmodule. This class contains aprim_typeproperty so that we can differentiate between different sets of PennyLane primitives. Consequently,QmlPrimitiveis now used to define all PennyLane primitives. (#6847)The
RiemannianGradientOptimizerhas been updated to take advantage of newer features. (#6882)The
keep_intermediate=Trueflag is now used to keep Catalyst’s IR when testing. (#6990)
Documentation 📝
A page on sharp bits and debugging tips has been added for PennyLane program capture: Program capture sharp bits. This page is recommended to consult any time errors occur when
qml.capture.enable()is present. (#7062)The Compiling Circuits page has been updated to include information on using the new experimental decompositions system. (#7066)
The docstring for
qml.transforms.decomposenow recommends theqml.clifford_t_decompositiontransform when decomposing to the Clifford + T gate set. (#7177)Typos were fixed in the docstring for
qml.QubitUnitary. (#7187)The docstring for
qml.prodhas been updated to explain that the order of the output may seem reversed, but it is correct. (#7083)The docstring for
qml.labs.trotter_errorhas been updated. (#7190)The
gates,qubitsandlambattributes ofDoubleFactorizationandFirstQuantizationhave dedicated documentation. (#7173)The code example in the docstring for
qml.PauliSentencenow properly copy-pastes. (#6949)The docstrings for
qml.unary_mapping,qml.binary_mapping,qml.christiansen_mapping,qml.qchem.localize_normal_modes, andqml.qchem.VibrationalPEShave been updated to include better code examples. (#6717)The docstrings for
qml.qchem.localize_normal_modesandqml.qchem.VibrationalPEShave been updated to include examples that can be copied. (#6834)A typo has been fixed in the code example for
qml.labs.dla.lie_closure_dense. (#6858)The code example in the docstring for
qml.BasisRotationwas corrected by includingwire_orderin the call toqml.matrix. (#6891)The docstring of
qml.noise.meas_eqhas been updated to make its functionality clearer. (#6920)The docstring for
qml.devices.default_tensor.DefaultTensorhas been updated to clarify differentiation support. (#7150)The docstring for
QuantumScriptshas been updated to remove outdated references toset_parameters. (#7174)The documentation for
qml.devicehas been updated to includenull.qubitin the list of readily available devices. (#7233)
Bug fixes 🐛
Using transforms with program capture enabled now works correctly with functions that accept pytree arguments. (#7233)
qml.math.requires_gradno longer returnsTruefor JAX inputs other thanjax.interpreters.ad.JVPTracerinstances. (#7233)PennyLane is now compatible with
pyzx 0.9. (#7188)Fixed a bug when
qml.matrixis applied on a sparse operator, which caused the output to have unnecessary epsilon inaccuracy. (#7147) (#7182)Reverted (#6933) to remove non-negligible performance impact due to wire flattening. (#7136)
Fixed a bug that caused the output of
qml.fourier.qnode_spectrum()to differ depending if equivalent gate generators are defined using different PennyLane operators. This was resolved by updatingqml.operation.gen_is_multi_term_hamiltonianto work with more complicated generators. (#7121)Modulo operator calls on MCMs now correctly offload to the autoray-backed
qml.math.moddispatch. (#7085)qml.transforms.single_qubit_fusionandqml.transforms.cancel_inversesnow correctly handle mid-circuit measurements when program capture is enabled. (#7020)qml.math.get_interfacenow correctly extracts the"scipy"interface if provided a list/array of sparse matrices. (#7015)qml.ops.Controlled.has_sparse_matrixnow provides the correct information by checking if the target operator has a sparse or dense matrix defined. (#7025)qml.capture.PlxprInterpreternow flattens pytree arguments before evaluation. (#6975)qml.GlobalPhase.sparse_matrixnow correctly returns a sparse matrix of the same shape asmatrix. (#6940)qml.expvalno longer silently casts to a real number when observable coefficients are imaginary. (#6939)Fixed
qml.wires.Wiresinitialization to disallowWiresobjects as wires labels. Now,Wiresis idempotent, e.g.Wires([Wires([0]), Wires([1])])==Wires([0, 1]). (#6933)qml.capture.PlxprInterpreternow correctly handles propagation of constants when interpreting higher-order primitives. (#6913)qml.capture.PlxprInterpreternow usesPrimitive.get_bind_paramsto resolve primitive calling signatures before binding primitives. (#6913)The interface is now detected from the data in the circuit, not the arguments to the QNode. This allows interface data to be strictly passed as closure variables and still be detected. (#6892)
qml.BasisStatenow casts its input to integers. (#6844)The
workflow.contstruct_batchandworkflow.construct_tapefunctions now correctly reflect themcm_methodpassed to theQNode, instead of assuming the method is alwaysdeferred. (#6903)Applying mid-circuit measurements inside
qml.condis not supported, and previously resulted in unclear error messages or incorrect results. It is now explicitly not allowed, and raises an error when calling the function returned byqml.cond. (#7027)
(#7051)qml.qchem.givens_decompositionno longer raises aRuntimeWarningwhen the input is a zero matrix. #7053)Comparing an adjoint of an
Observablewith anotherOperationusingqml.equalno longer incorrectly skips the check ensuring that the operator types match. (#7107)Downloading specific attributes of datasets in the
'other'category viaqml.data.loadno longer fails. (#7144)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso, Daniela Angulo, Ali Asadi, Utkarsh Azad, Astral Cai, Joey Carter, Henry Chang, Yushao Chen, Isaac De Vlugt, Diksha Dhawan, Lillian M.A. Frederiksen, Pietropaolo Frisoni, Marcus Gisslén, Diego Guala, Austin Huang, Soran Jahangiri, Korbinian Kottmann, Christina Lee, Joseph Lee, Dantong Li, William Maxwell, Anton Naim Ibrahim, Lee J. O’Riordan, Mudit Pandey, Vyom Patel, Andrija Paurevic, Justin Pickering, Alex Preciado, Shuli Shu, David Wierichs
Release 0.40.0¶
New features since last release
Efficient state preparation methods 🦾
State preparation tailored for matrix product states (MPS) is now supported with
qml.MPSPrepon thelightning.tensordevice. (#6431)Given a list of \(n\) tensors that represents an MPS, \([A^{(0)}, ..., A^{(n-1)}]\),
qml.MPSPreplets you directly inject the MPS into a QNode as the initial state of the circuit without any need for pre-processing. The first and last tensors in the list must be rank-2, while all intermediate tensors should be rank-3.import pennylane as qml import numpy as np mps = [ np.array([[0.0, 0.107], [0.994, 0.0]]), np.array( [ [[0.0, 0.0, 0.0, -0.0], [1.0, 0.0, 0.0, -0.0]], [[0.0, 1.0, 0.0, -0.0], [0.0, 0.0, 0.0, -0.0]], ] ), np.array( [ [[-1.0, 0.0], [0.0, 0.0]], [[0.0, 0.0], [0.0, 1.0]], [[0.0, -1.0], [0.0, 0.0]], [[0.0, 0.0], [1.0, 0.0]], ] ), np.array([[-1.0, -0.0], [-0.0, -1.0]]), ] dev = qml.device("lightning.tensor", wires = [0, 1, 2, 3]) @qml.qnode(dev) def circuit(): qml.MPSPrep(mps, wires = [0,1,2]) return qml.state()
>>> print(circuit()) [ 0. +0.j 0. +0.j 0. +0.j -0.1066+0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0.9943+0.j 0. +0.j 0. +0.j 0. +0.j]
At this time,
qml.MPSPrepis only supported on thelightning.tensordevice.Custom-made state preparation for linear combinations of quantum states is now available with
qml.Superposition. (#6670)Given a list of \(m\) coefficients \(c_i\) and basic states \(|b_i\rangle\),
qml.Superpositionprepares \(|\phi\rangle = \sum_i^m c_i |b_i\rangle\). Here is a simple example showing how to useqml.Superpositionto prepare \(\tfrac{1}{\sqrt{2}} |00\rangle + \tfrac{1}{\sqrt{2}} |10\rangle\).coeffs = np.array([0.70710678, 0.70710678]) basis = np.array([[0, 0], [1, 0]]) @qml.qnode(qml.device('default.qubit')) def circuit(): qml.Superposition(coeffs, basis, wires=[0, 1], work_wire=[2]) return qml.state()
>>> circuit() Array([0.7071068 +0.j, 0. +0.j, 0. +0.j, 0. +0.j, 0.70710677+0.j, 0. +0.j, 0. +0.j, 0. +0.j], dtype=complex64)
Note that specification of one
work_wireis required.
Enhanced QSVT functionality 🤩
New functionality to calculate and convert phase angles for QSP and QSVT has been added with
qml.poly_to_anglesandqml.transform_angles. (#6483)The
qml.poly_to_anglesfunction calculates phase angles directly given polynomial coefficients and the routine in which the angles will be used ("QSVT","QSP", or"GQSP"):>>> poly = [0, 1.0, 0, -1/2, 0, 1/3] >>> qsvt_angles = qml.poly_to_angles(poly, "QSVT") >>> print(qsvt_angles) [-5.49778714 1.57079633 1.57079633 0.5833829 1.61095884 0.74753829]
The
qml.transform_anglesfunction can be used to convert angles from one routine to another:>>> qsp_angles = np.array([0.2, 0.3, 0.5]) >>> qsvt_angles = qml.transform_angles(qsp_angles, "QSP", "QSVT") >>> print(qsvt_angles) [-6.86858347 1.87079633 -0.28539816]
The
qml.qsvtfunction has been improved to be more user-friendly, with enhanced capabilities. (#6520) (#6693)Block encoding and phase angle computation are now handled automatically, given a matrix to encode, polynomial coefficients, and a block encoding method (
"prepselprep","qubitization","embedding", or"fable", all implemented with their corresponding operators in PennyLane).# P(x) = -x + 0.5 x^3 + 0.5 x^5 poly = np.array([0, -1, 0, 0.5, 0, 0.5]) hamiltonian = qml.dot([0.3, 0.7], [qml.Z(1), qml.X(1) @ qml.Z(2)]) dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.qsvt(hamiltonian, poly, encoding_wires=[0], block_encoding="prepselprep") return qml.state() matrix = qml.matrix(circuit, wire_order=[0, 1, 2])()
>>> print(matrix[:4, :4].real) [[-0.1625 0. -0.3793 0. ] [ 0. -0.1625 0. 0.3793] [-0.3793 0. 0.1625 0. ] [ 0. 0.3793 0. 0.1625]]
The old functionality can still be accessed with
qml.qsvt_legacy.A new
qml.GQSPtemplate has been added to perform Generalized Quantum Signal Processing (GQSP). (#6565) Similar to QSVT, GQSP is an algorithm that polynomially transforms an input unitary operator, but with fewer restrictions on the chosen polynomial.You can also use
qml.poly_to_anglesto obtain angles for GQSP!# P(x) = 0.1 + 0.2j x + 0.3 x^2 poly = [0.1, 0.2j, 0.3] angles = qml.poly_to_angles(poly, "GQSP") @qml.prod # transforms the qfunc into an Operator def unitary(wires): qml.RX(0.3, wires) dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(angles): qml.GQSP(unitary(wires = 1), angles, control = 0) return qml.state() matrix = qml.matrix(circuit, wire_order=[0, 1])(angles)
>>> print(np.round(matrix,3)[:2, :2]) [[0.387+0.198j 0.03 -0.089j] [0.03 -0.089j 0.387+0.198j]]
Generalized Trotter products 🐖
Trotter products that work on exponentiated operators directly instead of full system hamiltonians can now be encoded into circuits with the addition of
qml.TrotterizedQfuncandqml.trotterize. This allows for custom specification of the first-order expansion of the Suzuki-Trotter product formula and extrapolating it to the \(n^{\text{th}}\) order. (#6627)If the first-order of the Suzuki-Trotter product formula for a given problem is known,
qml.TrotterizedQfuncandqml.trotterizelet you implement the \(n^{\text{th}}\)-order product formula while only specifying the first-order term as a quantum function.def my_custom_first_order_expansion(time, theta, phi, wires, flip): qml.RX(time * theta, wires[0]) qml.RY(time * phi, wires[1]) if flip: qml.CNOT(wires=wires[:2])
qml.trotterizerequires the quantum function representing the first-order product formula, the number of Trotter steps, and the desired order. It returns a function with the same call signature as the first-order product formula quantum function:@qml.qnode(qml.device("default.qubit")) def my_circuit(time, theta, phi, num_trotter_steps): qml.trotterize( first_order_expansion, n=num_trotter_steps, order=2, )(time, theta, phi, wires=['a', 'b'], flip=True) return qml.state()
Alternatively,
qml.TrotterizedQfunccan be used as follows:@qml.qnode(qml.device("default.qubit")) def my_circuit(time, theta, phi, num_trotter_steps): qml.TrotterizedQfunc( time, theta, phi, qfunc=my_custom_first_order_expansion, n=num_trotter_steps, order=2, wires=['a', 'b'], flip=True, ) return qml.state()
>>> time = 0.1 >>> theta, phi = (0.12, -3.45) >>> print(qml.draw(my_circuit, level="device")(time, theta, phi, num_trotter_steps=1)) a: ──RX(0.01)──╭●─╭●──RX(0.01)──┤ State b: ──RY(-0.17)─╰X─╰X──RY(-0.17)─┤ State
Both methods produce the same results, but offer different interfaces based on the application or overall preference.
Bosonic operators 🎈
A new module, qml.bose, has been added to PennyLane that includes support
for constructing and manipulating Bosonic operators and converting between Bosonic operators and
qubit operators.
Bosonic operators analogous to
qml.FermiWordandqml.FermiSentenceare now available withqml.BoseWordandqml.BoseSentence. (#6518)qml.BoseWordandqml.BoseSentenceoperate similarly to their fermionic counterparts. To create a Bose word, a dictionary is required as input, where the keys are tuples of boson indices and values are'+/-'(denoting the bosonic creation/annihilation operators). For example, the \(b^{\dagger}_0 b_1\) can be constructed as follows.>>> w = qml.BoseWord({(0, 0) : '+', (1, 1) : '-'}) >>> print(w) b⁺(0) b(1)
Multiple Bose words can then be combined to form a Bose sentence:
>>> w1 = qml.BoseWord({(0, 0) : '+', (1, 1) : '-'}) >>> w2 = qml.BoseWord({(0, 1) : '+', (1, 2) : '-'}) >>> s = qml.BoseSentence({w1 : 1.2, w2: 3.1}) >>> print(s) 1.2 * b⁺(0) b(1) + 3.1 * b⁺(1) b(2)
Functionality for converting bosonic operators to qubit operators is available with
qml.unary_mapping,qml.binary_mapping, andqml.christiansen_mapping. (#6623) (#6576) (#6564)All three mappings follow the same syntax, where a
qml.BoseWordorqml.BoseSentenceis required as input.>>> w = qml.BoseWord({(0, 0): "+"}) >>> qml.binary_mapping(w, n_states=4) 0.6830127018922193 * X(0) + -0.1830127018922193 * X(0) @ Z(1) + -0.6830127018922193j * Y(0) + 0.1830127018922193j * Y(0) @ Z(1) + 0.3535533905932738 * X(0) @ X(1) + -0.3535533905932738j * X(0) @ Y(1) + 0.3535533905932738j * Y(0) @ X(1) + (0.3535533905932738+0j) * Y(0) @ Y(1)
Additional fine-tuning is available within each function, such as the maximum number of allowed bosonic states and a tolerance for discarding imaginary parts of the coefficients.
Construct vibrational Hamiltonians 🔨
Several new features are available in the
qml.qchemmodule to help with the construction of vibrational Hamiltonians. This includes:The
VibrationalPESclass to store potential energy surface information. (#6652)pes_onemode = np.array([[0.309, 0.115, 0.038, 0.008, 0.000, 0.006, 0.020, 0.041, 0.070]]) pes_twomode = np.zeros((1, 1, 9, 9)) dipole_onemode = np.zeros((1, 9, 3)) gauss_weights = np.array([3.96e-05, 4.94e-03, 8.85e-02, 4.33e-01, 7.20e-01, 4.33e-01, 8.85e-02, 4.94e-03, 3.96e-05]) grid = np.array([-3.19, -2.27, -1.47, -0.72, 0.0, 0.72, 1.47, 2.27, 3.19]) pes_object = qml.qchem.VibrationalPES( freqs=np.array([0.025]), grid=grid, uloc=np.array([[1.0]]), gauss_weights=gauss_weights, pes_data=[pes_onemode, pes_twomode], dipole_data=[dipole_onemode], localized=False, dipole_level=1, )
The
taylor_hamiltonian()function to build a Taylor Hamiltonian from aVibrationalPESobject. (#6523)>>> qml.qchem.taylor_hamiltonian(pes_object, 4, 2) ( 0.016867926879358452 * I(0) + -0.007078617919572303 * Z(0) + 0.0008679410939323631 * X(0) )
The
taylor_bosonic()function to build a Taylor Hamiltonian in terms of Bosonic operators. (#6523)>>> coeffs_arr = qml.qchem.taylor_coeffs(pes_object) >>> bose_op = qml.qchem.taylor_bosonic(coeffs_arr, pes_object.freqs, is_local=pes_object.localized, uloc=pes_object.uloc) >>> type(bose_op) pennylane.bose.bosonic.BoseSentence
Additional functionality is also available to optimize molecular geometries and convert between representations:
Convert Christiansen Hamiltonian integrals in the harmonic oscillator basis to integrals in the vibrational self-consistent field (VSCF) basis with the
vscf_integrals()function. (#6688)>>> h1 = np.array([[[0.00968289, 0.00233724, 0.0007408, 0.00199125], [0.00233724, 0.02958449, 0.00675431, 0.0021936], [0.0007408, 0.00675431, 0.0506012, 0.01280986], [0.00199125, 0.0021936, 0.01280986, 0.07282307]]]) >>> qml.qchem.vscf_integrals(h_integrals=[h1], modals=[4,4,4]) ( [array([[[ 9.36124041e-03, 3.63798208e-19, -3.42019607e-19, -3.83743044e-19], [ 9.59982270e-19, 2.77803512e-02, 5.18290259e-18, -4.82000376e-18], [-2.73826508e-19, 4.88583546e-18, 4.63297357e-02, -2.87022759e-18], [-1.94549340e-19, -5.48544743e-18, -1.41379640e-18, 7.92203227e-02]]])], None )
Find the lowest energy configuration of molecules with
optimize_geometry(). (#6453) (#6666)>>> symbols = ['H', 'F'] >>> geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) >>> mol = qml.qchem.Molecule(symbols, geometry) >>> eq_geom = qml.qchem.optimize_geometry(mol) >>> eq_geom array([[ 0. , 0. , -0.40277116], [ 0. , 0. , 1.40277116]])
Separate normal mode frequencies and localize them with
localize_normal_modes(). (#6453)>>> freqs = np.array([1326.66001461, 2297.26736859, 2299.65032901]) >>> vectors = np.array([[[ 5.71518696e-18, -4.55642350e-01, 5.20920552e-01], [ 1.13167924e-17, 4.55642350e-01, 5.20920552e-01], [-1.23163569e-17, 5.09494945e-12, -3.27565762e-02]], [[-4.53008817e-17, 4.90364125e-01, 4.90363894e-01], [-1.98591028e-16, 4.90361513e-01, -4.90361744e-01], [-2.78235498e-18, -3.08350419e-02, -6.75886679e-08]], [[ 5.75393451e-17, 5.37047963e-01, 4.41957355e-01], [ 6.53049347e-17, -5.37050348e-01, 4.41959740e-01], [-5.49709883e-17, 7.49851221e-08, -2.77912798e-02]]]) >>> freqs_loc, vecs_loc, uloc = qml.qchem.localize_normal_modes(freqs, vectors) >>> freqs_loc array([1332.62008773, 2296.73455892, 2296.7346082 ])
Labs: a place for unified and rapid prototyping of research software 🧑🔬
The new qml.labs module will house experimental research software 🔬.
Features here may be useful for state-of-the-art research, beta testing, or getting a sneak peek
into potential new features before they are added to PennyLane.
Warning
This module is experimental! This means that features may not integrate well with other PennyLane staples like differentiability, JAX, or JIT compatibility. There may also be unexpected sharp bits 🔪 and errors ❌. Breaking changes and removals will happen without warning.
Please use these features carefully and let us know your thoughts. Your feedback will inform how these features become a part of mainline PennyLane.
Resource estimation
Resource estimation functionality in Labs is focused on being light-weight and flexible. The Labs
qml.labs.resource_estimationmodule involves modifications to core PennyLane that reduce the memory requirements and computational time of resource estimation. These include new or modified base classes and one new function:Resources- This class is simplified inlabs, removing the arguments:gate_sizes,depth, andshots. (#6428)ResourceOperator- ReplacesResourceOperation, expanded to include decompositions. (#6428)CompressedResourceOp- A new class with the minimum information to estimate resources: the operator type and the parameters needed to decompose it. (#6428)ResourceOperator- versions of many existing PennyLane operations, like Pauli operators,ResourceHadamard, andResourceCNOT. (#6447) (#6579) (#6538) (#6592)get_resources()- The new entry point to efficiently obtain the resources of quantum circuits. (#6500)
Using new resource versions of existing operations and
get_resources(), we can estimate resources quickly:import pennylane.labs.resource_estimation as re def my_circuit(): for w in range(2): re.ResourceHadamard(w) re.ResourceCNOT([0, 1]) re.ResourceRX(1.23, 0) re.ResourceRY(-4.56, 1) re.ResourceQFT(wires=[0, 1, 2]) return qml.expval(re.ResourceHadamard(2))
>>> res = re.get_resources(my_circuit)() >>> print(res) wires: 3 gates: 202 gate_types: {'Hadamard': 5, 'CNOT': 10, 'T': 187}
We can also set custom gate sets for decompositions:
>>> gate_set={"Hadamard","CNOT","RZ", "RX", "RY", "SWAP"} >>> res = re.get_resources(my_circuit, gate_set=gate_set)() >>> print(res) wires: 3 gates: 24 gate_types: {'Hadamard': 5, 'CNOT': 7, 'RX': 1, 'RY': 1, 'SWAP': 1, 'RZ': 9}
Alternatively, it is possible to manually substitute associated resources:
>>> new_resources = re.substitute(res, "SWAP", re.Resources(2, 3, {"CNOT":3})) >>> print(new_resources) {'Hadamard': 5, 'CNOT': 10, 'RX': 1, 'RY': 1, 'RZ': 9}
Experimental functionality for handling dynamical Lie algebras (DLAs)
Use the
qml.labs.dlamodule to perform the KAK decomposition:cartan_decomp(): obtain a Cartan decomposition of an input Lie algebra via an involution. (#6392)We provide a variety of involutions like
concurrence_involution(),even_odd_involution()and canonical Cartan involutions. (#6392) (#6396)cartan_subalgebra(): compute a horizontal Cartan subalgebra. (#6403)variational_kak_adj(): compute a variational KAK decomposition of a Hermitian operator using a Cartan decomposition and the adjoint representation of a horizontal Cartan subalgebra. (#6446)
To use this functionality we start with a set of Hermitian operators.
>>> n = 3 >>> gens = [qml.X(i) @ qml.X(i + 1) for i in range(n - 1)] >>> gens += [qml.Z(i) for i in range(n)] >>> H = qml.sum(*gens)
We then generate its Lie algebra by computing the Lie closure.
>>> g = qml.lie_closure(gens) >>> g = [op.pauli_rep for op in g] >>> print(g) [1 * X(0) @ X(1), 1 * X(1) @ X(2), 1.0 * Z(0), ...]
We then choose an involution (e.g.
concurrence_involution()) that defines a Cartan decompositiong = k + m.kis the vertical subalgebra, andmits horizontal complement (not a subalgebra).>>> from pennylane.labs.dla import concurrence_involution, cartan_decomp >>> involution = concurrence_involution >>> k, m = cartan_decomp(g, involution=involution)
The next step is just re-ordering the basis elements in
gand computing itsstructure_constants.>>> g = k + m >>> adj = qml.structure_constants(g)
We can then compute a (horizontal) Cartan subalgebra
a, that is, a maximal Abelian subalgebra ofm.>>> from pennylane.labs.dla import cartan_subalgebra >>> g, k, mtilde, a, adj = cartan_subalgebra(g, k, m, adj)
Having determined both subalgebras
kanda, we can compute the KAK decomposition variationally like in 2104.00728, see our demo on KAK decomposition in practice.>>> from pennylane.labs.dla import variational_kak_adj >>> dims = (len(k), len(mtilde), len(a)) >>> adjvec_a, theta_opt = variational_kak_adj(H, g, dims, adj, opt_kwargs={"n_epochs": 3000})
We also provide some additional features that are useful for handling dynamical Lie algebras.
Vibrational Hamiltonians
New functionality in labs helps with the construction of vibrational Hamiltonians.
Generate potential energy surfaces (PES) with
qml.labs.vibrational.vibrational_pes. (#6616) (#6676)>>> symbols = ['H', 'F'] >>> geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) >>> mol = qml.qchem.Molecule(symbols, geometry) >>> pes = vibrational_pes(mol)
Use the
qml.labs.vibrational.christiansen_hamiltonianfunction and potential energy surfaces to generate Hamiltonians in the Ch ristiansen form. (#6560)
Improvements 🛠
QChem improvements
The
qml.qchem.factorizefunction now supports new methods for double factorization: Cholesky decomposition (cholesky=True) and compressed double factorization (compressed=True). (#6573) (#6611)A new function for performing the block-invariant symmetry shift on electronic integrals has been added with
qml.qchem.symmetry_shift. (#6574)The differentiable Hartree-Fock workflow is now compatible with JAX. (#6096) (#6707)
Transform for combining GlobalPhase instances
A new transform called
qml.transforms.combine_global_phaseshas been added. It combines allqml.GlobalPhasegates in a circuit into a single one applied at the end. This can be useful for circuits that include a lot ofqml.GlobalPhasegates that are introduced directly during circuit creation, decompositions that includeqml.GlobalPhasegates, etc. (#6686)
Better drawing functionality
qml.draw_mplnow has awire_optionskeyword argument, which allows for global- and per-wire customization with options likecolor,linestyle, andlinewidth. (#6486)Here is an example that would make all wires cyan and bold except for wires 2 and 6, which are dashed and a different colour.
@qml.qnode(qml.device("default.qubit")) def circuit(x): for w in range(5): qml.Hadamard(w) return qml.expval(qml.PauliZ(0) @ qml.PauliY(1)) wire_options = {"color": "cyan", "linewidth": 5, 2: {"linestyle": "--", "color": "red"}, 6: {"linestyle": "--", "color": "orange"} } print(qml.draw_mpl(circuit, wire_options=wire_options)(0.52))
New device capabilities 💾
Two new methods,
setup_execution_configandpreprocess_transforms, have been added to theDeviceclass. Device developers are encouraged to override these two methods separately instead of thepreprocessmethod. For now, to avoid ambiguity, a device is allowed to override either these two methods orpreprocess, but not both. In the long term, we will slowly phase out the use ofpreprocessin favour of these two methods for better separation of concerns. (#6617)Developers of plugin devices now have the option of providing a TOML-formatted configuration file to declare the capabilities of the device. See Device Capabilities for details.
An internal module called
qml.devices.capabilitieshas been added that defines a newDeviceCapabilitesdata class, as well as functions that load and parse the TOML-formatted configuration files. (#6407)>>> from pennylane.devices.capabilities import DeviceCapabilities >>> capabilities = DeviceCapabilities.from_toml_file("my_device.toml") >>> isinstance(capabilities, DeviceCapabilities) True
Devices that extend
qml.devices.Devicenow have an optional class attribute calledcapabilities, which is an instance of theDeviceCapabilitiesdata class constructed from the configuration file if it exists. Otherwise, it is set toNone. (#6433)from pennylane.devices import Device class MyDevice(Device): config_filepath = "path/to/config.toml" ...
>>> isinstance(MyDevice.capabilities, DeviceCapabilities) True
Default implementations of
Device.setup_execution_configandDevice.preprocess_transformshave been added to the device API for devices that provide a TOML configuration file and, thus, have acapabilitiesproperty. (#6632) (#6653)
Capturing and representing hybrid programs
Support has been added for
if/elsestatements andforandwhileloops in circuits executed withqml.capture.enabled, via Autograph. Autograph conversion is now used by default inmake_plxpr, but can be skipped withautograph=False. (#6406) (#6413) (#6426) (#6645) (#6685)qml.transformnow accepts aplxpr_transformargument. This argument must be a function that can transform plxpr. Note that executing a transformed function will currently raise aNotImplementedError. To see more details, check out thedocumentation of qml.transform. (#6633) (#6722)Users can now apply transforms with program capture enabled. Transformed functions cannot be executed by default. To apply the transforms (and to be able to execute the function), it must be decorated with the new
qml.capture.expand_plxpr_transformsfunction, which accepts a callable as input and returns a new function for which all present transforms have been applied. (#6722)from functools import partial qml.capture.enable() wire_map = {0: 3, 1: 6, 2: 9} @partial(qml.map_wires, wire_map=wire_map) def circuit(x, y): qml.RX(x, 0) qml.CNOT([0, 1]) qml.CRY(y, [1, 2]) return qml.expval(qml.Z(2))
>>> qml.capture.make_plxpr(circuit)(1.2, 3.4) { lambda ; a:f32[] b:f32[]. let c:AbstractMeasurement(n_wires=None) = _map_wires_transform_transform[ args_slice=slice(0, 2, None) consts_slice=slice(2, 2, None) inner_jaxpr={ lambda ; d:f32[] e:f32[]. let _:AbstractOperator() = RX[n_wires=1] d 0 _:AbstractOperator() = CNOT[n_wires=2] 0 1 _:AbstractOperator() = CRY[n_wires=2] e 1 2 f:AbstractOperator() = PauliZ[n_wires=1] 2 g:AbstractMeasurement(n_wires=None) = expval_obs f in (g,) } targs_slice=slice(2, None, None) tkwargs={'wire_map': {0: 3, 1: 6, 2: 9}, 'queue': False} ] a b in (c,) } >>> transformed_circuit = qml.capture.expand_plxpr_transforms(circuit) >>> jax.make_jaxpr(transformed_circuit)(1.2, 3.4) { lambda ; a:f32[] b:f32[]. let _:AbstractOperator() = RX[n_wires=1] a 3 _:AbstractOperator() = CNOT[n_wires=2] 3 6 _:AbstractOperator() = CRY[n_wires=2] b 6 9 c:AbstractOperator() = PauliZ[n_wires=1] 9 d:AbstractMeasurement(n_wires=None) = expval_obs c in (d,) }
The
qml.iterative_qpefunction can now be compactly captured into plxpr. (#6680)Three new plxpr interpreters have been added that allow for functions and plxpr to be natively transformed with the same API as the corresponding existing transforms in PennyLane when program capture is enabled:
qml.capture.transforms.CancelInterpreter:this class cancels operators appearing consecutively that are adjoints of each other following the same API asqml.transforms.cancel_inverses. (#6692)qml.capture.transforms.DecomposeInterpreter: this class decomposes pennylane operators following the same API asqml.transforms.decompose. (#6691)qml.capture.transforms.MapWiresInterpreter: this class maps wires to new values following the same API asqml.map_wires. (#6697)
A
qml.tape.plxpr_to_tapefunction is now available that converts plxpr to a tape. (#6343)Execution with capture enabled now follows a new execution pipeline and natively passes the captured plxpr to the device. Since it no longer falls back to the old pipeline, execution only works with a reduced feature set. (#6655) (#6596)
PennyLane transforms can now be captured as primitives with experimental program capture enabled. (#6633)
jax.vmapcan be captured withqml.capture.make_plxprand is compatible with quantum circuits. (#6349) (#6422) (#6668)A
qml.capture.PlxprInterpreterbase class has been added for easy transformation and execution of plxpr. (#6141)A
DefaultQubitInterpreterclass has been added to provide plxpr execution using python based tools, and theDefaultQubit.eval_jaxprmethod has been implemented. (#6594) (#6328)An optional method,
eval_jaxpr, has been added to the device API for native execution of plxpr programs. (#6580)qml.capture.qnode_callhas been made private and moved to theworkflowmodule. (#6620)
Other Improvements
qml.math.gradandqml.math.jacobianhave been added to differentiate a function with inputs of any interface in a JAX-like manner. (#6741)qml.GroverOperatornow has awork_wiresproperty. (#6738)The
Wiresobject’s usage across Pennylane source code has been tidied up for internal consistency. (#6689)qml.equalnow supportsqml.PauliWordandqml.PauliSentenceinstances. (#6703)Redundant commutator computations from
qml.lie_closurehave been removed. (#6724)A comprehensive error is now raised when using
qml.fourier.qnode_spectrumwith standard Numpy arguments andinterface="auto". (#6622)Pauli string representations for the gates
{X, Y, Z, S, T, SX, SWAP, ISWAP, ECR, SISWAP}have been added, and a shape error in the matrix conversion ofqml.PauliSentences withlistorarrayinputs has been fixed. (#6562) (#6587)qml.QNodeandqml.executenow forbid certain keyword arguments from being passed positionally. (#6610)The string representations for the
qml.S,qml.T, andqml.SXhave been shortened. (#6542)Internal class functions and dunder methods have been added to allow for multiplying Resources objects in series and in parallel. (#6567)
The
diagonalize_measurementstransform no longer raises an error for unknown observables. Instead, they are left un-diagonalized, with the expectation that observable validation will catch any un-diagonalized observables that are also unsupported by the device. (#6653)A
qml.wires.Wiresobject can now be converted to a JAX array, if all wire labels are supported as JAX array elements. (#6699)A developer focused
runfunction has been added to theqml.workflowmodule for a cleaner and standardized approach to executing tapes on an ML interface. (#6657)Internal changes have been made to standardize execution interfaces, which resolves ambiguities in how the
interfacevalue is handled during execution. (#6643)All interface handling logic has been moved to
interface_utils.pyin theqml.mathmodule. (#6649)qml.executecan now be used withdiff_method="best". Classical cotransform information is now handled lazily by the workflow. Gradient method validation and program setup are now handled inside ofqml.execute, instead of inQNode. (#6716)PyTree support for measurements in a circuit has been added. (#6378)
@qml.qnode(qml.device("default.qubit")) def circuit(): qml.Hadamard(0) qml.CNOT([0,1]) return {"Probabilities": qml.probs(), "State": qml.state()}
>>> circuit() {'Probabilities': array([0.5, 0. , 0. , 0.5]), 'State': array([0.70710678+0.j, 0. +0.j, 0. +0.j, 0.70710678+0.j])}
The
_cache_transformtransform has been moved to its own file located inpennylane/workflow/_cache_transform.py. (#6624)The
qml.BasisRotationtemplate is now JIT compatible. (#6019) (#6779)The Jaxpr primitives for
for_loop,while_loopandcondnow store slices instead of numbers of arguments. This helps with keeping track of what order the arguments come in. (#6521)The
ExecutionConfig.gradient_methodfunction has been expanded to storeTransformDispatchertype. (#6455)The string representation of
Resourcesinstances has been improved to match the attribute names. (#6581)The documentation for the
dynamic_one_shottransform has been improved, and a warning is raised when a user-applieddynamic_one_shottransform is ignored in favour of the existing transform in a device’s preprocessing transform program. (#6701)A
qml.devices.qubit_mixedmodule has been added for mixed-state qubit device support. This module introduces anapply_operationhelper function that features:Two density matrix contraction methods using
einsumandtensordotOptimized handling of special cases including: Diagonal operators, Identity operators, CX (controlled-X), Multi-controlled X gates, Grover operators (#6379)
A function called
create_initial_statehas been added to allow for initializing a circuit with a density matrix usingqml.StatePreporqml.QubitDensityMatrix. (#6503)Several additions have been made to eventually migrate the
"default.mixed"device to the new device API:A
preprocessmethod has been added to theQubitMixeddevice class to preprocess the quantum circuit before execution. (#6601)A new class called
DefaultMixedNewAPIhas been added to theqml.devices.qubit_mixedmodule, which will replace the legacyDefaultMixed. (#6607)A new submodule called
devices.qubit_mixed.measurehas been added, featuring ameasurefunction for measuring qubits in mixed-state devices. (#6637)A new submodule called
devices.qubit_mixed.simulatehas been added, featuring asimulatefunction for simulating mixed states in analytic mode. (#6618)A new submodule called
devices.qubit_mixed.samplinghas been added, featuring functionssample_state,measure_with_samplesandsample_probsfor sampling qubits in mixed-state devices. (#6639)The finite-shot branch of
devices.qubit_mixed.simulatehas been added, which allows for accepting stochastic arguments such asshots,rngandprng_key. (#6665)Support for
qml.Snapshothas been added. (#6659)
Reporting of test warnings as failures has been added. (#6217)
A warning message in the Gradients and training documentation has been added that pertains to
ComplexWarnings. (#6543)A new figure was added to the landing page of the PennyLane website. (#6696)
Breaking changes 💔
The default graph coloring method of
qml.dot,qml.sum, andqml.pauli.optimize_measurementsfor grouping observables was changed from"rlf"to"lf". Internally,qml.pauli.group_observableshas been replaced withqml.pauli.compute_partition_indicesin several places to improve efficiency. (#6706)qml.fourier.qnode_spectrumno longer automatically converts pure Numpy parameters to the Autograd framework. As the function uses automatic differentiation for validation, parameters from such a framework have to be used. (#6622)qml.math.jax_argnums_to_tape_trainablehas been moved and made private to avoid an unnecessary QNode dependency in theqml.mathmodule. (#6609)Gradient transforms are now applied after the user’s transform program. This ensures user transforms work as expected on initial structures (e.g., embeddings or entangling layers), guarantees that gradient transforms only process compatible operations, aligns transform order with user expectations, and avoids confusion. (#6590)
Legacy operator arithmetic has been removed. This includes
qml.ops.Hamiltonian,qml.operation.Tensor,qml.operation.enable_new_opmath,qml.operation.disable_new_opmath, andqml.operation.convert_to_legacy_H. Note thatqml.Hamiltonianwill continue to dispatch toqml.ops.LinearCombination. For more information, check out the updated operator troubleshooting page. (#6548) (#6602) (#6589)The developer-facing
qml.utilsmodule has been removed. (#6588):Specifically, the following 4 sets of functions have been either moved or removed:
qml.utils._flatten,qml.utils.unflattenhas been moved and renamed toqml.optimize.qng._flatten_npandqml.optimize.qng._unflatten_nprespectively.qml.utils._inv_dictandqml._get_default_argshave been removed.qml.utils.pauli_eigshas been moved toqml.pauli.utils.qml.utils.expand_vectorhas been moved toqml.math.expand_vector.
The
qml.qinfomodule has been removed. Please use the corresponding functions in theqml.mathandqml.measurementsmodules instead. (#6584)Top level access to
Device,QubitDevice, andQutritDevicehave been removed. Instead, they are available asqml.devices.LegacyDevice,qml.devices.QubitDevice, andqml.devices.QutritDevice, respectively. (#6537)The
'ancilla'argument forqml.iterative_qpehas been removed. Instead, use the'aux_wire'argument. (#6532)The
qml.BasisStatePreparationtemplate has been removed. Instead, useqml.BasisState. (#6528)The
qml.workflow.set_shotshelper function has been removed. We no longer interact with the legacy device interface in our code. Instead, shots should be specified on the tape, and the device should use these shots. (#6534)QNode.gradient_fnhas been removed. Please useQNode.diff_methodinstead.QNode.get_gradient_fncan also be used to process the differentiation method. (#6535)The
qml.QubitStateVectortemplate has been removed. Instead, useqml.StatePrep. (#6525)qml.broadcasthas been removed. Users should useforloops instead. (#6527)The
max_expansionargument forqml.transforms.clifford_t_decompositionhas been removed. (#6571)The
expand_depthargument forqml.compilehas been removed. (#6531)The
qml.shadows.shadow_expvaltransform has been removed. Instead, please use theqml.shadow_expvalmeasurement process. (#6530) (#6561)The developer-facing
qml.drawer.MPLDrawerargumentn_wireshas been replaced withwire_map, which contains more complete information about wire labels and order. This allows the new functionality to specifywire_optionsfor specific wires when using string wire labels or non-sequential wire ordering. (#6805)
Deprecations 👋
The
tapeandqtapeproperties ofQNodehave been deprecated. Instead, use theqml.workflow.construct_tapefunction. (#6583) (#6650)The
max_expansionargument inqml.devices.preprocess.decomposeis deprecated and will be removed in v0.41. (#6400)The
decomp_depthargument inqml.transforms.set_decompositionis deprecated and will be removed in v0.41. (#6400)The
output_dimproperty ofqml.tape.QuantumScripthas been deprecated. Instead, use methodshapeofQuantumScriptorMeasurementProcessto get the same information. (#6577)The
QNode.get_best_methodandQNode.best_method_strmethods have been deprecated. Instead, use theqml.workflow.get_best_diff_methodfunction. (#6418)The
qml.executegradient_fnkeyword argument has been renamed todiff_methodto better align with the termionology used by the QNode.gradient_fnwill be removed in v0.41. (#6549)The old
qml.qsvtfunctionality is moved toqml.qsvt_legacyand is now deprecated. It will be removed in v0.41. (#6520)
Documentation 📝
The docstrings for
qml.qchem.Moleculeandqml.qchem.molecular_hamiltonianhave been updated to include a note that says that they are not compatible withqjitorjit.
(#6702)The documentation of
TrotterProducthas been updated to include the impact of the operands in the Hamiltonian on the structure of the created circuit. (#6629)The documentation of
QSVThas been updated to include examples for different block encodings. (#6673)The link to
qml.ops.one_qubit_transformwas fixed in theQubitUnitarydocstring. (#6745)
Bug fixes 🐛
Validation has been added to ensure that the device vjp is only used when the device actually supports it. (#6755)
qml.countsnow returns all outcomes when theall_outcomesargument isTrueand mid-circuit measurements are present. (#6732)qml.ControlledQubitUnitarynow has consistent behaviour with program capture enabled. (#6719)The
Wiresobject now throws aTypeErrorifwires=None. (#6713) (#6720)The
qml.Hermitianclass no longer checks that the provided matrix is hermitian. The reason for this removal is to allow for faster execution and avoid incompatibilities withjax.jit. (#6642)Subclasses of
qml.ops.Controlledno longer bind the primitives of their base operators when program capture is enabled. (#6672)The
qml.HilbertSchmidtandqml.LocalHilbertSchmidttemplates now apply the complex conjugate of the unitaries instead of the adjoint, providing the correct result. (#6604)QNode return behaviour is now consistent for lists and tuples. (#6568)
QNodes now accept arguments with types defined in libraries that are not necessarily in the list of supported interfaces, such as the
Graphclass defined innetworkx. (#6600)qml.math.get_deep_interfacenow works properly for Autograd arrays. (#6557)Printing instances of
qml.Identitynow returns the correct wires list. (#6506)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso, Shiwen An, Utkarsh Azad, Astral Cai, Yushao Chen, Isaac De Vlugt, Diksha Dhawan, Lasse Dierich, Lillian Frederiksen, Pietropaolo Frisoni, Simone Gasperini, Diego Guala, Austin Huang, Korbinian Kottmann, Christina Lee, Alan Martin, William Maxwell, Anton Naim Ibrahim, Andrija Paurevic, Justin Pickering, Jay Soni, David Wierichs.
Release 0.39.0¶
New features since last release
Creating spin Hamiltonians on lattices 💞
Functionality for creating custom Hamiltonians on arbitrary lattices has been added. (#6226) (#6237)
Hamiltonians beyond the available boiler-plate ones in the
qml.spinmodule can be created with the addition of three new functions:qml.spin.Lattice: a new object for instantiating customized lattices via primitive translation vectors and unit cell parameters,qml.spin.generate_lattice: a utility function for creating standardLatticeobjects, including'chain','square','rectangle','triangle','honeycomb','kagome','lieb','cubic','bcc','fcc', and'diamond',qml.spin.spin_hamiltonian: generates a spinHamiltonianobject given aLatticeobject with custom edges/nodes.
An example is shown below for a \(3 \times 3\) triangular lattice with open boundary conditions.
lattice = qml.spin.Lattice( n_cells=[3, 3], vectors=[[1, 0], [np.cos(np.pi/3), np.sin(np.pi/3)]], positions=[[0, 0]], boundary_condition=False )
We can validate this
latticeagainstqml.spin.generate_lattice('triangle', ...)by checking thelattice_points(the \((x, y)\) coordinates of all sites in the lattice):>>> lp = lattice.lattice_points >>> triangular_lattice = qml.spin.generate_lattice('triangle', n_cells=[3, 3]) >>> np.allclose(lp, triangular_lattice.lattice_points) True
The
edgesof theLatticeobject are nearest-neighbour by default, where we can add edges by using itsadd_edgemethod.Optionally, a
Latticeobject can have interactions and fields endowed to it by specifying values for itscustom_edgesandcustom_nodeskeyword arguments. The Hamiltonian can then be extracted with theqml.spin.spin_hamiltonianfunction. An example is shown below for the transverse-field Ising model Hamiltonian on a \(3 \times 3\) triangular lattice. Note that thecustom_edgesandcustom_nodeskeyword arguments only need to be defined for one unit cell repetition.edges = [ (0, 1), (0, 3), (1, 3) ] lattice = qml.spin.Lattice( n_cells=[3, 3], vectors=[[1, 0], [np.cos(np.pi/3), np.sin(np.pi/3)]], positions=[[0, 0]], boundary_condition=False, custom_edges=[[edge, ("ZZ", -1.0)] for edge in edges], custom_nodes=[[i, ("X", -0.5)] for i in range(3*3)], )
>>> tfim_ham = qml.spin.transverse_ising('triangle', [3, 3], coupling=1.0, h=0.5) >>> tfim_ham == qml.spin.spin_hamiltonian(lattice=lattice) True
More industry-standard spin Hamiltonians have been added in the
qml.spinmodule. (#6174) (#6201)Three new industry-standard spin Hamiltonians are now available with PennyLane v0.39:
qml.spin.emery: the Emery modelqml.spin.haldane: the Haldane modelqml.spin.kitaev: the Kitaev model
These additions accompany
qml.spin.heisenberg,qml.spin.transverse_ising, andqml.spin.fermi_hubbard, which were introduced in v0.38.
Calculating Polynomials 🔢
Polynomial functions can now be easily encoded into quantum circuits with
qml.OutPoly. (#6320)A new template called
qml.OutPolyis available, which provides the ability to encode a polynomial function in a quantum circuit. Given a polynomial function \(f(x_1, x_2, \cdots, x_N)\),qml.OutPolyrequires:f: a standard Python function that represents \(f(x_1, x_2, \cdots, x_N)\),input_registers(\(\vert x_1 \rangle\), \(\vert x_2 \rangle\), …, \(\vert x_N \rangle\)) : a list/tuple containingWiresobjects that correspond to the embedded numeric values of \(x_1, x_2, \cdots, x_N\),output_wires: the Wires for which the numeric value of \(f(x_1, x_2, \cdots, x_N)\) is stored.
Here is an example of using
qml.OutPolyto calculate \(f(x_1, x_2) = 3x_1^2 - x_1x_2\) for \(f(1, 2) = 1\).wires = qml.registers({"x1": 1, "x2": 2, "output": 2}) def f(x1, x2): return 3 * x1 ** 2 - x1 * x2 @qml.qnode(qml.device("default.qubit", shots = 1)) def circuit(): # load values of x1 and x2 qml.BasisEmbedding(1, wires=wires["x1"]) qml.BasisEmbedding(2, wires=wires["x2"]) # apply the polynomial qml.OutPoly( f, input_registers = [wires["x1"], wires["x2"]], output_wires = wires["output"]) return qml.sample(wires=wires["output"])
>>> circuit() array([0, 1])
The result,
[0, 1], is the binary representation of \(1\). By default, the result is calculated modulo \(2^\text{len(output_wires)}\) but can be overridden with themodkeyword argument.
Readout Noise 📠
Readout errors can now be included in
qml.NoiseModelandqml.add_noisewith the newqml.noise.meas_eqfunction. (#6321)Measurement/readout errors can be specified in a similar fashion to regular gate noise in PennyLane: a newly added Boolean function called
qml.noise.meas_eqthat accepts a measurement function (e.g.,qml.expval,qml.sample, or any other function that can be returned from a QNode) that, when present in the QNode, inserts a noisy operation viaqml.noise.partial_wiresor a custom noise function. Readout noise in PennyLane also follows the insertion convention, where the specified noise is inserted before the measurement.Here is an example of adding
qml.PhaseFlipnoise to anyqml.expvalmeasurement:c0 = qml.noise.meas_eq(qml.expval) n0 = qml.noise.partial_wires(qml.PhaseFlip, 0.2)
To include this in a
qml.NoiseModel, use itsmeas_mapkeyword argument:# gate-based noise c1 = qml.noise.wires_in([0, 2]) n1 = qml.noise.partial_wires(qml.RY, -0.42) noise_model = qml.NoiseModel({c1: n1}, meas_map={c0: n0})
>>> noise_model NoiseModel({ WiresIn([0, 2]): RY(phi=-0.42) }, meas_map = { MeasEq(expval): PhaseFlip(p=0.2) })
qml.noise.meas_eqcan also be combined with other Boolean functions inqml.noisevia bitwise operators for more versatility.To add this
noise_modelto a circuit, use theqml.add_noisetransform as per usual. For example,@qml.qnode(qml.device("default.mixed", wires=3)) def circuit(): qml.RX(0.1967, wires=0) for i in range(3): qml.Hadamard(i) return qml.expval(qml.X(0) @ qml.X(1))
>>> noisy_circuit = qml.add_noise(circuit, noise_model) >>> print(qml.draw(noisy_circuit)()) 0: ──RX(0.20)──RY(-0.42)────────H──RY(-0.42)──PhaseFlip(0.20)─┤ ╭<X@X> 1: ──H─────────PhaseFlip(0.20)────────────────────────────────┤ ╰<X@X> 2: ──H─────────RY(-0.42)──────────────────────────────────────┤ >>> print(circuit(), noisy_circuit()) 0.9807168489852615 0.35305806563469433
User-friendly decompositions 📠
A new transform called
qml.transforms.decomposehas been added to better facilitate the custom decomposition of operators in PennyLane circuits. (#6334)Previous to the addition of
qml.transforms.decompose, decomposing operators in PennyLane had to be done by specifying astopping_conditioninqml.device.preprocess.decompose. Withqml.transforms.decompose, the user-interface for specifying decompositions is much simpler and more versatile.Decomposing gates in a circuit can be done a few ways:
Specifying a
gate_setcomprising PennyLaneOperators to decompose into:from functools import partial dev = qml.device('default.qubit') allowed_gates = {qml.Toffoli, qml.RX, qml.RZ} @partial(qml.transforms.decompose, gate_set=allowed_gates) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=[0]) qml.Toffoli(wires=[0, 1, 2]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──RZ(1.57)──RX(1.57)──RZ(1.57)─╭●─┤ <Z> 1: ───────────────────────────────├●─┤ 2: ───────────────────────────────╰X─┤
Specifying a
gate_setthat is defined by a rule (Boolean function). For example, one can specify an arbitrary gate set to decompose into, so long as the resulting gates only act on one or two qubits:@partial(qml.transforms.decompose, gate_set = lambda op: len(op.wires) <= 2) @qml.qnode(dev) def circuit(): qml.Toffoli(wires=[0, 1, 2]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ───────────╭●───────────╭●────╭●──T──╭●─┤ <Z> 1: ────╭●─────│─────╭●─────│───T─╰X──T†─╰X─┤ 2: ──H─╰X──T†─╰X──T─╰X──T†─╰X──T──H────────┤
Specifying a value for
max_expansion. By default, decomposition occurs recursively until the desired gate set is reached, but this can be overridden to control the number of passes.phase = 1.0 target_wires = [0] unitary = qml.RX(phase, wires=0).matrix() n_estimation_wires = 1 estimation_wires = range(1, n_estimation_wires + 1) def qfunc(): qml.QuantumPhaseEstimation( unitary, target_wires=target_wires, estimation_wires=estimation_wires, ) decompose_once = qml.transforms.decompose(qfunc, max_expansion=1) decompose_twice = qml.transforms.decompose(qfunc, max_expansion=2)
>>> print(qml.draw(decompose_once)()) 0: ────╭U(M0)¹───────┤ 1: ──H─╰●───────QFT†─┤ M0 = [[0.87758256+0.j 0. -0.47942554j] [0. -0.47942554j 0.87758256+0.j ]] >>> print(qml.draw(decompose_twice)()) 0: ──RZ(1.57)──RY(0.50)─╭X──RY(-0.50)──RZ(-6.28)─╭X──RZ(4.71)─┤ 1: ──H──────────────────╰●───────────────────────╰●──H†───────┤
Improvements 🛠
qjit/jit compatibility and improvements
Quantum just-in-time (qjit) compilation
is the compilation of hybrid quantum-classical programs during execution of a program, rather than before
execution. PennyLane provides just-in-time compilation with its @qml.qjit decorator, powered by the
Catalyst compiler.
Several templates are now compatible with qjit:
The sample-based measurements now support samples that are JAX tracers, allowing compatiblity with qjit workflows. (#6211)
The
qml.FABLEtemplate now returns the correct value when jit is enabled. (#6263)qml.metric_tensoris now jit compatible. (#6468)qml.QutritBasisStatePreparationis now jit compatible. (#6308)All PennyLane templates are now unit tested to ensure jit compatibility. (#6309)
Various improvements to fermionic operators
qml.fermi.FermiWordandqml.fermi.FermiSentenceare now compatible with JAX arrays. (#6324)Fermionic operators interacting, in some way, with a JAX array will no longer raise an error. For example:
>>> import jax.numpy as jnp >>> w = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) >>> jnp.array([3]) * w FermiSentence({FermiWord({(0, 0): '+', (1, 1): '-'}): Array([3], dtype=int32)})
The
qml.fermi.FermiWordclass now has ashift_operatormethod to apply anti-commutator relations. (#6196)>>> w = qml.fermi.FermiWord({(0, 0): '+', (1, 1): '-'}) >>> w FermiWord({(0, 0): '+', (1, 1): '-'}) >>> w.shift_operator(0, 1) FermiSentence({FermiWord({(0, 1): '-', (1, 0): '+'}): -1})
The
qml.fermi.FermiWordandqml.fermi.FermiSentenceclasses now anadjointmethod. (#6166)>>> w = qml.fermi.FermiWord({(0, 0): '+', (1, 1): '-'}) >>> w.adjoint() FermiWord({(0, 1): '+', (1, 0): '-'})
The
to_matmethods forqml.fermi.FermiWordandqml.fermi.FermiSentencenow optionally return a sparse matrix with theformatkeyword argument. (#6173)>>> w = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) >>> w.to_mat(format="dense") array([[0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], [0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], [0.+0.j, 1.+0.j, 0.+0.j, 0.+0.j], [0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j]]) >>> w.to_mat(format="csr") <4x4 sparse matrix of type '<class 'numpy.complex128'>' with 1 stored elements in Compressed Sparse Row format>
When printed,
qml.fermi.FermiWordandqml.fermi.FermiSentencenow return a unique representation of the object. (#6167)>>> w = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) >>> print(w) a⁺(0) a(1)
qml.qchem.excitationsnow optionally returns fermionic operators with a newfermionickeyword argument (defaults toFalse). (#6171)>>> singles, doubles = excitations(electrons, orbitals, fermionic=True) >>> print(singles) [FermiWord({(0, 0): '+', (1, 2): '-'}), FermiWord({(0, 1): '+', (1, 3): '-'})]
A new optimizer
A new optimizer called
qml.MomentumQNGOptimizerhas been added. It inherits from the basicqml.QNGOptimizeroptimizer and requires one additional hyperparameter: the momentum coefficient, \(0 \leq \rho < 1\), the default value being \(\rho=0.9\). For \(\rho=0\),qml.MomentumQNGOptimizerreduces down toqml.QNGOptimizer. (#6240)
Other Improvements
default.tensorcan now handle mid-circuit measurements via the deferred measurement principle. (#6408)process_density_matrixwas implemented in 5StateMeasurementsubclasses:ExpVal,Var,Purity,MutualInformation, andVnEntropy. This facilitates future support for mixed-state devices and expanded density matrix operations. Also, a fix was made in theProbabilityMPclass to useqml.math.sqrtinstead ofnp.sqrt. (#6330)The decomposition for
qml.Qubitizationhas been improved to useqml.PrepSelPrep. (#6182)A
ReferenceQubitdevice (shortname:"reference.qubit") has been introduced for testing purposes and referencing for future plugin development. (#6181)qml.transforms.mitigate_with_znenow gives a clearer error message when being applied on circuits, not devices, that include channel noise. (#6346)A new function called
get_best_diff_methodhas been added toqml.workflow. (#6399)A new method called
construct_tapehas been added toqml.workflowfor users to construct single tapes from aQNode. (#6419)An infrastructural improvement was made to PennyLane datasets that allows us to upload datasets more easily. (#6126)
qml.Hadamardnow has a more friendly alias:qml.H. (#6450)A Boolean keyword argument called
show_wire_labelshas been added todrawanddraw_mpl, which hides wire labels when set toFalse(the default isTrue). (#6410)A new function called
sample_probshas been added to theqml.devices.qubitandqml.devices.qutrit_mixedmodules. This function takes probability distributions as input and returns sampled outcomes, simplifying the sampling process by separating it from other operations in the measurement chain and improving modularity. (#6354)qml.labshas been added to the PennyLane documentation. (#6397) (#6369)A
has_sparse_matrixproperty has been added toOperatorto indicate whether a sparse matrix is defined. (#6278) (#6310)qml.matrixnow works with empty objects (e.g., empty tapes, QNodes and quantum functions that do not call operations, and single operators with empty decompositions). (#6347)dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def node(): return qml.expval(qml.Z(0))
>>> qml.matrix(node)() array([[1., 0.], [0., 1.]])
PennyLane is now compatible with NumPy 2.0. (#6061) (#6258) (#6342)
PennyLane is now compatible with Jax 0.4.28. (#6255)
The
diagonalize_measurementstransform now uses a more efficient method of diagonalization when possible, based on thepauli_repof the relevant observables. (#6113)The
QuantumScript.copymethod now takesoperations,measurements,shotsandtrainable_paramsas keyword arguments. If any of these are passed when copying a tape, the specified attributes will replace the copied attributes on the new tape. (#6285) (#6363)The
Hermitianoperator now has acompute_sparse_matriximplementation. (#6225)When an observable is repeated on a tape,
tape.diagonalizing_gatesno longer returns the diagonalizing gates for each instance of the observable. Instead, the diagonalizing gates of each observable on the tape are included just once. (#6288)The number of diagonalizing gates returned in
qml.specsnow follows thelevelkeyword argument regarding whether the diagonalizing gates are modified by device, instead of always counting unprocessed diagonalizing gates. (#6290)A more sensible error message is raised from a
RecursionErrorencountered when accessing properties and methods of a nestedCompositeOporSProd. (#6375)By default,
qml.sumandqml.prodsetlazy=True, which keeps its operands nested. Given the recursive nature of such structures, if there are too many levels of nesting, aRecursionErrorwould occur when accessing many of the properties and methods.The performance of the decomposition of
qml.QFThas been improved. (#6434)
Capturing and representing hybrid programs
qml.wires.Wiresnow accepts JAX arrays as input. In many workflows with JAX, PennyLane may attempt to assign a JAX array to aWiresobject, which will cause an error since JAX arrays are not hashable. Now, JAX arrays are validWirestypes. Furthermore, aFutureWarningis no longer raised inJAX 0.4.30+when providing JAX tracers as input toqml.wires.Wires. (#6312)A new function called
qml.capture.make_plxprhas been added to take a function and create aCallablethat, when called, will return a PLxPR representation of the input function. (#6326)`Differentiation of hybrid programs via
qml.gradandqml.jacobiancan now be captured with PLxPR. When evaluating a capturedqml.grad(qml.jacobian) instruction, it will dispatch tojax.grad(jax.jacobian), which differs from the Autograd implementation without capture. Pytree inputs and outputs are supported. (#6120) (#6127) (#6134)Unit testing for capturing nested control flow has been improved. (#6111)
Some custom primitives for the capture project can now be imported via
from pennylane.capture.primitives import *. (#6129)All higher order primitives now use
jax.core.Jaxpras metadata instead of sometimes usingjax.core.ClosedJaxprorjax.core.Jaxpr. (#6319)
Breaking changes 💔
Red-herring validation in
QNode.constructhas been removed, which fixed a bug withqml.GlobalPhase. (#6373)Removing the
AllWiresvalidation inQNode.constructwas addressed as a solution to the following example not being able to run:@qml.qnode(qml.device('default.qubit', wires=2)) def circuit(x): qml.GlobalPhase(x, wires=0) return qml.state()
>>> circuit(0.5) array([0.87758256-0.47942554j, 0. +0.j , 1. +0.j , 0. +0.j ])
The
simplifyargument inqml.Hamiltonianandqml.ops.LinearCombinationhas been removed. Instead,qml.simplify()can be called on the constructed operator. (#6279)The functions
qml.qinfo.classical_fisherandqml.qinfo.quantum_fisherhave been removed and migrated to theqml.gradientsmodule.qml.gradients.classical_fisherandqml.gradients.quantum_fishershould be used instead. (#5911)Python 3.9 is no longer supported. Please update to 3.10 or newer. (#6223)
default.qubit.legacy,default.qubit.tf,default.qubit.torch,default.qubit.jax, anddefault.qubit.autogradhave been removed. Please usedefault.qubitfor all interfaces. (#6207) (#6208) (#6209) (#6210) (#6266)expand_fn,max_expansion,override_shots, anddevice_batch_transformhave been removed from the signature ofqml.execute. (#6203)max_expansionandexpansion_strategyhave been removed from the QNode. (#6203)expansion_strategyhas been removed fromqml.draw,qml.draw_mpl, andqml.specs.max_expansionhas been removed fromqml.specs, as it had no impact on the output. (#6203)qml.transforms.hamiltonian_expandandqml.transforms.sum_expandhave been removed. Please useqml.transforms.split_non_commutinginstead. (#6204)The
decomp_depthkeyword argument toqml.devicehas been removed. (#6234)Operator.expandhas been removed. Please useqml.tape.QuantumScript(op.decomposition())instead. (#6227)The native folding method
qml.transforms.fold_globalfor theqml.transforms.mitigate_with_znetransform no longer expands the circuit automatically. Instead, the user should applyqml.transforms.decomposeto decompose a circuit into a target gate set before applyingfold_globalormitigate_with_zne. (#6382)The
LightningVJPsclass has been removed, as all lightning devices now follow the new device interface. (#6420)
Deprecations 👋
The
expand_depthandmax_expansionarguments forqml.transforms.compileandqml.transforms.decompositions.clifford_t_decompositionrespectively have been deprecated. (#6404)Legacy operator arithmetic has been deprecated. This includes
qml.ops.Hamiltonian,qml.operation.Tensor,qml.operation.enable_new_opmath,qml.operation.disable_new_opmath, andqml.operation.convert_to_legacy_H. Note that when new operator arithmetic is enabled,qml.Hamiltonianwill continue to dispatch toqml.ops.LinearCombination; this behaviour is not deprecated. For more information, check out the updated operator troubleshooting page. (#6287) (#6365)qml.pauli.PauliSentence.hamiltonianandqml.pauli.PauliWord.hamiltonianhave been deprecated. Instead, please useqml.pauli.PauliSentence.operationandqml.pauli.PauliWord.operation, respectively. (#6287)qml.pauli.simplify()has been deprecated. Instead, please useqml.simplify(op)orop.simplify(). (#6287)The
qml.BasisStatePreparationtemplate has been deprecated. Instead, useqml.BasisState. (#6021)The
'ancilla'argument forqml.iterative_qpehas been deprecated. Instead, use the'aux_wire'argument. (#6277)qml.shadows.shadow_expvalhas been deprecated. Instead, use theqml.shadow_expvalmeasurement process. (#6277)qml.broadcasthas been deprecated. Please use Pythonforloops instead. (#6277)The
qml.QubitStateVectortemplate has been deprecated. Instead, useqml.StatePrep. (#6172)The
qml.qinfomodule has been deprecated. Please see the respective functions in theqml.mathandqml.measurementsmodules instead. (#5911)Device,QubitDevice, andQutritDevicewill no longer be accessible via top-level import in v0.40. They will still be accessible asqml.devices.LegacyDevice,qml.devices.QubitDevice, andqml.devices.QutritDevicerespectively. (#6238)QNode.gradient_fnhas been deprecated. Please useQNode.diff_methodandQNode.get_gradient_fninstead. (#6244)
Documentation 📝
Updated
qml.spindocumentation. (#6387)Updated links to PennyLane.ai in the documentation to use the latest URL format, which excludes the
.htmlprefix. (#6412)Update
qml.Qubitizationdocumentation based on new decomposition. (#6276)Fixed examples in the documentation of a few optimizers. (#6303) (#6315)
Corrected examples in the documentation of
qml.jacobian. (#6283) (#6315)Fixed spelling in a number of places across the documentation. (#6280)
Add
work_wiresparameter toqml.MultiControlledXdocstring signature. (#6271)Removed ambiguity in error raised by the
PauliRotclass. (#6298)Renamed an incorrectly named test in
test_pow_ops.py. (#6388)Removed outdated Docker description from installation page. (#6487)
Bug fixes 🐛
The wire order for
Snapshot‘s now matches the wire order of the device, rather than the simulation. (#6461)Fixed a bug where
QNSPSAOptimizer,QNGOptimizerandMomentumQNGOptimizercalculate invalid parameter updates if the metric tensor becomes singular. (#6471)The
default.qubitdevice now supports parameter broadcasting withqml.classical_shadowandqml.shadow_expval. (#6301)Fixed unnecessary call of
eigvalsinqml.ops.op_math.decompositions.two_qubit_unitary.pythat was causing an error in VJP. Raises warnings to users if this essentially nondifferentiable module is used. (#6437)Patches the
mathmodule to function with autoray 0.7.0. (#6429)Fixed incorrect differentiation of
PrepSelPrepwhen usingdiff_method="parameter-shift". (#6423)The
validate_device_wirestransform now raises an error if abstract wires are provided. (#6405)Fixed
qml.math.expand_matrixfor qutrit and arbitrary qudit operators. (#6398)MeasurementValuenow raises an error when it is used as a boolean. (#6386)default.qutritnow returns integer samples. (#6385)adjoint_metric_tensornow works with circuits containing state preparation operations. (#6358)quantum_fishernow respects the classical Jacobian of QNodes. (#6350)qml.map_wirescan now be applied to a batch of tapes. (#6295)Fixed float-to-complex casting in various places across PennyLane. (#6260) (#6268)
Fixed a bug where zero-valued JVPs were calculated wrongly in the presence of shot vectors. (#6219)
Fixed
qml.PrepSelPreptemplate to work withtorch. (#6191)Fixed a bug where
qml.equalnow correctly comparesqml.PrepSelPrepoperators. (#6182)The
qml.QSVTtemplate now orders theprojectorwires first and theUAwires second, which is the expected order of the decomposition. (#6212)The
qml.Qubitizationtemplate now orders thecontrolwires first and thehamiltonianwires second, which is the expected according to other templates. (#6229)Fixed a bug where a circuit using the
autogradinterface sometimes returns nested values that are not of theautogradinterface. (#6225)Fixed a bug where a simple circuit with no parameters or only builtin/NumPy arrays as parameters returns autograd tensors. (#6225)
qml.pauli.PauliVSpacenow uses a more stable SVD-based linear independence check to avoid running intoLinAlgError: Singular matrix. This stabilizes the usage ofqml.lie_closure. It also introduces normalization of the basis vector’s internal representation_Mto avoid exploding coefficients. (#6232)Fixed a bug where
csc_dot_productis used during measurement forSum/Hamiltonianthat contains observables that does not define a sparse matrix. (#6278) (#6310)Fixed a bug where
Nonewas added to the wires inqml.PhaseAdder,qml.Adderandqml.OutAdder. (#6360)Fixed a test after updating to the nightly version of Catalyst. (#6362)
Fixed a bug where
CommutingEvolutionwith a trainableHamiltoniancannot be differentiated using parameter shift. (#6372)Fixed a bug where
mitigate_with_zneloses theshotsinformation of the original tape. (#6444)Fixed a bug where
default.tensorraises an error when applyingIdentity/GlobalPhaseon no wires, andPauliRot/MultiRZon a single wire. (#6448)Fixes a bug where applying
qml.ctrlandqml.adjointon an operator type instead of an operator instance results in extra operators in the queue. (#6284)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso, Utkarsh Azad, Oleksandr Borysenko, Astral Cai, Yushao Chen, Isaac De Vlugt, Diksha Dhawan, Lillian M. A. Frederiksen, Pietropaolo Frisoni, Emiliano Godinez, Anthony Hayes, Austin Huang, Soran Jahangiri, Jacob Kitchen, Korbinian Kottmann, Christina Lee, William Maxwell, Erick Ochoa Lopez, Lee J. O’Riordan, Mudit Pandey, Andrija Paurevic, Alex Preciado, Ashish Kanwar Singh, David Wierichs,
Release 0.38.0¶
New features since last release
Registers of wires 🧸
A new function called
qml.registershas been added that lets you seamlessly create registers of wires. (#5957) (#6102)Using registers, it is easier to build large algorithms and circuits by applying gates and operations to predefined collections of wires. With
qml.registers, you can create registers of wires by providing a dictionary whose keys are register names and whose values are the number of wires in each register.>>> wire_reg = qml.registers({"alice": 4, "bob": 3}) >>> wire_reg {'alice': Wires([0, 1, 2, 3]), 'bob': Wires([4, 5, 6])}
The resulting data structure of
qml.registersis a dictionary with the same register names as keys, but the values areqml.wires.Wiresinstances.Nesting registers within other registers can be done by providing a nested dictionary, where the ordering of wire labels is based on the order of appearance and nestedness.
>>> wire_reg = qml.registers({"alice": {"alice1": 1, "alice2": 2}, "bob": {"bob1": 2, "bob2": 1}}) >>> wire_reg {'alice1': Wires([0]), 'alice2': Wires([1, 2]), 'alice': Wires([0, 1, 2]), 'bob1': Wires([3, 4]), 'bob2': Wires([5]), 'bob': Wires([3, 4, 5])}
Since the values of the dictionary are
Wiresinstances, their use within quantum circuits is very similar to that of alistof integers.dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): for w in wire_reg["alice"]: qml.Hadamard(w) for w in wire_reg["bob1"]: qml.RX(0.1967, wires=w) qml.CNOT(wires=[wire_reg["alice1"][0], wire_reg["bob2"][0]]) return [qml.expval(qml.Y(w)) for w in wire_reg["bob1"]] print(qml.draw(circuit)())
0: ──H────────╭●─┤ 1: ──H────────│──┤ 2: ──H────────│──┤ 3: ──RX(0.20)─│──┤ <Y> 4: ──RX(0.20)─│──┤ <Y> 5: ───────────╰X─┤
In tandem with
qml.registers, we’ve also made the following improvements toqml.wires.Wires:Wiresinstances now have a more copy-paste friendly representation when printed. (#5958)>>> from pennylane.wires import Wires >>> w = Wires([1, 2, 3]) >>> w Wires([1, 2, 3])
Python set-based combinations are now supported by
Wires. (#5983)This new feature unlocks the ability to combine
Wiresinstances in the following ways:intersection with
&orintersection():>>> wires1 = Wires([1, 2, 3]) >>> wires2 = Wires([2, 3, 4]) >>> wires1.intersection(wires2) # or wires1 & wires2 Wires([2, 3])
symmetric difference with
^orsymmetric_difference():>>> wires1.symmetric_difference(wires2) # or wires1 ^ wires2 Wires([1, 4])
union with
|orunion():>>> wires1.union(wires2) # or wires1 | wires2 Wires([1, 2, 3, 4])
difference with
-ordifference():>>> wires1.difference(wires2) # or wires1 - wires2 Wires([1])
Quantum arithmetic operations 🧮
Several new operator templates have been added to PennyLane that let you perform quantum arithmetic operations. (#6109) (#6112) (#6121)
qml.Adderperforms in-place modular addition: \(\text{Adder}(k, m)\vert x \rangle = \vert x + k \; \text{mod} \; m\rangle\).qml.PhaseAdderis similar toqml.Adder, but it performs in-place modular addition in the Fourier basis.qml.Multiplierperforms in-place multiplication: \(\text{Multiplier}(k, m)\vert x \rangle = \vert x \times k \; \text{mod} \; m \rangle\).qml.OutAdderperforms out-place modular addition: \(\text{OutAdder}(m)\vert x \rangle \vert y \rangle \vert b \rangle = \vert x \rangle \vert y \rangle \vert b + x + y \; \text{mod} \; m \rangle\).qml.OutMultiplierperforms out-place modular multiplication: \(\text{OutMultiplier}(m)\vert x \rangle \vert y \rangle \vert b \rangle = \vert x \rangle \vert y \rangle \vert b + x \times y \; \text{mod} \; m \rangle\).qml.ModExpperforms modular exponentiation: \(\text{ModExp}(base, m) \vert x \rangle \vert k \rangle = \vert x \rangle \vert k \times base^x \; \text{mod} \; m \rangle\).
Here is a comprehensive example that performs the following calculation:
(2 + 1) * 3 mod 7 = 2(or010in binary).dev = qml.device("default.qubit", shots=1) wire_reg = qml.registers({ "x_wires": 2, # |x>: stores the result of 2 + 1 = 3 "y_wires": 2, # |y>: multiples x by 3 "output_wires": 3, # stores the result of (2 + 1) * 3 m 7 = 2 "work_wires": 2 # for qml.OutMultiplier }) @qml.qnode(dev) def circuit(): # In-place addition qml.BasisEmbedding(2, wires=wire_reg["x_wires"]) qml.Adder(1, x_wires=wire_reg["x_wires"]) # add 1 to wires [0, 1] # Out-place multiplication qml.BasisEmbedding(3, wires=wire_reg["y_wires"]) qml.OutMultiplier( wire_reg["x_wires"], wire_reg["y_wires"], wire_reg["output_wires"], work_wires=wire_reg["work_wires"], mod=7 ) return qml.sample(wires=wire_reg["output_wires"])
>>> circuit() array([0, 1, 0])
Converting noise models from Qiskit ♻️
Convert Qiskit noise models into a PennyLane
NoiseModelwithqml.from_qiskit_noise. (#5996)In the last few releases, we’ve added substantial improvements and new features to the Pennylane-Qiskit plugin. With this release, a new
qml.from_qiskit_noisefunction allows you to convert a Qiskit noise model into a PennyLaneNoiseModel. Here is a simple example with two quantum errors that add two different depolarizing errors based on the presence of different gates in the circuit:import pennylane as qml import qiskit_aer.noise as noise error_1 = noise.depolarizing_error(0.001, 1) # 1-qubit noise error_2 = noise.depolarizing_error(0.01, 2) # 2-qubit noise noise_model = noise.NoiseModel() noise_model.add_all_qubit_quantum_error(error_1, ['rz', 'ry']) noise_model.add_all_qubit_quantum_error(error_2, ['cx'])
>>> qml.from_qiskit_noise(noise_model) NoiseModel({ OpIn(['RZ', 'RY']): QubitChannel(num_kraus=4, num_wires=1) OpIn(['CNOT']): QubitChannel(num_kraus=16, num_wires=2) })
Under the hood, PennyLane converts each quantum error in the Qiskit noise model into an equivalent
qml.QubitChanneloperator with the same canonical Kraus representation. Currently, noise models in PennyLane do not support readout errors. As such, those will be skipped during conversion if they are present in the Qiskit noise model.Make sure to
pip install pennylane-qiskitto access this new feature!
Substantial upgrades to mid-circuit measurements using tree-traversal 🌳
The
"tree-traversal"algorithm for mid-circuit measurements (MCMs) ondefault.qubithas been internally redesigned for better performance. (#5868)In the last release (v0.37), we introduced the tree-traversal MCM method, which was implemented in a recursive way for simplicity. However, this had the unintended consequence of very deep stack calls for circuits with many MCMs, resulting in stack overflows in some cases. With this release, we’ve refactored the implementation of the tree-traversal method into an iterative approach, which solves those inefficiencies when many MCMs are present in a circuit.
The
tree-traversalalgorithm is now compatible with analytic-mode execution (shots=None). (#5868)dev = qml.device("default.qubit") n_qubits = 5 @qml.qnode(dev, mcm_method="tree-traversal") def circuit(): for w in range(n_qubits): qml.Hadamard(w) for w in range(n_qubits - 1): qml.CNOT(wires=[w, w+1]) for w in range(n_qubits): m = qml.measure(w) qml.cond(m == 1, qml.RX)(0.1967 * (w + 1), w) return [qml.expval(qml.Z(w)) for w in range(n_qubits)]
>>> circuit() [tensor(0.00964158, requires_grad=True), tensor(0.03819446, requires_grad=True), tensor(0.08455748, requires_grad=True), tensor(0.14694258, requires_grad=True), tensor(0.2229438, requires_grad=True)]
Improvements 🛠
Creating spin Hamiltonians
Three new functions are now available for creating commonly-used spin Hamiltonians in PennyLane: (#6106) (#6128)
qml.spin.transverse_isingcreates the transverse-field Ising model Hamiltonian.qml.spin.heisenbergcreates the Heisenberg model Hamiltonian.qml.spin.fermi_hubbardcreates the Fermi-Hubbard model Hamiltonian.
Each Hamiltonian can be instantiated by specifying a
lattice, the number of unit cells,n_cells, and the Hamiltonian parameters as keyword arguments. Here is an example with the transverse-field Ising model:>>> tfim_ham = qml.spin.transverse_ising(lattice="square", n_cells=[2, 2], coupling=0.5, h=0.2) >>> tfim_ham ( -0.5 * (Z(0) @ Z(1)) + -0.5 * (Z(0) @ Z(2)) + -0.5 * (Z(1) @ Z(3)) + -0.5 * (Z(2) @ Z(3)) + -0.2 * X(0) + -0.2 * X(1) + -0.2 * X(2) + -0.2 * X(3) )
The resulting object is a
qml.Hamiltonianinstance, making it easy to use in circuits like the following.dev = qml.device("default.qubit", shots=1) @qml.qnode(dev) def circuit(): return qml.expval(tfim_ham)
>>> circuit() -2.0
More features will be added to the
qml.spinmodule in the coming releases, so stay tuned!
A Prep-Select-Prep template
A new template called
qml.PrepSelPrephas been added that implements a block-encoding of a linear combination of unitaries. (#5756) (#5987)This operator acts as a nice wrapper for having to perform
qml.StatePrep,qml.Select, andqml.adjoint(qml.StatePrep)in succession, which is quite common in many quantum algorithms (e.g., LCU and block encoding). Here is an example showing the equivalence between usingqml.PrepSelPrepandqml.StatePrep,qml.Select, andqml.adjoint(qml.StatePrep).coeffs = [0.3, 0.1] alphas = (np.sqrt(coeffs) / np.linalg.norm(np.sqrt(coeffs))) unitaries = [qml.X(2), qml.Z(2)] lcu = qml.dot(coeffs, unitaries) control = [0, 1] def prep_sel_prep(alphas, unitaries): qml.StatePrep(alphas, wires=control, pad_with=0) qml.Select(unitaries, control=control) qml.adjoint(qml.StatePrep)(alphas, wires=control, pad_with=0) @qml.qnode(qml.device("default.qubit")) def circuit(lcu, control, alphas, unitaries): qml.PrepSelPrep(lcu, control) qml.adjoint(prep_sel_prep)(alphas, unitaries) return qml.state()
>>> import numpy as np >>> np.round(circuit(lcu, control, alphas, unitaries), decimals=2) tensor([1.+0.j -0.+0.j -0.+0.j -0.+0.j 0.+0.j 0.+0.j 0.+0.j 0.+0.j], requires_grad=True)
QChem improvements
Molecules and Hamiltonians can now be constructed for all the elements present in the periodic table. (#5821)
This new feature is made possible by integrating with the basis-set-exchange package. If loading basis sets from
basis-set-exchangeis needed for your molecule, make sure that youpip install basis-set-exchangeand setload_data=True.symbols = ['Ti', 'Ti'] geometry = np.array([[0.0, 0.0, -1.1967], [0.0, 0.0, 1.1967]], requires_grad=True) mol = qml.qchem.Molecule(symbols, geometry, load_data=True)
>>> mol.n_electrons 44
qml.UCCSDnow accepts an additional optional argument,n_repeats, which defines the number of times the UCCSD template is repeated. This can improve the accuracy of the template by reducing the Trotter error, but would result in deeper circuits. (#5801)The
qml.qchem.qubit_observablefunction has been modified to return an ascending wire order for molecular Hamiltonians. (#5950)A new method called
to_mathas been added to theqml.FermiWordandqml.FermiSentenceclasses, which allows for computing the matrix representation of these Fermi operators. (#5920)
Improvements to operators
qml.GlobalPhasenow supports parameter broadcasting. (#5923)qml.Hermitiannow has acompute_decompositionmethod. (#6062)The implementation of
qml.PhaseShift,qml.S, andqml.Thas been improved, resulting in faster circuit execution times. (#5876)The
qml.CNOToperator no longer decomposes into itself. Instead, it raises aqml.DecompositionUndefinedError. (#6039)
Mid-circuit measurements
The
qml.dynamic_one_shottransform now supports circuits using the"tensorflow"interface. (#5973)If the conditional does not include a mid-circuit measurement, then
qml.condwill automatically evaluate conditionals using standard Python control flow. (#6016)This allows
qml.condto be used to represent a wider range of conditionals:dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): c = qml.cond(x > 2.7, qml.RX, qml.RZ) c(x, wires=0) return qml.probs(wires=0)
>>> print(qml.draw(circuit)(3.8)) 0: ──RX(3.80)─┤ Probs >>> print(qml.draw(circuit)(0.54)) 0: ──RZ(0.54)─┤ Probs
Transforms
qml.transforms.single_qubit_fusionandqml.transforms.merge_rotationsnow respect global phases. (#6031)A new transform called
qml.transforms.diagonalize_measurementshas been added. This transform converts measurements to the computational basis by applying the relevant diagonalizing gates. It can be set to diagonalize only a subset of the base observables{qml.X, qml.Y, qml.Z, qml.Hadamard}. (#5829)A new transform called
split_to_single_termshas been added. This transform splits expectation values of sums into multiple single-term measurements on a single tape, providing better support for simulators that can handle non-commuting observables but don’t natively support multi-term observables. (#5884)New functionality has been added to natively support exponential extrapolation when using
qml.transforms.mitigate_with_zne. This allows users to have more control over the error mitigation protocol without needing to add further dependencies. (#5972)
Capturing and representing hybrid programs
qml.for_loopnow supportsrange-like syntax with defaultstep=1. (#6068)Applying
adjointandctrlto a quantum function can now be captured into plxpr. Furthermore, theqml.condfunction can be captured into plxpr. (#5966) (#5967) (#5999) (#6058)During experimental program capture, functions that accept and/or return
pytreestructures can now be handled in theqml.QNodecall,qml.cond,qml.for_loopandqml.while_loop. (#6081)During experimental program capture, QNodes can now use closure variables. (#6052)
Mid-circuit measurements can now be captured with
qml.captureenabled. (#6015)qml.for_loopcan now be captured into plxpr. (#6041) (#6064)qml.for_loopandqml.while_loopnow fall back to standard Python control flow if@qjitis not present, allowing the same code to work with and without@qjitwithout any rewrites. (#6014)dev = qml.device("lightning.qubit", wires=3) @qml.qnode(dev) def circuit(x, n): @qml.for_loop(0, n, 1) def init_state(i): qml.Hadamard(wires=i) init_state() @qml.for_loop(0, n, 1) def apply_operations(i, x): qml.RX(x, wires=i) @qml.for_loop(i + 1, n, 1) def inner(j): qml.CRY(x**2, [i, j]) inner() return jnp.sin(x) apply_operations(x) return qml.probs()
>>> print(qml.draw(circuit)(0.5, 3)) 0: ──H──RX(0.50)─╭●────────╭●──────────────────────────────────────┤ Probs 1: ──H───────────╰RY(0.25)─│──────────RX(0.48)─╭●──────────────────┤ Probs 2: ──H─────────────────────╰RY(0.25)───────────╰RY(0.23)──RX(0.46)─┤ Probs >>> circuit(0.5, 3) array([0.125 , 0.125 , 0.09949758, 0.15050242, 0.07594666, 0.11917543, 0.08942104, 0.21545687]) >>> qml.qjit(circuit)(0.5, 3) Array([0.125 , 0.125 , 0.09949758, 0.15050242, 0.07594666, 0.11917543, 0.08942104, 0.21545687], dtype=float64)
Community contributions 🥳
Fixed a bug in
qml.ThermalRelaxationErrorwhere there was a typo fromtqtotg. (#5988)Readout error has been added using parameters
readout_relaxation_probsandreadout_misclassification_probson thedefault.qutrit.mixeddevice. These parameters add aqml.QutritAmplitudeDampingand aqml.TritFlipchannel, respectively, after measurement diagonalization. The amplitude damping error represents the potential for relaxation to occur during longer measurements. The trit flip error represents misclassification during readout. (#5842)qml.ops.qubit.BasisStateProjectornow has acompute_sparse_matrixmethod that computes the sparse CSR matrix representation of the projector onto the given basis state. (#5790)
Other improvements
qml.pauli.group_observablesnow usesrustworkxcolouring algorithms to solve the Minimum Clique Cover problem, resulting in orders of magnitude performance improvements. (#6043)This adds two new options for the
methodargument:dsatur(degree of saturation) andgis(independent set). In addition, the creation of the adjacency matrix now takes advantage of the symplectic representation of the Pauli observables.Additionally, a new function called
qml.pauli.compute_partition_indiceshas been added to calculate the indices from the partitioned observables more efficiently. These changes improve the wall time ofqml.LinearCombination.compute_groupingand thegrouping_type='qwc'by orders of magnitude.qml.countsmeasurements withall_outcomes=Truecan now be used with JAX jitting. Additionally, measurements broadcasted across all available wires (e.g.,qml.probs()) can now be used with JAX jit and devices that allow dynamic numbers of wires (only'default.qubit'currently). (#6108)qml.ops.op_math.ctrl_decomp_zyzcan now decompose special unitaries with multiple control wires. (#6042)A new method called
process_density_matrixhas been added to theProbabilityMPandDensityMatrixMPmeasurement processes, allowing for more efficient handling of quantum density matrices, particularly with batch processing support. This method simplifies the calculation of probabilities from quantum states represented as density matrices. (#5830)SProd.termsnow flattens out the terms if the base is a multi-term observable. (#5885)qml.QNGOptimizernow supports cost functions with multiple arguments, updating each argument independently. (#5926)semantic_versionhas been removed from the list of required packages in PennyLane. (#5836)qml.devices.LegacyDeviceFacadehas been added to map the legacy devices to the new device interface, making it easier for developers to develop legacy devices. (#5927)StateMP.process_statenow defines rules incast_to_complexfor complex casting, avoiding a superfluous statevector copy in PennyLane-Lightning simulations. (#5995)QuantumScript.hashis now cached, leading to performance improvements. (#5919)Observable validation for
default.qubitis now based on execution mode (analytic vs. finite shots) and measurement type (sample measurement vs. state measurement). This improves our error handling when, for example, non-hermitian operators are given toqml.expval. (#5890)A new
is_leafparameter has been added to the functionflattenin theqml.pytreesmodule. This is to allow for node flattening to be stopped for any node where theis_leafoptional argument evaluates to beingTrue. (#6107)A progress bar has been added to
qml.data.load()when downloading a dataset. (#5560)Upgraded and simplified
StatePrepandAmplitudeEmbeddingtemplates. (#6034) (#6170)Upgraded and simplified
BasisStateandBasisEmbeddingtemplates. (#6021)
Breaking changes 💔
MeasurementProcess.shape(shots: Shots, device:Device)is nowMeasurementProcess.shape(shots: Optional[int], num_device_wires:int = 0). This has been done to allow for jitting when a measurement is broadcasted across all available wires, but the device does not specify wires. (#6108)If the shape of a probability measurement is affected by a
Device.cutoffproperty, it will no longer work with jitting. (#6108)qml.GlobalPhaseis considered non-differentiable with tape transforms. As a consequence,qml.gradients.finite_diffandqml.gradients.spsa_gradno longer support differentiatingqml.GlobalPhasewith state-based outputs. (#5620)The
CircuitGraph.graphrustworkxgraph now stores indices into the circuit as the node labels, instead of the operator/ measurement itself. This allows the same operator to occur multiple times in the circuit. (#5907)The
queue_idxattribute has been removed from theOperator,CompositeOp, andSymbolicOpclasses. (#6005)qml.from_qasmno longer removes measurements from the QASM code. Usemeasurements=[]to remove measurements from the original circuit. (#5982)qml.transforms.map_batch_transformhas been removed, since transforms can be applied directly to a batch of tapes. Seeqml.transformfor more information. (#5981)QuantumScript.interfacehas been removed. (#5980)
Deprecations 👋
The
decomp_depthargument inqml.devicehas been deprecated. (#6026)The
max_expansionargument inqml.QNodehas been deprecated. (#6026)The
expansion_strategyattributeqml.QNodehas been deprecated. (#5989)The
expansion_strategyargument has been deprecated in all ofqml.draw,qml.draw_mpl, andqml.specs. Thelevelargument should be used instead. (#5989)Operator.expandhas been deprecated. Users should simply useqml.tape.QuantumScript(op.decomposition())for equivalent behaviour. (#5994)qml.transforms.sum_expandandqml.transforms.hamiltonian_expandhave been deprecated. Users should instead useqml.transforms.split_non_commutingfor equivalent behaviour. (#6003)The
expand_fnargument inqml.executehas been deprecated. Instead, please create aqml.transforms.core.TransformProgramwith the desired preprocessing and pass it to thetransform_programargument ofqml.execute. (#5984)The
max_expansionargument inqml.executehas been deprecated. Instead, please useqml.devices.preprocess.decomposewith the desired expansion level, add it to aqml.transforms.core.TransformProgramand pass it to thetransform_programargument ofqml.execute. (#5984)The
override_shotsargument inqml.executehas been deprecated. Instead, please add the shots to theQuantumTapes to be executed. (#5984)The
device_batch_transformargument inqml.executehas been deprecated. Instead, please create aqml.transforms.core.TransformProgramwith the desired preprocessing and pass it to thetransform_programargument ofqml.execute. (#5984)qml.qinfo.classical_fisherandqml.qinfo.quantum_fisherhave been deprecated. Instead, useqml.gradients.classical_fisherandqml.gradients.quantum_fisher. (#5985)The legacy devices
default.qubit.{autograd,torch,tf,jax,legacy}have been deprecated. Instead, usedefault.qubit, as it now supports backpropagation through the several backends. (#5997)The logic for internally switching a device for a different backpropagation compatible device is now deprecated, as it was in place for the deprecated
default.qubit.legacy. (#6032)
Documentation 📝
The docstring for
qml.qinfo.quantum_fisher, regarding the internally used functions and potentially required auxiliary wires, has been improved. (#6074)The docstring for
QuantumScript.expandandqml.tape.tape.expand_tapehas been improved. (#5974)
Bug fixes 🐛
The sparse matrix can now be computed for a product operator when one operand is a
GlobalPhaseon no wires. (#6197)For
default.qubit, JAX is now used for sampling whenever the state is a JAX array. This fixes normalization issues that can occur when the state uses 32-bit precision. (#6190)Fix Pytree serialization of operators with empty shot vectors (#6155)
Fixes an error in the
dynamic_one_shottransform when used with sampling a single shot. (#6149)qml.transforms.pattern_matching_optimizationnow preserves the tape measurements. (#6153)qml.transforms.broadcast_expandno longer squeezes out batch sizes of size 1, as a batch size of 1 is still a batch size. (#6147)Catalyst replaced
argnumwithargnumsin gradient related functions, therefore we updated the Catalyst calls to those functions in PennyLane. (#6117)fuse_rot_anglesnow returns NaN instead of incorrect derivatives at singular points. (#6031)qml.GlobalPhaseandqml.Identitycan now be captured with plxpr when acting on no wires. (#6060)Fixed
jax.gradandjax.jitto work forqml.AmplitudeEmbedding,qml.StatePrepandqml.MottonenStatePreparation. (#5620)Fixed a bug in
qml.centerthat omitted elements from the center if they were linear combinations of input elements. (#6049)Fix a bug where the global phase returned by
one_qubit_decompositiongained a broadcasting dimension. (#5923)Fixed a bug in
qml.SPSAOptimizerthat ignored keyword arguments in the objective function. (#6027)Fixed
dynamic_one_shotfor use with devices using the old device API, sinceoverride_shotswas deprecated. (#6024)CircuitGraphcan now handle circuits with the same operation instance occuring multiple times. (#5907)qml.QSVThas been updated to store wire order correctly. (#5959)qml.devices.qubit.measure_with_samplesnow returns the correct result if the provided measurements contain a sum of operators acting on the same wire. (#5978)qml.AmplitudeEmbeddinghas better support for features using low precision integer data types. (#5969)qml.BasisStateandqml.BasisEmbeddingnow works with jax.jit,lightning.qubit, and give the correct decomposition. (#6021)Jacobian shape has been fixed for measurements with dimension in
qml.gradients.vjp.compute_vjp_single. (5986)qml.lie_closurenow works with sums of Paulis. (#6023)Workflows that parameterize the coefficients of
qml.expare now jit-compatible. (#6082)Fixed a bug where
CompositeOp.overlapping_opschanges the original ordering of operators, causing an incorrect matrix to be generated forProdwithSumas operands. (#6091)qml.qsvtnow works with “Wx” convention and any number of angles. (#6105)Basis set data from the Basis Set Exchange library can now be loaded for elements with
SPD-type orbitals. (#6159)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Tarun Kumar Allamsetty, Guillermo Alonso, Ali Asadi, Utkarsh Azad, Tonmoy T. Bhattacharya, Gabriel Bottrill, Jack Brown, Ahmed Darwish, Astral Cai, Yushao Chen, Ahmed Darwish, Diksha Dhawan Maja Franz, Lillian M. A. Frederiksen, Pietropaolo Frisoni, Emiliano Godinez, Austin Huang, Renke Huang, Josh Izaac, Soran Jahangiri, Korbinian Kottmann, Christina Lee, Jorge Martinez de Lejarza, William Maxwell, Vincent Michaud-Rioux, Anurav Modak, Mudit Pandey, Andrija Paurevic, Erik Schultheis, nate stemen, David Wierichs,
Release 0.37.0¶
New features since last release
Execute wide circuits with Default Tensor 🔗
A new
default.tensordevice is now available for performing tensor network and matrix product state simulations of quantum circuits using the quimb backend. (#5699) (#5744) (#5786) (#5795)Either method can be selected when instantiating the
default.tensordevice by setting themethodkeyword argument to"tn"(tensor network) or"mps"(matrix product state).There are several templates in PennyLane that are tensor-network focused, which are excellent candidates for the
"tn"method fordefault.tensor. The following example shows how a circuit comprising gates in a tree tensor network architecture can be efficiently simulated usingmethod="tn".import pennylane as qml n_wires = 16 dev = qml.device("default.tensor", method="tn") def block(weights, wires): qml.CNOT(wires=[wires[0], wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_block_wires = 2 n_params_block = 2 n_blocks = qml.TTN.get_n_blocks(range(n_wires), n_block_wires) template_weights = [[0.1, -0.3]] * n_blocks @qml.qnode(dev) def circuit(template_weights): for i in range(n_wires): qml.Hadamard(i) qml.TTN(range(n_wires), n_block_wires, block, n_params_block, template_weights) return qml.expval(qml.Z(n_wires - 1))
>>> circuit(template_weights) 0.3839174759751649
For matrix product state simulations (
method="mps"), we can make the execution be approximate by settingmax_bond_dim(see the device’s documentation for more details). The maximum bond dimension has implications for the speed of the simulation and lets us control the degree of the approximation, as shown in the following example. First, set up the circuit:import numpy as np n_layers = 10 n_wires = 10 initial_shape, weights_shape = qml.SimplifiedTwoDesign.shape(n_layers, n_wires) np.random.seed(1967) initial_layer_weights = np.random.random(initial_shape) weights = np.random.random(weights_shape) def f(): qml.SimplifiedTwoDesign(initial_layer_weights, weights, range(n_wires)) return qml.expval(qml.Z(0))
The
default.tensordevice is instantiated with amax_bond_dimvalue:dev_dq = qml.device("default.qubit") value_dq = qml.QNode(f, dev_dq)() dev_mps = qml.device("default.tensor", max_bond_dim=5) value_mps = qml.QNode(f, dev_mps)()
With this bond dimension, the expectation values calculated for
default.qubitanddefault.tensorare different:>>> np.abs(value_dq - value_mps) tensor(0.0253213, requires_grad=True)
Learn more about
default.tensorand how to configure it by visiting the how-to guide.
Add noise models to your quantum circuits 📺
Support for building noise models and applying them to a quantum circuit has been added via the
NoiseModelclass and anadd_noisetransform. (#5674) (#5684) (#5718)Under the hood, PennyLane’s approach to noise models is insertion-based, meaning that noise is included by inserting additional operators (gates or channels) that describe the noise into the quantum circuit. Creating a
NoiseModelboils down to defining Boolean conditions under which specific noisy operations are inserted. There are several ways to specify conditions for adding noisy operations:qml.noise.op_eq(op): if the operatoropis encountered in the circuit, add noise.qml.noise.op_in(ops): if any operators inopsare encountered in the circuit, add noise.qml.noise.wires_eq(wires): if an operator is applied towires, add noise.qml.noise.wires_in(wires): if an operator is applied to any wire inwires, add noise.custom noise conditions: custom conditions can be defined as functions decorated with
qml.BooleanFnthat return a Boolean value. For example, the following function will insert noise if aqml.RYoperator is encountered with an angle of rotation that is less than0.5:@qml.BooleanFn def c0(op): return isinstance(op, qml.RY) and op.parameters[0] < 0.5
Conditions can also be combined together with
&,and,|, etc. Once the conditions under which noise is to be inserted have been stated, we can specify exactly what noise is inserted with the following:qml.noise.partial_wires(op): insertopon the wires that are specified by the condition that triggers adding this noisecustom noise operations: custom noise can be specified by defining a standard quantum function like below.
def n0(op, **kwargs): qml.RY(op.parameters[0] * 0.05, wires=op.wires)
With that, we can create a
qml.NoiseModelobject whose argument must be a dictionary mapping conditions to noise:c1 = qml.noise.op_eq(qml.X) & qml.noise.wires_in([0, 1]) n1 = qml.noise.partial_wires(qml.AmplitudeDamping, 0.4) noise_model = qml.NoiseModel({c0: n0, c1: n1})
>>> noise_model NoiseModel({ BooleanFn(c0): n0 OpEq(PauliX) | WiresIn([0, 1]): AmplitudeDamping(gamma=0.4) })
The noise model created can then be added to a QNode with
qml.add_noise:dev = qml.device("lightning.qubit", wires=3) @qml.qnode(dev) def circuit(): qml.Y(0) qml.CNOT([0, 1]) qml.RY(0.3, wires=2) # triggers c0 qml.X(1) # triggers c1 return qml.state()
>>> print(qml.draw(circuit)()) 0: ──Y────────╭●────┤ State 1: ───────────╰X──X─┤ State 2: ──RY(0.30)───────┤ State >>> circuit = qml.add_noise(circuit, noise_model) >>> print(qml.draw(circuit)()) 0: ──Y────────╭●───────────────────────────────────┤ State 1: ───────────╰X─────────X──AmplitudeDamping(0.40)─┤ State 2: ──RY(0.30)──RY(0.01)────────────────────────────┤ State
If more than one transform is applied to a QNode, control over when/where the
add_noisetransform is applied in relation to the other transforms can be specified with thelevelkeyword argument. By default,add_noiseis applied after all the transforms that have been manually applied to the QNode until that point. To learn more about this new functionality, check out our noise module documentation and keep your eyes peeled for an in-depth demo!
Catch bugs with the PennyLane debugger 🚫🐞
The new PennyLane quantum debugger allows pausing simulation via the
qml.breakpoint()command and provides tools for analyzing quantum circuits during execution. (#5680) (#5749) (#5789)This includes monitoring the circuit via measurements using
qml.debug_state(),qml.debug_probs(),qml.debug_expval(), andqml.debug_tape(), stepping through the operations in a quantum circuit, and interactively adding operations during execution.Including
qml.breakpoint()in a circuit will cause the simulation to pause during execution and bring up the interactive console. For example, consider the following code in a Python file calledscript.py:@qml.qnode(qml.device('default.qubit', wires=(0,1,2))) def circuit(x): qml.Hadamard(wires=0) qml.CNOT(wires=(0,2)) qml.breakpoint() qml.RX(x, wires=1) qml.RY(x, wires=2) qml.breakpoint() return qml.sample() circuit(1.2345)
Upon executing
script.py, the simulation pauses at the first breakpoint:> /Users/your/path/to/script.py(8)circuit() -> qml.RX(x, wires=1) (pldb):
While debugging, we can access circuit information. For example,
qml.debug_tape()returns the tape of the circuit, giving access to its operations and drawing:[pldb] tape = qml.debug_tape() [pldb] print(tape.draw(wire_order=[0,1,2])) 0: ──H─╭●─┤ 2: ────╰X─┤ [pldb] tape.operations [Hadamard(wires=[0]), CNOT(wires=[0, 2])]
While
qml.debug_state()is equivalent toqml.state()and gives the current state:[pldb] print(qml.debug_state()) [0.70710678+0.j 0. +0.j 0. +0.j 0. +0.j 1. +0.j 0.70710678+0.j 0. +0.j 0. +0.j]
Other debugger functions like
qml.debug_probs()andqml.debug_expval()also function like their simulation counterparts (qml.probsandqml.expval, respectively) and are described in more detail in the debugger documentationAdditionally, standard debugging commands are available to navigate through code, including
list,longlist,next,continue, andquit, as described in the debugging documentation.Finally, to modify a circuit mid-run, simply call the desired PennyLane operations:
[pldb] qml.CNOT(wires=(0,2)) CNOT(wires=[0, 2]) [pldb] print(qml.debug_tape().draw(wire_order=[0,1,2])) 0: ──H─╭●─╭●─┤ 2: ────╰X─╰X─┤
Stay tuned for an in-depth demonstration on using this feature with real-world examples!
Convert between OpenFermion and PennyLane 🤝
Two new functions called
qml.from_openfermionandqml.to_openfermionare now available to convert between OpenFermion and PennyLane objects. This includes both fermionic and qubit operators. (#5773) (#5808) (#5881)For fermionic operators:
>>> import openfermion >>> of_fermionic = openfermion.FermionOperator('0^ 2') >>> type(of_fermionic) <class 'openfermion.ops.operators.fermion_operator.FermionOperator'> >>> pl_fermionic = qml.from_openfermion(of_fermionic) >>> type(pl_fermionic) <class 'pennylane.fermi.fermionic.FermiWord'> >>> print(pl_fermionic) a⁺(0) a(2)
And for qubit operators:
>>> of_qubit = 0.5 * openfermion.QubitOperator('X0 X5') >>> pl_qubit = qml.from_openfermion(of_qubit) >>> print(pl_qubit) 0.5 * (X(0) @ X(5))
Better control over when drawing and specs take place 🎚️
It is now possible to control the stage at which
qml.draw,qml.draw_mpl, andqml.specsoccur within a QNode’s transform program. (#5855) (#5781)Consider the following circuit which has multiple transforms applied:
@qml.transforms.split_non_commuting @qml.transforms.cancel_inverses @qml.transforms.merge_rotations @qml.qnode(qml.device("default.qubit")) def f(): qml.Hadamard(0) qml.Y(0) qml.RX(0.4, 0) qml.RX(-0.4, 0) qml.Y(0) return qml.expval(qml.X(0) + 2 * qml.Y(0))
We can specify a
levelvalue when usingqml.draw():>>> print(qml.draw(f, level=0)()) # input program 0: ──H──Y──RX(0.40)──RX(-0.40)──Y─┤ <X+(2.00*Y)> >>> print(qml.draw(f, level=1)()) # rotations merged 0: ──H──Y──Y─┤ <X+(2.00*Y)> >>> print(qml.draw(f, level=2)()) # inverses cancelled 0: ──H─┤ <X+(2.00*Y)> >>> print(qml.draw(f, level=3)()) # Hamiltonian expanded 0: ──H─┤ <X> 0: ──H─┤ <Y>
The qml.workflow.get_transform_program function can be used to see the full transform program.
>>> qml.workflow.get_transform_program(f) TransformProgram(merge_rotations, cancel_inverses, split_non_commuting, validate_device_wires, mid_circuit_measurements, decompose, validate_measurements, validate_observables, no_sampling)
Note that additional transforms can be added automatically from device preprocessing or gradient calculations. Rather than providing an integer value to
level, it is possible to target the"user","gradient"or"device"stages:n_wires = 3 x = np.random.random((2, n_wires)) @qml.qnode(qml.device("default.qubit")) def f(): qml.BasicEntanglerLayers(x, range(n_wires)) return qml.expval(qml.X(0))
>>> print(qml.draw(f, level="device")()) 0: ──RX(0.28)─╭●────╭X──RX(0.70)─╭●────╭X─┤ <X> 1: ──RX(0.52)─╰X─╭●─│───RX(0.65)─╰X─╭●─│──┤ 2: ──RX(0.00)────╰X─╰●──RX(0.03)────╰X─╰●─┤
Improvements 🛠
Community contributions, including UnitaryHACK 💛
default.cliffordnow supports arbitrary state-based measurements withqml.Snapshot. (#5794)qml.equalnow properly handlesPow,Adjoint,Exp, andSProdoperators as arguments across different interfaces and tolerances with the addition of four new keyword arguments:check_interface,check_trainability,atolandrtol. (#5668)The implementation for
qml.assert_equalhas been updated forOperator,Controlled,Adjoint,Pow,Exp,SProd,ControlledSequence,Prod,Sum,TensorandHamiltonianinstances. (#5780) (#5877)qml.from_qasmnow supports the ability to convert mid-circuit measurements fromOpenQASM 2code, and it can now also take an optional argument to specify a list of measurements to be performed at the end of the circuit, just likeqml.from_qiskit. (#5818)Four new operators have been added for simulating noise on the
default.qutrit.mixeddevice: (#5502) (#5793) (#5503) (#5757) (#5799) (#5784)qml.QutritDepolarizingChannel: a channel that adds depolarizing noise.qml.QutritChannel: enables the specification of noise using a collection of (3x3) Kraus matrices.qml.QutritAmplitudeDamping: a channel that adds noise processes modelled by amplitude damping.qml.TritFlip: a channel that adds trit flip errors, such as misclassification.
Faster and more flexible mid-circuit measurements
The
default.qubitdevice supports a depth-first tree-traversal algorithm to accelerate native mid-circuit measurement execution. Accessible through the QNode argumentmcm_method="tree-traversal", this new implementation supports classical control, collecting statistics, and post-selection, along with all measurements enabled withqml.dynamic_one_shot. More information about this new mid-circuit measurement method can be found on our measurement documentation page. (#5180)qml.QNodeand the@qml.qnodedecorator now accept two new keyword arguments:postselect_modeandmcm_method. These keyword arguments can be used to configure how the device should behave when running circuits with mid-circuit measurements. (#5679) (#5833) (#5850)postselect_mode="hw-like"indicates to devices to discard invalid shots when postselecting mid-circuit measurements. Usepostselect_mode="fill-shots"to unconditionally sample the postselected value, thus making all samples valid. This is equivalent to sampling until the number of valid samples matches the total number of shots.mcm_methodwill indicate which strategy to use for running circuits with mid-circuit measurements. Usemcm_method="deferred"to use the deferred measurements principle, ormcm_method="one-shot"to execute once for each shot. Ifqml.qjitis being used (the Catalyst compiler),mcm_method="single-branch-statistics"is also available. Using this method, a single branch of the execution tree will be randomly explored.
The
dynamic_one_shottransform received a few improvements:When using
defer_measurementswith postselection, operations that will never be active due to the postselected state are skipped in the transformed quantum circuit. In addition, postselected controls are skipped, as they are evaluated when the transform is applied. This optimization feature can be turned off by settingreduce_postselected=False. (#5558)Consider a simple circuit with three mid-circuit measurements, two of which are postselecting, and a single gate conditioned on those measurements:
@qml.qnode(qml.device("default.qubit")) def node(x): qml.RX(x, 0) qml.RX(x, 1) qml.RX(x, 2) mcm0 = qml.measure(0, postselect=0, reset=False) mcm1 = qml.measure(1, postselect=None, reset=True) mcm2 = qml.measure(2, postselect=1, reset=False) qml.cond(mcm0 + mcm1 + mcm2 == 1, qml.RX)(0.5, 3) return qml.expval(qml.Z(0) @ qml.Z(3))
Without the new optimization, we obtain three gates, each controlled on the three measured qubits. They correspond to the combinations of controls that satisfy the condition
mcm0 + mcm1 + mcm2 == 1:>>> print(qml.draw(qml.defer_measurements(node, reduce_postselected=False))(0.6)) 0: ──RX(0.60)──|0⟩⟨0|─╭●─────────────────────────────────────────────┤ ╭<Z@Z> 1: ──RX(0.60)─────────│──╭●─╭X───────────────────────────────────────┤ │ 2: ──RX(0.60)─────────│──│──│───|1⟩⟨1|─╭○────────╭○────────╭●────────┤ │ 3: ───────────────────│──│──│──────────├RX(0.50)─├RX(0.50)─├RX(0.50)─┤ ╰<Z@Z> 4: ───────────────────╰X─│──│──────────├○────────├●────────├○────────┤ 5: ──────────────────────╰X─╰●─────────╰●────────╰○────────╰○────────┤
If we do not explicitly deactivate the optimization, we obtain a much simpler circuit:
>>> print(qml.draw(qml.defer_measurements(node))(0.6)) 0: ──RX(0.60)──|0⟩⟨0|─╭●─────────────────┤ ╭<Z@Z> 1: ──RX(0.60)─────────│──╭●─╭X───────────┤ │ 2: ──RX(0.60)─────────│──│──│───|1⟩⟨1|───┤ │ 3: ───────────────────│──│──│──╭RX(0.50)─┤ ╰<Z@Z> 4: ───────────────────╰X─│──│──│─────────┤ 5: ──────────────────────╰X─╰●─╰○────────┤
There is only one controlled gate with only one control wire.
Mid-circuit measurement tests have been streamlined and refactored, removing most end-to-end tests from the native MCM test file, but keeping one that validates multiple mid-circuit measurements with any allowed return and interface end-to-end tests. (#5787)
Access to QROM
The QROM algorithm is now available in PennyLane with
qml.QROM. This template allows you to enter classical data in the form of bitstrings. (#5688)bitstrings = ["010", "111", "110", "000"] dev = qml.device("default.qubit", shots = 1) @qml.qnode(dev) def circuit(): qml.BasisEmbedding(2, wires = [0,1]) qml.QROM(bitstrings = bitstrings, control_wires = [0,1], target_wires = [2,3,4], work_wires = [5,6,7]) return qml.sample(wires = [2,3,4])
>>> print(circuit()) [1 1 0]
Capturing and representing hybrid programs
A number of templates have been updated to be valid PyTrees and PennyLane operations. (#5698)
PennyLane operators, measurements, and QNodes can now automatically be captured as instructions in JAXPR. (#5564) (#5511) (#5708) (#5523) (#5686) (#5889)
The
qml.PyTreesmodule now hasflattenandunflattenmethods for serializing PyTrees. (#5701)qml.samplecan now be used on Boolean values representing mid-circuit measurement results in traced quantum functions. This feature is used with Catalyst to enable the patternm = measure(0); qml.sample(m). (#5673)
Quantum chemistry
The
qml.qchem.Moleculeobject received a few improvements:The
qml.qchem.molecular_hamiltonianfunction now supports parity and Bravyi-Kitaev mappings. (#5657)qml.qchem.molecular_dipolefunction has been added for calculating the dipole operator using the"dhf"and"openfermion"backends. (#5764)The qchem module now has dedicated functions for calling the
pyscfandopenfermionbackends and themolecular_hamiltonianandmolecular_dipolefunctions have been moved tohamiltoniananddipolemodules. (#5553) (#5863)More fermionic-to-qubit tests have been added to cover cases when the mapped operator is different for various mapping schemes. (#5873)
Easier development
Logging now allows for an easier opt-in across the stack and support has been extended to Catalyst. (#5528)
Three new Pytest markers have been added for easier management of our test suite:
unit,integrationandsystem. (#5517)
Other improvements
qml.MultiControlledXcan now be decomposed even when nowork_wiresare provided. The implementation returns \(\mathcal{O}(\mbox{len(control wires)}^2)\) operations and is applicable for any multi-controlled unitary gate. This decomposition is provided in arXiv:quant-ph/9503016. (#5735)A new function called
expectation_valuehas been added toqml.mathto calculate the expectation value of a matrix for pure states. (#4484)>>> state_vector = [1/np.sqrt(2), 0, 1/np.sqrt(2), 0] >>> operator_matrix = qml.matrix(qml.PauliZ(0), wire_order=[0,1]) >>> qml.math.expectation_value(operator_matrix, state_vector) tensor(-2.23711432e-17+0.j, requires_grad=True)
param_shiftwith thebroadcast=Trueoption now supports shot vectors and multiple measurements. (#5667)qml.TrotterProductis now compatible with resource tracking by inheriting fromResourcesOperation. (#5680)packagingis now a required package in PennyLane. (#5769)qml.ctrlnow works with tuple-valuedcontrol_valueswhen applied to any already controlled operation. (#5725)The sorting order of parameter-shift terms is now guaranteed to resolve ties in the absolute value with the sign of the shifts. (#5582)
qml.transforms.split_non_commutingcan now handle circuits containing measurements of multi-term observables. (#5729) (#5838) (#5828) (#5869) (#5939) (#5945)qml.devices.LegacyDeviceis now an alias forqml.Device, so it is easier to distinguish it fromqml.devices.Device, which follows the new device API. (#5581)The
dtypeforeigvalsofX,Y,ZandHadamardis changed frominttofloat, making them consistent with the other observables. Thedtypeof the returned values when sampling these observables (e.g.qml.sample(X(0))) is also changed tofloat. (#5607)The framework for the development of an
assert_equalfunction for testing operator comparison has been set up. (#5634) (#5858)The
decomposetransform has anerrorkeyword argument to specify the type of error that should be raised, allowing error types to be more consistent with the context thedecomposefunction is used in. (#5669)Empty initialization of
PauliVSpaceis permitted. (#5675)qml.tape.QuantumScriptproperties are only calculated when needed, instead of on initialization. This decreases the classical overhead by over 20%. Also,par_info,obs_sharing_wires, andobs_sharing_wires_idare now public attributes. (#5696)The
qml.datamodule now supports PyTree data types as dataset attributes (#5732)qml.ops.Conditionalnow inherits fromqml.ops.SymbolicOp, thus it inherits several useful common functionalities. Other properties such as adjoint and diagonalizing gates have been added using thebaseproperties. (##5772)New dispatches for
qml.ops.Conditionalandqml.MeasurementValuehave been added toqml.equal. (##5772)The
qml.snapshotstransform now supports arbitrary devices by running a separate tape for each snapshot for unsupported devices. (#5805)The
qml.Snapshotoperator now accepts sample-based measurements for finite-shot devices. (#5805)Device preprocess transforms now happen inside the ML boundary. (#5791)
Transforms applied to callables now use
functools.wrapsto preserve the docstring and call signature of the original function. (#5857)qml.qsvt()now supports JAX arrays with angle conversions. (#5853)The sorting order of parameter-shift terms is now guaranteed to resolve ties in the absolute value with the sign of the shifts. (#5583)
Breaking changes 💔
Passing
shotsas a keyword argument to aQNodeinitialization now raises an error instead of ignoring the input. (#5748)A custom decomposition can no longer be provided to
qml.QDrift. Instead, apply the operations in your custom operation directly withqml.apply. (#5698)Sampling observables composed of
X,Y,ZandHadamardnow returns values of typefloatinstead ofint. (#5607)qml.is_commutingno longer accepts thewire_mapargument, which does not bring any functionality. (#5660)qml.from_qasm_filehas been removed. The user can open files and load their content usingqml.from_qasm. (#5659)qml.loadhas been removed in favour of more specific functions, such asqml.from_qiskit, etc. (#5654)qml.transforms.convert_to_numpy_parametersis now a proper transform and its output signature has changed, returning a list ofQuantumScripts and a post-processing function instead of simply the transformed circuit. (#5693)Controlled.wiresdoes not includeself.work_wiresanymore. That can be accessed separately throughControlled.work_wires. Consequently,Controlled.active_wireshas been removed in favour of the more commonControlled.wires. (#5728)
Deprecations 👋
The
simplifyargument inqml.Hamiltonianandqml.ops.LinearCombinationhas been deprecated. Instead,qml.simplify()can be called on the constructed operator. (#5677)qml.transforms.map_batch_transformhas been deprecated, since a transform can be applied directly to a batch of tapes. (#5676)The default behaviour of
qml.from_qasm()to remove measurements in the QASM code has been deprecated. Usemeasurements=[]to keep this behaviour ormeasurements=Noneto keep the measurements from the QASM code. (#5882) (#5904)
Documentation 📝
The
qml.qchemdocs have been updated to showcase the new improvements. (#5758) (#5638)Several links to other functions in measurement process docstrings have been fixed. (#5913)
Information about mid-circuit measurements has been moved from the measurements quickstart page to its own mid-circuit measurements quickstart page (#5870)
The documentation for the
default.tensordevice has been added. (#5719)A small typo was fixed in the docstring for
qml.sample. (#5685)Typesetting for some of the documentation was fixed, (use of left/right delimiters, fractions, and fixing incorrectly set up commands) (#5804)
The
qml.Trackerexamples have been updated. (#5803)The input types for
coupling_mapinqml.transpilehave been updated to reflect all the allowed input types bynx.to_networkx_graph. (#5864)The text in the
qml.datamodule and datasets quickstart has been slightly modified to lead to the quickstart first and highlightlist_datasets. (5484)
Bug fixes 🐛
qml.compiler.activefirst checks whether Catalyst is imported at all to avoid changingjax_enable_x64on module initialization. (#5960)The
__invert__dunder method of theMeasurementValueclass uses an array-valued function. (#5955)Skip
Projector-measurement tests on devices that do not support it. (#5951)The
default.tensordevice now preserves the order of wires if the initial MPS is created from a dense state vector. (#5892)Fixed a bug where
hadamard_gradreturned a wrong shape forqml.probs()without wires. (#5860)An error is now raised on processing an
AnnotatedQueueinto aQuantumScriptif the queue contains something other than anOperator,MeasurementProcess, orQuantumScript. (#5866)Fixed a bug in the wire handling on special controlled ops. (#5856)
Fixed a bug where
Sum‘s with repeated identical operations ended up with the same hash asSum‘s with different numbers of repeats. (#5851)qml.qaoa.cost_layerandqml.qaoa.mixer_layercan now be used withSumoperators. (#5846)Fixed a bug where
qml.MottonenStatePreparationproduces wrong derivatives at special parameter values. (#5774)Fixed a bug where fractional powers and adjoints of operators were commuted, which is not well-defined/correct in general. Adjoints of fractional powers can no longer be evaluated. (#5835)
qml.qnn.TorchLayernow works with tuple returns. (#5816)An error is now raised if a transform is applied to a catalyst qjit object. (#5826)
qml.qnn.KerasLayerandqml.qnn.TorchLayerno longer mutate the inputqml.QNode‘s interface. (#5800)Docker builds on PR merging has been disabled. (#5777)
The validation of the adjoint method in
DefaultQubitcorrectly handles device wires now. (#5761)QuantumPhaseEstimation.map_wireson longer modifies the original operation instance. (#5698)The decomposition of
qml.AmplitudeAmplificationnow correctly queues all operations. (#5698)Replaced
semantic_versionwithpackaging.version.Version, since the former cannot handle the metadata.postin the version string. (#5754)The
dynamic_one_shottransform now has expanded support for thejaxandtorchinterfaces. (#5672)The decomposition of
StronglyEntanglingLayersis now compatible with broadcasting. (#5716)qml.condcan now be applied toControlledOpoperations when deferring measurements. (#5725)The legacy
Tensorclass can now handle aProjectorwith abstract tracer input. (#5720)Fixed a bug that raised an error regarding expected versus actual
dtypewhen usingJAX-JITon a circuit that returned samples of observables containing theqml.Identityoperator. (#5607)The signature of
CaptureMetaobjects (likeOperator) now match the signature of the__init__call. (#5727)Vanilla NumPy arrays are now used in
test_projector_expectationto avoid differentiatingqml.Projectorwith respect to the state attribute. (#5683)qml.Projectoris now compatible withjax.jit. (#5595)Finite-shot circuits with a
qml.probsmeasurement, both with awiresoropargument, can now be compiled withjax.jit. (#5619)param_shift,finite_diff,compile,insert,merge_rotations, andtranspilenow all work with circuits with non-commuting measurements. (#5424) (#5681)A correction has been added to
qml.bravyi_kitaevto call the correct function for aqml.FermiSentenceinput. (#5671)Fixed a bug where
sum_expandproduces incorrect result dimensions when combined with shot vectors, multiple measurements, and parameter broadcasting. (#5702)Fixed a bug in
qml.math.dotthat raises an error when only one of the operands is a scalar. (#5702)qml.matrixis now compatible with QNodes compiled byqml.qjit. (#5753)qml.snapshotsraises an error when a measurement other thanqml.stateis requested fromdefault.qubit.legacyinstead of silently returning the statevector. (#5805)Fixed a bug where
default.qutritwas falsely determined to be natively compatible withqml.snapshots. (#5805)Fixed a bug where the measurement of a
qml.Snapshotinstance was not passed on during theqml.adjointandqml.ctrloperations. (#5805)qml.CNOTandqml.Toffolinow have anarithmetic_depthof1, as they are controlled operations. (#5797)Fixed a bug where the gradient of
ControlledSequence,Reflection,AmplitudeAmplification, andQubitizationwas incorrect ondefault.qubit.legacywithparameter_shift. (#5806)Fixed a bug where
split_non_commutingraises an error when the circuit contains measurements of observables that are not Pauli words. (#5827)The
simplifymethod forqml.Expnow returns an operator with the correct number of Trotter steps, i.e. equal to the one from the pre-simplified operator. (#5831)Fixed a bug where
CompositeOp.overlapping_opswould put overlapping operators in different groups, leading to incorrect results returned byLinearCombination.eigvals(). (#5847)The correct decomposition for a
qml.PauliRotwith an identity aspauli_wordhas been implemented, i.e. returns aqml.GlobalPhasewith half the angle. (#5875)qml.pauli_decomposenow works in a jit-ted context, such asjax.jitandqml.qjit. (#5878)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Tarun Kumar Allamsetty, Guillermo Alonso-Linaje, Utkarsh Azad, Lillian M. A. Frederiksen, Ludmila Botelho, Gabriel Bottrill, Thomas Bromley, Jack Brown, Astral Cai, Ahmed Darwish, Isaac De Vlugt, Diksha Dhawan, Pietropaolo Frisoni, Emiliano Godinez, Diego Guala, Daria Van Hende, Austin Huang, David Ittah, Soran Jahangiri, Rohan Jain, Mashhood Khan, Korbinian Kottmann, Christina Lee, Vincent Michaud-Rioux, Lee James O’Riordan, Mudit Pandey, Kenya Sakka, Jay Soni, Kazuki Tsuoka, Haochen Paul Wang, David Wierichs.
Release 0.36.0¶
New features since last release
Estimate errors in a quantum circuit 🧮
This version of PennyLane lays the foundation for estimating the total error in a quantum circuit from the combination of individual gate errors. (#5154) (#5464) (#5465) (#5278) (#5384)
Two new user-facing classes enable calculating and propagating gate errors in PennyLane:
qml.resource.SpectralNormError: the spectral norm error is defined as the distance, in spectral norm, between the true unitary we intend to apply and the approximate unitary that is actually applied.qml.resource.ErrorOperation: a base class that inherits fromqml.operation.Operationand represents quantum operations which carry some form of algorithmic error.
SpectralNormErrorcan be used for back-of-the-envelope type calculations like obtaining the spectral norm error between two unitaries viaget_error:import pennylane as qml from pennylane.resource import ErrorOperation, SpectralNormError intended_op = qml.RY(0.40, 0) actual_op = qml.RY(0.41, 0) # angle of rotation is slightly off
>>> SpectralNormError.get_error(intended_op, actual_op) 0.004999994791668309
SpectralNormErroris also a key tool to specify errors in larger quantum circuits:For operations representing a major building block of an algorithm, we can create a custom operation that inherits from
ErrorOperation. This child class must override theerrormethod and should return aSpectralNormErrorinstance:class MyErrorOperation(ErrorOperation): def __init__(self, error_val, wires): self.error_val = error_val super().__init__(wires=wires) def error(self): return SpectralNormError(self.error_val)
In this toy example,
MyErrorOperationintroduces an arbitrarySpectralNormErrorwhen called in a QNode. It does not require a decomposition or matrix representation when used withnull.qubit(suggested for use with resource and error estimation since circuit executions are not required to calculate resources or errors).dev = qml.device("null.qubit") @qml.qnode(dev) def circuit(): MyErrorOperation(0.1, wires=0) MyErrorOperation(0.2, wires=1) return qml.state()
The total spectral norm error of the circuit can be calculated using
qml.specs:>>> qml.specs(circuit)()['errors'] {'SpectralNormError': SpectralNormError(0.30000000000000004)}
PennyLane already includes a number of built-in building blocks for algorithms like
QuantumPhaseEstimationandTrotterProduct.TrotterProductnow propagates errors based on the number of steps performed in the Trotter product.QuantumPhaseEstimationnow propagates errors based on the error of its input unitary.dev = qml.device('null.qubit') hamiltonian = qml.dot([1.0, 0.5, -0.25], [qml.X(0), qml.Y(0), qml.Z(0)]) @qml.qnode(dev) def circuit(): qml.TrotterProduct(hamiltonian, time=0.1, order=2) qml.QuantumPhaseEstimation(MyErrorOperation(0.01, wires=0), estimation_wires=[1, 2, 3]) return qml.state()
Again, the total spectral norm error of the circuit can be calculated using
qml.specs:>>> qml.specs(circuit)()["errors"] {'SpectralNormError': SpectralNormError(0.07616666666666666)}
Check out our error propagation demo to see how to use these new features in a real-world example!
Access an extended arsenal of quantum algorithms 🏹
The Fast Approximate BLock-Encodings (FABLE) algorithm for embedding a matrix into a quantum circuit as outlined in arXiv:2205.00081 is now accessible via the
qml.FABLEtemplate. (#5107)The usage of
qml.FABLEis similar toqml.BlockEncodebut provides a more efficient circuit construction at the cost of a user-defined approximation level,tol. The number of wires thatqml.FABLEoperates on is2*n + 1, wherendefines the dimension of the \(2^n \times 2^n\) matrix that we want to block-encode.import numpy as np A = np.array([[0.1, 0.2], [0.3, 0.4]]) dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(): qml.FABLE(A, tol = 0.001, wires=range(3)) return qml.state()
>>> mat = qml.matrix(circuit)() >>> 2 * mat[0:2, 0:2] array([[0.1+0.j, 0.2+0.j], [0.3+0.j, 0.4+0.j]])
A high-level interface for amplitude amplification and its variants is now available via the new
qml.AmplitudeAmplificationtemplate. (#5160)Based on arXiv:quant-ph/0005055, given a state \(\vert \Psi \rangle = \alpha \vert \phi \rangle + \beta \vert \phi^{\perp} \rangle\),
qml.AmplitudeAmplificationamplifies the amplitude of \(\vert \phi \rangle\).Here’s an example with a target state \(\vert \phi \rangle = \vert 2 \rangle = \vert 010 \rangle\), an input state \(\vert \Psi \rangle = H^{\otimes 3} \vert 000 \rangle\), as well as an oracle that flips the sign of \(\vert \phi \rangle\) and does nothing to \(\vert \phi^{\perp} \rangle\), which can be achieved in this case through
qml.FlipSign.@qml.prod def generator(wires): for wire in wires: qml.Hadamard(wires=wire) U = generator(wires=range(3)) O = qml.FlipSign(2, wires=range(3))
Here,
Uis a quantum operation that is created by decorating a quantum function with@qml.prod. This could alternatively be done by creating a user-defined custom operation with a decomposition. Amplitude amplification can then be set up within a circuit:dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): generator(wires=range(3)) # prepares |Psi> = U|0> qml.AmplitudeAmplification(U, O, iters=10) return qml.probs(wires=range(3))
>>> print(np.round(circuit(), 3)) [0.01 0.01 0.931 0.01 0.01 0.01 0.01 0.01 ]
As expected, we amplify the \(\vert 2 \rangle\) state.
Reflecting about a given quantum state is now available via
qml.Reflection. This operation is very useful in the amplitude amplification algorithm and offers a generalization ofqml.FlipSign, which operates on basis states. (#5159)qml.Reflectionworks by providing an operation, \(U\), that prepares the desired state, \(\vert \psi \rangle\), that we want to reflect about. In other words, \(U\) is such that \(U \vert 0 \rangle = \vert \psi \rangle\). In PennyLane, \(U\) must be anOperator.For example, if we want to reflect about \(\vert \psi \rangle = \vert + \rangle\), then \(U = H\):
U = qml.Hadamard(wires=0) dev = qml.device('default.qubit') @qml.qnode(dev) def circuit(): qml.Reflection(U) return qml.state()
>>> circuit() tensor([0.-6.123234e-17j, 1.+6.123234e-17j], requires_grad=True)
Performing qubitization is now easily accessible with the new
qml.Qubitizationoperator. (#5500)qml.Qubitizationencodes a Hamiltonian into a suitable unitary operator. When applied in conjunction with quantum phase estimation (QPE), it allows for computing the eigenvalue of an eigenvector of the given Hamiltonian.H = qml.dot([0.1, 0.3, -0.3], [qml.Z(0), qml.Z(1), qml.Z(0) @ qml.Z(2)]) @qml.qnode(qml.device("default.qubit")) def circuit(): # initialize the eigenvector qml.PauliX(2) # apply QPE measurements = qml.iterative_qpe( qml.Qubitization(H, control = [3,4]), ancilla = 5, iters = 3 ) return qml.probs(op = measurements)
Make use of more methods to map from molecules 🗺️
A new function called
qml.bravyi_kitaevhas been added to perform the Bravyi-Kitaev mapping of fermionic Hamiltonians to qubit Hamiltonians. (#5390)This function presents an alternative mapping to
qml.jordan_wignerorqml.parity_transformwhich can help us measure expectation values more efficiently on hardware. Simply provide a fermionic Hamiltonian (created fromfrom_string,FermiA,FermiC,FermiSentence, orFermiWord) and the number of qubits / spin orbitals in the system,n:>>> fermi_ham = qml.fermi.from_string('0+ 1+ 1- 0-') >>> qubit_ham = qml.bravyi_kitaev(fermi_ham, n=6, tol=0.0) >>> print(qubit_ham) 0.25 * I(0) + -0.25 * Z(0) + -0.25 * (Z(0) @ Z(1)) + 0.25 * Z(1)
The
qml.qchem.hf_statefunction has been upgraded to be compatible withqml.parity_transformand the new Bravyi-Kitaev mapping (qml.bravyi_kitaev). (#5472) (#5472)>>> state_bk = qml.qchem.hf_state(2, 6, basis="bravyi_kitaev") >>> print(state_bk) [1 0 0 0 0 0] >>> state_parity = qml.qchem.hf_state(2, 6, basis="parity") >>> print(state_parity) [1 0 0 0 0 0]
Calculate dynamical Lie algebras 👾
The dynamical Lie algebra (DLA) of a set of operators captures the range of unitary evolutions that the operators can generate. In v0.36 of PennyLane, we have added support for calculating important DLA concepts including:
A new
qml.lie_closurefunction to compute the Lie closure of a list of operators, providing one way to obtain the DLA. (#5161) (#5169) (#5627)For a list of operators
ops = [op1, op2, op3, ..], one computes all nested commutators betweenopsuntil no new operators are generated from commutation. All these operators together form the DLA, see e.g. section IIB of arXiv:2308.01432.Take for example the following operators:
from pennylane import X, Y, Z ops = [X(0) @ X(1), Z(0), Z(1)]
A first round of commutators between all elements yields the new operators
Y(0) @ X(1)andX(0) @ Y(1)(omitting scalar prefactors).>>> qml.commutator(X(0) @ X(1), Z(0)) -2j * (Y(0) @ X(1)) >>> qml.commutator(X(0) @ X(1), Z(1)) -2j * (X(0) @ Y(1))
A next round of commutators between all elements further yields the new operator
Y(0) @ Y(1).>>> qml.commutator(X(0) @ Y(1), Z(0)) -2j * (Y(0) @ Y(1))
After that, no new operators emerge from taking nested commutators and we have the resulting DLA. This can now be done in short via
qml.lie_closureas follows.>>> ops = [X(0) @ X(1), Z(0), Z(1)] >>> dla = qml.lie_closure(ops) >>> dla [X(0) @ X(1), Z(0), Z(1), -1.0 * (Y(0) @ X(1)), -1.0 * (X(0) @ Y(1)), -1.0 * (Y(0) @ Y(1))]
Computing the structure constants (the adjoint representation) of a dynamical Lie algebra. (5406)
For example, we can compute the adjoint representation of the transverse field Ising model DLA.
>>> dla = [X(0) @ X(1), Z(0), Z(1), Y(0) @ X(1), X(0) @ Y(1), Y(0) @ Y(1)] >>> structure_const = qml.structure_constants(dla) >>> structure_const.shape (6, 6, 6)
Visit the documentation of qml.structure_constants to understand how structure constants are a useful way to represent a DLA.
Computing the center of a dynamical Lie algebra. (#5477)
Given a DLA
g, we can now compute its centre. Thecenteris the collection of operators that commute with all other operators in the DLA.>>> g = [X(0), X(1) @ X(0), Y(1), Z(1) @ X(0)] >>> qml.center(g) [X(0)]
To help explain these concepts, check out the dynamical Lie algebras demo.
Improvements 🛠
Simulate mixed-state qutrit systems
Mixed qutrit states can now be simulated with the
default.qutrit.mixeddevice. (#5495) (#5451) (#5186) (#5082) (#5213)Thanks to contributors from the University of British Columbia, a mixed-state qutrit device is now available for simulation, providing a noise-capable equivalent to
default.qutrit.dev = qml.device("default.qutrit.mixed") def circuit(): qml.TRY(0.1, wires=0) @qml.qnode(dev) def shots_circuit(): circuit() return qml.sample(), qml.expval(qml.GellMann(wires=0, index=1)) @qml.qnode(dev) def density_matrix_circuit(): circuit() return qml.state()
>>> shots_circuit(shots=5) (array([0, 0, 0, 0, 0]), 0.19999999999999996) >>> density_matrix_circuit() tensor([[0.99750208+0.j, 0.04991671+0.j, 0. +0.j], [0.04991671+0.j, 0.00249792+0.j, 0. +0.j], [0. +0.j, 0. +0.j, 0. +0.j]], requires_grad=True)
However, there’s one crucial ingredient that we still need to add: support for qutrit noise operations. Keep your eyes peeled for this to arrive in the coming releases!
Work easily and efficiently with operators
This release completes the main phase of PennyLane’s switchover to an updated approach for handling arithmetic operations between operators. The new approach is now enabled by default and is intended to realize a few objectives:
To make it as easy to work with PennyLane operators as it would be with pen and paper.
To improve the efficiency of operator arithmetic.
In many cases, this update should not break code. If issues do arise, check out the updated operator troubleshooting page and don’t hesitate to reach out to us on the PennyLane discussion forum. As a last resort the old behaviour can be enabled by calling
qml.operation.disable_new_opmath(), but this is not recommended because support will not continue in future PennyLane versions (v0.36 and higher). (#5269)A new class called
qml.ops.LinearCombinationhas been introduced. In essence, this class is an updated equivalent of the now-deprecatedqml.ops.Hamiltonianbut for usage with the new operator arithmetic. (#5216)qml.ops.Sumnow supports storing grouping information. Grouping type and method can be specified during construction using thegrouping_typeandmethodkeyword arguments ofqml.dot,qml.sum, orqml.ops.Sum. The grouping indices are stored inSum.grouping_indices. (#5179)a = qml.X(0) b = qml.prod(qml.X(0), qml.X(1)) c = qml.Z(0) obs = [a, b, c] coeffs = [1.0, 2.0, 3.0] op = qml.dot(coeffs, obs, grouping_type="qwc")
>>> op.grouping_indices ((2,), (0, 1))
Additionally,
grouping_typeandmethodcan be set or changed after construction usingSum.compute_grouping():a = qml.X(0) b = qml.prod(qml.X(0), qml.X(1)) c = qml.Z(0) obs = [a, b, c] coeffs = [1.0, 2.0, 3.0] op = qml.dot(coeffs, obs)
>>> op.grouping_indices is None True >>> op.compute_grouping(grouping_type="qwc") >>> op.grouping_indices ((2,), (0, 1))
Note that the grouping indices refer to the lists returned by
Sum.terms(), notSum.operands.A new function called
qml.operation.convert_to_legacy_Hthat convertsSum,SProd, andProdtoHamiltonianinstances has been added. This function is intended for developers and will be removed in a future release without a deprecation cycle. (#5309)The
qml.is_commutingfunction now acceptsSum,SProd, andProdinstances. (#5351)Operators can now be left-multiplied by NumPy arrays (i.e.,
arr * op). (#5361)op.generator(), whereopis anOperatorinstance, now returns operators consistent with the global setting forqml.operator.active_new_opmath()wherever possible.Sum,SProdandProdinstances will be returned even after disabling the new operator arithmetic in cases where they offer additional functionality not available using legacy operators. (#5253) (#5410) (#5411) (#5421)Prodinstances temporarily have a newobsproperty, which helps smoothen the transition of the new operator arithmetic system. In particular, this is aimed at preventing breaking code that usesTensor.obs. The property has been immediately deprecated. Moving forward, we recommend usingop.operands. (#5539)qml.ApproxTimeEvolutionis now compatible with any operator that has a definedpauli_rep. (#5362)Hamiltonian.pauli_repis now defined if the Hamiltonian is a linear combination of Pauli operators. (#5377)Prodinstances created with qutrit operators now have a definedeigvals()method. (#5400)qml.transforms.hamiltonian_expandandqml.transforms.sum_expandcan now handle multi-term observables with a constant offset (i.e., terms likeqml.I()). (#5414) (#5543)qml.qchem.taper_operationis now compatible with the new operator arithmetic. (#5326)The warning for an observable that might not be hermitian in QNode executions has been removed. This enables jit-compilation. (#5506)
qml.transforms.split_non_commutingwill now work with single-term operator arithmetic. (#5314)LinearCombinationandSumnow accept_grouping_indiceson initialization. This addition is relevant to developers only. (#5524)Calculating the dense, differentiable matrix for
PauliSentenceand operators with Pauli sentences is now faster. (#5578)
Community contributions 🥳
ExpectationMP,VarianceMP,CountsMP, andSampleMPnow have aprocess_countsmethod (similar toprocess_samples). This allows for calculating measurements given acountsdictionary. (#5256) (#5395)Type-hinting has been added in the
Operatorclass for better interpretability. (#5490)An alternate strategy for sampling with multiple different
shotsvalues has been implemented via theshots.bins()method, which samples all shots at once and then processes each separately. (#5476)
Mid-circuit measurements and dynamic circuits
A new module called
qml.capturethat will contain PennyLane’s own capturing mechanism for hybrid quantum-classical programs has been added. (#5509)The
dynamic_one_shottransform has been introduced, enabling dynamic circuit execution on circuits with finiteshotsand devices that natively support mid-circuit measurements. (#5266)The
QubitDeviceclass and children classes support thedynamic_one_shottransform provided that they support mid-circuit measurement operations natively. (#5317)default.qubitcan now be provided a random seed for sampling mid-circuit measurements with finite shots. This (1) ensures that random behaviour is more consistent withdynamic_one_shotanddefer_measurementsand (2) makes our continuous-integration (CI) have less failures due to stochasticity. (#5337)
Performance and broadcasting
Gradient transforms may now be applied to batched/broadcasted QNodes as long as the broadcasting is in non-trainable parameters. (#5452)
The performance of computing the matrix of
qml.QFThas been improved. (#5351)qml.transforms.broadcast_expandnow supports shot vectors when returningqml.sample(). (#5473)LightningVJPsis now compatible with Lightning devices using the new device API. (#5469)
Device capabilities
Obtaining classical shadows using the
default.clifforddevice is now compatible with stimv1.13.0. (#5409)default.mixedhas improved support for sampling-based measurements with non-NumPy interfaces. (#5514) (#5530)default.mixednow supports arbitrary state-based measurements withqml.Snapshot. (#5552)null.qubithas been upgraded to the new device API and has support for all measurements and various modes of differentiation. (#5211)
Other improvements
Entanglement entropy can now be calculated with
qml.math.vn_entanglement_entropy, which computes the von Neumann entanglement entropy from a density matrix. A corresponding QNode transform,qml.qinfo.vn_entanglement_entropy, has also been added. (#5306)qml.drawandqml.draw_mplwill now attempt to sort the wires if no wire order is provided by the user or the device. (#5576)A clear error message is added in
KerasLayerwhen using the newest version of TensorFlow with Keras 3 (which is not currently compatible withKerasLayer), linking to instructions to enable Keras 2. (#5488)qml.ops.Conditionalnow stores thedata,num_params, andndim_paramattributes of the operator it wraps. (#5473)The
molecular_hamiltonianfunction callsPySCFdirectly whenmethod='pyscf'is selected. (#5118)cache_executehas been replaced with an alternate implementation based on@transform. (#5318)QNodes now defer
diff_methodvalidation to the device under the new device API. (#5176)The device test suite has been extended to cover gradient methods, templates and arithmetic observables. (#5273) (#5518)
A typo and string formatting mistake have been fixed in the error message for
ClassicalShadow._convert_to_pauli_wordswhen the input is not a validpauli_rep. (#5572)Circuits running on
lightning.qubitand that returnqml.state()now preserve thedtypewhen specified. (#5547)
Breaking changes 💔
qml.matrix()called on the following will now raise an error ifwire_orderis not specified:single_tape_transform,batch_transform,qfunc_transform,op_transform,gradient_transformandhessian_transformhave been removed. Instead, switch to using the newqml.transformfunction. Please refer to the transform docs to see how this can be done. (#5339)Attempting to multiply
PauliWordandPauliSentencewith*will raise an error. Instead, use@to conform with the PennyLane convention. (#5341)DefaultQubitnow uses a pre-emptive key-splitting strategy to avoid reusing JAX PRNG keys throughout a singleexecutecall. (#5515)qml.pauli.pauli_multandqml.pauli.pauli_mult_with_phasehave been removed. Instead, useqml.simplify(qml.prod(pauli_1, pauli_2))to get the reduced operator. (#5324)>>> op = qml.simplify(qml.prod(qml.PauliX(0), qml.PauliZ(0))) >>> op -1j*(PauliY(wires=[0])) >>> [phase], [base] = op.terms() >>> phase, base (-1j, PauliY(wires=[0]))
The
dynamic_one_shottransform now uses sampling (SampleMP) to get back the values of the mid-circuit measurements. (#5486)Operatordunder methods now combine like-operator arithmetic classes vialazy=False. This reduces the chances of getting aRecursionErrorand makes nested operators easier to work with. (#5478)The private functions
_pauli_mult,_binary_matrixand_get_pauli_mapfrom thepaulimodule have been removed. The same functionality can be achieved using newer features in thepaulimodule. (#5323)MeasurementProcess.nameandMeasurementProcess.datahave been removed. UseMeasurementProcess.obs.nameandMeasurementProcess.obs.datainstead. (#5321)Operator.validate_subspace(subspace)has been removed. Instead, useqml.ops.qutrit.validate_subspace(subspace). (#5311)The contents of
qml.interfaceshas been moved insideqml.workflow. The old import path no longer exists. (#5329)Since
default.mixeddoes not support snapshots with measurements, attempting to do so will result in aDeviceErrorinstead of getting the density matrix. (#5416)LinearCombination._obs_datahas been removed. You can still useLinearCombination.compareto check mathematical equivalence between aLinearCombinationand another operator. (#5504)
Deprecations 👋
Accessing
qml.ops.Hamiltonianis deprecated because it points to the old version of the class that may not be compatible with the new approach to operator arithmetic. Instead, usingqml.Hamiltonianis recommended because it dispatches to theLinearCombinationclass when the new approach to operator arithmetic is enabled. This will allow you to continue to useqml.Hamiltonianwith existing code without needing to make any changes. (#5393)qml.loadhas been deprecated. Instead, please use the functions outlined in the Importing workflows quickstart guide. (#5312)Specifying
control_valueswith a bit string inqml.MultiControlledXhas been deprecated. Instead, use a list of booleans or 1s and 0s. (#5352)qml.from_qasm_filehas been deprecated. Instead, please open the file and then load its content usingqml.from_qasm. (#5331)>>> with open("test.qasm", "r") as f: ... circuit = qml.from_qasm(f.read())
Documentation 📝
A new page explaining the shapes and nesting of return types has been added. (#5418)
Redundant documentation for the
evolvefunction has been removed. (#5347)The final example in the
compiledocstring has been updated to use transforms correctly. (#5348)A link to the demos for using
qml.SpecialUnitaryandqml.QNGOptimizerhas been added to their respective docstrings. (#5376)A code example in the
qml.measuredocstring has been added that showcases returning mid-circuit measurement statistics from QNodes. (#5441)The computational basis convention used for
qml.measure— 0 and 1 rather than ±1 — has been clarified in its docstring. (#5474)A new Release news section has been added to the table of contents, containing release notes, deprecations, and other pages focusing on recent changes. (#5548)
A summary of all changes has been added in the “Updated Operators” page in the new “Release news” section in the docs. (#5483) (#5636)
Bug fixes 🐛
Patches the QNode so that parameter-shift will be considered best with lightning if
qml.metric_tensoris in the transform program. (#5624)Stopped printing the ID of
qcut.MeasureNodeandqcut.PrepareNodein tape drawing. (#5613)Improves the error message for setting shots on the new device interface, or trying to access a property that no longer exists. (#5616)
Fixed a bug where
qml.drawandqml.draw_mplincorrectly raised errors for circuits collecting statistics on mid-circuit measurements while usingqml.defer_measurements. (#5610)Using shot vectors with
param_shift(... broadcast=True)caused a bug. This combination is no longer supported and will be added again in the next release. Fixed a bug with custom gradient recipes that only consist of unshifted terms. (#5612) (#5623)qml.countsnow returns the same keys withdynamic_one_shotanddefer_measurements. (#5587)null.qubitnow automatically supports any operation without a decomposition. (#5582)Fixed a bug where the shape and type of derivatives obtained by applying a gradient transform to a QNode differed based on whether the QNode uses classical coprocessing. (#4945)
ApproxTimeEvolution,CommutingEvolution,QDrift, andTrotterProductnow de-queue their input observable. (#5524)(In)equality of
qml.HilbertSchmidtinstances is now reported correctly byqml.equal. (#5538)qml.ParticleConservingU1andqml.ParticleConservingU2no longer raise an error when the initial state is not specified but default to the all-zeros state. (#5535)qml.countsno longer returns negative samples when measuring 8 or more wires. (#5544) (#5556)The
dynamic_one_shottransform now works with broadcasting. (#5473)Diagonalizing gates are now applied when measuring
qml.probson non-computational basis states on a Lightning device. (#5529)two_qubit_decompositionno longer diverges at a special case of a unitary matrix. (#5448)The
qml.QNSPSAOptimizernow correctly handles optimization for legacy devices that do not follow the new device API. (#5497)Operators applied to all wires are now drawn correctly in a circuit with mid-circuit measurements. (#5501)
Fixed a bug where certain unary mid-circuit measurement expressions would raise an uncaught error. (#5480)
Probabilities now sum to 1 when using the
torchinterface withdefault_dtypeset totorch.float32. (#5462)Tensorflow can now handle devices with
float32results butfloat64input parameters. (#5446)Fixed a bug where the
argnumkeyword argument ofqml.gradients.stoch_pulse_gradreferences the wrong parameters in a tape, creating an inconsistency with other differentiation methods and preventing some use cases. (#5458)Bounded value failures due to numerical noise with calls to
np.random.binomialis now avoided. (#5447)Using
@with legacy Hamiltonian instances now properly de-queues the previously existing operations. (#5455)The
QNSPSAOptimizernow properly handles differentiable parameters, resulting in being able to use it for more than one optimization step. (#5439)The QNode interface now resets if an error occurs during execution. (#5449)
Failing tests due to changes with Lightning’s adjoint diff pipeline have been fixed. (#5450)
Failures occurring when making autoray-dispatched calls to Torch with paired CPU data have been fixed. (#5438)
jax.jitnow works withqml.samplewith a multi-wire observable. (#5422)qml.qinfo.quantum_fishernow works with non-default.qubitdevices. (#5423)We no longer perform unwanted
dtypepromotion in thepauli_repofSProdinstances when using Tensorflow. (#5246)Fixed
TestQubitIntegration.test_countsintests/interfaces/test_jax_qnode.pyto always produce counts for all outcomes. (#5336)Fixed
PauliSentence.to_mat(wire_order)to support identities with wires. (#5407)CompositeOp.map_wiresnow correctly maps theoverlapping_opsproperty. (#5430)DefaultQubit.supports_derivativeshas been updated to correctly handle circuits containing mid-circuit measurements and adjoint differentiation. (#5434)SampleMP,ExpectationMP,CountsMP, andVarianceMPconstructed witheigvalscan now properly process samples. (#5463)Fixed a bug in
hamiltonian_expandthat produces incorrect output dimensions when shot vectors are combined with parameter broadcasting. (#5494)default.qubitnow allows measuringIdentityon no wires and observables containingIdentityon no wires. (#5570)Fixed a bug where
TorchLayerdoes not work with shot vectors. (#5492)Fixed a bug where the output shape of a QNode returning a list containing a single measurement is incorrect when combined with shot vectors. (#5492)
Fixed a bug in
qml.math.kronthat makes Torch incompatible with NumPy. (#5540)Fixed a bug in
_group_measurementsthat fails to group measurements with commuting observables when they are operands ofProd. (#5525)qml.equalcan now be used with sums and products that contain operators on no wires likeIandGlobalPhase. (#5562)CompositeOp.has_diagonalizing_gatesnow does a more complete check of the base operators to ensure consistency betweenop.has_diagonalzing_gatesandop.diagonalizing_gates()(#5603)Updated the
methodkwarg ofqml.TrotterProduct().error()to be more clear that we are computing upper-bounds. (#5637)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Tarun Kumar Allamsetty, Guillermo Alonso, Mikhail Andrenkov, Utkarsh Azad, Gabriel Bottrill, Thomas Bromley, Astral Cai, Diksha Dhawan, Isaac De Vlugt, Amintor Dusko, Pietropaolo Frisoni, Lillian M. A. Frederiksen, Diego Guala, Austin Huang, Soran Jahangiri, Korbinian Kottmann, Christina Lee, Vincent Michaud-Rioux, Mudit Pandey, Kenya Sakka, Jay Soni, Matthew Silverman, David Wierichs.
Release 0.35.0¶
New features since last release
Qiskit 1.0 integration 🔌
This version of PennyLane makes it easier to import circuits from Qiskit. (#5218) (#5168)
The
qml.from_qiskitfunction converts a Qiskit QuantumCircuit into a PennyLane quantum function. Althoughqml.from_qiskitalready exists in PennyLane, we have made a number of improvements to make importing from Qiskit easier. And yes —qml.from_qiskitfunctionality is compatible with both Qiskit 1.0 and earlier versions! Here’s a comprehensive list of the improvements:You can now append PennyLane measurements onto the quantum function returned by
qml.from_qiskit. Consider this simple Qiskit circuit:import pennylane as qml from qiskit import QuantumCircuit qc = QuantumCircuit(2) qc.rx(0.785, 0) qc.ry(1.57, 1)
We can convert it into a PennyLane QNode in just a few lines, with PennyLane
measurementseasily included:>>> dev = qml.device("default.qubit") >>> measurements = qml.expval(qml.Z(0) @ qml.Z(1)) >>> qfunc = qml.from_qiskit(qc, measurements=measurements) >>> qnode = qml.QNode(qfunc, dev) >>> qnode() tensor(0.00056331, requires_grad=True)
Quantum circuits that already contain Qiskit-side measurements can be faithfully converted with
qml.from_qiskit. Consider this example Qiskit circuit:qc = QuantumCircuit(3, 2) # Teleportation qc.rx(0.9, 0) # Prepare input state on qubit 0 qc.h(1) # Prepare Bell state on qubits 1 and 2 qc.cx(1, 2) qc.cx(0, 1) # Perform teleportation qc.h(0) qc.measure(0, 0) qc.measure(1, 1) with qc.if_test((1, 1)): # Perform first conditional qc.x(2)
This circuit can be converted into PennyLane with the Qiskit measurements still accessible. For example, we can use those results as inputs to a mid-circuit measurement in PennyLane:
@qml.qnode(dev) def teleport(): m0, m1 = qml.from_qiskit(qc)() qml.cond(m0, qml.Z)(2) return qml.density_matrix(2)
>>> teleport() tensor([[0.81080498+0.j , 0. +0.39166345j], [0. -0.39166345j, 0.18919502+0.j ]], requires_grad=True)
It is now more intuitive to handle and differentiate parametrized Qiskit circuits. Consider the following circuit:
from qiskit.circuit import Parameter from pennylane import numpy as np angle0 = Parameter("x") angle1 = Parameter("y") qc = QuantumCircuit(2, 2) qc.rx(angle0, 0) qc.ry(angle1, 1) qc.cx(1, 0)
We can convert this circuit into a QNode with two arguments, corresponding to
xandy:measurements = qml.expval(qml.PauliZ(0)) qfunc = qml.from_qiskit(qc, measurements) qnode = qml.QNode(qfunc, dev)
The QNode can be evaluated and differentiated:
>>> x, y = np.array([0.4, 0.5], requires_grad=True) >>> qnode(x, y) tensor(0.80830707, requires_grad=True) >>> qml.grad(qnode)(x, y) (tensor(-0.34174675, requires_grad=True), tensor(-0.44158016, requires_grad=True))
This shows how easy it is to make a Qiskit circuit differentiable with PennyLane.
In addition to circuits, it is also possible to convert operators from Qiskit to PennyLane with a new function called
qml.from_qiskit_op. (#5251)A Qiskit SparsePauliOp can be converted to a PennyLane operator using
qml.from_qiskit_op:>>> from qiskit.quantum_info import SparsePauliOp >>> qiskit_op = SparsePauliOp(["II", "XY"]) >>> qiskit_op SparsePauliOp(['II', 'XY'], coeffs=[1.+0.j, 1.+0.j]) >>> pl_op = qml.from_qiskit_op(qiskit_op) >>> pl_op I(0) + X(1) @ Y(0)
Combined with
qml.from_qiskit, it becomes easy to quickly calculate quantities like expectation values by converting the whole workflow to PennyLane:qc = QuantumCircuit(2) # Create circuit qc.rx(0.785, 0) qc.ry(1.57, 1) measurements = qml.expval(pl_op) # Create QNode qfunc = qml.from_qiskit(qc, measurements) qnode = qml.QNode(qfunc, dev)
>>> qnode() # Evaluate! tensor(0.29317504, requires_grad=True)
Native mid-circuit measurements on Default Qubit 💡
Mid-circuit measurements can now be more scalable and efficient in finite-shots mode with
default.qubitby simulating them in a similar way to what happens on quantum hardware. (#5088) (#5120)Previously, mid-circuit measurements (MCMs) would be automatically replaced with an additional qubit using the
@qml.defer_measurementstransform. The circuit below would have required thousands of qubits to simulate.Now, MCMs are performed in a similar way to quantum hardware with finite shots on
default.qubit. For each shot and each time an MCM is encountered, the device evaluates the probability of projecting onto|0>or|1>and makes a random choice to collapse the circuit state. This approach works well when there are a lot of MCMs and the number of shots is not too high.import pennylane as qml dev = qml.device("default.qubit", shots=10) @qml.qnode(dev) def f(): for i in range(1967): qml.Hadamard(0) qml.measure(0) return qml.sample(qml.PauliX(0))
>>> f() tensor([-1, -1, -1, 1, 1, -1, 1, -1, 1, -1], requires_grad=True)
Work easily and efficiently with operators 🔧
Over the past few releases, PennyLane’s approach to operator arithmetic has been in the process of being overhauled. We have a few objectives:
To make it as easy to work with PennyLane operators as it would be with pen and paper.
To improve the efficiency of operator arithmetic.
The updated operator arithmetic functionality is still being finalized, but can be activated using
qml.operation.enable_new_opmath(). In the next release, the new behaviour will become the default, so we recommend enabling now to become familiar with the new system!The following updates have been made in this version of PennyLane:
You can now easily access Pauli operators via
I,X,Y, andZ: (#5116)>>> from pennylane import I, X, Y, Z >>> X(0) X(0)
The original long-form names
Identity,PauliX,PauliY, andPauliZremain available, but use of the short-form names is now recommended.The original long-form names
Identity,PauliX,PauliY, andPauliZremain available, but use of the short-form names is now recommended.A new
qml.commutatorfunction is now available that allows you to compute commutators between PennyLane operators. (#5051) (#5052) (#5098)>>> qml.commutator(X(0), Y(0)) 2j * Z(0)
Operators in PennyLane can have a backend Pauli representation, which can be used to perform faster operator arithmetic. Now, the Pauli representation will be automatically used for calculations when available. (#4989) (#5001) (#5003) (#5017) (#5027)
The Pauli representation can be optionally accessed via
op.pauli_rep:>>> qml.operation.enable_new_opmath() >>> op = X(0) + Y(0) >>> op.pauli_rep 1.0 * X(0) + 1.0 * Y(0)
Extensive improvements have been made to the string representations of PennyLane operators, making them shorter and possible to copy-paste as valid PennyLane code. (#5116) (#5138)
>>> 0.5 * X(0) 0.5 * X(0) >>> 0.5 * (X(0) + Y(1)) 0.5 * (X(0) + Y(1))
Sums with many terms are broken up into multiple lines, but can still be copied back as valid code:
>>> 0.5 * (X(0) @ X(1)) + 0.7 * (X(1) @ X(2)) + 0.8 * (X(2) @ X(3)) ( 0.5 * (X(0) @ X(1)) + 0.7 * (X(1) @ X(2)) + 0.8 * (X(2) @ X(3)) )
Linear combinations of operators and operator multiplication via
SumandProd, respectively, have been updated to reach feature parity withHamiltonianandTensor, respectively. This should minimize the effort to port over any existing code. (#5070) (#5132) (#5133)Updates include support for grouping via the
paulimodule:>>> obs = [X(0) @ Y(1), Z(0), Y(0) @ Z(1), Y(1)] >>> qml.pauli.group_observables(obs) [[Y(0) @ Z(1)], [X(0) @ Y(1), Y(1)], [Z(0)]]
New Clifford device 🦾
A new
default.clifforddevice enables efficient simulation of large-scale Clifford circuits defined in PennyLane through the use of stim as a backend. (#4936) (#4954) (#5144)Given a circuit with only Clifford gates, one can use this device to obtain the usual range of PennyLane measurements as well as the state represented in the Tableau form of Aaronson & Gottesman (2004):
import pennylane as qml dev = qml.device("default.clifford", tableau=True) @qml.qnode(dev) def circuit(): qml.CNOT(wires=[0, 1]) qml.PauliX(wires=[1]) qml.ISWAP(wires=[0, 1]) qml.Hadamard(wires=[0]) return qml.state()
>>> circuit() array([[0, 1, 1, 0, 0], [1, 0, 1, 1, 1], [0, 0, 0, 1, 0], [1, 0, 0, 1, 1]])
The
default.clifforddevice also supports thePauliError,DepolarizingChannel,BitFlipandPhaseFlipnoise channels when operating in finite-shot mode.
Improvements 🛠
Faster gradients with VJPs and other performance improvements
Vector-Jacobian products (VJPs) can result in faster computations when the output of your quantum Node has a low dimension. They can be enabled by setting
device_vjp=Truewhen loading a QNode. In the next release of PennyLane, VJPs are planned to be used by default, when available.In this release, we have unlocked:
Adjoint device VJPs can be used with
jax.jacobian, meaning thatdevice_vjp=Trueis always faster when using JAX withdefault.qubit. (#4963)PennyLane can now use lightning-provided VJPs. (#4914)
VJPs can be used with TensorFlow, though support has not yet been added for
tf.Functionand Tensorflow Autograph. (#4676)
Measuring
qml.probsis now faster due to an optimization in converting samples to counts. (#5145)The performance of circuit-cutting workloads with large numbers of generated tapes has been improved. (#5005)
Queueing (
AnnotatedQueue) has been removed fromqml.cut_circuitandqml.cut_circuit_mcto improve performance for large workflows. (#5108)
Community contributions 🥳
A new function called
qml.fermi.parity_transformhas been added for parity mapping of a fermionic Hamiltonian. (#4928)It is now possible to transform a fermionic Hamiltonian to a qubit Hamiltonian with parity mapping.
import pennylane as qml fermi_ham = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) qubit_ham = qml.fermi.parity_transform(fermi_ham, n=6)
>>> print(qubit_ham) -0.25j * Y(0) + (-0.25+0j) * (X(0) @ Z(1)) + (0.25+0j) * X(0) + 0.25j * (Y(0) @ Z(1))
The transform
split_non_commutingnow accepts measurements of typeprobs,sample, andcounts, which accept both wires and observables. (#4972)The efficiency of matrix calculations when an operator is symmetric over a given set of wires has been improved. (#3601)
The
pennylane/math/quantum.pymodule now has support for computing the minimum entropy of a density matrix. (#3959)>>> x = [1, 0, 0, 1] / np.sqrt(2) >>> x = qml.math.dm_from_state_vector(x) >>> qml.math.min_entropy(x, indices=[0]) 0.6931471805599455
A function called
apply_operationthat applies operations to device-compatible states has been added to the newqutrit_mixedmodule found inqml.devices. (#5032)A function called
measurehas been added to the newqutrit_mixedmodule found inqml.devicesthat measures device-compatible states for a collection of measurement processes. (#5049)A
partial_tracefunction has been added toqml.mathfor taking the partial trace of matrices. (#5152)
Other operator arithmetic improvements
The following capabilities have been added for Pauli arithmetic: (#4989) (#5001) (#5003) (#5017) (#5027) (#5018)
You can now multiply
PauliWordandPauliSentenceinstances by scalars (e.g.,0.5 * PauliWord({0: "X"})or0.5 * PauliSentence({PauliWord({0: "X"}): 1.})).You can now intuitively add and subtract
PauliWordandPauliSentenceinstances and scalars together (scalars are treated implicitly as multiples of the identity,I). For example,ps1 + pw1 + 1.for some Pauli wordpw1 = PauliWord({0: "X", 1: "Y"})and Pauli sentenceps1 = PauliSentence({pw1: 3.}).You can now element-wise multiply
PauliWord,PauliSentence, and operators together withqml.dot(e.g.,qml.dot([0.5, -1.5, 2], [pw1, ps1, id_word])withid_word = PauliWord({})).qml.matrixnow acceptsPauliWordandPauliSentenceinstances (e.g.,qml.matrix(PauliWord({0: "X"}))).It is now possible to compute commutators with Pauli operators natively with the new
commutatormethod.>>> op1 = PauliWord({0: "X", 1: "X"}) >>> op2 = PauliWord({0: "Y"}) + PauliWord({1: "Y"}) >>> op1.commutator(op2) 2j * Z(0) @ X(1) + 2j * X(0) @ Z(1)
Composite operations (e.g., those made with
qml.prodandqml.sum) and scalar-product operations convertHamiltonianandTensoroperands toSumandProdtypes, respectively. This helps avoid the mixing of incompatible operator types. (#5031) (#5063)qml.Identity()can be initialized without wires. Measuring it is currently not possible, though. (#5106)qml.dotnow returns aSumclass even when all the coefficients match. (#5143)qml.pauli.group_observablesnow supports groupingProdandSProdoperators. (#5070)The performance of converting a
PauliSentenceto aSumhas been improved. (#5141) (#5150)Akin to
qml.Hamiltonianfeatures, the coefficients and operators that make up composite operators formed viaSumorProdcan now be accessed with theterms()method. (#5132) (#5133) (#5164)>>> qml.operation.enable_new_opmath() >>> op = X(0) @ (0.5 * X(1) + X(2)) >>> op.terms() ([0.5, 1.0], [X(1) @ X(0), X(2) @ X(0)])
String representations of
ParametrizedHamiltonianhave been updated to match the style of other PL operators. (#5215)
Other improvements
The
pl-device-testsuite is now compatible with theqml.devices.Deviceinterface. (#5229)The
QSVToperation now determines itsdatafrom the block encoding and projector operator data. (#5226) (#5248)The
BlockEncodeoperator is now JIT-compatible with JAX. (#5110)The
qml.qsvtfunction usesqml.GlobalPhaseinstead ofqml.expto define a global phase. (#5105)The
tests/ops/functions/conftest.pytest has been updated to ensure that all operator types are tested for validity. (#4978)A new
pennylane.workflowmodule has been added. This module now containsqnode.py,execution.py,set_shots.py,jacobian_products.py, and the submoduleinterfaces. (#5023)A more informative error is now raised when calling
adjoint_jacobianwith trainable state-prep operations. (#5026)qml.workflow.get_transform_programandqml.workflow.construct_batchhave been added to inspect the transform program and batch of tapes at different stages. (#5084)All custom controlled operations such as
CRX,CZ,CNOT,ControlledPhaseShiftnow inherit fromControlledOp, giving them additional properties such ascontrol_wireandcontrol_values. Callingqml.ctrlonRX,RY,RZ,Rot, andPhaseShiftwith a single control wire will return gates of typesCRX,CRY, etc. as opposed to a generalControlledoperator. (#5069) (#5199)The CI will now fail if coverage data fails to upload to codecov. Previously, it would silently pass and the codecov check itself would never execute. (#5101)
qml.ctrlcalled on operators with custom controlled versions will now return instances of the custom class, and it will flatten nested controlled operators to a single multi-controlled operation. ForPauliX,CNOT,Toffoli, andMultiControlledX, callingqml.ctrlwill always resolve to the best option inCNOT,Toffoli, orMultiControlledXdepending on the number of control wires and control values. (#5125)Unwanted warning filters have been removed from tests and no
PennyLaneDeprecationWarnings are being raised unexpectedly. (#5122)New error tracking and propagation functionality has been added (#5115) (#5121)
The method
map_batch_transformhas been replaced with the method_batch_transformimplemented inTransformDispatcher. (#5212)TransformDispatchercan now dispatch onto a batch of tapes, making it easier to compose transforms when working in the tape paradigm. (#5163)qml.ctrlis now a simple wrapper that either calls PennyLane’s built increate_controlled_opor uses the Catalyst implementation. (#5247)Controlled composite operations can now be decomposed using ZYZ rotations. (#5242)
New functions called
qml.devices.modifiers.simulator_trackingandqml.devices.modifiers.single_tape_supporthave been added to add basic default behavior onto a device class. (#5200)
Breaking changes 💔
Passing additional arguments to a transform that decorates a QNode must now be done through the use of
functools.partial. (#5046)qml.ExpvalCosthas been removed. Users should useqml.expval()moving forward. (#5097)Caching of executions is now turned off by default when
max_diff == 1, as the classical overhead cost outweighs the probability that duplicate circuits exists. (#5243)The entry point convention registering compilers with PennyLane has changed. (#5140)
To allow for packages to register multiple compilers with PennyLane, the
entry_pointsconvention under the designated group namepennylane.compilershas been modified.Previously, compilers would register
qjit(JIT decorator),ops(compiler-specific operations), andcontext(for tracing and program capture).Now, compilers must register
compiler_name.qjit,compiler_name.ops, andcompiler_name.context, wherecompiler_nameis replaced by the name of the provided compiler.For more information, please see the documentation on adding compilers.
PennyLane source code is now compatible with the latest version of
black. (#5112) (#5119)gradient_analysis_and_validationhas been renamed tofind_and_validate_gradient_methods. Instead of returning a list, it now returns a dictionary of gradient methods for each parameter index, and no longer mutates the tape. (#5035)Multiplying two
PauliWordinstances no longer returns a tuple(new_word, coeff)but insteadPauliSentence({new_word: coeff}). The old behavior is still available with the private methodPauliWord._matmul(other)for faster processing. (#5045)Observable.return_typehas been removed. Instead, you should inspect the type of the surrounding measurement process. (#5044)ClassicalShadow.entropy()no longer needs anatolkeyword as a better method to estimate entropies from approximate density matrix reconstructions (with potentially negative eigenvalues). (#5048)Controlled operators with a custom controlled version decompose like how their controlled counterpart decomposes as opposed to decomposing into their controlled version. (#5069) (#5125)
For example:
>>> qml.ctrl(qml.RX(0.123, wires=1), control=0).decomposition() [ RZ(1.5707963267948966, wires=[1]), RY(0.0615, wires=[1]), CNOT(wires=[0, 1]), RY(-0.0615, wires=[1]), CNOT(wires=[0, 1]), RZ(-1.5707963267948966, wires=[1]) ]
QuantumScript.is_sampledandQuantumScript.all_sampledhave been removed. Users should now validate these properties manually. (#5072)qml.transforms.one_qubit_decompositionandqml.transforms.two_qubit_decompositionhave been removed. Instead, you should useqml.ops.one_qubit_decompositionandqml.ops.two_qubit_decomposition. (#5091)
Deprecations 👋
Calling
qml.matrixwithout providing awire_orderon objects where the wire order could be ambiguous now raises a warning. In the future, thewire_orderargument will be required in these cases. (#5039)Operator.validate_subspace(subspace)has been relocated to theqml.ops.qutrit.parametric_opsmodule and will be removed from the Operator class in an upcoming release. (#5067)Matrix and tensor products between
PauliWordandPauliSentenceinstances are done using the@operator,*will be used only for scalar multiplication. Note also the breaking change that the product of twoPauliWordinstances now returns aPauliSentenceinstead of a tuple(new_word, coeff). (#4989) (#5054)MeasurementProcess.nameandMeasurementProcess.dataare now deprecated, as they contain dummy values that are no longer needed. (#5047) (#5071) (#5076) (#5122)qml.pauli.pauli_multandqml.pauli.pauli_mult_with_phaseare now deprecated. Instead, you should useqml.simplify(qml.prod(pauli_1, pauli_2))to get the reduced operator. (#5057)The private functions
_pauli_mult,_binary_matrixand_get_pauli_mapfrom thepaulimodule have been deprecated, as they are no longer used anywhere and the same functionality can be achieved using newer features in thepaulimodule. (#5057)Sum.ops,Sum.coeffs,Prod.opsandProd.coeffswill be deprecated in the future. (#5164)
Documentation 📝
The module documentation for
pennylane.tapenow explains the difference betweenQuantumTapeandQuantumScript. (#5065)A typo in a code example in the
qml.transformsAPI has been fixed. (#5014)Documentation for
qml.datahas been updated and now mentions a way to access the same dataset simultaneously from multiple environments. (#5029)A clarification for the definition of
argnumadded to gradient methods has been made. (#5035)A typo in the code example for
qml.qchem.dipole_ofhas been fixed. (#5036)A development guide on deprecations and removals has been added. (#5083)
A note about the eigenspectrum of second-quantized Hamiltonians has been added to
qml.eigvals. (#5095)A warning about two mathematically equivalent Hamiltonians undergoing different time evolutions has been added to
qml.TrotterProductandqml.ApproxTimeEvolution. (#5137)A reference to the paper that provides the image of the
qml.QAOAEmbeddingtemplate has been added. (#5130)The docstring of
qml.samplehas been updated to advise the use of single-shot expectations instead when differentiating a circuit. (#5237)A quick start page has been added called “Importing Circuits”. This explains how to import quantum circuits and operations defined outside of PennyLane. (#5281)
Bug fixes 🐛
QubitChannelcan now be used with jitting. (#5288)Fixed a bug in the matplotlib drawer where the colour of
Barrierdid not match the requested style. (#5276)qml.drawandqml.draw_mplnow apply all applied transforms before drawing. (#5277)ctrl_decomp_zyzis now differentiable. (#5198)qml.ops.Pow.matrix()is now differentiable with TensorFlow with integer exponents. (#5178)The
qml.MottonenStatePreparationtemplate has been updated to include a global phase operation. (#5166)Fixed a queuing bug when using
qml.prodwith a quantum function that queues a single operator. (#5170)The
qml.TrotterProducttemplate has been updated to accept scalar products of operators as an input Hamiltonian. (#5073)Fixed a bug where caching together with JIT compilation and broadcasted tapes yielded wrong results
Operator.hashnow depends on the memory location,id, of a JAX tracer instead of its string representation. (#3917)qml.transforms.undo_swapscan now work with operators with hyperparameters or nesting. (#5081)qml.transforms.split_non_commutingwill now pass the original shots along. (#5081)If
argnumis provided to a gradient transform, only the parameters specified inargnumwill have their gradient methods validated. (#5035)StatePrepoperations expanded onto more wires are now compatible with backprop. (#5028)qml.equalworks well withqml.Sumoperators when wire labels are a mix of integers and strings. (#5037)The return value of
Controlled.generatornow contains a projector that projects onto the correct subspace based on the control value specified. (#5068)CosineWindowno longer raises an unexpected error when used on a subset of wires at the beginning of a circuit. (#5080)tf.functionnow works withTensorSpec(shape=None)by skipping batch size computation. (#5089)PauliSentence.wiresno longer imposes a false order. (#5041)qml.qchem.import_statenow applies the chemist-to-physicist sign convention when initializing a PennyLane state vector from classically pre-computed wavefunctions. That is, it interleaves spin-up/spin-down operators for the same spatial orbital index, as standard in PennyLane (instead of commuting all spin-up operators to the left, as is standard in quantum chemistry). (#5114)Multi-wire controlled
CNOTandPhaseShiftare now be decomposed correctly. (#5125) (#5148)draw_mplno longer raises an error when drawing a circuit containing an adjoint of a controlled operation. (#5149)default.mixedno longer throwsValueErrorwhen applying a state vector that is not of typecomplex128when used with tensorflow. (#5155)ctrl_decomp_zyzno longer raises aTypeErrorif the rotation parameters are of typetorch.Tensor(#5183)Comparing
ProdandSumobjects now works regardless of nested structure withqml.equalif the operators have a validpauli_repproperty. (#5177)Controlled
GlobalPhasewith non-zero control wires no longer throws an error. (#5194)A
QNodetransformed withmitigate_with_znenow accepts batch parameters. (#5195)The matrix of an empty
PauliSentenceinstance is now correct (all-zeros). Further, matrices of emptyPauliWordandPauliSentenceinstances can now be turned into matrices. (#5188)PauliSentenceinstances can handle matrix multiplication withPauliWordinstances. (#5208)CompositeOp.eigendecompositionis now JIT-compatible. (#5207)QubitDensityMatrixnow works with JAX-JIT on thedefault.mixeddevice. (#5203) (#5236)When a QNode specifies
diff_method="adjoint",default.qubitno longer tries to decompose non-trainable operations with non-scalar parameters such asQubitUnitary. (#5233)The overwriting of the class names of
I,X,Y, andZno longer happens in the initialization after causing problems with datasets. This now happens globally. (#5252)The
adjoint_metric_tensortransform now works withjax. (#5271)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Abhishek Abhishek, Mikhail Andrenkov, Utkarsh Azad, Trenten Babcock, Gabriel Bottrill, Thomas Bromley, Astral Cai, Skylar Chan, Isaac De Vlugt, Diksha Dhawan, Lillian Frederiksen, Pietropaolo Frisoni, Eugenio Gigante, Diego Guala, David Ittah, Soran Jahangiri, Jacky Jiang, Korbinian Kottmann, Christina Lee, Xiaoran Li, Vincent Michaud-Rioux, Romain Moyard, Pablo Antonio Moreno Casares, Erick Ochoa Lopez, Lee J. O’Riordan, Mudit Pandey, Alex Preciado, Matthew Silverman, Jay Soni.
Release 0.34.0¶
New features since last release
Statistics and drawing for mid-circuit measurements 🎨
It is now possible to return statistics of composite mid-circuit measurements. (#4888)
Mid-circuit measurement results can be composed using basic arithmetic operations and then statistics can be calculated by putting the result within a PennyLane measurement like
qml.expval(). For example:import pennylane as qml dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(phi, theta): qml.RX(phi, wires=0) m0 = qml.measure(wires=0) qml.RY(theta, wires=1) m1 = qml.measure(wires=1) return qml.expval(~m0 + m1) print(circuit(1.23, 4.56))
1.2430187928114291Another option, for ease-of-use when using
qml.sample(),qml.probs(), orqml.counts(), is to provide a simple list of mid-circuit measurement results:dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(phi, theta): qml.RX(phi, wires=0) m0 = qml.measure(wires=0) qml.RY(theta, wires=1) m1 = qml.measure(wires=1) return qml.sample(op=[m0, m1]) print(circuit(1.23, 4.56, shots=5))
[[0 1] [0 1] [0 0] [1 0] [0 1]]
Composite mid-circuit measurement statistics are supported on
default.qubitanddefault.mixed. To learn more about which measurements and arithmetic operators are supported, refer to the measurements page and the documentation for qml.measure.Mid-circuit measurements can now be visualized with the text-based
qml.draw()and the graphicalqml.draw_mpl()methods. (#4775) (#4803) (#4832) (#4901) (#4850) (#4917) (#4930) (#4957)Drawing of mid-circuit measurement capabilities including qubit reuse and reset, postselection, conditioning, and collecting statistics is now supported. Here is an all-encompassing example:
def circuit(): m0 = qml.measure(0, reset=True) m1 = qml.measure(1, postselect=1) qml.cond(m0 - m1 == 0, qml.S)(0) m2 = qml.measure(1) qml.cond(m0 + m1 == 2, qml.T)(0) qml.cond(m2, qml.PauliX)(1)
The text-based drawer outputs:
>>> print(qml.draw(circuit)()) 0: ──┤↗│ │0⟩────────S───────T────┤ 1: ───║────────┤↗₁├──║──┤↗├──║──X─┤ ╚═════════║════╬═══║═══╣ ║ ╚════╩═══║═══╝ ║ ╚══════╝
The graphical drawer outputs:
>>> print(qml.draw_mpl(circuit)())
Catalyst is seamlessly integrated with PennyLane ⚗️
Catalyst, our next-generation compilation framework, is now accessible within PennyLane, allowing you to more easily benefit from hybrid just-in-time (JIT) compilation.
To access these features, simply install
pennylane-catalyst:pip install pennylane-catalyst
The qml.compiler module provides support for hybrid quantum-classical compilation. (#4692) (#4979)
Through the use of the
qml.qjitdecorator, entire workflows can be JIT compiled — including both quantum and classical processing — down to a machine binary on first-function execution. Subsequent calls to the compiled function will execute the previously-compiled binary, resulting in significant performance improvements.import pennylane as qml dev = qml.device("lightning.qubit", wires=2) @qml.qjit @qml.qnode(dev) def circuit(theta): qml.Hadamard(wires=0) qml.RX(theta, wires=1) qml.CNOT(wires=[0,1]) return qml.expval(qml.PauliZ(wires=1))
>>> circuit(0.5) # the first call, compilation occurs here array(0.) >>> circuit(0.5) # the precompiled quantum function is called array(0.)
Currently, PennyLane supports the Catalyst hybrid compiler with the
qml.qjitdecorator. A significant benefit of Catalyst is the ability to preserve complex control flow around quantum operations — such asifstatements andforloops, and including measurement feedback — during compilation, while continuing to support end-to-end autodifferentiation.The following functions can now be used with the
qml.qjitdecorator:qml.grad,qml.jacobian,qml.vjp,qml.jvp, andqml.adjoint. (#4709) (#4724) (#4725) (#4726)When
qml.gradorqml.jacobianare used with@qml.qjit, they are patched to catalyst.grad and catalyst.jacobian, respectively.dev = qml.device("lightning.qubit", wires=1) @qml.qjit def workflow(x): @qml.qnode(dev) def circuit(x): qml.RX(np.pi * x[0], wires=0) qml.RY(x[1], wires=0) return qml.probs() g = qml.jacobian(circuit) return g(x)
>>> workflow(np.array([2.0, 1.0])) array([[ 3.48786850e-16, -4.20735492e-01], [-8.71967125e-17, 4.20735492e-01]])
JIT-compatible functionality for control flow has been added via
qml.for_loop,qml.while_loop, andqml.cond. (#4698) (#5006)qml.for_loopandqml.while_loopcan be deployed as decorators on functions that are the body of the loop. The arguments to both follow typical conventions:@qml.for_loop(lower_bound, upper_bound, step)
@qml.while_loop(cond_function)
Here is a concrete example with
qml.for_loop:qml.for_loopandqml.while_loopcan be deployed as decorators on functions that are the body of the loop. The arguments to both follow typical conventions:@qml.for_loop(lower_bound, upper_bound, step)
@qml.while_loop(cond_function)
Here is a concrete example with
qml.for_loop:dev = qml.device("lightning.qubit", wires=1) @qml.qjit @qml.qnode(dev) def circuit(n: int, x: float): @qml.for_loop(0, n, 1) def loop_rx(i, x): # perform some work and update (some of) the arguments qml.RX(x, wires=0) # update the value of x for the next iteration return jnp.sin(x) # apply the for loop final_x = loop_rx(x) return qml.expval(qml.PauliZ(0)), final_x
>>> circuit(7, 1.6) (array(0.97926626), array(0.55395718))
Decompose circuits into the Clifford+T gateset 🧩
The new
qml.clifford_t_decomposition()transform provides an approximate breakdown of an input circuit into the Clifford+T gateset. Behind the scenes, this decomposition is enacted via thesk_decomposition()function using the Solovay-Kitaev algorithm. (#4801) (#4802)The Solovay-Kitaev algorithm approximately decomposes a quantum circuit into the Clifford+T gateset. To account for this, a desired total circuit decomposition error,
epsilon, must be specified when usingqml.clifford_t_decomposition:dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.RX(1.1, 0) return qml.state() circuit = qml.clifford_t_decomposition(circuit, epsilon=0.1)
>>> print(qml.draw(circuit)()) 0: ──T†──H──T†──H──T──H──T──H──T──H──T──H──T†──H──T†──T†──H──T†──H──T──H──T──H──T──H──T──H──T†──H ───T†──H──T──H──GlobalPhase(0.39)─┤
The resource requirements of this circuit can also be evaluated:
>>> with qml.Tracker(dev) as tracker: ... circuit() >>> resources_lst = tracker.history["resources"] >>> resources_lst[0] wires: 1 gates: 34 depth: 34 shots: Shots(total=None) gate_types: {'Adjoint(T)': 8, 'Hadamard': 16, 'T': 9, 'GlobalPhase': 1} gate_sizes: {1: 33, 0: 1}
Use an iterative approach for quantum phase estimation 🔄
Iterative Quantum Phase Estimation is now available with
qml.iterative_qpe. (#4804)The subroutine can be used similarly to mid-circuit measurements:
import pennylane as qml dev = qml.device("default.qubit", shots=5) @qml.qnode(dev) def circuit(): # Initial state qml.PauliX(wires=[0]) # Iterative QPE measurements = qml.iterative_qpe(qml.RZ(2., wires=[0]), ancilla=[1], iters=3) return [qml.sample(op=meas) for meas in measurements]
>>> print(circuit()) [array([0, 0, 0, 0, 0]), array([1, 0, 0, 0, 0]), array([0, 1, 1, 1, 1])]
The \(i\)-th element in the list refers to the 5 samples generated by the \(i\)-th measurement of the algorithm.
Improvements 🛠
Community contributions 🥳
The
+=operand can now be used with aPauliSentence, which has also provides a performance boost. (#4662)The Approximate Quantum Fourier Transform (AQFT) is now available with
qml.AQFT. (#4715)qml.drawandqml.draw_mplnow render operator IDs. (#4749)The ID can be specified as a keyword argument when instantiating an operator:
>>> def circuit(): ... qml.RX(0.123, id="data", wires=0) >>> print(qml.draw(circuit)()) 0: ──RX(0.12,"data")─┤
Non-parametric operators such as
Barrier,Snapshot, andWirecuthave been grouped together and moved topennylane/ops/meta.py. Additionally, the relevant tests have been organized and placed in a new file,tests/ops/test_meta.py. (#4789)The
TRX,TRY, andTRZoperators are now differentiable via backpropagation ondefault.qutrit. (#4790)The function
qml.equalnow supportsControlledSequenceoperators. (#4829)XZX decomposition has been added to the list of supported single-qubit unitary decompositions. (#4862)
==and!=operands can now be used withTransformProgramandTransformContainersinstances. (#4858)A
qutrit_mixedmodule has been added toqml.devicesto store helper functions for a future qutrit mixed-state device. A function calledcreate_initial_statehas been added to this module that creates device-compatible initial states. (#4861)The function
qml.Snapshotnow supports arbitrary state-based measurements (i.e., measurements of typeStateMeasurement). (#4876)qml.equalnow supports the comparison ofQuantumScriptandBasisRotationobjects. (#4902) (#4919)The function
qml.draw_mplnow accept a keyword argumentfigto specify the output figure window. (#4956)
Better support for batching
qml.AmplitudeEmbeddingnow supports batching when used with Tensorflow. (#4818)default.qubitcan now evolve already batched states withqml.pulse.ParametrizedEvolution. (#4863)qml.ArbitraryUnitarynow supports batching. (#4745)Operator and tape batch sizes are evaluated lazily, helping run expensive computations less frequently and an issue with Tensorflow pre-computing batch sizes. (#4911)
Performance improvements and benchmarking
Autograd, PyTorch, and JAX can now use vector-Jacobian products (VJPs) provided by the device from the new device API. If a device provides a VJP, this can be selected by providing
device_vjp=Trueto a QNode orqml.execute. (#4935) (#4557) (#4654) (#4878) (#4841)>>> dev = qml.device('default.qubit') >>> @qml.qnode(dev, diff_method="adjoint", device_vjp=True) >>> def circuit(x): ... qml.RX(x, wires=0) ... return qml.expval(qml.PauliZ(0)) >>> with dev.tracker: ... g = qml.grad(circuit)(qml.numpy.array(0.1)) >>> dev.tracker.totals {'batches': 1, 'simulations': 1, 'executions': 1, 'vjp_batches': 1, 'vjps': 1} >>> g -0.09983341664682815
qml.expvalwith largeHamiltonianobjects is now faster and has a significantly lower memory footprint (and constant with respect to the number ofHamiltonianterms) when theHamiltonianis aPauliSentence. This is due to the introduction of a specializeddotmethod in thePauliSentenceclass which performsPauliSentence-stateproducts. (#4839)default.qubitno longer uses a dense matrix forMultiControlledXfor more than 8 operation wires. (#4673)Some relevant Pytests have been updated to enable its use as a suite of benchmarks. (#4703)
default.qubitnow appliesGroverOperatorfaster by not using its matrix representation but a custom rule forapply_operation. Also, the matrix representation ofGroverOperatornow runs faster. (#4666)A new pipeline to run benchmarks and plot graphs comparing with a fixed reference has been added. This pipeline will run on a schedule and can be activated on a PR with the label
ci:run_benchmarks. (#4741)default.qubitnow supports adjoint differentiation for arbitrary diagonal state-based measurements. (#4865)The benchmarks pipeline has been expanded to export all benchmark data to a single JSON file and a CSV file with runtimes. This includes all references and local benchmarks. (#4873)
Final phase of updates to transforms
qml.quantum_monte_carloandqml.simplifynow use the new transform system. (#4708) (#4949)The formal requirement that type hinting be provided when using the
qml.transformdecorator has been removed. Type hinting can still be used, but is now optional. Please use a type checker such as mypy if you wish to ensure types are being passed correctly. (#4942)
Other improvements
Add PyTree-serialization interface for the
Wiresclass. (#4998)PennyLane now supports Python 3.12. (#4985)
SampleMeasurementnow has an optional methodprocess_countsfor computing the measurement results from a counts dictionary. (#4941)A new function called
ops.functions.assert_validhas been added for checking if anOperatorclass is defined correctly. (#4764)Shotsobjects can now be multiplied by scalar values. (#4913)GlobalPhasenow decomposes to nothing in case devices do not support global phases. (#4855)Custom operations can now provide their matrix directly through the
Operator.matrix()method without needing to update thehas_matrixproperty.has_matrixwill now automatically beTrueifOperator.matrixis overridden, even ifOperator.compute_matrixis not. (#4844)The logic for re-arranging states before returning them has been improved. (#4817)
When multiplying
SparseHamiltonians by a scalar value, the result now stays as aSparseHamiltonian. (#4828)trainable_paramscan now be set upon initialization of aQuantumScriptinstead of having to set the parameter after initialization. (#4877)default.qubitnow calculates the expectation value ofHermitianoperators in a differentiable manner. (#4866)The
rotdecomposition now has support for returning a global phase. (#4869)The
"pennylane_sketch"MPL-drawer style has been added. This is the same as the"pennylane"style, but with sketch-style lines. (#4880)Operators now define a
pauli_repproperty, an instance ofPauliSentence, defaulting toNoneif the operator has not defined it (or has no definition in the Pauli basis). (#4915)qml.ShotAdaptiveOptimizercan now use a multinomial distribution for spreading shots across the terms of a Hamiltonian measured in a QNode. Note that this is equivalent to what can be done withqml.ExpvalCost, but this is the preferred method becauseExpvalCostis deprecated. (#4896)Decomposition of
qml.PhaseShiftnow usesqml.GlobalPhasefor retaining the global phase information. (#4657) (#4947)qml.equalforControlledoperators no longer returnsFalsewhen equivalent but differently-ordered sets of control wires and control values are compared. (#4944)All PennyLane
Operatorsubclasses are automatically tested byops.functions.assert_validto ensure that they follow PennyLaneOperatorstandards. (#4922)Probability measurements can now be calculated from a
countsdictionary with the addition of aprocess_countsmethod in theProbabilityMPclass. (#4952)ClassicalShadow.entropynow uses the algorithm outlined in 1106.5458 to project the approximate density matrix (with potentially negative eigenvalues) onto the closest valid density matrix. (#4959)The
ControlledSequence.compute_decompositiondefault now decomposes thePowoperators, improving compatibility with machine learning interfaces. (#4995)
Breaking changes 💔
The function
qml.transforms.classical_jacobianhas been moved to the gradients module and is now accessible asqml.gradients.classical_jacobian. (#4900)The transforms submodule
qml.transforms.qcutis now its own module:qml.qcut. (#4819)The decomposition of
GroverOperatornow has an additional global phase operation. (#4666)qml.condand theConditionaloperation have been moved from thetransformsfolder to theops/op_mathfolder.qml.transforms.Conditionalwill now be available asqml.ops.Conditional. (#4860)The
prepkeyword argument has been removed fromQuantumScriptandQuantumTape.StatePrepBaseoperations should be placed at the beginning of theopslist instead. (#4756)qml.gradients.pulse_generatoris now namedqml.gradients.pulse_odegento adhere to paper naming conventions. (#4769)Specifying
control_valuespassed toqml.ctrlas a string is no longer supported. (#4816)The
rotdecomposition will now normalize its rotation angles to the range[0, 4pi]for consistency (#4869)QuantumScript.graphis now built usingtape.measurementsinstead oftape.observablesbecause it depended on the now-deprecatedObservable.return_typeproperty. (#4762)The
"pennylane"MPL-drawer style now draws straight lines instead of sketch-style lines. (#4880)The default value for the
term_samplingargument ofShotAdaptiveOptimizeris nowNoneinstead of"weighted_random_sampling". (#4896)
Deprecations 👋
single_tape_transform,batch_transform,qfunc_transform, andop_transformare deprecated. Use the newqml.transformfunction instead. (#4774)Observable.return_typeis deprecated. Instead, you should inspect the type of the surrounding measurement process. (#4762) (#4798)All deprecations now raise a
qml.PennyLaneDeprecationWarninginstead of aUserWarning. (#4814)QuantumScript.is_sampledandQuantumScript.all_sampledare deprecated. Users should now validate these properties manually. (#4773)With an algorithmic improvement to
ClassicalShadow.entropy, the keywordatolbecomes obsolete and will be removed in v0.35. (#4959)
Documentation 📝
Documentation for unitaries and operations’ decompositions has been moved from
qml.transformstoqml.ops.ops_math. (#4906)Documentation for
qml.metric_tensorandqml.adjoint_metric_tensorandqml.transforms.classical_jacobianis now accessible via the gradients API pageqml.gradientsin the documentation. (#4900)Documentation for
qml.specshas been moved to theresourcemodule. (#4904)Documentation for QCut has been moved to its own API page:
qml.qcut. (#4819)The documentation page for
qml.measurementsnow links top-level accessible functions (e.g.,qml.expval) to their top-level pages rather than their module-level pages (e.g.,qml.measurements.expval). (#4750)Information for the documentation of
qml.matrixabout wire ordering has been added for usingqml.matrixon a QNode which uses a device withdevice.wires=None. (#4874)
Bug fixes 🐛
TransformDispatchernow stops queuing when performing the transform when applying it to a qfunc. Only the output of the transform will be queued. (#4983)qml.map_wiresnow works properly withqml.condandqml.measure. (#4884)Powoperators are now picklable. (#4966)Finite differences and SPSA can now be used with tensorflow-autograph on setups that were seeing a bus error. (#4961)
qml.condno longer incorrectly queues operators used arguments. (#4948)Attributeobjects now returnFalseinstead of raising aTypeErrorwhen checking if an object is inside the set. (#4933)Fixed a bug where the parameter-shift rule of
qml.ctrl(op)was wrong ifophad a generator that has two or more eigenvalues and is stored as aSparseHamiltonian. (#4899)Fixed a bug where trainable parameters in the post-processing of finite-differences were incorrect for JAX when applying the transform directly on a QNode. (#4879)
qml.gradandqml.jacobiannow explicitly raise errors if trainable parameters are integers. (#4836)JAX-JIT now works with shot vectors. (#4772)
JAX can now differentiate a batch of circuits where one tape does not have trainable parameters. (#4837)
The decomposition of
GroverOperatornow has the same global phase as its matrix. (#4666)The
tape.to_openqasmmethod no longer mistakenly includes interface information in the parameter string when converting tapes using non-NumPy interfaces. (#4849)qml.defer_measurementsnow correctly transforms circuits when terminal measurements include wires used in mid-circuit measurements. (#4787)Fixed a bug where the adjoint differentiation method would fail if an operation that has a parameter with
grad_method=Noneis present. (#4820)MottonenStatePreparationandBasisStatePreparationnow raise an error when decomposing a broadcasted state vector. (#4767)Gradient transforms now work with overridden shot vectors and
default.qubit. (#4795)Any
ScalarSymbolicOp, likeEvolution, now states that it has a matrix if the target is aHamiltonian. (#4768)In
default.qubit, initial states are now initialized with the simulator’s wire order, not the circuit’s wire order. (#4781)qml.compilewill now always decompose toexpand_depth, even if a target basis set is not specified. (#4800)qml.transforms.transpilecan now handle measurements that are broadcasted onto all wires. (#4793)Parametrized circuits whose operators do not act on all wires return PennyLane tensors instead of NumPy arrays, as expected. (#4811) (#4817)
qml.transforms.merge_amplitude_embeddingno longer depends on queuing, allowing it to work as expected with QNodes. (#4831)qml.pow(op)andqml.QubitUnitary.pow()now also work with Tensorflow data raised to an integer power. (#4827)The text drawer has been fixed to correctly label
qml.qinfomeasurements, as well asqml.classical_shadowqml.shadow_expval. (#4803)Removed an implicit assumption that an empty
PauliSentencegets treated as identity under multiplication. (#4887)Using a
CNOTorPauliZoperation with large batched states and the Tensorflow interface no longer raises an unexpected error. (#4889)qml.map_wiresno longer fails when mapping nested quantum tapes. (#4901)Conversion of circuits to openqasm now decomposes to a depth of 10, allowing support for operators requiring more than 2 iterations of decomposition, such as the
ApproxTimeEvolutiongate. (#4951)MPLDrawerdoes not add the bonus space for classical wires when no classical wires are present. (#4987)Projectornow works with parameter-broadcasting. (#4993)The jax-jit interface can now be used with float32 mode. (#4990)
Keras models with a
qnn.KerasLayerno longer fail to save and load weights properly when they are named “weights”. (#5008)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso, Ali Asadi, Utkarsh Azad, Gabriel Bottrill, Thomas Bromley, Astral Cai, Minh Chau, Isaac De Vlugt, Amintor Dusko, Pieter Eendebak, Lillian Frederiksen, Pietropaolo Frisoni, Josh Izaac, Juan Giraldo, Emiliano Godinez Ramirez, Ankit Khandelwal, Korbinian Kottmann, Christina Lee, Vincent Michaud-Rioux, Anurav Modak, Romain Moyard, Mudit Pandey, Matthew Silverman, Jay Soni, David Wierichs, Justin Woodring, Sergei Mironov.
Release 0.33.1¶
Bug fixes 🐛
Fix gradient performance regression due to expansion of VJP products. (#4806)
qml.defer_measurementsnow correctly transforms circuits when terminal measurements include wires used in mid-circuit measurements. (#4787)Any
ScalarSymbolicOp, likeEvolution, now states that it has a matrix if the target is aHamiltonian. (#4768)In
default.qubit, initial states are now initialized with the simulator’s wire order, not the circuit’s wire order. (#4781)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Christina Lee, Lee James O’Riordan, Mudit Pandey
Release 0.33.0¶
New features since last release
Postselection and statistics in mid-circuit measurements 📌
It is now possible to request postselection on a mid-circuit measurement. (#4604)
This can be achieved by specifying the
postselectkeyword argument inqml.measureas either0or1, corresponding to the basis states.import pennylane as qml dev = qml.device("default.qubit") @qml.qnode(dev, interface=None) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) qml.measure(0, postselect=1) return qml.expval(qml.PauliZ(1)), qml.sample(wires=1)
This circuit prepares the \(| \Phi^{+} \rangle\) Bell state and postselects on measuring \(|1\rangle\) in wire
0. The output of wire1is then also \(|1\rangle\) at all times:>>> circuit(shots=10) (-1.0, array([1, 1, 1, 1, 1, 1]))
Note that the number of shots is less than the requested amount because we have thrown away the samples where \(|0\rangle\) was measured in wire
0.Measurement statistics can now be collected for mid-circuit measurements. (#4544)
dev = qml.device("default.qubit") @qml.qnode(dev) def circ(x, y): qml.RX(x, wires=0) qml.RY(y, wires=1) m0 = qml.measure(1) return qml.expval(qml.PauliZ(0)), qml.expval(m0), qml.sample(m0)
>>> circ(1.0, 2.0, shots=10000) (0.5606, 0.7089, array([0, 1, 1, ..., 1, 1, 1]))
Support is provided for both finite-shot and analytic modes and devices default to using the deferred measurement principle to enact the mid-circuit measurements.
Exponentiate Hamiltonians with flexible Trotter products 🐖
Higher-order Trotter-Suzuki methods are now easily accessible through a new operation called
TrotterProduct. (#4661)Trotterization techniques are an affective route towards accurate and efficient Hamiltonian simulation. The Suzuki-Trotter product formula allows for the ability to express higher-order approximations to the matrix exponential of a Hamiltonian, and it is now available to use in PennyLane via the
TrotterProductoperation. Simply specify theorderof the approximation and the evolutiontime.coeffs = [0.25, 0.75] ops = [qml.PauliX(0), qml.PauliZ(0)] H = qml.dot(coeffs, ops) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): qml.Hadamard(0) qml.TrotterProduct(H, time=2.4, order=2) return qml.state()
>>> circuit() [-0.13259524+0.59790098j 0. +0.j -0.13259524-0.77932754j 0. +0.j ]
Approximating matrix exponentiation with random product formulas, qDrift, is now available with the new
QDriftoperation. (#4671)As shown in 1811.08017, qDrift is a Markovian process that can provide a speedup in Hamiltonian simulation. At a high level, qDrift works by randomly sampling from the Hamiltonian terms with a probability that depends on the Hamiltonian coefficients. This method for Hamiltonian simulation is now ready to use in PennyLane with the
QDriftoperator. Simply specify the evolutiontimeand the number of samples drawn from the Hamiltonian,n:coeffs = [0.25, 0.75] ops = [qml.PauliX(0), qml.PauliZ(0)] H = qml.dot(coeffs, ops) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): qml.Hadamard(0) qml.QDrift(H, time=1.2, n = 10) return qml.probs()
>>> circuit() array([0.61814334, 0. , 0.38185666, 0. ])
Building blocks for quantum phase estimation 🧱
A new operator called
CosineWindowhas been added to prepare an initial state based on a cosine wave function. (#4683)As outlined in 2110.09590, the cosine tapering window is part of a modification to quantum phase estimation that can provide a cubic improvement to the algorithm’s error rate. Using
CosineWindowwill prepare a state whose amplitudes follow a cosinusoidal distribution over the computational basis.import matplotlib.pyplot as plt dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) def example_circuit(): qml.CosineWindow(wires=range(4)) return qml.state() output = example_circuit() plt.style.use("pennylane.drawer.plot") plt.bar(range(len(output)), output) plt.show()
Controlled gate sequences raised to decreasing powers, a sub-block in quantum phase estimation, can now be created with the new
ControlledSequenceoperator. (#4707)To use
ControlledSequence, specify the controlled unitary operator and the control wires,control:dev = qml.device("default.qubit", wires = 4) @qml.qnode(dev) def circuit(): for i in range(3): qml.Hadamard(wires = i) qml.ControlledSequence(qml.RX(0.25, wires = 3), control = [0, 1, 2]) qml.adjoint(qml.QFT)(wires = range(3)) return qml.probs(wires = range(3))
>>> print(circuit()) [0.92059345 0.02637178 0.00729619 0.00423258 0.00360545 0.00423258 0.00729619 0.02637178]
New device capabilities, integration with Catalyst, and more! ⚗️
default.qubitnow uses the newqml.devices.DeviceAPI and functionality inqml.devices.qubit. If you experience any issues with the updateddefault.qubit, please let us know by posting an issue. The old version of the device is still accessible by the short namedefault.qubit.legacy, or directly viaqml.devices.DefaultQubitLegacy. (#4594) (#4436) (#4620) (#4632)This changeover has a number of benefits for
default.qubit, including:The number of wires is now optional — simply having
qml.device("default.qubit")is valid! If wires are not provided at instantiation, the device automatically infers the required number of wires for each circuit provided for execution.dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.PauliZ(0) qml.RZ(0.1, wires=1) qml.Hadamard(2) return qml.state()
>>> print(qml.draw(circuit)()) 0: ──Z────────┤ State 1: ──RZ(0.10)─┤ State 2: ──H────────┤ State
default.qubitis no longer silently swapped out with an interface-appropriate device when the backpropagation differentiation method is used. For example, consider:import jax dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, diff_method="backprop") def f(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)) f(jax.numpy.array(0.2))
In previous versions of PennyLane, the device will be swapped for the JAX equivalent:
>>> f.device <DefaultQubitJax device (wires=1, shots=None) at 0x7f8c8bff50a0> >>> f.device == dev False
Now,
default.qubitcan itself dispatch to all the interfaces in a backprop-compatible way and hence does not need to be swapped:>>> f.device <default.qubit device (wires=1) at 0x7f20d043b040> >>> f.device == dev True
A QNode that has been decorated with
qjitfrom PennyLane’s Catalyst library for just-in-time hybrid compilation is now compatible withqml.draw. (#4609)import catalyst @catalyst.qjit @qml.qnode(qml.device("lightning.qubit", wires=3)) def circuit(x, y, z, c): """A quantum circuit on three wires.""" @catalyst.for_loop(0, c, 1) def loop(i): qml.Hadamard(wires=i) qml.RX(x, wires=0) loop() qml.RY(y, wires=1) qml.RZ(z, wires=2) return qml.expval(qml.PauliZ(0)) draw = qml.draw(circuit, decimals=None)(1.234, 2.345, 3.456, 1)
>>> print(draw) 0: ──RX──H──┤ <Z> 1: ──H───RY─┤ 2: ──RZ─────┤
Improvements 🛠
More PyTrees!
MeasurementProcessandQuantumScriptobjects are now registered as JAX PyTrees. (#4607) (#4608)It is now possible to JIT-compile functions with arguments that are a
MeasurementProcessor aQuantumScript:import jax tape0 = qml.tape.QuantumTape([qml.RX(1.0, 0), qml.RY(0.5, 0)], [qml.expval(qml.PauliZ(0))]) dev = qml.device('lightning.qubit', wires=5) execute_kwargs = {"device": dev, "gradient_fn": qml.gradients.param_shift, "interface":"jax"} jitted_execute = jax.jit(qml.execute, static_argnames=execute_kwargs.keys()) jitted_execute((tape0, ), **execute_kwargs)
Improving QChem and existing algorithms
Computationally expensive functions in
integrals.py,electron_repulsionand_hermite_coulomb, have been modified to replace indexing with slicing for better compatibility with JAX. (#4685)qml.qchem.import_statehas been extended to import more quantum chemistry wavefunctions, from MPS, DMRG and SHCI classical calculations performed with the Block2 and Dice libraries. #4523 #4524 #4626 #4634Check out our how-to guide to learn more about how PennyLane integrates with your favourite quantum chemistry libraries.
The qchem
fermionic_dipoleandparticle_numberfunctions have been updated to use aFermiSentence. The deprecated features for using tuples to represent fermionic operations are removed. (#4546) (#4556)The tensor-network template
qml.MPSnow supports changing theoffsetbetween subsequent blocks for more flexibility. (#4531)Builtin types support with
qml.pauli_decomposehave been improved. (#4577)AmplitudeEmbeddingnow inherits fromStatePrep, allowing for it to not be decomposed when at the beginning of a circuit, thus behaving likeStatePrep. (#4583)qml.cut_circuitis now compatible with circuits that compute the expectation values of Hamiltonians with two or more terms. (#4642)
Next-generation device API
default.qubitnow tracks the number of equivalent qpu executions and total shots when the device is sampling. Note that"simulations"denotes the number of simulation passes, whereas"executions"denotes how many different computational bases need to be sampled in. Additionally, the newdefault.qubittracks the results ofdevice.execute. (#4628) (#4649)DefaultQubitcan now accept ajax.random.PRNGKeyas aseedto set the key for the JAX pseudo random number generator when using the JAX interface. This corresponds to theprng_keyondefault.qubit.jaxin the old API. (#4596)The
JacobianProductCalculatorabstract base class and implementationsTransformJacobianProductsDeviceDerivatives, andDeviceJacobianProductshave been added topennylane.interfaces.jacobian_products. (#4435) (#4527) (#4637)DefaultQubitdispatches to a faster implementation for applyingParametrizedEvolutionto a state when it is more efficient to evolve the state than the operation matrix. (#4598) (#4620)Wires can be provided to the new device API. (#4538) (#4562)
qml.sample()in the new device API now returns anp.int64array instead ofnp.bool8. (#4539)The new device API now has a
repr()method. (#4562)DefaultQubitnow works as expected with measurement processes that don’t specify wires. (#4580)Various improvements to measurements have been made for feature parity between
default.qubit.legacyand the newDefaultQubit. This includes not trying to squeeze batchedCountsMPresults and implementingMutualInfoMP.map_wires. (#4574)devices.qubit.simulatenow accepts an interface keyword argument. If a QNode withDefaultQubitspecifies an interface, the result will be computed with that interface. (#4582)ShotAdaptiveOptimizerhas been updated to pass shots to QNode executions instead of overriding device shots before execution. This makes it compatible with the new device API. (#4599)pennylane.devices.preprocessnow offers the transformsdecompose,validate_observables,validate_measurements,validate_device_wires,validate_multiprocessing_workers,warn_about_trainable_observables, andno_samplingto assist in constructing devices under the new device API. (#4659)Updated
qml.device,devices.preprocessingand thetape_expand.set_decompositioncontext manager to bringDefaultQubitto feature parity withdefault.qubit.legacywith regards to using custom decompositions. TheDefaultQubitdevice can now be included in aset_decompositioncontext or initialized with acustom_decompsdictionary, as well as a custommax_depthfor decomposition. (#4675)
Other improvements
The
StateMPmeasurement now accepts a wire order (e.g., a device wire order). Theprocess_statemethod will re-order the given state to go from the inputted wire-order to the process’s wire-order. If the process’s wire-order contains extra wires, it will assume those are in the zero-state. (#4570) (#4602)Methods called
add_transformandinsert_front_transformhave been added toTransformProgram. (#4559)Instances of the
TransformProgramclass can now be added together. (#4549)Transforms can now be applied to devices following the new device API. (#4667)
All gradient transforms have been updated to the new transform program system. (#4595)
Multi-controlled operations with a single-qubit special unitary target can now automatically decompose. (#4697)
pennylane.defer_measurementswill now exit early if the input does not contain mid circuit measurements. (#4659)The density matrix aspects of
StateMPhave been split into their own measurement process calledDensityMatrixMP. (#4558)StateMeasurement.process_statenow assumes that the input is flat.ProbabilityMP.process_statehas been updated to reflect this assumption and avoid redundant reshaping. (#4602)qml.expreturns a more informative error message when decomposition is unavailable for non-unitary operators. (#4571)Added
qml.math.get_deep_interfaceto get the interface of a scalar hidden deep in lists or tuples. (#4603)Updated
qml.math.ndimandqml.math.shapeto work with built-in lists or tuples that contain interface-specific scalar dat (e.g.,[(tf.Variable(1.1), tf.Variable(2.2))]). (#4603)When decomposing a unitary matrix with
one_qubit_decompositionand opting to include theGlobalPhasein the decomposition, the phase is no longer cast todtype=complex. (#4653)_qfunc_outputhas been removed fromQuantumScript, as it is no longer necessary. There is still a_qfunc_outputproperty onQNodeinstances. (#4651)qml.data.loadproperly handles parameters that come after'full'(#4663)The
qml.jordan_wignerfunction has been modified to optionally remove the imaginary components of the computed qubit operator, if imaginary components are smaller than a threshold. (#4639)qml.data.loadcorrectly performs a full download of the dataset after a partial download of the same dataset has already been performed. (#4681)The performance of
qml.data.load()has been improved when partially loading a dataset (#4674)Plots generated with the
pennylane.drawer.plotstyle ofmatplotlib.pyplotnow have black axis labels and are generated at a default DPI of 300. (#4690)Shallow copies of the
QNodenow also copy theexecute_kwargsand transform program. When applying a transform to aQNode, the new qnode is only a shallow copy of the original and thus keeps the same device. (#4736)QubitDeviceandCountsMPare updated to disregard samples containing failed hardware measurements (record asnp.NaN) when tallying samples, rather than counting failed measurements as ground-state measurements, and to displayqml.countscoming from these hardware devices correctly. (#4739)
Breaking changes 💔
qml.defer_measurementsnow raises an error if a transformed circuit measuresqml.probs,qml.sample, orqml.countswithout any wires or observable, or if it measuresqml.state. (#4701)The device test suite now converts device keyword arguments to integers or floats if possible. (#4640)
MeasurementProcess.eigvals()now raises anEigvalsUndefinedErrorif the measurement observable does not have eigenvalues. (#4544)The
__eq__and__hash__methods ofOperatorandMeasurementProcessno longer rely on the object’s address in memory. Using==with operators and measurement processes will now behave the same asqml.equal, and objects of the same type with the same data and hyperparameters will have the same hash. (#4536)In the following scenario, the second and third code blocks show the previous and current behaviour of operator and measurement process equality, determined by
==:op1 = qml.PauliX(0) op2 = qml.PauliX(0) op3 = op1
Old behaviour:
>>> op1 == op2 False >>> op1 == op3 True
New behaviour:
>>> op1 == op2 True >>> op1 == op3 True
The
__hash__dunder method defines the hash of an object. The default hash of an object is determined by the objects memory address. However, the new hash is determined by the properties and attributes of operators and measurement processes. Consider the scenario below. The second and third code blocks show the previous and current behaviour.op1 = qml.PauliX(0) op2 = qml.PauliX(0)
Old behaviour:
>>> print({op1, op2}) {PauliX(wires=[0]), PauliX(wires=[0])}
New behaviour:
>>> print({op1, op2}) {PauliX(wires=[0])}
The old return type and associated functions
qml.enable_returnandqml.disable_returnhave been removed. (#4503)The
modekeyword argument inQNodehas been removed. Please usegrad_on_executioninstead. (#4503)The CV observables
qml.Xandqml.Phave been removed. Please useqml.QuadXandqml.QuadPinstead. (#4533)The
sampler_seedargument ofqml.gradients.spsa_gradhas been removed. Instead, thesampler_rngargument should be set, either to an integer value, which will be used to create a PRNG internally, or to a NumPy pseudo-random number generator (PRNG) created vianp.random.default_rng(seed). (#4550)The
QuantumScript.set_parametersmethod and theQuantumScript.datasetter have been removed. Please useQuantumScript.bind_new_parametersinstead. (#4548)The method
tape.unwrap()and correspondingUnwrapTapeandUnwrapclasses have been removed. Instead oftape.unwrap(), useqml.transforms.convert_to_numpy_parameters. (#4535)The
RandomLayers.compute_decompositionkeyword argumentratio_imprivitivehas been changed toratio_imprimto match the call signature of the operation. (#4552)The private
TmpPauliRotoperator used forSpecialUnitaryno longer decomposes to nothing when the theta value is trainable. (#4585)ProbabilityMP.marginal_probhas been removed. Its contents have been moved intoprocess_state, which effectively just calledmarginal_probwithnp.abs(state) ** 2. (#4602)
Deprecations 👋
The following decorator syntax for transforms has been deprecated and will raise a warning: (#4457)
@transform_fn(**transform_kwargs) @qml.qnode(dev) def circuit(): ...
If you are using a transform that has supporting
transform_kwargs, please call the transform directly usingcircuit = transform_fn(circuit, **transform_kwargs), or usefunctools.partial:@functools.partial(transform_fn, **transform_kwargs) @qml.qnode(dev) def circuit(): ...
The
prepkeyword argument inQuantumScripthas been deprecated and will be removed fromQuantumScript.StatePrepBaseoperations should be placed at the beginning of theopslist instead. (#4554)qml.gradients.pulse_generatorhas been renamed toqml.gradients.pulse_odegento adhere to paper naming conventions. During v0.33,pulse_generatoris still available but raises a warning. (#4633)
Documentation 📝
A warning section in the docstring for
DefaultQubitregarding the start method used in multiprocessing has been added. This may help users circumvent issues arising in Jupyter notebooks on macOS for example. (#4622)Documentation improvements to the new device API have been made. The documentation now correctly states that interface-specific parameters are only passed to the device for backpropagation derivatives. (#4542)
Functions for qubit-simulation to the
qml.devicessub-page of the “Internal” section have been added. Note that these functions are unstable while device upgrades are underway. (#4555)A documentation improvement to the usage example in the
qml.QuantumMonteCarlopage has been made. An integral was missing the differential \(dx\). (#4593)A documentation improvement for the use of the
pennylanestyle ofqml.drawerand thepennylane.drawer.plotstyle ofmatplotlib.pyplothas been made by clarifying the use of the default font. (#4690)
Bug fixes 🐛
Jax jit now works when a probability measurement is broadcasted onto all wires. (#4742)
Fixed
LocalHilbertSchmidt.compute_decompositionso that the template can be used in a QNode. (#4719)Fixes
transforms.transpilewith arbitrary measurement processes. (#4732)Providing
work_wires=Nonetoqml.GroverOperatorno longer interpretsNoneas a wire. (#4668)Fixed an issue where the
__copy__method of theqml.Select()operator attempted to access un-initialized data. (#4551)Fixed the
skip_firstoption inexpand_tape_state_prep. (#4564)convert_to_numpy_parametersnow usesqml.ops.functions.bind_new_parameters. This reinitializes the operation and makes sure everything references the new NumPy parameters. (#4540)tf.functionno longer breaksProbabilityMP.process_state, which is needed by new devices. (#4470)Fixed unit tests for
qml.qchem.mol_data. (#4591)Fixed
ProbabilityMP.process_stateso that it allows for proper Autograph compilation. Without this, decorating a QNode that returns anexpvalwithtf.functionwould fail when computing the expectation. (#4590)The
torch.nn.Moduleproperties are now accessible on apennylane.qnn.TorchLayer. (#4611)qml.math.takewith Pytorch now returnstensor[..., indices]when the user requests the last axis (axis=-1). Without the fix, it would wrongly returntensor[indices]. (#4605)Ensured the logging
TRACElevel works with gradient-free execution. (#4669)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso, Utkarsh Azad, Thomas Bromley, Isaac De Vlugt, Jack Brown, Stepan Fomichev, Joana Fraxanet, Diego Guala, Soran Jahangiri, Edward Jiang, Korbinian Kottmann, Ivana Kurečić Christina Lee, Lillian M. A. Frederiksen, Vincent Michaud-Rioux, Romain Moyard, Daniel F. Nino, Lee James O’Riordan, Mudit Pandey, Matthew Silverman, Jay Soni.
Release 0.32.0¶
New features since last release
Encode matrices using a linear combination of unitaries ⛓️️
It is now possible to encode an operator
Ainto a quantum circuit by decomposing it into a linear combination of unitaries using PREP (qml.StatePrep) and SELECT (qml.Select) routines. (#4431) (#4437) (#4444) (#4450) (#4506) (#4526)Consider an operator
Acomposed of a linear combination of Pauli terms:>>> A = qml.PauliX(2) + 2 * qml.PauliY(2) + 3 * qml.PauliZ(2)
A decomposable block-encoding circuit can be created:
def block_encode(A, control_wires): probs = A.coeffs / np.sum(A.coeffs) state = np.pad(np.sqrt(probs, dtype=complex), (0, 1)) unitaries = A.ops qml.StatePrep(state, wires=control_wires) qml.Select(unitaries, control=control_wires) qml.adjoint(qml.StatePrep)(state, wires=control_wires)
>>> print(qml.draw(block_encode, show_matrices=False)(A, control_wires=[0, 1])) 0: ─╭|Ψ⟩─╭Select─╭|Ψ⟩†─┤ 1: ─╰|Ψ⟩─├Select─╰|Ψ⟩†─┤ 2: ──────╰Select───────┤
This circuit can be used as a building block within a larger QNode to perform algorithms such as QSVT and Hamiltonian simulation.
Decomposing a Hermitian matrix into a linear combination of Pauli words via
qml.pauli_decomposeis now faster and differentiable. (#4395) (#4479) (#4493)def find_coeffs(p): mat = np.array([[3, p], [p, 3]]) A = qml.pauli_decompose(mat) return A.coeffs
>>> import jax >>> from jax import numpy as np >>> jax.jacobian(find_coeffs)(np.array(2.)) Array([0., 1.], dtype=float32, weak_type=True)
Monitor PennyLane's inner workings with logging 📃
Python-native logging can now be enabled with
qml.logging.enable_logging(). (#4377) (#4383)Consider the following code that is contained in
my_code.py:import pennylane as qml qml.logging.enable_logging() # enables logging dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def f(x): qml.RX(x, wires=0) return qml.state() f(0.5)
Executing
my_code.pywith logging enabled will detail every step in PennyLane’s pipeline that gets used to run your code.$ python my_code.py [1967-02-13 15:18:38,591][DEBUG][<PID 8881:MainProcess>] - pennylane.qnode.__init__()::"Creating QNode(func=<function f at 0x7faf2a6fbaf0>, device=<DefaultQubit device (wires=2, shots=None) at 0x7faf2a689b50>, interface=auto, diff_method=best, expansion_strategy=gradient, max_expansion=10, grad_on_execution=best, mode=None, cache=True, cachesize=10000, max_diff=1, gradient_kwargs={}" ...Additional logging configuration settings can be specified by modifying the contents of the logging configuration file, which can be located by running
qml.logging.config_path(). Follow our logging docs page for more details!
More input states for quantum chemistry calculations ⚛️
Input states obtained from advanced quantum chemistry calculations can be used in a circuit. (#4427) (#4433) (#4461) (#4476) (#4505)
Quantum chemistry calculations rely on an initial state that is typically selected to be the trivial Hartree-Fock state. For molecules with a complicated electronic structure, using initial states obtained from affordable post-Hartree-Fock calculations helps to improve the efficiency of the quantum simulations. These calculations can be done with external quantum chemistry libraries such as PySCF.
It is now possible to import a PySCF solver object in PennyLane and extract the corresponding wave function in the form of a state vector that can be directly used in a circuit. First, perform your classical quantum chemistry calculations and then use the qml.qchem.import_state function to import the solver object and return a state vector.
>>> from pyscf import gto, scf, ci
>>> mol = gto.M(atom=[['H', (0, 0, 0)], ['H', (0,0,0.71)]], basis='sto6g')
>>> myhf = scf.UHF(mol).run()
>>> myci = ci.UCISD(myhf).run()
>>> wf_cisd = qml.qchem.import_state(myci, tol=1e-1)
>>> print(wf_cisd)
[ 0. +0.j 0. +0.j 0. +0.j 0.1066467 +0.j
1. +0.j 0. +0.j 0. +0.j 0. +0.j
2. +0.j 0. +0.j 0. +0.j 0. +0.j
-0.99429698+0.j 0. +0.j 0. +0.j 0. +0.j]
The state vector can be implemented in a circuit using ``qml.StatePrep``.
>>> dev = qml.device('default.qubit', wires=4)
>>> @qml.qnode(dev)
... def circuit():
... qml.StatePrep(wf_cisd, wires=range(4))
... return qml.state()
>>> print(circuit())
[ 0. +0.j 0. +0.j 0. +0.j 0.1066467 +0.j
1. +0.j 0. +0.j 0. +0.j 0. +0.j
2. +0.j 0. +0.j 0. +0.j 0. +0.j
-0.99429698+0.j 0. +0.j 0. +0.j 0. +0.j]
The currently supported post-Hartree-Fock methods are RCISD, UCISD, RCCSD, and UCCSD which
denote restricted (R) and unrestricted (U) configuration interaction (CI) and coupled cluster (CC)
calculations with single and double (SD) excitations.
Reuse and reset qubits after mid-circuit measurements ♻️
PennyLane now allows you to define circuits that reuse a qubit after a mid-circuit measurement has taken place. Optionally, the wire can also be reset to the \(|0\rangle\) state. (#4402) (#4432)
Post-measurement reset can be activated by setting
reset=Truewhen calling qml.measure. In this version of PennyLane, executing circuits with qubit reuse will result in the defer_measurements transform being applied. This transform replaces each reused wire with an additional qubit. However, future releases of PennyLane will explore device-level support for qubit reuse without consuming additional qubits.Qubit reuse and reset is also fully differentiable:
dev = qml.device("default.qubit", wires=4) @qml.qnode(dev) def circuit(p): qml.RX(p, wires=0) m = qml.measure(0, reset=True) qml.cond(m, qml.Hadamard)(1) qml.RX(p, wires=0) m = qml.measure(0) qml.cond(m, qml.Hadamard)(1) return qml.expval(qml.PauliZ(1))
>>> jax.grad(circuit)(0.4) Array(-0.35867804, dtype=float32, weak_type=True)
You can read more about mid-circuit measurements in the documentation, and stay tuned for more mid-circuit measurement features in the next few releases!
Improvements 🛠
A new PennyLane drawing style
Circuit drawings and plots can now be created following a PennyLane style. (#3950)
The
qml.draw_mplfunction accepts astyle='pennylane'argument to create PennyLane themed circuit diagrams:def circuit(x, z): qml.QFT(wires=(0,1,2,3)) qml.Toffoli(wires=(0,1,2)) qml.CSWAP(wires=(0,2,3)) qml.RX(x, wires=0) qml.CRZ(z, wires=(3,0)) return qml.expval(qml.PauliZ(0)) qml.draw_mpl(circuit, style="pennylane")(1, 1)
PennyLane-styled plots can also be drawn by passing
"pennylane.drawer.plot"to Matplotlib’splt.style.usefunction:import matplotlib.pyplot as plt plt.style.use("pennylane.drawer.plot") for i in range(3): plt.plot(np.random.rand(10))
If the font Quicksand Bold isn’t available, an available default font is used instead.
Making operators immutable and PyTrees
Any class inheriting from
Operatoris now automatically registered as a pytree with JAX. This unlocks the ability to jit functions ofOperator. (#4458)>>> op = qml.adjoint(qml.RX(1.0, wires=0)) >>> jax.jit(qml.matrix)(op) Array([[0.87758255-0.j , 0. +0.47942555j], [0. +0.47942555j, 0.87758255-0.j ]], dtype=complex64, weak_type=True) >>> jax.tree_util.tree_map(lambda x: x+1, op) Adjoint(RX(2.0, wires=[0]))
All
Operatorobjects now defineOperator._flattenandOperator._unflattenmethods that separate trainable from untrainable components. These methods will be used in serialization and pytree registration. Custom operations may need an update to ensure compatibility with new PennyLane features. (#4483) (#4314)The
QuantumScriptclass now has abind_new_parametersmethod that allows creation of newQuantumScriptobjects with the provided parameters. (#4345)The
qml.gradientsmodule no longer mutates operators in-place for any gradient transforms. Instead, operators that need to be mutated are copied with new parameters. (#4220)PennyLane no longer directly relies on
Operator.__eq__. (#4398)qml.equalno longer raises errors when operators or measurements of different types are compared. Instead, it returnsFalse. (#4315)
Transforms
Transform programs are now integrated with the QNode. (#4404)
def null_postprocessing(results: qml.typing.ResultBatch) -> qml.typing.Result: return results[0] @qml.transforms.core.transform def scale_shots(tape: qml.tape.QuantumTape, shot_scaling) -> (Tuple[qml.tape.QuantumTape], Callable): new_shots = tape.shots.total_shots * shot_scaling new_tape = qml.tape.QuantumScript(tape.operations, tape.measurements, shots=new_shots) return (new_tape, ), null_postprocessing dev = qml.devices.experimental.DefaultQubit2() @partial(scale_shots, shot_scaling=2) @qml.qnode(dev, interface=None) def circuit(): return qml.sample(wires=0)
>>> circuit(shots=1) array([False, False])
Transform Programs,
qml.transforms.core.TransformProgram, can now be called on a batch of circuits and return a new batch of circuits and a single post processing function. (#4364)TransformDispatchernow allows registration of custom QNode transforms. (#4466)QNode transforms in
qml.qinfonow support custom wire labels. #4331qml.transforms.adjoint_metric_tensornow uses the simulation tools inqml.devices.qubitinstead of private methods ofqml.devices.DefaultQubit. (#4456)Auxiliary wires and device wires are now treated the same way in
qml.transforms.metric_tensoras inqml.gradients.hadamard_grad. All valid wire input formats foraux_wireare supported. (#4328)
Next-generation device API
The experimental device interface has been integrated with the QNode for JAX, JAX-JIT, TensorFlow and PyTorch. (#4323) (#4352) (#4392) (#4393)
The experimental
DefaultQubit2device now supports computing VJPs and JVPs using the adjoint method. (#4374)New functions called
adjoint_jvpandadjoint_vjpthat compute the JVP and VJP of a tape using the adjoint method have been added toqml.devices.qubit.adjoint_jacobian(#4358)DefaultQubit2now accepts amax_workersargument which controls multiprocessing. AProcessPoolExecutorexecutes tapes asynchronously using a pool of at mostmax_workersprocesses. Ifmax_workersisNoneor not given, only the current process executes tapes. If you experience any issue, say using JAX, TensorFlow, Torch, try settingmax_workerstoNone. (#4319) (#4425)qml.devices.experimental.Devicenow accepts a shots keyword argument and has ashotsproperty. This property is only used to set defaults for a workflow, and does not directly influence the number of shots used in executions or derivatives. (#4388)expand_fn()forDefaultQubit2has been updated to decomposeStatePrepoperations present in the middle of a circuit. (#4444)If no seed is specified on initialization with
DefaultQubit2, the local random number generator will be seeded from NumPy’s global random number generator. (#4394)
Improvements to machine learning library interfaces
pennylane/interfaceshas been refactored. Theexecute_fnpassed to the machine learning framework boundaries is now responsible for converting parameters to NumPy. The gradients module can now handle TensorFlow parameters, but gradient tapes now retain the originaldtypeinstead of converting tofloat64. This may cause instability with finite-difference differentiation andfloat32parameters. The machine learning boundary functions are now uncoupled from their legacy counterparts. (#4415)qml.interfaces.set_shotsnow accepts aShotsobject as well asint‘s and tuples ofint‘s. (#4388)Readability improvements and stylistic changes have been made to
pennylane/interfaces/jax_jit_tuple.py(#4379)
Pulses
A
HardwareHamiltoniancan now be summed withintorfloatobjects. A sequence ofHardwareHamiltonians can now be summed via the builtinsum. (#4343)qml.pulse.transmon_drivehas been updated in accordance with 1904.06560. In particular, the functional form has been changed from \(\Omega(t)(\cos(\omega_d t + \phi) X - \sin(\omega_d t + \phi) Y)$ to $\Omega(t) \sin(\omega_d t + \phi) Y\). (#4418) (#4465) (#4478) (#4418)
Other improvements
The
qchemmodule has been upgraded to use the fermionic operators of thefermimodule. #4336 #4521The calculation of
Sum,Prod,SProd,PauliWord, andPauliSentencesparse matrices are orders of magnitude faster. (#4475) (#4272) (#4411)A function called
qml.math.fidelity_statevectorthat computes the fidelity between two state vectors has been added. (#4322)qml.ctrl(qml.PauliX)returns aCNOT,Toffoli, orMultiControlledXoperation instead ofControlled(PauliX). (#4339)When given a callable,
qml.ctrlnow does its custom pre-processing on all queued operators from the callable. (#4370)The
qchemfunctionsprimitive_normandcontracted_normhave been modified to be compatible with higher versions of SciPy. The private function_fac2for computing double factorials has also been added. #4321tape_expandnow usesOperator.decompositioninstead ofOperator.expandin order to make more performant choices. (#4355)CI now runs tests with TensorFlow 2.13.0 (#4472)
All tests in CI and pre-commit hooks now enable linting. (#4335)
The default label for a
StatePrepBaseoperator is now|Ψ⟩. (#4340)Device.default_expand_fn()has been updated to decomposeqml.StatePrepoperations present in the middle of a provided circuit. (#4437)QNode.constructhas been updated to only apply theqml.defer_measurementstransform if the device does not natively support mid-circuit measurements. (#4516)The application of the
qml.defer_measurementstransform has been moved fromQNode.constructtoqml.Device.batch_transformto allow more fine-grain control over whendefer_measurementsshould be used. (#4432)The label for
ParametrizedEvolutioncan display parameters with the requested format as set by the kwargdecimals. Array-like parameters are displayed in the same format as matrices and stored in the cache. (#4151)
Breaking changes 💔
Applying gradient transforms to broadcasted/batched tapes has been deactivated until it is consistently supported for QNodes as well. (#4480)
Gradient transforms no longer implicitly cast
float32parameters tofloat64. Finite difference differentiation withfloat32parameters may no longer give accurate results. (#4415)The
do_queuekeyword argument inqml.operation.Operatorhas been removed. Instead of settingdo_queue=False, use theqml.QueuingManager.stop_recording()context. (#4317)Operator.expandnow uses the output ofOperator.decompositioninstead of what it queues. (#4355)The gradients module no longer needs shot information passed to it explicitly, as the shots are on the tapes. (#4448)
qml.StatePrephas been renamed toqml.StatePrepBaseandqml.QubitStateVectorhas been renamed toqml.StatePrep.qml.operation.StatePrepandqml.QubitStateVectorare still accessible. (#4450)Support for Python 3.8 has been dropped. (#4453)
MeasurementValue‘s signature has been updated to accept a list ofMidMeasureMP‘s rather than a list of their IDs. (#4446)The
grouping_typeandgrouping_methodkeyword arguments have been removed fromqchem.molecular_hamiltonian. (#4301)zyz_decompositionandxyx_decompositionhave been removed. Useone_qubit_decompositioninstead. (#4301)LieAlgebraOptimizerhas been removed. UseRiemannianGradientOptimizerinstead. (#4301)Operation.base_namehas been removed. (#4301)QuantumScript.namehas been removed. (#4301)qml.math.reduced_dmhas been removed. Useqml.math.reduce_dmorqml.math.reduce_statevectorinstead. (#4301)The
qml.specsdictionary no longer supports direct key access to certain keys. (#4301)Instead, these quantities can be accessed as fields of the new
Resourcesobject saved underspecs_dict["resources"]:num_operationsis no longer supported, usespecs_dict["resources"].num_gatesnum_used_wiresis no longer supported, usespecs_dict["resources"].num_wiresgate_typesis no longer supported, usespecs_dict["resources"].gate_typesgate_sizesis no longer supported, usespecs_dict["resources"].gate_sizesdepthis no longer supported, usespecs_dict["resources"].depth
qml.math.purity,qml.math.vn_entropy,qml.math.mutual_info,qml.math.fidelity,qml.math.relative_entropy, andqml.math.max_entropyno longer support state vectors as input. (#4322)The private
QuantumScript._preplist has been removed, and prep operations now go into the_opslist. (#4485)
Deprecations 👋
qml.enable_returnandqml.disable_returnhave been deprecated. Please avoid callingdisable_return, as the old return system has been deprecated along with these switch functions. (#4316)qml.qchem.jordan_wignerhas been deprecated. Useqml.jordan_wignerinstead. List input to define the fermionic operator has also been deprecated; the fermionic operators in theqml.fermimodule should be used instead. (#4332)The
qml.RandomLayers.compute_decompositionkeyword argumentratio_imprimitivewill be changed toratio_imprimto match the call signature of the operation. (#4314)The CV observables
qml.Xandqml.Phave been deprecated. Useqml.QuadXandqml.QuadPinstead. (#4330)The method
tape.unwrap()and correspondingUnwrapTapeandUnwrapclasses have been deprecated. Useconvert_to_numpy_parametersinstead. (#4344)The
modekeyword argument in QNode has been deprecated, as it was only used in the old return system (which has also been deprecated). Please usegrad_on_executioninstead. (#4316)The
QuantumScript.set_parametersmethod and theQuantumScript.datasetter have been deprecated. Please useQuantumScript.bind_new_parametersinstead. (#4346)The
__eq__and__hash__dunder methods ofOperatorandMeasurementProcesswill now raise warnings to reflect upcoming changes to operator and measurement process equality and hashing. (#4144) (#4454) (#4489) (#4498)The
sampler_seedargument ofqml.gradients.spsa_gradhas been deprecated, along with a bug fix of the seed-setting behaviour. Instead, thesampler_rngargument should be set, either to an integer value, which will be used to create a PRNG internally or to a NumPy pseudo-random number generator created vianp.random.default_rng(seed). (4165)
Documentation 📝
The
qml.pulse.transmon_interactionandqml.pulse.transmon_drivedocumentation has been updated. #4327qml.ApproxTimeEvolution.compute_decomposition()now has a code example. (#4354)The documentation for
qml.devices.experimental.Devicehas been improved to clarify some aspects of its use. (#4391)Input types and sources for operators in
qml.import_operatorare specified. (#4476)
Bug fixes 🐛
qml.Projectoris pickle-able again. (#4452)_copy_and_shift_paramsdoes not cast or convert integral types, just relying on+and*‘s casting rules in this case. (#4477)Sparse matrix calculations of
SProds containing aTensorare now allowed. When usingTensor.sparse_matrix(), it is recommended to use thewire_orderkeyword argument overwires. (#4424)op.adjointhas been replaced withqml.adjointinQNSPSAOptimizer. (#4421)jax.ad(deprecated) has been replaced byjax.interpreters.ad. (#4403)metric_tensorstops accidentally catching errors that stem from flawed wires assignments in the original circuit, leading to recursion errors. (#4328)A warning is now raised if control indicators are hidden when calling
qml.draw_mpl(#4295)qml.qinfo.puritynow produces correct results with custom wire labels. (#4331)default.qutritnow supports all qutrit operations used withqml.adjoint. (#4348)The observable data of
qml.GellMannnow includes its index, allowing correct comparison between instances ofqml.GellMann, as well as Hamiltonians and Tensors containingqml.GellMann. (#4366)qml.transforms.merge_amplitude_embeddingnow works correctly when theAmplitudeEmbeddings have a batch dimension. (#4353)The
jordan_wignerfunction has been modified to work with Hamiltonians built with an active space. (#4372)When a
styleoption is not provided,qml.draw_mpluses the current style set fromqml.drawer.use_styleinstead ofblack_white. (#4357)qml.devices.qubit.preprocess.validate_and_expand_adjointno longer sets the trainable parameters of the expanded tape. (#4365)qml.default_expand_fnnow selectively expands operations or measurements allowing more operations to be executed in circuits when measuring non-qwc Hamiltonians. (#4401)qml.ControlledQubitUnitaryno longer reportshas_decompositionasTruewhen it does not really have a decomposition. (#4407)qml.transforms.split_non_commutingnow correctly works on tapes containing bothexpvalandvarmeasurements. (#4426)Subtracting a
Prodfrom another operator now works as expected. (#4441)The
sampler_seedargument ofqml.gradients.spsa_gradhas been changed tosampler_rng. One can either provide an integer, which will be used to create a PRNG internally. Previously, this lead to the same direction being sampled, whennum_directionsis greater than 1. Alternatively, one can provide a NumPy PRNG, which allows reproducibly callingspsa_gradwithout getting the same results every time. (4165) (4482)qml.math.get_dtype_namenow works with autograd array boxes. (#4494)The backprop gradient of
qml.math.fidelityis now correct. (#4380)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Utkarsh Azad, Thomas Bromley, Isaac De Vlugt, Amintor Dusko, Stepan Fomichev, Lillian M. A. Frederiksen, Soran Jahangiri, Edward Jiang, Korbinian Kottmann, Ivana Kurečić, Christina Lee, Vincent Michaud-Rioux, Romain Moyard, Lee James O’Riordan, Mudit Pandey, Borja Requena, Matthew Silverman, Jay Soni, David Wierichs, Frederik Wilde.
Release 0.31.0¶
New features since last release
Seamlessly create and combine fermionic operators 🔬
Fermionic operators and arithmetic are now available. (#4191) (#4195) (#4200) (#4201) (#4209) (#4229) (#4253) (#4255) (#4262) (#4278)
There are a couple of ways to create fermionic operators with this new feature:
qml.FermiCandqml.FermiA: the fermionic creation and annihilation operators, respectively. These operators are defined by passing the index of the orbital that the fermionic operator acts on. For instance, the operatorsa⁺(0)anda(3)are respectively constructed as>>> qml.FermiC(0) a⁺(0) >>> qml.FermiA(3) a(3)
These operators can be composed with (
*) and linearly combined with (+and-) other Fermi operators to create arbitrary fermionic Hamiltonians. Multiplying several Fermi operators together creates an operator that we call a Fermi word:>>> word = qml.FermiC(0) * qml.FermiA(0) * qml.FermiC(3) * qml.FermiA(3) >>> word a⁺(0) a(0) a⁺(3) a(3)
Fermi words can be linearly combined to create a fermionic operator that we call a Fermi sentence:
>>> sentence = 1.2 * word - 0.345 * qml.FermiC(3) * qml.FermiA(3) >>> sentence 1.2 * a⁺(0) a(0) a⁺(3) a(3) - 0.345 * a⁺(3) a(3)
via qml.fermi.from_string: create a fermionic operator that represents multiple creation and annihilation operators being multiplied by each other (a Fermi word).
>>> qml.fermi.from_string('0+ 1- 0+ 1-') a⁺(0) a(1) a⁺(0) a(1) >>> qml.fermi.from_string('0^ 1 0^ 1') a⁺(0) a(1) a⁺(0) a(1)
Fermi words created with
from_stringcan also be linearly combined to create a Fermi sentence:>>> word1 = qml.fermi.from_string('0+ 0- 3+ 3-') >>> word2 = qml.fermi.from_string('3+ 3-') >>> sentence = 1.2 * word1 + 0.345 * word2 >>> sentence 1.2 * a⁺(0) a(0) a⁺(3) a(3) + 0.345 * a⁺(3) a(3)
Additionally, any fermionic operator, be it a single fermionic creation/annihilation operator, a Fermi word, or a Fermi sentence, can be mapped to the qubit basis by using qml.jordan_wigner:
>>> qml.jordan_wigner(sentence) ((0.4725+0j)*(Identity(wires=[0]))) + ((-0.4725+0j)*(PauliZ(wires=[3]))) + ((-0.3+0j)*(PauliZ(wires=[0]))) + ((0.3+0j)*(PauliZ(wires=[0]) @ PauliZ(wires=[3])))
Learn how to create fermionic Hamiltonians describing some simple chemical systems by checking out our fermionic operators demo!
Workflow-level resource estimation 🧮
PennyLane’s Tracker now monitors the resource requirements of circuits being executed by the device. (#4045) (#4110)
Suppose we have a workflow that involves executing circuits with different qubit numbers. We can obtain the resource requirements as a function of the number of qubits by executing the workflow with the
Trackercontext:dev = qml.device("default.qubit", wires=4) @qml.qnode(dev) def circuit(n_wires): for i in range(n_wires): qml.Hadamard(i) return qml.probs(range(n_wires)) with qml.Tracker(dev) as tracker: for i in range(1, 5): circuit(i)
The resource requirements of individual circuits can then be inspected as follows:
>>> resources = tracker.history["resources"] >>> resources[0] wires: 1 gates: 1 depth: 1 shots: Shots(total=None) gate_types: {'Hadamard': 1} gate_sizes: {1: 1} >>> [r.num_wires for r in resources] [1, 2, 3, 4]
Moreover, it is possible to predict the resource requirements without evaluating circuits using the
null.qubitdevice, which follows the standard execution pipeline but returns numeric zeros. Consider the following workflow that takes the gradient of a50-qubit circuit:n_wires = 50 dev = qml.device("null.qubit", wires=n_wires) weight_shape = qml.StronglyEntanglingLayers.shape(2, n_wires) weights = np.random.random(weight_shape, requires_grad=True) @qml.qnode(dev, diff_method="parameter-shift") def circuit(weights): qml.StronglyEntanglingLayers(weights, wires=range(n_wires)) return qml.expval(qml.PauliZ(0)) with qml.Tracker(dev) as tracker: qml.grad(circuit)(weights)
The tracker can be inspected to extract resource requirements without requiring a 50-qubit circuit run:
>>> tracker.totals {'executions': 451, 'batches': 2, 'batch_len': 451} >>> tracker.history["resources"][0] wires: 50 gates: 200 depth: 77 shots: Shots(total=None) gate_types: {'Rot': 100, 'CNOT': 100} gate_sizes: {1: 100, 2: 100}
Custom operations can now be constructed that solely define resource requirements — an explicit decomposition or matrix representation is not needed. (#4033)
PennyLane is now able to estimate the total resource requirements of circuits that include one or more of these operations, allowing you to estimate requirements for high-level algorithms composed of abstract subroutines.
These operations can be defined by inheriting from ResourcesOperation and overriding the
resources()method to return an appropriate Resources object:class CustomOp(qml.resource.ResourcesOperation): def resources(self): n = len(self.wires) r = qml.resource.Resources( num_wires=n, num_gates=n ** 2, depth=5, ) return r
>>> wires = [0, 1, 2] >>> c = CustomOp(wires) >>> c.resources() wires: 3 gates: 9 depth: 5 shots: Shots(total=None) gate_types: {} gate_sizes: {}
A quantum circuit that contains
CustomOpcan be created and inspected using qml.specs:dev = qml.device("default.qubit", wires=wires) @qml.qnode(dev) def circ(): qml.PauliZ(wires=0) CustomOp(wires) return qml.state()
>>> specs = qml.specs(circ)() >>> specs["resources"].depth 6
Community contributions from UnitaryHack 🤝
ParametrizedHamiltonian now has an improved string representation. (#4176)
>>> def f1(p, t): return p[0] * jnp.sin(p[1] * t) >>> def f2(p, t): return p * t >>> coeffs = [2., f1, f2] >>> observables = [qml.PauliX(0), qml.PauliY(0), qml.PauliZ(0)] >>> qml.dot(coeffs, observables) (2.0*(PauliX(wires=[0]))) + (f1(params_0, t)*(PauliY(wires=[0]))) + (f2(params_1, t)*(PauliZ(wires=[0])))
The quantum information module now supports trace distance. (#4181)
Two cases are enabled for calculating the trace distance:
A QNode transform via qml.qinfo.trace_distance:
dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(param): qml.RY(param, wires=0) qml.CNOT(wires=[0, 1]) return qml.state()
>>> trace_distance_circuit = qml.qinfo.trace_distance(circuit, circuit, wires0=[0], wires1=[0]) >>> x, y = np.array(0.4), np.array(0.6) >>> trace_distance_circuit((x,), (y,)) 0.047862689546603415
Flexible post-processing via qml.math.trace_distance:
>>> rho = np.array([[0.3, 0], [0, 0.7]]) >>> sigma = np.array([[0.5, 0], [0, 0.5]]) >>> qml.math.trace_distance(rho, sigma) 0.19999999999999998
It is now possible to prepare qutrit basis states with qml.QutritBasisState. (#4185)
wires = range(2) dev = qml.device("default.qutrit", wires=wires) @qml.qnode(dev) def qutrit_circuit(): qml.QutritBasisState([1, 1], wires=wires) qml.TAdd(wires=wires) return qml.probs(wires=1)
>>> qutrit_circuit() array([0., 0., 1.])
A new transform called one_qubit_decomposition has been added to provide a unified interface for decompositions of a single-qubit unitary matrix into sequences of X, Y, and Z rotations. All decompositions simplify the rotations angles to be between
0and4pi. (#4210) (#4246)>>> from pennylane.transforms import one_qubit_decomposition >>> U = np.array([[-0.28829348-0.78829734j, 0.30364367+0.45085995j], ... [ 0.53396245-0.10177564j, 0.76279558-0.35024096j]]) >>> one_qubit_decomposition(U, 0, "ZYZ") [RZ(tensor(12.32427531, requires_grad=True), wires=[0]), RY(tensor(1.14938178, requires_grad=True), wires=[0]), RZ(tensor(1.73305815, requires_grad=True), wires=[0])] >>> one_qubit_decomposition(U, 0, "XYX", return_global_phase=True) [RX(tensor(10.84535137, requires_grad=True), wires=[0]), RY(tensor(1.39749741, requires_grad=True), wires=[0]), RX(tensor(0.45246584, requires_grad=True), wires=[0]), (0.38469215914523336-0.9230449299422961j)*(Identity(wires=[0]))]
The
has_unitary_generatorattribute inqml.ops.qubit.attributesno longer contains operators with non-unitary generators. (#4183)PennyLane Docker builds have been updated to include the latest plugins and interface versions. (#4178)
Extended support for differentiating pulses ⚛️
The stochastic parameter-shift gradient method can now be used with hardware-compatible Hamiltonians. (#4132) (#4215)
This new feature generalizes the stochastic parameter-shift gradient transform for pulses (
stoch_pulse_grad) to support Hermitian generating terms beyond just Pauli words in pulse Hamiltonians, which makes it hardware-compatible.A new differentiation method called qml.gradients.pulse_generator is available, which combines classical processing with the parameter-shift rule for multivariate gates to differentiate pulse programs. Access it in your pulse programs by setting
diff_method=qml.gradients.pulse_generator. (#4160)qml.pulse.ParametrizedEvolutionnow uses batched compressed sparse row (BCSR) format. This allows for computing Jacobians of the unitary directly even whendense=False. (#4126)def U(params): H = jnp.polyval * qml.PauliZ(0) # time dependent Hamiltonian Um = qml.evolve(H, dense=False)(params, t=10.) return qml.matrix(Um) params = jnp.array([[0.5]], dtype=complex) jac = jax.jacobian(U, holomorphic=True)(params)
Broadcasting and other tweaks to Torch and Keras layers 🦾
The
TorchLayerandKerasLayerintegrations withtorch.nnandKerashave been upgraded. Consider the followingTorchLayer:n_qubits = 2 dev = qml.device("default.qubit", wires=n_qubits) @qml.qnode(dev) def qnode(inputs, weights): qml.AngleEmbedding(inputs, wires=range(n_qubits)) qml.BasicEntanglerLayers(weights, wires=range(n_qubits)) return [qml.expval(qml.PauliZ(wires=i)) for i in range(n_qubits)] n_layers = 6 weight_shapes = {"weights": (n_layers, n_qubits)} qlayer = qml.qnn.TorchLayer(qnode, weight_shapes)
The following features are now available:
Native support for parameter broadcasting. (#4131)
>>> batch_size = 10 >>> inputs = torch.rand((batch_size, n_qubits)) >>> qlayer(inputs) >>> dev.num_executions == 1 True
The ability to draw a
TorchLayerandKerasLayerusingqml.draw()andqml.draw_mpl(). (#4197)>>> print(qml.draw(qlayer, show_matrices=False)(inputs)) 0: ─╭AngleEmbedding(M0)─╭BasicEntanglerLayers(M1)─┤ <Z> 1: ─╰AngleEmbedding(M0)─╰BasicEntanglerLayers(M1)─┤ <Z>
Support for
KerasLayermodel saving and clearer instructions onTorchLayermodel saving. (#4149) (#4158)>>> torch.save(qlayer.state_dict(), "weights.pt") # Saving >>> qlayer.load_state_dict(torch.load("weights.pt")) # Loading >>> qlayer.eval()
Hybrid models containing
KerasLayerorTorchLayerobjects can also be saved and loaded.
Improvements 🛠
A more flexible projector
qml.Projectornow accepts a state vector representation, which enables the creation of projectors in any basis. (#4192)dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(state): return qml.expval(qml.Projector(state, wires=[0, 1])) zero_state = [0, 0] plusplus_state = np.array([1, 1, 1, 1]) / 2
>>> circuit(zero_state) tensor(1., requires_grad=True) >>> circuit(plusplus_state) tensor(0.25, requires_grad=True)
Do more with qutrits
Three qutrit rotation operators have been added that are analogous to
RX,RY, andRZ:qml.TRX: an X rotationqml.TRY: a Y rotationqml.TRZ: a Z rotation
Qutrit devices now support parameter-shift differentiation. (#2845)
The qchem module
qchem.molecular_hamiltonian(),qchem.qubit_observable(),qchem.import_operator(), andqchem.dipole_moment()now return an arithmetic operator ifenable_new_opmath()is active. (#4138) (#4159) (#4189) (#4204)Non-cubic lattice support for all electron resource estimation has been added. (3956)
The
qchem.molecular_hamiltonian()function has been upgraded to support custom wires for constructing differentiable Hamiltonians. The zero imaginary component of the Hamiltonian coefficients have been removed. (#4050) (#4094)Jordan-Wigner transforms that cache Pauli gate objects have been accelerated. (#4046)
An error is now raised by
qchem.molecular_hamiltonianwhen thedhfmethod is used for an open-shell system. This duplicates a similar error inqchem.Moleculebut makes it clear that thepyscfbackend can be used for open-shell calculations. (#4058)Updated various qubit tapering methods to support operator arithmetic. (#4252)
Next-generation device API
The new device interface has been integrated with
qml.executefor autograd, backpropagation, and no differentiation. (#3903)Support for adjoint differentiation has been added to the
DefaultQubit2device. (#4037)A new function called
measure_with_samplesthat returns a sample-based measurement result given a state has been added. (#4083) (#4093) (#4162) (#4254)DefaultQubit2.preprocessnow returns a newExecutionConfigobject with decisions forgradient_method,use_device_gradient, andgrad_on_execution. (#4102)Support for sample-based measurements has been added to the
DefaultQubit2device. (#4105) (#4114) (#4133) (#4172)The
DefaultQubit2device now has aseedkeyword argument. (#4120)Added a
densekeyword toParametrizedEvolutionthat allows forcing dense or sparse matrices. (#4079) (#4095) (#4285)Adds the Type variables
pennylane.typing.Resultandpennylane.typing.ResultBatchfor type hinting the result of an execution. (#4018)qml.devices.ExecutionConfigno longer has ashotsproperty, as it is now on theQuantumScript.
It now has ause_device_gradientproperty.ExecutionConfig.grad_on_execution = Noneindicates a request for"best", instead of a string. (#4102)The new device interface for Jax has been integrated with
qml.execute. (#4137)The new device interface is now integrated with
qml.executefor Tensorflow. (#4169)The experimental device
DefaultQubit2now supportsqml.Snapshot. (#4193)The experimental device interface is integrated with the
QNode. (#4196)The new device interface in integrated with
qml.executefor Torch. (#4257)
Handling shots
QuantumScriptnow has ashotsproperty, allowing shots to be tied to executions instead of devices. (#4067) (#4103) (#4106) (#4112)Several Python built-in functions are now properly defined for instances of the
Shotsclass.print: printingShotsinstances is now human-readablestr: convertingShotsinstances to human-readable strings==: equating two differentShotsinstanceshash: obtaining the hash values ofShotsinstances
qml.devices.ExecutionConfigno longer has ashotsproperty, as it is now on theQuantumScript. It now has ause_device_gradientproperty.ExecutionConfig.grad_on_execution = Noneindicates a request for"best"instead of a string. (#4102)QuantumScript.shotshas been integrated with QNodes so that shots are placed on theQuantumScriptduringQNodeconstruction. (#4110)The
gradientsmodule has been updated to use the newShotsobject internally (#4152)
Operators
qml.prodnow accepts a single quantum function input for creating newProdoperators. (#4011)DiagonalQubitUnitarynow decomposes intoRZ,IsingZZandMultiRZgates instead of aQubitUnitaryoperation with a dense matrix. (#4035)All objects being queued in an
AnnotatedQueueare now wrapped so thatAnnotatedQueueis not dependent on the has of any operators or measurement processes. (#4087)A
densekeyword toParametrizedEvolutionthat allows forcing dense or sparse matrices has been added. (#4079) (#4095)Added a new function
qml.ops.functions.bind_new_parametersthat creates a copy of an operator with new parameters without mutating the original operator. (#4113) (#4256)qml.CYhas been moved fromqml.ops.qubit.non_parametric_opstoqml.ops.op_math.controlled_opsand now inherits fromqml.ops.op_math.ControlledOp. (#4116)qml.CZnow inherits from theControlledOpclass and supports exponentiation to arbitrary powers withpow, which is no longer limited to integers. It also supportssparse_matrixanddecompositionrepresentations. (#4117)The construction of the Pauli representation for the
Sumclass is now faster. (#4142)qml.drawer.drawable_layers.drawable_layersandqml.CircuitGraphhave been updated to not rely onOperatorequality or hash to work correctly. (#4143)
Other improvements
A transform dispatcher and program have been added. (#4109) (#4187)
Reduced density matrix functionality has been added via
qml.math.reduce_dmandqml.math.reduce_statevector. Both functions have broadcasting support. (#4173)The following functions in
qml.qinfonow support parameter broadcasting:reduced_dmpurityvn_entropymutual_infofidelityrelative_entropytrace_distance
The following functions in
qml.mathnow support parameter broadcasting:purityvn_entropymutual_infofidelityrelative_entropymax_entropysqrt_matrix
pulse.ParametrizedEvolutionnow raises an error if the number of input parameters does not match the number of parametrized coefficients in theParametrizedHamiltonianthat generates it. An exception is made forHardwareHamiltonians which are not checked. (#4216)The default value for the
show_matriceskeyword argument in all drawing methods is nowTrue. This allows for quick insights into broadcasted tapes, for example. (#3920)Type variables for
qml.typing.Resultandqml.typing.ResultBatchhave been added for type hinting the result of an execution. (#4108)The Jax-JIT interface now uses symbolic zeros to determine trainable parameters. (4075)
A new function called
pauli.pauli_word_prefactor()that extracts the prefactor for a given Pauli word has been added. (#4164)Variable-length argument lists of functions and methods in some docstrings is now more clear. (#4242)
qml.drawer.drawable_layers.drawable_layersandqml.CircuitGraphhave been updated to not rely onOperatorequality or hash to work correctly. (#4143)Drawing mid-circuit measurements connected by classical control signals to conditional operations is now possible. (#4228)
The autograd interface now submits all required tapes in a single batch on the backward pass. (#4245)
Breaking changes 💔
The default value for the
show_matriceskeyword argument in all drawing methods is nowTrue. This allows for quick insights into broadcasted tapes, for example. (#3920)DiagonalQubitUnitarynow decomposes intoRZ,IsingZZ, andMultiRZgates rather than aQubitUnitary. (#4035)Jax trainable parameters are now
Tracerinstead ofJVPTracer. It is not always the right definition for the JIT interface, but we update them in the custom JVP using symbolic zeros. (4075)The experimental Device interface
qml.devices.experimental.Devicenow requires that thepreprocessmethod also returns anExecutionConfigobject. This allows the device to choose what"best"means for various hyperparameters likegradient_methodandgrad_on_execution. (#4007) (#4102)Gradient transforms with Jax no longer support
argnum. Useargnumsinstead. (#4076)qml.collections,qml.op_sum, andqml.utils.sparse_hamiltonianhave been removed. (#4071)The
pennylane.transforms.qcutmodule now uses(op, id(op))as nodes in directed multigraphs that are used within the circuit cutting workflow instead ofop. This change removes the dependency of the module on the hash of operators. (#4227)Operator.datanow returns atupleinstead of alist. (#4222)The pulse differentiation methods,
pulse_generatorandstoch_pulse_grad, now raise an error when they are applied to a QNode directly. Instead, use differentiation via a JAX entry point (jax.grad,jax.jacobian, …). (#4241)
Deprecations 👋
LieAlgebraOptimizerhas been renamed toRiemannianGradientOptimizer. [(#4153)(https://github.com/PennyLaneAI/pennylane/pull/4153)]Operation.base_namehas been deprecated. Please useOperation.nameortype(op).__name__instead.QuantumScript‘snamekeyword argument and property have been deprecated. This also affectsQuantumTapeandOperationRecorder. (#4141)The
qml.groupingmodule has been removed. Its functionality has been reorganized in theqml.paulimodule.The public methods of
DefaultQubitare pending changes to follow the new device API, as used inDefaultQubit2. Warnings have been added to the docstrings to reflect this. (#4145)qml.math.reduced_dmhas been deprecated. Please useqml.math.reduce_dmorqml.math.reduce_statevectorinstead. (#4173)qml.math.purity,qml.math.vn_entropy,qml.math.mutual_info,qml.math.fidelity,qml.math.relative_entropy, andqml.math.max_entropyno longer support state vectors as input. Please callqml.math.dm_from_state_vectoron the input before passing to any of these functions. (#4186)The
do_queuekeyword argument inqml.operation.Operatorhas been deprecated. Instead of settingdo_queue=False, use theqml.QueuingManager.stop_recording()context. (#4148)zyz_decompositionandxyx_decompositionare now deprecated in favour ofone_qubit_decomposition. (#4230)
Documentation 📝
The documentation is updated to construct
QuantumTapeupon initialization instead of with queuing. (#4243)The docstring for
qml.ops.op_math.Pow.__new__is now complete and it has been updated along withqml.ops.op_math.Adjoint.__new__. (#4231)The docstring for
qml.gradnow states that it should be used with the Autograd interface only. (#4202)The description of
multin theqchem.Moleculedocstring now correctly states the value ofmultthat is supported. (#4058)
Bug Fixes 🐛
Fixed adjoint jacobian results with
grad_on_execution=Falsein the JAX-JIT interface. (4217)Fixed the matrix of
SProdwhen the coefficient is tensorflow and the target matrix is notcomplex128. (#4249)Fixed a bug where
stoch_pulse_gradwould ignore prefactors of rescaled Pauli words in the generating terms of a pulse Hamiltonian. (4156)Fixed a bug where the wire ordering of the
wiresargument toqml.density_matrixwas not taken into account. (#4072)A patch in
interfaces/autograd.pythat checks for thestrawberryfields.gbsdevice has been removed. That device is pinned to PennyLane <= v0.29.0, so that patch is no longer necessary. (#4089)qml.pauli.are_identical_pauli_wordsnow treats all identities as equal. Identity terms on Hamiltonians with non-standard wire orders are no longer eliminated. (#4161)qml.pauli_sentence()is now compatible with empty Hamiltoniansqml.Hamiltonian([], []). (#4171)Fixed a bug with Jax where executing multiple tapes with
gradient_fn="device"would fail. (#4190)A more meaningful error message is raised when broadcasting with adjoint differentiation on
DefaultQubit. (#4203)The
has_unitary_generatorattribute inqml.ops.qubit.attributesno longer contains operators with non-unitary generators. (#4183)Fixed a bug where
op = qml.qsvt()was incorrect up to a global phase when usingconvention="Wx""andqml.matrix(op). (#4214)Fixed a buggy calculation of the angle in
xyx_decompositionthat causes it to give an incorrect decomposition. Anifconditional was intended to prevent divide by zero errors, but the division was by the sine of the argument. So, any multiple of $pi$ should trigger the conditional, but it was only checking if the argument was 0. Example:qml.Rot(2.3, 2.3, 2.3)(#4210)Fixed bug that caused
ShotAdaptiveOptimizerto truncate dimensions of parameter-distributed shots during optimization. (#4240)Sumobservables can now have trainable parameters. (#4251) (#4275)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Venkatakrishnan AnushKrishna, Utkarsh Azad, Thomas Bromley, Isaac De Vlugt, Lillian M. A. Frederiksen, Emiliano Godinez Ramirez Nikhil Harle Soran Jahangiri, Edward Jiang, Korbinian Kottmann, Christina Lee, Vincent Michaud-Rioux, Romain Moyard, Tristan Nemoz, Mudit Pandey, Manul Patel, Borja Requena, Modjtaba Shokrian-Zini, Mainak Roy, Matthew Silverman, Jay Soni, Edward Thomas, David Wierichs, Frederik Wilde.
Release 0.30.0¶
New features since last release
Pulse programming on hardware ⚛️🔬
Support for loading time-dependent Hamiltonians that are compatible with quantum hardware has been added, making it possible to load a Hamiltonian that describes an ensemble of Rydberg atoms or a collection of transmon qubits. (#3749) (#3911) (#3930) (#3936) (#3966) (#3987) (#4021) (#4040)
Rydberg atoms are the foundational unit for neutral atom quantum computing. A Rydberg-system Hamiltonian can be constructed from a drive term —
qml.pulse.rydberg_drive— and an interaction term —qml.pulse.rydberg_interaction:from jax import numpy as jnp atom_coordinates = [[0, 0], [0, 4], [4, 0], [4, 4]] wires = [0, 1, 2, 3] amplitude = lambda p, t: p * jnp.sin(jnp.pi * t) phase = jnp.pi / 2 detuning = 3 * jnp.pi / 4 H_d = qml.pulse.rydberg_drive(amplitude, phase, detuning, wires) H_i = qml.pulse.rydberg_interaction(atom_coordinates, wires) H = H_d + H_i
The time-dependent Hamiltonian
Hcan be used in a PennyLane pulse-level differentiable circuit:dev = qml.device("default.qubit.jax", wires=wires) @qml.qnode(dev, interface="jax") def circuit(params): qml.evolve(H)(params, t=[0, 10]) return qml.expval(qml.PauliZ(0))
>>> params = jnp.array([2.4]) >>> circuit(params) Array(0.6316659, dtype=float32) >>> import jax >>> jax.grad(circuit)(params) Array([1.3116529], dtype=float32)
The qml.pulse page contains additional details. Check out our release blog post for a demonstration of how to perform the execution on actual hardware!
A pulse-level circuit can now be differentiated using a stochastic parameter-shift method. (#3780) (#3900) (#4000) (#4004)
The new qml.gradient.stoch_pulse_grad differentiation method unlocks stochastic-parameter-shift differentiation for pulse-level circuits. The current version of this new method is restricted to Hamiltonians composed of parametrized Pauli words, but future updates to extend to parametrized Pauli sentences can allow this method to be compatible with hardware-based systems such as an ensemble of Rydberg atoms.
This method can be activated by setting
diff_methodto qml.gradient.stoch_pulse_grad:>>> dev = qml.device("default.qubit.jax", wires=2) >>> sin = lambda p, t: jax.numpy.sin(p * t) >>> ZZ = qml.PauliZ(0) @ qml.PauliZ(1) >>> H = 0.5 * qml.PauliX(0) + qml.pulse.constant * ZZ + sin * qml.PauliX(1) >>> @qml.qnode(dev, interface="jax", diff_method=qml.gradients.stoch_pulse_grad) >>> def ansatz(params): ... qml.evolve(H)(params, (0.2, 1.)) ... return qml.expval(qml.PauliY(1)) >>> params = [jax.numpy.array(0.4), jax.numpy.array(1.3)] >>> jax.grad(ansatz)(params) [Array(0.16921353, dtype=float32, weak_type=True), Array(-0.2537478, dtype=float32, weak_type=True)]
Quantum singular value transformation 🐛➡️🦋
PennyLane now supports the quantum singular value transformation (QSVT), which describes how a quantum circuit can be constructed to apply a polynomial transformation to the singular values of an input matrix. (#3756) (#3757) (#3758) (#3905) (#3909) (#3926) (#4023)
Consider a matrix
Aalong with a vectoranglesthat describes the target polynomial transformation. Theqml.qsvtfunction creates a corresponding circuit:dev = qml.device("default.qubit", wires=2) A = np.array([[0.1, 0.2], [0.3, 0.4]]) angles = np.array([0.1, 0.2, 0.3]) @qml.qnode(dev) def example_circuit(A): qml.qsvt(A, angles, wires=[0, 1]) return qml.expval(qml.PauliZ(wires=0))
This circuit is composed of
qml.BlockEncodeandqml.PCPhaseoperations.>>> example_circuit(A) tensor(0.97777078, requires_grad=True) >>> print(example_circuit.qtape.expand(depth=1).draw(decimals=2)) 0: ─╭∏_ϕ(0.30)─╭BlockEncode(M0)─╭∏_ϕ(0.20)─╭BlockEncode(M0)†─╭∏_ϕ(0.10)─┤ <Z> 1: ─╰∏_ϕ(0.30)─╰BlockEncode(M0)─╰∏_ϕ(0.20)─╰BlockEncode(M0)†─╰∏_ϕ(0.10)─┤
The qml.qsvt function creates a circuit that is targeted at simulators due to the use of matrix-based operations. For advanced users, you can use the operation-based
qml.QSVTtemplate to perform the transformation with a custom choice of unitary and projector operations, which may be hardware compatible if a decomposition is provided.The QSVT is a complex but powerful transformation capable of generalizing important algorithms like amplitude amplification. Stay tuned for a demo in the coming few weeks to learn more!
Intuitive QNode returns ↩️
An updated QNode return system has been introduced. PennyLane QNodes now return exactly what you tell them to! 🎉 (#3957) (#3969) (#3946) (#3913) (#3914) (#3934)
This was an experimental feature introduced in version 0.25 of PennyLane that was enabled via
qml.enable_return(). Now, it’s the default return system. Let’s see how it works.Consider the following circuit:
import pennylane as qml dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)), qml.probs(0)
In version 0.29 and earlier of PennyLane,
circuit()would return a single length-3 array:>>> circuit(0.5) tensor([0.87758256, 0.93879128, 0.06120872], requires_grad=True)
In versions 0.30 and above,
circuit()returns a length-2 tuple containing the expectation value and probabilities separately:>>> circuit(0.5) (tensor(0.87758256, requires_grad=True), tensor([0.93879128, 0.06120872], requires_grad=True))
You can find more details about this change, along with help and troubleshooting tips to solve any issues. If you still have questions, comments, or concerns, we encourage you to post on the PennyLane discussion forum.
A bunch of performance tweaks 🏃💨
Single-qubit operations that have multi-qubit control can now be decomposed more efficiently using fewer CNOT gates. (#3851)
Three decompositions from arXiv:2302.06377 are provided and compare favourably to the already-available
qml.ops.ctrl_decomp_zyz:wires = [0, 1, 2, 3, 4, 5] control_wires = wires[1:] @qml.qnode(qml.device('default.qubit', wires=6)) def circuit(): with qml.QueuingManager.stop_recording(): # the decomposition does not un-queue the target target = qml.RX(np.pi/2, wires=0) qml.ops.ctrl_decomp_bisect(target, (1, 2, 3, 4, 5)) return qml.state() print(qml.draw(circuit, expansion_strategy="device")())
0: ──H─╭X──U(M0)─╭X──U(M0)†─╭X──U(M0)─╭X──U(M0)†──H─┤ State 1: ────├●────────│──────────├●────────│─────────────┤ State 2: ────├●────────│──────────├●────────│─────────────┤ State 3: ────╰●────────│──────────╰●────────│─────────────┤ State 4: ──────────────├●───────────────────├●────────────┤ State 5: ──────────────╰●───────────────────╰●────────────┤ State
A new decomposition to
qml.SingleExcitationhas been added that halves the number of CNOTs required. (3976)>>> qml.SingleExcitation.compute_decomposition(1.23, wires=(0,1)) [Adjoint(T(wires=[0])), Hadamard(wires=[0]), S(wires=[0]), Adjoint(T(wires=[1])), Adjoint(S(wires=[1])), Hadamard(wires=[1]), CNOT(wires=[1, 0]), RZ(-0.615, wires=[0]), RY(0.615, wires=[1]), CNOT(wires=[1, 0]), Adjoint(S(wires=[0])), Hadamard(wires=[0]), T(wires=[0]), Hadamard(wires=[1]), S(wires=[1]), T(wires=[1])]
The adjoint differentiation method can now be more efficient, avoiding the decomposition of operations that can be differentiated directly. Any operation that defines a
generator()can be differentiated with the adjoint method. (#3874)For example, in version 0.29 the
qml.CRYoperation would be decomposed when calculating the adjoint-method gradient. Executing the code below shows that this decomposition no longer takes place in version 0.30 andqml.CRYis differentiated directly:import jax from jax import numpy as jnp def compute_decomposition(self, phi, wires): print("A decomposition has been performed!") decomp_ops = [ qml.RY(phi / 2, wires=wires[1]), qml.CNOT(wires=wires), qml.RY(-phi / 2, wires=wires[1]), qml.CNOT(wires=wires), ] return decomp_ops qml.CRY.compute_decomposition = compute_decomposition dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, diff_method="adjoint") def circuit(phi): qml.Hadamard(wires=0) qml.CRY(phi, wires=[0, 1]) return qml.expval(qml.PauliZ(1)) phi = jnp.array(0.5) jax.grad(circuit)(phi)
Derivatives are computed more efficiently when using
jax.jitwith gradient transforms; the trainable parameters are now set correctly instead of every parameter having to be set as trainable. (#3697)In the circuit below, only the derivative with respect to parameter
bis now calculated:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, interface="jax-jit") def circuit(a, b): qml.RX(a, wires=0) qml.RY(b, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)) a = jnp.array(0.4) b = jnp.array(0.5) jac = jax.jacobian(circuit, argnums=[1]) jac_jit = jax.jit(jac) jac_jit(a, b) assert len(circuit.tape.trainable_params) == 1
Improvements 🛠
Next-generation device API
In this release and future releases, we will be making changes to our device API with the goal in mind to make developing plugins much easier for developers and unlock new device capabilities. Users shouldn’t yet feel any of these changes when using PennyLane, but here is what has changed this release:
Several functions in
devices/qubithave been added or improved:sample_state: returns a series of samples based on a given state vector and a number of shots. (#3720)simulate: supports measuring expectation values of large observables such asqml.Hamiltonian,qml.SparseHamiltonian, andqml.Sum. (#3759)apply_operation: supports broadcasting. (#3852)adjoint_jacobian: supports adjoint differentiation in the new qubit state-vector device. (#3790)
qml.devices.qubit.preprocessnow allows circuits with non-commuting observables. (#3857)qml.devices.qubit.measurenow computes the expectation values ofHamiltonianandSumin a backpropagation-compatible way. (#3862)
Pulse programming
Here are the functions, classes, and more that were added or improved to facilitate simulating ensembles of Rydberg atoms: (#3749) (#3911) (#3930) (#3936) (#3966) (#3987) (#3889) (#4021)
HardwareHamiltonian: an internal class that contains additional information about pulses and settings.rydberg_interaction: a user-facing function that returns aHardwareHamiltoniancontaining the Hamiltonian of the interaction of all the Rydberg atoms.transmon_interaction: a user-facing function for constructing the Hamiltonian that describes the circuit QED interaction Hamiltonian of superconducting transmon systems.drive: a user-facing function function that returns aParametrizedHamiltonian(HardwareHamiltonian) containing the Hamiltonian of the interaction between a driving electro-magnetic field and a group of qubits.rydberg_drive: a user-facing function that returns aParametrizedHamiltonian(HardwareHamiltonian) containing the Hamiltonian of the interaction between a driving laser field and a group of Rydberg atoms.max_distance: a keyword argument added toqml.pulse.rydberg_interactionto allow for the removal of negligible contributions from atoms beyondmax_distancefrom each other.
ParametrizedEvolutionnow takes two new Boolean keyword arguments:return_intermediateandcomplementary. They allow computing intermediate time evolution matrices. (#3900)Activating
return_intermediatewill return intermediate time evolution steps, for example for the matrix of the Operation, or of a quantum circuit when used in a QNode. Activatingcomplementarywill make these intermediate steps be the remaining time evolution complementary to the output forcomplementary=False. See the docstring for details.Hardware-compatible pulse sequence gradients with
qml.gradient.stoch_pulse_gradcan now be calculated faster using the new keyword argumentuse_broadcasting. Executing aParametrizedEvolutionthat returns intermediate evolutions has increased performance using the state vector ODE solver, as well. (#4000) (#4004)
Intuitive QNode returns
The QNode keyword argument
modehas been replaced by the booleangrad_on_execution. (#3969)The
"default.gaussian"device and parameter-shift CV both support the new return system, but only for single measurements. (#3946)Keras and Torch NN modules are now compatible with the new return type system. (#3913) (#3914)
DefaultQutritnow supports the new return system. (#3934)
Performance improvements
The efficiency of
tapering(),tapering_hf()andclifford()have been improved. (3942)The peak memory requirements of
tapering()andtapering_hf()have been improved when used for larger observables. (3977)Pauli arithmetic has been updated to convert to a Hamiltonian more efficiently. (#3939)
Operatorhas a new Boolean attributehas_generator. It returns whether or not theOperatorhas ageneratordefined.has_generatoris used inqml.operation.has_gen, which improves its performance and extends differentiation support. (#3875)The performance of
CompositeOphas been significantly improved now that it overrides determining whether it is being used with a batch of parameters (seeOperator._check_batching).Hamiltonianalso now overrides this, but it does nothing since it does not support batching. (#3915)The performance of a
Sumoperator has been significantly improved now thatis_hermitianchecks that all coefficients are real if the operator has a pre-computed Pauli representation. (#3915)The
coefficientsfunction and thevisualizesubmodule of theqml.fouriermodule now allow assigning different degrees for different parameters of the input function. (#3005)Previously, the arguments
degreeandfilter_thresholdtoqml.fourier.coefficientswere expected to be integers. Now, they can be a sequences of integers with one integer per function parameter (i.e.len(degree)==n_inputs), resulting in a returned array with shape(2*degrees[0]+1,..., 2*degrees[-1]+1). The functions inqml.fourier.visualizeaccordingly accept such arrays of coefficients.
Other improvements
A
Shotsclass has been added to themeasurementsmodule to hold shot-related data. (#3682)The custom JVP rules in PennyLane also now support non-scalar and mixed-shape tape parameters as well as multi-dimensional tape return types, like broadcasted
qml.probs, for example. (#3766)The
qchem.jordan_wignerfunction has been extended to support more fermionic operator orders. (#3754) (#3751)The
AdaptiveOptimizerhas been updated to use non-default user-defined QNode arguments. (#3765)Operators now use
TensorLiketypes dunder methods. (#3749)qml.QubitStateVector.state_vectornow supports broadcasting. (#3852)qml.SparseHamiltoniancan now be applied to any wires in a circuit rather than being restricted to all wires in the circuit. (#3888)Operators can now be divided by scalars with
/with the addition of theOperation.__truediv__dunder method. (#3749)Printing an instance of
MutualInfoMPnow displays the distribution of the wires between the two subsystems. (#3898)Operator.num_wireshas been changed from an abstract value toAnyWires. (#3919)qml.transforms.sum_expandis not run inDevice.batch_transformif the device supportsSumobservables. (#3915)The type of
n_electronsinqml.qchem.Moleculehas been set toint. (#3885)Explicit errors have been added to
QutritDeviceifclassical_shadoworshadow_expvalis measured. (#3934)QubitDevicenow defines the private_get_diagonalizing_gates(circuit)method and uses it when executing circuits. This allows devices that inherit fromQubitDeviceto override and customize their definition of diagonalizing gates. (#3938)retworkxhas been renamed torustworkxto accommodate the change in the package name. (#3975)Exp,Sum,Prod, andSProdoperator data is now a flat list instead of nested. (#3958) (#3983)qml.transforms.convert_to_numpy_parametershas been added to convert a circuit with interface-specific parameters to one with only numpy parameters. This transform is designed to replaceqml.tape.Unwrap. (#3899)qml.operation.WiresEnum.AllWiresis now -2 instead of 0 to avoid the ambiguity betweenop.num_wires = 0andop.num_wires = AllWires. (#3978)Execution code has been updated to use the new
qml.transforms.convert_to_numpy_parametersinstead ofqml.tape.Unwrap. (#3989)A sub-routine of
expand_tapehas been converted intoqml.tape.tape.rotations_and_diagonal_measurements, a helper function that computes rotations and diagonal measurements for a tape with measurements with overlapping wires. (#3912)Various operators and templates have been updated to ensure that their decompositions only return lists of operators. (#3243)
The
qml.operation.enable_new_opmathtoggle has been introduced to cause dunder methods to return arithmetic operators instead of aHamiltonianorTensor. (#4008)>>> type(qml.PauliX(0) @ qml.PauliZ(1)) <class 'pennylane.operation.Tensor'> >>> qml.operation.enable_new_opmath() >>> type(qml.PauliX(0) @ qml.PauliZ(1)) <class 'pennylane.ops.op_math.prod.Prod'> >>> qml.operation.disable_new_opmath() >>> type(qml.PauliX(0) @ qml.PauliZ(1)) <class 'pennylane.operation.Tensor'>
A new data class called
Resourceshas been added to store resources like the number of gates and circuit depth throughout a quantum circuit. (#3981)A new function called
_count_resources()has been added to count the resources required when executing aQuantumTapefor a given number of shots. (#3996)QuantumScript.specshas been modified to make use of the newResourcesclass. This also modifies the output ofqml.specs(). (#4015)A new class called
ResourcesOperationhas been added to allow users to define operations with custom resource information. (#4026)For example, users can define a custom operation by inheriting from this new class:
>>> class CustomOp(qml.resource.ResourcesOperation): ... def resources(self): ... return qml.resource.Resources(num_wires=1, num_gates=2, ... gate_types={"PauliX": 2}) ... >>> CustomOp(wires=1) CustomOp(wires=[1])
Then, we can track and display the resources of the workflow using
qml.specs():>>> dev = qml.device("default.qubit", wires=[0,1]) >>> @qml.qnode(dev) ... def circ(): ... qml.PauliZ(wires=0) ... CustomOp(wires=1) ... return qml.state() ... >>> print(qml.specs(circ)()['resources']) wires: 2 gates: 3 depth: 1 shots: 0 gate_types: {'PauliZ': 1, 'PauliX': 2}
MeasurementProcess.shapenow accepts aShotsobject as one of its arguments to reduce exposure to unnecessary execution details. (#4012)
Breaking changes 💔
The
seed_recipesargument has been removed fromqml.classical_shadowandqml.shadow_expval. (#4020)The tape method
get_operationhas an updated signature. (#3998)Both JIT interfaces are no longer compatible with JAX
>0.4.3(we raise an error for those versions). (#3877)An operation that implements a custom
generatormethod, but does not always return a valid generator, also has to implement ahas_generatorproperty that reflects in which scenarios a generator will be returned. (#3875)Trainable parameters for the Jax interface are the parameters that are
JVPTracer, defined by settingargnums. Previously, all JAX tracers, including those used for JIT compilation, were interpreted to be trainable. (#3697)The keyword argument
argnumsis now used for gradient transforms using Jax instead ofargnum.argnumis automatically converted toargnumswhen using Jax and will no longer be supported in v0.31 of PennyLane. (#3697) (#3847)qml.OrbitalRotationand, consequently,qml.GateFabricare now more consistent with the interleaved Jordan-Wigner ordering. Previously, they were consistent with the sequential Jordan-Wigner ordering. (#3861)Some
MeasurementProcessclasses can now only be instantiated with arguments that they will actually use. For example, you can no longer createStateMP(qml.PauliX(0))orPurityMP(eigvals=(-1,1), wires=Wires(0)). (#3898)Exp,Sum,Prod, andSProdoperator data is now a flat list, instead of nested. (#3958) (#3983)qml.tape.tape.expand_tapeand, consequentially,QuantumScript.expandno longer update the input tape with rotations and diagonal measurements. Note that the newly expanded tape that is returned will still have the rotations and diagonal measurements. (#3912)qml.Evolutionnow initializes the coefficient with a factor of-1jinstead of1j. (#4024)
Deprecations 👋
Nothing for this release!
Documentation 📝
The documentation of
QubitUnitaryandDiagonalQubitUnitarywas clarified regarding the parameters of the operations. (#4031)A typo has been corrected in the documentation for the introduction to
inspecting_circuitsandchemistry. (#3844)Usage DetailsandTheorysections have been separated in the documentation forqml.qchem.taper_operation. (3977)
Bug fixes 🐛
ctrl_decomp_bisectandctrl_decomp_zyzare no longer used by default when decomposing controlled operations due to the presence of a global phase difference in the zyz decomposition of some target operators. (#4065)Fixed a bug where
qml.math.dotreturned a numpy array instead of an autograd array, breaking autograd derivatives in certain circumstances. (#4019)Operators now cast a
tupleto annp.ndarrayas well aslist. (#4022)Fixed a bug where
qml.ctrlwith parametric gates was incompatible with PyTorch tensors on GPUs. (#4002)Fixed a bug where the broadcast expand results were stacked along the wrong axis for the new return system. (#3984)
A more informative error message is raised in
qml.jacobianto explain potential problems with the new return types specification. (#3997)Fixed a bug where calling
Evolution.generatorwithcoeffbeing a complex ArrayBox raised an error. (#3796)MeasurementProcess.hashnow uses the hash property of the observable. The property now depends on all properties that affect the behaviour of the object, such asVnEntropyMP.log_baseor the distribution of wires between the two subsystems inMutualInfoMP. (#3898)The enum
measurements.Purityhas been added so thatPurityMP.return_typeis defined.strandreprforPurityMPare also now defined. (#3898)Sum.hashandProd.hashhave been changed slightly to work with non-numeric wire labels.sum_expandshould now return correct results and not treat some products as the same operation. (#3898)Fixed bug where the coefficients where not ordered correctly when summing a
ParametrizedHamiltonianwith other operators. (#3749) (#3902)The metric tensor transform is now fully compatible with Jax and therefore users can provide multiple parameters. (#3847)
qml.math.ndimandqml.math.shapeare now registered for built-ins and autograd to accomodate Autoray 0.6.1. #3864Ensured that
qml.data.loadreturns datasets in a stable and expected order. (#3856)The
qml.equalfunction now handles comparisons ofParametrizedEvolutionoperators. (#3870)qml.devices.qubit.apply_operationcatches thetf.errors.UnimplementedErrorthat occurs whenPauliZorCNOTgates are applied to a large (>8 wires) tensorflow state. When that occurs, the logic falls back to the tensordot logic instead. (#3884)Fixed parameter broadcasting support with
qml.countsin most cases and introduced explicit errors otherwise. (#3876)An error is now raised if a QNode with Jax-jit in use returns
countswhile having trainable parameters (#3892)A correction has been added to the reference values in
test_dipole_ofto account for small changes (~2e-8) in the computed dipole moment values resulting from the new PySCF 2.2.0 release. (#3908)SampleMP.shapeis now correct when sampling only occurs on a subset of the device wires. (#3921)An issue has been fixed in
qchem.Moleculeto allow basis sets other than the hard-coded ones to be used in theMoleculeclass. (#3955)Fixed bug where all devices that inherit from
DefaultQubitclaimed to supportParametrizedEvolution. Now, onlyDefaultQubitJaxsupports the operator, as expected. (#3964)Ensured that parallel
AnnotatedQueuesdo not queue each other’s contents. (#3924)Added a
map_wiresmethod toPauliWordandPauliSentence, and ensured that operators call it in their respectivemap_wiresmethods if they have a Pauli rep. (#3985)Fixed a bug when a
Tensoris multiplied by aHamiltonianor vice versa. (#4036)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Komi Amiko, Utkarsh Azad, Thomas Bromley, Isaac De Vlugt, Olivia Di Matteo, Lillian M. A. Frederiksen, Diego Guala, Soran Jahangiri, Korbinian Kottmann, Christina Lee, Vincent Michaud-Rioux, Albert Mitjans Coma, Romain Moyard, Lee J. O’Riordan, Mudit Pandey, Matthew Silverman, Jay Soni, David Wierichs.
Release 0.29.0¶
New features since last release
Pulse programming 🔊
Support for creating pulse-based circuits that describe evolution under a time-dependent Hamiltonian has now been added, as well as the ability to execute and differentiate these pulse-based circuits on simulator. (#3586) (#3617) (#3645) (#3652) (#3665) (#3673) (#3706) (#3730)
A time-dependent Hamiltonian can be created using
qml.pulse.ParametrizedHamiltonian, which holds information representing a linear combination of operators with parametrized coefficents and can be constructed as follows:from jax import numpy as jnp f1 = lambda p, t: p * jnp.sin(t) * (t - 1) f2 = lambda p, t: p[0] * jnp.cos(p[1]* t ** 2) XX = qml.PauliX(0) @ qml.PauliX(1) YY = qml.PauliY(0) @ qml.PauliY(1) ZZ = qml.PauliZ(0) @ qml.PauliZ(1) H = 2 * ZZ + f1 * XX + f2 * YY
>>> H ParametrizedHamiltonian: terms=3 >>> p1 = jnp.array(1.2) >>> p2 = jnp.array([2.3, 3.4]) >>> H((p1, p2), t=0.5) (2*(PauliZ(wires=[0]) @ PauliZ(wires=[1]))) + ((-0.2876553231625218*(PauliX(wires=[0]) @ PauliX(wires=[1]))) + (1.517961235535459*(PauliY(wires=[0]) @ PauliY(wires=[1]))))
The time-dependent Hamiltonian can be used within a circuit with
qml.evolve:def pulse_circuit(params, time): qml.evolve(H)(params, time) return qml.expval(qml.PauliX(0) @ qml.PauliY(1))
Pulse-based circuits can be executed and differentiated on the
default.qubit.jaxsimulator using JAX as an interface:>>> dev = qml.device("default.qubit.jax", wires=2) >>> qnode = qml.QNode(pulse_circuit, dev, interface="jax") >>> params = (p1, p2) >>> qnode(params, time=0.5) Array(0.72153819, dtype=float64) >>> jax.grad(qnode)(params, time=0.5) (Array(-0.11324919, dtype=float64), Array([-0.64399616, 0.06326374], dtype=float64))
Check out the qml.pulse documentation page for more details!
Special unitary operation 🌞
A new operation
qml.SpecialUnitaryhas been added, providing access to an arbitrary unitary gate via a parametrization in the Pauli basis. (#3650) (#3651) (#3674)qml.SpecialUnitarycreates a unitary that exponentiates a linear combination of all possible Pauli words in lexicographical order — except for the identity operator — fornum_wireswires, of which there are4**num_wires - 1. As its first argument,qml.SpecialUnitarytakes a list of the4**num_wires - 1parameters that are the coefficients of the linear combination.To see all possible Pauli words for
num_wireswires, you can use theqml.ops.qubit.special_unitary.pauli_basis_stringsfunction:>>> qml.ops.qubit.special_unitary.pauli_basis_strings(1) # 4**1-1 = 3 Pauli words ['X', 'Y', 'Z'] >>> qml.ops.qubit.special_unitary.pauli_basis_strings(2) # 4**2-1 = 15 Pauli words ['IX', 'IY', 'IZ', 'XI', 'XX', 'XY', 'XZ', 'YI', 'YX', 'YY', 'YZ', 'ZI', 'ZX', 'ZY', 'ZZ']
To use
qml.SpecialUnitary, for example, on a single qubit, we may define>>> thetas = np.array([0.2, 0.1, -0.5]) >>> U = qml.SpecialUnitary(thetas, 0) >>> qml.matrix(U) array([[ 0.8537127 -0.47537233j, 0.09507447+0.19014893j], [-0.09507447+0.19014893j, 0.8537127 +0.47537233j]])
A single non-zero entry in the parameters will create a Pauli rotation:
>>> x = 0.412 >>> theta = x * np.array([1, 0, 0]) # The first entry belongs to the Pauli word "X" >>> su = qml.SpecialUnitary(theta, wires=0) >>> rx = qml.RX(-2 * x, 0) # RX introduces a prefactor -0.5 that has to be compensated >>> qml.math.allclose(qml.matrix(su), qml.matrix(rx)) True
This operation can be differentiated with hardware-compatible methods like parameter shifts and it supports parameter broadcasting/batching, but not both at the same time. Learn more by visiting the qml.SpecialUnitary documentation.
Always differentiable 📈
The Hadamard test gradient transform is now available via
qml.gradients.hadamard_grad. This transform is also available as a differentiation method withinQNodes. (#3625) (#3736)qml.gradients.hadamard_gradis a hardware-compatible transform that calculates the gradient of a quantum circuit using the Hadamard test. Note that the device requires an auxiliary wire to calculate the gradient.>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit(params): ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.RX(params[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> params = np.array([0.1, 0.2, 0.3], requires_grad=True) >>> qml.gradients.hadamard_grad(circuit)(params) (tensor(-0.3875172, requires_grad=True), tensor(-0.18884787, requires_grad=True), tensor(-0.38355704, requires_grad=True))
This transform can be registered directly as the quantum gradient transform to use during autodifferentiation:
>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev, interface="jax", diff_method="hadamard") ... def circuit(params): ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.RX(params[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> params = jax.numpy.array([0.1, 0.2, 0.3]) >>> jax.jacobian(circuit)(params) Array([-0.3875172 , -0.18884787, -0.38355705], dtype=float32)
The gradient transform
qml.gradients.spsa_gradis now registered as a differentiation method for QNodes. (#3440)The SPSA gradient transform can now be used implicitly by marking a QNode as differentiable with SPSA. It can be selected via
>>> dev = qml.device("default.qubit", wires=1) >>> @qml.qnode(dev, interface="jax", diff_method="spsa", h=0.05, num_directions=20) ... def circuit(x): ... qml.RX(x, 0) ... return qml.expval(qml.PauliZ(0)) >>> jax.jacobian(circuit)(jax.numpy.array(0.5)) Array(-0.4792258, dtype=float32, weak_type=True)
The argument
num_directionsdetermines how many directions of simultaneous perturbation are used and therefore the number of circuit evaluations, up to a prefactor. See the SPSA gradient transform documentation for details. Note: The full SPSA optimization method is already available asqml.SPSAOptimizer.The default interface is now
auto. There is no need to specify the interface anymore; it is automatically determined by checking your QNode parameters. (#3677) (#3752) (#3829)import jax import jax.numpy as jnp qml.enable_return() a = jnp.array(0.1) b = jnp.array(0.2) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliY(1))
>>> circuit(a, b) (Array(0.9950042, dtype=float32), Array(-0.19767681, dtype=float32)) >>> jac = jax.jacobian(circuit)(a, b) >>> jac (Array(-0.09983341, dtype=float32, weak_type=True), Array(0.01983384, dtype=float32, weak_type=True))
The JAX-JIT interface now supports higher-order gradient computation with the new return types system. (#3498)
Here is an example of using JAX-JIT to compute the Hessian of a circuit:
import pennylane as qml import jax from jax import numpy as jnp jax.config.update("jax_enable_x64", True) qml.enable_return() dev = qml.device("default.qubit", wires=2) @jax.jit @qml.qnode(dev, interface="jax-jit", diff_method="parameter-shift", max_diff=2) def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=1) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1)) a, b = jnp.array(1.0), jnp.array(2.0)
>>> jax.hessian(circuit, argnums=[0, 1])(a, b) (((Array(-0.54030231, dtype=float64, weak_type=True), Array(0., dtype=float64, weak_type=True)), (Array(-1.76002563e-17, dtype=float64, weak_type=True), Array(0., dtype=float64, weak_type=True))), ((Array(0., dtype=float64, weak_type=True), Array(-1.00700085e-17, dtype=float64, weak_type=True)), (Array(0., dtype=float64, weak_type=True), Array(0.41614684, dtype=float64, weak_type=True))))
The
qchemworkflow has been modified to support both Autograd and JAX frameworks. (#3458) (#3462) (#3495)The JAX interface is automatically used when the differentiable parameters are JAX objects. Here is an example for computing the Hartree-Fock energy gradients with respect to the atomic coordinates.
import pennylane as qml from pennylane import numpy as np import jax symbols = ["H", "H"] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) mol = qml.qchem.Molecule(symbols, geometry) args = [jax.numpy.array(mol.coordinates)]
>>> jax.grad(qml.qchem.hf_energy(mol))(*args) Array([[ 0. , 0. , 0.3650435], [ 0. , 0. , -0.3650435]], dtype=float64)
The kernel matrix utility functions in
qml.kernelsare now autodifferentiation-compatible. In addition, they support batching, for example for quantum kernel execution with shot vectors. (#3742)This allows for the following:
dev = qml.device('default.qubit', wires=2, shots=(100, 100)) @qml.qnode(dev) def circuit(x1, x2): qml.templates.AngleEmbedding(x1, wires=dev.wires) qml.adjoint(qml.templates.AngleEmbedding)(x2, wires=dev.wires) return qml.probs(wires=dev.wires) kernel = lambda x1, x2: circuit(x1, x2)
We can then compute the kernel matrix on a set of 4 (random) feature vectors
Xbut using two sets of 100 shots each via>>> X = np.random.random((4, 2)) >>> qml.kernels.square_kernel_matrix(X, kernel)[:, 0] tensor([[[1. , 0.86, 0.88, 0.92], [0.86, 1. , 0.75, 0.97], [0.88, 0.75, 1. , 0.91], [0.92, 0.97, 0.91, 1. ]], [[1. , 0.93, 0.91, 0.92], [0.93, 1. , 0.8 , 1. ], [0.91, 0.8 , 1. , 0.91], [0.92, 1. , 0.91, 1. ]]], requires_grad=True)
Note that we have extracted the first probability vector entry for each 100-shot evaluation.
Smartly decompose Hamiltonian evolution 💯
Hamiltonian evolution using
qml.evolveorqml.expcan now be decomposed into operations. (#3691) (#3777)If the time-evolved Hamiltonian is equivalent to another PennyLane operation, then that operation is returned as the decomposition:
>>> exp_op = qml.evolve(qml.PauliX(0) @ qml.PauliX(1)) >>> exp_op.decomposition() [IsingXX((2+0j), wires=[0, 1])]
If the Hamiltonian is a Pauli word, then the decomposition is provided as a
qml.PauliRotoperation:>>> qml.evolve(qml.PauliZ(0) @ qml.PauliX(1)).decomposition() [PauliRot((2+0j), ZX, wires=[0, 1])]
Otherwise, the Hamiltonian is a linear combination of operators and the Suzuki-Trotter decomposition is used:
>>> qml.evolve(qml.sum(qml.PauliX(0), qml.PauliY(0), qml.PauliZ(0)), num_steps=2).decomposition() [RX((1+0j), wires=[0]), RY((1+0j), wires=[0]), RZ((1+0j), wires=[0]), RX((1+0j), wires=[0]), RY((1+0j), wires=[0]), RZ((1+0j), wires=[0])]
Tools for quantum chemistry and other applications 🛠️
A new method called
qml.qchem.givens_decompositionhas been added, which decomposes a unitary into a sequence of Givens rotation gates with phase shifts and a diagonal phase matrix. (#3573)unitary = np.array([[ 0.73678+0.27511j, -0.5095 +0.10704j, -0.06847+0.32515j], [-0.21271+0.34938j, -0.38853+0.36497j, 0.61467-0.41317j], [ 0.41356-0.20765j, -0.00651-0.66689j, 0.32839-0.48293j]]) phase_mat, ordered_rotations = qml.qchem.givens_decomposition(unitary)
>>> phase_mat tensor([-0.20604358+0.9785369j , -0.82993272+0.55786114j, 0.56230612-0.82692833j], requires_grad=True) >>> ordered_rotations [(tensor([[-0.65087861-0.63937521j, -0.40933651-0.j ], [-0.29201359-0.28685265j, 0.91238348-0.j ]], requires_grad=True), (0, 1)), (tensor([[ 0.47970366-0.33308926j, -0.8117487 -0.j ], [ 0.66677093-0.46298215j, 0.5840069 -0.j ]], requires_grad=True), (1, 2)), (tensor([[ 0.36147547+0.73779454j, -0.57008306-0.j ], [ 0.2508207 +0.51194108j, 0.82158706-0.j ]], requires_grad=True), (0, 1))]
A new template called
qml.BasisRotationhas been added, which performs a basis transformation defined by a set of fermionic ladder operators. (#3573)import pennylane as qml from pennylane import numpy as np V = np.array([[ 0.53672126+0.j , -0.1126064 -2.41479668j], [-0.1126064 +2.41479668j, 1.48694623+0.j ]]) eigen_vals, eigen_vecs = np.linalg.eigh(V) umat = eigen_vecs.T wires = range(len(umat)) def circuit(): qml.adjoint(qml.BasisRotation(wires=wires, unitary_matrix=umat)) for idx, eigenval in enumerate(eigen_vals): qml.RZ(eigenval, wires=[idx]) qml.BasisRotation(wires=wires, unitary_matrix=umat)
>>> circ_unitary = qml.matrix(circuit)() >>> np.round(circ_unitary/circ_unitary[0][0], 3) tensor([[ 1. -0.j , -0. +0.j , -0. +0.j , -0. +0.j ], [-0. +0.j , -0.516-0.596j, -0.302-0.536j, -0. +0.j ], [-0. +0.j , 0.35 +0.506j, -0.311-0.724j, -0. +0.j ], [-0. +0.j , -0. +0.j , -0. +0.j , -0.438+0.899j]], requires_grad=True)
A new function called
qml.qchem.load_basissethas been added to extractqml.qchembasis set data from the Basis Set Exchange library. (#3363)A new function called
qml.math.max_entropyhas been added to compute the maximum entropy of a quantum state. (#3594)A new template called
qml.TwoLocalSwapNetworkhas been added that implements a canonical 2-complete linear (2-CCL) swap network described in arXiv:1905.05118. (#3447)dev = qml.device('default.qubit', wires=5) weights = np.random.random(size=qml.templates.TwoLocalSwapNetwork.shape(len(dev.wires))) acquaintances = lambda index, wires, param: (qml.CRY(param, wires=index) if np.abs(wires[0]-wires[1]) else qml.CRZ(param, wires=index)) @qml.qnode(dev) def swap_network_circuit(): qml.templates.TwoLocalSwapNetwork(dev.wires, acquaintances, weights, fermionic=False) return qml.state()
>>> print(weights) tensor([0.20308242, 0.91906199, 0.67988804, 0.81290256, 0.08708985, 0.81860084, 0.34448344, 0.05655892, 0.61781612, 0.51829044], requires_grad=True) >>> print(qml.draw(swap_network_circuit, expansion_strategy = 'device')()) 0: ─╭●────────╭SWAP─────────────────╭●────────╭SWAP─────────────────╭●────────╭SWAP─┤ State 1: ─╰RY(0.20)─╰SWAP─╭●────────╭SWAP─╰RY(0.09)─╰SWAP─╭●────────╭SWAP─╰RY(0.62)─╰SWAP─┤ State 2: ─╭●────────╭SWAP─╰RY(0.68)─╰SWAP─╭●────────╭SWAP─╰RY(0.34)─╰SWAP─╭●────────╭SWAP─┤ State 3: ─╰RY(0.92)─╰SWAP─╭●────────╭SWAP─╰RY(0.82)─╰SWAP─╭●────────╭SWAP─╰RY(0.52)─╰SWAP─┤ State 4: ─────────────────╰RY(0.81)─╰SWAP─────────────────╰RY(0.06)─╰SWAP─────────────────┤ State
Improvements 🛠
Pulse programming
A new function called
qml.pulse.pwchas been added as a convenience function for defining aqml.pulse.ParametrizedHamiltonian. This function can be used to create a callable coefficient by setting the timespan over which the function should be non-zero. The resulting callable can be passed an array of parameters and a time. (#3645)>>> timespan = (2, 4) >>> f = qml.pulse.pwc(timespan) >>> f * qml.PauliX(0) ParametrizedHamiltonian: terms=1
The
paramsarray will be used as bin values evenly distributed over the timespan, and the parametertwill determine which of the bins is returned.>>> f(params=[1.2, 2.3, 3.4, 4.5], t=3.9) DeviceArray(4.5, dtype=float32) >>> f(params=[1.2, 2.3, 3.4, 4.5], t=6) # zero outside the range (2, 4) DeviceArray(0., dtype=float32)
A new function called
qml.pulse.pwc_from_functionhas been added as a decorator for defining aqml.pulse.ParametrizedHamiltonian. This function can be used to decorate a function and create a piecewise constant approximation of it. (#3645)>>> @qml.pulse.pwc_from_function((2, 4), num_bins=10) ... def f1(p, t): ... return p * t
The resulting function approximates the same of
p**2 * ton the intervalt=(2, 4)in 10 bins, and returns zero outside the interval.# t=2 and t=2.1 are within the same bin >>> f1(3, 2), f1(3, 2.1) (DeviceArray(6., dtype=float32), DeviceArray(6., dtype=float32)) # next bin >>> f1(3, 2.2) DeviceArray(6.6666665, dtype=float32) # outside the interval t=(2, 4) >>> f1(3, 5) DeviceArray(0., dtype=float32)
Add
ParametrizedHamiltonianPytreeclass, which is a pytree jax object representing a parametrized Hamiltonian, where the matrix computation is delayed to improve performance. (#3779)
Operations and batching
The function
qml.dothas been updated to compute the dot product between a vector and a list of operators. (#3586)>>> coeffs = np.array([1.1, 2.2]) >>> ops = [qml.PauliX(0), qml.PauliY(0)] >>> qml.dot(coeffs, ops) (1.1*(PauliX(wires=[0]))) + (2.2*(PauliY(wires=[0]))) >>> qml.dot(coeffs, ops, pauli=True) 1.1 * X(0) + 2.2 * Y(0)
qml.evolvereturns the evolution of anOperatoror aParametrizedHamiltonian. (#3617) (#3706)qml.ControlledQubitUnitarynow inherits fromqml.ops.op_math.ControlledOp, which definesdecomposition,expand, andsparse_matrixrather than raising an error. (#3450)Parameter broadcasting support has been added for the
qml.ops.op_math.Controlledclass if the base operator supports broadcasting. (#3450)The
qml.generatorfunction now checks if the generator is Hermitian, rather than whether it is a subclass ofObservable. This allows it to return valid generators fromSymbolicOpandCompositeOpclasses. (#3485)The
qml.equalfunction has been extended to compareProdandSumoperators. (#3516)qml.purityhas been added as a measurement process for purity (#3551)In-place inversion has been removed for qutrit operations in preparation for the removal of in-place inversion. (#3566)
The
qml.utils.sparse_hamiltonianfunction has been moved to theeqml.Hamiltonian.sparse_matrixmethod. (#3585)The
qml.pauli.PauliSentence.operation()method has been improved to avoid instantiating anSProdoperator when the coefficient is equal to 1. (#3595)Batching is now allowed in all
SymbolicOpoperators, which includeExp,PowandSProd. (#3597)The
SumandProdoperations now have broadcasted operands. (#3611)The XYX single-qubit unitary decomposition has been implemented. (#3628)
All dunder methods now return
NotImplemented, allowing the right dunder method (e.g.__radd__) of the other class to be called. (#3631)The
qml.GellMannoperators now include their index when displayed. (#3641)qml.ops.ctrl_decomp_zyzhas been added to compute the decomposition of a controlled single-qubit operation given a single-qubit operation and the control wires. (#3681)qml.pauli.is_pauli_wordnow supportsProdandSProdoperators, and it returnsFalsewhen aHamiltoniancontains more than one term. (#3692)qml.pauli.pauli_word_to_stringnow supportsProd,SProdandHamiltonianoperators. (#3692)qml.ops.op_math.Controlledcan now decompose single qubit target operations more effectively using the ZYZ decomposition. (#3726)The
qml.qchem.Moleculeclass raises an error when the molecule has an odd number of electrons or when the spin multiplicity is not 1. (#3748)
qml.qchem.basis_rotationnow accounts for spin, allowing it to perform Basis Rotation Groupings for molecular hamiltonians. (#3714) (#3774)The gradient transforms work for the new return type system with non-trivial classical jacobians. (#3776)
The
default.mixeddevice has received a performance improvement for multi-qubit operations. This also allows to apply channels that act on more than seven qubits, which was not possible before. (#3584)qml.dotnow groups coefficients together. (#3691)>>> qml.dot(coeffs=[2, 2, 2], ops=[qml.PauliX(0), qml.PauliY(1), qml.PauliZ(2)]) 2*(PauliX(wires=[0]) + PauliY(wires=[1]) + PauliZ(wires=[2]))
qml.generatornow supports operators withSumandProdgenerators. (#3691)The
Sum._sortmethod now takes into account the name of the operator when sorting. (#3691)A new tape transform called
qml.transforms.sign_expandhas been added. It implements the optimal decomposition of a fast-forwardable Hamiltonian that minimizes the variance of its estimator in the Single-Qubit-Measurement from arXiv:2207.09479. (#2852)
Differentiability and interfaces
The
qml.mathmodule now also contains a submodule for fast Fourier transforms,qml.math.fft. (#1440)The submodule in particular provides differentiable versions of the following functions, available in all common interfaces for PennyLane
Note that the output of the derivative of these functions may differ when used with complex-valued inputs, due to different conventions on complex-valued derivatives.
Validation has been added on gradient keyword arguments when initializing a QNode — if unexpected keyword arguments are passed, a
UserWarningis raised. A list of the current expected gradient function keyword arguments can be accessed viaqml.gradients.SUPPORTED_GRADIENT_KWARGS. (#3526)The
numpyversion has been constrained to<1.24. (#3563)Support for two-qubit unitary decomposition with JAX-JIT has been added. (#3569)
qml.math.sizenow supports PyTorch tensors. (#3606)Most quantum channels are now fully differentiable on all interfaces. (#3612)
qml.math.matmulnow supports PyTorch and Autograd tensors. (#3613)Add
qml.math.detach, which detaches a tensor from its trace. This stops automatic gradient computations. (#3674)Add
typing.TensorLiketype. (#3675)qml.QuantumMonteCarlotemplate is now JAX-JIT compatible when passingjax.numpyarrays to the template. (#3734)DefaultQubitJaxnow supports evolving the state vector when executingqml.pulse.ParametrizedEvolutiongates. (#3743)SProd.sparse_matrixnow supports interface-specific variables with a single element as thescalar. (#3770)Added
argnumargument tometric_tensor. By passing a sequence of indices referring to trainable tape parameters, the metric tensor is only computed with respect to these parameters. This reduces the number of tapes that have to be run. (#3587)The parameter-shift derivative of variances saves a redundant evaluation of the corresponding unshifted expectation value tape, if possible (#3744)
Next generation device API
The
apply_operationsingle-dispatch function is added todevices/qubitthat applies an operation to a state and returns a new state. (#3637)The
preprocessfunction is added todevices/qubitthat validates, expands, and transforms a batch ofQuantumTapeobjects to abstract preprocessing details away from the device. (#3708)The
create_initial_statefunction is added todevices/qubitthat returns an initial state for an execution. (#3683)The
simulatefunction is added todevices/qubitthat turns a single quantum tape into a measurement result. The function only supports state based measurements with either no observables or observables with diagonalizing gates. It supports simultaneous measurement of non-commuting observables. (#3700)The
ExecutionConfigdata class has been added. (#3649)The
StatePrepclass has been added as an interface that state-prep operators must implement. (#3654)qml.QubitStateVectornow implements theStatePrepinterface. (#3685)qml.BasisStatenow implements theStatePrepinterface. (#3693)New Abstract Base Class for devices
Deviceis added to thedevices.experimentalsubmodule. This interface is still in experimental mode and not integrated with the rest of pennylane. (#3602)
Other improvements
Writing Hamiltonians to a file using the
qml.datamodule has been improved by employing a condensed writing format. (#3592)Lazy-loading in the
qml.data.Dataset.read()method is more universally supported. (#3605)The
qchem.Moleculeclass raises an error when the molecule has an odd number of electrons or when the spin multiplicity is not 1. (#3748)qml.drawandqml.draw_mplhave been updated to draw any quantum function, which allows for visualizing only part of a complete circuit/QNode. (#3760)The string representation of a Measurement Process now includes the
_eigvalsproperty if it is set. (#3820)
Breaking changes 💔
The argument
modein execution has been replaced by the booleangrad_on_executionin the new execution pipeline. (#3723)qml.VQECosthas been removed. (#3735)The default interface is now
auto. (#3677) (#3752) (#3829)The interface is determined during the QNode call instead of the initialization. It means that the
gradient_fnandgradient_kwargsare only defined on the QNode at the beginning of the call. Moreover, without specifying the interface it is not possible to guarantee that the device will not be changed during the call if you are using backprop (such asdefault.qubitchanging todefault.qubit.jax) whereas before it was happening at initialization.The tape method
get_operationcan also now return the operation index in the tape, and it can be activated by setting thereturn_op_indextoTrue:get_operation(idx, return_op_index=True). It will become the default in version0.30. (#3667)Operation.inv()and theOperation.inversesetter have been removed. Please useqml.adjointorqml.powinstead. (#3618)For example, instead of
>>> qml.PauliX(0).inv()
use
>>> qml.adjoint(qml.PauliX(0))
The
Operation.inverseproperty has been removed completely. (#3725)The target wires of
qml.ControlledQubitUnitaryare no longer available viaop.hyperparameters["u_wires"]. Instead, they can be accesses viaop.base.wiresorop.target_wires. (#3450)The tape constructed by a
QNodeis no longer queued to surrounding contexts. (#3509)Nested operators like
Tensor,Hamiltonian, andAdjointnow remove their owned operators from the queue instead of updating their metadata to have an"owner". (#3282)qml.qchem.scf,qml.RandomLayers.compute_decomposition, andqml.Wires.select_randomnow use local random number generators instead of global random number generators. This may lead to slightly different random numbers and an independence of the results from the global random number generation state. Please provide a seed to each individual function instead if you want controllable results. (#3624)qml.transforms.measurement_groupinghas been removed. Users should useqml.transforms.hamiltonian_expandinstead. (#3701)op.simplify()for operators which are linear combinations of Pauli words will use a builtin Pauli representation to more efficiently compute the simplification of the operator. (#3481)All
Operator‘s input parameters that are lists are cast into vanilla numpy arrays. (#3659)QubitDevice.expvalno longer permutes an observable’s wire order before passing it toQubitDevice.probability. The associated downstream changes fordefault.qubithave been made, but this may still affect expectations for other devices that inherit fromQubitDeviceand overrideprobability(or any other helper functions that take a wire order such asmarginal_prob,estimate_probabilityoranalytic_probability). (#3753)
Deprecations 👋
qml.utils.sparse_hamiltonianfunction has been deprecated, and usage will now raise a warning. Instead, one should use theqml.Hamiltonian.sparse_matrixmethod. (#3585)qml.op_sumhas been deprecated. Users should useqml.suminstead. (#3686)The use of
Evolutiondirectly has been deprecated. Users should useqml.evolveinstead. This new function changes the sign of the given parameter. (#3706)Use of
qml.dotwith aQNodeCollectionhas been deprecated. (#3586)
Documentation 📝
Revise note on GPU support in the circuit introduction. (#3836)
Make warning about vanilla version of NumPy for differentiation more prominent. (#3838)
The documentation for
qml.operationhas been improved. (#3664)The code example in
qml.SparseHamiltonianhas been updated with the correct wire range. (#3643)A hyperlink has been added in the text for a URL in the
qml.qchem.mol_datadocstring. (#3644)A typo was corrected in the documentation for
qml.math.vn_entropy. (#3740)
Bug fixes 🐛
Fixed a bug where measuring
qml.probsin the computational basis with non-commuting measurements returned incorrect results. Now an error is raised. (#3811)Fixed a bug where measuring
qml.probsin the computational basis with non-commuting measurements returned incorrect results. Now an error is raised. (#3811)Fixed a bug in the drawer where nested controlled operations would output the label of the operation being controlled, rather than the control values. (#3745)
Fixed a bug in
qml.transforms.metric_tensorwhere prefactors of operation generators were taken into account multiple times, leading to wrong outputs for non-standard operations. (#3579)Local random number generators are now used where possible to avoid mutating the global random state. (#3624)
The
networkxversion change being broken has been fixed by selectively skipping aqcutTensorFlow-JIT test. (#3609) (#3619)Fixed the wires for the
Ydecomposition in the ZX calculus transform. (#3598)qml.pauli.PauliWordis now pickle-able. (#3588)Child classes of
QuantumScriptnow return their own type when usingSomeChildClass.from_queue. (#3501)A typo has been fixed in the calculation and error messages in
operation.py(#3536)qml.data.Dataset.write()now ensures that any lazy-loaded values are loaded before they are written to a file. (#3605)Tensor._batch_sizeis now set toNoneduring initialization, copying andmap_wires. (#3642) (#3661)Tensor.has_matrixis now set toTrue. (#3647)Fixed typo in the example of
qml.IsingZZgate decomposition. (#3676)Fixed a bug that made tapes/qnodes using
qml.Snapshotincompatible withqml.drawer.tape_mpl. (#3704)Tensor._pauli_repis set toNoneduring initialization andTensor.datahas been added to its setter. (#3722)qml.math.ndimhas been redirected tojnp.ndimwhen using it on ajaxtensor. (#3730)Implementations of
marginal_prob(and subsequently,qml.probs) now return probabilities with the expected wire order. (#3753)This bug affected most probabilistic measurement processes on devices that inherit from
QubitDevicewhen the measured wires are out of order with respect to the device wires and 3 or more wires are measured. The assumption was that marginal probabilities would be computed with the device’s state and wire order, then re-ordered according to the measurement process wire order. Instead, the re-ordering went in the inverse direction (that is, from measurement process wire order to device wire order). This is now fixed. Note that this only occurred for 3 or more measured wires because this mapping is identical otherwise. More details and discussion of this bug can be found in the original bug report.Empty iterables can no longer be returned from QNodes. (#3769)
The keyword arguments for
qml.equalnow are used when comparing the observables of a Measurement Process. The eigvals of measurements are only requested if both observables areNone, saving computational effort. (#3820)Only converts input to
qml.Hermitianto a numpy array if the input is a list. (#3820)
Contributors ✍
This release contains contributions from (in alphabetical order):
Gian-Luca Anselmetti, Guillermo Alonso-Linaje, Juan Miguel Arrazola, Ikko Ashimine, Utkarsh Azad, Miriam Beddig, Cristian Boghiu, Thomas Bromley, Astral Cai, Isaac De Vlugt, Olivia Di Matteo, Lillian M. A. Frederiksen, Soran Jahangiri, Korbinian Kottmann, Christina Lee, Albert Mitjans Coma, Romain Moyard, Mudit Pandey, Borja Requena, Matthew Silverman, Jay Soni, Antal Száva, Frederik Wilde, David Wierichs, Moritz Willmann.
Release 0.28.0¶
New features since last release
Custom measurement processes 📐
Custom measurements can now be facilitated with the addition of the
qml.measurementsmodule. (#3286) (#3343) (#3288) (#3312) (#3287) (#3292) (#3287) (#3326) (#3327) (#3388) (#3439) (#3466)Within
qml.measurementsare new subclasses that allow for the possibility to create custom measurements:SampleMeasurement: represents a sample-based measurementStateMeasurement: represents a state-based measurementMeasurementTransform: represents a measurement process that requires the application of a batch transform
Creating a custom measurement involves making a class that inherits from one of the classes above. An example is given below. Here, the measurement computes the number of samples obtained of a given state:
from pennylane.measurements import SampleMeasurement class CountState(SampleMeasurement): def __init__(self, state: str): self.state = state # string identifying the state, e.g. "0101" wires = list(range(len(state))) super().__init__(wires=wires) def process_samples(self, samples, wire_order, shot_range, bin_size): counts_mp = qml.counts(wires=self._wires) counts = counts_mp.process_samples(samples, wire_order, shot_range, bin_size) return counts.get(self.state, 0) def __copy__(self): return CountState(state=self.state)
We can now execute the new measurement in a QNode as follows.
dev = qml.device("default.qubit", wires=1, shots=10000) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return CountState(state="1")
>>> circuit(1.23) tensor(3303., requires_grad=True)
Differentiability is also supported for this new measurement process:
>>> x = qml.numpy.array(1.23, requires_grad=True) >>> qml.grad(circuit)(x) 4715.000000000001
For more information about these new features, see the documentation for ``qml.measurements` <https://docs.pennylane.ai/en/stable/code/qml_measurements.html>`_.
ZX Calculus 🧮
QNodes can now be converted into ZX diagrams via the PyZX framework. (#3446)
ZX diagrams are the medium for which we can envision a quantum circuit as a graph in the ZX-calculus language, showing properties of quantum protocols in a visually compact and logically complete fashion.
QNodes decorated with
@qml.transforms.to_zxwill return a PyZX graph that represents the computation in the ZX-calculus language.dev = qml.device("default.qubit", wires=2) @qml.transforms.to_zx @qml.qnode(device=dev) def circuit(p): qml.RZ(p[0], wires=1), qml.RZ(p[1], wires=1), qml.RX(p[2], wires=0), qml.PauliZ(wires=0), qml.RZ(p[3], wires=1), qml.PauliX(wires=1), qml.CNOT(wires=[0, 1]), qml.CNOT(wires=[1, 0]), qml.SWAP(wires=[0, 1]), return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> params = [5 / 4 * np.pi, 3 / 4 * np.pi, 0.1, 0.3] >>> circuit(params) Graph(20 vertices, 23 edges)
Information about PyZX graphs can be found in the PyZX Graphs API.
QChem databases and basis sets ⚛️
The symbols and geometry of a compound from the PubChem database can now be accessed via
qchem.mol_data(). (#3289) (#3378)>>> import pennylane as qml >>> from pennylane.qchem import mol_data >>> mol_data("BeH2") (['Be', 'H', 'H'], tensor([[ 4.79404621, 0.29290755, 0. ], [ 3.77945225, -0.29290755, 0. ], [ 5.80882913, -0.29290755, 0. ]], requires_grad=True)) >>> mol_data(223, "CID") (['N', 'H', 'H', 'H', 'H'], tensor([[ 0. , 0. , 0. ], [ 1.82264085, 0.52836742, 0.40402345], [ 0.01417295, -1.67429735, -0.98038991], [-0.98927163, -0.22714508, 1.65369933], [-0.84773114, 1.373075 , -1.07733286]], requires_grad=True))
Perform quantum chemistry calculations with two new basis sets:
6-311gandCC-PVDZ. (#3279)>>> symbols = ["H", "He"] >>> geometry = np.array([[1.0, 0.0, 0.0], [0.0, 0.0, 0.0]], requires_grad=False) >>> charge = 1 >>> basis_names = ["6-311G", "CC-PVDZ"] >>> for basis_name in basis_names: ... mol = qml.qchem.Molecule(symbols, geometry, charge=charge, basis_name=basis_name) ... print(qml.qchem.hf_energy(mol)()) [-2.84429531] [-2.84061284]
A bunch of new operators 👀
The controlled CZ gate and controlled Hadamard gate are now available via
qml.CCZandqml.CH, respectively. (#3408)>>> ccz = qml.CCZ(wires=[0, 1, 2]) >>> qml.matrix(ccz) [[ 1 0 0 0 0 0 0 0] [ 0 1 0 0 0 0 0 0] [ 0 0 1 0 0 0 0 0] [ 0 0 0 1 0 0 0 0] [ 0 0 0 0 1 0 0 0] [ 0 0 0 0 0 1 0 0] [ 0 0 0 0 0 0 1 0] [ 0 0 0 0 0 0 0 -1]] >>> ch = qml.CH(wires=[0, 1]) >>> qml.matrix(ch) [[ 1. 0. 0. 0. ] [ 0. 1. 0. 0. ] [ 0. 0. 0.70710678 0.70710678] [ 0. 0. 0.70710678 -0.70710678]]
Three new parametric operators,
qml.CPhaseShift00,qml.CPhaseShift01, andqml.CPhaseShift10, are now available. Each of these operators performs a phase shift akin toqml.ControlledPhaseShiftbut on different positions of the state vector. (#2715)>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) >>> def circuit(): ... qml.PauliX(wires=1) ... qml.CPhaseShift01(phi=1.23, wires=[0,1]) ... return qml.state() ... >>> circuit() tensor([0. +0.j , 0.33423773+0.9424888j, 1. +0.j , 0. +0.j ], requires_grad=True)
A new gate operation called
qml.FermionicSWAPhas been added. This implements the exchange of spin orbitals representing fermionic-modes while maintaining proper anti-symmetrization. (#3380)dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(phi): qml.BasisState(np.array([0, 1]), wires=[0, 1]) qml.FermionicSWAP(phi, wires=[0, 1]) return qml.state()
>>> circuit(0.1) tensor([0. +0.j , 0.99750208+0.04991671j, 0.00249792-0.04991671j, 0. +0.j ], requires_grad=True)
Create operators defined from a generator via
qml.ops.op_math.Evolution. (#3375)qml.ops.op_math.Evolutiondefines the exponential of an operator $hat{O}$ of the form $e^{ixhat{O}}$, with a single trainable parameter, $x$. Limiting to a single trainable parameter allows the use ofqml.gradients.param_shiftto find the gradient with respect to the parameter $x$.dev = qml.device('default.qubit', wires=2) @qml.qnode(dev, diff_method=qml.gradients.param_shift) def circuit(phi): qml.ops.op_math.Evolution(qml.PauliX(0), -.5 * phi) return qml.expval(qml.PauliZ(0))
>>> phi = np.array(1.2) >>> circuit(phi) tensor(0.36235775, requires_grad=True) >>> qml.grad(circuit)(phi) -0.9320390495504149
The qutrit Hadamard gate,
qml.THadamard, is now available. (#3340)The operation accepts a
subspacekeyword argument which determines which variant of the qutrit Hadamard to use.>>> th = qml.THadamard(wires=0, subspace=[0, 1]) >>> qml.matrix(th) array([[ 0.70710678+0.j, 0.70710678+0.j, 0. +0.j], [ 0.70710678+0.j, -0.70710678+0.j, 0. +0.j], [ 0. +0.j, 0. +0.j, 1. +0.j]])
New transforms, functions, and more 😯
Calculating the purity of arbitrary quantum states is now supported. (#3290)
The purity can be calculated in an analogous fashion to, say, the Von Neumann entropy:
qml.math.puritycan be used as an in-line function:>>> x = [1, 0, 0, 1] / np.sqrt(2) >>> qml.math.purity(x, [0, 1]) 1.0 >>> qml.math.purity(x, [0]) 0.5 >>> x = [[1 / 2, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 1 / 2]] >>> qml.math.purity(x, [0, 1]) 0.5
qml.qinfo.transforms.puritycan transform a QNode returning a state to a function that returns the purity:dev = qml.device("default.mixed", wires=2) @qml.qnode(dev) def circuit(x): qml.IsingXX(x, wires=[0, 1]) return qml.state()
>>> qml.qinfo.transforms.purity(circuit, wires=[0])(np.pi / 2) 0.5 >>> qml.qinfo.transforms.purity(circuit, wires=[0, 1])(np.pi / 2) 1.0
As with the other methods in
qml.qinfo, the purity is fully differentiable:>>> param = np.array(np.pi / 4, requires_grad=True) >>> qml.grad(qml.qinfo.transforms.purity(circuit, wires=[0]))(param) -0.5
A new gradient transform,
qml.gradients.spsa_grad, that is based on the idea of SPSA is now available. (#3366)This new transform allows users to compute a single estimate of a quantum gradient using simultaneous perturbation of parameters and a stochastic approximation. A QNode that takes, say, an argument
x, the approximate gradient can be computed as follows.>>> dev = qml.device("default.qubit", wires=2) >>> x = np.array(0.4, requires_grad=True) >>> @qml.qnode(dev) ... def circuit(x): ... qml.RX(x, 0) ... qml.RX(x, 1) ... return qml.expval(qml.PauliZ(0)) >>> grad_fn = qml.gradients.spsa_grad(circuit, h=0.1, num_directions=1) >>> grad_fn(x) array(-0.38876964)
The argument
num_directionsdetermines how many directions of simultaneous perturbation are used, which is proportional to the number of circuit evaluations. See the SPSA gradient transform documentation for details. Note that the full SPSA optimizer is already available asqml.SPSAOptimizer.Multiple mid-circuit measurements can now be combined arithmetically to create new conditionals. (#3159)
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.Hadamard(wires=1) m0 = qml.measure(wires=0) m1 = qml.measure(wires=1) combined = 2 * m1 + m0 qml.cond(combined == 2, qml.RX)(1.3, wires=2) return qml.probs(wires=2)
>>> circuit() [0.90843735 0.09156265]
A new method called
pauli_decompose()has been added to theqml.paulimodule, which takes a hermitian matrix, decomposes it in the Pauli basis, and returns it either as aqml.Hamiltonianorqml.PauliSentenceinstance. (#3384)OperationorHamiltonianinstances can now be generated from aqml.PauliSentenceorqml.PauliWordvia the newoperation()andhamiltonian()methods. (#3391)A
sum_expandfunction has been added for tapes, which splits a tape measuring aSumexpectation into mutliple tapes of summand expectations, and provides a function to recombine the results. (#3230)
(Experimental) More interface support for multi-measurement and gradient output types 🧪
The autograd and Tensorflow interfaces now support devices with shot vectors when
qml.enable_return()has been called. (#3374) (#3400)Here is an example using Tensorflow:
import tensorflow as tf qml.enable_return() dev = qml.device("default.qubit", wires=2, shots=[1000, 2000, 3000]) @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(a): qml.RY(a, wires=0) qml.RX(0.2, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.probs([0, 1])
>>> a = tf.Variable(0.4) >>> with tf.GradientTape() as tape: ... res = circuit(a) ... res = tf.stack([tf.experimental.numpy.hstack(r) for r in res]) ... >>> res <tf.Tensor: shape=(3, 5), dtype=float64, numpy= array([[0.902, 0.951, 0. , 0. , 0.049], [0.898, 0.949, 0. , 0. , 0.051], [0.892, 0.946, 0. , 0. , 0.054]])> >>> tape.jacobian(res, a) <tf.Tensor: shape=(3, 5), dtype=float64, numpy= array([[-0.345 , -0.1725 , 0. , 0. , 0.1725 ], [-0.383 , -0.1915 , 0. , 0. , 0.1915 ], [-0.38466667, -0.19233333, 0. , 0. , 0.19233333]])>
The PyTorch interface is now fully supported when
qml.enable_return()has been called, allowing the calculation of the Jacobian and the Hessian using custom differentiation methods (e.g., parameter-shift, finite difference, or adjoint). (#3416)import torch qml.enable_return() dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, diff_method="parameter-shift", interface="torch") def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.probs([0, 1])
>>> a = torch.tensor(0.1, requires_grad=True) >>> b = torch.tensor(0.2, requires_grad=True) >>> torch.autograd.functional.jacobian(circuit, (a, b)) ((tensor(-0.0998), tensor(0.)), (tensor([-0.0494, -0.0005, 0.0005, 0.0494]), tensor([-0.0991, 0.0991, 0.0002, -0.0002])))
The JAX-JIT interface now supports first-order gradient computation when
qml.enable_return()has been called. (#3235) (#3445)import jax from jax import numpy as jnp jax.config.update("jax_enable_x64", True) qml.enable_return() dev = qml.device("lightning.qubit", wires=2) @jax.jit @qml.qnode(dev, interface="jax-jit", diff_method="parameter-shift") def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=0) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1)) a, b = jnp.array(1.0), jnp.array(2.0)
>>> jax.jacobian(circuit, argnums=[0, 1])(a, b) ((Array(0.35017549, dtype=float64, weak_type=True), Array(-0.4912955, dtype=float64, weak_type=True)), (Array(5.55111512e-17, dtype=float64, weak_type=True), Array(0., dtype=float64, weak_type=True)))
Improvements 🛠
qml.pauli.is_pauli_wordnow supports instances ofqml.Hamiltonian. (#3389)When
qml.probs,qml.counts, andqml.sampleare called with no arguments, they measure all wires. Calling any of the aforementioned measurements with an empty wire list (e.g.,qml.sample(wires=[])) will raise an error. (#3299)Made
qml.gradients.finite_diffmore convenient to use with custom data type observables/devices by reducing the number of magic methods that need to be defined in the custom data type to supportfinite_diff. (#3426)The
qml.ISWAPgate is now natively supported ondefault.mixed, improving on its efficiency. (#3284)Added more input validation to
qml.transforms.hamiltonian_expandsuch that Hamiltonian objects with no terms raise an error. (#3339)Continuous integration checks are now performed for Python 3.11 and Torch v1.13. Python 3.7 is dropped. (#3276)
qml.Trackernow also logs results intracker.historywhen tracking the execution of a circuit. (#3306)The execution time of
Wires.all_wireshas been improved by avoiding data type changes and making use ofitertools.chain. (#3302)Printing an instance of
qml.qchem.Moleculeis now more concise and informational. (#3364)The error message for
qml.transforms.insertwhen it fails to diagonalize non-qubit-wise-commuting observables is now more detailed. (#3381)Extended the
qml.equalfunction toqml.HamiltonianandTensorobjects. (#3390)QuantumTape._process_queuehas been moved toqml.queuing.process_queueto disentangle its functionality from theQuantumTapeclass. (#3401)QPE can now accept a target operator instead of a matrix and target wires pair. (#3373)
The
qml.ops.op_math.Controlled.map_wiresmethod now usesbase.map_wiresinternally instead of the private_wiresproperty setter. (#3405)A new function called
qml.tape.make_qscripthas been created for converting a quantum function into a quantum script. This replacesqml.transforms.make_tape. (#3429)Add a
_pauli_repattribute to operators to integrate the new Pauli arithmetic classes with native PennyLane objects. (#3443)Extended the functionality of
qml.matrixto qutrits. (#3508)The
qcut.pyfile inpennylane/transforms/has been reorganized into multiple files that are now inpennylane/transforms/qcut/. (#3413)A warning now appears when creating a
Tensorobject with overlapping wires, informing that this can lead to undefined behaviour. (#3459)Extended the
qml.equalfunction toqml.ops.op_math.Controlledandqml.ops.op_math.ControlledOpobjects. (#3463)Nearly every instance of
with QuantumTape()has been replaced withQuantumScriptconstruction. (#3454)Added
validate_subspacestatic method toqml.Operatorto check the validity of the subspace of certain qutrit operations. (#3340)qml.equalnow supports operators created viaqml.s_prod,qml.pow,qml.exp, andqml.adjoint. (#3471)Devices can now disregard observable grouping indices in Hamiltonians through the optional
use_groupingattribute. (#3456)Add the optional argument
lazy=Trueto functionsqml.s_prod,qml.prodandqml.op_sumto allow simplification. (#3483)Updated the
qml.transforms.zyz_decompositionfunction such that it now supports broadcast operators. This means that single-qubitqml.QubitUnitaryoperators, instantiated from a batch of unitaries, can now be decomposed. (#3477)The performance of executing circuits under the
jax.vmaptransformation has been improved by being able to leverage the batch-execution capabilities of some devices. (#3452)The tolerance for converting openfermion Hamiltonian complex coefficients to real ones has been modified to prevent conversion errors. (#3367)
OperationRecordernow inherits fromAnnotatedQueueandQuantumScriptinstead ofQuantumTape. (#3496)Updated
qml.transforms.split_non_commutingto support the new return types. (#3414)Updated
qml.transforms.mitigate_with_zneto support the new return types. (#3415)Updated
qml.transforms.metric_tensor,qml.transforms.adjoint_metric_tensor,qml.qinfo.classical_fisher, andqml.qinfo.quantum_fisherto support the new return types. (#3449)Updated
qml.transforms.batch_paramsandqml.transforms.batch_inputto support the new return types. (#3431)Updated
qml.transforms.cut_circuitandqml.transforms.cut_circuit_mcto support the new return types. (#3346)Limit NumPy version to
<1.24. (#3346)
Breaking changes 💔
Python 3.7 support is no longer maintained. PennyLane will be maintained for versions 3.8 and up. (#3276)
The
log_baseattribute has been moved fromMeasurementProcessto the newVnEntropyMPandMutualInfoMPclasses, which inherit fromMeasurementProcess. (#3326)qml.utils.decompose_hamiltonian()has been removed. Please useqml.pauli.pauli_decompose()instead. (#3384)The
return_typeattribute ofMeasurementProcesshas been removed where possible. Useisinstancechecks instead. (#3399)Instead of having an
OrderedDictattribute called_queue,AnnotatedQueuenow inherits fromOrderedDictand encapsulates the queue. Consequentially, this also applies to theQuantumTapeclass which inherits fromAnnotatedQueue. (#3401)The
ShadowMeasurementProcessclass has been renamed toClassicalShadowMP. (#3388)The
qml.Operation.get_parameter_shiftmethod has been removed. Thegradientsmodule should be used for general parameter-shift rules instead. (#3419)The signature of the
QubitDevice.statisticsmethod has been changed fromdef statistics(self, observables, shot_range=None, bin_size=None, circuit=None):
to
def statistics(self, circuit: QuantumTape, shot_range=None, bin_size=None):
The
MeasurementProcessclass is now an abstract class andreturn_typeis now a property of the class. (#3434)
Deprecations 👋
Deprecations cycles are tracked at doc/developement/deprecations.rst.
The following methods are deprecated: (#3281)
qml.tape.get_active_tape: Useqml.QueuingManager.active_context()insteadqml.transforms.qcut.remap_tape_wires: Useqml.map_wiresinsteadqml.tape.QuantumTape.inv(): Useqml.tape.QuantumTape.adjoint()insteadqml.tape.stop_recording(): Useqml.QueuingManager.stop_recording()insteadqml.tape.QuantumTape.stop_recording(): Useqml.QueuingManager.stop_recording()insteadqml.QueuingContextis nowqml.QueuingManagerQueuingManager.safe_update_infoandAnnotatedQueue.safe_update_info: Useupdate_infoinstead.
qml.transforms.measurement_groupinghas been deprecated. Useqml.transforms.hamiltonian_expandinstead. (#3417)The
observablesargument inQubitDevice.statisticsis deprecated. Please usecircuitinstead. (#3433)The
seed_recipesargument inqml.classical_shadowandqml.shadow_expvalis deprecated. A new argumentseedhas been added, which defaults to None and can contain an integer with the wanted seed. (#3388)qml.transforms.make_tapehas been deprecated. Please useqml.tape.make_qscriptinstead. (#3478)
Documentation 📝
Added documentation on parameter broadcasting regarding both its usage and technical aspects. (#3356)
The quickstart guide on circuits as well as the the documentation of QNodes and Operators now contain introductions and details on parameter broadcasting. The QNode documentation mostly contains usage details, the Operator documentation is concerned with implementation details and a guide to support broadcasting in custom operators.
The return type statements of gradient and Hessian transforms and a series of other functions that are a
batch_transformhave been corrected. (#3476)Developer documentation for the queuing module has been added. (#3268)
More mentions of diagonalizing gates for all relevant operations have been corrected. (#3409)
The docstrings for
compute_eigvalsused to say that the diagonalizing gates implemented $U$, the unitary such that $O = U Sigma U^{dagger}$, where $O$ is the original observable and $Sigma$ a diagonal matrix. However, the diagonalizing gates actually implement $U^{dagger}$, since $langle psi | O | psi rangle = langle psi | U Sigma U^{dagger} | psi rangle$, making $U^{dagger} | psi rangle$ the actual state being measured in the $Z$-basis.A warning about using
dillto pickle and unpickle datasets has been added. (#3505)
Bug fixes 🐛
Fixed a bug that prevented
qml.gradients.param_shiftfrom being used for broadcasted tapes. (#3528)Fixed a bug where
qml.transforms.hamiltonian_expanddidn’t preserve the type of the input results in its output. (#3339)Fixed a bug that made
qml.gradients.param_shiftraise an error when used with unshifted terms only in a custom recipe, and when using any unshifted terms at all under the new return type system. (#3177)The original tape
_obs_sharing_wiresattribute is updated during its expansion. (#3293)An issue with
drain=Falsein the adaptive optimizer has been fixed. Before the fix, the operator pool needed to be reconstructed inside the optimization pool whendrain=False. With this fix, this reconstruction is no longer needed. (#3361)If the device originally has no shots but finite shots are dynamically specified, Hamiltonian expansion now occurs. (#3369)
qml.matrix(op)now fails if the operator truly has no matrix (e.g.,qml.Barrier) to matchop.matrix(). (#3386)The
pad_withargument in theqml.AmplitudeEmbeddingtemplate is now compatible with all interfaces. (#3392)Operator.pownow queues its constituents by default. (#3373)Fixed a bug where a QNode returning
qml.samplewould produce incorrect results when run on a device defined with a shot vector. (#3422)The
qml.datamodule now works as expected on Windows. (#3504)
Contributors ✍️
This release contains contributions from (in alphabetical order):
Guillermo Alonso, Juan Miguel Arrazola, Utkarsh Azad, Samuel Banning, Thomas Bromley, Astral Cai, Albert Mitjans Coma, Ahmed Darwish, Isaac De Vlugt, Olivia Di Matteo, Amintor Dusko, Pieter Eendebak, Lillian M. A. Frederiksen, Diego Guala, Katharine Hyatt, Josh Izaac, Soran Jahangiri, Edward Jiang, Korbinian Kottmann, Christina Lee, Romain Moyard, Lee James O’Riordan, Mudit Pandey, Kevin Shen, Matthew Silverman, Jay Soni, Antal Száva, David Wierichs, Moritz Willmann, and Filippo Vicentini.
Release 0.27.0¶
New features since last release
An all-new data module 💾
The
qml.datamodule is now available, allowing users to download, load, and create quantum datasets. (#3156)Datasets are hosted on Xanadu Cloud and can be downloaded by using
qml.data.load():>>> H2_datasets = qml.data.load( ... data_name="qchem", molname="H2", basis="STO-3G", bondlength=1.1 ... ) >>> H2data = H2_datasets[0] >>> H2data <Dataset = description: qchem/H2/STO-3G/1.1, attributes: ['molecule', 'hamiltonian', ...]>
Datasets available to be downloaded can be listed with
qml.data.list_datasets().To download or load only specific properties of a dataset, we can specify the desired properties in
qml.data.loadwith theattributeskeyword argument:>>> H2_hamiltonian = qml.data.load( ... data_name="qchem", molname="H2", basis="STO-3G", bondlength=1.1, ... attributes=["molecule", "hamiltonian"] ... )[0] >>> H2_hamiltonian.hamiltonian <Hamiltonian: terms=15, wires=[0, 1, 2, 3]>
The available attributes can be found using
qml.data.list_attributes():To select data interactively, we can use
qml.data.load_interactive():>>> qml.data.load_interactive() Please select a data name: 1) qspin 2) qchem Choice [1-2]: 1 Please select a sysname: ... Please select a periodicity: ... Please select a lattice: ... Please select a layout: ... Please select attributes: ... Force download files? (Default is no) [y/N]: N Folder to download to? (Default is pwd, will download to /datasets subdirectory): Please confirm your choices: dataset: qspin/Ising/open/rectangular/4x4 attributes: ['parameters', 'ground_states'] force: False dest folder: datasets Would you like to continue? (Default is yes) [Y/n]: <Dataset = description: qspin/Ising/open/rectangular/4x4, attributes: ['parameters', 'ground_states']>
Once a dataset is loaded, its properties can be accessed as follows:
>>> dev = qml.device("default.qubit",wires=4) >>> @qml.qnode(dev) ... def circuit(): ... qml.BasisState(H2data.hf_state, wires = [0, 1, 2, 3]) ... for op in H2data.vqe_gates: ... qml.apply(op) ... return qml.expval(H2data.hamiltonian) >>> print(circuit()) -1.0791430411076344
It’s also possible to create custom datasets with
qml.data.Dataset:>>> example_hamiltonian = qml.Hamiltonian(coeffs=[1,0.5], observables=[qml.PauliZ(wires=0),qml.PauliX(wires=1)]) >>> example_energies, _ = np.linalg.eigh(qml.matrix(example_hamiltonian)) >>> example_dataset = qml.data.Dataset( ... data_name = 'Example', hamiltonian=example_hamiltonian, energies=example_energies ... ) >>> example_dataset.data_name 'Example' >>> example_dataset.hamiltonian (0.5) [X1] + (1) [Z0] >>> example_dataset.energies array([-1.5, -0.5, 0.5, 1.5])
Custom datasets can be saved and read with the
qml.data.Dataset.write()andqml.data.Dataset.read()methods, respectively.>>> example_dataset.write('./path/to/dataset.dat') >>> read_dataset = qml.data.Dataset() >>> read_dataset.read('./path/to/dataset.dat') >>> read_dataset.data_name 'Example' >>> read_dataset.hamiltonian (0.5) [X1] + (1) [Z0] >>> read_dataset.energies array([-1.5, -0.5, 0.5, 1.5])
We will continue to work on adding more datasets and features for
qml.datain future releases.
Adaptive optimization 🏃🏋️🏊
Optimizing quantum circuits can now be done adaptively with
qml.AdaptiveOptimizer. (#3192)The
qml.AdaptiveOptimizertakes an initial circuit and a collection of operators as input and adds a selected gate to the circuit at each optimization step. The process of growing the circuit can be repeated until the circuit gradients converge to zero within a given threshold. The adaptive optimizer can be used to implement algorithms such as ADAPT-VQE as shown in the following example.Firstly, we define some preliminary variables needed for VQE:
symbols = ["H", "H", "H"] geometry = np.array([[0.01076341, 0.04449877, 0.0], [0.98729513, 1.63059094, 0.0], [1.87262415, -0.00815842, 0.0]], requires_grad=False) H, qubits = qml.qchem.molecular_hamiltonian(symbols, geometry, charge = 1)
The collection of gates to grow the circuit is built to contain all single and double excitations:
n_electrons = 2 singles, doubles = qml.qchem.excitations(n_electrons, qubits) singles_excitations = [qml.SingleExcitation(0.0, x) for x in singles] doubles_excitations = [qml.DoubleExcitation(0.0, x) for x in doubles] operator_pool = doubles_excitations + singles_excitations
Next, an initial circuit that prepares a Hartree-Fock state and returns the expectation value of the Hamiltonian is defined:
hf_state = qml.qchem.hf_state(n_electrons, qubits) dev = qml.device("default.qubit", wires=qubits) @qml.qnode(dev) def circuit(): qml.BasisState(hf_state, wires=range(qubits)) return qml.expval(H)
Finally, the optimizer is instantiated and then the circuit is created and optimized adaptively:
opt = qml.optimize.AdaptiveOptimizer() for i in range(len(operator_pool)): circuit, energy, gradient = opt.step_and_cost(circuit, operator_pool, drain_pool=True) print('Energy:', energy) print(qml.draw(circuit)()) print('Largest Gradient:', gradient) print() if gradient < 1e-3: break
Energy: -1.246549938420637 0: ─╭BasisState(M0)─╭G²(0.20)─┤ ╭<𝓗> 1: ─├BasisState(M0)─├G²(0.20)─┤ ├<𝓗> 2: ─├BasisState(M0)─│─────────┤ ├<𝓗> 3: ─├BasisState(M0)─│─────────┤ ├<𝓗> 4: ─├BasisState(M0)─├G²(0.20)─┤ ├<𝓗> 5: ─╰BasisState(M0)─╰G²(0.20)─┤ ╰<𝓗> Largest Gradient: 0.14399872776755085 Energy: -1.2613740231529604 0: ─╭BasisState(M0)─╭G²(0.20)─╭G²(0.19)─┤ ╭<𝓗> 1: ─├BasisState(M0)─├G²(0.20)─├G²(0.19)─┤ ├<𝓗> 2: ─├BasisState(M0)─│─────────├G²(0.19)─┤ ├<𝓗> 3: ─├BasisState(M0)─│─────────╰G²(0.19)─┤ ├<𝓗> 4: ─├BasisState(M0)─├G²(0.20)───────────┤ ├<𝓗> 5: ─╰BasisState(M0)─╰G²(0.20)───────────┤ ╰<𝓗> Largest Gradient: 0.1349349562423238 Energy: -1.2743971719780331 0: ─╭BasisState(M0)─╭G²(0.20)─╭G²(0.19)──────────┤ ╭<𝓗> 1: ─├BasisState(M0)─├G²(0.20)─├G²(0.19)─╭G(0.00)─┤ ├<𝓗> 2: ─├BasisState(M0)─│─────────├G²(0.19)─│────────┤ ├<𝓗> 3: ─├BasisState(M0)─│─────────╰G²(0.19)─╰G(0.00)─┤ ├<𝓗> 4: ─├BasisState(M0)─├G²(0.20)────────────────────┤ ├<𝓗> 5: ─╰BasisState(M0)─╰G²(0.20)────────────────────┤ ╰<𝓗> Largest Gradient: 0.00040841755397108586
For a detailed breakdown of its implementation, check out the Adaptive circuits for quantum chemistry demo.
Automatic interface detection 🧩
QNodes now accept an
autointerface argument which automatically detects the machine learning library to use. (#3132)from pennylane import numpy as np import torch import tensorflow as tf from jax import numpy as jnp dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, interface="auto") def circuit(weight): qml.RX(weight[0], wires=0) qml.RY(weight[1], wires=1) return qml.expval(qml.PauliZ(0)) interface_tensors = [[0, 1], np.array([0, 1]), torch.Tensor([0, 1]), tf.Variable([0, 1], dtype=float), jnp.array([0, 1])] for tensor in interface_tensors: res = circuit(weight=tensor) print(f"Result value: {res:.2f}; Result type: {type(res)}")
Result value: 1.00; Result type: <class 'pennylane.numpy.tensor.tensor'> Result value: 1.00; Result type: <class 'pennylane.numpy.tensor.tensor'> Result value: 1.00; Result type: <class 'torch.Tensor'> Result value: 1.00; Result type: <class 'tensorflow.python.framework.ops.EagerTensor'> Result value: 1.00; Result type: <class 'jaxlib.xla_extension.Array'>
Upgraded JAX-JIT gradient support 🏎
JAX-JIT support for computing the gradient of QNodes that return a single vector of probabilities or multiple expectation values is now available. (#3244) (#3261)
import jax from jax import numpy as jnp from jax.config import config config.update("jax_enable_x64", True) dev = qml.device("lightning.qubit", wires=2) @jax.jit @qml.qnode(dev, diff_method="parameter-shift", interface="jax") def circuit(x, y): qml.RY(x, wires=0) qml.RY(y, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1)) x = jnp.array(1.0) y = jnp.array(2.0)
>>> jax.jacobian(circuit, argnums=[0, 1])(x, y) (Array([-0.84147098, 0.35017549], dtype=float64, weak_type=True), Array([ 4.47445479e-18, -4.91295496e-01], dtype=float64, weak_type=True))
Note that this change depends on
jax.pure_callback, which requiresjax>=0.3.17.
Construct Pauli words and sentences 🔤
We’ve reorganized and grouped everything in PennyLane responsible for manipulating Pauli operators into a
paulimodule. Thegroupingmodule has been deprecated as a result, and logic was moved frompennylane/groupingtopennylane/pauli/grouping. (#3179)qml.pauli.PauliWordandqml.pauli.PauliSentencecan be used to represent tensor products and linear combinations of Pauli operators, respectively. These provide a more performant method to compute sums and products of Pauli operators. (#3195)qml.pauli.PauliWordrepresents tensor products of Pauli operators. We can efficiently multiply and extract the matrix of these operators using this representation.>>> pw1 = qml.pauli.PauliWord({0:"X", 1:"Z"}) >>> pw2 = qml.pauli.PauliWord({0:"Y", 1:"Z"}) >>> pw1, pw2 (X(0) @ Z(1), Y(0) @ Z(1)) >>> pw1 * pw2 (Z(0), 1j) >>> pw1.to_mat(wire_order=[0,1]) array([[ 0, 0, 1, 0], [ 0, 0, 0, -1], [ 1, 0, 0, 0], [ 0, -1, 0, 0]])
qml.pauli.PauliSentencerepresents linear combinations of Pauli words. We can efficiently add, multiply and extract the matrix of these operators in this representation.>>> ps1 = qml.pauli.PauliSentence({pw1: 1.2, pw2: 0.5j}) >>> ps2 = qml.pauli.PauliSentence({pw1: -1.2}) >>> ps1 1.2 * X(0) @ Z(1) + 0.5j * Y(0) @ Z(1) >>> ps1 + ps2 0.0 * X(0) @ Z(1) + 0.5j * Y(0) @ Z(1) >>> ps1 * ps2 -1.44 * I + (-0.6+0j) * Z(0) >>> (ps1 + ps2).to_mat(wire_order=[0,1]) array([[ 0. +0.j, 0. +0.j, 0.5+0.j, 0. +0.j], [ 0. +0.j, 0. +0.j, 0. +0.j, -0.5+0.j], [-0.5+0.j, 0. +0.j, 0. +0.j, 0. +0.j], [ 0. +0.j, 0.5+0.j, 0. +0.j, 0. +0.j]])
(Experimental) More support for multi-measurement and gradient output types 🧪
qml.enable_return()now supports QNodes returning multiple measurements, including shots vectors, and gradient output types. (#2886) (#3052) (#3041) (#3090) (#3069) (#3137) (#3127) (#3099) (#3098) (#3095) (#3091) (#3176) (#3170) (#3194) (#3267) (#3234) (#3232) (#3223) (#3222) (#3315)In v0.25, we introduced
qml.enable_return(), which separates measurements into their own tensors. The motivation of this change is the deprecation of raggedndarraycreation in NumPy.With this release, we’re continuing to elevate this feature by adding support for:
Execution (
qml.execute)Jacobian vector product (JVP) computation
Gradient transforms (
qml.gradients.param_shift,qml.gradients.finite_diff,qml.gradients.hessian_transform,qml.gradients.param_shift_hessian).Interfaces (Autograd, TensorFlow, and JAX, although without JIT)
With this added support, the JAX interface can handle multiple shots (shots vectors), measurements, and gradient output types with
qml.enable_return():import jax qml.enable_return() dev = qml.device("default.qubit", wires=2, shots=(1, 10000)) params = jax.numpy.array([0.1, 0.2]) @qml.qnode(dev, interface="jax", diff_method="parameter-shift", max_diff=2) def circuit(x): qml.RX(x[0], wires=[0]) qml.RY(x[1], wires=[1]) qml.CNOT(wires=[0, 1]) return qml.var(qml.PauliZ(0) @ qml.PauliX(1)), qml.probs(wires=[0])
>>> jax.hessian(circuit)(params) ((Array([[ 0., 0.], [ 2., -3.]], dtype=float32), Array([[[-0.5, 0. ], [ 0. , 0. ]], [[ 0.5, 0. ], [ 0. , 0. ]]], dtype=float32)), (Array([[ 0.07677898, 0.0563341 ], [ 0.07238522, -1.830669 ]], dtype=float32), Array([[[-4.9707499e-01, 2.9999996e-04], [-6.2500127e-04, 1.2500001e-04]], [[ 4.9707499e-01, -2.9999996e-04], [ 6.2500127e-04, -1.2500001e-04]]], dtype=float32)))
For more details, please refer to the documentation.
New basis rotation and tapering features in qml.qchem 🤓
Grouped coefficients, observables, and basis rotation transformation matrices needed to construct a qubit Hamiltonian in the rotated basis of molecular orbitals are now calculable via
qml.qchem.basis_rotation(). (#3011)>>> symbols = ['H', 'H'] >>> geometry = np.array([[0.0, 0.0, 0.0], [1.398397361, 0.0, 0.0]], requires_grad = False) >>> mol = qml.qchem.Molecule(symbols, geometry) >>> core, one, two = qml.qchem.electron_integrals(mol)() >>> coeffs, ops, unitaries = qml.qchem.basis_rotation(one, two, tol_factor=1.0e-5) >>> unitaries [tensor([[-1.00000000e+00, -5.46483514e-13], [ 5.46483514e-13, -1.00000000e+00]], requires_grad=True), tensor([[-1.00000000e+00, 3.17585063e-14], [-3.17585063e-14, -1.00000000e+00]], requires_grad=True), tensor([[-0.70710678, -0.70710678], [-0.70710678, 0.70710678]], requires_grad=True), tensor([[ 2.58789009e-11, 1.00000000e+00], [-1.00000000e+00, 2.58789009e-11]], requires_grad=True)]
Any gate operation can now be tapered according to \(\mathbb{Z}_2\) symmetries of the Hamiltonian via
qml.qchem.taper_operation. (#3002) (#3121)>>> symbols = ['He', 'H'] >>> geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.4589]]) >>> mol = qml.qchem.Molecule(symbols, geometry, charge=1) >>> H, n_qubits = qml.qchem.molecular_hamiltonian(symbols, geometry) >>> generators = qml.qchem.symmetry_generators(H) >>> paulixops = qml.qchem.paulix_ops(generators, n_qubits) >>> paulix_sector = qml.qchem.optimal_sector(H, generators, mol.n_electrons) >>> tap_op = qml.qchem.taper_operation(qml.SingleExcitation, generators, paulixops, ... paulix_sector, wire_order=H.wires, op_wires=[0, 2]) >>> tap_op(3.14159) [Exp(1.5707949999999993j PauliY)]
Moreover, the obtained tapered operation can be used directly within a QNode.
>>> dev = qml.device('default.qubit', wires=[0, 1]) >>> @qml.qnode(dev) ... def circuit(params): ... tap_op(params[0]) ... return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) >>> drawer = qml.draw(circuit, show_all_wires=True) >>> print(drawer(params=[3.14159])) 0: ──Exp(0.00+1.57j Y)─┤ ╭<Z@Z> 1: ────────────────────┤ ╰<Z@Z>
Functionality has been added to estimate the number of measurements required to compute an expectation value with a target error and estimate the error in computing an expectation value with a given number of measurements. (#3000)
New functions, operations, and observables 🤩
Wires of operators or entire QNodes can now be mapped to other wires via
qml.map_wires(). (#3143) (#3145)The
qml.map_wires()function requires a dictionary representing a wire map. Use it witharbitrary operators:
>>> op = qml.RX(0.54, wires=0) + qml.PauliX(1) + (qml.PauliZ(2) @ qml.RY(1.23, wires=3)) >>> op (RX(0.54, wires=[0]) + PauliX(wires=[1])) + (PauliZ(wires=[2]) @ RY(1.23, wires=[3])) >>> wire_map = {0: 10, 1: 11, 2: 12, 3: 13} >>> qml.map_wires(op, wire_map) (RX(0.54, wires=[10]) + PauliX(wires=[11])) + (PauliZ(wires=[12]) @ RY(1.23, wires=[13]))
A
map_wiresmethod has also been added to operators, which returns a copy of the operator with its wires changed according to the given wire map.entire QNodes:
dev = qml.device("default.qubit", wires=["A", "B", "C", "D"]) wire_map = {0: "A", 1: "B", 2: "C", 3: "D"} @qml.qnode(dev) def circuit(): qml.RX(0.54, wires=0) qml.PauliX(1) qml.PauliZ(2) qml.RY(1.23, wires=3) return qml.probs(wires=0)
>>> mapped_circuit = qml.map_wires(circuit, wire_map) >>> mapped_circuit() tensor([0.92885434, 0.07114566], requires_grad=True) >>> print(qml.draw(mapped_circuit)()) A: ──RX(0.54)─┤ Probs B: ──X────────┤ C: ──Z────────┤ D: ──RY(1.23)─┤
The
qml.IntegerComparatorarithmetic operation is now available. (#3113)Given a basis state \(\vert n \rangle\), where \(n\) is a positive integer, and a fixed positive integer \(L\),
qml.IntegerComparatorflips a target qubit if \(n \geq L\). Alternatively, the flipping condition can be \(n < L\) as demonstrated below:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): qml.BasisState(np.array([0, 1]), wires=range(2)) qml.broadcast(qml.Hadamard, wires=range(2), pattern='single') qml.IntegerComparator(2, geq=False, wires=[0, 1]) return qml.state()
>>> circuit() [-0.5+0.j 0.5+0.j -0.5+0.j 0.5+0.j]
The
qml.GellMannqutrit observable, the ternary generalization of the Pauli observables, is now available. (#3035)When using
qml.GellMann, theindexkeyword argument determines which of the 8 Gell-Mann matrices is used.dev = qml.device("default.qutrit", wires=2) @qml.qnode(dev) def circuit(): qml.TClock(wires=0) qml.TShift(wires=1) qml.TAdd(wires=[0, 1]) return qml.expval(qml.GellMann(wires=0, index=8) + qml.GellMann(wires=1, index=3))
>>> circuit() -0.42264973081037416
Controlled qutrit operations can now be performed with
qml.ControlledQutritUnitary. (#2844)The control wires and values that define the operation are defined analogously to the qubit operation.
dev = qml.device("default.qutrit", wires=3) @qml.qnode(dev) def circuit(U): qml.TShift(wires=0) qml.TAdd(wires=[0, 1]) qml.ControlledQutritUnitary(U, control_wires=[0, 1], control_values='12', wires=2) return qml.state()
>>> U = np.array([[1, 1, 0], [1, -1, 0], [0, 0, np.sqrt(2)]]) / np.sqrt(2) >>> circuit(U) tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], requires_grad=True)
Improvements
PennyLane now supports Python 3.11! (#3297)
qml.sampleandqml.countswork more efficiently and track if computational basis samples are being generated when they are called without specifying an observable. (#3207)The parameters of a basis set containing a different number of Gaussian functions are now easier to differentiate. (#3213)
Printing a
qml.MultiControlledXoperator now shows thecontrol_valueskeyword argument. (#3113)qml.simplifyand transforms likeqml.matrix,batch_transform,hamiltonian_expand, andsplit_non_commutingnow work withQuantumScriptas well asQuantumTape. (#3209)A redundant flipping of the initial state in the UCCSD and kUpCCGSD templates has been removed. (#3148)
qml.adjointnow supports batching if the base operation supports batching. (#3168)qml.OrbitalRotationis now decomposed into twoqml.SingleExcitationoperations for faster execution and more efficient parameter-shift gradient calculations on devices that natively supportqml.SingleExcitation. (#3171)The
Expclass decomposes into aPauliRotclass if the coefficient is imaginary and the base operator is a Pauli Word. (#3249)Added the operator attributes
has_decompositionandhas_adjointthat indicate whether a correspondingdecompositionoradjointmethod is available. (#2986)Structural improvements are made to
QueuingManager, formerlyQueuingContext, andAnnotatedQueue. (#2794) (#3061) (#3085)QueuingContextis renamed toQueuingManager.QueuingManagershould now be the global communication point for putting queuable objects into the active queue.QueuingManageris no longer an abstract base class.AnnotatedQueueand its children no longer inherit fromQueuingManager.QueuingManageris no longer a context manager.Recording queues should start and stop recording via the
QueuingManager.add_active_queueandQueuingContext.remove_active_queueclass methods instead of directly manipulating the_active_contextsproperty.AnnotatedQueueand its children no longer provide global information about actively recording queues. This information is now only available throughQueuingManager.AnnotatedQueueand its children no longer have the private_append,_remove,_update_info,_safe_update_info, and_get_infomethods. The public analogues should be used instead.QueuingManager.safe_update_infoandAnnotatedQueue.safe_update_infoare deprecated. Their functionality is moved toupdate_info.
qml.Identitynow accepts multiple wires.
>>> id_op = qml.Identity([0, 1]) >>> id_op.matrix() array([[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.], [0., 0., 0., 1.]]) >>> id_op.sparse_matrix() <4x4 sparse matrix of type '<class 'numpy.float64'>' with 4 stored elements in Compressed Sparse Row format> >>> id_op.eigvals() array([1., 1., 1., 1.])
Added
unitary_checkkeyword argument to the constructor of theQubitUnitaryclass which indicates whether the user wants to check for unitarity of the input matrix or not. Its default value isfalse. (#3063)Modified the representation of
WireCutby usingqml.draw_mpl. (#3067)Improved the performance of
qml.math.expand_matrixfunction for dense and sparse matrices. (#3060) (#3064)Added support for sums and products of operator classes with scalar tensors of any interface (NumPy, JAX, Tensorflow, PyTorch…). (#3149)
>>> s_prod = torch.tensor(4) * qml.RX(1.23, 0) >>> s_prod 4*(RX(1.23, wires=[0])) >>> s_prod.scalar tensor(4)
Added
overlapping_opsproperty to theCompositeclass to improve the performance of theeigvals,diagonalizing_gatesandProd.matrixmethods. (#3084)Added the
map_wiresmethod to the operators, which returns a copy of the operator with its wires changed according to the given wire map. (#3143)>>> op = qml.Toffoli([0, 1, 2]) >>> wire_map = {0: 2, 2: 0} >>> op.map_wires(wire_map=wire_map) Toffoli(wires=[2, 1, 0])
Calling
compute_matrixandcompute_sparse_matrixof simple non-parametric operations is now faster and more memory-efficient with the addition of caching. (#3134)Added details to the output of
Exp.label(). (#3126)qml.math.unwrapno longer creates ragged arrays. Lists remain lists. (#3163)New
null.qubitdevice. Thenull.qubitperforms no operations or memory allocations. (#2589)default.qubitfavours decomposition and avoids matrix construction forQFTandGroverOperatorat larger qubit numbers. (#3193)qml.ControlledQubitUnitarynow has acontrol_valuesproperty. (#3206)Added a new
qml.tape.QuantumScriptclass that contains all the non-queuing behavior ofQuantumTape. Now,QuantumTapeinherits fromQuantumScriptas well asAnnotatedQueue. (#3097)Extended the
qml.equalfunction to MeasurementProcesses (#3189)qml.drawer.draw.draw_mplnow accepts astylekwarg to select a style for plotting, rather than callingqml.drawer.use_style(style)before plotting. Setting a style fordraw_mpldoes not change the global configuration for matplotlib plotting. If nostyleis passed, the function defaults to plotting with theblack_whitestyle. (#3247)
Breaking changes
QuantumTape._par_infois now a list of dictionaries, instead of a dictionary whose keys are integers starting from zero. (#3185)QueuingContexthas been renamed toQueuingManager. (#3061)Deprecation patches for the return types enum’s location and
qml.utils.expandare removed. (#3092)_multi_dispatchfunctionality has been moved inside theget_interfacefunction. This function can now be called with one or multiple tensors as arguments. (#3136)>>> torch_scalar = torch.tensor(1) >>> torch_tensor = torch.Tensor([2, 3, 4]) >>> numpy_tensor = np.array([5, 6, 7]) >>> qml.math.get_interface(torch_scalar) 'torch' >>> qml.math.get_interface(numpy_tensor) 'numpy'
_multi_dispatchpreviously had only one argument which contained a list of the tensors to be dispatched:>>> qml.math._multi_dispatch([torch_scalar, torch_tensor, numpy_tensor]) 'torch'
To differentiate whether the user wants to get the interface of a single tensor or multiple tensors,
get_interfacenow accepts a different argument per tensor to be dispatched:>>> qml.math.get_interface(*[torch_scalar, torch_tensor, numpy_tensor]) 'torch' >>> qml.math.get_interface(torch_scalar, torch_tensor, numpy_tensor) 'torch'
Operator.compute_termsis removed. On a specific instance of an operator,op.terms()can be used instead. There is no longer a static method for this. (#3215)
Deprecations
QueuingManager.safe_update_infoandAnnotatedQueue.safe_update_infoare deprecated. Instead,update_infono longer raises errors if the object isn’t in the queue. (#3085)qml.tape.stop_recordingandQuantumTape.stop_recordinghave been moved toqml.QueuingManager.stop_recording. The old functions will still be available until v0.29. (#3068)qml.tape.get_active_tapehas been deprecated. Useqml.QueuingManager.active_context()instead. (#3068)Operator.compute_termshas been removed. On a specific instance of an operator, useop.terms()instead. There is no longer a static method for this. (#3215)qml.tape.QuantumTape.inv()has been deprecated. Useqml.tape.QuantumTape.adjointinstead. (#3237)qml.transforms.qcut.remap_tape_wireshas been deprecated. Useqml.map_wiresinstead. (#3186)The grouping module
qml.groupinghas been deprecated. Useqml.pauliorqml.pauli.groupinginstead. The module will still be available until v0.28. (#3262)
Documentation
The code block in the usage details of the UCCSD template has been updated. (#3140)
Added a “Deprecations” page to the developer documentation. (#3093)
The example of the
qml.FlipSigntemplate has been updated. (#3219)
Bug fixes
qml.SparseHamiltoniannow validates the size of the input matrix. (#3278)Users no longer see unintuitive errors when inputing sequences to
qml.Hermitian. (#3181)The evaluation of QNodes that return either
vn_entropyormutual_inforaises an informative error message when using devices that define a vector of shots. (#3180)Fixed a bug that made
qml.AmplitudeEmbeddingincompatible with JITting. (#3166)Fixed the
qml.transforms.transpiletransform to work correctly for all two-qubit operations. (#3104)Fixed a bug with the control values of a controlled version of a
ControlledQubitUnitary. (#3119)Fixed a bug where
qml.math.fidelity(non_trainable_state, trainable_state)failed unexpectedly. (#3160)Fixed a bug where
qml.QueuingManager.stop_recordingdid not clean up if yielded code raises an exception. (#3182)Returning
qml.sample()orqml.counts()with other measurements of non-commuting observables now raises a QuantumFunctionError (e.g.,return qml.expval(PauliX(wires=0)), qml.sample()now raises an error). (#2924)Fixed a bug where
op.eigvals()would return an incorrect result if the operator was a non-hermitian composite operator. (#3204)Fixed a bug where
qml.BasisStatePreparationandqml.BasisEmbeddingwere not jit-compilable with JAX. (#3239)Fixed a bug where
qml.MottonenStatePreparationwas not jit-compilable with JAX. (#3260)Fixed a bug where
qml.expval(qml.Hamiltonian())would not raise an error if the Hamiltonian involved some wires that are not present on the device. (#3266)Fixed a bug where
qml.tape.QuantumTape.shape()did not account for the batch dimension of the tape (#3269)
Contributors
This release contains contributions from (in alphabetical order):
Kamal Mohamed Ali, Guillermo Alonso-Linaje, Juan Miguel Arrazola, Utkarsh Azad, Thomas Bromley, Albert Mitjans Coma, Isaac De Vlugt, Olivia Di Matteo, Amintor Dusko, Lillian M. A. Frederiksen, Diego Guala, Josh Izaac, Soran Jahangiri, Edward Jiang, Korbinian Kottmann, Christina Lee, Romain Moyard, Lee J. O’Riordan, Mudit Pandey, Matthew Silverman, Jay Soni, Antal Száva, David Wierichs,
Release 0.26.0¶
New features since last release
Classical shadows 👤
PennyLane now provides built-in support for implementing the classical-shadows measurement protocol. (#2820) (#2821) (#2871) (#2968) (#2959) (#2968)
The classical-shadow measurement protocol is described in detail in the paper Predicting Many Properties of a Quantum System from Very Few Measurements. As part of the support for classical shadows in this release, two new finite-shot and fully-differentiable measurements are available:
QNodes returning the new measurement
qml.classical_shadow()will return two entities;bits(0 or 1 if the 1 or -1 eigenvalue is sampled, respectively) andrecipes(the randomized Pauli measurements that are performed for each qubit, labelled by integer):dev = qml.device("default.qubit", wires=2, shots=3) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) return qml.classical_shadow(wires=[0, 1])
>>> bits, recipes = circuit() >>> bits tensor([[0, 0], [1, 0], [0, 1]], dtype=uint8, requires_grad=True) >>> recipes tensor([[2, 2], [0, 2], [0, 2]], dtype=uint8, requires_grad=True)
QNodes returning
qml.shadow_expval()yield the expectation value estimation using classical shadows:dev = qml.device("default.qubit", wires=range(2), shots=10000) @qml.qnode(dev) def circuit(x, H): qml.Hadamard(0) qml.CNOT((0,1)) qml.RX(x, wires=0) return qml.shadow_expval(H) x = np.array(0.5, requires_grad=True) H = qml.Hamiltonian( [1., 1.], [qml.PauliZ(0) @ qml.PauliZ(1), qml.PauliX(0) @ qml.PauliX(1)] )
>>> circuit(x, H) tensor(1.8486, requires_grad=True) >>> qml.grad(circuit)(x, H) -0.4797000000000001
Fully-differentiable QNode transforms for both new classical-shadows measurements are also available via
qml.shadows.shadow_stateandqml.shadows.shadow_expval, respectively.For convenient post-processing, we’ve also added the ability to calculate general Renyi entropies by way of the
ClassicalShadowclass’entropymethod, which requires the wires of the subsystem of interest and the Renyi entropy order:>>> shadow = qml.ClassicalShadow(bits, recipes) >>> vN_entropy = shadow.entropy(wires=[0, 1], alpha=1)
Qutrits: quantum circuits for tertiary degrees of freedom ☘️
An entirely new framework for quantum computing is now simulatable with the addition of qutrit functionalities. (#2699) (#2781) (#2782) (#2783) (#2784) (#2841) (#2843)
Qutrits are like qubits, but instead live in a three-dimensional Hilbert space; they are not binary degrees of freedom, they are tertiary. The advent of qutrits allows for all sorts of interesting theoretical, practical, and algorithmic capabilities that have yet to be discovered.
To facilitate qutrit circuits requires a new device:
default.qutrit. Thedefault.qutritdevice is a Python-based simulator, akin todefault.qubit, and is defined as per usual:>>> dev = qml.device("default.qutrit", wires=1)
The following operations are supported on
default.qutritdevices:The qutrit shift operator,
qml.TShift, and the ternary clock operator,qml.TClock, as defined in this paper by Yeh et al. (2022), which are the qutrit analogs of the Pauli X and Pauli Z operations, respectively.The
qml.TAddandqml.TSWAPoperations which are the qutrit analogs of the CNOT and SWAP operations, respectively.Custom unitary operations via
qml.QutritUnitary.qml.stateandqml.probsmeasurements.Measuring user-specified Hermitian matrix observables via
qml.THermitian.
A comprehensive example of these features is given below:
dev = qml.device("default.qutrit", wires=1) U = np.array([ [1, 1, 1], [1, 1, 1], [1, 1, 1] ] ) / np.sqrt(3) obs = np.array([ [1, 1, 0], [1, -1, 0], [0, 0, np.sqrt(2)] ] ) / np.sqrt(2) @qml.qnode(dev) def qutrit_state(U, obs): qml.TShift(0) qml.TClock(0) qml.QutritUnitary(U, wires=0) return qml.state() @qml.qnode(dev) def qutrit_expval(U, obs): qml.TShift(0) qml.TClock(0) qml.QutritUnitary(U, wires=0) return qml.expval(qml.THermitian(obs, wires=0))
>>> qutrit_state(U, obs) tensor([-0.28867513+0.5j, -0.28867513+0.5j, -0.28867513+0.5j], requires_grad=True) >>> qutrit_expval(U, obs) tensor(0.80473785, requires_grad=True)
We will continue to add more and more support for qutrits in future releases.
Simplifying just got... simpler 😌
The
qml.simplify()function has several intuitive improvements with this release. (#2978) (#2982) (#2922) (#3012)qml.simplifycan now perform the following:simplify parametrized operations
simplify the adjoint and power of specific operators
group like terms in a sum
resolve products of Pauli operators
combine rotation angles of identical rotation gates
Here is an example of
qml.simplifyin action with parameterized rotation gates. In this case, the angles of rotation are simplified to be modulo \(4\pi\).>>> op1 = qml.RX(30.0, wires=0) >>> qml.simplify(op1) RX(4.867258771281655, wires=[0]) >>> op2 = qml.RX(4 * np.pi, wires=0) >>> qml.simplify(op2) Identity(wires=[0])
All of these simplification features can be applied directly to quantum functions, QNodes, and tapes via decorating with
@qml.simplify, as well:dev = qml.device("default.qubit", wires=2) @qml.simplify @qml.qnode(dev) def circuit(): qml.adjoint(qml.prod(qml.RX(1, 0) ** 1, qml.RY(1, 0), qml.RZ(1, 0))) return qml.probs(wires=0)
>>> circuit() >>> list(circuit.tape) [RZ(11.566370614359172, wires=[0]) @ RY(11.566370614359172, wires=[0]) @ RX(11.566370614359172, wires=[0]), probs(wires=[0])]
QNSPSA optimizer 💪
A new optimizer called
qml.QNSPSAOptimizeris available that implements the quantum natural simultaneous perturbation stochastic approximation (QNSPSA) method based on Simultaneous Perturbation Stochastic Approximation of the Quantum Fisher Information. (#2818)qml.QNSPSAOptimizeris a second-order SPSA algorithm, which combines the convergence power of the quantum-aware Quantum Natural Gradient (QNG) optimization method with the reduced quantum evaluations of SPSA methods.While the QNSPSA optimizer requires additional circuit executions (10 executions per step) compared to standard SPSA optimization (3 executions per step), these additional evaluations are used to provide a stochastic estimation of a second-order metric tensor, which often helps the optimizer to achieve faster convergence.
Use
qml.QNSPSAOptimizerlike you would any other optimizer:max_iterations = 50 opt = qml.QNSPSAOptimizer() for _ in range(max_iterations): params, cost = opt.step_and_cost(cost, params)
Check out our demo on the QNSPSA optimizer for more information.
Operator and parameter broadcasting supplements 📈
Operator methods for exponentiation and raising to a power have been added. (#2799) (#3029)
The
qml.expfunction can be used to create observables or generic rotation gates:>>> x = 1.234 >>> t = qml.PauliX(0) @ qml.PauliX(1) + qml.PauliY(0) @ qml.PauliY(1) >>> isingxy = qml.exp(t, 0.25j * x) >>> isingxy.matrix() array([[1. +0.j , 0. +0.j , 1. +0.j , 0. +0.j ], [0. +0.j , 0.8156179+0.j , 1. +0.57859091j, 0. +0.j ], [0. +0.j , 0. +0.57859091j, 0.8156179+0.j , 0. +0.j ], [0. +0.j , 0. +0.j , 1. +0.j , 1. +0.j ]])
The
qml.powfunction raises a given operator to a power:>>> op = qml.pow(qml.PauliX(0), 2) >>> op.matrix() array([[1, 0], [0, 1]])
An operator called
qml.PSWAPis now available. (#2667)The
qml.PSWAPgate – or phase-SWAP gate – was previously available within the PennyLane-Braket plugin only. Enjoy it natively in PennyLane with v0.26.Check whether or not an operator is hermitian or unitary with
qml.is_hermitianandqml.is_unitary. (#2960)>>> op1 = qml.PauliX(wires=0) >>> qml.is_hermitian(op1) True >>> op2 = qml.PauliX(0) + qml.RX(np.pi/3, 0) >>> qml.is_unitary(op2) False
Embedding templates now support parameter broadcasting. (#2810)
Embedding templates like
AmplitudeEmbeddingorIQPEmbeddingnow support parameter broadcasting with a leading broadcasting dimension in their variational parameters.AmplitudeEmbedding, for example, would usually use a one-dimensional input vector of features. With broadcasting, we can now compute>>> features = np.array([ ... [0.5, 0.5, 0., 0., 0.5, 0., 0.5, 0.], ... [1., 0., 0., 0., 0., 0., 0., 0.], ... [0.5, 0.5, 0., 0., 0., 0., 0.5, 0.5], ... ]) >>> op = qml.AmplitudeEmbedding(features, wires=[1, 5, 2]) >>> op.batch_size 3
An exception is
BasisEmbedding, which is not broadcastable.
Improvements
The
qml.math.expand_matrix()method now allows the sparse matrix representation of an operator to be extended to a larger hilbert space. (#2998)>>> from scipy import sparse >>> mat = sparse.csr_matrix([[0, 1], [1, 0]]) >>> qml.math.expand_matrix(mat, wires=[1], wire_order=[0,1]).toarray() array([[0., 1., 0., 0.], [1., 0., 0., 0.], [0., 0., 0., 1.], [0., 0., 1., 0.]])
qml.ctrlnow usesControlledinstead ofControlledOperation. The newControlledclass wraps individualOperator‘s instead of a tape. It provides improved representations and integration. (#2990)qml.matrixcan now compute the matrix of tapes and QNodes that contain multiple broadcasted operations or non-broadcasted operations after broadcasted ones. (#3025)A common scenario in which this becomes relevant is the decomposition of broadcasted operations: the decomposition in general will contain one or multiple broadcasted operations as well as operations with no or fixed parameters that are not broadcasted.
Lists of operators are now internally sorted by their respective wires while also taking into account their commutativity property. (#2995)
Some methods of the
QuantumTapeclass have been simplified and reordered to improve both readability and performance. (#2963)The
qml.qchem.molecular_hamiltonianfunction is modified to support observable grouping. (#2997)qml.ops.op_math.Controllednow has basic decomposition functionality. (#2938)Automatic circuit cutting has been improved by making better partition imbalance derivations. Now it is more likely to generate optimal cuts for larger circuits. (#2517)
By default,
qml.countsonly returns the outcomes observed in sampling. Optionally, specifyingqml.counts(all_outcomes=True)will return a dictionary containing all possible outcomes. (#2889)>>> dev = qml.device("default.qubit", wires=2, shots=1000) >>> >>> @qml.qnode(dev) >>> def circuit(): ... qml.Hadamard(wires=0) ... qml.CNOT(wires=[0, 1]) ... return qml.counts(all_outcomes=True) >>> result = circuit() >>> result {'00': 495, '01': 0, '10': 0, '11': 505}
Internal use of in-place inversion is eliminated in preparation for its deprecation. (#2965)
Controlledoperators now work withqml.is_commuting. (#2994)qml.prodandqml.op_sumnow support thesparse_matrix()method. (#3006)>>> xy = qml.prod(qml.PauliX(1), qml.PauliY(1)) >>> op = qml.op_sum(xy, qml.Identity(0)) >>> >>> sparse_mat = op.sparse_matrix(wire_order=[0,1]) >>> type(sparse_mat) <class 'scipy.sparse.csr.csr_matrix'> >>> sparse_mat.toarray() [[1.+1.j 0.+0.j 0.+0.j 0.+0.j] [0.+0.j 1.-1.j 0.+0.j 0.+0.j] [0.+0.j 0.+0.j 1.+1.j 0.+0.j] [0.+0.j 0.+0.j 0.+0.j 1.-1.j]]
Provided
sparse_matrix()support for single qubit observables. (#2964)qml.Barrierwithonly_visual=Truenow simplifies viaop.simplify()to the identity operator or a product of identity operators. (#3016)More accurate and intuitive outputs for printing some operators have been added. (#3013)
Results for the matrix of the sum or product of operators are stored in a more efficient manner. (#3022)
The computation of the (sparse) matrix for the sum or product of operators is now more efficient. (#3030)
When the factors of
qml.proddon’t share any wires, the matrix and sparse matrix are computed using a kronecker product for improved efficiency. (#3040)qml.grouping.is_pauli_wordnow returnsFalsefor operators that don’t inherit fromqml.Observableinstead of raising an error. (#3039)Added functionality to iterate over operators created from
qml.op_sumandqml.prod. (#3028)>>> op = qml.op_sum(qml.PauliX(0), qml.PauliY(1), qml.PauliZ(2)) >>> len(op) 3 >>> op[1] PauliY(wires=[1]) >>> [o.name for o in op] ['PauliX', 'PauliY', 'PauliZ']
Deprecations
In-place inversion is now deprecated. This includes
op.inv()andop.inverse=value. Please useqml.adjointorqml.powinstead. Support for these methods will remain till v0.28. (#2988)Don’t use:
>>> v1 = qml.PauliX(0).inv() >>> v2 = qml.PauliX(0) >>> v2.inverse = True
Instead use:
>>> qml.adjoint(qml.PauliX(0)) Adjoint(PauliX(wires=[0])) >>> qml.pow(qml.PauliX(0), -1) PauliX(wires=[0])**-1 >>> qml.pow(qml.PauliX(0), -1, lazy=False) PauliX(wires=[0]) >>> qml.PauliX(0) ** -1 PauliX(wires=[0])**-1
qml.adjointtakes the conjugate transpose of an operator, whileqml.pow(op, -1)indicates matrix inversion. For unitary operators,adjointwill be more efficient thanqml.pow(op, -1), even though they represent the same thing.The
supports_reversible_diffdevice capability is unused and has been removed. (#2993)
Breaking changes
Measuring an operator that might not be hermitian now raises a warning instead of an error. To definitively determine whether or not an operator is hermitian, use
qml.is_hermitian. (#2960)The
ControlledOperationclass has been removed. This was a developer-only class, so the change should not be evident to any users. It is replaced byControlled. (#2990)The default
executemethod for theQubitDevicebase class now callsself.statisticswith an additional keyword argumentcircuit, which represents the quantum tape being executed. Any device that overridesstatisticsshould edit the signature of the method to include the newcircuitkeyword argument. (#2820)The
expand_matrix()has been moved frompennylane.operationtopennylane.math.matrix_manipulation(#3008)qml.grouping.utils.is_commutinghas been removed, and its Pauli word logic is now part ofqml.is_commuting. (#3033)qml.is_commutinghas been moved frompennylane.transforms.commutation_dagtopennylane.ops.functions. (#2991)
Documentation
Updated the Fourier transform docs to use
circuit_spectruminstead ofspectrum, which has been deprecated. (#3018)Corrected the docstrings for diagonalizing gates for all relevant operations. The docstrings used to say that the diagonalizing gates implemented \(U\), the unitary such that \(O = U \Sigma U^{\dagger}\), where \(O\) is the original observable and \(\Sigma\) a diagonal matrix. However, the diagonalizing gates actually implement \(U^{\dagger}\), since \(\langle \psi | O | \psi \rangle = \langle \psi | U \Sigma U^{\dagger} | \psi \rangle\), making \(U^{\dagger} | \psi \rangle\) the actual state being measured in the Z-basis. (#2981)
Bug fixes
Fixed a bug with
qml.ops.Expoperators when the coefficient is autograd but the diagonalizing gates don’t act on all wires. (#3057)Fixed a bug where the tape transform
single_qubit_fusioncomputed wrong rotation angles for specific combinations of rotations. (#3024)Jax gradients now work with a QNode when the quantum function was transformed by
qml.simplify. (#3017)Operators that have
num_wires = AnyWiresornum_wires = AnyWiresnow raise an error, with certain exceptions, when instantiated withwires=[]. (#2979)Fixed a bug where printing
qml.Hamiltonianwith complex coefficients raisesTypeErrorin some cases. (#3004)Added a more descriptive error message when measuring non-commuting observables at the end of a circuit with
probs,samples,countsandallcounts. (#3065)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Utkarsh Azad, Tom Bromley, Olivia Di Matteo, Isaac De Vlugt, Yiheng Duan, Lillian Marie Austin Frederiksen, Josh Izaac, Soran Jahangiri, Edward Jiang, Ankit Khandelwal, Korbinian Kottmann, Meenu Kumari, Christina Lee, Albert Mitjans Coma, Romain Moyard, Rashid N H M, Zeyue Niu, Mudit Pandey, Matthew Silverman, Jay Soni, Antal Száva, Cody Wang, David Wierichs.
Release 0.25.1¶
Bug fixes
Fixed Torch device discrepencies for certain parametrized operations by updating
qml.math.arrayandqml.math.eyeto preserve the Torch device used. (#2967)
Contributors
This release contains contributions from (in alphabetical order):
Romain Moyard, Rashid N H M, Lee James O’Riordan, Antal Száva
Release 0.25.0¶
New features since last release
Estimate computational resource requirements 🧠
Functionality for estimating molecular simulation computations has been added with
qml.resource. (#2646) (#2653) (#2665) (#2694) (#2720) (#2723) (#2746) (#2796) (#2797) (#2874) (#2944) (#2644)The new resource module allows you to estimate the number of non-Clifford gates and logical qubits needed to implement quantum phase estimation algorithms for simulating materials and molecules. This includes support for quantum algorithms using first and second quantization with specific bases:
First quantization using a plane-wave basis via the
FirstQuantizationclass:>>> n = 100000 # number of plane waves >>> eta = 156 # number of electrons >>> omega = 1145.166 # unit cell volume in atomic units >>> algo = FirstQuantization(n, eta, omega) >>> print(algo.gates, algo.qubits) 1.10e+13, 4416
Second quantization with a double-factorized Hamiltonian via the
DoubleFactorizationclass:symbols = ["O", "H", "H"] geometry = np.array( [ [0.00000000, 0.00000000, 0.28377432], [0.00000000, 1.45278171, -1.00662237], [0.00000000, -1.45278171, -1.00662237], ], requires_grad=False, ) mol = qml.qchem.Molecule(symbols, geometry, basis_name="sto-3g") core, one, two = qml.qchem.electron_integrals(mol)() algo = DoubleFactorization(one, two)
>>> print(algo.gates, algo.qubits) 103969925, 290
The methods of the
FirstQuantizationand theDoubleFactorizationclasses, such asqubit_cost(number of logical qubits) andgate_cost(number of non-Clifford gates), can be also accessed as static methods:>>> qml.resource.FirstQuantization.qubit_cost(100000, 156, 169.69608, 0.01) 4377 >>> qml.resource.FirstQuantization.gate_cost(100000, 156, 169.69608, 0.01) 3676557345574
Differentiable error mitigation ⚙️
Differentiable zero-noise-extrapolation (ZNE) error mitigation is now available. (#2757)
Elevate any variational quantum algorithm to a mitigated algorithm with improved results on noisy hardware while maintaining differentiability throughout.
In order to do so, use the
qml.transforms.mitigate_with_znetransform on your QNode and provide the PennyLane proprietaryqml.transforms.fold_globalfolding function andqml.transforms.poly_extrapolateextrapolation function. Here is an example for a noisy simulation device where we mitigate a QNode and are still able to compute the gradient:# Describe noise noise_gate = qml.DepolarizingChannel noise_strength = 0.1 # Load devices dev_ideal = qml.device("default.mixed", wires=1) dev_noisy = qml.transforms.insert(noise_gate, noise_strength)(dev_ideal) scale_factors = [1, 2, 3] @mitigate_with_zne( scale_factors, qml.transforms.fold_global, qml.transforms.poly_extrapolate, extrapolate_kwargs={'order': 2} ) @qml.qnode(dev_noisy) def qnode_mitigated(theta): qml.RY(theta, wires=0) return qml.expval(qml.PauliX(0))
>>> theta = np.array(0.5, requires_grad=True) >>> qml.grad(qnode_mitigated)(theta) 0.5712737447327619
More native support for parameter broadcasting 📡
default.qubitnow natively supports parameter broadcasting, providing increased performance when executing the same circuit at various parameter positions compared to manually looping over parameters, or directly using theqml.transforms.broadcast_expandtransform. (#2627)dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
>>> circuit(np.array([0.1, 0.3, 0.2])) tensor([0.99500417, 0.95533649, 0.98006658], requires_grad=True)
Currently, not all templates have been updated to support broadcasting.
Parameter-shift gradients now allow for parameter broadcasting internally, which can result in a significant speedup when computing gradients of circuits with many parameters. (#2749)
The gradient transform
qml.gradients.param_shiftnow accepts the keyword argumentbroadcast. If set toTrue, broadcasting is used to compute the derivative:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x, y): qml.RX(x, wires=0) qml.RY(y, wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> x = np.array([np.pi/3, np.pi/2], requires_grad=True) >>> y = np.array([np.pi/6, np.pi/5], requires_grad=True) >>> qml.gradients.param_shift(circuit, broadcast=True)(x, y) (tensor([[-0.7795085, 0. ], [ 0. , -0.7795085]], requires_grad=True), tensor([[-0.125, 0. ], [0. , -0.125]], requires_grad=True))
The following example highlights how to make use of broadcasting gradients at the QNode level. Internally, broadcasting is used to compute the parameter-shift rule when required, which may result in performance improvements.
@qml.qnode(dev, diff_method="parameter-shift", broadcast=True) def circuit(x, y): qml.RX(x, wires=0) qml.RY(y, wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> x = np.array(0.1, requires_grad=True) >>> y = np.array(0.4, requires_grad=True) >>> qml.grad(circuit)(x, y) (array(-0.09195267), array(-0.38747287))
Here, only 2 circuits are created internally, rather than 4 with
broadcast=False.To illustrate the speedup, for a constant-depth circuit with Pauli rotations and controlled Pauli rotations, the time required to compute
qml.gradients.param_shift(circuit, broadcast=False)(params)(“No broadcasting”) andqml.gradients.param_shift(circuit, broadcast=True)(params)(“Broadcasting”) as a function of the number of qubits is given here.Operations for quantum chemistry now support parameter broadcasting. (#2726)
>>> op = qml.SingleExcitation(np.array([0.3, 1.2, -0.7]), wires=[0, 1]) >>> op.matrix().shape (3, 4, 4)
{kind=link}
Intuitive operator arithmetic 🧮
New functionality for representing the sum, product, and scalar-product of operators is available. (#2475) (#2625) (#2622) (#2721)
The following functionalities have been added to facilitate creating new operators whose matrix, terms, and eigenvalues can be accessed as per usual, while maintaining differentiability. Operators created from these new features can be used within QNodes as operations or as observables (where physically applicable).
Summing any number of operators via
qml.op_sumresults in a “summed” operator:>>> ops_to_sum = [qml.PauliX(0), qml.PauliY(1), qml.PauliZ(0)] >>> summed_ops = qml.op_sum(*ops_to_sum) >>> summed_ops PauliX(wires=[0]) + PauliY(wires=[1]) + PauliZ(wires=[0]) >>> qml.matrix(summed_ops) array([[ 1.+0.j, 0.-1.j, 1.+0.j, 0.+0.j], [ 0.+1.j, 1.+0.j, 0.+0.j, 1.+0.j], [ 1.+0.j, 0.+0.j, -1.+0.j, 0.-1.j], [ 0.+0.j, 1.+0.j, 0.+1.j, -1.+0.j]]) >>> summed_ops.terms() ([1.0, 1.0, 1.0], (PauliX(wires=[0]), PauliY(wires=[1]), PauliZ(wires=[0])))
Multiplying any number of operators via
qml.prodresults in a “product” operator, where the matrix product or tensor product is used correspondingly:>>> theta = 1.23 >>> prod_op = qml.prod(qml.PauliZ(0), qml.RX(theta, 1)) >>> prod_op PauliZ(wires=[0]) @ RX(1.23, wires=[1]) >>> qml.eigvals(prod_op) [-1.39373197 -0.23981492 0.23981492 1.39373197]
Taking the product of a coefficient and an operator via
qml.s_prodproduces a “scalar-product” operator:>>> sprod_op = qml.s_prod(2.0, qml.PauliX(0)) >>> sprod_op 2.0*(PauliX(wires=[0])) >>> sprod_op.matrix() array([[ 0., 2.], [ 2., 0.]]) >>> sprod_op.terms() ([2.0], [PauliX(wires=[0])])
Each of these new functionalities can be used within QNodes as operators or observables, where applicable, while also maintaining differentiability. For example:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(angles): qml.prod(qml.PauliZ(0), qml.RY(angles[0], 1)) qml.op_sum(qml.PauliX(1), qml.RY(angles[1], 0)) return qml.expval(qml.op_sum(qml.PauliX(0), qml.PauliZ(1)))
>>> angles = np.array([1.23, 4.56], requires_grad=True) >>> circuit(angles) tensor(0.33423773, requires_grad=True) >>> qml.grad(circuit)(angles) array([-0.9424888, 0. ])
All PennyLane operators can now be added, subtracted, multiplied, scaled, and raised to powers using
+,-,@,*,**, respectively. (#2849) (#2825) (#2891)You can now add scalars to operators, where the interpretation is that the scalar is a properly-sized identity matrix;
>>> sum_op = 5 + qml.PauliX(0) >>> sum_op.matrix() array([[5., 1.], [1., 5.]])
The
+and-operators can be used to combine all Pennylane operators:>>> sum_op = qml.RX(phi=1.23, wires=0) + qml.RZ(phi=3.14, wires=0) - qml.RY(phi=0.12, wires=0) >>> sum_op RX(1.23, wires=[0]) + RZ(3.14, wires=[0]) + -1*(RY(0.12, wires=[0])) >>> qml.matrix(sum_op) array([[-0.18063077-0.99999968j, 0.05996401-0.57695852j], [-0.05996401-0.57695852j, -0.18063077+0.99999968j]])
Note that the behavior of
+and-with observables is different; it still creates a Hamiltonian.The
*and@operators can be used to scale and compose all PennyLane operators.>>> prod_op = 2*qml.RX(1, wires=0) @ qml.RY(2, wires=0) >>> prod_op 2*(RX(1, wires=[0])) @ RY(2, wires=[0]) >>> qml.matrix(prod_op) array([[ 0.94831976-0.80684536j, -1.47692053-0.51806945j], [ 1.47692053-0.51806945j, 0.94831976+0.80684536j]])
The
**operator can be used to raise PennyLane operators to a power.>>> exp_op = qml.RZ(1.0, wires=0) ** 2 >>> exp_op RZ**2(1.0, wires=[0]) >>> qml.matrix(exp_op) array([[0.54030231-0.84147098j, 0. +0.j ], [0. +0.j , 0.54030231+0.84147098j]])
A new class called
Controlledis available inqml.ops.op_mathto represent a controlled version of any operator. This will eventually be integrated intoqml.ctrlto provide a performance increase and more feature coverage. (#2634)Arithmetic operations can now be simplified using
qml.simplify. (#2835) (#2854)>>> op = qml.adjoint(qml.adjoint(qml.RX(x, wires=0))) >>> op Adjoint(Adjoint(RX))(tensor([1.04719755, 1.57079633], requires_grad=True), wires=[0]) >>> qml.simplify(op) RX(tensor([1.04719755, 1.57079633], requires_grad=True), wires=[0])
A new function called
qml.equalcan be used to compare the equality of parametric operators. (#2651)>>> qml.equal(qml.RX(1.23, 0), qml.RX(1.23, 0)) True >>> qml.equal(qml.RY(4.56, 0), qml.RY(7.89, 0)) False
Marvelous mixed state features 🙌
The
default.mixeddevice now supports backpropagation with the"jax"interface, which can result in significant speedups. (#2754) (#2776)dev = qml.device("default.mixed", wires=2) @qml.qnode(dev, diff_method="backprop", interface="jax") def circuit(angles): qml.RX(angles[0], wires=0) qml.RY(angles[1], wires=1) return qml.expval(qml.PauliZ(0) + qml.PauliZ(1))
>>> angles = np.array([np.pi/6, np.pi/5], requires_grad=True) >>> qml.grad(circuit)(angles) array([-0.8660254 , -0.25881905])
Additionally, quantum channels now support Jax and TensorFlow tensors. This allows quantum channels to be used inside QNodes decorated by
tf.function,jax.jit, orjax.vmap.The
default.mixeddevice now supports readout error. (#2786)A new keyword argument called
readout_probcan be specified when creating adefault.mixeddevice. Any circuits running on adefault.mixeddevice with a finitereadout_prob(upper-bounded by 1) will alter the measurements performed at the end of the circuit similarly to how aqml.BitFlipchannel would affect circuit measurements:>>> dev = qml.device("default.mixed", wires=2, readout_prob=0.1) >>> @qml.qnode(dev) ... def circuit(): ... return qml.expval(qml.PauliZ(0)) >>> circuit() array(0.8)
Relative entropy is now available in qml.qinfo 💥
The quantum information module now supports computation of relative entropy. (#2772)
We’ve enabled two cases for calculating the relative entropy:
A QNode transform via
qml.qinfo.relative_entropy:dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(param): qml.RY(param, wires=0) qml.CNOT(wires=[0, 1]) return qml.state()
>>> relative_entropy_circuit = qml.qinfo.relative_entropy(circuit, circuit, wires0=[0], wires1=[0]) >>> x, y = np.array(0.4), np.array(0.6) >>> relative_entropy_circuit((x,), (y,)) 0.017750012490703237
Support in
qml.mathfor flexible post-processing:>>> rho = np.array([[0.3, 0], [0, 0.7]]) >>> sigma = np.array([[0.5, 0], [0, 0.5]]) >>> qml.math.relative_entropy(rho, sigma) tensor(0.08228288, requires_grad=True)
New measurements, operators, and more! ✨
A new measurement called
qml.countsis available. (#2686) (#2839) (#2876)QNodes with
shots != Nonethat returnqml.countswill yield a dictionary whose keys are bitstrings representing computational basis states that were measured, and whose values are the corresponding counts (i.e., how many times that computational basis state was measured):dev = qml.device("default.qubit", wires=2, shots=1000) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) return qml.counts()
>>> circuit() {'00': 495, '11': 505}
qml.countscan also accept observables, where the resulting dictionary is ordered by the eigenvalues of the observable.dev = qml.device("default.qubit", wires=2, shots=1000) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) return qml.counts(qml.PauliZ(0)), qml.counts(qml.PauliZ(1))
>>> circuit() ({-1: 470, 1: 530}, {-1: 470, 1: 530})
A new experimental return type for QNodes with multiple measurements has been added. (#2814) (#2815) (#2860)
QNodes returning a list or tuple of different measurements return an intuitive data structure via
qml.enable_return(), where the individual measurements are separated into their own tensors:qml.enable_return() dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.Hadamard(wires=[0]) qml.CRX(x, wires=[0, 1]) return (qml.probs(wires=[0]), qml.vn_entropy(wires=[0]), qml.probs(wires=0), qml.expval(wires=1))
>>> circuit(0.5) (tensor([0.5, 0.5], requires_grad=True), tensor(0.08014815, requires_grad=True), tensor([0.5, 0.5], requires_grad=True), tensor(0.93879128, requires_grad=True))
In addition, QNodes that utilize this new return type support backpropagation. This new return type can be disabled thereafter via
qml.disable_return().An operator called
qml.FlipSignis now available. (#2780)Mathematically,
qml.FlipSignfunctions as follows: \(\text{FlipSign}(n) \vert m \rangle = (-1)^\delta_{n,m} \vert m \rangle\), where \(\vert m \rangle\) is an arbitrary qubit state and $n$ is a qubit configuration:basis_state = [0, 1] dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): for wire in list(range(2)): qml.Hadamard(wires = wire) qml.FlipSign(basis_state, wires = list(range(2))) return qml.state()
>>> circuit() tensor([ 0.5+0.j -0.5+0.j 0.5+0.j 0.5+0.j], requires_grad=True)
The simultaneous perturbation stochastic approximation (SPSA) optimizer is available via
qml.SPSAOptimizer. (#2661)The SPSA optimizer is suitable for cost functions whose evaluation may involve noise. Use the SPSA optimizer like you would any other optimizer:
max_iterations = 50 opt = qml.SPSAOptimizer(maxiter=max_iterations) for _ in range(max_iterations): params, cost = opt.step_and_cost(cost, params)
More drawing styles 🎨
New PennyLane-inspired
sketchandsketch_darkstyles are now available for drawing circuit diagram graphics. (#2709)
Improvements 📈
default.qubitnow natively executes any operation that defines a matrix except for trainablePowoperations. (#2836)Added
expmto theqml.mathmodule for matrix exponentiation. (#2890)When adjoint differentiation is requested, circuits are now decomposed so that all trainable operations have a generator. (#2836)
A warning is now emitted for
qml.state,qml.density_matrix,qml.vn_entropy, andqml.mutual_infowhen using a device with finite shots or a shot list since these measurements are always analytic. (#2918)The efficiency of the Hartree-Fock workflow has been improved by removing repetitive steps. (#2850)
The coefficients of the non-differentiable molecular Hamiltonians generated with openfermion now have
requires_grad = Falseby default. (#2865)Upgraded performance of the
compute_matrixmethod of broadcastable parametric operations. (#2759)Jacobians are now cached with the Autograd interface when using the parameter-shift rule. (#2645)
The
qml.stateandqml.density_matrixmeasurements now support custom wire labels. (#2779)Add trivial behaviour logic to
qml.operation.expand_matrix. (#2785)Added an
are_pauli_words_qwcfunction which checks if certain Pauli words are pairwise qubit-wise commuting. This new function improves performance when measuring hamiltonians with many commuting terms. (#2789)Adjoint differentiation now uses the adjoint symbolic wrapper instead of in-place inversion. (#2855)
Breaking changes 💔
The deprecated
qml.hfmodule is removed. Users with code that callsqml.hfcan simply replaceqml.hfwithqml.qchemin most cases, or refer to the qchem documentation and demos for more information. (#2795)default.qubitnow usesstopping_conditionto specify support for anything with a matrix. To override this behavior in inheriting devices and to support only a specific subset of operations, developers need to overridestopping_condition. (#2836)Custom devices inheriting from
DefaultQubitorQubitDevicecan break due to the introduction of parameter broadcasting. (#2627)A custom device should only break if all three following statements hold simultaneously:
The custom device inherits from
DefaultQubit, notQubitDevice.The device implements custom methods in the simulation pipeline that are incompatible with broadcasting (for example
expval,apply_operationoranalytic_probability).The custom device maintains the flag
"supports_broadcasting": Truein itscapabilitiesdictionary or it overwritesDevice.batch_transformwithout applyingbroadcast_expand(or both).
The
capabilities["supports_broadcasting"]is set toTrueforDefaultQubit. Typically, the easiest fix will be to change thecapabilities["supports_broadcasting"]flag toFalsefor the child device and/or to include a call tobroadcast_expandinCustomDevice.batch_transform, similar to howDevice.batch_transformcalls it.Separately from the above, custom devices that inherit from
QubitDeviceand implement a custom_gathermethod need to allow for the kwargaxisto be passed to this_gathermethod.The argument
argnumof the functionqml.batch_inputhas been redefined: now it indicates the indices of the batched parameters, which need to be non-trainable, in the quantum tape. Consequently, its default value (set to 0) has been removed. (#2873)Before this breaking change, one could call
qml.batch_inputwithout any arguments when using batched inputs as the first argument of the quantum circuit.dev = qml.device("default.qubit", wires=2, shots=None) @qml.batch_input() # argnum = 0 @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(inputs, weights): # argument `inputs` is batched qml.RY(weights[0], wires=0) qml.AngleEmbedding(inputs, wires=range(2), rotation="Y") qml.RY(weights[1], wires=1) return qml.expval(qml.PauliZ(1))
With this breaking change, users must set a value to
argnumspecifying the index of the batched inputs with respect to all quantum tape parameters. In this example the quantum tape parameters are[ weights[0], inputs, weights[1] ], thusargnumshould be set to 1, specifying thatinputsis batched:dev = qml.device("default.qubit", wires=2, shots=None) @qml.batch_input(argnum=1) @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(inputs, weights): qml.RY(weights[0], wires=0) qml.AngleEmbedding(inputs, wires=range(2), rotation="Y") qml.RY(weights[1], wires=1) return qml.expval(qml.PauliZ(1))
PennyLane now depends on newer versions (>=2.7) of the
semantic_versionpackage, which provides an updated API that is incompatible which versions of the package prior to 2.7. If you run into issues relating to this package, please reinstall PennyLane. (#2744) (#2767)
Documentation 📕
Added a dedicated docstring for the
QubitDevice.samplemethod. (#2812)Optimization examples of using JAXopt and Optax with the JAX interface have been added. (#2769)
Updated IsingXY gate docstring. (#2858)
Bug fixes 🐞
Fixes
qml.equalso that operators with different inverse properties are not equal. (#2947)Cleans up interactions between operator arithmetic and batching by testing supported cases and adding errors when batching is not supported. (#2900)
Fixed a bug where the parameter-shift rule wasn’t defined for
qml.kUpCCGSD. (#2913)Reworked the Hermiticity check in
qml.Hermitianby usingqml.mathcalls because calling.conj()on anEagerTensorfrom TensorFlow raised an error. (#2895)Fixed a bug where the parameter-shift gradient breaks when using both custom
grad_recipes that contain unshifted terms and recipes that do not contain any unshifted terms. (#2834)Fixed mixed CPU-GPU data-locality issues for the Torch interface. (#2830)
Fixed a bug where the parameter-shift Hessian of circuits with untrainable parameters might be computed with respect to the wrong parameters or might raise an error. (#2822)
Fixed a bug where the custom implementation of the
states_to_binarydevice method was not used. (#2809)qml.grouping.group_observablesnow works when individual wire labels are iterable. (#2752)The adjoint of an adjoint now has a correct
expandresult. (#2766)Fixed the ability to return custom objects as the expectation value of a QNode with the Autograd interface. (#2808)
The WireCut operator now raises an error when instantiating it with an empty list. (#2826)
Hamiltonians with grouped observables are now allowed to be measured on devices which were transformed using
qml.transform.insert(). (#2857)Fixed a bug where
qml.batch_inputraised an error when using a batched operator that was not located at the beginning of the circuit. In addition, nowqml.batch_inputraises an error when using trainable batched inputs, which avoids an unwanted behaviour with duplicated parameters. (#2873)Calling
qml.equalwith nested operators now raises aNotImplementedError. (#2877)Fixed a bug where a non-sensible error message was raised when using
qml.countswithshots=False. (#2928)Fixed a bug where no error was raised and a wrong value was returned when using
qml.countswith another non-commuting observable. (#2928)Operator Arithmetic now allows
Hamiltonianobjects to be used and produces correct matrices. (#2957)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Utkarsh Azad, Samuel Banning, Prajwal Borkar, Isaac De Vlugt, Olivia Di Matteo, Kristiyan Dilov, David Ittah, Josh Izaac, Soran Jahangiri, Edward Jiang, Ankit Khandelwal, Korbinian Kottmann, Meenu Kumari, Christina Lee, Sergio Martínez-Losa, Albert Mitjans Coma, Ixchel Meza Chavez, Romain Moyard, Lee James O’Riordan, Mudit Pandey, Bogdan Reznychenko, Shuli Shu, Jay Soni, Modjtaba Shokrian-Zini, Antal Száva, David Wierichs, Moritz Willmann
Release 0.24.0¶
New features since last release
All new quantum information quantities 📏
Functionality for computing quantum information quantities for QNodes has been added. (#2554) (#2569) (#2598) (#2617) (#2631) (#2640) (#2663) (#2684) (#2688) (#2695) (#2710) (#2712)
This includes two new QNode measurements:
The Von Neumann entropy via
qml.vn_entropy:>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit_entropy(x): ... qml.IsingXX(x, wires=[0,1]) ... return qml.vn_entropy(wires=[0], log_base=2) >>> circuit_entropy(np.pi/2) 1.0
The mutual information via
qml.mutual_info:>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit(x): ... qml.IsingXX(x, wires=[0,1]) ... return qml.mutual_info(wires0=[0], wires1=[1], log_base=2) >>> circuit(np.pi/2) 2.0
New differentiable transforms are also available in the
qml.qinfomodule:The classical and quantum Fisher information via
qml.qinfo.classical_fisher,qml.qinfo.quantum_fisher, respectively:dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circ(params): qml.RY(params[0], wires=1) qml.CNOT(wires=(1,0)) qml.RY(params[1], wires=1) qml.RZ(params[2], wires=1) return qml.expval(qml.PauliX(0) @ qml.PauliX(1) - 0.5 * qml.PauliZ(1)) params = np.array([0.5, 1., 0.2], requires_grad=True) cfim = qml.qinfo.classical_fisher(circ)(params) qfim = qml.qinfo.quantum_fisher(circ)(params)
These quantities are typically employed in variational optimization schemes to tilt the gradient in a more favourable direction — producing what is known as the natural gradient. For example:
>>> grad = qml.grad(circ)(params) >>> cfim @ grad # natural gradient [ 5.94225615e-01 -2.61509542e-02 -1.18674655e-18] >>> qfim @ grad # quantum natural gradient [ 0.59422561 -0.02615095 -0.03989212]
The fidelity between two arbitrary states via
qml.qinfo.fidelity:dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def circuit_rx(x): qml.RX(x[0], wires=0) qml.RZ(x[1], wires=0) return qml.state() @qml.qnode(dev) def circuit_ry(y): qml.RY(y, wires=0) return qml.state()
>>> x = np.array([0.1, 0.3], requires_grad=True) >>> y = np.array(0.2, requires_grad=True) >>> fid_func = qml.qinfo.fidelity(circuit_rx, circuit_ry, wires0=[0], wires1=[0]) >>> fid_func(x, y) 0.9905158135644924 >>> df = qml.grad(fid_func) >>> df(x, y) (array([-0.04768725, -0.29183666]), array(-0.09489803))
Reduced density matrices of arbitrary states via
qml.qinfo.reduced_dm:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.IsingXX(x, wires=[0,1]) return qml.state()
>>> qml.qinfo.reduced_dm(circuit, wires=[0])(np.pi/2) [[0.5+0.j 0.+0.j] [0.+0.j 0.5+0.j]]
Similar transforms,
qml.qinfo.vn_entropyandqml.qinfo.mutual_infoexist for transforming QNodes.
Currently, all quantum information measurements and transforms are differentiable, but only support statevector devices, with hardware support to come in a future release (with the exception of
qml.qinfo.classical_fisherandqml.qinfo.quantum_fisher, which are both hardware compatible).For more information, check out the new qinfo module and measurements page.
In addition to the QNode transforms and measurements above, functions for computing and differentiating quantum information metrics with numerical statevectors and density matrices have been added to the
qml.mathmodule. This enables flexible custom post-processing.Added functions include:
qml.math.reduced_dmqml.math.vn_entropyqml.math.mutual_infoqml.math.fidelity
For example:
>>> x = torch.tensor([1.0, 0.0, 0.0, 1.0], requires_grad=True) >>> en = qml.math.vn_entropy(x / np.sqrt(2.), indices=[0]) >>> en tensor(0.6931, dtype=torch.float64, grad_fn=<DivBackward0>) >>> en.backward() >>> x.grad tensor([-0.3069, 0.0000, 0.0000, -0.3069])
Faster mixed-state training with backpropagation 📉
The
default.mixeddevice now supports differentiation via backpropagation with the Autograd, TensorFlow, and PyTorch (CPU) interfaces, leading to significantly more performant optimization and training. (#2615) (#2670) (#2680)As a result, the default differentiation method for the device is now
"backprop". To continue using the old default"parameter-shift", explicitly specify this differentiation method in the QNode:dev = qml.device("default.mixed", wires=2) @qml.qnode(dev, interface="autograd", diff_method="backprop") def circuit(x): qml.RY(x, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(wires=1))
>>> x = np.array(0.5, requires_grad=True) >>> circuit(x) array(0.87758256) >>> qml.grad(circuit)(x) -0.479425538604203
Support for quantum parameter broadcasting 📡
Quantum operators, functions, and tapes now support broadcasting across parameter dimensions, making it more convenient for developers to execute their PennyLane programs with multiple sets of parameters. (#2575) (#2609)
Parameter broadcasting refers to passing tensor parameters with additional leading dimensions to quantum operators; additional dimensions will flow through the computation, and produce additional dimensions at the output.
For example, instantiating a rotation gate with a one-dimensional array leads to a broadcasted
Operation:>>> x = np.array([0.1, 0.2, 0.3], requires_grad=True) >>> op = qml.RX(x, 0) >>> op.batch_size 3
Its matrix correspondingly is augmented by a leading dimension of size
batch_size:>>> np.round(qml.matrix(op), 4) tensor([[[0.9988+0.j , 0. -0.05j ], [0. -0.05j , 0.9988+0.j ]], [[0.995 +0.j , 0. -0.0998j], [0. -0.0998j, 0.995 +0.j ]], [[0.9888+0.j , 0. -0.1494j], [0. -0.1494j, 0.9888+0.j ]]], requires_grad=True) >>> qml.matrix(op).shape (3, 2, 2)
This can be extended to quantum functions, where we may mix-and-match operations with batched parameters and those without. However, the
batch_sizeof each batchedOperatorwithin the quantum function must be the same:>>> dev = qml.device('default.qubit', wires=1) >>> @qml.qnode(dev) ... def circuit_rx(x, z): ... qml.RX(x, wires=0) ... qml.RZ(z, wires=0) ... qml.RY(0.3, wires=0) ... return qml.probs(wires=0) >>> circuit_rx([0.1, 0.2], [0.3, 0.4]) tensor([[0.97092256, 0.02907744], [0.95671515, 0.04328485]], requires_grad=True)
Parameter broadcasting is supported on all devices, hardware and simulator. Note that if not natively supported by the underlying device, parameter broadcasting may result in additional quantum device evaluations.
A new transform,
qml.transforms.broadcast_expand, has been added, which automates the process of transforming quantum functions (and tapes) to multiple quantum evaluations with no parameter broadcasting. (#2590)>>> dev = qml.device('default.qubit', wires=1) >>> @qml.transforms.broadcast_expand() >>> @qml.qnode(dev) ... def circuit_rx(x, z): ... qml.RX(x, wires=0) ... qml.RZ(z, wires=0) ... qml.RY(0.3, wires=0) ... return qml.probs(wires=0) >>> print(qml.draw(circuit_rx)([0.1, 0.2], [0.3, 0.4])) 0: ──RX(0.10)──RZ(0.30)──RY(0.30)─┤ Probs \ 0: ──RX(0.20)──RZ(0.40)──RY(0.30)─┤ Probs
Under-the-hood, this transform is used for devices that don’t natively support parameter broadcasting.
To specify that a device natively supports broadcasted tapes, the new flag
Device.capabilities()["supports_broadcasting"]should be set toTrue.To support parameter broadcasting for new or custom operations, the following new
Operatorclass attributes must be specified:Operator.ndim_paramsspecifies expected number of dimensions for each parameter
Once set,
Operator.batch_sizeandQuantumTape.batch_sizewill dynamically compute the parameter broadcasting axis dimension, if present.
Improved JAX JIT support 🏎
JAX just-in-time (JIT) compilation now supports vector-valued QNodes, enabling new types of workflows and significant performance boosts. (#2034)
Vector-valued QNodes include those with:
qml.probs;qml.state;qml.sampleormultiple
qml.expval/qml.varmeasurements.
Consider a QNode that returns basis-state probabilities:
dev = qml.device('default.qubit', wires=2) x = jnp.array(0.543) y = jnp.array(-0.654) @jax.jit @qml.qnode(dev, diff_method="parameter-shift", interface="jax") def circuit(x, y): qml.RX(x, wires=[0]) qml.RY(y, wires=[1]) qml.CNOT(wires=[0, 1]) return qml.probs(wires=[1])
>>> circuit(x, y) Array([0.8397495 , 0.16025047], dtype=float32)
Note that computing the jacobian of vector-valued QNode is not supported with JAX JIT. The output of vector-valued QNodes can, however, be used in the definition of scalar-valued cost functions whose gradients can be computed.
For example, one can define a cost function that outputs the first element of the probability vector:
def cost(x, y): return circuit(x, y)[0]
>>> jax.grad(cost, argnums=[0])(x, y) (Array(-0.2050439, dtype=float32),)
More drawing styles 🎨
New
solarized_lightandsolarized_darkstyles are available for drawing circuit diagram graphics. (#2662)
New operations & transforms 🤖
The
qml.IsingXYgate is now available (see 1912.04424). (#2649)The
qml.ECR(echoed cross-resonance) operation is now available (see 2105.01063). This gate is a maximally-entangling gate and is equivalent to a CNOT gate up to single-qubit pre-rotations. (#2613)The adjoint transform
adjointcan now accept either a single instantiated operator or a quantum function. It returns an entity of the same type / call signature as what it was given: (#2222) (#2672)>>> qml.adjoint(qml.PauliX(0)) Adjoint(PauliX)(wires=[0]) >>> qml.adjoint(qml.RX)(1.23, wires=0) Adjoint(RX)(1.23, wires=[0])
Now,
adjointwraps operators in a symbolic operator classqml.ops.op_math.Adjoint. This class should not be constructed directly; theadjointconstructor should always be used instead. The class behaves just like any otherOperator:>>> op = qml.adjoint(qml.S(0)) >>> qml.matrix(op) array([[1.-0.j, 0.-0.j], [0.-0.j, 0.-1.j]]) >>> qml.eigvals(op) array([1.-0.j, 0.-1.j])
A new symbolic operator class
qml.ops.op_math.Powrepresents an operator raised to a power. Whendecomposition()is called, a list of new operators equal to this one raised to the given power is given: (#2621)>>> op = qml.ops.op_math.Pow(qml.PauliX(0), 0.5) >>> op.decomposition() [SX(wires=[0])] >>> qml.matrix(op) array([[0.5+0.5j, 0.5-0.5j], [0.5-0.5j, 0.5+0.5j]])
A new transform
qml.batch_partialis available which behaves similarly tofunctools.partial, but supports batching in the unevaluated parameters. (#2585)This is useful for executing a circuit with a batch dimension in some of its parameters:
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x, y): qml.RX(x, wires=0) qml.RY(y, wires=0) return qml.expval(qml.PauliZ(wires=0))
>>> batched_partial_circuit = qml.batch_partial(circuit, x=np.array(np.pi / 4)) >>> y = np.array([0.2, 0.3, 0.4]) >>> batched_partial_circuit(y=y) tensor([0.69301172, 0.67552491, 0.65128847], requires_grad=True)
A new transform
qml.split_non_commutingis available, which splits a quantum function or tape into multiple functions/tapes determined by groups of commuting observables: (#2587)dev = qml.device("default.qubit", wires=1) @qml.transforms.split_non_commuting @qml.qnode(dev) def circuit(x): qml.RX(x,wires=0) return [qml.expval(qml.PauliX(0)), qml.expval(qml.PauliZ(0))]
>>> print(qml.draw(circuit)(0.5)) 0: ──RX(0.50)─┤ <X> \ 0: ──RX(0.50)─┤ <Z>
Improvements
Expectation values of multiple non-commuting observables from within a single QNode are now supported: (#2587)
>>> dev = qml.device('default.qubit', wires=1) >>> @qml.qnode(dev) ... def circuit_rx(x, z): ... qml.RX(x, wires=0) ... qml.RZ(z, wires=0) ... return qml.expval(qml.PauliX(0)), qml.expval(qml.PauliY(0)) >>> circuit_rx(0.1, 0.3) tensor([ 0.02950279, -0.09537451], requires_grad=True)
Selecting which parts of parameter-shift Hessians are computed is now possible. (#2538)
The
argnumkeyword argument forqml.gradients.param_shift_hessianis now allowed to be a two-dimensional Booleanarray_like. Only the indicated entries of the Hessian will then be computed.A particularly useful example is the computation of the diagonal of the Hessian:
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=0) qml.RX(x[2], wires=0) return qml.expval(qml.PauliZ(0)) argnum = qml.math.eye(3, dtype=bool) x = np.array([0.2, -0.9, 1.1], requires_grad=True)
>>> qml.gradients.param_shift_hessian(circuit, argnum=argnum)(x) tensor([[-0.09928388, 0. , 0. ], [ 0. , -0.27633945, 0. ], [ 0. , 0. , -0.09928388]], requires_grad=True)
Commuting Pauli operators are now measured faster. (#2425)
The logic that checks for qubit-wise commuting (QWC) observables has been improved, resulting in a performance boost that is noticable when many commuting Pauli operators of the same type are measured.
It is now possible to add
Observableobjects to the integer0, for exampleqml.PauliX(wires=[0]) + 0. (#2603)Wires can now be passed as the final argument to an
Operator, instead of requiring the wires to be explicitly specified with keywordwires. This functionality already existed forObservables, but now extends to allOperators: (#2432)>>> qml.S(0) S(wires=[0]) >>> qml.CNOT((0,1)) CNOT(wires=[0, 1])
The
qml.taperfunction can now be used to consistently taper any additional observables such as dipole moment, particle number, and spin operators using the symmetries obtained from the Hamiltonian. (#2510)Sparse Hamiltonians’ representation has changed from Coordinate (COO) to Compressed Sparse Row (CSR) format. (#2561)
The CSR representation is more performant for arithmetic operations and matrix-vector products. This change decreases the
expval()calculation time forqml.SparseHamiltonian, specially for large workflows. In addition, the CSR format consumes less memory forqml.SparseHamiltonianstorage.IPython now displays the
strrepresentation of aHamiltonian, rather than therepr. This displays more information about the object. (#2648)The
qml.qchemtests have been restructured. (#2593) (#2545)OpenFermion-dependent tests are now localized and collected in
tests.qchem.of_tests. The new moduletest_structureis created to collect the tests of theqchem.structuremodule in one place and remove their dependency to OpenFermion.Test classes have been created to group the integrals and matrices unit tests.
An
operations_onlyargument is introduced to thetape.get_parametersmethod. (#2543)The
gradientsmodule now uses faster subroutines and uniform formats of gradient rules. (#2452)Instead of checking types, objects are now processed in the
QuantumTapebased on a new_queue_categoryproperty. This is a temporary fix that will disappear in the future. (#2408)The
QNodeclass now contains a new methodbest_method_strthat returns the best differentiation method for a provided device and interface, in human-readable format. (#2533)Using
Operation.inv()in a queuing environment no longer updates the queue’s metadata, but merely updates the operation in place. (#2596)A new method
safe_update_infois added toqml.QueuingContext. This method is substituted forqml.QueuingContext.update_infoin a variety of places. (#2612) (#2675)BasisEmbeddingcan accept an int as argument instead of a list of bits. (#2601)For example,
qml.BasisEmbedding(4, wires = range(4))is now equivalent toqml.BasisEmbedding([0,1,0,0], wires = range(4))(as4==0b100).Introduced a new
is_hermitianproperty toOperators to determine if an operator can be used in a measurement process. (#2629)Added separate
requirements_dev.txtfor separation of concerns for code development and just using PennyLane. (#2635)The performance of building sparse Hamiltonians has been improved by accumulating the sparse representation of coefficient-operator pairs in a temporary storage and by eliminating unnecessary
kronoperations on identity matrices. (#2630)Control values are now displayed distinctly in text and matplotlib drawings of circuits. (#2668)
The
TorchLayerinit_methodargument now accepts either atorch.nn.initfunction or a dictionary which should specify atorch.nn.init/torch.Tensorfor each different weight. (#2678)The unused keyword argument
do_queueforOperation.adjointis now fully removed. (#2583)Several non-decomposable
Adjointoperators are added to the device test suite. (#2658)The developer-facing
powmethod has been added toOperatorwith concrete implementations for many classes. (#2225)The
ctrltransform andControlledOperationhave been moved to the newqml.ops.op_mathsubmodule. The developer-facingControlledOperationclass is no longer imported top-level. (#2656)
Deprecations
qml.ExpvalCosthas been deprecated, and usage will now raise a warning. (#2571)Instead, it is recommended to simply pass Hamiltonians to the
qml.expvalfunction inside QNodes:@qml.qnode(dev) def ansatz(params): some_qfunc(params) return qml.expval(Hamiltonian)
Breaking changes
When using
qml.TorchLayer, weights with negative shapes will now raise an error, while weights withsize = 0will result in creating empty Tensor objects. (#2678)PennyLane no longer supports TensorFlow
<=2.3. (#2683)The
qml.queuing.Queueclass has been removed. (#2599)The
qml.utils.expandfunction is now removed;qml.operation.expand_matrixshould be used instead. (#2654)The module
qml.gradients.param_shift_hessianhas been renamed toqml.gradients.parameter_shift_hessianin order to distinguish it from the identically named function. Note that theparam_shift_hessianfunction is unaffected by this change and can be invoked in the same manner as before via theqml.gradientsmodule. (#2528)The properties
eigvalandmatrixfrom theOperatorclass were replaced with the methodseigval()andmatrix(wire_order=None). (#2498)Operator.decomposition()is now an instance method, and no longer accepts parameters. (#2498)Adds tests, adds no-coverage directives, and removes inaccessible logic to improve code coverage. (#2537)
The base classes
QubitDeviceandDefaultQubitnow accept data-types for a statevector. This enables a derived class (device) in a plugin to choose correct data-types: (#2448)>>> dev = qml.device("default.qubit", wires=4, r_dtype=np.float32, c_dtype=np.complex64) >>> dev.R_DTYPE <class 'numpy.float32'> >>> dev.C_DTYPE <class 'numpy.complex64'>
Bug fixes
Fixed a bug where returning
qml.density_matrixusing the PyTorch interface would return a density matrix with wrong shape. (#2643)Fixed a bug to make
param_shift_hessianwork with QNodes in which gates marked as trainable do not have any impact on the QNode output. (#2584)QNodes can now interpret variations on the interface name, like
"tensorflow"or"jax-jit", when requesting backpropagation. (#2591)Fixed a bug for
diff_method="adjoint"where incorrect gradients were computed for QNodes with parametrized observables (e.g.,qml.Hermitian). (#2543)Fixed a bug where
QNGOptimizerdid not work with operators whose generator was a Hamiltonian. (#2524)Fixed a bug with the decomposition of
qml.CommutingEvolution. (#2542)Fixed a bug enabling PennyLane to work with the latest version of Autoray. (#2549)
Fixed a bug which caused different behaviour for
Hamiltonian @ ObservableandObservable @ Hamiltonian. (#2570)Fixed a bug in
DiagonalQubitUnitary._controlledwhere an invalid operation was queued instead of the controlled version of the diagonal unitary. (#2525)Updated the gradients fix to only apply to the
strawberryfields.gbsdevice, since the original logic was breaking some devices. (#2485) (#2595)Fixed a bug in
qml.transforms.insertwhere operations were not inserted after gates within a template. (#2704)Hamiltonian.wiresis now properly updated after in place operations. (#2738)
Documentation
The centralized Xanadu Sphinx Theme is now used to style the Sphinx documentation. (#2450)
Added a reference to
qml.utils.sparse_hamiltonianinqml.SparseHamiltonianto clarify how to construct sparse Hamiltonians in PennyLane. (2572)Added a new section in the Gradients and Training page that summarizes the supported device configurations and provides justification. In addition, code examples were added for some selected configurations. (#2540)
Added a note for the Depolarization Channel that specifies how the channel behaves for the different values of depolarization probability
p. (#2669)The quickstart documentation has been improved. (#2530) (#2534) (#2564 (#2565 (#2566) (#2607) (#2608)
The quantum chemistry quickstart documentation has been improved. (#2500)
Testing documentation has been improved. (#2536)
Documentation for the
pre-commitpackage has been added. (#2567)Documentation for draw control wires change has been updated. (#2682)
Contributors
This release contains contributions from (in alphabetical order):
Guillermo Alonso-Linaje, Mikhail Andrenkov, Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Samuel Banning, Avani Bhardwaj, Thomas Bromley, Albert Mitjans Coma, Isaac De Vlugt, Amintor Dusko, Trent Fridey, Christian Gogolin, Qi Hu, Katharine Hyatt, David Ittah, Josh Izaac, Soran Jahangiri, Edward Jiang, Nathan Killoran, Korbinian Kottmann, Ankit Khandelwal, Christina Lee, Chae-Yeun Park, Mason Moreland, Romain Moyard, Maria Schuld, Jay Soni, Antal Száva, tal66, David Wierichs, Roeland Wiersema, WingCode.
Release 0.23.1¶
Bug fixes
Fixed a bug enabling PennyLane to work with the latest version of Autoray. (#2548)
Contributors
This release contains contributions from (in alphabetical order):
Josh Izaac
Release 0.23.0¶
New features since last release
More powerful circuit cutting ✂️
Quantum circuit cutting (running
N-wire circuits on devices with fewer thanNwires) is now supported for QNodes of finite-shots using the new@qml.cut_circuit_mctransform. (#2313) (#2321) (#2332) (#2358) (#2382) (#2399) (#2407) (#2444)With these new additions, samples from the original circuit can be simulated using a Monte Carlo method, using fewer qubits at the expense of more device executions. Additionally, this transform can take an optional classical processing function as an argument and return an expectation value.
The following
3-qubit circuit contains aWireCutoperation and asamplemeasurement. When decorated with@qml.cut_circuit_mc, we can cut the circuit into two2-qubit fragments:dev = qml.device("default.qubit", wires=2, shots=1000) @qml.cut_circuit_mc @qml.qnode(dev) def circuit(x): qml.RX(0.89, wires=0) qml.RY(0.5, wires=1) qml.RX(1.3, wires=2) qml.CNOT(wires=[0, 1]) qml.WireCut(wires=1) qml.CNOT(wires=[1, 2]) qml.RX(x, wires=0) qml.RY(0.7, wires=1) qml.RX(2.3, wires=2) return qml.sample(wires=[0, 2])
we can then execute the circuit as usual by calling the QNode:
>>> x = 0.3 >>> circuit(x) tensor([[1, 1], [0, 1], [0, 1], ..., [0, 1], [0, 1], [0, 1]], requires_grad=True)
Furthermore, the number of shots can be temporarily altered when calling the QNode:
>>> results = circuit(x, shots=123) >>> results.shape (123, 2)
The
cut_circuit_mctransform also supports returning sample-based expectation values of observables using theclassical_processing_fnargument. Refer to theUsageDetailssection of the transform documentation for an example.The
cut_circuittransform now supports automatic graph partitioning by specifyingauto_cutter=Trueto cut arbitrary tape-converted graphs using the general purpose graph partitioning framework KaHyPar. (#2330) (#2428)Note that
KaHyParneeds to be installed separately with theauto_cutter=Trueoption.For integration with the existing low-level manual cut pipeline, refer to the documentation of the function .
@qml.cut_circuit(auto_cutter=True) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.RY(0.9, wires=1) qml.RX(0.3, wires=2) qml.CZ(wires=[0, 1]) qml.RY(-0.4, wires=0) qml.CZ(wires=[1, 2]) return qml.expval(qml.grouping.string_to_pauli_word("ZZZ"))
>>> x = np.array(0.531, requires_grad=True) >>> circuit(x) 0.47165198882111165 >>> qml.grad(circuit)(x) -0.276982865449393
Grand QChem unification ⚛️ 🏰
Quantum chemistry functionality — previously split between an external
pennylane-qchempackage and internalqml.hfdifferentiable Hartree-Fock solver — is now unified into a single, included,qml.qchemmodule. (#2164) (#2385) (#2352) (#2420) (#2454)
(#2199) (#2371) (#2272) (#2230) (#2415) (#2426) (#2465)The
qml.qchemmodule provides a differentiable Hartree-Fock solver and the functionality to construct a fully-differentiable molecular Hamiltonian.For example, one can continue to generate molecular Hamiltonians using
qml.qchem.molecular_hamiltonian:symbols = ["H", "H"] geometry = np.array([[0., 0., -0.66140414], [0., 0., 0.66140414]]) hamiltonian, qubits = qml.qchem.molecular_hamiltonian(symbols, geometry, method="dhf")
By default, this will use the differentiable Hartree-Fock solver; however, simply set
method="pyscf"to continue to use PySCF for Hartree-Fock calculations.Functions are added for building a differentiable dipole moment observable. Functions for computing multipole moment molecular integrals, needed for building the dipole moment observable, are also added. (#2173) (#2166)
The dipole moment observable can be constructed using
qml.qchem.dipole_moment:symbols = ['H', 'H'] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) mol = qml.qchem.Molecule(symbols, geometry) args = [geometry] D = qml.qchem.dipole_moment(mol)(*args)
The efficiency of computing molecular integrals and Hamiltonian is improved. This has been done by adding optimized functions for building fermionic and qubit observables and optimizing the functions used for computing the electron repulsion integrals. (#2316)
The
6-31Gbasis set is added to the qchem basis set repo. This addition allows performing differentiable Hartree-Fock calculations with basis sets beyond the minimalsto-3gbasis set for atoms with atomic number 1-10. (#2372)The
6-31Gbasis set can be used to construct a Hamiltonian assymbols = ["H", "H"] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) H, qubits = qml.qchem.molecular_hamiltonian(symbols, geometry, basis="6-31g")
External dependencies are replaced with local functions for spin and particle number observables. (#2197) (#2362)
Pattern matching optimization 🔎 💎
Added an optimization transform that matches pieces of user-provided identity templates in a circuit and replaces them with an equivalent component. (#2032)
For example, consider the following circuit where we want to replace sequence of two
pennylane.Sgates with apennylane.PauliZgate.def circuit(): qml.S(wires=0) qml.PauliZ(wires=0) qml.S(wires=1) qml.CZ(wires=[0, 1]) qml.S(wires=1) qml.S(wires=2) qml.CZ(wires=[1, 2]) qml.S(wires=2) return qml.expval(qml.PauliX(wires=0))
We specify use the following pattern that implements the identity:
with qml.tape.QuantumTape() as pattern: qml.S(wires=0) qml.S(wires=0) qml.PauliZ(wires=0)
To optimize the circuit with this identity pattern, we apply the
qml.transforms.pattern_matchingtransform.>>> dev = qml.device('default.qubit', wires=5) >>> qnode = qml.QNode(circuit, dev) >>> optimized_qfunc = qml.transforms.pattern_matching_optimization(pattern_tapes=[pattern])(circuit) >>> optimized_qnode = qml.QNode(optimized_qfunc, dev) >>> print(qml.draw(qnode)()) 0: ──S──Z─╭C──────────┤ <X> 1: ──S────╰Z──S─╭C────┤ 2: ──S──────────╰Z──S─┤ >>> print(qml.draw(optimized_qnode)()) 0: ──S⁻¹─╭C────┤ <X> 1: ──Z───╰Z─╭C─┤ 2: ──Z──────╰Z─┤
For more details on using pattern matching optimization you can check the corresponding documentation and also the following paper.
Measure the distance between two unitaries📏
Added the
HilbertSchmidtand theLocalHilbertSchmidttemplates to be used for computing distance measures between unitaries. (#2364)Given a unitary
U,qml.HilberSchmidtcan be used to measure the distance between unitaries and to define a cost function (cost_hst) used for learning a unitaryVthat is equivalent toUup to a global phase:# Represents unitary U with qml.tape.QuantumTape(do_queue=False) as u_tape: qml.Hadamard(wires=0) # Represents unitary V def v_function(params): qml.RZ(params[0], wires=1) @qml.qnode(dev) def hilbert_test(v_params, v_function, v_wires, u_tape): qml.HilbertSchmidt(v_params, v_function=v_function, v_wires=v_wires, u_tape=u_tape) return qml.probs(u_tape.wires + v_wires) def cost_hst(parameters, v_function, v_wires, u_tape): return (1 - hilbert_test(v_params=parameters, v_function=v_function, v_wires=v_wires, u_tape=u_tape)[0])
>>> cost_hst(parameters=[0.1], v_function=v_function, v_wires=[1], u_tape=u_tape) tensor(0.999, requires_grad=True)
For more information refer to the documentation of qml.HilbertSchmidt.
More tensor network support 🕸️
Adds the
qml.MERAtemplate for implementing quantum circuits with the shape of a multi-scale entanglement renormalization ansatz (MERA). (#2418)MERA follows the style of previous tensor network templates and is similar to quantum convolutional neural networks.
def block(weights, wires): qml.CNOT(wires=[wires[0],wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_wires = 4 n_block_wires = 2 n_params_block = 2 n_blocks = qml.MERA.get_n_blocks(range(n_wires),n_block_wires) template_weights = [[0.1,-0.3]]*n_blocks dev= qml.device('default.qubit',wires=range(n_wires)) @qml.qnode(dev) def circuit(template_weights): qml.MERA(range(n_wires),n_block_wires,block, n_params_block, template_weights) return qml.expval(qml.PauliZ(wires=1))
It may be necessary to reorder the wires to see the MERA architecture clearly:
>>> print(qml.draw(circuit,expansion_strategy='device',wire_order=[2,0,1,3])(template_weights)) 2: ───────────────╭C──RY(0.10)──╭X──RY(-0.30)───────────────┤ 0: ─╭X──RY(-0.30)─│─────────────╰C──RY(0.10)──╭C──RY(0.10)──┤ 1: ─╰C──RY(0.10)──│─────────────╭X──RY(-0.30)─╰X──RY(-0.30)─┤ <Z> 3: ───────────────╰X──RY(-0.30)─╰C──RY(0.10)────────────────┤
New transform for transpilation ⚙️
Added a swap based transpiler transform. (#2118)
The transpile function takes a quantum function and a coupling map as inputs and compiles the circuit to ensure that it can be executed on corresponding hardware. The transform can be used as a decorator in the following way:
dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) @qml.transforms.transpile(coupling_map=[(0, 1), (1, 2), (2, 3)]) def circuit(param): qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[0, 2]) qml.CNOT(wires=[0, 3]) qml.PhaseShift(param, wires=0) return qml.probs(wires=[0, 1, 2, 3])
>>> print(qml.draw(circuit)(0.3)) 0: ─╭C───────╭C──────────╭C──Rϕ(0.30)─┤ ╭Probs 1: ─╰X─╭SWAP─╰X────╭SWAP─╰X───────────┤ ├Probs 2: ────╰SWAP─╭SWAP─╰SWAP──────────────┤ ├Probs 3: ──────────╰SWAP────────────────────┤ ╰Probs
Improvements
QuantumTapeobjects are now iterable, allowing iteration over the contained operations and measurements. (#2342)with qml.tape.QuantumTape() as tape: qml.RX(0.432, wires=0) qml.RY(0.543, wires=0) qml.CNOT(wires=[0, 'a']) qml.RX(0.133, wires='a') qml.expval(qml.PauliZ(wires=[0]))
Given a
QuantumTapeobject the underlying quantum circuit can be iterated over using aforloop:>>> for op in tape: ... print(op) RX(0.432, wires=[0]) RY(0.543, wires=[0]) CNOT(wires=[0, 'a']) RX(0.133, wires=['a']) expval(PauliZ(wires=[0]))
Indexing into the circuit is also allowed via
tape[i]:>>> tape[0] RX(0.432, wires=[0])
A tape object can also be converted to a sequence (e.g., to a
list) of operations and measurements:>>> list(tape) [RX(0.432, wires=[0]), RY(0.543, wires=[0]), CNOT(wires=[0, 'a']), RX(0.133, wires=['a']), expval(PauliZ(wires=[0]))]
Added the
QuantumTape.shapemethod andQuantumTape.numeric_typeattribute to allow extracting information about the shape and numeric type of the output returned by a quantum tape after execution. (#2044)dev = qml.device("default.qubit", wires=2) a = np.array([0.1, 0.2, 0.3]) def func(a): qml.RY(a[0], wires=0) qml.RX(a[1], wires=0) qml.RY(a[2], wires=0) with qml.tape.QuantumTape() as tape: func(a) qml.state()
>>> tape.shape(dev) (1, 4) >>> tape.numeric_type complex
Defined a
MeasurementProcess.shapemethod and aMeasurementProcess.numeric_typeattribute to allow extracting information about the shape and numeric type of results obtained when evaluating QNodes using the specific measurement process. (#2044)The parameter-shift Hessian can now be computed for arbitrary operations that support the general parameter-shift rule for gradients, using
qml.gradients.param_shift_hessian(#2319)Multiple ways to obtain the gradient recipe are supported, in the following order of preference:
A custom
grad_recipe. It is iterated to obtain the shift rule for the second-order derivatives in the diagonal entries of the Hessian.Custom
parameter_frequencies. The second-order shift rule can directly be computed using them.An operation’s
generator. Its eigenvalues will be used to obtainparameter_frequencies, if they are not given explicitly for an operation.
The strategy for expanding a circuit can now be specified with the
qml.specstransform, for example to calculate the specifications of the circuit that will actually be executed by the device (expansion_strategy="device"). (#2395)The
default.qubitanddefault.mixeddevices now skip over identity operators instead of performing matrix multiplication with the identity. (#2356) (#2365)The function
qml.eigvalsis modified to use the efficientscipy.sparse.linalg.eigshmethod for obtaining the eigenvalues of aSparseHamiltonian. Thisscipymethod is called to compute \(k\) eigenvalues of a sparse \(N \times N\) matrix ifkis smaller than \(N-1\). If a larger \(k\) is requested, the dense matrix representation of the Hamiltonian is constructed and the regularqml.math.linalg.eigvalshis applied. (#2333)The function
qml.ctrlwas given the optional argumentcontrol_values=None. If overridden,control_valuestakes an integer or a list of integers corresponding to the binary value that each control value should take. The same change is reflected inControlledOperation. Control values of0are implemented byqml.PauliXapplied before and after the controlled operation (#2288)Operators now have a
has_matrixproperty denoting whether or not the operator defines a matrix. (#2331) (#2476)Circuit cutting now performs expansion to search for wire cuts in contained operations or tapes. (#2340)
The
qml.drawandqml.draw_mpltransforms are now located in thedrawermodule. They can still be accessed via the top-levelqmlnamespace. (#2396)Raise a warning where caching produces identical shot noise on execution results with finite shots. (#2478)
Deprecations
The
ObservableReturnTypesSample,Variance,Expectation,Probability,State, andMidMeasurehave been moved tomeasurementsfromoperation. (#2329) (#2481)
Breaking changes
The caching ability of devices has been removed. Using the caching on the QNode level is the recommended alternative going forward. (#2443)
One way for replicating the removed
QubitDevicecaching behaviour is by creating acacheobject (e.g., a dictionary) and passing it to theQNode:n_wires = 4 wires = range(n_wires) dev = qml.device('default.qubit', wires=n_wires) cache = {} @qml.qnode(dev, diff_method='parameter-shift', cache=cache) def expval_circuit(params): qml.templates.BasicEntanglerLayers(params, wires=wires, rotation=qml.RX) return qml.expval(qml.PauliZ(0) @ qml.PauliY(1) @ qml.PauliX(2) @ qml.PauliZ(3)) shape = qml.templates.BasicEntanglerLayers.shape(5, n_wires) params = np.random.random(shape)
>>> expval_circuit(params) tensor(0.20598436, requires_grad=True) >>> dev.num_executions 1 >>> expval_circuit(params) tensor(0.20598436, requires_grad=True) >>> dev.num_executions 1
The
qml.finite_difffunction has been removed. Please useqml.gradients.finite_diffto compute the gradient of tapes of QNodes. Otherwise, manual implementation is required. (#2464)The
get_unitary_matrixtransform has been removed, please useqml.matrixinstead. (#2457)The
update_stepsizemethod has been removed fromGradientDescentOptimizerand its child optimizers. Thestepsizeproperty can be interacted with directly instead. (#2370)Most optimizers no longer flatten and unflatten arguments during computation. Due to this change, user provided gradient functions must return the same shape as
qml.grad. (#2381)The old circuit text drawing infrastructure has been removed. (#2310)
RepresentationResolverwas replaced by theOperator.labelmethod.qml.drawer.CircuitDrawerwas replaced byqml.drawer.tape_text.qml.drawer.CHARSETSwas removed because unicode is assumed to be accessible.Gridandqml.drawer.drawable_gridwere removed because the custom data class was replaced by list of sets of operators or measurements.qml.transforms.draw_oldwas replaced byqml.draw.qml.CircuitGraph.greedy_layerswas deleted, as it was no longer needed by the circuit drawer and did not seem to have uses outside of that situation.qml.CircuitGraph.drawwas deleted, as we draw tapes instead.The tape method
qml.tape.QuantumTape.drawnow simply callsqml.drawer.tape_text.In the new pathway, the
charsetkeyword was deleted, themax_lengthkeyword defaults to100, and thedecimalsandshow_matriceskeywords were added.
The deprecated QNode, available via
qml.qnode_old.QNode, has been removed. Please transition to using the standardqml.QNode. (#2336) (#2337) (#2338)In addition, several other components which powered the deprecated QNode have been removed:
The deprecated, non-batch compatible interfaces, have been removed.
The deprecated tape subclasses
QubitParamShiftTape,JacobianTape,CVParamShiftTape, andReversibleTapehave been removed.
The deprecated tape execution method
tape.execute(device)has been removed. Please useqml.execute([tape], device)instead. (#2339)
Bug fixes
Fixed a bug in the
qml.PauliRotoperation, where computing the generator was not taking into account the operation wires. (#2466)Fixed a bug where non-trainable arguments were shifted in the
NesterovMomentumOptimizerif a trainable argument was after it in the argument list. (#2466)Fixed a bug with
@jax.jitfor grad whendiff_method="adjoint"andmode="backward". (#2460)Fixed a bug where
qml.DiagonalQubitUnitarydid not support@jax.jitand@tf.function. (#2445)Fixed a bug in the
qml.PauliRotoperation, where computing the generator was not taking into account the operation wires. (#2442)Fixed a bug with the padding capability of
AmplitudeEmbeddingwhere the inputs are on the GPU. (#2431)Fixed a bug by adding a comprehensible error message for calling
qml.probswithout passing wires or an observable. (#2438)The behaviour of
qml.about()was modified to avoid warnings being emitted due to legacy behaviour ofpip. (#2422)Fixed a bug where observables were not considered when determining the use of the
jax-jitinterface. (#2427) (#2474)Fixed a bug where computing statistics for a relatively few number of shots (e.g.,
shots=10), an error arose due to indexing into an array using aArray. (#2427)PennyLane Lightning version in Docker container is pulled from latest wheel-builds. (#2416)
Optimizers only consider a variable trainable if they have
requires_grad = True. (#2381)Fixed a bug with
qml.expval,qml.var,qml.stateandqml.probs(whenqml.probsis the only measurement) where thedtypespecified on the device did not match thedtypeof the QNode output. (#2367)Fixed a bug where the output shapes from batch transforms are inconsistent with the QNode output shape. (#2215)
Fixed a bug caused by the squeezing in
qml.gradients.param_shift_hessian. (#2215)Fixed a bug in which the
expval/varof aTensor(Observable)would depend on the order in which the observable is defined: (#2276)>>> @qml.qnode(dev) ... def circ(op): ... qml.RX(0.12, wires=0) ... qml.RX(1.34, wires=1) ... qml.RX(3.67, wires=2) ... return qml.expval(op) >>> op1 = qml.Identity(wires=0) @ qml.Identity(wires=1) @ qml.PauliZ(wires=2) >>> op2 = qml.PauliZ(wires=2) @ qml.Identity(wires=0) @ qml.Identity(wires=1) >>> print(circ(op1), circ(op2)) -0.8636111153905662 -0.8636111153905662
Fixed a bug where
qml.hf.transform_hf()would fail due to missing wires in the qubit operator that is prepared for tapering the HF state. (#2441)Fixed a bug with custom device defined jacobians not being returned properly. (#2485)
Documentation
The sections on adding operator and observable support in the “How to add a plugin” section of the plugins page have been updated. (#2389)
The missing arXiv reference in the
LieAlgebraoptimizer has been fixed. (#2325)
Contributors
This release contains contributions from (in alphabetical order):
Karim Alaa El-Din, Guillermo Alonso-Linaje, Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Sam Banning, Thomas Bromley, Alain Delgado, Isaac De Vlugt, Olivia Di Matteo, Amintor Dusko, Anthony Hayes, David Ittah, Josh Izaac, Soran Jahangiri, Nathan Killoran, Christina Lee, Angus Lowe, Romain Moyard, Zeyue Niu, Matthew Silverman, Lee James O’Riordan, Maria Schuld, Jay Soni, Antal Száva, Maurice Weber, David Wierichs.
Release 0.22.2¶
Bug fixes
Most compilation transforms, and relevant subroutines, have been updated to support just-in-time compilation with jax.jit. This fix was intended to be included in
v0.22.0, but due to a bug was incomplete. (#2397)
Documentation
The documentation run has been updated to require
jinja2==3.0.3due to an issue that arises withjinja2v3.1.0andsphinxv3.5.3. (#2378)
Contributors
This release contains contributions from (in alphabetical order):
Olivia Di Matteo, Christina Lee, Romain Moyard, Antal Száva.
Release 0.22.1¶
Bug fixes
Fixes cases with
qml.measurewhere unexpected operations were added to the circuit. (#2328)
Contributors
This release contains contributions from (in alphabetical order):
Guillermo Alonso-Linaje, Antal Száva.
Release 0.22.0¶
New features since last release
Quantum circuit cutting ✂️
You can now run
N-wire circuits on devices with fewer thanNwires, by strategically placingWireCutoperations that allow their circuit to be partitioned into smaller fragments, at a cost of needing to perform a greater number of device executions. Circuit cutting is enabled by decorating a QNode with the@qml.cut_circuittransform. (#2107) (#2124) (#2153) (#2165) (#2158) (#2169) (#2192) (#2216) (#2168) (#2223) (#2231) (#2234) (#2244) (#2251) (#2265) (#2254) (#2260) (#2257) (#2279)The example below shows how a three-wire circuit can be run on a two-wire device:
dev = qml.device("default.qubit", wires=2) @qml.cut_circuit @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.RY(0.9, wires=1) qml.RX(0.3, wires=2) qml.CZ(wires=[0, 1]) qml.RY(-0.4, wires=0) qml.WireCut(wires=1) qml.CZ(wires=[1, 2]) return qml.expval(qml.grouping.string_to_pauli_word("ZZZ"))
Instead of executing the circuit directly, it will be partitioned into smaller fragments according to the
WireCutlocations, and each fragment executed multiple times. Combining the results of the fragment executions will recover the expected output of the original uncut circuit.>>> x = np.array(0.531, requires_grad=True) >>> circuit(0.531) 0.47165198882111165
Circuit cutting support is also differentiable:
>>> qml.grad(circuit)(x) -0.276982865449393
For more details on circuit cutting, check out the qml.cut_circuit documentation page or Peng et. al.
Conditional operations: quantum teleportation unlocked 🔓🌀
Support for mid-circuit measurements and conditional operations has been added, to enable use cases like quantum teleportation, quantum error correction and quantum error mitigation. (#2211) (#2236) (#2275)
Two new functions have been added to support this capability:
qml.measure()places mid-circuit measurements in the middle of a quantum function.qml.cond()allows operations and quantum functions to be conditioned on the result of a previous measurement.
For example, the code below shows how to teleport a qubit from wire 0 to wire 2:
dev = qml.device("default.qubit", wires=3) input_state = np.array([1, -1], requires_grad=False) / np.sqrt(2) @qml.qnode(dev) def teleport(state): # Prepare input state qml.QubitStateVector(state, wires=0) # Prepare Bell state qml.Hadamard(wires=1) qml.CNOT(wires=[1, 2]) # Apply gates qml.CNOT(wires=[0, 1]) qml.Hadamard(wires=0) # Measure first two wires m1 = qml.measure(0) m2 = qml.measure(1) # Condition final wire on results qml.cond(m2 == 1, qml.PauliX)(wires=2) qml.cond(m1 == 1, qml.PauliZ)(wires=2) # Return state on final wire return qml.density_matrix(wires=2)
We can double-check that the qubit has been teleported by computing the overlap between the input state and the resulting state on wire 2:
>>> output_state = teleport(input_state) >>> output_state tensor([[ 0.5+0.j, -0.5+0.j], [-0.5+0.j, 0.5+0.j]], requires_grad=True) >>> input_state.conj() @ output_state @ input_state tensor(1.+0.j, requires_grad=True)
For a full description of new capabilities, refer to the Mid-circuit measurements and conditional operations section in the documentation.
Train mid-circuit measurements by deferring them, via the new
@qml.defer_measurementstransform. (#2211) (#2236) (#2275)If a device doesn’t natively support mid-circuit measurements, the
@qml.defer_measurementstransform can be applied to the QNode to transform the QNode into one with terminal measurements and controlled operations:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) @qml.defer_measurements def circuit(x): qml.Hadamard(wires=0) m = qml.measure(0) def op_if_true(): return qml.RX(x**2, wires=1) def op_if_false(): return qml.RY(x, wires=1) qml.cond(m==1, op_if_true, op_if_false)() return qml.expval(qml.PauliZ(1))
>>> x = np.array(0.7, requires_grad=True) >>> print(qml.draw(circuit, expansion_strategy="device")(x)) 0: ──H─╭C─────────X─╭C─────────X─┤ 1: ────╰RX(0.49)────╰RY(0.70)────┤ <Z> >>> circuit(x) tensor(0.82358752, requires_grad=True)
Deferring mid-circuit measurements also enables differentiation:
>>> qml.grad(circuit)(x) -0.651546965338656
Debug with mid-circuit quantum snapshots 📷
A new operation
qml.Snapshothas been added to assist in debugging quantum functions. (#2233) (#2289) (#2291) (#2315)qml.Snapshotsaves the internal state of devices at arbitrary points of execution.Currently supported devices include:
default.qubit: each snapshot saves the quantum state vectordefault.mixed: each snapshot saves the density matrixdefault.gaussian: each snapshot saves the covariance matrix and vector of means
During normal execution, the snapshots are ignored:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, interface=None) def circuit(): qml.Snapshot() qml.Hadamard(wires=0) qml.Snapshot("very_important_state") qml.CNOT(wires=[0, 1]) qml.Snapshot() return qml.expval(qml.PauliX(0))
However, when using the
qml.snapshotstransform, intermediate device states will be stored and returned alongside the results.>>> qml.snapshots(circuit)() {0: array([1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j]), 'very_important_state': array([0.70710678+0.j, 0. +0.j, 0.70710678+0.j, 0. +0.j]), 2: array([0.70710678+0.j, 0. +0.j, 0. +0.j, 0.70710678+0.j]), 'execution_results': array(0.)}
Batch embedding and state preparation data 📦
Added the
@qml.batch_inputtransform to enable batching non-trainable gate parameters. In addition, theqml.qnn.KerasLayerclass has been updated to natively support batched training data. (#2069)As with other transforms,
@qml.batch_inputcan be used to decorate QNodes:dev = qml.device("default.qubit", wires=2, shots=None) @qml.batch_input(argnum=0) @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(inputs, weights): # add a batch dimension to the embedding data qml.AngleEmbedding(inputs, wires=range(2), rotation="Y") qml.RY(weights[0], wires=0) qml.RY(weights[1], wires=1) return qml.expval(qml.PauliZ(1))
Batched input parameters can then be passed during QNode evaluation:
>>> x = tf.random.uniform((10, 2), 0, 1) >>> w = tf.random.uniform((2,), 0, 1) >>> circuit(x, w) <tf.Tensor: shape=(10,), dtype=float64, numpy= array([0.46230079, 0.73971315, 0.95666004, 0.5355225 , 0.66180948, 0.44519553, 0.93874261, 0.9483197 , 0.78737918, 0.90866411])>
Even more mighty quantum transforms 🐛➡🦋
New functions and transforms of operators have been added:
qml.matrix()for computing the matrix representation of one or more unitary operators. (#2241)qml.eigvals()for computing the eigenvalues of one or more operators. (#2248)qml.generator()for computing the generator of a single-parameter unitary operation. (#2256)
All operator transforms can be used on instantiated operators,
>>> op = qml.RX(0.54, wires=0) >>> qml.matrix(op) [[0.9637709+0.j 0. -0.26673144j] [0. -0.26673144j 0.9637709+0.j ]]
Operator transforms can also be used in a functional form:
>>> x = torch.tensor(0.6, requires_grad=True) >>> matrix_fn = qml.matrix(qml.RX) >>> matrix_fn(x, wires=[0]) tensor([[0.9553+0.0000j, 0.0000-0.2955j], [0.0000-0.2955j, 0.9553+0.0000j]], grad_fn=<AddBackward0>)
In its functional form, it is fully differentiable with respect to gate arguments:
>>> loss = torch.real(torch.trace(matrix_fn(x, wires=0))) >>> loss.backward() >>> x.grad tensor(-0.2955)
Some operator transform can also act on multiple operations, by passing quantum functions or tapes:
>>> def circuit(theta): ... qml.RX(theta, wires=1) ... qml.PauliZ(wires=0) >>> qml.matrix(circuit)(np.pi / 4) array([[ 0.92387953+0.j, 0.+0.j , 0.-0.38268343j, 0.+0.j], [ 0.+0.j, -0.92387953+0.j, 0.+0.j, 0. +0.38268343j], [ 0. -0.38268343j, 0.+0.j, 0.92387953+0.j, 0.+0.j], [ 0.+0.j, 0.+0.38268343j, 0.+0.j, -0.92387953+0.j]])
A new transform has been added to construct the pairwise-commutation directed acyclic graph (DAG) representation of a quantum circuit. (#1712)
In the DAG, each node represents a quantum operation, and edges represent non-commutation between two operations.
This transform takes into account that not all operations can be moved next to each other by pairwise commutation:
>>> def circuit(x, y, z): ... qml.RX(x, wires=0) ... qml.RX(y, wires=0) ... qml.CNOT(wires=[1, 2]) ... qml.RY(y, wires=1) ... qml.Hadamard(wires=2) ... qml.CRZ(z, wires=[2, 0]) ... qml.RY(-y, wires=1) ... return qml.expval(qml.PauliZ(0)) >>> dag_fn = qml.commutation_dag(circuit) >>> dag = dag_fn(np.pi / 4, np.pi / 3, np.pi / 2)
Nodes in the commutation DAG can be accessed via the
get_nodes()method, returning a list of the form(ID, CommutationDAGNode):>>> nodes = dag.get_nodes() >>> nodes NodeDataView({0: <pennylane.transforms.commutation_dag.CommutationDAGNode object at 0x7f461c4bb580>, ...}, data='node')
Specific nodes in the commutation DAG can be accessed via the
get_node()method:>>> second_node = dag.get_node(2) >>> second_node <pennylane.transforms.commutation_dag.CommutationDAGNode object at 0x136f8c4c0> >>> second_node.op CNOT(wires=[1, 2]) >>> second_node.successors [3, 4, 5, 6] >>> second_node.predecessors []
Improvements
The text-based drawer accessed via
qml.draw()has been optimized and improved. (#2128) (#2198)The new drawer has:
a
decimalskeyword for controlling parameter roundinga
show_matriceskeyword for controlling display of matricesa different algorithm for determining positions
deprecation of the
charsetkeywordadditional minor cosmetic changes
@qml.qnode(qml.device('lightning.qubit', wires=2)) def circuit(a, w): qml.Hadamard(0) qml.CRX(a, wires=[0, 1]) qml.Rot(*w, wires=[1]) qml.CRX(-a, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> print(qml.draw(circuit, decimals=2)(a=2.3, w=[1.2, 3.2, 0.7])) 0: ──H─╭C─────────────────────────────╭C─────────┤ ╭<Z@Z> 1: ────╰RX(2.30)──Rot(1.20,3.20,0.70)─╰RX(-2.30)─┤ ╰<Z@Z>
The frequencies of gate parameters are now accessible as an operation property and can be used for circuit analysis, optimization via the
RotosolveOptimizerand differentiation with the parameter-shift rule (including the general shift rule). (#2180) (#2182) (#2227)>>> op = qml.CRot(0.4, 0.1, 0.3, wires=[0, 1]) >>> op.parameter_frequencies [(0.5, 1.0), (0.5, 1.0), (0.5, 1.0)]
When using
qml.gradients.param_shift, either a customgrad_recipeor the parameter frequencies are used to obtain the shift rule for the operation, in that order of preference.See Vidal and Theis (2018) and Wierichs et al. (2021) for theoretical background information on the general parameter-shift rule.
No two-term parameter-shift rule is assumed anymore by default. (#2227)
Previously, operations marked for analytic differentiation that did not provide a
generator,parameter_frequenciesor a customgrad_recipewere assumed to satisfy the two-term shift rule. This now has to be made explicit for custom operations by adding any of the above attributes.Most compilation transforms, and relevant subroutines, have been updated to support just-in-time compilation with
jax.jit. (#1894)The
qml.draw_mpltransform supports aexpansion_strategykeyword argument. (#2271)The
qml.gradientsmodule has been streamlined and special-purpose functions moved closer to their use cases, while preserving existing behaviour. (#2200)Added a new
partition_pauli_groupfunction to thegroupingmodule for efficiently measuring theN-qubit Pauli group with3 ** Nqubit-wise commuting terms. (#2185)The Operator class has undergone a major refactor with the following changes:
Matrices: the static method
Operator.compute_matrices()defines the matrix representation of the operator, and the functionqml.matrix(op)computes this for a given instance. (#1996)Eigvals: the static method
Operator.compute_eigvals()defines the matrix representation of the operator, and the functionqml.eigvals(op)computes this for a given instance. (#2048)Decompositions: the static method
Operator.compute_decomposition()defines the matrix representation of the operator, and the methodop.decomposition()computes this for a given instance. (#2024) (#2053)Sparse matrices: the static method
Operator.compute_sparse_matrix()defines the sparse matrix representation of the operator, and the methodop.sparse_matrix()computes this for a given instance. (#2050)Linear combinations of operators: The static method
compute_terms(), used for representing the linear combination of coefficients and operators representing the operator, has been added. The methodop.terms()computes this for a given instance. Currently, only theHamiltonianclass overwritescompute_terms()to store coefficients and operators. TheHamiltonian.termsproperty hence becomes a proper method called byHamiltonian.terms(). (#2036)Diagonalization: The
diagonalizing_gates()representation has been moved to the highest-levelOperatorclass and is therefore available to all subclasses. A conditionqml.operation.defines_diagonalizing_gateshas been added, which can be used in tape contexts without queueing. In addition, a staticcompute_diagonalizing_gatesmethod has been added, which is called by default indiagonalizing_gates(). (#1985) (#1993)Error handling has been improved for Operator representations. Custom errors subclassing
OperatorPropertyUndefinedare raised if a representation has not been defined. This replaces theNotImplementedErrorand allows finer control for developers. (#2064) (#2287)A
Operator.hyperparametersattribute, used for storing operation parameters that are never trainable, has been added to the operator class. (#2017)The
string_for_inverseattribute is removed. (#2021)The
expand()method was moved from theOperationclass to the mainOperatorclass. (#2053) (#2239)
Deprecations
There are several important changes when creating custom operations: (#2214) (#2227) (#2030) (#2061)
The
Operator.matrixmethod has been deprecated andOperator.compute_matrixshould be defined instead. Operator matrices should be accessed usingqml.matrix(op). If you were previously defining the class methodOperator._matrix(), this is a a breaking change — please update your operation to instead overwriteOperator.compute_matrix.The
Operator.decompositionmethod has been deprecated andOperator.compute_decompositionshould be defined instead. Operator decompositions should be accessed usingOperator.decomposition().The
Operator.eigvalsmethod has been deprecated andOperator.compute_eigvalsshould be defined instead. Operator eigenvalues should be accessed usingqml.eigvals(op).The
Operator.generatorproperty is now a method, and should return an operator instance representing the generator. Note that unlike the other representations above, this is a breaking change. Operator generators should be accessed usingqml.generator(op).The
Operation.get_parameter_shiftmethod has been deprecated and will be removed in a future release.Instead, the functionalities for general parameter-shift rules in the
qml.gradientsmodule should be used, together with the operation attributesparameter_frequenciesorgrad_recipe.
Executing tapes using
tape.execute(dev)is deprecated. Please use theqml.execute([tape], dev)function instead. (#2306)The subclasses of the quantum tape, including
JacobianTape,QubitParamShiftTape,CVParamShiftTape, andReversibleTapeare deprecated. Instead of callingJacobianTape.jacobian()andJacobianTape.hessian(), please use a standardQuantumTape, and apply gradient transforms using theqml.gradientsmodule. (#2306)qml.transforms.get_unitary_matrix()has been deprecated and will be removed in a future release. For extracting matrices of operations and quantum functions, please useqml.matrix(). (#2248)The
qml.finite_diff()function has been deprecated and will be removed in an upcoming release. Instead,qml.gradients.finite_diff()can be used to compute purely quantum gradients (that is, gradients of tapes or QNode). (#2212)The
MultiControlledXoperation now accepts a singlewireskeyword argument for bothcontrol_wiresandwires. The singlewireskeyword should be all the control wires followed by a single target wire. (#2121) (#2278)
Breaking changes
The representation of an operator as a matrix has been overhauled. (#1996)
The “canonical matrix”, which is independent of wires, is now defined in the static method
compute_matrix()instead of_matrix. By default, this method is assumed to take all parameters and non-trainable hyperparameters that define the operation.>>> qml.RX.compute_matrix(0.5) [[0.96891242+0.j 0. -0.24740396j] [0. -0.24740396j 0.96891242+0.j ]]
If no canonical matrix is specified for a gate,
compute_matrix()raises aMatrixUndefinedError.The generator property has been updated to an instance method,
Operator.generator(). It now returns an instantiated operation, representing the generator of the instantiated operator. (#2030) (#2061)Various operators have been updated to specify the generator as either an
Observable,Tensor,Hamiltonian,SparseHamiltonian, orHermitianoperator.In addition,
qml.generator(operation)has been added to aid in retrieving generator representations of operators.The argument
wiresinheisenberg_obs,heisenberg_expandandheisenberg_trwas renamed towire_orderto be consistent with other matrix representations. (#2051)The property
kraus_matriceshas been changed to a method, and_kraus_matricesrenamed tocompute_kraus_matrices, which is now a static method. (#2055)The
pennylane.measuremodule has been renamed topennylane.measurements. (#2236)
Bug fixes
The
basisproperty ofqml.SWAPwas set to"X", which is incorrect; it is now set toNone. (#2287)The
qml.RandomLayerstemplate now decomposes when the weights are a list of lists. (#2266)The
qml.QubitUnitaryoperation now supports just-in-time compilation using JAX. (#2249)Fixes a bug in the JAX interface where
Arrayobjects were not being converted to NumPy arrays before executing an external device. (#2255)The
qml.ctrltransform now works correctly with gradient transforms such as the parameter-shift rule. (#2238)Fixes a bug in which passing required arguments into operations as keyword arguments would throw an error because the documented call signature didn’t match the function definition. (#1976)
The operation
OrbitalRotationpreviously was wrongfully registered to satisfy the four-term parameter shift rule. The correct eight-term rule will now be used when using the parameter-shift rule. (#2180)Fixes a bug where
qml.gradients.param_shift_hessianwould produce an error whenever all elements of the Hessian are known in advance to be 0. (#2299)
Documentation
The developer guide on adding templates and the architecture overview were rewritten to reflect the past and planned changes of the operator refactor. (#2066)
Links to the Strawberry Fields documentation for information on the CV model. (#2259)
Fixes the documentation example for
qml.QFT. (#2232)Fixes the documentation example for using
qml.samplewithjax.jit. (#2196)The
qml.numpysubpackage is now included in the PennyLane API documentation. (#2179)Improves the documentation of
RotosolveOptimizerregarding the usage of the passedsubstep_optimizerand its keyword arguments. (#2160)Ensures that signatures of
@qml.qfunc_transformdecorated functions display correctly in the docs. (#2286)Docstring examples now display using the updated text-based circuit drawer. (#2252)
Add docstring to
OrbitalRotation.grad_recipe. (#2193)
Contributors
This release contains contributions from (in alphabetical order):
Catalina Albornoz, Jack Y. Araz, Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Sam Banning, Thomas Bromley, Olivia Di Matteo, Christian Gogolin, Diego Guala, Anthony Hayes, David Ittah, Josh Izaac, Soran Jahangiri, Nathan Killoran, Christina Lee, Angus Lowe, Maria Fernanda Morris, Romain Moyard, Zeyue Niu, Lee James O’Riordan, Chae-Yeun Park, Maria Schuld, Jay Soni, Antal Száva, David Wierichs.
Release 0.21.0¶
New features since last release
Reduce qubit requirements of simulating Hamiltonians ⚛️
Functions for tapering qubits based on molecular symmetries have been added, following results from Setia et al. (#1966) (#1974) (#2041) (#2042)
With this functionality, a molecular Hamiltonian and the corresponding Hartree-Fock (HF) state can be transformed to a new Hamiltonian and HF state that acts on a reduced number of qubits, respectively.
# molecular geometry symbols = ["He", "H"] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.4588684632]]) mol = qml.hf.Molecule(symbols, geometry, charge=1) # generate the qubit Hamiltonian H = qml.hf.generate_hamiltonian(mol)(geometry) # determine Hamiltonian symmetries generators, paulix_ops = qml.hf.generate_symmetries(H, len(H.wires)) opt_sector = qml.hf.optimal_sector(H, generators, mol.n_electrons) # taper the Hamiltonian H_tapered = qml.hf.transform_hamiltonian(H, generators, paulix_ops, opt_sector)
We can compare the number of qubits required by the original Hamiltonian and the tapered Hamiltonian:
>>> len(H.wires) 4 >>> len(H_tapered.wires) 2
For quantum chemistry algorithms, the Hartree-Fock state can also be tapered:
n_elec = mol.n_electrons n_qubits = mol.n_orbitals * 2 hf_tapered = qml.hf.transform_hf( generators, paulix_ops, opt_sector, n_elec, n_qubits )
>>> hf_tapered tensor([1, 1], requires_grad=True)
New tensor network templates 🪢
Quantum circuits with the shape of a matrix product state tensor network can now be easily implemented using the new
qml.MPStemplate, based on the work arXiv:1803.11537. (#1871)def block(weights, wires): qml.CNOT(wires=[wires[0], wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_wires = 4 n_block_wires = 2 n_params_block = 2 template_weights = np.array([[0.1, -0.3], [0.4, 0.2], [-0.15, 0.5]], requires_grad=True) dev = qml.device("default.qubit", wires=range(n_wires)) @qml.qnode(dev) def circuit(weights): qml.MPS(range(n_wires), n_block_wires, block, n_params_block, weights) return qml.expval(qml.PauliZ(wires=n_wires - 1))
The resulting circuit is:
>>> print(qml.draw(circuit, expansion_strategy="device")(template_weights)) 0: ──╭C──RY(0.1)───────────────────────────────┤ 1: ──╰X──RY(-0.3)──╭C──RY(0.4)─────────────────┤ 2: ────────────────╰X──RY(0.2)──╭C──RY(-0.15)──┤ 3: ─────────────────────────────╰X──RY(0.5)────┤ ⟨Z⟩
Added a template for tree tensor networks,
qml.TTN. (#2043)def block(weights, wires): qml.CNOT(wires=[wires[0], wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_wires = 4 n_block_wires = 2 n_params_block = 2 n_blocks = qml.MPS.get_n_blocks(range(n_wires), n_block_wires) template_weights = [[0.1, -0.3]] * n_blocks dev = qml.device("default.qubit", wires=range(n_wires)) @qml.qnode(dev) def circuit(template_weights): qml.TTN(range(n_wires), n_block_wires, block, n_params_block, template_weights) return qml.expval(qml.PauliZ(wires=n_wires - 1))
The resulting circuit is:
>>> print(qml.draw(circuit, expansion_strategy="device")(template_weights)) 0: ──╭C──RY(0.1)─────────────────┤ 1: ──╰X──RY(-0.3)──╭C──RY(0.1)───┤ 2: ──╭C──RY(0.1)───│─────────────┤ 3: ──╰X──RY(-0.3)──╰X──RY(-0.3)──┤ ⟨Z⟩
Generalized RotosolveOptmizer 📉
The
RotosolveOptimizerhas been generalized to arbitrary frequency spectra in the cost function. Also note the changes in behaviour listed under Breaking changes. (#2081)Previously, the RotosolveOptimizer only supported variational circuits using special gates such as single-qubit Pauli rotations. Now, circuits with arbitrary gates are supported natively without decomposition, as long as the frequencies of the gate parameters are known. This new generalization extends the Rotosolve optimization method to a larger class of circuits, and can reduce the cost of the optimization compared to decomposing all gates to single-qubit rotations.
Consider the QNode
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def qnode(x, Y): qml.RX(2.5 * x, wires=0) qml.CNOT(wires=[0, 1]) qml.RZ(0.3 * Y[0], wires=0) qml.CRY(1.1 * Y[1], wires=[1, 0]) return qml.expval(qml.PauliX(0) @ qml.PauliZ(1)) x = np.array(0.8, requires_grad=True) Y = np.array([-0.2, 1.5], requires_grad=True)
Its frequency spectra can be easily obtained via
qml.fourier.qnode_spectrum:>>> spectra = qml.fourier.qnode_spectrum(qnode)(x, Y) >>> spectra {'x': {(): [-2.5, 0.0, 2.5]}, 'Y': {(0,): [-0.3, 0.0, 0.3], (1,): [-1.1, -0.55, 0.0, 0.55, 1.1]}}
We may then initialize the
RotosolveOptimizerand minimize the QNode cost function by providing this information about the frequency spectra. We also compare the cost at each step to the initial cost.>>> cost_init = qnode(x, Y) >>> opt = qml.RotosolveOptimizer() >>> for _ in range(2): ... x, Y = opt.step(qnode, x, Y, spectra=spectra) ... print(f"New cost: {np.round(qnode(x, Y), 3)}; Initial cost: {np.round(cost_init, 3)}") New cost: 0.0; Initial cost: 0.706 New cost: -1.0; Initial cost: 0.706
The optimization with
RotosolveOptimizeris performed in substeps. The minimal cost of these substeps can be retrieved by settingfull_output=True.>>> x = np.array(0.8, requires_grad=True) >>> Y = np.array([-0.2, 1.5], requires_grad=True) >>> opt = qml.RotosolveOptimizer() >>> for _ in range(2): ... (x, Y), history = opt.step(qnode, x, Y, spectra=spectra, full_output=True) ... print(f"New cost: {np.round(qnode(x, Y), 3)} reached via substeps {np.round(history, 3)}") New cost: 0.0 reached via substeps [-0. 0. 0.] New cost: -1.0 reached via substeps [-1. -1. -1.]
However, note that these intermediate minimal values are evaluations of the reconstructions that Rotosolve creates and uses internally for the optimization, and not of the original objective function. For noisy cost functions, these intermediate evaluations may differ significantly from evaluations of the original cost function.
Improved JAX support 💻
The JAX interface now supports evaluating vector-valued QNodes. (#2110)
Vector-valued QNodes include those with:
qml.probs;qml.state;qml.sampleormultiple
qml.expval/qml.varmeasurements.
Consider a QNode that returns basis-state probabilities:
dev = qml.device('default.qubit', wires=2) x = jnp.array(0.543) y = jnp.array(-0.654) @qml.qnode(dev, diff_method="parameter-shift", interface="jax") def circuit(x, y): qml.RX(x, wires=[0]) qml.RY(y, wires=[1]) qml.CNOT(wires=[0, 1]) return qml.probs(wires=[1])
The QNode can be evaluated and its jacobian can be computed:
>>> circuit(x, y) Array([0.8397495 , 0.16025047], dtype=float32) >>> jax.jacobian(circuit, argnums=[0, 1])(x, y) (Array([-0.2050439, 0.2050439], dtype=float32, weak_type=True), Array([ 0.26043, -0.26043], dtype=float32, weak_type=True))
Note that
jax.jitis not yet supported for vector-valued QNodes.
Speedier quantum natural gradient ⚡
A new function for computing the metric tensor on simulators,
qml.adjoint_metric_tensor, has been added, that uses classically efficient methods to massively improve performance. (#1992)This method, detailed in Jones (2020), computes the metric tensor using four copies of the state vector and a number of operations that scales quadratically in the number of trainable parameters.
Note that as it makes use of state cloning, it is inherently classical and can only be used with statevector simulators and
shots=None.It is particularly useful for larger circuits for which backpropagation requires inconvenient or even unfeasible amounts of storage, but is slower. Furthermore, the adjoint method is only available for analytic computation, not for measurements simulation with
shots!=None.dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circuit(x, y): qml.Rot(*x[0], wires=0) qml.Rot(*x[1], wires=1) qml.Rot(*x[2], wires=2) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[1, 2]) qml.CNOT(wires=[2, 0]) qml.RY(y[0], wires=0) qml.RY(y[1], wires=1) qml.RY(y[0], wires=2) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)), qml.expval(qml.PauliY(1)) x = np.array([[0.2, 0.4, -0.1], [-2.1, 0.5, -0.2], [0.1, 0.7, -0.6]], requires_grad=False) y = np.array([1.3, 0.2], requires_grad=True)
>>> qml.adjoint_metric_tensor(circuit)(x, y) tensor([[ 0.25495723, -0.07086695], [-0.07086695, 0.24945606]], requires_grad=True)
Computational cost
The adjoint method uses \(2P^2+4P+1\) gates and state cloning operations if the circuit is composed only of trainable gates, where \(P\) is the number of trainable operations. If non-trainable gates are included, each of them is applied about \(n^2-n\) times, where \(n\) is the number of trainable operations that follow after the respective non-trainable operation in the circuit. This means that non-trainable gates later in the circuit are executed less often, making the adjoint method a bit cheaper if such gates appear later. The adjoint method requires memory for 4 independent state vectors, which corresponds roughly to storing a state vector of a system with 2 additional qubits.
Compute the Hessian on hardware ⬆️
A new gradient transform
qml.gradients.param_shift_hessianhas been added to directly compute the Hessian (2nd order partial derivative matrix) of QNodes on hardware. (#1884)The function generates parameter-shifted tapes which allow the Hessian to be computed analytically on hardware and software devices. Compared to using an auto-differentiation framework to compute the Hessian via parameter shifts, this function will use fewer device invocations and can be used to inspect the parameter-shifted “Hessian tapes” directly. The function remains fully differentiable on all supported PennyLane interfaces.
Additionally, the parameter-shift Hessian comes with a new batch transform decorator
@qml.gradients.hessian_transform, which can be used to create custom Hessian functions.The following code demonstrates how to use the parameter-shift Hessian:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=0) return qml.expval(qml.PauliZ(0)) x = np.array([0.1, 0.2], requires_grad=True) hessian = qml.gradients.param_shift_hessian(circuit)(x)
>>> hessian tensor([[-0.97517033, 0.01983384], [ 0.01983384, -0.97517033]], requires_grad=True)
Improvements
The
qml.transforms.inserttransform now supports adding operation after or before certain specific gates. (#1980)Added a modified version of the
simplifyfunction to thehfmodule. (#2103)This function combines redundant terms in a Hamiltonian and eliminates terms with a coefficient smaller than a cutoff value. The new function makes construction of molecular Hamiltonians more efficient. For LiH, as an example, the time to construct the Hamiltonian is reduced roughly by a factor of 20.
The QAOA module now accepts both NetworkX and RetworkX graphs as function inputs. (#1791)
The
CircuitGraph, used to represent circuits via directed acyclic graphs, now uses RetworkX for its internal representation. This results in significant speedup for algorithms that rely on a directed acyclic graph representation. (#1791)For subclasses of
Operatorwhere the number of parameters is known before instantiation, thenum_paramsis reverted back to being a static property. This allows to programmatically know the number of parameters before an operator is instantiated without changing the user interface. A test was added to ensure that different ways of definingnum_paramswork as expected. (#2101) (#2135)A
WireCutoperator has been added for manual wire cut placement when constructing a QNode. (#2093)The new function
qml.drawer.tape_textproduces a string drawing of a tape. This function differs in implementation and minor stylistic details from the old string circuit drawing infrastructure. (#1885)The
RotosolveOptimizernow raises an error if no trainable arguments are detected, instead of silently skipping update steps for all arguments. (#2109)The function
qml.math.safe_squeezeis introduced andgradient_transformallows for QNode argument axes of size1. (#2080)qml.math.safe_squeezewrapsqml.math.squeeze, with slight modifications:When provided the
axiskeyword argument, axes that do not have size1will be ignored, instead of raising an error.The keyword argument
exclude_axisallows to explicitly exclude axes from the squeezing.
The
adjointtransform now raises and error whenever the object it is applied to is not callable. (#2060)An example is a list of operations to which one might apply
qml.adjoint:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit_wrong(params): # Note the difference: v v qml.adjoint(qml.templates.AngleEmbedding(params, wires=dev.wires)) return qml.state() @qml.qnode(dev) def circuit_correct(params): # Note the difference: v v qml.adjoint(qml.templates.AngleEmbedding)(params, wires=dev.wires) return qml.state() params = list(range(1, 3))
Evaluating
circuit_wrong(params)now raises aValueErrorand if we applyqml.adjointcorrectly, we get>>> circuit_correct(params) [ 0.47415988+0.j 0. 0.73846026j 0. 0.25903472j -0.40342268+0.j ]
A precision argument has been added to the tape’s
to_openqasmfunction to control the precision of parameters. (#2071)Interferometer now has a
shapemethod. (#1946)The Barrier and Identity operations now support the
adjointmethod. (#2062) (#2063)qml.BasisStatePreparationnow supports thebatch_paramsdecorator. (#2091)Added a new
multi_dispatchdecorator that helps ease the definition of new functions inside PennyLane. The decorator is used throughout the math module, demonstrating use cases. (#2082) (#2096)We can decorate a function, indicating the arguments that are tensors handled by the interface:
>>> @qml.math.multi_dispatch(argnum=[0, 1]) ... def some_function(tensor1, tensor2, option, like): ... # the interface string is stored in ``like``. ... ...
Previously, this was done using the private utility function
_multi_dispatch.>>> def some_function(tensor1, tensor2, option): ... interface = qml.math._multi_dispatch([tensor1, tensor2]) ... ...
The
IsingZZgate was added to thediagonal_in_z_basisattribute. For this an explicit_eigvalsmethod was added. (#2113)The
IsingXX,IsingYYandIsingZZgates were added to thecomposable_rotationsattribute. (#2113)
Breaking changes
QNode arguments will no longer be considered trainable by default when using the Autograd interface. In order to obtain derivatives with respect to a parameter, it should be instantiated via PennyLane’s NumPy wrapper using the
requires_grad=Trueattribute. The previous behaviour was deprecated in version v0.19.0 of PennyLane. (#2116) (#2125) (#2139) (#2148) (#2156)from pennylane import numpy as np @qml.qnode(qml.device("default.qubit", wires=2)) def circuit(x): ... x = np.array([0.1, 0.2], requires_grad=True) qml.grad(circuit)(x)
For the
qml.gradandqml.jacobianfunctions, trainability can alternatively be indicated via theargnumkeyword:import numpy as np @qml.qnode(qml.device("default.qubit", wires=2)) def circuit(hyperparam, param): ... x = np.array([0.1, 0.2]) qml.grad(circuit, argnum=1)(0.5, x)
qml.jacobiannow follows a different convention regarding its output shape. (#2059)Previously,
qml.jacobianwould attempt to stack the Jacobian for multiple QNode arguments, which succeeded whenever the arguments have the same shape. In this case, the stacked Jacobian would also be transposed, leading to the output shape(*reverse_QNode_args_shape, *reverse_output_shape, num_QNode_args)If no stacking and transposing occurs, the output shape instead is a
tuplewhere each entry corresponds to one QNode argument and has the shape(*output_shape, *QNode_arg_shape).This breaking change alters the behaviour in the first case and removes the attempt to stack and transpose, so that the output always has the shape of the second type.
Note that the behaviour is unchanged — that is, the Jacobian tuple is unpacked into a single Jacobian — if
argnum=Noneand there is only one QNode argument with respect to which the differentiation takes place, or if an integer is provided asargnum.A workaround that allowed
qml.jacobianto differentiate multiple QNode arguments will no longer support higher-order derivatives. In such cases, combining multiple arguments into a single array is recommended.qml.metric_tensor,qml.adjoint_metric_tensorandqml.transforms.classical_jacobiannow follow a different convention regarding their output shape when being used with the Autograd interface (#2059)See the previous entry for details. This breaking change immediately follows from the change in
qml.jacobianwheneverhybrid=Trueis used in the above methods.The behaviour of
RotosolveOptimizerhas been changed regarding its keyword arguments. (#2081)The keyword arguments
optimizerandoptimizer_kwargsfor theRotosolveOptimizerhave been renamed tosubstep_optimizerandsubstep_kwargs, respectively. Furthermore they have been moved fromstepandstep_and_costto the initialization__init__.The keyword argument
num_freqshas been renamed tonums_frequencyand is expected to take a different shape now: Previously, it was expected to be anintor a list of entries, with each entry in turn being either anintor alistofintentries. Now the expected structure is a nested dictionary, matching the formatting expected by qml.fourier.reconstruct This also matches the expected formatting of the new keyword argumentsspectraandshifts.For more details, see the RotosolveOptimizer documentation.
Deprecations
Deprecates the caching ability provided by
QubitDevice. (#2154)Going forward, the preferred way is to use the caching abilities of the QNode:
dev = qml.device("default.qubit", wires=2) cache = {} @qml.qnode(dev, diff_method='parameter-shift', cache=cache) def circuit(): qml.RY(0.345, wires=0) return qml.expval(qml.PauliZ(0))
>>> for _ in range(10): ... circuit() >>> dev.num_executions 1
Bug fixes
Fixes a bug where an incorrect number of executions are recorded by a QNode using a custom cache with
diff_method="backprop". (#2171)Fixes a bug where the
default.qubit.jaxdevice can’t be used withdiff_method=Noneand jitting. (#2136)Fixes a bug where the Torch interface was not properly unwrapping Torch tensors to NumPy arrays before executing gradient tapes on devices. (#2117)
Fixes a bug for the TensorFlow interface where the dtype of input tensors was not cast. (#2120)
Fixes a bug where batch transformed QNodes would fail to apply batch transforms provided by the underlying device. (#2111)
An error is now raised during QNode creation if backpropagation is requested on a device with finite shots specified. (#2114)
Pytest now ignores any
DeprecationWarningraised within autograd’snumpy_wrappermodule. Other assorted minor test warnings are fixed. (#2007)Fixes a bug where the QNode was not correctly diagonalizing qubit-wise commuting observables. (#2097)
Fixes a bug in
gradient_transformwhere the hybrid differentiation of circuits with a single parametrized gate failed and QNode argument axes of size1where removed from the output gradient. (#2080)The available
diff_methodoptions for QNodes has been corrected in both the error messages and the documentation. (#2078)Fixes a bug in
DefaultQubitwhere the second derivative of QNodes at positions corresponding to vanishing state vector amplitudes is wrong. (#2057)Fixes a bug where PennyLane didn’t require v0.20.0 of PennyLane-Lightning, but raised an error with versions of Lightning earlier than v0.20.0 due to the new batch execution pipeline. (#2033)
Fixes a bug in
classical_jacobianwhen used with Torch, where the Jacobian of the preprocessing was also computed for non-trainable parameters. (#2020)Fixes a bug in queueing of the
two_qubit_decompositionmethod that originally led to circuits with >3 two-qubit unitaries failing when passed through theunitary_to_rotoptimization transform. (#2015)Fixes a bug which allows using
jax.jitto be compatible with circuits which returnqml.probswhen thedefault.qubit.jaxis provided with a custom shot vector. (#2028)Updated the
adjoint()method for non-parametric qubit operations to solve a bug where repeatedadjoint()calls don’t return the correct operator. (#2133)Fixed a bug in
insert()which prevented operations that inherited from multiple classes to be inserted. (#2172)
Documentation
Fixes an error in the signs of equations in the
DoubleExcitationpage. (#2072)Extends the interfaces description page to explicitly mention device compatibility. (#2031)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Sam Banning, Thomas Bromley, Esther Cruz, Olivia Di Matteo, Christian Gogolin, Diego Guala, Anthony Hayes, David Ittah, Josh Izaac, Soran Jahangiri, Edward Jiang, Ankit Khandelwal, Nathan Killoran, Korbinian Kottmann, Christina Lee, Romain Moyard, Lee James O’Riordan, Maria Schuld, Jay Soni, Antal Száva, David Wierichs, Shaoming Zhang.
Release 0.20.0¶
New features since last release
Shiny new circuit drawer!🎨🖌️
PennyLane now supports drawing a QNode with matplotlib! (#1803) (#1811) (#1931) (#1954)
dev = qml.device("default.qubit", wires=4) @qml.qnode(dev) def circuit(x, z): qml.QFT(wires=(0,1,2,3)) qml.Toffoli(wires=(0,1,2)) qml.CSWAP(wires=(0,2,3)) qml.RX(x, wires=0) qml.CRZ(z, wires=(3,0)) return qml.expval(qml.PauliZ(0)) fig, ax = qml.draw_mpl(circuit)(1.2345, 1.2345) fig.show()

New and improved quantum-aware optimizers
Added
qml.LieAlgebraOptimizer, a new quantum-aware Lie Algebra optimizer that allows one to perform gradient descent on the special unitary group. (#1911)dev = qml.device("default.qubit", wires=2) H = -1.0 * qml.PauliX(0) - qml.PauliZ(1) - qml.PauliY(0) @ qml.PauliX(1) @qml.qnode(dev) def circuit(): qml.RX(0.1, wires=[0]) qml.RY(0.5, wires=[1]) qml.CNOT(wires=[0,1]) qml.RY(0.6, wires=[0]) return qml.expval(H) opt = qml.LieAlgebraOptimizer(circuit=circuit, stepsize=0.1)
Note that, unlike other optimizers, the
LieAlgebraOptimizeraccepts a QNode with no parameters, and instead grows the circuit by appending operations during the optimization:>>> circuit() tensor(-1.3351865, requires_grad=True) >>> circuit1, cost = opt.step_and_cost() >>> circuit1() tensor(-1.99378872, requires_grad=True)
For more details, see the LieAlgebraOptimizer documentation.
The
qml.metric_tensortransform can now be used to compute the full tensor, beyond the block diagonal approximation. (#1725)This is performed using Hadamard tests, and requires an additional wire on the device to execute the circuits produced by the transform, as compared to the number of wires required by the original circuit. The transform defaults to computing the full tensor, which can be controlled by the
approxkeyword argument.As an example, consider the QNode
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circuit(weights): qml.RX(weights[0], wires=0) qml.RY(weights[1], wires=0) qml.CNOT(wires=[0, 1]) qml.RZ(weights[2], wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) weights = np.array([0.2, 1.2, -0.9], requires_grad=True)
Then we can compute the (block) diagonal metric tensor as before, now using the
approx="block-diag"keyword:>>> qml.metric_tensor(circuit, approx="block-diag")(weights) [[0.25 0. 0. ] [0. 0.24013262 0. ] [0. 0. 0.21846983]]
Instead, we now can also compute the full metric tensor, using Hadamard tests on the additional wire of the device:
>>> qml.metric_tensor(circuit)(weights) [[ 0.25 0. -0.23300977] [ 0. 0.24013262 0.01763859] [-0.23300977 0.01763859 0.21846983]]
See the metric tensor documentation. for more information and usage details.
Faster performance with optimized quantum workflows
The QNode has been re-written to support batch execution across the board, custom gradients, better decomposition strategies, and higher-order derivatives. (#1807) (#1969)
Internally, if multiple circuits are generated for simultaneous execution, they will be packaged into a single job for execution on the device. This can lead to significant performance improvement when executing the QNode on remote quantum hardware or simulator devices with parallelization capabilities.
Custom gradient transforms can be specified as the differentiation method:
@qml.gradients.gradient_transform def my_gradient_transform(tape): ... return tapes, processing_fn @qml.qnode(dev, diff_method=my_gradient_transform) def circuit():
For breaking changes related to the use of the new QNode, refer to the Breaking Changes section.
Note that the old QNode remains accessible at
@qml.qnode_old.qnode, however this will be removed in the next release.Custom decompositions can now be applied to operations at the device level. (#1900)
For example, suppose we would like to implement the following QNode:
def circuit(weights): qml.BasicEntanglerLayers(weights, wires=[0, 1, 2]) return qml.expval(qml.PauliZ(0)) original_dev = qml.device("default.qubit", wires=3) original_qnode = qml.QNode(circuit, original_dev)
>>> weights = np.array([[0.4, 0.5, 0.6]]) >>> print(qml.draw(original_qnode, expansion_strategy="device")(weights)) 0: ──RX(0.4)──╭C──────╭X──┤ ⟨Z⟩ 1: ──RX(0.5)──╰X──╭C──│───┤ 2: ──RX(0.6)──────╰X──╰C──┤
Now, let’s swap out the decomposition of the
CNOTgate intoCZandHadamard, and furthermore the decomposition ofHadamardintoRZandRYrather than the decomposition already available in PennyLane. We define the two decompositions like so, and pass them to a device:def custom_cnot(wires): return [ qml.Hadamard(wires=wires[1]), qml.CZ(wires=[wires[0], wires[1]]), qml.Hadamard(wires=wires[1]) ] def custom_hadamard(wires): return [ qml.RZ(np.pi, wires=wires), qml.RY(np.pi / 2, wires=wires) ] # Can pass the operation itself, or a string custom_decomps = {qml.CNOT : custom_cnot, "Hadamard" : custom_hadamard} decomp_dev = qml.device("default.qubit", wires=3, custom_decomps=custom_decomps) decomp_qnode = qml.QNode(circuit, decomp_dev)
Now when we draw or run a QNode on this device, the gates will be expanded according to our specifications:
>>> print(qml.draw(decomp_qnode, expansion_strategy="device")(weights)) 0: ──RX(0.4)──────────────────────╭C──RZ(3.14)──RY(1.57)──────────────────────────╭Z──RZ(3.14)──RY(1.57)──┤ ⟨Z⟩ 1: ──RX(0.5)──RZ(3.14)──RY(1.57)──╰Z──RZ(3.14)──RY(1.57)──╭C──────────────────────│───────────────────────┤ 2: ──RX(0.6)──RZ(3.14)──RY(1.57)──────────────────────────╰Z──RZ(3.14)──RY(1.57)──╰C──────────────────────┤
A separate context manager,
set_decomposition, has also been implemented to enable application of custom decompositions on devices that have already been created.>>> with qml.transforms.set_decomposition(custom_decomps, original_dev): ... print(qml.draw(original_qnode, expansion_strategy="device")(weights)) 0: ──RX(0.4)──────────────────────╭C──RZ(3.14)──RY(1.57)──────────────────────────╭Z──RZ(3.14)──RY(1.57)──┤ ⟨Z⟩ 1: ──RX(0.5)──RZ(3.14)──RY(1.57)──╰Z──RZ(3.14)──RY(1.57)──╭C──────────────────────│───────────────────────┤ 2: ──RX(0.6)──RZ(3.14)──RY(1.57)──────────────────────────╰Z──RZ(3.14)──RY(1.57)──╰C──────────────────────┤
Given an operator of the form \(U=e^{iHt}\), where \(H\) has commuting terms and known eigenvalues,
qml.gradients.generate_shift_rulecomputes the generalized parameter shift rules for determining the gradient of the expectation value \(f(t) = \langle 0|U(t)^\dagger \hat{O} U(t)|0\rangle\) on hardware. (#1788) (#1932)Given
\[H = \sum_i a_i h_i,\]where the eigenvalues of \(H\) are known and all \(h_i\) commute, we can compute the frequencies (the unique positive differences of any two eigenvalues) using
qml.gradients.eigvals_to_frequencies.qml.gradients.generate_shift_rulecan then be used to compute the parameter shift rules to compute \(f'(t)\) using2Rshifted cost function evaluations. This becomes cheaper than the standard application of the chain rule and two-term shift rule whenRis less than the number of Pauli words in the generator.For example, consider the case where \(H\) has eigenspectrum
(-1, 0, 1):>>> frequencies = qml.gradients.eigvals_to_frequencies((-1, 0, 1)) >>> frequencies (1, 2) >>> coeffs, shifts = qml.gradients.generate_shift_rule(frequencies) >>> coeffs array([ 0.85355339, -0.85355339, -0.14644661, 0.14644661]) >>> shifts array([ 0.78539816, -0.78539816, 2.35619449, -2.35619449])
As we can see,
generate_shift_rulereturns four coefficients \(c_i\) and shifts \(s_i\) corresponding to a four term parameter shift rule. The gradient can then be reconstructed via:\[\frac{\partial}{\partial\phi}f = \sum_{i} c_i f(\phi + s_i),\]where \(f(\phi) = \langle 0|U(\phi)^\dagger \hat{O} U(\phi)|0\rangle\) for some observable \(\hat{O}\) and the unitary \(U(\phi)=e^{iH\phi}\).
Support for TensorFlow AutoGraph mode with quantum hardware
It is now possible to use TensorFlow’s AutoGraph mode with QNodes on all devices and with arbitrary differentiation methods. Previously, AutoGraph mode only support
diff_method="backprop". This will result in significantly more performant model execution, at the cost of a more expensive initial compilation. (#1866)Use AutoGraph to convert your QNodes or cost functions into TensorFlow graphs by decorating them with
@tf.function:dev = qml.device("lightning.qubit", wires=2) @qml.qnode(dev, diff_method="adjoint", interface="tf", max_diff=1) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)), qml.expval(qml.PauliZ(0)) @tf.function def cost(x): return tf.reduce_sum(circuit(x)) x = tf.Variable([0.5, 0.7], dtype=tf.float64) with tf.GradientTape() as tape: loss = cost(x) grad = tape.gradient(loss, x)
The initial execution may take slightly longer than when executing the circuit in eager mode; this is because TensorFlow is tracing the function to create the graph. Subsequent executions will be much more performant.
Note that using AutoGraph with backprop-enabled devices, such as
default.qubit, will yield the best performance.For more details, please see the TensorFlow AutoGraph documentation.
Characterize your quantum models with classical QNode reconstruction
The
qml.fourier.reconstructfunction is added. It can be used to reconstruct QNodes outputting expectation values along a specified parameter dimension, with a minimal number of calls to the original QNode. The returned reconstruction is exact and purely classical, and can be evaluated without any quantum executions. (#1864)The reconstruction technique differs for functions with equidistant frequencies that are reconstructed using the function value at equidistant sampling points, and for functions with arbitrary frequencies reconstructed using arbitrary sampling points.
As an example, consider the following QNode:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x, Y, f=1.0): qml.RX(f * x, wires=0) qml.RY(Y[0], wires=0) qml.RY(Y[1], wires=1) qml.CNOT(wires=[0, 1]) qml.RY(3 * Y[1], wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
It has three variational parameters overall: A scalar input
xand an array-valued inputYwith two entries. Additionally, we can tune the dependence onxwith the frequencyf. We then can reconstruct the QNode output function with respect toxvia>>> x = 0.3 >>> Y = np.array([0.1, -0.9]) >>> rec = qml.fourier.reconstruct(circuit, ids="x", nums_frequency={"x": {0: 1}})(x, Y) >>> rec {'x': {0: <function pennylane.fourier.reconstruct._reconstruct_equ.<locals>._reconstruction(x)>}}
As we can see, we get a nested dictionary in the format of the input
nums_frequencywith functions as values. These functions are simple float-to-float callables:>>> univariate = rec["x"][0] >>> univariate(x) -0.880208251507
For more details on usage, reconstruction cost and differentiability support, please see the fourier.reconstruct docstring.
State-of-the-art operations and templates
A circuit template for time evolution under a commuting Hamiltonian utilizing generalized parameter shift rules for cost function gradients is available as
qml.CommutingEvolution. (#1788)If the template is handed a frequency spectrum during its instantiation, then
generate_shift_ruleis internally called to obtain the general parameter shift rules with respect toCommutingEvolution‘s \(t\) parameter, otherwise the shift rule for a decomposition ofCommutingEvolutionwill be used.The template can be initialized within QNode as:
import pennylane as qml n_wires = 2 dev = qml.device('default.qubit', wires=n_wires) coeffs = [1, -1] obs = [qml.PauliX(0) @ qml.PauliY(1), qml.PauliY(0) @ qml.PauliX(1)] hamiltonian = qml.Hamiltonian(coeffs, obs) frequencies = (2,4) @qml.qnode(dev) def circuit(time): qml.PauliX(0) qml.CommutingEvolution(hamiltonian, time, frequencies) return qml.expval(qml.PauliZ(0))
Note that there is no internal validation that 1) the input
qml.Hamiltonianis fully commuting and 2) the eigenvalue frequency spectrum is correct, since these checks become prohibitively expensive for large Hamiltonians.The
qml.Barrier()operator has been added. With it we can separate blocks in compilation or use it as a visual tool. (#1844)Added the identity observable to be an operator. Now we can explicitly call the identity operation on our quantum circuits for both qubit and CV devices. (#1829)
Added the
qml.QubitDensityMatrixinitialization gate for mixed state simulation. (#1850)A thermal relaxation channel is added to the Noisy channels. The channel description can be found on the supplementary information of Quantum classifier with tailored quantum kernels. (#1766)
Added a new
qml.PauliErrorchannel that allows the application of an arbitrary number of Pauli operators on an arbitrary number of wires. (#1781)
Manipulate QNodes to your ❤️s content with new transforms
The
merge_amplitude_embeddingtransformation has been created to automatically merge all gates of this type into one. (#1933)from pennylane.transforms import merge_amplitude_embedding dev = qml.device("default.qubit", wires = 3) @qml.qnode(dev) @merge_amplitude_embedding def qfunc(): qml.AmplitudeEmbedding([0,1,0,0], wires = [0,1]) qml.AmplitudeEmbedding([0,1], wires = 2) return qml.expval(qml.PauliZ(wires = 0))
>>> print(qml.draw(qnode)()) 0: ──╭AmplitudeEmbedding(M0)──┤ ⟨Z⟩ 1: ──├AmplitudeEmbedding(M0)──┤ 2: ──╰AmplitudeEmbedding(M0)──┤ M0 = [0.+0.j 0.+0.j 0.+0.j 1.+0.j 0.+0.j 0.+0.j 0.+0.j 0.+0.j]
The
undo_swapstransformation has been created to automatically remove all swaps of a circuit. (#1960)dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) @qml.transforms.undo_swaps def qfunc(): qml.Hadamard(wires=0) qml.PauliX(wires=1) qml.SWAP(wires=[0,1]) qml.SWAP(wires=[0,2]) qml.PauliY(wires=0) return qml.expval(qml.PauliZ(0))
>>> print(qml.draw(qfunc)()) 0: ──Y──┤ ⟨Z⟩ 1: ──H──┤ 2: ──X──┤
Improvements
Added functions for computing the values of atomic and molecular orbitals at a given position. (#1867)
The functions
atomic_orbitalandmolecular_orbitalcan be used, as shown in the following codeblock, to evaluate the orbitals. By generating values of the orbitals at different positions, one can plot the spatial shape of a desired orbital.symbols = ['H', 'H'] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]], requires_grad = False) mol = hf.Molecule(symbols, geometry) hf.generate_scf(mol)() ao = mol.atomic_orbital(0) mo = mol.molecular_orbital(1)
>>> print(ao(0.0, 0.0, 0.0)) >>> print(mo(0.0, 0.0, 0.0)) 0.6282468778183719 0.018251285973461928
Added support for Python 3.10. (#1964)
The execution of QNodes that have
multiple return types;
a return type other than Variance and Expectation
now raises a descriptive error message when using the JAX interface. (#2011)
The PennyLane
qchempackage is now lazily imported; it will only be imported the first time it is accessed. (#1962)qml.math.scatter_element_addnow supports adding multiple values at multiple indices with a single function call, in all interfaces (#1864)For example, we may set five values of a three-dimensional tensor in the following way:
>>> X = tf.zeros((3, 2, 9), dtype=tf.float64) >>> indices = [(0, 0, 1, 2, 2), (0, 0, 0, 0, 1), (1, 3, 8, 6, 7)] >>> values = [1 * i for i in range(1,6)] >>> qml.math.scatter_element_add(X, indices, values) <tf.Tensor: shape=(3, 2, 9), dtype=float64, numpy= array([[[0., 1., 0., 2., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 3.], [0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 4., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 5., 0.]]])>
All instances of
str.formathave been replace with f-strings. (#1970)Tests do not loop over automatically imported and instantiated operations any more, which was opaque and created unnecessarily many tests. (#1895)
A
decompose()method has been added to theOperatorclass such that we can obtain (and queue) decompositions directly from instances of operations. (#1873)>>> op = qml.PhaseShift(0.3, wires=0) >>> op.decompose() [RZ(0.3, wires=[0])]
qml.circuit_drawer.tape_mplproduces a matplotlib figure and axes given a tape. (#1787)The
AngleEmbedding,BasicEntanglerLayersandMottonenStatePreparationtemplates now support parameters with batch dimension when using the@qml.batch_paramsdecorator. (#1812) (#1883) (#1893)qml.drawnow supports amax_lengthargument to help prevent text overflows when printing circuits. (#1892)Identityoperation is now part of both theops.qubitandops.cvmodules. (#1956)
Breaking changes
The QNode has been re-written to support batch execution across the board, custom gradients, better decomposition strategies, and higher-order derivatives. (#1807) (#1969)
Arbitrary \(n\)-th order derivatives are supported on hardware using gradient transforms such as the parameter-shift rule. To specify that an \(n\)-th order derivative of a QNode will be computed, the
max_diffargument should be set. By default, this is set to 1 (first-order derivatives only). Increasing this value allows for higher order derivatives to be extracted, at the cost of additional (classical) computational overhead during the backwards pass.When decomposing the circuit, the default decomposition strategy
expansion_strategy="gradient"will prioritize decompositions that result in the smallest number of parametrized operations required to satisfy the differentiation method. While this may lead to a slight increase in classical processing, it significantly reduces the number of circuit evaluations needed to compute gradients of complicated unitaries.To return to the old behaviour,
expansion_strategy="device"can be specified.
Note that the old QNode remains accessible at
@qml.qnode_old.qnode, however this will be removed in the next release.Certain features deprecated in
v0.19.0have been removed: (#1981) (#1963)The
qml.templatedecorator (use a ` QuantumTape <https://pennylane.readthedocs.io/en/stable/code/api/pennylane.tape.QuantumTape.html>`_ as a context manager to record operations and itsoperationsattribute to return them, see the linked page for examples);The
default.tensoranddefault.tensor.tfexperimental devices;The
qml.fourier.spectrumfunction (use theqml.fourier.circuit_spectrumorqml.fourier.qnode_spectrumfunctions instead);The
diag_approxkeyword argument ofqml.metric_tensorandqml.QNGOptimizer(passapprox='diag'instead).
The default behaviour of the
qml.metric_tensortransform has been modified. By default, the full metric tensor is computed, leading to higher cost than the previous default of computing the block diagonal only. At the same time, the Hadamard tests for the full metric tensor require an additional wire on the device, so that>>> qml.metric_tensor(some_qnode)(weights)
will revert back to the block diagonal restriction and raise a warning if the used device does not have an additional wire. (#1725)
The
circuit_drawermodule has been renameddrawer. (#1949)The
par_domainattribute in the operator class has been removed. (#1907)The
mutablekeyword argument has been removed from the QNode, due to underlying bugs that result in incorrect results being returned from immutable QNodes. This functionality will return in an upcoming release. (#1807)The reversible QNode differentiation method has been removed; the adjoint differentiation method is preferred instead (
diff_method='adjoint'). (#1807)QuantumTape.trainable_paramsnow is a list instead of a set. This means thattape.trainable_paramswill return a list unlike before, but setting thetrainable_paramswith a set works exactly as before. (#1904)The
num_paramsattribute in the operator class is now dynamic. This makes it easier to define operator subclasses with a flexible number of parameters. (#1898) (#1909)The static method
decomposition(), formerly in theOperationclass, has been moved to the baseOperatorclass. (#1873)DiagonalOperationis not a separate subclass any more. (#1889)Instead, devices can check for the diagonal property using attributes:
from pennylane.ops.qubit.attributes import diagonal_in_z_basis if op in diagonal_in_z_basis: # do something
Custom operations can be added to this attribute at runtime via
diagonal_in_z_basis.add("MyCustomOp").
Bug fixes
Fixes a bug with
qml.probswhen usingdefault.qubit.jax. (#1998)Fixes a bug where output tensors of a QNode would always be put on the default GPU with
default.qubit.torch. (#1982)Device test suite doesn’t use empty circuits so that it can also test the IonQ plugin, and it checks if operations are supported in more places. (#1979)
Fixes a bug where the metric tensor was computed incorrectly when using gates with
gate.inverse=True. (#1987)Corrects the documentation of
qml.transforms.classical_jacobianfor the Autograd interface (and improves test coverage). (#1978)Fixes a bug where differentiating a QNode with
qml.stateusing the JAX interface raised an error. (#1906)Fixes a bug with the adjoint of
qml.QFT. (#1955)Fixes a bug where the
ApproxTimeEvolutiontemplate was not correctly computing the operation wires from the input Hamiltonian. This did not affect computation with theApproxTimeEvolutiontemplate, but did cause circuit drawing to fail. (#1952)Fixes a bug where the classical preprocessing Jacobian computed by
qml.transforms.classical_jacobianwith JAX returned a reduced submatrix of the Jacobian. (#1948)Fixes a bug where the operations are not accessed in the correct order in
qml.fourier.qnode_spectrum, leading to wrong outputs. (#1935)Fixes several Pylint errors. (#1951)
Fixes a bug where the device test suite wasn’t testing certain operations. (#1943)
Fixes a bug where batch transforms would mutate a QNodes execution options. (#1934)
qml.drawnow supports arbitrary templates with matrix parameters. (#1917)QuantumTape.trainable_paramsnow is a list instead of a set, making it more stable in very rare edge cases. (#1904)ExpvalCostnow returns corrects results shape whenoptimize=Truewith shots batch. (#1897)qml.circuit_drawer.MPLDrawerwas slightly modified to work with matplotlib version 3.5. (#1899)qml.CSWAPandqml.CRotnow definecontrol_wires, andqml.SWAPreturns the default empty wires object. (#1830)The
requires_gradattribute ofqml.numpy.tensorobjects is now preserved when pickling/unpickling the object. (#1856)Device tests no longer throw warnings about the
requires_gradattribute of variational parameters. (#1913)AdamOptimizerandAdagradOptimizerhad small fixes to their optimization step updates. (#1929)Fixes a bug where differentiating a QNode with multiple array arguments via
qml.gradients.param_shiftthrows an error. (#1989)AmplitudeEmbeddingtemplate no longer produces aComplexWarningwhen thefeaturesparameter is batched and provided as a 2D array. (#1990)qml.circuit_drawer.CircuitDrawerno longer produces an error when attempting to draw tapes inside of circuits (e.g. from decomposition of an operation or manual placement). (#1994)Fixes a bug where using SciPy sparse matrices with the new QNode could lead to a warning being raised about prioritizing the TensorFlow and PyTorch interfaces. (#2001)
Fixed a bug where the
QueueContextwas not empty when first importing PennyLane. (#1957)Fixed circuit drawing problem with
InterferometerandCVNeuralNet. (#1953)
Documentation
Added examples in documentation for some operations. (#1902)
Improves the Developer’s Guide Testing document. (#1896)
Added documentation examples for
AngleEmbedding,BasisEmbedding,StronglyEntanglingLayers,SqueezingEmbedding,DisplacementEmbedding,MottonenStatePreparationandInterferometer. (#1910) (#1908) (#1912) (#1920) (#1936) (#1937)
Contributors
This release contains contributions from (in alphabetical order):
Catalina Albornoz, Guillermo Alonso-Linaje, Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Samuel Banning, Benjamin Cordier, Alain Delgado, Olivia Di Matteo, Anthony Hayes, David Ittah, Josh Izaac, Soran Jahangiri, Jalani Kanem, Ankit Khandelwal, Nathan Killoran, Shumpei Kobayashi, Robert Lang, Christina Lee, Cedric Lin, Alejandro Montanez, Romain Moyard, Lee James O’Riordan, Chae-Yeun Park, Isidor Schoch, Maria Schuld, Jay Soni, Antal Száva, Rodrigo Vargas, David Wierichs, Roeland Wiersema, Moritz Willmann.
Release 0.19.1¶
Bug fixes
Fixes several bugs when using parametric operations with the
default.qubit.tensordevice on GPU. The device takes thetorch_deviceargument once again to allow running non-parametric QNodes on the GPU. (#1927)Fixes a bug where using JAX’s jit function on certain QNodes that contain the
qml.QubitStateVectoroperation raised an error with earlier JAX versions (e.g.,jax==0.2.10andjaxlib==0.1.64). (#1924)
Contributors
This release contains contributions from (in alphabetical order):
Josh Izaac, Christina Lee, Romain Moyard, Lee James O’Riordan, Antal Száva.
Release 0.19.0¶
New features since last release
Differentiable Hartree-Fock solver
A differentiable Hartree-Fock (HF) solver has been added. It can be used to construct molecular Hamiltonians that can be differentiated with respect to nuclear coordinates and basis-set parameters. (#1610)
The HF solver computes the integrals over basis functions, constructs the relevant matrices, and performs self-consistent-field iterations to obtain a set of optimized molecular orbital coefficients. These coefficients and the computed integrals over basis functions are used to construct the one- and two-body electron integrals in the molecular orbital basis which can be used to generate a differentiable second-quantized Hamiltonian in the fermionic and qubit basis.
The following code shows the construction of the Hamiltonian for the hydrogen molecule where the geometry of the molecule is differentiable.
symbols = ["H", "H"] geometry = np.array([[0.0000000000, 0.0000000000, -0.6943528941], [0.0000000000, 0.0000000000, 0.6943528941]], requires_grad=True) mol = qml.hf.Molecule(symbols, geometry) args_mol = [geometry] hamiltonian = qml.hf.generate_hamiltonian(mol)(*args_mol)
>>> hamiltonian.coeffs tensor([-0.09041082+0.j, 0.17220382+0.j, 0.17220382+0.j, 0.16893367+0.j, 0.04523101+0.j, -0.04523101+0.j, -0.04523101+0.j, 0.04523101+0.j, -0.22581352+0.j, 0.12092003+0.j, -0.22581352+0.j, 0.16615103+0.j, 0.16615103+0.j, 0.12092003+0.j, 0.17464937+0.j], requires_grad=True)
The generated Hamiltonian can be used in a circuit where the atomic coordinates and circuit parameters are optimized simultaneously.
symbols = ["H", "H"] geometry = np.array([[0.0000000000, 0.0000000000, 0.0], [0.0000000000, 0.0000000000, 2.0]], requires_grad=True) mol = qml.hf.Molecule(symbols, geometry) dev = qml.device("default.qubit", wires=4) params = [np.array([0.0], requires_grad=True)] def generate_circuit(mol): @qml.qnode(dev) def circuit(*args): qml.BasisState(np.array([1, 1, 0, 0]), wires=[0, 1, 2, 3]) qml.DoubleExcitation(*args[0][0], wires=[0, 1, 2, 3]) return qml.expval(qml.hf.generate_hamiltonian(mol)(*args[1:])) return circuit for n in range(25): mol = qml.hf.Molecule(symbols, geometry) args = [params, geometry] # initial values of the differentiable parameters g_params = qml.grad(generate_circuit(mol), argnum = 0)(*args) params = params - 0.5 * g_params[0] forces = qml.grad(generate_circuit(mol), argnum = 1)(*args) geometry = geometry - 0.5 * forces print(f'Step: {n}, Energy: {generate_circuit(mol)(*args)}, Maximum Force: {forces.max()}')
In addition, the new Hartree-Fock solver can further be used to optimize the basis set parameters. For details, please refer to the differentiable Hartree-Fock solver documentation.
Integration with Mitiq
Error mitigation using the zero-noise extrapolation method is now available through the
transforms.mitigate_with_znetransform. This transform can integrate with the Mitiq package for unitary folding and extrapolation functionality. (#1813)Consider the following noisy device:
noise_strength = 0.05 dev = qml.device("default.mixed", wires=2) dev = qml.transforms.insert(qml.AmplitudeDamping, noise_strength)(dev)
We can mitigate the effects of this noise for circuits run on this device by using the added transform:
from mitiq.zne.scaling import fold_global from mitiq.zne.inference import RichardsonFactory n_wires = 2 n_layers = 2 shapes = qml.SimplifiedTwoDesign.shape(n_wires, n_layers) np.random.seed(0) w1, w2 = [np.random.random(s) for s in shapes] @qml.transforms.mitigate_with_zne([1, 2, 3], fold_global, RichardsonFactory.extrapolate) @qml.beta.qnode(dev) def circuit(w1, w2): qml.SimplifiedTwoDesign(w1, w2, wires=range(2)) return qml.expval(qml.PauliZ(0))
Now, when we execute
circuit, errors will be automatically mitigated:>>> circuit(w1, w2) 0.19113067083636542
Powerful new transforms
The unitary matrix corresponding to a quantum circuit can now be generated using the new
get_unitary_matrix()transform. (#1609) (#1786)This transform is fully differentiable across all supported PennyLane autodiff frameworks.
def circuit(theta): qml.RX(theta, wires=1) qml.PauliZ(wires=0) qml.CNOT(wires=[0, 1])
>>> theta = torch.tensor(0.3, requires_grad=True) >>> matrix = qml.transforms.get_unitary_matrix(circuit)(theta) >>> print(matrix) tensor([[ 0.9888+0.0000j, 0.0000+0.0000j, 0.0000-0.1494j, 0.0000+0.0000j], [ 0.0000+0.0000j, 0.0000+0.1494j, 0.0000+0.0000j, -0.9888+0.0000j], [ 0.0000-0.1494j, 0.0000+0.0000j, 0.9888+0.0000j, 0.0000+0.0000j], [ 0.0000+0.0000j, -0.9888+0.0000j, 0.0000+0.0000j, 0.0000+0.1494j]], grad_fn=<MmBackward>) >>> loss = torch.real(torch.trace(matrix)) >>> loss.backward() >>> theta.grad tensor(-0.1494)
Arbitrary two-qubit unitaries can now be decomposed into elementary gates. This functionality has been incorporated into the
qml.transforms.unitary_to_rottransform, and is available separately asqml.transforms.two_qubit_decomposition. (#1552)As an example, consider the following randomly-generated matrix and circuit that uses it:
U = np.array([ [-0.03053706-0.03662692j, 0.01313778+0.38162226j, 0.4101526 -0.81893687j, -0.03864617+0.10743148j], [-0.17171136-0.24851809j, 0.06046239+0.1929145j, -0.04813084-0.01748555j, -0.29544883-0.88202604j], [ 0.39634931-0.78959795j, -0.25521689-0.17045233j, -0.1391033 -0.09670952j, -0.25043606+0.18393466j], [ 0.29599198-0.19573188j, 0.55605806+0.64025769j, 0.06140516+0.35499559j, 0.02674726+0.1563311j ] ]) dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) @qml.transforms.unitary_to_rot def circuit(x, y): qml.QubitUnitary(U, wires=[0, 1]) return qml.expval(qml.PauliZ(wires=0))
If we run the circuit, we can see the new decomposition:
>>> circuit(0.3, 0.4) tensor(-0.81295986, requires_grad=True) >>> print(qml.draw(circuit)(0.3, 0.4)) 0: ──Rot(2.78, 0.242, -2.28)──╭X──RZ(0.176)───╭C─────────────╭X──Rot(-3.87, 0.321, -2.09)──┤ ⟨Z⟩ 1: ──Rot(4.64, 2.69, -1.56)───╰C──RY(-0.883)──╰X──RY(-1.47)──╰C──Rot(1.68, 0.337, 0.587)───┤
A new transform,
@qml.batch_params, has been added, that makes QNodes handle a batch dimension in trainable parameters. (#1710) (#1761)This transform will create multiple circuits, one per batch dimension. As a result, it is both simulator and hardware compatible.
@qml.batch_params @qml.beta.qnode(dev) def circuit(x, weights): qml.RX(x, wires=0) qml.RY(0.2, wires=1) qml.templates.StronglyEntanglingLayers(weights, wires=[0, 1, 2]) return qml.expval(qml.Hadamard(0))
The
qml.batch_paramsdecorator allows us to pass argumentsxandweightsthat have a batch dimension. For example,>>> batch_size = 3 >>> x = np.linspace(0.1, 0.5, batch_size) >>> weights = np.random.random((batch_size, 10, 3, 3))
If we evaluate the QNode with these inputs, we will get an output of shape
(batch_size,):>>> circuit(x, weights) tensor([0.08569816, 0.12619101, 0.21122004], requires_grad=True)
The
inserttransform has now been added, providing a way to insert single-qubit operations into a quantum circuit. The transform can apply to quantum functions, tapes, and devices. (#1795)The following QNode can be transformed to add noise to the circuit:
dev = qml.device("default.mixed", wires=2) @qml.qnode(dev) @qml.transforms.insert(qml.AmplitudeDamping, 0.2, position="end") def f(w, x, y, z): qml.RX(w, wires=0) qml.RY(x, wires=1) qml.CNOT(wires=[0, 1]) qml.RY(y, wires=0) qml.RX(z, wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
Executions of this circuit will differ from the noise-free value:
>>> f(0.9, 0.4, 0.5, 0.6) tensor(0.754847, requires_grad=True) >>> print(qml.draw(f)(0.9, 0.4, 0.5, 0.6)) 0: ──RX(0.9)──╭C──RY(0.5)──AmplitudeDamping(0.2)──╭┤ ⟨Z ⊗ Z⟩ 1: ──RY(0.4)──╰X──RX(0.6)──AmplitudeDamping(0.2)──╰┤ ⟨Z ⊗ Z⟩
Common tape expansion functions are now available in
qml.transforms, alongside a newcreate_expand_fnfunction for easily creating expansion functions from stopping criteria. (#1734) (#1760)create_expand_fntakes the default depth to which the expansion function should expand a tape, a stopping criterion, an optional device, and a docstring to be set for the created function. The stopping criterion must take a queuable object and return a boolean.For example, to create an expansion function that decomposes all trainable, multi-parameter operations:
>>> stop_at = ~(qml.operation.has_multipar & qml.operation.is_trainable) >>> expand_fn = qml.transforms.create_expand_fn(depth=5, stop_at=stop_at)
The created expansion function can be used within a custom transform. Devices can also be provided, producing expansion functions that decompose tapes to support the native gate set of the device.
Batch execution of circuits
A new, experimental QNode has been added, that adds support for batch execution of circuits, custom quantum gradient support, and arbitrary order derivatives. This QNode is available via
qml.beta.QNode, and@qml.beta.qnode. (#1642) (#1646) (#1651) (#1804)It differs from the standard QNode in several ways:
Custom gradient transforms can be specified as the differentiation method:
@qml.gradients.gradient_transform def my_gradient_transform(tape): ... return tapes, processing_fn @qml.beta.qnode(dev, diff_method=my_gradient_transform) def circuit():
Arbitrary \(n\)-th order derivatives are supported on hardware using gradient transforms such as the parameter-shift rule. To specify that an \(n\)-th order derivative of a QNode will be computed, the
max_diffargument should be set. By default, this is set to 1 (first-order derivatives only).Internally, if multiple circuits are generated for execution simultaneously, they will be packaged into a single job for execution on the device. This can lead to significant performance improvement when executing the QNode on remote quantum hardware.
When decomposing the circuit, the default decomposition strategy will prioritize decompositions that result in the smallest number of parametrized operations required to satisfy the differentiation method. Additional decompositions required to satisfy the native gate set of the quantum device will be performed later, by the device at execution time. While this may lead to a slight increase in classical processing, it significantly reduces the number of circuit evaluations needed to compute gradients of complex unitaries.
In an upcoming release, this QNode will replace the existing one. If you come across any bugs while using this QNode, please let us know via a bug report on our GitHub bug tracker.
Currently, this beta QNode does not support the following features:
Non-mutability via the
mutablekeyword argumentThe
reversibleQNode differentiation methodThe ability to specify a
dtypewhen using PyTorch and TensorFlow.
It is also not tested with the
qml.qnnmodule.
New operations and templates
Added a new operation
OrbitalRotation, which implements the spin-adapted spatial orbital rotation gate. (#1665)An example circuit that uses
OrbitalRotationoperation is:dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) def circuit(phi): qml.BasisState(np.array([1, 1, 0, 0]), wires=[0, 1, 2, 3]) qml.OrbitalRotation(phi, wires=[0, 1, 2, 3]) return qml.state()
If we run this circuit, we will get the following output
>>> circuit(0.1) array([ 0. +0.j, 0. +0.j, 0. +0.j, 0.00249792+0.j, 0. +0.j, 0. +0.j, -0.04991671+0.j, 0. +0.j, 0. +0.j, -0.04991671+0.j, 0. +0.j, 0. +0.j, 0.99750208+0.j, 0. +0.j, 0. +0.j, 0. +0.j])
Added a new template
GateFabric, which implements a local, expressive, quantum-number-preserving ansatz proposed by Anselmetti et al. in arXiv:2104.05692. (#1687)An example of a circuit using
GateFabrictemplate is:coordinates = np.array([0.0, 0.0, -0.6614, 0.0, 0.0, 0.6614]) H, qubits = qml.qchem.molecular_hamiltonian(["H", "H"], coordinates) ref_state = qml.qchem.hf_state(electrons=2, orbitals=qubits) dev = qml.device('default.qubit', wires=qubits) @qml.qnode(dev) def ansatz(weights): qml.templates.GateFabric(weights, wires=[0,1,2,3], init_state=ref_state, include_pi=True) return qml.expval(H)
For more details, see the GateFabric documentation.
Added a new template
kUpCCGSD, which implements a unitary coupled cluster ansatz with generalized singles and pair doubles excitation operators, proposed by Joonho Lee et al. in arXiv:1810.02327. (#1743)An example of a circuit using
kUpCCGSDtemplate is:coordinates = np.array([0.0, 0.0, -0.6614, 0.0, 0.0, 0.6614]) H, qubits = qml.qchem.molecular_hamiltonian(["H", "H"], coordinates) ref_state = qml.qchem.hf_state(electrons=2, orbitals=qubits) dev = qml.device('default.qubit', wires=qubits) @qml.qnode(dev) def ansatz(weights): qml.templates.kUpCCGSD(weights, wires=[0,1,2,3], k=0, delta_sz=0, init_state=ref_state) return qml.expval(H)
Improved utilities for quantum compilation and characterization
The new
qml.fourier.qnode_spectrumfunction extends the formerqml.fourier.spectrumfunction and takes classical processing of QNode arguments into account. The frequencies are computed per (requested) QNode argument instead of per gateid. The gateids are ignored. (#1681) (#1720)Consider the following example, which uses non-trainable inputs
x,yandzas well as trainable parameterswas arguments to the QNode.import pennylane as qml import numpy as np n_qubits = 3 dev = qml.device("default.qubit", wires=n_qubits) @qml.qnode(dev) def circuit(x, y, z, w): for i in range(n_qubits): qml.RX(0.5*x[i], wires=i) qml.Rot(w[0,i,0], w[0,i,1], w[0,i,2], wires=i) qml.RY(2.3*y[i], wires=i) qml.Rot(w[1,i,0], w[1,i,1], w[1,i,2], wires=i) qml.RX(z, wires=i) return qml.expval(qml.PauliZ(wires=0)) x = np.array([1., 2., 3.]) y = np.array([0.1, 0.3, 0.5]) z = -1.8 w = np.random.random((2, n_qubits, 3))
This circuit looks as follows:
>>> print(qml.draw(circuit)(x, y, z, w)) 0: ──RX(0.5)──Rot(0.598, 0.949, 0.346)───RY(0.23)──Rot(0.693, 0.0738, 0.246)──RX(-1.8)──┤ ⟨Z⟩ 1: ──RX(1)────Rot(0.0711, 0.701, 0.445)──RY(0.69)──Rot(0.32, 0.0482, 0.437)───RX(-1.8)──┤ 2: ──RX(1.5)──Rot(0.401, 0.0795, 0.731)──RY(1.15)──Rot(0.756, 0.38, 0.38)─────RX(-1.8)──┤
Applying the
qml.fourier.qnode_spectrumfunction to the circuit for the non-trainable parameters, we obtain:>>> spec = qml.fourier.qnode_spectrum(circuit, encoding_args={"x", "y", "z"})(x, y, z, w) >>> for inp, freqs in spec.items(): ... print(f"{inp}: {freqs}") "x": {(0,): [-0.5, 0.0, 0.5], (1,): [-0.5, 0.0, 0.5], (2,): [-0.5, 0.0, 0.5]} "y": {(0,): [-2.3, 0.0, 2.3], (1,): [-2.3, 0.0, 2.3], (2,): [-2.3, 0.0, 2.3]} "z": {(): [-3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0]}
We can see that all three parameters in the QNode arguments
xandycontribute the spectrum of a Pauli rotation[-1.0, 0.0, 1.0], rescaled with the prefactor of the respective parameter in the circuit. The threeRXrotations using the parameterzaccumulate, yielding a more complex frequency spectrum.For details on how to control for which parameters the spectrum is computed, a comparison to
qml.fourier.circuit_spectrum, and other usage details, please see the fourier.qnode_spectrum docstring.Two new methods were added to the Device API, allowing PennyLane devices increased control over circuit decompositions. (#1651)
Device.expand_fn(tape) -> tape: expands a tape such that it is supported by the device. By default, performs the standard device-specific gate set decomposition done in the default QNode. Devices may overwrite this method in order to define their own decomposition logic.Note that the numerical result after applying this method should remain unchanged; PennyLane will assume that the expanded tape returns exactly the same value as the original tape when executed.
Device.batch_transform(tape) -> (tapes, processing_fn): preprocesses the tape in the case where the device needs to generate multiple circuits to execute from the input circuit. The requirement of a post-processing function makes this distinct to theexpand_fnmethod above.By default, this method applies the transform
\[\left\langle \sum_i c_i h_i\right\rangle → \sum_i c_i \left\langle h_i \right\rangle\]if
expval(H)is present on devices that do not natively support Hamiltonians with non-commuting terms.
A new class has been added to store operator attributes, such as
self_inverses, andcomposable_rotation, as a list of operation names. (#1763)A number of such attributes, for the purpose of compilation transforms, can be found in
ops/qubit/attributes.py, but the class can also be used to create your own. For example, we can create a new Attribute,pauli_ops, like so:>>> from pennylane.ops.qubit.attributes import Attribute >>> pauli_ops = Attribute(["PauliX", "PauliY", "PauliZ"])
We can check either a string or an Operation for inclusion in this set:
>>> qml.PauliX(0) in pauli_ops True >>> "Hadamard" in pauli_ops False
We can also dynamically add operators to the sets at runtime. This is useful for adding custom operations to the attributes such as
composable_rotationsandself_inversesthat are used in compilation transforms. For example, suppose you have created a new Operation,MyGate, which you know to be its own inverse. Adding it to the set, like so>>> from pennylane.ops.qubit.attributes import self_inverses >>> self_inverses.add("MyGate")
will enable the gate to be considered by the
cancel_inversescompilation transform if two such gates are adjacent in a circuit.
Improvements
The
qml.metric_tensortransform has been improved with regards to both function and performance. (#1638) (#1721)If the underlying device supports batch execution of circuits, the quantum circuits required to compute the metric tensor elements will be automatically submitted as a batched job. This can lead to significant performance improvements for devices with a non-trivial job submission overhead.
Previously, the transform would only return the metric tensor with respect to gate arguments, and ignore any classical processing inside the QNode, even very trivial classical processing such as parameter permutation. The metric tensor now takes into account classical processing, and returns the metric tensor with respect to QNode arguments, not simply gate arguments:
>>> @qml.qnode(dev) ... def circuit(x): ... qml.Hadamard(wires=1) ... qml.RX(x[0], wires=0) ... qml.CNOT(wires=[0, 1]) ... qml.RY(x[1] ** 2, wires=1) ... qml.RY(x[1], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> x = np.array([0.1, 0.2], requires_grad=True) >>> qml.metric_tensor(circuit)(x) array([[0.25 , 0. ], [0. , 0.28750832]])
To revert to the previous behaviour of returning the metric tensor with respect to gate arguments,
qml.metric_tensor(qnode, hybrid=False)can be passed.>>> qml.metric_tensor(circuit, hybrid=False)(x) array([[0.25 , 0. , 0. ], [0. , 0.25 , 0. ], [0. , 0. , 0.24750832]])
The metric tensor transform now works with a larger set of operations. In particular, all operations that have a single variational parameter and define a generator are now supported. In addition to a reduction in decomposition overhead, the change also results in fewer circuit evaluations.
The expansion rule in the
qml.metric_tensortransform has been changed. (#1721)If
hybrid=False, the changed expansion rule might lead to a changed output.The
ApproxTimeEvolutiontemplate can now be used with Hamiltonians that have trainable coefficients. (#1789)Resulting QNodes can be differentiated with respect to both the time parameter and the Hamiltonian coefficients.
dev = qml.device('default.qubit', wires=2) obs = [qml.PauliX(0) @ qml.PauliY(1), qml.PauliY(0) @ qml.PauliX(1)] @qml.qnode(dev) def circuit(coeffs, t): H = qml.Hamiltonian(coeffs, obs) qml.templates.ApproxTimeEvolution(H, t, 2) return qml.expval(qml.PauliZ(0))
>>> t = np.array(0.54, requires_grad=True) >>> coeffs = np.array([-0.6, 2.0], requires_grad=True) >>> qml.grad(circuit)(coeffs, t) (array([-1.07813375, -1.07813375]), array(-2.79516158))
All differentiation methods, including backpropagation and the parameter-shift rule, are supported.
Quantum function transforms and batch transforms can now be applied to devices. Once applied to a device, any quantum function executed on the modified device will be transformed prior to execution. (#1809) (#1810)
dev = qml.device("default.mixed", wires=1) dev = qml.transforms.merge_rotations()(dev) @qml.beta.qnode(dev) def f(w, x, y, z): qml.RX(w, wires=0) qml.RX(x, wires=0) qml.RX(y, wires=0) qml.RX(z, wires=0) return qml.expval(qml.PauliZ(0))
>>> print(f(0.9, 0.4, 0.5, 0.6)) -0.7373937155412453 >>> print(qml.draw(f, expansion_strategy="device")(0.9, 0.4, 0.5, 0.6)) 0: ──RX(2.4)──┤ ⟨Z⟩
It is now possible to draw QNodes that have been transformed by a ‘batch transform’; that is, a transform that maps a single QNode into multiple circuits under the hood. Examples of batch transforms include
@qml.metric_tensorand@qml.gradients. (#1762)For example, consider the parameter-shift rule, which generates two circuits per parameter; one circuit that has the parameter shifted forward, and another that has the parameter shifted backwards:
dev = qml.device("default.qubit", wires=2) @qml.gradients.param_shift @qml.beta.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(wires=0))
>>> print(qml.draw(circuit)(0.6)) 0: ──RX(2.17)──╭C──┤ ⟨Z⟩ 1: ────────────╰X──┤ 0: ──RX(-0.971)──╭C──┤ ⟨Z⟩ 1: ──────────────╰X──┤
Support for differentiable execution of batches of circuits has been extended to the JAX interface for scalar functions, via the beta
pennylane.interfaces.batchmodule. (#1634) (#1685)For example using the
executefunction from thepennylane.interfaces.batchmodule:from pennylane.interfaces.batch import execute def cost_fn(x): with qml.tape.JacobianTape() as tape1: qml.RX(x[0], wires=[0]) qml.RY(x[1], wires=[1]) qml.CNOT(wires=[0, 1]) qml.var(qml.PauliZ(0) @ qml.PauliX(1)) with qml.tape.JacobianTape() as tape2: qml.RX(x[0], wires=0) qml.RY(x[0], wires=1) qml.CNOT(wires=[0, 1]) qml.probs(wires=1) result = execute( [tape1, tape2], dev, gradient_fn=qml.gradients.param_shift, interface="autograd" ) return (result[0] + result[1][0, 0])[0] res = jax.grad(cost_fn)(params)
All qubit operations have been re-written to use the
qml.mathframework for internal classical processing and the generation of their matrix representations. As a result these representations are now fully differentiable, and the framework-specific device classes no longer need to maintain framework-specific versions of these matrices. (#1749) (#1802)The use of
expval(H), whereHis a cost Hamiltonian generated by theqaoamodule, has been sped up. This was achieved by making PennyLane decompose a circuit with anexpval(H)measurement into subcircuits if theHamiltonian.grouping_indicesattribute is set, and setting this attribute in the relevantqaoamodule functions. (#1718)Operations can now have gradient recipes that depend on the state of the operation. (#1674)
For example, this allows for gradient recipes that are parameter dependent:
class RX(qml.RX): @property def grad_recipe(self): # The gradient is given by [f(2x) - f(0)] / (2 sin(x)), by subsituting # shift = x into the two term parameter-shift rule. x = self.data[0] c = 0.5 / np.sin(x) return ([[c, 0.0, 2 * x], [-c, 0.0, 0.0]],)
Shots can now be passed as a runtime argument to transforms that execute circuits in batches, similarly to QNodes. (#1707)
An example of such a transform are the gradient transforms in the
qml.gradientsmodule. As a result, we can now call gradient transforms (such asqml.gradients.param_shift) and set the number of shots at runtime.>>> dev = qml.device("default.qubit", wires=1, shots=1000) >>> @qml.beta.qnode(dev) ... def circuit(x): ... qml.RX(x, wires=0) ... return qml.expval(qml.PauliZ(0)) >>> grad_fn = qml.gradients.param_shift(circuit) >>> param = np.array(0.564, requires_grad=True) >>> grad_fn(param, shots=[(1, 10)]).T array([[-1., -1., -1., -1., -1., 0., -1., 0., -1., 0.]]) >>> param2 = np.array(0.1233, requires_grad=True) >>> grad_fn(param2, shots=None) array([[-0.12298782]])
Templates are now top level imported and can be used directly e.g.
qml.QFT(wires=0). (#1779)qml.probsnow accepts an attributeopthat allows to rotate the computational basis and get the probabilities in the rotated basis. (#1692)Refactored the
expand_fnfunctionality in the Device class to avoid any edge cases leading to failures with plugins. (#1838)Updated the
qml.QNGOptimizer.step_and_costmethod to avoid the use of deprecated functionality. (#1834)Added a custom
torch.to_numpyimplementation topennylane/math/single_dispatch.pyto ensure compabilitity with PyTorch 1.10. (#1824) (#1825)The default for an
Operation‘scontrol_wiresattribute is now an emptyWiresobject instead of the attribute raising aNonImplementedError. (#1821)qml.circuit_drawer.MPLDrawerwill now automatically rotate and resize text to fit inside the rectangle created by thebox_gatemethod. (#1764)Operators now have a
labelmethod to determine how they are drawn. This will eventually override theRepresentationResolverclass. (#1678)The operation
labelmethod now supports string variables. (#1815)A new utility class
qml.BooleanFnis introduced. It wraps a function that takes a single argument and returns a Boolean. (#1734)After wrapping,
qml.BooleanFncan be called like the wrapped function, and multiple instances can be manipulated and combined with the bitwise operators&,|and~.There is a new utility function
qml.math.is_independentthat checks whether a callable is independent of its arguments. (#1700)This function is experimental and might behave differently than expected.
Note that the test relies on both numerical and analytical checks, except when using the PyTorch interface which only performs a numerical check. It is known that there are edge cases on which this test will yield wrong results, in particular non-smooth functions may be problematic. For details, please refer to the is_indpendent docstring.
The
qml.beta.QNodenow supports theqml.qnnmodule. (#1748)@qml.beta.QNodenow supports theqml.specstransform. (#1739)qml.circuit_drawer.drawable_layersandqml.circuit_drawer.drawable_gridprocess a list of operations to layer positions for drawing. (#1639)qml.transforms.batch_transformnow acceptsexpand_fns that take additional arguments and keyword arguments. In fact,expand_fnandtransform_fnnow must have the same signature. (#1721)The
qml.batch_transformdecorator is now ignored during Sphinx builds, allowing the correct signature to display in the built documentation. (#1733)The tests for qubit operations are split into multiple files. (#1661)
The transform for the Jacobian of the classical preprocessing within a QNode,
qml.transforms.classical_jacobian, now takes a keyword argumentargnumto specify the QNode argument indices with respect to which the Jacobian is computed. (#1645)An example for the usage of
argnumis@qml.qnode(dev) def circuit(x, y, z): qml.RX(qml.math.sin(x), wires=0) qml.CNOT(wires=[0, 1]) qml.RY(y ** 2, wires=1) qml.RZ(1 / z, wires=1) return qml.expval(qml.PauliZ(0)) jac_fn = qml.transforms.classical_jacobian(circuit, argnum=[1, 2])
The Jacobian can then be computed at specified parameters.
>>> x, y, z = np.array([0.1, -2.5, 0.71]) >>> jac_fn(x, y, z) (array([-0., -5., -0.]), array([-0. , -0. , -1.98373339]))
The returned arrays are the derivatives of the three parametrized gates in the circuit with respect to
yandzrespectively.There also are explicit tests for
classical_jacobiannow, which previously was tested implicitly via its use in themetric_tensortransform.For more usage details, please see the classical Jacobian docstring.
A new utility function
qml.math.is_abstract(tensor)has been added. This function returnsTrueif the tensor is abstract; that is, it has no value or shape. This can occur if within a function that has been just-in-time compiled. (#1845)qml.circuit_drawer.CircuitDrawercan accept a string for thecharsetkeyword, instead of aCharSetobject. (#1640)qml.math.sortwill now return only the sorted torch tensor and not the corresponding indices, making sort consistent across interfaces. (#1691)Specific QNode execution options are now re-used by batch transforms to execute transformed QNodes. (#1708)
To standardize across all optimizers,
qml.optimize.AdamOptimizernow also usesaccumulation(in form ofcollections.namedtuple) to keep track of running quantities. Before it used three variablesfm,smandt. (#1757)
Breaking changes
The operator attributes
has_unitary_generator,is_composable_rotation,is_self_inverse,is_symmetric_over_all_wires, andis_symmetric_over_control_wireshave been removed as attributes from the base class. They have been replaced by the sets that store the names of operations with similar properties inops/qubit/attributes.py. (#1763)The
qml.invfunction has been removed,qml.adjointshould be used instead. (#1778)The input signature of an
expand_fnused in abatch_transformnow must have the same signature as the providedtransform_fn, and vice versa. (#1721)The
default.qubit.torchdevice automatically determines if computations should be run on a CPU or a GPU and doesn’t take atorch_deviceargument anymore. (#1705)The utility function
qml.math.requires_gradnow returnsTruewhen using Autograd if and only if therequires_grad=Trueattribute is set on the NumPy array. Previously, this function would returnTruefor all NumPy arrays and Python floats, unlessrequires_grad=Falsewas explicitly set. (#1638)The operation
qml.Interferometerhas been renamedqml.InterferometerUnitaryin order to distinguish it from the templateqml.templates.Interferometer. (#1714)The
qml.transforms.invisibledecorator has been replaced withqml.tape.stop_recording, which may act as a context manager as well as a decorator to ensure that contained logic is non-recordable or non-queueable within a QNode or quantum tape context. (#1754)Templates
SingleExcitationUnitaryandDoubleExcitationUnitaryhave been renamed toFermionicSingleExcitationandFermionicDoubleExcitation, respectively. (#1822)
Deprecations
Allowing cost functions to be differentiated using
qml.gradorqml.jacobianwithout explicitly marking parameters as trainable is being deprecated, and will be removed in an upcoming release. Please specify therequires_gradattribute for every argument, or specifyargnumwhen usingqml.gradorqml.jacobian. (#1773)The following raises a warning in v0.19.0 and will raise an error in an upcoming release:
import pennylane as qml dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def test(x): qml.RY(x, wires=[0]) return qml.expval(qml.PauliZ(0)) par = 0.3 qml.grad(test)(par)
Preferred approaches include specifying the
requires_gradattribute:import pennylane as qml from pennylane import numpy as np dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def test(x): qml.RY(x, wires=[0]) return qml.expval(qml.PauliZ(0)) par = np.array(0.3, requires_grad=True) qml.grad(test)(par)
Or specifying the
argnumargument when usingqml.gradorqml.jacobian:import pennylane as qml dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def test(x): qml.RY(x, wires=[0]) return qml.expval(qml.PauliZ(0)) par = 0.3 qml.grad(test, argnum=0)(par)

The
default.tensordevice from the beta folder is no longer maintained and has been deprecated. It will be removed in future releases. (#1851)The
qml.metric_tensorandqml.QNGOptimizerkeyword argumentdiag_approxis deprecated. Approximations can be controlled with the more fine-grainedapproxkeyword argument, withapprox="block-diag"(the default) reproducing the old behaviour. (#1721) (#1834)The
templatedecorator is now deprecated with a warning message and will be removed in releasev0.20.0. It has been removed from different PennyLane functions. (#1794) (#1808)The
qml.fourier.spectrumfunction has been renamed toqml.fourier.circuit_spectrum, in order to clearly separate the newqnode_spectrumfunction from this one.qml.fourier.spectrumis now an alias forcircuit_spectrumbut is flagged for deprecation and will be removed soon. (#1681)The
initmodule, which contains functions to generate random parameter tensors for templates, is flagged for deprecation and will be removed in the next release cycle. Instead, the templates’shapemethod can be used to get the desired shape of the tensor, which can then be generated manually. (#1689)To generate the parameter tensors, the
np.random.normalandnp.random.uniformfunctions can be used (just like in theinitmodule). Considering the default arguments of these functions as of NumPy v1.21, some non-default options were used by theinitmodule:All functions generating normally distributed parameters used
np.random.normalby passingscale=0.1;Most functions generating uniformly distributed parameters (except for certain CVQNN initializers) used
np.random.uniformby passinghigh=2*math.pi;The
cvqnn_layers_r_uniform,cvqnn_layers_a_uniform,cvqnn_layers_kappa_uniformfunctions usednp.random.uniformby passinghigh=0.1.
The
QNode.drawmethod has been deprecated, and will be removed in an upcoming release. Please use theqml.drawtransform instead. (#1746)The
QNode.metric_tensormethod has been deprecated, and will be removed in an upcoming release. Please use theqml.metric_tensortransform instead. (#1638)The
padparameter of theqml.AmplitudeEmbeddingtemplate has been removed. It has instead been renamed to thepad_withparameter. (#1805)
Bug fixes
Fixes a bug where
qml.math.dotfailed to work with@tf.functionautograph mode. (#1842)Fixes a bug where in rare instances the parameters of a tape are returned unsorted by
Tape.get_parameters. (#1836)Fixes a bug with the arrow width in the
measureofqml.circuit_drawer.MPLDrawer. (#1823)The helper functions
qml.math.block_diagandqml.math.scatter_element_addnow are entirely differentiable when using Autograd. Previously only indexed entries of the block diagonal could be differentiated, while the derivative w.r.t to the second argument ofqml.math.scatter_element_adddispatched to NumPy instead of Autograd. (#1816) (#1818)Fixes a bug such that the original shot vector information of a device is preserved, so that outside the context manager the device remains unchanged. (#1792)
Modifies
qml.math.taketo be compatible with a breaking change released in JAX 0.2.24 and ensure that PennyLane supports this JAX version. (#1769)Fixes a bug where the GPU cannot be used with
qml.qnn.TorchLayer. (#1705)Fix a bug where the devices cache the same result for different observables return types. (#1719)
Fixed a bug of the default circuit drawer where having more measurements compared to the number of measurements on any wire raised a
KeyError. (#1702)Fix a bug where it was not possible to use
jax.jiton aQNodewhen usingQubitStateVector. (#1683)The device suite tests can now execute successfully if no shots configuration variable is given. (#1641)
Fixes a bug where the
qml.gradients.param_shifttransform would raise an error while attempting to compute the variance of a QNode with ragged output. (#1646)Fixes a bug in
default.mixed, to ensure that returned probabilities are always non-negative. (#1680)Fixes a bug where gradient transforms would fail to apply to QNodes containing classical processing. (#1699)
Fixes a bug where the the parameter-shift method was not correctly using the fallback gradient function when all circuit parameters required the fallback. (#1782)
Documentation
Adds a link to https://pennylane.ai/qml/demonstrations in the navbar. (#1624)
Corrects the docstring of
ExpvalCostby addingwiresto the signature of theansatzargument. (#1715)Updated docstring examples using the
qchem.molecular_hamiltonianfunction. (#1724)Updates the ‘Gradients and training’ quickstart guide to provide information on gradient transforms. (#1751)
All instances of
qnode.draw()have been updated to instead use the transformqml.draw(qnode). (#1750)Add the
jaxinterface in QNode Documentation. (#1755)Reorganized all the templates related to quantum chemistry under a common header
Quantum Chemistry templates. (#1822)
Contributors
This release contains contributions from (in alphabetical order):
Catalina Albornoz, Juan Miguel Arrazola, Utkarsh Azad, Akash Narayanan B, Sam Banning, Thomas Bromley, Jack Ceroni, Alain Delgado, Olivia Di Matteo, Andrew Gardhouse, Anthony Hayes, Theodor Isacsson, David Ittah, Josh Izaac, Soran Jahangiri, Nathan Killoran, Christina Lee, Guillermo Alonso-Linaje, Romain Moyard, Lee James O’Riordan, Carrie-Anne Rubidge, Maria Schuld, Rishabh Singh, Jay Soni, Ingrid Strandberg, Antal Száva, Teresa Tamayo-Mendoza, Rodrigo Vargas, Cody Wang, David Wierichs, Moritz Willmann.
Release 0.18.0¶
New features since last release
PennyLane now comes packaged with lightning.qubit
The C++-based lightning.qubit device is now included with installations of PennyLane. (#1663)
The
lightning.qubitdevice is a fast state-vector simulator equipped with the efficient adjoint method for differentiating quantum circuits, check out the plugin release notes for more details! The device can be accessed in the following way:import pennylane as qml wires = 3 layers = 2 dev = qml.device("lightning.qubit", wires=wires) @qml.qnode(dev, diff_method="adjoint") def circuit(weights): qml.templates.StronglyEntanglingLayers(weights, wires=range(wires)) return qml.expval(qml.PauliZ(0)) weights = qml.init.strong_ent_layers_normal(layers, wires, seed=1967)
Evaluating circuits and their gradients on the device can be achieved using the standard approach:
>>> print(f"Circuit evaluated: {circuit(weights)}") Circuit evaluated: 0.9801286266677633 >>> print(f"Circuit gradient:\n{qml.grad(circuit)(weights)}") Circuit gradient: [[[-9.35301749e-17 -1.63051504e-01 -4.14810501e-04] [-7.88816484e-17 -1.50136528e-04 -1.77922957e-04] [-5.20670796e-17 -3.92874550e-02 8.14523075e-05]] [[-1.14472273e-04 3.85963953e-02 -9.39190132e-18] [-5.76791765e-05 -9.78478343e-02 0.00000000e+00] [ 0.00000000e+00 0.00000000e+00 0.00000000e+00]]]
The adjoint method operates after a forward pass by iteratively applying inverse gates to scan backwards through the circuit. The method is already available in PennyLane’s
default.qubitdevice, but the version provided bylightning.qubitintegrates with the C++ backend and is more performant, as shown in the plot below:
Support for native backpropagation using PyTorch
The built-in PennyLane simulator
default.qubitnow supports backpropogation with PyTorch. (#1360) (#1598)As a result,
default.qubitcan now use end-to-end classical backpropagation as a means to compute gradients. End-to-end backpropagation can be faster than the parameter-shift rule for computing quantum gradients when the number of parameters to be optimized is large. This is now the default differentiation method when usingdefault.qubitwith PyTorch.Using this method, the created QNode is a ‘white-box’ that is tightly integrated with your PyTorch computation, including TorchScript and GPU support.
x = torch.tensor(0.43316321, dtype=torch.float64, requires_grad=True) y = torch.tensor(0.2162158, dtype=torch.float64, requires_grad=True) z = torch.tensor(0.75110998, dtype=torch.float64, requires_grad=True) p = torch.tensor([x, y, z], requires_grad=True) dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="torch", diff_method="backprop") def circuit(x): qml.Rot(x[0], x[1], x[2], wires=0) return qml.expval(qml.PauliZ(0)) res = circuit(p) res.backward()
>>> res = circuit(p) >>> res.backward() >>> print(p.grad) tensor([-9.1798e-17, -2.1454e-01, -1.0511e-16], dtype=torch.float64)
Improved quantum optimization methods
The
RotosolveOptimizernow can tackle general parametrized circuits, and is no longer restricted to single-qubit Pauli rotations. (#1489)This includes:
layers of gates controlled by the same parameter,
controlled variants of parametrized gates, and
Hamiltonian time evolution.
Note that the eigenvalue spectrum of the gate generator needs to be known to use
RotosolveOptimizerfor a general gate, and it is required to produce equidistant frequencies. For details see Vidal and Theis, 2018 and Wierichs, Izaac, Wang, Lin 2021.Consider a circuit with a mixture of Pauli rotation gates, controlled Pauli rotations, and single-parameter layers of Pauli rotations:
dev = qml.device('default.qubit', wires=3, shots=None) @qml.qnode(dev) def cost_function(rot_param, layer_par, crot_param): for i, par in enumerate(rot_param): qml.RX(par, wires=i) for w in dev.wires: qml.RX(layer_par, wires=w) for i, par in enumerate(crot_param): qml.CRY(par, wires=[i, (i+1) % 3]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1) @ qml.PauliZ(2))
This cost function has one frequency for each of the first
RXrotation angles, three frequencies for the layer ofRXgates that depend onlayer_par, and two frequencies for each of theCRYgate parameters. Rotosolve can then be used to minimize thecost_function:# Initial parameters init_param = [ np.array([0.3, 0.2, 0.67], requires_grad=True), np.array(1.1, requires_grad=True), np.array([-0.2, 0.1, -2.5], requires_grad=True), ] # Numbers of frequencies per parameter num_freqs = [[1, 1, 1], 3, [2, 2, 2]] opt = qml.RotosolveOptimizer() param = init_param.copy()
In addition, the optimization technique for the Rotosolve substeps can be chosen via the
optimizerandoptimizer_kwargskeyword arguments and the minimized cost of the intermediate univariate reconstructions can be read out viafull_output, including the cost after the full Rotosolve step:for step in range(3): param, cost, sub_cost = opt.step_and_cost( cost_function, *param, num_freqs=num_freqs, full_output=True, optimizer="brute", ) print(f"Cost before step: {cost}") print(f"Minimization substeps: {np.round(sub_cost, 6)}")
Cost before step: 0.042008210392535605 Minimization substeps: [-0.230905 -0.863336 -0.980072 -0.980072 -1. -1. -1. ] Cost before step: -0.999999999068121 Minimization substeps: [-1. -1. -1. -1. -1. -1. -1.] Cost before step: -1.0 Minimization substeps: [-1. -1. -1. -1. -1. -1. -1.]
For usage details please consider the docstring of the optimizer.
Faster, trainable, Hamiltonian simulations
Hamiltonians are now trainable with respect to their coefficients. (#1483)
from pennylane import numpy as np dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(coeffs, param): qml.RX(param, wires=0) qml.RY(param, wires=0) return qml.expval( qml.Hamiltonian(coeffs, [qml.PauliX(0), qml.PauliZ(0)], simplify=True) ) coeffs = np.array([-0.05, 0.17]) param = np.array(1.7) grad_fn = qml.grad(circuit)
>>> grad_fn(coeffs, param) (array([-0.12777055, 0.0166009 ]), array(0.0917819))
Furthermore, a gradient recipe for Hamiltonian coefficients has been added. This makes it possible to compute parameter-shift gradients of these coefficients on devices that natively support Hamiltonians. (#1551)
Hamiltonians are now natively supported on the
default.qubitdevice ifshots=None. This makes VQE workflows a lot faster in some cases. (#1551) (#1596)
The Hamiltonian can now store grouping information, which can be accessed by a device to speed up computations of the expectation value of a Hamiltonian. (#1515)
obs = [qml.PauliX(0), qml.PauliX(1), qml.PauliZ(0)] coeffs = np.array([1., 2., 3.]) H = qml.Hamiltonian(coeffs, obs, grouping_type='qwc')
Initialization with a
grouping_typeother thanNonestores the indices required to make groups of commuting observables and their coefficients.>>> H.grouping_indices [[0, 1], [2]]
Create multi-circuit quantum transforms and custom gradient rules
Custom gradient transforms can now be created using the new
@qml.gradients.gradient_transformdecorator on a batch-tape transform. (#1589)Quantum gradient transforms are a specific case of
qml.batch_transform.Supported gradient transforms must be of the following form:
@qml.gradients.gradient_transform def my_custom_gradient(tape, argnum=None, **kwargs): ... return gradient_tapes, processing_fn
Various built-in quantum gradient transforms are provided within the
qml.gradientsmodule, includingqml.gradients.param_shift. Once defined, quantum gradient transforms can be applied directly to QNodes:>>> @qml.qnode(dev) ... def circuit(x): ... qml.RX(x, wires=0) ... qml.CNOT(wires=[0, 1]) ... return qml.expval(qml.PauliZ(0)) >>> circuit(0.3) tensor(0.95533649, requires_grad=True) >>> qml.gradients.param_shift(circuit)(0.5) array([[-0.47942554]])
Quantum gradient transforms are fully differentiable, allowing higher order derivatives to be accessed:
>>> qml.grad(qml.gradients.param_shift(circuit))(0.5) tensor(-0.87758256, requires_grad=True)
Refer to the page of quantum gradient transforms for more details.
The ability to define batch transforms has been added via the new
@qml.batch_transformdecorator. (#1493)A batch transform is a transform that takes a single tape or QNode as input, and executes multiple tapes or QNodes independently. The results may then be post-processed before being returned.
For example, consider the following batch transform:
@qml.batch_transform def my_transform(tape, a, b): """Generates two tapes, one with all RX replaced with RY, and the other with all RX replaced with RZ.""" tape1 = qml.tape.JacobianTape() tape2 = qml.tape.JacobianTape() # loop through all operations on the input tape for op in tape.operations + tape.measurements: if op.name == "RX": with tape1: qml.RY(a * qml.math.abs(op.parameters[0]), wires=op.wires) with tape2: qml.RZ(b * qml.math.abs(op.parameters[0]), wires=op.wires) else: for t in [tape1, tape2]: with t: qml.apply(op) def processing_fn(results): return qml.math.sum(qml.math.stack(results)) return [tape1, tape2], processing_fn
We can transform a QNode directly using decorator syntax:
>>> @my_transform(0.65, 2.5) ... @qml.qnode(dev) ... def circuit(x): ... qml.Hadamard(wires=0) ... qml.RX(x, wires=0) ... return qml.expval(qml.PauliX(0)) >>> print(circuit(-0.5)) 1.2629730888100839
Batch tape transforms are fully differentiable:
>>> gradient = qml.grad(circuit)(-0.5) >>> print(gradient) 2.5800122591960153
Batch transforms can also be applied to existing QNodes,
>>> new_qnode = my_transform(existing_qnode, *transform_weights) >>> new_qnode(weights)
or to tapes (in which case, the processed tapes and classical post-processing functions are returned):
>>> tapes, fn = my_transform(tape, 0.65, 2.5) >>> from pennylane.interfaces.batch import execute >>> dev = qml.device("default.qubit", wires=1) >>> res = execute(tapes, dev, interface="autograd", gradient_fn=qml.gradients.param_shift) 1.2629730888100839
Vector-Jacobian product transforms have been added to the
qml.gradientspackage. (#1494)The new transforms include:
qml.gradients.vjpqml.gradients.batch_vjp
Support for differentiable execution of batches of circuits has been added, via the beta
pennylane.interfaces.batchmodule. (#1501) (#1508) (#1542) (#1549) (#1608) (#1618) (#1637)For now, this is a low-level feature, and will be integrated into the QNode in a future release. For example:
from pennylane.interfaces.batch import execute def cost_fn(x): with qml.tape.JacobianTape() as tape1: qml.RX(x[0], wires=[0]) qml.RY(x[1], wires=[1]) qml.CNOT(wires=[0, 1]) qml.var(qml.PauliZ(0) @ qml.PauliX(1)) with qml.tape.JacobianTape() as tape2: qml.RX(x[0], wires=0) qml.RY(x[0], wires=1) qml.CNOT(wires=[0, 1]) qml.probs(wires=1) result = execute( [tape1, tape2], dev, gradient_fn=qml.gradients.param_shift, interface="autograd" ) return result[0] + result[1][0, 0] res = qml.grad(cost_fn)(params)
Improvements
A new operation
qml.SISWAPhas been added, the square-root of theqml.ISWAPoperation. (#1563)The
frobenius_inner_productfunction has been moved to theqml.mathmodule, and is now differentiable using all autodiff frameworks. (#1388)A warning is raised to inform the user that specifying a list of shots is only supported for
QubitDevicebased devices. (#1659)The
qml.circuit_drawer.MPLDrawerclass provides manual circuit drawing functionality using Matplotlib. While not yet integrated with automatic circuit drawing, this class provides customization and control. (#1484)from pennylane.circuit_drawer import MPLDrawer drawer = MPLDrawer(n_wires=3, n_layers=3) drawer.label([r"$|\Psi\rangle$", r"$|\theta\rangle$", "aux"]) drawer.box_gate(layer=0, wires=[0, 1, 2], text="Entangling Layers", text_options={'rotation': 'vertical'}) drawer.box_gate(layer=1, wires=[0, 1], text="U(θ)") drawer.CNOT(layer=2, wires=[1, 2]) drawer.measure(layer=3, wires=2) drawer.fig.suptitle('My Circuit', fontsize='xx-large')

The slowest tests, more than 1.5 seconds, now have the pytest mark
slow, and can be selected or deselected during local execution of tests. (#1633)The device test suite has been expanded to cover more qubit operations and observables. (#1510)
The
MultiControlledXclass now inherits fromOperationinstead ofControlledQubitUnitarywhich makes theMultiControlledXgate a non-parameterized gate. (#1557)The
utils.sparse_hamiltonianfunction can now deal with non-integer wire labels, and it throws an error for the edge case of observables that are created from multi-qubit operations. (#1550)Added the matrix attribute to
qml.templates.subroutines.GroverOperator(#1553)The
tape.to_openqasm()method now has ameasure_allargument that specifies whether the serialized OpenQASM script includes computational basis measurements on all of the qubits or just those specified by the tape. (#1559)An error is now raised when no arguments are passed to an observable, to inform that wires have not been supplied. (#1547)
The
group_observablestransform is now differentiable. (#1483)For example:
import jax from jax import numpy as jnp coeffs = jnp.array([1., 2., 3.]) obs = [PauliX(wires=0), PauliX(wires=1), PauliZ(wires=1)] def group(coeffs, select=None): _, grouped_coeffs = qml.grouping.group_observables(obs, coeffs) # in this example, grouped_coeffs is a list of two jax tensors # [Array([1., 2.], dtype=float32), Array([3.], dtype=float32)] return grouped_coeffs[select] jac_fn = jax.jacobian(group)
>>> jac_fn(coeffs, select=0) [[1. 0. 0.] [0. 1. 0.]] >>> jac_fn(coeffs, select=1) [[0., 0., 1.]]
The tape does not verify any more that all Observables have owners in the annotated queue. (#1505)
This allows manipulation of Observables inside a tape context. An example is
expval(Tensor(qml.PauliX(0), qml.Identity(1)).prune())which makes the expval an owner of the pruned tensor and its constituent observables, but leaves the original tensor in the queue without an owner.The
qml.ResetErroris now supported fordefault.mixeddevice. (#1541)QNode.diff_methodwill now reflect which method was selected fromdiff_method="best". (#1568)QNodes now support
diff_method=None. This works the same asinterface=None. Such QNodes accept floats, ints, lists and NumPy arrays and return NumPy output but can not be differentiated. (#1585)QNodes now include validation to warn users if a supplied keyword argument is not one of the recognized arguments. (#1591)
Breaking changes
The
QFToperation has been moved, and is now accessible viapennylane.templates.QFT. (#1548)Specifying
shots=Nonewithqml.samplewas previously deprecated. From this release onwards, settingshots=Nonewhen sampling will raise an error also fordefault.qubit.jax. (#1629)An error is raised during QNode creation when a user requests backpropagation on a device with finite-shots. (#1588)
The class
qml.Interferometeris deprecated and will be renamedqml.InterferometerUnitaryafter one release cycle. (#1546)All optimizers except for Rotosolve and Rotoselect now have a public attribute
stepsize. Temporary backward compatibility has been added to support the use of_stepsizefor one release cycle.update_stepsizemethod is deprecated. (#1625)
Bug fixes
Fixed a bug with shot vectors and
Devicebase class. (#1666)Fixed a bug where
@jax.jitwould fail on a QNode that usedqml.QubitStateVector. (#1649)Fixed a bug related to an edge case of single-qubit
zyz_decompositionwhen only off-diagonal elements are present. (#1643)MottonenStatepreparationcan now be run with a single wire label not in a list. (#1620)Fixed the circuit representation of CY gates to align with CNOT and CZ gates when calling the circuit drawer. (#1504)
Dask and CVXPY dependent tests are skipped if those packages are not installed. (#1617)
The
qml.layertemplate now works with tensorflow variables. (#1615)Remove
QFTfrom possible operations indefault.qubitanddefault.mixed. (#1600)Fixed a bug when computing expectations of Hamiltonians using TensorFlow. (#1586)
Fixed a bug when computing the specs of a circuit with a Hamiltonian observable. (#1533)
Documentation
The
qml.Identityoperation is placed under the sections Qubit observables and CV observables. (#1576)Updated the documentation of
qml.grouping,qml.kernelsandqml.qaoamodules to present the list of functions first followed by the technical details of the module. (#1581)Recategorized Qubit operations into new and existing categories so that code for each operation is easier to locate. (#1566)
Contributors
This release contains contributions from (in alphabetical order):
Vishnu Ajith, Akash Narayanan B, Thomas Bromley, Olivia Di Matteo, Sahaj Dhamija, Tanya Garg, Anthony Hayes, Theodor Isacsson, Josh Izaac, Prateek Jain, Ankit Khandelwal, Nathan Killoran, Christina Lee, Ian McLean, Johannes Jakob Meyer, Romain Moyard, Lee James O’Riordan, Esteban Payares, Pratul Saini, Maria Schuld, Arshpreet Singh, Jay Soni, Ingrid Strandberg, Antal Száva, Slimane Thabet, David Wierichs, Vincent Wong.
Release 0.17.0¶
New features since the last release
Circuit optimization
PennyLane can now perform quantum circuit optimization using the top-level transform
qml.compile. Thecompiletransform allows you to chain together sequences of tape and quantum function transforms into custom circuit optimization pipelines. (#1475)For example, take the following decorated quantum function:
dev = qml.device('default.qubit', wires=[0, 1, 2]) @qml.qnode(dev) @qml.compile() def qfunc(x, y, z): qml.Hadamard(wires=0) qml.Hadamard(wires=1) qml.Hadamard(wires=2) qml.RZ(z, wires=2) qml.CNOT(wires=[2, 1]) qml.RX(z, wires=0) qml.CNOT(wires=[1, 0]) qml.RX(x, wires=0) qml.CNOT(wires=[1, 0]) qml.RZ(-z, wires=2) qml.RX(y, wires=2) qml.PauliY(wires=2) qml.CZ(wires=[1, 2]) return qml.expval(qml.PauliZ(wires=0))
The default behaviour of
qml.compileis to apply a sequence of three transforms:commute_controlled,cancel_inverses, and thenmerge_rotations.>>> print(qml.draw(qfunc)(0.2, 0.3, 0.4)) 0: ──H───RX(0.6)──────────────────┤ ⟨Z⟩ 1: ──H──╭X────────────────────╭C──┤ 2: ──H──╰C────────RX(0.3)──Y──╰Z──┤
The
qml.compiletransform is flexible and accepts a custom pipeline of tape and quantum function transforms (you can even write your own!). For example, if we wanted to only push single-qubit gates through controlled gates and cancel adjacent inverses, we could do:from pennylane.transforms import commute_controlled, cancel_inverses pipeline = [commute_controlled, cancel_inverses] @qml.qnode(dev) @qml.compile(pipeline=pipeline) def qfunc(x, y, z): qml.Hadamard(wires=0) qml.Hadamard(wires=1) qml.Hadamard(wires=2) qml.RZ(z, wires=2) qml.CNOT(wires=[2, 1]) qml.RX(z, wires=0) qml.CNOT(wires=[1, 0]) qml.RX(x, wires=0) qml.CNOT(wires=[1, 0]) qml.RZ(-z, wires=2) qml.RX(y, wires=2) qml.PauliY(wires=2) qml.CZ(wires=[1, 2]) return qml.expval(qml.PauliZ(wires=0))
>>> print(qml.draw(qfunc)(0.2, 0.3, 0.4)) 0: ──H───RX(0.4)──RX(0.2)────────────────────────────┤ ⟨Z⟩ 1: ──H──╭X───────────────────────────────────────╭C──┤ 2: ──H──╰C────────RZ(0.4)──RZ(-0.4)──RX(0.3)──Y──╰Z──┤
The following compilation transforms have been added and are also available to use, either independently, or within a
qml.compilepipeline:commute_controlled: push commuting single-qubit gates through controlled operations. (#1464)cancel_inverses: removes adjacent pairs of operations that cancel out. (#1455)merge_rotations: combines adjacent rotation gates of the same type into a single gate, including controlled rotations. (#1455)single_qubit_fusion: acts on all sequences of single-qubit operations in a quantum function, and converts each sequence to a singleRotgate. (#1458)
For more details on
qml.compileand the available compilation transforms, see the compilation documentation.
QNodes are even more powerful
Computational basis samples directly from the underlying device can now be returned directly from QNodes via
qml.sample(). (#1441)dev = qml.device("default.qubit", wires=3, shots=5) @qml.qnode(dev) def circuit_1(): qml.Hadamard(wires=0) qml.Hadamard(wires=1) return qml.sample() @qml.qnode(dev) def circuit_2(): qml.Hadamard(wires=0) qml.Hadamard(wires=1) return qml.sample(wires=[0,2]) # no observable provided and wires specified
>>> print(circuit_1()) [[1, 0, 0], [1, 1, 0], [1, 0, 0], [0, 0, 0], [0, 1, 0]] >>> print(circuit_2()) [[1, 0], [1, 0], [1, 0], [0, 0], [0, 0]] >>> print(qml.draw(circuit_2)()) 0: ──H──╭┤ Sample[basis] 1: ──H──│┤ 2: ─────╰┤ Sample[basis]
The new
qml.applyfunction can be used to add operations that might have already been instantiated elsewhere to the QNode and other queuing contexts: (#1433)op = qml.RX(0.4, wires=0) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.RY(x, wires=0) qml.apply(op) return qml.expval(qml.PauliZ(0))
>>> print(qml.draw(circuit)(0.6)) 0: ──RY(0.6)──RX(0.4)──┤ ⟨Z⟩
Previously instantiated measurements can also be applied to QNodes.
Device Resource Tracker
The new Device Tracker capabilities allows for flexible and versatile tracking of executions, even inside parameter-shift gradients. This functionality will improve the ease of monitoring large batches and remote jobs. (#1355)
dev = qml.device('default.qubit', wires=1, shots=100) @qml.qnode(dev, diff_method="parameter-shift") def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)) x = np.array(0.1) with qml.Tracker(circuit.device) as tracker: qml.grad(circuit)(x)
>>> tracker.totals {'executions': 3, 'shots': 300, 'batches': 1, 'batch_len': 2} >>> tracker.history {'executions': [1, 1, 1], 'shots': [100, 100, 100], 'batches': [1], 'batch_len': [2]} >>> tracker.latest {'batches': 1, 'batch_len': 2}
Users can also provide a custom function to the
callbackkeyword that gets called each time the information is updated. This functionality allows users to monitor remote jobs or large parameter-shift batches.>>> def shots_info(totals, history, latest): ... print("Total shots: ", totals['shots']) >>> with qml.Tracker(circuit.device, callback=shots_info) as tracker: ... qml.grad(circuit)(0.1) Total shots: 100 Total shots: 200 Total shots: 300 Total shots: 300
Containerization support
Docker support for building PennyLane with support for all interfaces (TensorFlow, Torch, and Jax), as well as device plugins and QChem, for GPUs and CPUs, has been added. (#1391)
The build process using Docker and
makerequires that the repository source code is cloned or downloaded from GitHub. Visit the the detailed description for an extended list of options.
Improved Hamiltonian simulations
Added a sparse Hamiltonian observable and the functionality to support computing its expectation value with
default.qubit. (#1398)For example, the following QNode returns the expectation value of a sparse Hamiltonian:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, diff_method="parameter-shift") def circuit(param, H): qml.PauliX(0) qml.SingleExcitation(param, wires=[0, 1]) return qml.expval(qml.SparseHamiltonian(H, [0, 1]))
We can execute this QNode, passing in a sparse identity matrix:
>>> print(circuit([0.5], scipy.sparse.eye(4).tocoo())) 0.9999999999999999
The expectation value of the sparse Hamiltonian is computed directly, which leads to executions that are faster by orders of magnitude. Note that “parameter-shift” is the only differentiation method that is currently supported when the observable is a sparse Hamiltonian.
VQE problems can now be intuitively set up by passing the Hamiltonian as an observable. (#1474)
dev = qml.device("default.qubit", wires=2) H = qml.Hamiltonian([1., 2., 3.], [qml.PauliZ(0), qml.PauliY(0), qml.PauliZ(1)]) w = qml.init.strong_ent_layers_uniform(1, 2, seed=1967) @qml.qnode(dev) def circuit(w): qml.templates.StronglyEntanglingLayers(w, wires=range(2)) return qml.expval(H)
>>> print(circuit(w)) -1.5133943637878295 >>> print(qml.grad(circuit)(w)) [[[-8.32667268e-17 1.39122955e+00 -9.12462052e-02] [ 1.02348685e-16 -7.77143238e-01 -1.74708049e-01]]]
Note that other measurement types like
var(H)orsample(H), as well as multiple expectations likeexpval(H1), expval(H2)are not supported.Added functionality to compute the sparse matrix representation of a
qml.Hamiltonianobject. (#1394)
New gradients module
A new gradients module
qml.gradientshas been added, which provides differentiable quantum gradient transforms. (#1476) (#1479) (#1486)Available quantum gradient transforms include:
qml.gradients.finite_diffqml.gradients.param_shiftqml.gradients.param_shift_cv
For example,
>>> params = np.array([0.3,0.4,0.5], requires_grad=True) >>> with qml.tape.JacobianTape() as tape: ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.RX(params[2], wires=0) ... qml.expval(qml.PauliZ(0)) ... qml.var(qml.PauliZ(0)) >>> tape.trainable_params = {0, 1, 2} >>> gradient_tapes, fn = qml.gradients.finite_diff(tape) >>> res = dev.batch_execute(gradient_tapes) >>> fn(res) array([[-0.69688381, -0.32648317, -0.68120105], [ 0.8788057 , 0.41171179, 0.85902895]])
Even more new operations and templates
Grover Diffusion Operator template added. (#1442)
For example, if we have an oracle that marks the “all ones” state with a negative sign:
n_wires = 3 wires = list(range(n_wires)) def oracle(): qml.Hadamard(wires[-1]) qml.Toffoli(wires=wires) qml.Hadamard(wires[-1])
We can perform Grover’s Search Algorithm:
dev = qml.device('default.qubit', wires=wires) @qml.qnode(dev) def GroverSearch(num_iterations=1): for wire in wires: qml.Hadamard(wire) for _ in range(num_iterations): oracle() qml.templates.GroverOperator(wires=wires) return qml.probs(wires)
We can see this circuit yields the marked state with high probability:
>>> GroverSearch(num_iterations=1) tensor([0.03125, 0.03125, 0.03125, 0.03125, 0.03125, 0.03125, 0.03125, 0.78125], requires_grad=True) >>> GroverSearch(num_iterations=2) tensor([0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.9453125], requires_grad=True)
A decomposition has been added to
QubitUnitarythat makes the single-qubit case fully differentiable in all interfaces. Furthermore, a quantum function transform,unitary_to_rot(), has been added to decompose all single-qubit instances ofQubitUnitaryin a quantum circuit. (#1427)Instances of
QubitUnitarymay now be decomposed directly toRotoperations, orRZoperations if the input matrix is diagonal. For example, let>>> U = np.array([ [-0.28829348-0.78829734j, 0.30364367+0.45085995j], [ 0.53396245-0.10177564j, 0.76279558-0.35024096j] ])
Then, we can compute the decomposition as:
>>> qml.QubitUnitary.decomposition(U, wires=0) [Rot(-0.24209530281458358, 1.1493817777199102, 1.733058145303424, wires=[0])]
We can also apply the transform directly to a quantum function, and compute the gradients of parameters used to construct the unitary matrices.
def qfunc_with_qubit_unitary(angles): z, x = angles[0], angles[1] Z_mat = np.array([[np.exp(-1j * z / 2), 0.0], [0.0, np.exp(1j * z / 2)]]) c = np.cos(x / 2) s = np.sin(x / 2) * 1j X_mat = np.array([[c, -s], [-s, c]]) qml.Hadamard(wires="a") qml.QubitUnitary(Z_mat, wires="a") qml.QubitUnitary(X_mat, wires="b") qml.CNOT(wires=["b", "a"]) return qml.expval(qml.PauliX(wires="a"))
>>> dev = qml.device("default.qubit", wires=["a", "b"]) >>> transformed_qfunc = qml.transforms.unitary_to_rot(qfunc_with_qubit_unitary) >>> transformed_qnode = qml.QNode(transformed_qfunc, dev) >>> input = np.array([0.3, 0.4], requires_grad=True) >>> transformed_qnode(input) tensor(0.95533649, requires_grad=True) >>> qml.grad(transformed_qnode)(input) array([-0.29552021, 0. ])
Ising YY gate functionality added. (#1358)
Improvements
The tape does not verify any more that all Observables have owners in the annotated queue. (#1505)
This allows manipulation of Observables inside a tape context. An example is
expval(Tensor(qml.PauliX(0), qml.Identity(1)).prune())which makes the expval an owner of the pruned tensor and its constituent observables, but leaves the original tensor in the queue without an owner.The
stepandstep_and_costmethods ofQNGOptimizernow accept a customgrad_fnkeyword argument to use for gradient computations. (#1487)The precision used by
default.qubit.jaxnow matches the float precision indicated byfrom jax.config import config config.read('jax_enable_x64')
where
Truemeansfloat64/complex128andFalsemeansfloat32/complex64. (#1485)The
./pennylane/ops/qubit.pyfile is broken up into a folder of six separate files. (#1467)Changed to using commas as the separator of wires in the string representation of
qml.Hamiltonianobjects for multi-qubit terms. (#1465)Changed to using
np.object_instead ofnp.objectas per the NumPy deprecations starting version 1.20. (#1466)Change the order of the covariance matrix and the vector of means internally in
default.gaussian. (#1331)Added the
idattribute to templates. (#1438)The
qml.mathmodule, for framework-agnostic tensor manipulation, has two new functions available: (#1490)qml.math.get_trainable_indices(sequence_of_tensors): returns the indices corresponding to trainable tensors in the input sequence.qml.math.unwrap(sequence_of_tensors): unwraps a sequence of tensor-like objects to NumPy arrays.
In addition, the behaviour of
qml.math.requires_gradhas been improved in order to correctly determine trainability during Autograd and JAX backwards passes.A new tape method,
tape.unwrap()is added. This method is a context manager; inside the context, the tape’s parameters are unwrapped to NumPy arrays and floats, and the trainable parameter indices are set. (#1491)These changes are temporary, and reverted on exiting the context.
>>> with tf.GradientTape(): ... with qml.tape.QuantumTape() as tape: ... qml.RX(tf.Variable(0.1), wires=0) ... qml.RY(tf.constant(0.2), wires=0) ... qml.RZ(tf.Variable(0.3), wires=0) ... with tape.unwrap(): ... print("Trainable params:", tape.trainable_params) ... print("Unwrapped params:", tape.get_parameters()) Trainable params: {0, 2} Unwrapped params: [0.1, 0.3] >>> print("Original parameters:", tape.get_parameters()) Original parameters: [<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=0.1>, <tf.Variable 'Variable:0' shape=() dtype=float32, numpy=0.3>]
In addition,
qml.tape.Unwrapis a context manager that unwraps multiple tapes:>>> with qml.tape.Unwrap(tape1, tape2):
Breaking changes
Removed the deprecated tape methods
get_resourcesandget_depthas they are superseded by thespecstape attribute. (#1522)Specifying
shots=Nonewithqml.samplewas previously deprecated. From this release onwards, settingshots=Nonewhen sampling will raise an error. (#1522)The existing
pennylane.collections.applyfunction is no longer accessible viaqml.apply, and needs to be imported directly from thecollectionspackage. (#1358)
Bug fixes
Fixes a bug in
qml.adjointandqml.ctrlwhere the adjoint of operations outside of aQNodeor aQuantumTapecould not be obtained. (#1532)Fixes a bug in
GradientDescentOptimizerandNesterovMomentumOptimizerwhere a cost function with one trainable parameter and non-trainable parameters raised an error. (#1495)Fixed an example in the documentation’s introduction to numpy gradients, where the wires were a non-differentiable argument to the QNode. (#1499)
Fixed a bug where the adjoint of
qml.QFTwhen using theqml.adjointfunction was not correctly computed. (#1451)Fixed the differentiability of the operation
IsingYYfor Autograd, Jax and Tensorflow. (#1425)Fixed a bug in the
torchinterface that prevented gradients from being computed on a GPU. (#1426)Quantum function transforms now preserve the format of the measurement results, so that a single measurement returns a single value rather than an array with a single element. (#1434)
Fixed a bug in the parameter-shift Hessian implementation, which resulted in the incorrect Hessian being returned for a cost function that performed post-processing on a vector-valued QNode. (#1436)
Fixed a bug in the initialization of
QubitUnitarywhere the size of the matrix was not checked against the number of wires. (#1439)
Documentation
Improved Contribution Guide and Pull Requests Guide. (#1461)
Examples have been added to clarify use of the continuous-variable
FockStateVectoroperation in the multi-mode case. (#1472)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Olivia Di Matteo, Anthony Hayes, Theodor Isacsson, Josh Izaac, Soran Jahangiri, Nathan Killoran, Arshpreet Singh Khangura, Leonhard Kunczik, Christina Lee, Romain Moyard, Lee James O’Riordan, Ashish Panigrahi, Nahum Sá, Maria Schuld, Jay Soni, Antal Száva, David Wierichs.
Release 0.16.0¶
First class support for quantum kernels
The new
qml.kernelsmodule provides basic functionalities for working with quantum kernels as well as post-processing methods to mitigate sampling errors and device noise: (#1102)num_wires = 6 wires = range(num_wires) dev = qml.device('default.qubit', wires=wires) @qml.qnode(dev) def kernel_circuit(x1, x2): qml.templates.AngleEmbedding(x1, wires=wires) qml.adjoint(qml.templates.AngleEmbedding)(x2, wires=wires) return qml.probs(wires) kernel = lambda x1, x2: kernel_circuit(x1, x2)[0] X_train = np.random.random((10, 6)) X_test = np.random.random((5, 6)) # Create symmetric square kernel matrix (for training) K = qml.kernels.square_kernel_matrix(X_train, kernel) # Compute kernel between test and training data. K_test = qml.kernels.kernel_matrix(X_train, X_test, kernel) K1 = qml.kernels.mitigate_depolarizing_noise(K, num_wires, method='single')
Extract the fourier representation of quantum circuits
PennyLane now has a
fouriermodule, which hosts a growing library of methods that help with investigating the Fourier representation of functions implemented by quantum circuits. The Fourier representation can be used to examine and characterize the expressivity of the quantum circuit. (#1160) (#1378)For example, one can plot distributions over Fourier series coefficients like this one:

Seamless support for working with the Pauli group
Added functionality for constructing and manipulating the Pauli group (#1181).
The function
qml.grouping.pauli_groupprovides a generator to easily loop over the group, or construct and store it in its entirety. For example, we can construct the single-qubit Pauli group like so:>>> from pennylane.grouping import pauli_group >>> pauli_group_1_qubit = list(pauli_group(1)) >>> pauli_group_1_qubit [Identity(wires=[0]), PauliZ(wires=[0]), PauliX(wires=[0]), PauliY(wires=[0])]
We can multiply together its members at the level of Pauli words using the
pauli_multandpauli_multi_with_phasefunctions. This can be done on arbitrarily-labeled wires as well, by defining a wire map.>>> from pennylane.grouping import pauli_group, pauli_mult >>> wire_map = {'a' : 0, 'b' : 1, 'c' : 2} >>> pg = list(pauli_group(3, wire_map=wire_map)) >>> pg[3] PauliZ(wires=['b']) @ PauliZ(wires=['c']) >>> pg[55] PauliY(wires=['a']) @ PauliY(wires=['b']) @ PauliZ(wires=['c']) >>> pauli_mult(pg[3], pg[55], wire_map=wire_map) PauliY(wires=['a']) @ PauliX(wires=['b'])
Functions for conversion of Pauli observables to strings (and back), are included.
>>> from pennylane.grouping import pauli_word_to_string, string_to_pauli_word >>> pauli_word_to_string(pg[55], wire_map=wire_map) 'YYZ' >>> string_to_pauli_word('ZXY', wire_map=wire_map) PauliZ(wires=['a']) @ PauliX(wires=['b']) @ PauliY(wires=['c'])
Calculation of the matrix representation for arbitrary Paulis and wire maps is now also supported.
>>> from pennylane.grouping import pauli_word_to_matrix >>> wire_map = {'a' : 0, 'b' : 1} >>> pauli_word = qml.PauliZ('b') # corresponds to Pauli 'IZ' >>> pauli_word_to_matrix(pauli_word, wire_map=wire_map) array([[ 1., 0., 0., 0.], [ 0., -1., 0., -0.], [ 0., 0., 1., 0.], [ 0., -0., 0., -1.]])
New transforms
The
qml.specsQNode transform creates a function that returns specifications or details about the QNode, including depth, number of gates, and number of gradient executions required. (#1245)For example:
dev = qml.device('default.qubit', wires=4) @qml.qnode(dev, diff_method='parameter-shift') def circuit(x, y): qml.RX(x[0], wires=0) qml.Toffoli(wires=(0, 1, 2)) qml.CRY(x[1], wires=(0, 1)) qml.Rot(x[2], x[3], y, wires=0) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliX(1))
We can now use the
qml.specstransform to generate a function that returns details and resource information:>>> x = np.array([0.05, 0.1, 0.2, 0.3], requires_grad=True) >>> y = np.array(0.4, requires_grad=False) >>> specs_func = qml.specs(circuit) >>> specs_func(x, y) {'gate_sizes': defaultdict(int, {1: 2, 3: 1, 2: 1}), 'gate_types': defaultdict(int, {'RX': 1, 'Toffoli': 1, 'CRY': 1, 'Rot': 1}), 'num_operations': 4, 'num_observables': 2, 'num_diagonalizing_gates': 1, 'num_used_wires': 3, 'depth': 4, 'num_trainable_params': 4, 'num_parameter_shift_executions': 11, 'num_device_wires': 4, 'device_name': 'default.qubit', 'diff_method': 'parameter-shift'}
The tape methods
get_resourcesandget_depthare superseded byspecsand will be deprecated after one release cycle.Adds a decorator
@qml.qfunc_transformto easily create a transformation that modifies the behaviour of a quantum function. (#1315)For example, consider the following transform, which scales the parameter of all
RXgates by \(x \rightarrow \sin(a) \sqrt{x}\), and the parameters of allRYgates by \(y \rightarrow \cos(a * b) y\):@qml.qfunc_transform def my_transform(tape, a, b): for op in tape.operations + tape.measurements: if op.name == "RX": x = op.parameters[0] qml.RX(qml.math.sin(a) * qml.math.sqrt(x), wires=op.wires) elif op.name == "RY": y = op.parameters[0] qml.RX(qml.math.cos(a * b) * y, wires=op.wires) else: op.queue()
We can now apply this transform to any quantum function:
dev = qml.device("default.qubit", wires=2) def ansatz(x): qml.Hadamard(wires=0) qml.RX(x[0], wires=0) qml.RY(x[1], wires=1) qml.CNOT(wires=[0, 1]) @qml.qnode(dev) def circuit(params, transform_weights): qml.RX(0.1, wires=0) # apply the transform to the ansatz my_transform(*transform_weights)(ansatz)(params) return qml.expval(qml.PauliZ(1))
We can print this QNode to show that the qfunc transform is taking place:
>>> x = np.array([0.5, 0.3], requires_grad=True) >>> transform_weights = np.array([0.1, 0.6], requires_grad=True) >>> print(qml.draw(circuit)(x, transform_weights)) 0: ──RX(0.1)────H──RX(0.0706)──╭C──┤ 1: ──RX(0.299)─────────────────╰X──┤ ⟨Z⟩
Evaluating the QNode, as well as the derivative, with respect to the gate parameter and the transform weights:
>>> circuit(x, transform_weights) tensor(0.00672829, requires_grad=True) >>> qml.grad(circuit)(x, transform_weights) (array([ 0.00671711, -0.00207359]), array([6.69695008e-02, 3.73694364e-06]))
Adds a
hamiltonian_expandtape transform. This takes a tape ending inqml.expval(H), whereHis a Hamiltonian, and maps it to a collection of tapes which can be executed and passed into a post-processing function yielding the expectation value. (#1142)Example use:
H = qml.PauliZ(0) + 3 * qml.PauliZ(0) @ qml.PauliX(1) with qml.tape.QuantumTape() as tape: qml.Hadamard(wires=1) qml.expval(H) tapes, fn = qml.transforms.hamiltonian_expand(tape)
We can now evaluate the transformed tapes, and apply the post-processing function:
>>> dev = qml.device("default.qubit", wires=3) >>> res = dev.batch_execute(tapes) >>> fn(res) 3.999999999999999
The
quantum_monte_carlotransform has been added, allowing an input circuit to be transformed into the full quantum Monte Carlo algorithm. (#1316)Suppose we want to measure the expectation value of the sine squared function according to a standard normal distribution. We can calculate the expectation value analytically as
0.432332, but we can also estimate using the quantum Monte Carlo algorithm. The first step is to discretize the problem:from scipy.stats import norm m = 5 M = 2 ** m xmax = np.pi # bound to region [-pi, pi] xs = np.linspace(-xmax, xmax, M) probs = np.array([norm().pdf(x) for x in xs]) probs /= np.sum(probs) func = lambda i: np.sin(xs[i]) ** 2 r_rotations = np.array([2 * np.arcsin(np.sqrt(func(i))) for i in range(M)])
The
quantum_monte_carlotransform can then be used:from pennylane.templates.state_preparations.mottonen import ( _uniform_rotation_dagger as r_unitary, ) n = 6 N = 2 ** n a_wires = range(m) wires = range(m + 1) target_wire = m estimation_wires = range(m + 1, n + m + 1) dev = qml.device("default.qubit", wires=(n + m + 1)) def fn(): qml.templates.MottonenStatePreparation(np.sqrt(probs), wires=a_wires) r_unitary(qml.RY, r_rotations, control_wires=a_wires[::-1], target_wire=target_wire) @qml.qnode(dev) def qmc(): qml.quantum_monte_carlo(fn, wires, target_wire, estimation_wires)() return qml.probs(estimation_wires) phase_estimated = np.argmax(qmc()[:int(N / 2)]) / N
The estimated value can be retrieved using:
>>> (1 - np.cos(np.pi * phase_estimated)) / 2 0.42663476277231915
The resources required to perform the quantum Monte Carlo algorithm can also be inspected using the
specstransform.
Extended QAOA module
Functionality to support solving the maximum-weighted cycle problem has been added to the
qaoamodule. (#1207) (#1209) (#1251) (#1213) (#1220) (#1214) (#1283) (#1297) (#1396) (#1403)The
max_weight_cyclefunction returns the appropriate cost and mixer Hamiltonians:>>> a = np.random.random((3, 3)) >>> np.fill_diagonal(a, 0) >>> g = nx.DiGraph(a) # create a random directed graph >>> cost, mixer, mapping = qml.qaoa.max_weight_cycle(g) >>> print(cost) (-0.9775906842165344) [Z2] + (-0.9027248603361988) [Z3] + (-0.8722207409852838) [Z0] + (-0.6426184210832898) [Z5] + (-0.2832594164291379) [Z1] + (-0.0778133996933755) [Z4] >>> print(mapping) {0: (0, 1), 1: (0, 2), 2: (1, 0), 3: (1, 2), 4: (2, 0), 5: (2, 1)}
Additional functionality can be found in the qml.qaoa.cycle module.
Extended operations and templates
Added functionality to compute the sparse matrix representation of a
qml.Hamiltonianobject. (#1394)coeffs = [1, -0.45] obs = [qml.PauliZ(0) @ qml.PauliZ(1), qml.PauliY(0) @ qml.PauliZ(1)] H = qml.Hamiltonian(coeffs, obs) H_sparse = qml.utils.sparse_hamiltonian(H)
The resulting matrix is a sparse matrix in scipy coordinate list (COO) format:
>>> H_sparse <4x4 sparse matrix of type '<class 'numpy.complex128'>' with 8 stored elements in COOrdinate format>
The sparse matrix can be converted to an array as:
>>> H_sparse.toarray() array([[ 1.+0.j , 0.+0.j , 0.+0.45j, 0.+0.j ], [ 0.+0.j , -1.+0.j , 0.+0.j , 0.-0.45j], [ 0.-0.45j, 0.+0.j , -1.+0.j , 0.+0.j ], [ 0.+0.j , 0.+0.45j, 0.+0.j , 1.+0.j ]])
Adds the new template
AllSinglesDoublesto prepare quantum states of molecules using theSingleExcitationandDoubleExcitationoperations. The new template reduces significantly the number of operations and the depth of the quantum circuit with respect to the traditional UCCSD unitary. (#1383)For example, consider the case of two particles and four qubits. First, we define the Hartree-Fock initial state and generate all possible single and double excitations.
import pennylane as qml from pennylane import numpy as np electrons = 2 qubits = 4 hf_state = qml.qchem.hf_state(electrons, qubits) singles, doubles = qml.qchem.excitations(electrons, qubits)
Now we can use the template
AllSinglesDoublesto define the quantum circuit,from pennylane.templates import AllSinglesDoubles wires = range(qubits) dev = qml.device('default.qubit', wires=wires) @qml.qnode(dev) def circuit(weights, hf_state, singles, doubles): AllSinglesDoubles(weights, wires, hf_state, singles, doubles) return qml.expval(qml.PauliZ(0)) params = np.random.normal(0, np.pi, len(singles) + len(doubles))
and execute it:
>>> circuit(params, hf_state, singles=singles, doubles=doubles) tensor(-0.73772194, requires_grad=True)
Adds
QubitCarryandQubitSumoperations for basic arithmetic. (#1169)The following example adds two 1-bit numbers, returning a 2-bit answer:
dev = qml.device('default.qubit', wires = 4) a = 0 b = 1 @qml.qnode(dev) def circuit(): qml.BasisState(np.array([a, b]), wires=[1, 2]) qml.QubitCarry(wires=[0, 1, 2, 3]) qml.CNOT(wires=[1, 2]) qml.QubitSum(wires=[0, 1, 2]) return qml.probs(wires=[3, 2]) probs = circuit() bitstrings = tuple(itertools.product([0, 1], repeat = 2)) indx = np.argwhere(probs == 1).flatten()[0] output = bitstrings[indx]
>>> print(output) (0, 1)
Added the
qml.Projectorobservable, which is available on all devices inheriting from theQubitDeviceclass. (#1356) (#1368)Using
qml.Projector, we can define the basis state projectors to use when computing expectation values. Let us take for example a circuit that prepares Bell states:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(basis_state): qml.Hadamard(wires=[0]) qml.CNOT(wires=[0, 1]) return qml.expval(qml.Projector(basis_state, wires=[0, 1]))
We can then specify the
|00>basis state to construct the|00><00|projector and compute the expectation value:>>> basis_state = [0, 0] >>> circuit(basis_state) tensor(0.5, requires_grad=True)
As expected, we get similar results when specifying the
|11>basis state:>>> basis_state = [1, 1] >>> circuit(basis_state) tensor(0.5, requires_grad=True)
The following new operations have been added:
Improvements
The
argnumkeyword argument can now be specified for a QNode to define a subset of trainable parameters used to estimate the Jacobian. (#1371)For example, consider two trainable parameters and a quantum function:
dev = qml.device("default.qubit", wires=2) x = np.array(0.543, requires_grad=True) y = np.array(-0.654, requires_grad=True) def circuit(x,y): qml.RX(x, wires=[0]) qml.RY(y, wires=[1]) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliX(1))
When computing the gradient of the QNode, we can specify the trainable parameters to consider by passing the
argnumkeyword argument:>>> qnode1 = qml.QNode(circuit, dev, diff_method="parameter-shift", argnum=[0,1]) >>> print(qml.grad(qnode1)(x,y)) (array(0.31434679), array(0.67949903))
Specifying a proper subset of the trainable parameters will estimate the Jacobian:
>>> qnode2 = qml.QNode(circuit, dev, diff_method="parameter-shift", argnum=[0]) >>> print(qml.grad(qnode2)(x,y)) (array(0.31434679), array(0.))
Allows creating differentiable observables that return custom objects such that the observable is supported by devices. (1291)
As an example, first we define
NewObservableclass:from pennylane.devices import DefaultQubit class NewObservable(qml.operation.Observable): """NewObservable""" num_wires = qml.operation.AnyWires num_params = 0 par_domain = None def diagonalizing_gates(self): """Diagonalizing gates""" return []
Once we have this new observable class, we define a
SpecialObjectclass that can be used to encode data in an observable and a new device that supports our new observable and returns aSpecialObjectas the expectation value (the code is shortened for brevity, the extended example can be found as a test in the previously referenced pull request):class SpecialObject: def __init__(self, val): self.val = val def __mul__(self, other): new = SpecialObject(self.val) new *= other return new ... class DeviceSupportingNewObservable(DefaultQubit): name = "Device supporting NewObservable" short_name = "default.qubit.newobservable" observables = DefaultQubit.observables.union({"NewObservable"}) def expval(self, observable, **kwargs): if self.shots is None and isinstance(observable, NewObservable): val = super().expval(qml.PauliZ(wires=0), **kwargs) return SpecialObject(val) return super().expval(observable, **kwargs)
At this point, we can create a device that will support the differentiation of a
NewObservableobject:dev = DeviceSupportingNewObservable(wires=1, shots=None) @qml.qnode(dev, diff_method="parameter-shift") def qnode(x): qml.RY(x, wires=0) return qml.expval(NewObservable(wires=0))
We can then compute the jacobian of this object:
>>> result = qml.jacobian(qnode)(0.2) >>> print(result) <__main__.SpecialObject object at 0x7fd2c54721f0> >>> print(result.item().val) -0.19866933079506116
PennyLane NumPy now includes the random module’s
Generatorobjects, the recommended way of random number generation. This allows for random number generation using a local, rather than global seed. (#1267)from pennylane import numpy as np rng = np.random.default_rng() random_mat1 = rng.random((3,2)) random_mat2 = rng.standard_normal(3, requires_grad=False)
The performance of adjoint jacobian differentiation was significantly improved as the method now reuses the state computed on the forward pass. This can be turned off to save memory with the Torch and TensorFlow interfaces by passing
adjoint_cache=Falseduring QNode creation. (#1341)The
Operator(and by inheritance, theOperationandObservableclass and their children) now have anidattribute, which can mark an operator in a circuit, for example to identify it on the tape by a tape transform. (#1377)The
benchmarkmodule was deleted, since it was outdated and is superseded by the new separate benchmark repository. (#1343)Decompositions in terms of elementary gates has been added for:
qml.CSWAP(#1306)qml.SWAP(#1329)qml.SingleExcitation(#1303)qml.SingleExcitationPlusandqml.SingleExcitationMinus(#1278)qml.DoubleExcitation(#1303)qml.Toffoli(#1320)qml.MultiControlledX. (#1287) When controlling on three or more wires, an ancilla register of worker wires is required to support the decomposition.ctrl_wires = [f"c{i}" for i in range(5)] work_wires = [f"w{i}" for i in range(3)] target_wires = ["t0"] all_wires = ctrl_wires + work_wires + target_wires dev = qml.device("default.qubit", wires=all_wires) with qml.tape.QuantumTape() as tape: qml.MultiControlledX(control_wires=ctrl_wires, wires=target_wires, work_wires=work_wires)
>>> tape = tape.expand(depth=1) >>> print(tape.draw(wire_order=qml.wires.Wires(all_wires))) c0: ──────────────╭C──────────────────────╭C──────────┤ c1: ──────────────├C──────────────────────├C──────────┤ c2: ──────────╭C──│───╭C──────────────╭C──│───╭C──────┤ c3: ──────╭C──│───│───│───╭C──────╭C──│───│───│───╭C──┤ c4: ──╭C──│───│───│───│───│───╭C──│───│───│───│───│───┤ w0: ──│───│───├C──╰X──├C──│───│───│───├C──╰X──├C──│───┤ w1: ──│───├C──╰X──────╰X──├C──│───├C──╰X──────╰X──├C──┤ w2: ──├C──╰X──────────────╰X──├C──╰X──────────────╰X──┤ t0: ──╰X──────────────────────╰X──────────────────────┤
Added
qml.CPhaseas an alias for the existingqml.ControlledPhaseShiftoperation. (#1319).The
Deviceclass now uses caching when mapping wires. (#1270)The
Wiresclass now uses caching for computing itshash. (#1270)Added custom gate application for Toffoli in
default.qubit. (#1249)Added validation for noise channel parameters. Invalid noise parameters now raise a
ValueError. (#1357)The device test suite now provides test cases for checking gates by comparing expectation values. (#1212)
PennyLane’s test suite is now code-formatted using
black -l 100. (#1222)PennyLane’s
qchempackage and tests are now code-formatted usingblack -l 100. (#1311)
Breaking changes
The
qml.inv()function is now deprecated with a warning to use the more generalqml.adjoint(). (#1325)Removes support for Python 3.6 and adds support for Python 3.9. (#1228)
The tape methods
get_resourcesandget_depthare superseded byspecsand will be deprecated after one release cycle. (#1245)Using the
qml.sample()measurement on devices withshots=Nonecontinue to raise a warning with this functionality being fully deprecated and raising an error after one release cycle. (#1079) (#1196)
Bug fixes
QNodes now display readable information when in interactive environments or when printed. (#1359).
Fixes a bug with
qml.math.castwhere theMottonenStatePreparationoperation expected a float type instead of double. (#1400)Fixes a bug where a copy of
qml.ControlledQubitUnitarywas non-functional as it did not have all the necessary information. (#1411)Warns when adjoint or reversible differentiation specified or called on a device with finite shots. (#1406)
Fixes the differentiability of the operations
IsingXXandIsingZZfor Autograd, Jax and Tensorflow. (#1390)Fixes a bug where multiple identical Hamiltonian terms will produce a different result with
optimize=TrueusingExpvalCost. (#1405)Fixes bug where
shots=Nonewas not reset when changing shots temporarily in a QNode call likecircuit(0.1, shots=3). (#1392)Fixes floating point errors with
diff_method="finite-diff"andorder=1when parameters arefloat32. (#1381)Fixes a bug where
qml.ctrlwould fail to transform gates that had no control defined and no decomposition defined. (#1376)Copying the
JacobianTapenow correctly also copies thejacobian_optionsattribute. This fixes a bug allowing the JAX interface to support adjoint differentiation. (#1349)Fixes drawing QNodes that contain multiple measurements on a single wire. (#1353)
Fixes drawing QNodes with no operations. (#1354)
Fixes incorrect wires in the decomposition of the
ControlledPhaseShiftoperation. (#1338)Fixed tests for the
Permuteoperation that used a QNode and hence expanded tapes twice instead of once due to QNode tape expansion and an explicit tape expansion call. (#1318).Prevent Hamiltonians that share wires from being multiplied together. (#1273)
Fixed a bug where the custom range sequences could not be passed to the
StronglyEntanglingLayerstemplate. (#1332)Fixed a bug where
qml.sum()andqml.dot()do not support the JAX interface. (#1380)
Documentation
Math present in the
QubitParamShiftTapeclass docstring now renders correctly. (#1402)Fix typo in the documentation of
qml.StronglyEntanglingLayers. (#1367)Fixed typo in TensorFlow interface documentation (#1312)
Fixed typos in the mathematical expressions in documentation of
qml.DoubleExcitation. (#1278)Remove unsupported
Noneoption from theqml.QNodedocstrings. (#1271)Updated the docstring of
qml.PolyXPto reference the new location of internal usage. (#1262)Removes occurrences of the deprecated device argument
analyticfrom the documentation. (#1261)Updated PyTorch and TensorFlow interface introductions. (#1333)
Updates the quantum chemistry quickstart to reflect recent changes to the
qchemmodule. (#1227)
Contributors
This release contains contributions from (in alphabetical order):
Marius Aglitoiu, Vishnu Ajith, Juan Miguel Arrazola, Thomas Bromley, Jack Ceroni, Alaric Cheng, Miruna Daian, Olivia Di Matteo, Tanya Garg, Christian Gogolin, Alain Delgado Gran, Diego Guala, Anthony Hayes, Ryan Hill, Theodor Isacsson, Josh Izaac, Soran Jahangiri, Pavan Jayasinha, Nathan Killoran, Christina Lee, Ryan Levy, Alberto Maldonado, Johannes Jakob Meyer, Romain Moyard, Ashish Panigrahi, Nahum Sá, Maria Schuld, Brian Shi, Antal Száva, David Wierichs, Vincent Wong.
Release 0.15.1¶
Bug fixes
Fixes two bugs in the parameter-shift Hessian. (#1260)
Fixes a bug where having an unused parameter in the Autograd interface would result in an indexing error during backpropagation.
The parameter-shift Hessian only supports the two-term parameter-shift rule currently, so raises an error if asked to differentiate any unsupported gates (such as the controlled rotation gates).
A bug which resulted in
qml.adjoint()andqml.inv()failing to work with templates has been fixed. (#1243)Deprecation warning instances in PennyLane have been changed to
UserWarning, to account for recent changes to how Python warnings are filtered in PEP565. (#1211)
Documentation
Updated the order of the parameters to the
GaussianStateoperation to match the way that the PennyLane-SF plugin uses them. (#1255)
Contributors
This release contains contributions from (in alphabetical order):
Thomas Bromley, Olivia Di Matteo, Diego Guala, Anthony Hayes, Ryan Hill, Josh Izaac, Christina Lee, Maria Schuld, Antal Száva.
Release 0.15.0¶
New features since last release
Better and more flexible shot control
Adds a new optimizer
qml.ShotAdaptiveOptimizer, a gradient-descent optimizer where the shot rate is adaptively calculated using the variances of the parameter-shift gradient. (#1139)By keeping a running average of the parameter-shift gradient and the variance of the parameter-shift gradient, this optimizer frugally distributes a shot budget across the partial derivatives of each parameter.
In addition, if computing the expectation value of a Hamiltonian, weighted random sampling can be used to further distribute the shot budget across the local terms from which the Hamiltonian is constructed.
This optimizer is based on both the iCANS1 and Rosalin shot-adaptive optimizers.
Once constructed, the cost function can be passed directly to the optimizer’s
stepmethod. The attributeopt.total_shots_usedcan be used to track the number of shots per iteration.>>> coeffs = [2, 4, -1, 5, 2] >>> obs = [ ... qml.PauliX(1), ... qml.PauliZ(1), ... qml.PauliX(0) @ qml.PauliX(1), ... qml.PauliY(0) @ qml.PauliY(1), ... qml.PauliZ(0) @ qml.PauliZ(1) ... ] >>> H = qml.Hamiltonian(coeffs, obs) >>> dev = qml.device("default.qubit", wires=2, shots=100) >>> cost = qml.ExpvalCost(qml.templates.StronglyEntanglingLayers, H, dev) >>> params = qml.init.strong_ent_layers_uniform(n_layers=2, n_wires=2) >>> opt = qml.ShotAdaptiveOptimizer(min_shots=10) >>> for i in range(5): ... params = opt.step(cost, params) ... print(f"Step {i}: cost = {cost(params):.2f}, shots_used = {opt.total_shots_used}") Step 0: cost = -5.68, shots_used = 240 Step 1: cost = -2.98, shots_used = 336 Step 2: cost = -4.97, shots_used = 624 Step 3: cost = -5.53, shots_used = 1054 Step 4: cost = -6.50, shots_used = 1798
Batches of shots can now be specified as a list, allowing measurement statistics to be course-grained with a single QNode evaluation. (#1103)
>>> shots_list = [5, 10, 1000] >>> dev = qml.device("default.qubit", wires=2, shots=shots_list)
When QNodes are executed on this device, a single execution of 1015 shots will be submitted. However, three sets of measurement statistics will be returned; using the first 5 shots, second set of 10 shots, and final 1000 shots, separately.
For example, executing a circuit with two outputs will lead to a result of shape
(3, 2):>>> @qml.qnode(dev) ... def circuit(x): ... qml.RX(x, wires=0) ... qml.CNOT(wires=[0, 1]) ... return qml.expval(qml.PauliZ(0) @ qml.PauliX(1)), qml.expval(qml.PauliZ(0)) >>> circuit(0.5) [[0.33333333 1. ] [0.2 1. ] [0.012 0.868 ]]
This output remains fully differentiable.
The number of shots can now be specified on a per-call basis when evaluating a QNode. (#1075).
For this, the qnode should be called with an additional
shotskeyword argument:>>> dev = qml.device('default.qubit', wires=1, shots=10) # default is 10 >>> @qml.qnode(dev) ... def circuit(a): ... qml.RX(a, wires=0) ... return qml.sample(qml.PauliZ(wires=0)) >>> circuit(0.8) [ 1 1 1 -1 -1 1 1 1 1 1] >>> circuit(0.8, shots=3) [ 1 1 1] >>> circuit(0.8) [ 1 1 1 -1 -1 1 1 1 1 1]
New differentiable quantum transforms
A new module is available, qml.transforms, which contains differentiable quantum transforms. These are functions that act on QNodes, quantum functions, devices, and tapes, transforming them while remaining fully differentiable.
A new adjoint transform has been added. (#1111) (#1135)
This new method allows users to apply the adjoint of an arbitrary sequence of operations.
def subroutine(wire): qml.RX(0.123, wires=wire) qml.RY(0.456, wires=wire) dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def circuit(): subroutine(0) qml.adjoint(subroutine)(0) return qml.expval(qml.PauliZ(0))
This creates the following circuit:
>>> print(qml.draw(circuit)()) 0: --RX(0.123)--RY(0.456)--RY(-0.456)--RX(-0.123)--| <Z>
Directly applying to a gate also works as expected.
qml.adjoint(qml.RX)(0.123, wires=0) # applies RX(-0.123)
A new transform
qml.ctrlis now available that adds control wires to subroutines. (#1157)def my_ansatz(params): qml.RX(params[0], wires=0) qml.RZ(params[1], wires=1) # Create a new operation that applies `my_ansatz` # controlled by the "2" wire. my_ansatz2 = qml.ctrl(my_ansatz, control=2) @qml.qnode(dev) def circuit(params): my_ansatz2(params) return qml.state()
This is equivalent to:
@qml.qnode(...) def circuit(params): qml.CRX(params[0], wires=[2, 0]) qml.CRZ(params[1], wires=[2, 1]) return qml.state()
The
qml.transforms.classical_jacobiantransform has been added. (#1186)This transform returns a function to extract the Jacobian matrix of the classical part of a QNode, allowing the classical dependence between the QNode arguments and the quantum gate arguments to be extracted.
For example, given the following QNode:
>>> @qml.qnode(dev) ... def circuit(weights): ... qml.RX(weights[0], wires=0) ... qml.RY(weights[0], wires=1) ... qml.RZ(weights[2] ** 2, wires=1) ... return qml.expval(qml.PauliZ(0))
We can use this transform to extract the relationship \(f: \mathbb{R}^n \rightarrow\mathbb{R}^m\) between the input QNode arguments \(w\) and the gate arguments \(g\), for a given value of the QNode arguments:
>>> cjac_fn = qml.transforms.classical_jacobian(circuit) >>> weights = np.array([1., 1., 1.], requires_grad=True) >>> cjac = cjac_fn(weights) >>> print(cjac) [[1. 0. 0.] [1. 0. 0.] [0. 0. 2.]]
The returned Jacobian has rows corresponding to gate arguments, and columns corresponding to QNode arguments; that is, \(J_{ij} = \frac{\partial}{\partial g_i} f(w_j)\).
More operations and templates
Added the
SingleExcitationtwo-qubit operation, which is useful for quantum chemistry applications. (#1121)It can be used to perform an SO(2) rotation in the subspace spanned by the states \(|01\rangle\) and \(|10\rangle\). For example, the following circuit performs the transformation \(|10\rangle \rightarrow \cos(\phi/2)|10\rangle - \sin(\phi/2)|01\rangle\):
dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(phi): qml.PauliX(wires=0) qml.SingleExcitation(phi, wires=[0, 1])
The
SingleExcitationoperation supports analytic gradients on hardware using only four expectation value calculations, following results from Kottmann et al.Added the
DoubleExcitationfour-qubit operation, which is useful for quantum chemistry applications. (#1123)It can be used to perform an SO(2) rotation in the subspace spanned by the states \(|1100\rangle\) and \(|0011\rangle\). For example, the following circuit performs the transformation \(|1100\rangle\rightarrow \cos(\phi/2)|1100\rangle - \sin(\phi/2)|0011\rangle\):
dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(phi): qml.PauliX(wires=0) qml.PauliX(wires=1) qml.DoubleExcitation(phi, wires=[0, 1, 2, 3])
The
DoubleExcitationoperation supports analytic gradients on hardware using only four expectation value calculations, following results from Kottmann et al..Added the
QuantumMonteCarlotemplate for performing quantum Monte Carlo estimation of an expectation value on simulator. (#1130)The following example shows how the expectation value of sine squared over a standard normal distribution can be approximated:
from scipy.stats import norm m = 5 M = 2 ** m n = 10 N = 2 ** n target_wires = range(m + 1) estimation_wires = range(m + 1, n + m + 1) xmax = np.pi # bound to region [-pi, pi] xs = np.linspace(-xmax, xmax, M) probs = np.array([norm().pdf(x) for x in xs]) probs /= np.sum(probs) func = lambda i: np.sin(xs[i]) ** 2 dev = qml.device("default.qubit", wires=(n + m + 1)) @qml.qnode(dev) def circuit(): qml.templates.QuantumMonteCarlo( probs, func, target_wires=target_wires, estimation_wires=estimation_wires, ) return qml.probs(estimation_wires) phase_estimated = np.argmax(circuit()[:int(N / 2)]) / N expectation_estimated = (1 - np.cos(np.pi * phase_estimated)) / 2
Added the
QuantumPhaseEstimationtemplate for performing quantum phase estimation for an input unitary matrix. (#1095)Consider the matrix corresponding to a rotation from an
RXgate:>>> phase = 5 >>> target_wires = [0] >>> unitary = qml.RX(phase, wires=0).matrix
The
phaseparameter can be estimated usingQuantumPhaseEstimation. For example, using five phase-estimation qubits:n_estimation_wires = 5 estimation_wires = range(1, n_estimation_wires + 1) dev = qml.device("default.qubit", wires=n_estimation_wires + 1) @qml.qnode(dev) def circuit(): # Start in the |+> eigenstate of the unitary qml.Hadamard(wires=target_wires) QuantumPhaseEstimation( unitary, target_wires=target_wires, estimation_wires=estimation_wires, ) return qml.probs(estimation_wires) phase_estimated = np.argmax(circuit()) / 2 ** n_estimation_wires # Need to rescale phase due to convention of RX gate phase_estimated = 4 * np.pi * (1 - phase)
Added the
ControlledPhaseShiftgate as well as theQFToperation for applying quantum Fourier transforms. (#1064)@qml.qnode(dev) def circuit_qft(basis_state): qml.BasisState(basis_state, wires=range(3)) qml.templates.QFT(wires=range(3)) return qml.state()
Added the
ControlledQubitUnitaryoperation. This enables implementation of multi-qubit gates with a variable number of control qubits. It is also possible to specify a different state for the control qubits using thecontrol_valuesargument (also known as a mixed-polarity multi-controlled operation). (#1069) (#1104)For example, we can create a multi-controlled T gate using:
T = qml.T._matrix() qml.ControlledQubitUnitary(T, control_wires=[0, 1, 3], wires=2, control_values="110")
Here, the T gate will be applied to wire
2if control wires0and1are in state1, and control wire3is in state0. If no value is passed tocontrol_values, the gate will be applied if all control wires are in the1state.Added
MultiControlledXfor multi-controlledNOTgates. This is a special case ofControlledQubitUnitarythat applies a Pauli X gate conditioned on the state of an arbitrary number of control qubits. (#1104)
Support for higher-order derivatives on hardware
Computing second derivatives and Hessians of QNodes is now supported with the parameter-shift differentiation method, on all machine learning interfaces. (#1130) (#1129) (#1110)
Hessians are computed using the parameter-shift rule, and can be evaluated on both hardware and simulator devices.
dev = qml.device('default.qubit', wires=1) @qml.qnode(dev, diff_method="parameter-shift") def circuit(p): qml.RY(p[0], wires=0) qml.RX(p[1], wires=0) return qml.expval(qml.PauliZ(0)) x = np.array([1.0, 2.0], requires_grad=True)
>>> hessian_fn = qml.jacobian(qml.grad(circuit)) >>> hessian_fn(x) [[0.2248451 0.7651474] [0.7651474 0.2248451]]
Added the function
finite_diff()to compute finite-difference approximations to the gradient and the second-order derivatives of arbitrary callable functions. (#1090)This is useful to compute the derivative of parametrized
pennylane.Hamiltonianobservables with respect to their parameters.For example, in quantum chemistry simulations it can be used to evaluate the derivatives of the electronic Hamiltonian with respect to the nuclear coordinates:
>>> def H(x): ... return qml.qchem.molecular_hamiltonian(['H', 'H'], x)[0] >>> x = np.array([0., 0., -0.66140414, 0., 0., 0.66140414]) >>> grad_fn = qml.finite_diff(H, N=1) >>> grad = grad_fn(x) >>> deriv2_fn = qml.finite_diff(H, N=2, idx=[0, 1]) >>> deriv2_fn(x)
The JAX interface now supports all devices, including hardware devices, via the parameter-shift differentiation method. (#1076)
For example, using the JAX interface with Cirq:
dev = qml.device('cirq.simulator', wires=1) @qml.qnode(dev, interface="jax", diff_method="parameter-shift") def circuit(x): qml.RX(x[1], wires=0) qml.Rot(x[0], x[1], x[2], wires=0) return qml.expval(qml.PauliZ(0)) weights = jnp.array([0.2, 0.5, 0.1]) print(circuit(weights))
Currently, when used with the parameter-shift differentiation method, only a single returned expectation value or variance is supported. Multiple expectations/variances, as well as probability and state returns, are not currently allowed.
Improvements
dev = qml.device("default.qubit", wires=2)
inputstate = [np.sqrt(0.2), np.sqrt(0.3), np.sqrt(0.4), np.sqrt(0.1)]
@qml.qnode(dev)
def circuit():
mottonen.MottonenStatePreparation(inputstate,wires=[0, 1])
return qml.expval(qml.PauliZ(0))
Previously returned:
>>> print(qml.draw(circuit)())
0: ──RY(1.57)──╭C─────────────╭C──╭C──╭C──┤ ⟨Z⟩
1: ──RY(1.35)──╰X──RY(0.422)──╰X──╰X──╰X──┤
In this release, it now returns:
>>> print(qml.draw(circuit)())
0: ──RY(1.57)──╭C─────────────╭C──┤ ⟨Z⟩
1: ──RY(1.35)──╰X──RY(0.422)──╰X──┤
The templates are now classes inheriting from
Operation, and define the ansatz in theirexpand()method. This change does not affect the user interface. (#1138) (#1156) (#1163) (#1192)For convenience, some templates have a new method that returns the expected shape of the trainable parameter tensor, which can be used to create random tensors.
shape = qml.templates.BasicEntanglerLayers.shape(n_layers=2, n_wires=4) weights = np.random.random(shape) qml.templates.BasicEntanglerLayers(weights, wires=range(4))
QubitUnitarynow validates to ensure the input matrix is two dimensional. (#1128)Most layers in Pytorch or Keras accept arbitrary dimension inputs, where each dimension barring the last (in the case where the actual weight function of the layer operates on one-dimensional vectors) is broadcast over. This is now also supported by KerasLayer and TorchLayer. (#1062).
Example use:
dev = qml.device("default.qubit", wires=4) x = tf.ones((5, 4, 4)) @qml.qnode(dev) def layer(weights, inputs): qml.templates.AngleEmbedding(inputs, wires=range(4)) qml.templates.StronglyEntanglingLayers(weights, wires=range(4)) return [qml.expval(qml.PauliZ(i)) for i in range(4)] qlayer = qml.qnn.KerasLayer(layer, {"weights": (4, 4, 3)}, output_dim=4) out = qlayer(x)
The output tensor has the following shape:
>>> out.shape (5, 4, 4)
If only one argument to the function
qml.gradhas therequires_gradattribute set to True, then the returned gradient will be a NumPy array, rather than a tuple of length 1. (#1067) (#1081)An improvement has been made to how
QubitDevicegenerates and post-processess samples, allowing QNode measurement statistics to work on devices with more than 32 qubits. (#1088)Due to the addition of
density_matrix()as a return type from a QNode, tuples are now supported by theoutput_dimparameter inqnn.KerasLayer. (#1070)Two new utility methods are provided for working with quantum tapes. (#1175)
qml.tape.get_active_tape()gets the currently recording tape.tape.stop_recording()is a context manager that temporarily stops the currently recording tape from recording additional tapes or quantum operations.
For example:
>>> with qml.tape.QuantumTape(): ... qml.RX(0, wires=0) ... current_tape = qml.tape.get_active_tape() ... with current_tape.stop_recording(): ... qml.RY(1.0, wires=1) ... qml.RZ(2, wires=1) >>> current_tape.operations [RX(0, wires=[0]), RZ(2, wires=[1])]
When printing
qml.Hamiltonianobjects, the terms are sorted by number of wires followed by coefficients. (#981)Adds
qml.math.conjto the PennyLane math module. (#1143)This new method will do elementwise conjugation to the given tensor-like object, correctly dispatching to the required tensor-manipulation framework to preserve differentiability.
>>> a = np.array([1.0 + 2.0j]) >>> qml.math.conj(a) array([1.0 - 2.0j])
The four-term parameter-shift rule, as used by the controlled rotation operations, has been updated to use coefficients that minimize the variance as per https://arxiv.org/abs/2104.05695. (#1206)
A new transform
qml.transforms.invisiblehas been added, to make it easier to transform QNodes. (#1175)
Breaking changes
Devices do not have an
analyticargument or attribute anymore. Instead,shotsis the source of truth for whether a simulator estimates return values from a finite number of shots, or whether it returns analytic results (shots=None). (#1079) (#1196)dev_analytic = qml.device('default.qubit', wires=1, shots=None) dev_finite_shots = qml.device('default.qubit', wires=1, shots=1000) def circuit(): qml.Hadamard(wires=0) return qml.expval(qml.PauliZ(wires=0)) circuit_analytic = qml.QNode(circuit, dev_analytic) circuit_finite_shots = qml.QNode(circuit, dev_finite_shots)
Devices with
shots=Nonereturn deterministic, exact results:>>> circuit_analytic() 0.0 >>> circuit_analytic() 0.0
Devices with
shots > 0return stochastic results estimated from samples in each run:>>> circuit_finite_shots() -0.062 >>> circuit_finite_shots() 0.034
The
qml.sample()measurement can only be used on devices on which the number of shots is set explicitly.If creating a QNode from a quantum function with an argument named
shots, aUserWarningis raised, warning the user that this is a reserved argument to change the number of shots on a per-call basis. (#1075)For devices inheriting from
QubitDevice, the methodsexpval,var,sampleaccept two new keyword arguments —shot_rangeandbin_size. (#1103)These new arguments allow for the statistics to be performed on only a subset of device samples. This finer level of control is accessible from the main UI by instantiating a device with a batch of shots.
For example, consider the following device:
>>> dev = qml.device("my_device", shots=[5, (10, 3), 100])
This device will execute QNodes using 135 shots, however measurement statistics will be course grained across these 135 shots:
All measurement statistics will first be computed using the first 5 shots — that is,
shots_range=[0, 5],bin_size=5.Next, the tuple
(10, 3)indicates 10 shots, repeated 3 times. This will useshot_range=[5, 35], performing the expectation value in bins of size 10 (bin_size=10).Finally, we repeat the measurement statistics for the final 100 shots,
shot_range=[35, 135],bin_size=100.
The old PennyLane core has been removed, including the following modules: (#1100)
pennylane.variablespennylane.qnodes
As part of this change, the location of the new core within the Python module has been moved:
Moves
pennylane.tape.interfaces→pennylane.interfacesMerges
pennylane.CircuitGraphandpennylane.TapeCircuitGraph→pennylane.CircuitGraphMerges
pennylane.OperationRecorderandpennylane.TapeOperationRecorder→pennylane.tape.operation_recorderMerges
pennylane.measureandpennylane.tape.measure→pennylane.measureMerges
pennylane.operationandpennylane.tape.operation→pennylane.operationMerges
pennylane._queuingandpennylane.tape.queuing→pennylane.queuing
This has no affect on import location.
In addition,
All tape-mode functions have been removed (
qml.enable_tape(),qml.tape_mode_active()),All tape fixtures have been deleted,
Tests specifically for non-tape mode have been deleted.
The device test suite no longer accepts the
analytickeyword. (#1216)
Bug fixes
Fixes a bug where using the circuit drawer with a
ControlledQubitUnitaryoperation raised an error. (#1174)Fixes a bug and a test where the
QuantumTape.is_sampledattribute was not being updated. (#1126)Fixes a bug where
BasisEmbeddingwould not accept inputs whose bits are all ones or all zeros. (#1114)The
ExpvalCostclass raises an error if instantiated with non-expectation measurement statistics. (#1106)Fixes a bug where decompositions would reset the differentiation method of a QNode. (#1117)
Fixes a bug where the second-order CV parameter-shift rule would error if attempting to compute the gradient of a QNode with more than one second-order observable. (#1197)
Fixes a bug where repeated Torch interface applications after expansion caused an error. (#1223)
Sampling works correctly with batches of shots specified as a list. (#1232)
Documentation
Updated the diagram used in the Architectural overview page of the Development guide such that it doesn’t mention Variables. (#1235)
Typos addressed in templates documentation. (#1094)
Upgraded the documentation to use Sphinx 3.5.3 and the new m2r2 package. (#1186)
Added
flakyas dependency for running tests in the documentation. (#1113)
Contributors
This release contains contributions from (in alphabetical order):
Shahnawaz Ahmed, Juan Miguel Arrazola, Thomas Bromley, Olivia Di Matteo, Alain Delgado Gran, Kyle Godbey, Diego Guala, Theodor Isacsson, Josh Izaac, Soran Jahangiri, Nathan Killoran, Christina Lee, Daniel Polatajko, Chase Roberts, Sankalp Sanand, Pritish Sehzpaul, Maria Schuld, Antal Száva, David Wierichs.
Release 0.14.1¶
Bug fixes
Fixes a testing bug where tests that required JAX would fail if JAX was not installed. The tests will now instead be skipped if JAX can not be imported. (#1066)
Fixes a bug where inverse operations could not be differentiated using backpropagation on
default.qubit. (#1072)The QNode has a new keyword argument,
max_expansion, that determines the maximum number of times the internal circuit should be expanded when executed on a device. In addition, the default number of max expansions has been increased from 2 to 10, allowing devices that require more than two operator decompositions to be supported. (#1074)Fixes a bug where
Hamiltonianobjects created with non-list arguments raised an error for arithmetic operations. (#1082)Fixes a bug where
Hamiltonianobjects with no coefficients or operations would return a faulty result when used withExpvalCost. (#1082)
Documentation
Updates mentions of
generate_hamiltoniantomolecular_hamiltonianin the docstrings of theExpvalCostandHamiltonianclasses. (#1077)
Contributors
This release contains contributions from (in alphabetical order):
Thomas Bromley, Josh Izaac, Antal Száva.
Release 0.14.0¶
New features since last release
Perform quantum machine learning with JAX
QNodes created with
default.qubitnow support a JAX interface, allowing JAX to be used to create, differentiate, and optimize hybrid quantum-classical models. (#947)This is supported internally via a new
default.qubit.jaxdevice. This device runs end to end in JAX, meaning that it supports all of the awesome JAX transformations (jax.vmap,jax.jit,jax.hessian, etc).Here is an example of how to use the new JAX interface:
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="jax", diff_method="backprop") def circuit(x): qml.RX(x[1], wires=0) qml.Rot(x[0], x[1], x[2], wires=0) return qml.expval(qml.PauliZ(0)) weights = jnp.array([0.2, 0.5, 0.1]) grad_fn = jax.grad(circuit) print(grad_fn(weights))
Currently, only
diff_method="backprop"is supported, with plans to support more in the future.
New, faster, quantum gradient methods
A new differentiation method has been added for use with simulators. The
"adjoint"method operates after a forward pass by iteratively applying inverse gates to scan backwards through the circuit. (#1032)This method is similar to the reversible method, but has a lower time overhead and a similar memory overhead. It follows the approach provided by Jones and Gacon. This method is only compatible with certain statevector-based devices such as
default.qubit.Example use:
import pennylane as qml wires = 1 device = qml.device("default.qubit", wires=wires) @qml.qnode(device, diff_method="adjoint") def f(params): qml.RX(0.1, wires=0) qml.Rot(*params, wires=0) qml.RX(-0.3, wires=0) return qml.expval(qml.PauliZ(0)) params = [0.1, 0.2, 0.3] qml.grad(f)(params)
The default logic for choosing the ‘best’ differentiation method has been altered to improve performance. (#1008)
If the quantum device provides its own gradient, this is now the preferred differentiation method.
If the quantum device natively supports classical backpropagation, this is now preferred over the parameter-shift rule.
This will lead to marked speed improvement during optimization when using
default.qubit, with a sight penalty on the forward-pass evaluation.
More details are available below in the ‘Improvements’ section for plugin developers.
PennyLane now supports analytical quantum gradients for noisy channels, in addition to its existing support for unitary operations. The noisy channels
BitFlip,PhaseFlip, andDepolarizingChannelall support analytic gradients out of the box. (#968)A method has been added for calculating the Hessian of quantum circuits using the second-order parameter shift formula. (#961)
The following example shows the calculation of the Hessian:
n_wires = 5 weights = [2.73943676, 0.16289932, 3.4536312, 2.73521126, 2.6412488] dev = qml.device("default.qubit", wires=n_wires) with qml.tape.QubitParamShiftTape() as tape: for i in range(n_wires): qml.RX(weights[i], wires=i) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[2, 1]) qml.CNOT(wires=[3, 1]) qml.CNOT(wires=[4, 3]) qml.expval(qml.PauliZ(1)) print(tape.hessian(dev))
The Hessian is not yet supported via classical machine learning interfaces, but will be added in a future release.
More operations and templates
Two new error channels,
BitFlipandPhaseFliphave been added. (#954)They can be used in the same manner as existing error channels:
dev = qml.device("default.mixed", wires=2) @qml.qnode(dev) def circuit(): qml.RX(0.3, wires=0) qml.RY(0.5, wires=1) qml.BitFlip(0.01, wires=0) qml.PhaseFlip(0.01, wires=1) return qml.expval(qml.PauliZ(0))
Apply permutations to wires using the
Permutesubroutine. (#952)import pennylane as qml dev = qml.device('default.qubit', wires=5) @qml.qnode(dev) def apply_perm(): # Send contents of wire 4 to wire 0, of wire 2 to wire 1, etc. qml.templates.Permute([4, 2, 0, 1, 3], wires=dev.wires) return qml.expval(qml.PauliZ(0))
QNode transformations
The
qml.metric_tensorfunction transforms a QNode to produce the Fubini-Study metric tensor with full autodifferentiation support—even on hardware. (#1014)Consider the following QNode:
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev, interface="autograd") def circuit(weights): # layer 1 qml.RX(weights[0, 0], wires=0) qml.RX(weights[0, 1], wires=1) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[1, 2]) # layer 2 qml.RZ(weights[1, 0], wires=0) qml.RZ(weights[1, 1], wires=2) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[1, 2]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)), qml.expval(qml.PauliY(2))
We can use the
metric_tensorfunction to generate a new function, that returns the metric tensor of this QNode:>>> met_fn = qml.metric_tensor(circuit) >>> weights = np.array([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]], requires_grad=True) >>> met_fn(weights) tensor([[0.25 , 0. , 0. , 0. ], [0. , 0.25 , 0. , 0. ], [0. , 0. , 0.0025, 0.0024], [0. , 0. , 0.0024, 0.0123]], requires_grad=True)
The returned metric tensor is also fully differentiable, in all interfaces. For example, differentiating the
(3, 2)element:>>> grad_fn = qml.grad(lambda x: met_fn(x)[3, 2]) >>> grad_fn(weights) array([[ 0.04867729, -0.00049502, 0. ], [ 0. , 0. , 0. ]])
Differentiation is also supported using Torch, Jax, and TensorFlow.
Adds the new function
qml.math.cov_matrix(). This function accepts a list of commuting observables, and the probability distribution in the shared observable eigenbasis after the application of an ansatz. It uses these to construct the covariance matrix in a framework independent manner, such that the output covariance matrix is autodifferentiable. (#1012)For example, consider the following ansatz and observable list:
obs_list = [qml.PauliX(0) @ qml.PauliZ(1), qml.PauliY(2)] ansatz = qml.templates.StronglyEntanglingLayers
We can construct a QNode to output the probability distribution in the shared eigenbasis of the observables:
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev, interface="autograd") def circuit(weights): ansatz(weights, wires=[0, 1, 2]) # rotate into the basis of the observables for o in obs_list: o.diagonalizing_gates() return qml.probs(wires=[0, 1, 2])
We can now compute the covariance matrix:
>>> weights = qml.init.strong_ent_layers_normal(n_layers=2, n_wires=3) >>> cov = qml.math.cov_matrix(circuit(weights), obs_list) >>> cov array([[0.98707611, 0.03665537], [0.03665537, 0.99998377]])
Autodifferentiation is fully supported using all interfaces:
>>> cost_fn = lambda weights: qml.math.cov_matrix(circuit(weights), obs_list)[0, 1] >>> qml.grad(cost_fn)(weights)[0] array([[[ 4.94240914e-17, -2.33786398e-01, -1.54193959e-01], [-3.05414996e-17, 8.40072236e-04, 5.57884080e-04], [ 3.01859411e-17, 8.60411436e-03, 6.15745204e-04]], [[ 6.80309533e-04, -1.23162742e-03, 1.08729813e-03], [-1.53863193e-01, -1.38700657e-02, -1.36243323e-01], [-1.54665054e-01, -1.89018172e-02, -1.56415558e-01]]])
A new
qml.drawfunction is available, allowing QNodes to be easily drawn without execution by providing example input. (#962)@qml.qnode(dev) def circuit(a, w): qml.Hadamard(0) qml.CRX(a, wires=[0, 1]) qml.Rot(*w, wires=[1]) qml.CRX(-a, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
The QNode circuit structure may depend on the input arguments; this is taken into account by passing example QNode arguments to the
qml.draw()drawing function:>>> drawer = qml.draw(circuit) >>> result = drawer(a=2.3, w=[1.2, 3.2, 0.7]) >>> print(result) 0: ──H──╭C────────────────────────────╭C─────────╭┤ ⟨Z ⊗ Z⟩ 1: ─────╰RX(2.3)──Rot(1.2, 3.2, 0.7)──╰RX(-2.3)──╰┤ ⟨Z ⊗ Z⟩
A faster, leaner, and more flexible core
The new core of PennyLane, rewritten from the ground up and developed over the last few release cycles, has achieved feature parity and has been made the new default in PennyLane v0.14. The old core has been marked as deprecated, and will be removed in an upcoming release. (#1046) (#1040) (#1034) (#1035) (#1027) (#1026) (#1021) (#1054) (#1049)
While high-level PennyLane code and tutorials remain unchanged, the new core provides several advantages and improvements:
Faster and more optimized: The new core provides various performance optimizations, reducing pre- and post-processing overhead, and reduces the number of quantum evaluations in certain cases.
Support for in-QNode classical processing: this allows for differentiable classical processing within the QNode.
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="tf") def circuit(p): qml.RX(tf.sin(p[0])**2 + p[1], wires=0) return qml.expval(qml.PauliZ(0))
The classical processing functions used within the QNode must match the QNode interface. Here, we use TensorFlow:
>>> params = tf.Variable([0.5, 0.1], dtype=tf.float64) >>> with tf.GradientTape() as tape: ... res = circuit(params) >>> grad = tape.gradient(res, params) >>> print(res) tf.Tensor(0.9460913127754935, shape=(), dtype=float64) >>> print(grad) tf.Tensor([-0.27255248 -0.32390003], shape=(2,), dtype=float64)
As a result of this change, quantum decompositions that require classical processing are fully supported and end-to-end differentiable in tape mode.
No more Variable wrapping: QNode arguments no longer become
Variableobjects within the QNode.dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): print("Parameter value:", x) qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
Internal QNode parameters can be easily inspected, printed, and manipulated:
>>> circuit(0.5) Parameter value: 0.5 tensor(0.87758256, requires_grad=True)
Less restrictive QNode signatures: There is no longer any restriction on the QNode signature; the QNode can be defined and called following the same rules as standard Python functions.
For example, the following QNode uses positional, named, and variable keyword arguments:
x = torch.tensor(0.1, requires_grad=True) y = torch.tensor([0.2, 0.3], requires_grad=True) z = torch.tensor(0.4, requires_grad=True) @qml.qnode(dev, interface="torch") def circuit(p1, p2=y, **kwargs): qml.RX(p1, wires=0) qml.RY(p2[0] * p2[1], wires=0) qml.RX(kwargs["p3"], wires=0) return qml.var(qml.PauliZ(0))
When we call the QNode, we may pass the arguments by name even if defined positionally; any argument not provided will use the default value.
>>> res = circuit(p1=x, p3=z) >>> print(res) tensor(0.2327, dtype=torch.float64, grad_fn=<SelectBackward>) >>> res.backward() >>> print(x.grad, y.grad, z.grad) tensor(0.8396) tensor([0.0289, 0.0193]) tensor(0.8387)
This extends to the
qnnmodule, whereKerasLayerandTorchLayermodules can be created from QNodes with unrestricted signatures.Smarter measurements: QNodes can now measure wires more than once, as long as all observables are commuting:
@qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return [ qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) ]
Further, the
qml.ExpvalCost()function allows for optimizing measurements to reduce the number of quantum evaluations required.
With the new PennyLane core, there are a few small breaking changes, detailed below in the ‘Breaking Changes’ section.
Improvements
The built-in PennyLane optimizers allow more flexible cost functions. The cost function passed to most optimizers may accept any combination of trainable arguments, non-trainable arguments, and keyword arguments. (#959) (#1053)
The full changes apply to:
AdagradOptimizerAdamOptimizerGradientDescentOptimizerMomentumOptimizerNesterovMomentumOptimizerRMSPropOptimizerRotosolveOptimizer
The
requires_grad=Falseproperty must mark any non-trainable constant argument. TheRotoselectOptimizerallows passing only keyword arguments.Example use:
def cost(x, y, data, scale=1.0): return scale * (x[0]-data)**2 + scale * (y-data)**2 x = np.array([1.], requires_grad=True) y = np.array([1.0]) data = np.array([2.], requires_grad=False) opt = qml.GradientDescentOptimizer() # the optimizer step and step_and_cost methods can # now update multiple parameters at once x_new, y_new, data = opt.step(cost, x, y, data, scale=0.5) (x_new, y_new, data), value = opt.step_and_cost(cost, x, y, data, scale=0.5) # list and tuple unpacking is also supported params = (x, y, data) params = opt.step(cost, *params)
The circuit drawer has been updated to support the inclusion of unused or inactive wires, by passing the
show_all_wiresargument. (#1033)dev = qml.device('default.qubit', wires=[-1, "a", "q2", 0]) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=-1) qml.CNOT(wires=[-1, "q2"]) return qml.expval(qml.PauliX(wires="q2"))
>>> print(qml.draw(circuit, show_all_wires=True)()) >>> -1: ──H──╭C──┤ a: ─────│───┤ q2: ─────╰X──┤ ⟨X⟩ 0: ─────────┤
The logic for choosing the ‘best’ differentiation method has been altered to improve performance. (#1008)
If the device provides its own gradient, this is now the preferred differentiation method.
If a device provides additional interface-specific versions that natively support classical backpropagation, this is now preferred over the parameter-shift rule.
Devices define additional interface-specific devices via their
capabilities()dictionary. For example,default.qubitsupports supplementary devices for TensorFlow, Autograd, and JAX:{ "passthru_devices": { "tf": "default.qubit.tf", "autograd": "default.qubit.autograd", "jax": "default.qubit.jax", }, }
As a result of this change, if the QNode
diff_methodis not explicitly provided, it is possible that the QNode will run on a supplementary device of the device that was specifically provided:dev = qml.device("default.qubit", wires=2) qml.QNode(dev) # will default to backprop on default.qubit.autograd qml.QNode(dev, interface="tf") # will default to backprop on default.qubit.tf qml.QNode(dev, interface="jax") # will default to backprop on default.qubit.jax
The
default.qubitdevice has been updated so that internally it applies operations in a more functional style, i.e., by accepting an input state and returning an evolved state. (#1025)A new test series,
pennylane/devices/tests/test_compare_default_qubit.py, has been added, allowing to test if a chosen device gives the same result asdefault.qubit. (#897)Three tests are added:
test_hermitian_expectation,test_pauliz_expectation_analytic, andtest_random_circuit.
Adds the following agnostic tensor manipulation functions to the
qml.mathmodule:abs,angle,arcsin,concatenate,dot,squeeze,sqrt,sum,take,where. These functions are required to fully support end-to-end differentiable Mottonen and Amplitude embedding. (#922) (#1011)The
qml.mathmodule now supports JAX. (#985)Several improvements have been made to the
Wiresclass to reduce overhead and simplify the logic of how wire labels are interpreted: (#1019) (#1010) (#1005) (#983) (#967)If the input
wiresto a wires class instantiationWires(wires)can be iterated over, its elements are interpreted as wire labels. Otherwise,wiresis interpreted as a single wire label. The only exception to this are strings, which are always interpreted as a single wire label, so users can address wires with labels such as"ancilla".Any type can now be a wire label as long as it is hashable. The hash is used to establish the uniqueness of two labels.
Indexing wires objects now returns a label, instead of a new
Wiresobject. For example:>>> w = Wires([0, 1, 2]) >>> w[1] >>> 1
The check for uniqueness of wires moved from
Wiresinstantiation to theqml.wires._processfunction in order to reduce overhead from repeated creation ofWiresinstances.Calls to the
Wiresclass are substantially reduced, for example by avoiding to call Wires on Wires instances onOperationinstantiation, and by using labels instead ofWiresobjects inside the default qubit device.
Adds the
PauliRotgenerator to theqml.operationmodule. This generator is required to construct the metric tensor. (#963)The templates are modified to make use of the new
qml.mathmodule, for framework-agnostic tensor manipulation. This allows the template library to be differentiable in backpropagation mode (diff_method="backprop"). (#873)The circuit drawer now allows for the wire order to be (optionally) modified: (#992)
>>> dev = qml.device('default.qubit', wires=["a", -1, "q2"]) >>> @qml.qnode(dev) ... def circuit(): ... qml.Hadamard(wires=-1) ... qml.CNOT(wires=["a", "q2"]) ... qml.RX(0.2, wires="a") ... return qml.expval(qml.PauliX(wires="q2"))
Printing with default wire order of the device:
>>> print(circuit.draw()) a: ─────╭C──RX(0.2)──┤ -1: ──H──│────────────┤ q2: ─────╰X───────────┤ ⟨X⟩
Changing the wire order:
>>> print(circuit.draw(wire_order=["q2", "a", -1])) q2: ──╭X───────────┤ ⟨X⟩ a: ──╰C──RX(0.2)──┤ -1: ───H───────────┤
Breaking changes
QNodes using the new PennyLane core will no longer accept ragged arrays as inputs.
When using the new PennyLane core and the Autograd interface, non-differentiable data passed as a QNode argument or a gate must have the
requires_gradproperty set toFalse:@qml.qnode(dev) def circuit(weights, data): basis_state = np.array([1, 0, 1, 1], requires_grad=False) qml.BasisState(basis_state, wires=[0, 1, 2, 3]) qml.templates.AmplitudeEmbedding(data, wires=[0, 1, 2, 3]) qml.templates.BasicEntanglerLayers(weights, wires=[0, 1, 2, 3]) return qml.probs(wires=0) data = np.array(data, requires_grad=False) weights = np.array(weights, requires_grad=True) circuit(weights, data)
Bug fixes
Fixes an issue where if the constituent observables of a tensor product do not exist in the queue, an error is raised. With this fix, they are first queued before annotation occurs. (#1038)
Fixes an issue with tape expansions where information about sampling (specifically the
is_sampledtape attribute) was not preserved. (#1027)Tape expansion was not properly taking into devices that supported inverse operations, causing inverse operations to be unnecessarily decomposed. The QNode tape expansion logic, as well as the
Operation.expand()method, has been modified to fix this. (#956)Fixes an issue where the Autograd interface was not unwrapping non-differentiable PennyLane tensors, which can cause issues on some devices. (#941)
qml.vqe.Hamiltonianprints any observable with any number of strings. (#987)Fixes a bug where parameter-shift differentiation would fail if the QNode contained a single probability output. (#1007)
Fixes an issue when using trainable parameters that are lists/arrays with
tape.vjp. (#1042)The
TensorNobservable is updated to support being copied without any parameters or wires passed. (#1047)Fixed deprecation warning when importing
Sequencefromcollectionsinstead ofcollections.abcinvqe/vqe.py. (#1051)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Thomas Bromley, Olivia Di Matteo, Theodor Isacsson, Josh Izaac, Christina Lee, Alejandro Montanez, Steven Oud, Chase Roberts, Sankalp Sanand, Maria Schuld, Antal Száva, David Wierichs, Jiahao Yao.
Release 0.13.0¶
New features since last release
Automatically optimize the number of measurements
QNodes in tape mode now support returning observables on the same wire whenever the observables are qubit-wise commuting Pauli words. Qubit-wise commuting observables can be evaluated with a single device run as they are diagonal in the same basis, via a shared set of single-qubit rotations. (#882)
The following example shows a single QNode returning the expectation values of the qubit-wise commuting Pauli words
XXandXI:qml.enable_tape() @qml.qnode(dev) def f(x): qml.Hadamard(wires=0) qml.Hadamard(wires=1) qml.CRot(0.1, 0.2, 0.3, wires=[1, 0]) qml.RZ(x, wires=1) return qml.expval(qml.PauliX(0) @ qml.PauliX(1)), qml.expval(qml.PauliX(0))
>>> f(0.4) tensor([0.89431013, 0.9510565 ], requires_grad=True)
The
ExpvalCostclass (previouslyVQECost) now provides observable optimization using theoptimizeargument, resulting in potentially fewer device executions. (#902)This is achieved by separating the observables composing the Hamiltonian into qubit-wise commuting groups and evaluating those groups on a single QNode using functionality from the
qml.groupingmodule:qml.enable_tape() commuting_obs = [qml.PauliX(0), qml.PauliX(0) @ qml.PauliZ(1)] H = qml.vqe.Hamiltonian([1, 1], commuting_obs) dev = qml.device("default.qubit", wires=2) ansatz = qml.templates.StronglyEntanglingLayers cost_opt = qml.ExpvalCost(ansatz, H, dev, optimize=True) cost_no_opt = qml.ExpvalCost(ansatz, H, dev, optimize=False) params = qml.init.strong_ent_layers_uniform(3, 2)
Grouping these commuting observables leads to fewer device executions:
>>> cost_opt(params) >>> ex_opt = dev.num_executions >>> cost_no_opt(params) >>> ex_no_opt = dev.num_executions - ex_opt >>> print("Number of executions:", ex_no_opt) Number of executions: 2 >>> print("Number of executions (optimized):", ex_opt) Number of executions (optimized): 1
New quantum gradient features
Compute the analytic gradient of quantum circuits in parallel on supported devices. (#840)
This release introduces support for batch execution of circuits, via a new device API method
Device.batch_execute(). Devices that implement this new API support submitting a batch of circuits for parallel evaluation simultaneously, which can significantly reduce the computation time.Furthermore, if using tape mode and a compatible device, gradient computations will automatically make use of the new batch API—providing a speedup during optimization.
Gradient recipes are now much more powerful, allowing for operations to define their gradient via an arbitrary linear combination of circuit evaluations. (#909) (#915)
With this change, gradient recipes can now be of the form \(\frac{\partial}{\partial\phi_k}f(\phi_k) = \sum_{i} c_i f(a_i \phi_k + s_i )\), and are no longer restricted to two-term shifts with identical (but opposite in sign) shift values.
As a result, PennyLane now supports native analytic quantum gradients for the controlled rotation operations
CRX,CRY,CRZ, andCRot. This allows for parameter-shift analytic gradients on hardware, without decomposition.Note that this is a breaking change for developers; please see the Breaking Changes section for more details.
The
qnn.KerasLayerclass now supports differentiating the QNode through classical backpropagation in tape mode. (#869)qml.enable_tape() dev = qml.device("default.qubit.tf", wires=2) @qml.qnode(dev, interface="tf", diff_method="backprop") def f(inputs, weights): qml.templates.AngleEmbedding(inputs, wires=range(2)) qml.templates.StronglyEntanglingLayers(weights, wires=range(2)) return [qml.expval(qml.PauliZ(i)) for i in range(2)] weight_shapes = {"weights": (3, 2, 3)} qlayer = qml.qnn.KerasLayer(f, weight_shapes, output_dim=2) inputs = tf.constant(np.random.random((4, 2)), dtype=tf.float32) with tf.GradientTape() as tape: out = qlayer(inputs) tape.jacobian(out, qlayer.trainable_weights)
New operations, templates, and measurements
Adds the
qml.density_matrixQNode return with partial trace capabilities. (#878)The density matrix over the provided wires is returned, with all other subsystems traced out.
qml.density_matrixcurrently works for both thedefault.qubitanddefault.mixeddevices.qml.enable_tape() dev = qml.device("default.qubit", wires=2) def circuit(x): qml.PauliY(wires=0) qml.Hadamard(wires=1) return qml.density_matrix(wires=[1]) # wire 0 is traced out
Adds the square-root X gate
SX. (#871)dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(): qml.SX(wires=[0]) return qml.expval(qml.PauliZ(wires=[0]))
Two new hardware-efficient particle-conserving templates have been implemented to perform VQE-based quantum chemistry simulations. The new templates apply several layers of the particle-conserving entanglers proposed in Figs. 2a and 2b of Barkoutsos et al., arXiv:1805.04340 (#875) (#876)
Estimate and track resources
The
QuantumTapeclass now contains basic resource estimation functionality. The methodtape.get_resources()returns a dictionary with a list of the constituent operations and the number of times they appear in the circuit. Similarly,tape.get_depth()computes the circuit depth. (#862)>>> with qml.tape.QuantumTape() as tape: ... qml.Hadamard(wires=0) ... qml.RZ(0.26, wires=1) ... qml.CNOT(wires=[1, 0]) ... qml.Rot(1.8, -2.7, 0.2, wires=0) ... qml.Hadamard(wires=1) ... qml.CNOT(wires=[0, 1]) ... qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) >>> tape.get_resources() {'Hadamard': 2, 'RZ': 1, 'CNOT': 2, 'Rot': 1} >>> tape.get_depth() 4
The number of device executions over a QNode’s lifetime can now be returned using
num_executions. (#853)>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit(x, y): ... qml.RX(x, wires=[0]) ... qml.RY(y, wires=[1]) ... qml.CNOT(wires=[0, 1]) ... return qml.expval(qml.PauliZ(0) @ qml.PauliX(1)) >>> for _ in range(10): ... circuit(0.432, 0.12) >>> print(dev.num_executions) 10
Improvements
Support for tape mode has improved across PennyLane. The following features now work in tape mode:
A new function,
qml.refresh_devices(), has been added, allowing PennyLane to rescan installed PennyLane plugins and refresh the device list. In addition, theqml.deviceloader will attempt to refresh devices if the required plugin device cannot be found. This will result in an improved experience if installing PennyLane and plugins within a running Python session (for example, on Google Colab), and avoid the need to restart the kernel/runtime. (#907)When using
grad_fn = qml.grad(cost)to compute the gradient of a cost function with the Autograd interface, the value of the intermediate forward pass is now available via thegrad_fn.forwardproperty (#914):def cost_fn(x, y): return 2 * np.sin(x[0]) * np.exp(-x[1]) + x[0] ** 3 + np.cos(y) params = np.array([0.1, 0.5], requires_grad=True) data = np.array(0.65, requires_grad=False) grad_fn = qml.grad(cost_fn) grad_fn(params, data) # perform backprop and evaluate the gradient grad_fn.forward # the cost function value
Gradient-based optimizers now have a
step_and_costmethod that returns both the next step as well as the objective (cost) function output. (#916)>>> opt = qml.GradientDescentOptimizer() >>> params, cost = opt.step_and_cost(cost_fn, params)
PennyLane provides a new experimental module
qml.procwhich provides framework-agnostic processing functions for array and tensor manipulations. (#886)Given the input tensor-like object, the call is dispatched to the corresponding array manipulation framework, allowing for end-to-end differentiation to be preserved.
>>> x = torch.tensor([1., 2.]) >>> qml.proc.ones_like(x) tensor([1, 1]) >>> y = tf.Variable([[0], [5]]) >>> qml.proc.ones_like(y, dtype=np.complex128) <tf.Tensor: shape=(2, 1), dtype=complex128, numpy= array([[1.+0.j], [1.+0.j]])>
Note that these functions are experimental, and only a subset of common functionality is supported. Furthermore, the names and behaviour of these functions may differ from similar functions in common frameworks; please refer to the function docstrings for more details.
The gradient methods in tape mode now fully separate the quantum and classical processing. Rather than returning the evaluated gradients directly, they now return a tuple containing the required quantum and classical processing steps. (#840)
def gradient_method(idx, param, **options): # generate the quantum tapes that must be computed # to determine the quantum gradient tapes = quantum_gradient_tapes(self) def processing_fn(results): # perform classical processing on the evaluated tapes # returning the evaluated quantum gradient return classical_processing(results) return tapes, processing_fn
The
JacobianTape.jacobian()method has been similarly modified to accumulate all gradient quantum tapes and classical processing functions, evaluate all quantum tapes simultaneously, and then apply the post-processing functions to the evaluated tape results.The MultiRZ gate now has a defined generator, allowing it to be used in quantum natural gradient optimization. (#912)
The CRot gate now has a
decompositionmethod, which breaks the gate down into rotations and CNOT gates. This allowsCRotto be used on devices that do not natively support it. (#908)The classical processing in the
MottonenStatePreparationtemplate has been largely rewritten to use dense matrices and tensor manipulations wherever possible. This is in preparation to support differentiation through the template in the future. (#864)Device-based caching has replaced QNode caching. Caching is now accessed by passing a
cacheargument to the device. (#851)The
cacheargument should be an integer specifying the size of the cache. For example, a cache of size 10 is created using:>>> dev = qml.device("default.qubit", wires=2, cache=10)
The
Operation,Tensor, andMeasurementProcessclasses now have the__copy__special method defined. (#840)This allows us to ensure that, when a shallow copy is performed of an operation, the mutable list storing the operation parameters is also shallow copied. Both the old operation and the copied operation will continue to share the same parameter data,
>>> import copy >>> op = qml.RX(0.2, wires=0) >>> op2 = copy.copy(op) >>> op.data[0] is op2.data[0] True
however the list container is not a reference:
>>> op.data is op2.data False
This allows the parameters of the copied operation to be modified, without mutating the parameters of the original operation.
The
QuantumTape.copymethod has been tweaked so that (#840):Optionally, the tape’s operations are shallow copied in addition to the tape by passing the
copy_operations=Trueboolean flag. This allows the copied tape’s parameters to be mutated without affecting the original tape’s parameters. (Note: the two tapes will share parameter data until one of the tapes has their parameter list modified.)Copied tapes can be cast to another
QuantumTapesubclass by passing thetape_clskeyword argument.
Breaking changes
Updated how parameter-shift gradient recipes are defined for operations, allowing for gradient recipes that are specified as an arbitrary number of terms. (#909)
Previously,
Operation.grad_recipewas restricted to two-term parameter-shift formulas. With this change, the gradient recipe now contains elements of the form \([c_i, a_i, s_i]\), resulting in a gradient recipe of \(\frac{\partial}{\partial\phi_k}f(\phi_k) = \sum_{i} c_i f(a_i \phi_k + s_i )\).As this is a breaking change, all custom operations with defined gradient recipes must be updated to continue working with PennyLane 0.13. Note though that if
grad_recipe = None, the default gradient recipe remains unchanged, and corresponds to the two terms \([c_0, a_0, s_0]=[1/2, 1, \pi/2]\) and \([c_1, a_1, s_1]=[-1/2, 1, -\pi/2]\) for every parameter.The
VQECostclass has been renamed toExpvalCostto reflect its general applicability beyond VQE. Use ofVQECostis still possible but will result in a deprecation warning. (#913)
Bug fixes
The
default.qubit.tfdevice is updated to handle TensorFlow objects (e.g.,tf.Variable) as gate parameters correctly when using theMultiRZandCRotoperations. (#921)PennyLane tensor objects are now unwrapped in BaseQNode when passed as a keyword argument to the quantum function. (#903) (#893)
The new tape mode now prevents multiple observables from being evaluated on the same wire if the observables are not qubit-wise commuting Pauli words. (#882)
Fixes a bug in
default.qubitwhereby inverses of common gates were not being applied via efficient gate-specific methods, instead falling back to matrix-vector multiplication. The following gates were affected:PauliX,PauliY,PauliZ,Hadamard,SWAP,S,T,CNOT,CZ. (#872)The
PauliRotoperation now gracefully handles single-qubit Paulis, and all-identity Paulis (#860).Fixes a bug whereby binary Python operators were not properly propagating the
requires_gradattribute to the output tensor. (#889)Fixes a bug which prevents
TorchLayerfrom doingbackwardwhen CUDA is enabled. (#899)Fixes a bug where multi-threaded execution of
QNodeCollectionsometimes fails because of simultaneous queuing. This is fixed by adding thread locking during queuing. (#910)Fixes a bug in
QuantumTape.set_parameters(). The previous implementation assumed that theself.trainable_parmsset would always be iterated over in increasing integer order. However, this is not guaranteed behaviour, and can lead to the incorrect tape parameters being set if this is not the case. (#923)Fixes broken error message if a QNode is instantiated with an unknown exception. (#930)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Thomas Bromley, Christina Lee, Alain Delgado Gran, Olivia Di Matteo, Anthony Hayes, Theodor Isacsson, Josh Izaac, Soran Jahangiri, Nathan Killoran, Shumpei Kobayashi, Romain Moyard, Zeyue Niu, Maria Schuld, Antal Száva.
Release 0.12.0¶
New features since last release
New and improved simulators
PennyLane now supports a new device,
default.mixed, designed for simulating mixed-state quantum computations. This enables native support for implementing noisy channels in a circuit, which generally map pure states to mixed states. (#794) (#807) (#819)The device can be initialized as
>>> dev = qml.device("default.mixed", wires=1)
This allows the construction of QNodes that include non-unitary operations, such as noisy channels:
>>> @qml.qnode(dev) ... def circuit(params): ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.AmplitudeDamping(0.5, wires=0) ... return qml.expval(qml.PauliZ(0)) >>> print(circuit([0.54, 0.12])) 0.9257702929524184 >>> print(circuit([0, np.pi])) 0.0
New tools for optimizing measurements
The new
groupingmodule provides functionality for grouping simultaneously measurable Pauli word observables. (#761) (#850) (#852)The
optimize_measurementsfunction will take as input a list of Pauli word observables and their corresponding coefficients (if any), and will return the partitioned Pauli terms diagonalized in the measurement basis and the corresponding diagonalizing circuits.from pennylane.grouping import optimize_measurements h, nr_qubits = qml.qchem.molecular_hamiltonian("h2", "h2.xyz") rotations, grouped_ops, grouped_coeffs = optimize_measurements(h.ops, h.coeffs, grouping="qwc")
The diagonalizing circuits of
rotationscorrespond to the diagonalized Pauli word groupings ofgrouped_ops.Pauli word partitioning utilities are performed by the
PauliGroupingStrategyclass. An input list of Pauli words can be partitioned into mutually commuting, qubit-wise-commuting, or anticommuting groupings.For example, partitioning Pauli words into anticommutative groupings by the Recursive Largest First (RLF) graph colouring heuristic:
from pennylane import PauliX, PauliY, PauliZ, Identity from pennylane.grouping import group_observables pauli_words = [ Identity('a') @ Identity('b'), Identity('a') @ PauliX('b'), Identity('a') @ PauliY('b'), PauliZ('a') @ PauliX('b'), PauliZ('a') @ PauliY('b'), PauliZ('a') @ PauliZ('b') ] groupings = group_observables(pauli_words, grouping_type='anticommuting', method='rlf')
Various utility functions are included for obtaining and manipulating Pauli words in the binary symplectic vector space representation.
For instance, two Pauli words may be converted to their binary vector representation:
>>> from pennylane.grouping import pauli_to_binary >>> from pennylane.wires import Wires >>> wire_map = {Wires('a'): 0, Wires('b'): 1} >>> pauli_vec_1 = pauli_to_binary(qml.PauliX('a') @ qml.PauliY('b')) >>> pauli_vec_2 = pauli_to_binary(qml.PauliZ('a') @ qml.PauliZ('b')) >>> pauli_vec_1 [1. 1. 0. 1.] >>> pauli_vec_2 [0. 0. 1. 1.]
Their product up to a phase may be computed by taking the sum of their binary vector representations, and returned in the operator representation.
>>> from pennylane.grouping import binary_to_pauli >>> binary_to_pauli((pauli_vec_1 + pauli_vec_2) % 2, wire_map) Tensor product ['PauliY', 'PauliX']: 0 params, wires ['a', 'b']
For more details on the grouping module, see the grouping module documentation
Returning the quantum state from simulators
The quantum state of a QNode can now be returned using the
qml.state()return function. (#818)import pennylane as qml dev = qml.device("default.qubit", wires=3) qml.enable_tape() @qml.qnode(dev) def qfunc(x, y): qml.RZ(x, wires=0) qml.CNOT(wires=[0, 1]) qml.RY(y, wires=1) qml.CNOT(wires=[0, 2]) return qml.state() >>> qfunc(0.56, 0.1) array([0.95985437-0.27601028j, 0. +0.j , 0.04803275-0.01381203j, 0. +0.j , 0. +0.j , 0. +0.j , 0. +0.j , 0. +0.j ])
Differentiating the state is currently available when using the classical backpropagation differentiation method (
diff_method="backprop") with a compatible device, and when using the new tape mode.
New operations and channels
PennyLane now includes standard channels such as the Amplitude-damping, Phase-damping, and Depolarizing channels, as well as the ability to make custom qubit channels. (#760) (#766) (#778)
The controlled-Y operation is now available via
qml.CY. For devices that do not natively support the controlled-Y operation, it will be decomposed intoqml.RY,qml.CNOT, andqml.Soperations. (#806)
Preview the next-generation PennyLane QNode
The new PennyLane
tapemodule provides a re-formulated QNode class, rewritten from the ground-up, that uses a newQuantumTapeobject to represent the QNode’s quantum circuit. Tape mode provides several advantages over the standard PennyLane QNode. (#785) (#792) (#796) (#800) (#803) (#804) (#805) (#808) (#810) (#811) (#815) (#820) (#823) (#824) (#829)Support for in-QNode classical processing: Tape mode allows for differentiable classical processing within the QNode.
No more Variable wrapping: In tape mode, QNode arguments no longer become
Variableobjects within the QNode.Less restrictive QNode signatures: There is no longer any restriction on the QNode signature; the QNode can be defined and called following the same rules as standard Python functions.
Unifying all QNodes: The tape-mode QNode merges all QNodes (including the
JacobianQNodeand thePassthruQNode) into a single unified QNode, with identical behaviour regardless of the differentiation type.Optimizations: Tape mode provides various performance optimizations, reducing pre- and post-processing overhead, and reduces the number of quantum evaluations in certain cases.
Note that tape mode is experimental, and does not currently have feature-parity with the existing QNode. Feedback and bug reports are encouraged and will help improve the new tape mode.
Tape mode can be enabled globally via the
qml.enable_tapefunction, without changing your PennyLane code:qml.enable_tape() dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="tf") def circuit(p): print("Parameter value:", p) qml.RX(tf.sin(p[0])**2 + p[1], wires=0) return qml.expval(qml.PauliZ(0))
For more details, please see the tape mode documentation.
Improvements
QNode caching has been introduced, allowing the QNode to keep track of the results of previous device executions and reuse those results in subsequent calls. Note that QNode caching is only supported in the new and experimental tape-mode. (#817)
Caching is available by passing a
cachingargument to the QNode:dev = qml.device("default.qubit", wires=2) qml.enable_tape() @qml.qnode(dev, caching=10) # cache up to 10 evaluations def qfunc(x): qml.RX(x, wires=0) qml.RX(0.3, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(1)) qfunc(0.1) # first evaluation executes on the device qfunc(0.1) # second evaluation accesses the cached result
Sped up the application of certain gates in
default.qubitby using array/tensor manipulation tricks. The following gates are affected:PauliX,PauliY,PauliZ,Hadamard,SWAP,S,T,CNOT,CZ. (#772)The computation of marginal probabilities has been made more efficient for devices with a large number of wires, achieving in some cases a 5x speedup. (#799)
Adds arithmetic operations (addition, tensor product, subtraction, and scalar multiplication) between
Hamiltonian,Tensor, andObservableobjects, and inline arithmetic operations between Hamiltonians and other observables. (#765)Hamiltonians can now easily be defined as sums of observables:
>>> H = 3 * qml.PauliZ(0) - (qml.PauliX(0) @ qml.PauliX(1)) + qml.Hamiltonian([4], [qml.PauliZ(0)]) >>> print(H) (7.0) [Z0] + (-1.0) [X0 X1]
Adds
compare()method toObservableandHamiltonianclasses, which allows for comparison between observable quantities. (#765)>>> H = qml.Hamiltonian([1], [qml.PauliZ(0)]) >>> obs = qml.PauliZ(0) @ qml.Identity(1) >>> print(H.compare(obs)) True
>>> H = qml.Hamiltonian([2], [qml.PauliZ(0)]) >>> obs = qml.PauliZ(1) @ qml.Identity(0) >>> print(H.compare(obs)) False
Adds
simplify()method to theHamiltonianclass. (#765)>>> H = qml.Hamiltonian([1, 2], [qml.PauliZ(0), qml.PauliZ(0) @ qml.Identity(1)]) >>> H.simplify() >>> print(H) (3.0) [Z0]
Added a new bit-flip mixer to the
qml.qaoamodule. (#774)Summation of two
Wiresobjects is now supported and will return aWiresobject containing the set of all wires defined by the terms in the summation. (#812)
Breaking changes
The PennyLane NumPy module now returns scalar (zero-dimensional) arrays where Python scalars were previously returned. (#820) (#833)
For example, this affects array element indexing, and summation:
>>> x = np.array([1, 2, 3], requires_grad=False) >>> x[0] tensor(1, requires_grad=False) >>> np.sum(x) tensor(6, requires_grad=True)
This may require small updates to user code. A convenience method,
np.tensor.unwrap(), has been added to help ease the transition. This converts PennyLane NumPy tensors to standard NumPy arrays and Python scalars:>>> x = np.array(1.543, requires_grad=False) >>> x.unwrap() 1.543
Note, however, that information regarding array differentiability will be lost.
The device capabilities dictionary has been redesigned, for clarity and robustness. In particular, the capabilities dictionary is now inherited from the parent class, various keys have more expressive names, and all keys are now defined in the base device class. For more details, please refer to the developer documentation. (#781)
Bug fixes
Changed to use lists for storing variable values inside
BaseQNodeallowing complex matrices to be passed toQubitUnitary. (#773)Fixed a bug within
default.qubit, resulting in greater efficiency when applying a state vector to all wires on the device. (#849)
Documentation
Equations have been added to the
qml.sampleandqml.probsdocstrings to clarify the mathematical foundation of the performed measurements. (#843)
Contributors
This release contains contributions from (in alphabetical order):
Aroosa Ijaz, Juan Miguel Arrazola, Thomas Bromley, Jack Ceroni, Alain Delgado Gran, Josh Izaac, Soran Jahangiri, Nathan Killoran, Robert Lang, Cedric Lin, Olivia Di Matteo, Nicolás Quesada, Maria Schuld, Antal Száva.
Release 0.11.0¶
New features since last release
New and improved simulators
Added a new device,
default.qubit.autograd, a pure-state qubit simulator written using Autograd. This device supports classical backpropagation (diff_method="backprop"); this can be faster than the parameter-shift rule for computing quantum gradients when the number of parameters to be optimized is large. (#721)>>> dev = qml.device("default.qubit.autograd", wires=1) >>> @qml.qnode(dev, diff_method="backprop") ... def circuit(x): ... qml.RX(x[1], wires=0) ... qml.Rot(x[0], x[1], x[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> weights = np.array([0.2, 0.5, 0.1]) >>> grad_fn = qml.grad(circuit) >>> print(grad_fn(weights)) array([-2.25267173e-01, -1.00864546e+00, 6.93889390e-18])
See the device documentation for more details.
A new experimental C++ state-vector simulator device is now available,
lightning.qubit. It uses the C++ Eigen library to perform fast linear algebra calculations for simulating quantum state-vector evolution.lightning.qubitis currently in beta; it can be installed viapip:$ pip install pennylane-lightning
Once installed, it can be used as a PennyLane device:
>>> dev = qml.device("lightning.qubit", wires=2)
For more details, please see the lightning qubit documentation.
New algorithms and templates
Added built-in QAOA functionality via the new
qml.qaoamodule. (#712) (#718) (#741) (#720)This includes the following features:
New
qml.qaoa.x_mixerandqml.qaoa.xy_mixerfunctions for defining Pauli-X and XY mixer Hamiltonians.MaxCut: The
qml.qaoa.maxcutfunction allows easy construction of the cost Hamiltonian and recommended mixer Hamiltonian for solving the MaxCut problem for a supplied graph.Layers:
qml.qaoa.cost_layerandqml.qaoa.mixer_layertake cost and mixer Hamiltonians, respectively, and apply the corresponding QAOA cost and mixer layers to the quantum circuit
For example, using PennyLane to construct and solve a MaxCut problem with QAOA:
wires = range(3) graph = Graph([(0, 1), (1, 2), (2, 0)]) cost_h, mixer_h = qaoa.maxcut(graph) def qaoa_layer(gamma, alpha): qaoa.cost_layer(gamma, cost_h) qaoa.mixer_layer(alpha, mixer_h) def antatz(params, **kwargs): for w in wires: qml.Hadamard(wires=w) # repeat the QAOA layer two times qml.layer(qaoa_layer, 2, params[0], params[1]) dev = qml.device('default.qubit', wires=len(wires)) cost_function = qml.VQECost(ansatz, cost_h, dev)
Added an
ApproxTimeEvolutiontemplate to the PennyLane templates module, which can be used to implement Trotterized time-evolution under a Hamiltonian. (#710)
Added a
qml.layertemplate-constructing function, which takes a unitary, and repeatedly applies it on a set of wires to a given depth. (#723)def subroutine(): qml.Hadamard(wires=[0]) qml.CNOT(wires=[0, 1]) qml.PauliX(wires=[1]) dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(): qml.layer(subroutine, 3) return [qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1))]
This creates the following circuit:
>>> circuit() >>> print(circuit.draw()) 0: ──H──╭C──X──H──╭C──X──H──╭C──X──┤ ⟨Z⟩ 1: ─────╰X────────╰X────────╰X─────┤ ⟨Z⟩
Added the
qml.utils.decompose_hamiltonianfunction. This function can be used to decompose a Hamiltonian into a linear combination of Pauli operators. (#671)>>> A = np.array( ... [[-2, -2+1j, -2, -2], ... [-2-1j, 0, 0, -1], ... [-2, 0, -2, -1], ... [-2, -1, -1, 0]]) >>> coeffs, obs_list = decompose_hamiltonian(A)
New device features
It is now possible to specify custom wire labels, such as
['anc1', 'anc2', 0, 1, 3], where the labels can be strings or numbers. (#666)Custom wire labels are defined by passing a list to the
wiresargument when creating the device:>>> dev = qml.device("default.qubit", wires=['anc1', 'anc2', 0, 1, 3])
Quantum operations should then be invoked with these custom wire labels:
>>> @qml.qnode(dev) >>> def circuit(): ... qml.Hadamard(wires='anc2') ... qml.CNOT(wires=['anc1', 3]) ... ...
The existing behaviour, in which the number of wires is specified on device initialization, continues to work as usual. This gives a default behaviour where wires are labelled by consecutive integers.
>>> dev = qml.device("default.qubit", wires=5)
An integrated device test suite has been added, which can be used to run basic integration tests on core or external devices. (#695) (#724) (#733)
The test can be invoked against a particular device by calling the
pl-device-testcommand line program:$ pl-device-test --device=default.qubit --shots=1234 --analytic=False
If the tests are run on external devices, the device and its dependencies must be installed locally. For more details, please see the plugin test documentation.
Improvements
The functions implementing the quantum circuits building the Unitary Coupled-Cluster (UCCSD) VQE ansatz have been improved, with a more consistent naming convention and improved docstrings. (#748)
The changes include:
The terms 1particle-1hole (ph) and 2particle-2hole (pphh) excitations were replaced with the names single and double excitations, respectively.
The non-differentiable arguments in the
UCCSDtemplate were renamed accordingly:ph→s_wires,pphh→d_wiresThe term virtual, previously used to refer the unoccupied orbitals, was discarded.
The Usage Details sections were updated and improved.
Added support for TensorFlow 2.3 and PyTorch 1.6. (#725)
Returning probabilities is now supported from photonic QNodes. As with qubit QNodes, photonic QNodes returning probabilities are end-to-end differentiable. (#699)
>>> dev = qml.device("strawberryfields.fock", wires=2, cutoff_dim=5) >>> @qml.qnode(dev) ... def circuit(a): ... qml.Displacement(a, 0, wires=0) ... return qml.probs(wires=0) >>> print(circuit(0.5)) [7.78800783e-01 1.94700196e-01 2.43375245e-02 2.02812704e-03 1.26757940e-04]
Breaking changes
The
pennylane.pluginsandpennylane.beta.pluginsfolders have been renamed topennylane.devicesandpennylane.beta.devices, to reflect their content better. (#726)
Bug fixes
The PennyLane interface conversion functions can now convert QNodes with pre-existing interfaces. (#707)
Documentation
The interfaces section of the documentation has been renamed to ‘Interfaces and training’, and updated with the latest variable handling details. (#753)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Thomas Bromley, Jack Ceroni, Alain Delgado Gran, Shadab Hussain, Theodor Isacsson, Josh Izaac, Nathan Killoran, Maria Schuld, Antal Száva, Nicola Vitucci.
Release 0.10.0¶
New features since last release
New and improved simulators
Added a new device,
default.qubit.tf, a pure-state qubit simulator written using TensorFlow. As a result, it supports classical backpropagation as a means to compute the Jacobian. This can be faster than the parameter-shift rule for computing quantum gradients when the number of parameters to be optimized is large.default.qubit.tfis designed to be used with end-to-end classical backpropagation (diff_method="backprop") with the TensorFlow interface. This is the default method of differentiation when creating a QNode with this device.Using this method, the created QNode is a ‘white-box’ that is tightly integrated with your TensorFlow computation, including AutoGraph support:
>>> dev = qml.device("default.qubit.tf", wires=1) >>> @tf.function ... @qml.qnode(dev, interface="tf", diff_method="backprop") ... def circuit(x): ... qml.RX(x[1], wires=0) ... qml.Rot(x[0], x[1], x[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> weights = tf.Variable([0.2, 0.5, 0.1]) >>> with tf.GradientTape() as tape: ... res = circuit(weights) >>> print(tape.gradient(res, weights)) tf.Tensor([-2.2526717e-01 -1.0086454e+00 1.3877788e-17], shape=(3,), dtype=float32)
See the
default.qubit.tfdocumentation for more details.The default.tensor plugin has been significantly upgraded. It now allows two different tensor network representations to be used:
"exact"and"mps". The former uses a exact factorized representation of quantum states, while the latter uses a matrix product state representation. (#572) (#599)
New machine learning functionality and integrations
PennyLane QNodes can now be converted into Torch layers, allowing for creation of quantum and hybrid models using the
torch.nnAPI. (#588)A PennyLane QNode can be converted into a
torch.nnlayer using theqml.qnn.TorchLayerclass:>>> @qml.qnode(dev) ... def qnode(inputs, weights_0, weight_1): ... # define the circuit ... # ... >>> weight_shapes = {"weights_0": 3, "weight_1": 1} >>> qlayer = qml.qnn.TorchLayer(qnode, weight_shapes)
A hybrid model can then be easily constructed:
>>> model = torch.nn.Sequential(qlayer, torch.nn.Linear(2, 2))
Added a new “reversible” differentiation method which can be used in simulators, but not hardware.
The reversible approach is similar to backpropagation, but trades off extra computation for enhanced memory efficiency. Where backpropagation caches the state tensors at each step during a simulated evolution, the reversible method only caches the final pre-measurement state.
Compared to the parameter-shift method, the reversible method can be faster or slower, depending on the density and location of parametrized gates in a circuit (circuits with higher density of parametrized gates near the end of the circuit will see a benefit). (#670)
>>> dev = qml.device("default.qubit", wires=2) ... @qml.qnode(dev, diff_method="reversible") ... def circuit(x): ... qml.RX(x, wires=0) ... qml.RX(x, wires=0) ... qml.CNOT(wires=[0,1]) ... return qml.expval(qml.PauliZ(0)) >>> qml.grad(circuit)(0.5) (array(-0.47942554),)
New templates and cost functions
Added the new templates
UCCSD,SingleExcitationUnitary, andDoubleExcitationUnitary, which together implement the Unitary Coupled-Cluster Singles and Doubles (UCCSD) ansatz to perform VQE-based quantum chemistry simulations using PennyLane-QChem. (#622) (#638) (#654) (#659) (#622)Added module
pennylane.qnn.costwith classSquaredErrorLoss. The module contains classes to calculate losses and cost functions on circuits with trainable parameters. (#642)
Improvements
Improves the wire management by making the
Operator.wiresattribute awiresobject. (#666)A significant improvement with respect to how QNodes and interfaces mark quantum function arguments as differentiable when using Autograd, designed to improve performance and make QNodes more intuitive. (#648) (#650)
In particular, the following changes have been made:
A new
ndarraysubclasspennylane.numpy.tensor, which extends NumPy arrays with the keyword argument and attributerequires_grad. Tensors which haverequires_grad=Falseare treated as non-differentiable by the Autograd interface.A new subpackage
pennylane.numpy, which wrapsautograd.numpysuch that NumPy functions accept therequires_gradkeyword argument, and allows Autograd to differentiatepennylane.numpy.tensorobjects.The
argnumargument toqml.gradis now optional; if not provided, arguments explicitly marked asrequires_grad=Falseare excluded for the list of differentiable arguments. The ability to passargnumhas been retained for backwards compatibility, and if present the old behaviour persists.
The QNode Torch interface now inspects QNode positional arguments. If any argument does not have the attribute
requires_grad=True, it is automatically excluded from quantum gradient computations. (#652) (#660)The QNode TF interface now inspects QNode positional arguments. If any argument is not being watched by a
tf.GradientTape(), it is automatically excluded from quantum gradient computations. (#655) (#660)QNodes have two new public methods:
QNode.set_trainable_args()andQNode.get_trainable_args(). These are designed to be called by interfaces, to specify to the QNode which of its input arguments are differentiable. Arguments which are non-differentiable will not be converted to PennyLane Variable objects within the QNode. (#660)Added
decompositionmethod to PauliX, PauliY, PauliZ, S, T, Hadamard, and PhaseShift gates, which decomposes each of these gates into rotation gates. (#668)The
CircuitGraphclass now supports serializing contained circuit operations and measurement basis rotations to an OpenQASM2.0 script via the newCircuitGraph.to_openqasm()method. (#623)
Breaking changes
Removes support for Python 3.5. (#639)
Documentation
Various small typos were fixed.
Contributors
This release contains contributions from (in alphabetical order):
Thomas Bromley, Jack Ceroni, Alain Delgado Gran, Theodor Isacsson, Josh Izaac, Nathan Killoran, Maria Schuld, Antal Száva, Nicola Vitucci.
Release 0.9.0¶
New features since last release
New machine learning integrations
PennyLane QNodes can now be converted into Keras layers, allowing for creation of quantum and hybrid models using the Keras API. (#529)
A PennyLane QNode can be converted into a Keras layer using the
KerasLayerclass:from pennylane.qnn import KerasLayer @qml.qnode(dev) def circuit(inputs, weights_0, weight_1): # define the circuit # ... weight_shapes = {"weights_0": 3, "weight_1": 1} qlayer = qml.qnn.KerasLayer(circuit, weight_shapes, output_dim=2)
A hybrid model can then be easily constructed:
model = tf.keras.models.Sequential([qlayer, tf.keras.layers.Dense(2)])
Added a new type of QNode,
qml.qnodes.PassthruQNode. For simulators which are coded in an external library which supports automatic differentiation, PennyLane will treat a PassthruQNode as a “white box”, and rely on the external library to directly provide gradients via backpropagation. This can be more efficient than the using parameter-shift rule for a large number of parameters. (#488)Currently this behaviour is supported by PennyLane’s
default.tensor.tfdevice backend, compatible with the'tf'interface using TensorFlow 2:dev = qml.device('default.tensor.tf', wires=2) @qml.qnode(dev, diff_method="backprop") def circuit(params): qml.RX(params[0], wires=0) qml.RX(params[1], wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)) qnode = PassthruQNode(circuit, dev) params = tf.Variable([0.3, 0.1]) with tf.GradientTape() as tape: tape.watch(params) res = qnode(params) grad = tape.gradient(res, params)
New optimizers
Added the
qml.RotosolveOptimizer, a gradient-free optimizer that minimizes the quantum function by updating each parameter, one-by-one, via a closed-form expression while keeping other parameters fixed. (#636) (#539)Added the
qml.RotoselectOptimizer, which uses Rotosolve to minimizes a quantum function with respect to both the rotation operations applied and the rotation parameters. (#636) (#539)For example, given a quantum function
fthat accepts parametersxand a list of corresponding rotation operationsgenerators, the Rotoselect optimizer will, at each step, update both the parameter values and the list of rotation gates to minimize the loss:>>> opt = qml.optimize.RotoselectOptimizer() >>> x = [0.3, 0.7] >>> generators = [qml.RX, qml.RY] >>> for _ in range(100): ... x, generators = opt.step(f, x, generators)
New operations
Added the
PauliRotgate, which performs an arbitrary Pauli rotation on multiple qubits, and theMultiRZgate, which performs a rotation generated by a tensor product of Pauli Z operators. (#559)dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) def circuit(angle): qml.PauliRot(angle, "IXYZ", wires=[0, 1, 2, 3]) return [qml.expval(qml.PauliZ(wire)) for wire in [0, 1, 2, 3]]
>>> circuit(0.4) [1. 0.92106099 0.92106099 1. ] >>> print(circuit.draw()) 0: ──╭RI(0.4)──┤ ⟨Z⟩ 1: ──├RX(0.4)──┤ ⟨Z⟩ 2: ──├RY(0.4)──┤ ⟨Z⟩ 3: ──╰RZ(0.4)──┤ ⟨Z⟩
If the
PauliRotgate is not supported on the target device, it will be decomposed intoHadamard,RXandMultiRZgates. Note that identity gates in the Pauli word result in untouched wires:>>> print(circuit.draw()) 0: ───────────────────────────────────┤ ⟨Z⟩ 1: ──H──────────╭RZ(0.4)──H───────────┤ ⟨Z⟩ 2: ──RX(1.571)──├RZ(0.4)──RX(-1.571)──┤ ⟨Z⟩ 3: ─────────────╰RZ(0.4)──────────────┤ ⟨Z⟩
If the
MultiRZgate is not supported, it will be decomposed intoCNOTandRZgates:>>> print(circuit.draw()) 0: ──────────────────────────────────────────────────┤ ⟨Z⟩ 1: ──H──────────────╭X──RZ(0.4)──╭X──────H───────────┤ ⟨Z⟩ 2: ──RX(1.571)──╭X──╰C───────────╰C──╭X──RX(-1.571)──┤ ⟨Z⟩ 3: ─────────────╰C───────────────────╰C──────────────┤ ⟨Z⟩
PennyLane now provides
DiagonalQubitUnitaryfor diagonal gates, that are e.g., encountered in IQP circuits. These kinds of gates can be evaluated much faster on a simulator device. (#567)The gate can be used, for example, to efficiently simulate oracles:
dev = qml.device('default.qubit', wires=3) # Function as a bitstring f = np.array([1, 0, 0, 1, 1, 0, 1, 0]) @qml.qnode(dev) def circuit(weights1, weights2): qml.templates.StronglyEntanglingLayers(weights1, wires=[0, 1, 2]) # Implements the function as a phase-kickback oracle qml.DiagonalQubitUnitary((-1)**f, wires=[0, 1, 2]) qml.templates.StronglyEntanglingLayers(weights2, wires=[0, 1, 2]) return [qml.expval(qml.PauliZ(w)) for w in range(3)]
Added the
TensorNCVObservable that can represent the tensor product of theNumberOperatoron photonic backends. (#608)
New templates
Added the
ArbitraryUnitaryandArbitraryStatePreparationtemplates, which usePauliRotgates to perform an arbitrary unitary and prepare an arbitrary basis state with the minimal number of parameters. (#590)dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(weights1, weights2): qml.templates.ArbitraryStatePreparation(weights1, wires=[0, 1, 2]) qml.templates.ArbitraryUnitary(weights2, wires=[0, 1, 2]) return qml.probs(wires=[0, 1, 2])
Added the
IQPEmbeddingtemplate, which encodes inputs into the diagonal gates of an IQP circuit. (#605)
Added the
SimplifiedTwoDesigntemplate, which implements the circuit design of Cerezo et al. (2020). (#556)
Added the
BasicEntanglerLayerstemplate, which is a simple layer architecture of rotations and CNOT nearest-neighbour entanglers. (#555)
PennyLane now offers a broadcasting function to easily construct templates:
qml.broadcast()takes single quantum operations or other templates and applies them to wires in a specific pattern. (#515) (#522) (#526) (#603)For example, we can use broadcast to repeat a custom template across multiple wires:
from pennylane.templates import template @template def mytemplate(pars, wires): qml.Hadamard(wires=wires) qml.RY(pars, wires=wires) dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(pars): qml.broadcast(mytemplate, pattern="single", wires=[0,1,2], parameters=pars) return qml.expval(qml.PauliZ(0))
>>> circuit([1, 1, 0.1]) -0.841470984807896 >>> print(circuit.draw()) 0: ──H──RY(1.0)──┤ ⟨Z⟩ 1: ──H──RY(1.0)──┤ 2: ──H──RY(0.1)──┤
For other available patterns, see the broadcast function documentation.
Breaking changes
The
QAOAEmbeddingnow uses the newMultiRZgate as aZZentangler, which changes the convention. While previously, theZZgate in the embedding was implemented asCNOT(wires=[wires[0], wires[1]]) RZ(2 * parameter, wires=wires[0]) CNOT(wires=[wires[0], wires[1]])
the
MultiRZcorresponds toCNOT(wires=[wires[1], wires[0]]) RZ(parameter, wires=wires[0]) CNOT(wires=[wires[1], wires[0]])
which differs in the factor of
2, and fixes a bug in the wires that theCNOTwas applied to. (#609)Probability methods are handled by
QubitDeviceand device method requirements are modified to simplify plugin development. (#573)The internal variables
AllandAnyto mark anOperationas acting on all or any wires have been renamed toAllWiresandAnyWires. (#614)
Improvements
A new
Wiresclass was introduced for the internal bookkeeping of wire indices. (#615)Improvements to the speed/performance of the
default.qubitdevice. (#567) (#559)Added the
"backprop"and"device"differentiation methods to theqnodedecorator. (#552)"backprop": Use classical backpropagation. Default on simulator devices that are classically end-to-end differentiable. The returned QNode can only be used with the same machine learning framework (e.g.,default.tensor.tfsimulator with thetensorflowinterface)."device": Queries the device directly for the gradient.
Using the
"backprop"differentiation method with thedefault.tensor.tfdevice, the created QNode is a ‘white-box’, and is tightly integrated with the overall TensorFlow computation:>>> dev = qml.device("default.tensor.tf", wires=1) >>> @qml.qnode(dev, interface="tf", diff_method="backprop") >>> def circuit(x): ... qml.RX(x[1], wires=0) ... qml.Rot(x[0], x[1], x[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> vars = tf.Variable([0.2, 0.5, 0.1]) >>> with tf.GradientTape() as tape: ... res = circuit(vars) >>> tape.gradient(res, vars) <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-2.2526717e-01, -1.0086454e+00, 1.3877788e-17], dtype=float32)>
The circuit drawer now displays inverted operations, as well as wires where probabilities are returned from the device: (#540)
>>> @qml.qnode(dev) ... def circuit(theta): ... qml.RX(theta, wires=0) ... qml.CNOT(wires=[0, 1]) ... qml.S(wires=1).inv() ... return qml.probs(wires=[0, 1]) >>> circuit(0.2) array([0.99003329, 0. , 0. , 0.00996671]) >>> print(circuit.draw()) 0: ──RX(0.2)──╭C───────╭┤ Probs 1: ───────────╰X──S⁻¹──╰┤ Probs
You can now evaluate the metric tensor of a VQE Hamiltonian via the new
VQECost.metric_tensormethod. This allowsVQECostobjects to be directly optimized by the quantum natural gradient optimizer (qml.QNGOptimizer). (#618)The input check functions in
pennylane.templates.utilsare now public and visible in the API documentation. (#566)Added keyword arguments for step size and order to the
qnodedecorator, as well as theQNodeandJacobianQNodeclasses. This enables the user to set the step size and order when using finite difference methods. These options are also exposed when creating QNode collections. (#530) (#585) (#587)The decomposition for the
CRYgate now uses the simpler formRY @ CNOT @ RY @ CNOT(#547)The underlying queuing system was refactored, removing the
qml._current_contextproperty that held the currently activeQNodeorOperationRecorder. Now, all objects that expose a queue for operations inherit fromQueuingContextand register their queue globally. (#548)The PennyLane repository has a new benchmarking tool which supports the comparison of different git revisions. (#568) (#560) (#516)
Documentation
Updated the development section by creating a landing page with links to sub-pages containing specific guides. (#596)
Extended the developer’s guide by a section explaining how to add new templates. (#564)
Bug fixes
tf.GradientTape().jacobian()can now be evaluated on QNodes using the TensorFlow interface. (#626)RandomLayers()is now compatible with the qiskit devices. (#597)DefaultQubit.probability()now returns the correct probability when called withdevice.analytic=False. (#563)Fixed a bug in the
StronglyEntanglingLayerstemplate, allowing it to work correctly when applied to a single wire. (544)Fixed a bug when inverting operations with decompositions; operations marked as inverted are now correctly inverted when the fallback decomposition is called. (#543)
The
QNode.print_applied()method now correctly displays wires whereqml.prob()is being returned. #542
Contributors
This release contains contributions from (in alphabetical order):
Ville Bergholm, Lana Bozanic, Thomas Bromley, Theodor Isacsson, Josh Izaac, Nathan Killoran, Maggie Li, Johannes Jakob Meyer, Maria Schuld, Sukin Sim, Antal Száva.
Release 0.8.0¶
New features since last release
Added a quantum chemistry package,
pennylane.qchem, which supports integration with OpenFermion, Psi4, PySCF, and OpenBabel. (#453)Features include:
Generate the qubit Hamiltonians directly starting with the atomic structure of the molecule.
Calculate the mean-field (Hartree-Fock) electronic structure of molecules.
Allow to define an active space based on the number of active electrons and active orbitals.
Perform the fermionic-to-qubit transformation of the electronic Hamiltonian by using different functions implemented in OpenFermion.
Convert OpenFermion’s QubitOperator to a Pennylane
Hamiltonianclass.Perform a Variational Quantum Eigensolver (VQE) computation with this Hamiltonian in PennyLane.
Check out the quantum chemistry quickstart, as well the quantum chemistry and VQE tutorials.
PennyLane now has some functions and classes for creating and solving VQE problems. (#467)
qml.Hamiltonian: a lightweight class for representing qubit Hamiltoniansqml.VQECost: a class for quickly constructing a differentiable cost function given a circuit ansatz, Hamiltonian, and one or more devices>>> H = qml.vqe.Hamiltonian(coeffs, obs) >>> cost = qml.VQECost(ansatz, hamiltonian, dev, interface="torch") >>> params = torch.rand([4, 3]) >>> cost(params) tensor(0.0245, dtype=torch.float64)
Added a circuit drawing feature that provides a text-based representation of a QNode instance. It can be invoked via
qnode.draw(). The user can specify to display variable names instead of variable values and choose either an ASCII or Unicode charset. (#446)Consider the following circuit as an example:
@qml.qnode(dev) def qfunc(a, w): qml.Hadamard(0) qml.CRX(a, wires=[0, 1]) qml.Rot(w[0], w[1], w[2], wires=[1]) qml.CRX(-a, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
We can draw the circuit after it has been executed:
>>> result = qfunc(2.3, [1.2, 3.2, 0.7]) >>> print(qfunc.draw()) 0: ──H──╭C────────────────────────────╭C─────────╭┤ ⟨Z ⊗ Z⟩ 1: ─────╰RX(2.3)──Rot(1.2, 3.2, 0.7)──╰RX(-2.3)──╰┤ ⟨Z ⊗ Z⟩ >>> print(qfunc.draw(charset="ascii")) 0: --H--+C----------------------------+C---------+| <Z @ Z> 1: -----+RX(2.3)--Rot(1.2, 3.2, 0.7)--+RX(-2.3)--+| <Z @ Z> >>> print(qfunc.draw(show_variable_names=True)) 0: ──H──╭C─────────────────────────────╭C─────────╭┤ ⟨Z ⊗ Z⟩ 1: ─────╰RX(a)──Rot(w[0], w[1], w[2])──╰RX(-1*a)──╰┤ ⟨Z ⊗ Z⟩
Added
QAOAEmbeddingand its parameter initialization as a new trainable template. (#442)
Added the
qml.probs()measurement function, allowing QNodes to differentiate variational circuit probabilities on simulators and hardware. (#432)@qml.qnode(dev) def circuit(x): qml.Hadamard(wires=0) qml.RY(x, wires=0) qml.RX(x, wires=1) qml.CNOT(wires=[0, 1]) return qml.probs(wires=[0])
Executing this circuit gives the marginal probability of wire 1:
>>> circuit(0.2) [0.40066533 0.59933467]
QNodes that return probabilities fully support autodifferentiation.
Added the convenience load functions
qml.from_pyquil,qml.from_quilandqml.from_quil_filethat convert pyQuil objects and Quil code to PennyLane templates. This feature requires version 0.8 or above of the PennyLane-Forest plugin. (#459)Added a
qml.invmethod that inverts templates and sequences of Operations. Added a@qml.templatedecorator that makes templates return the queued Operations. (#462)For example, using this function to invert a template inside a QNode:
@qml.template def ansatz(weights, wires): for idx, wire in enumerate(wires): qml.RX(weights[idx], wires=[wire]) for idx in range(len(wires) - 1): qml.CNOT(wires=[wires[idx], wires[idx + 1]]) dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(weights): qml.inv(ansatz(weights, wires=[0, 1])) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
Added the
QNodeCollectioncontainer class, that allows independent QNodes to be stored and evaluated simultaneously. Experimental support for asynchronous evaluation of contained QNodes is provided with theparallel=Truekeyword argument. (#466)Added a high level
qml.mapfunction, that maps a quantum circuit template over a list of observables or devices, returning aQNodeCollection. (#466)For example:
>>> def my_template(params, wires, **kwargs): >>> qml.RX(params[0], wires=wires[0]) >>> qml.RX(params[1], wires=wires[1]) >>> qml.CNOT(wires=wires) >>> obs_list = [qml.PauliX(0) @ qml.PauliZ(1), qml.PauliZ(0) @ qml.PauliX(1)] >>> dev = qml.device("default.qubit", wires=2) >>> qnodes = qml.map(my_template, obs_list, dev, measure="expval") >>> qnodes([0.54, 0.12]) array([-0.06154835 0.99280864])
Added high level
qml.sum,qml.dot,qml.applyfunctions that act on QNode collections. (#466)qml.applyallows vectorized functions to act over the entire QNode collection:>>> qnodes = qml.map(my_template, obs_list, dev, measure="expval") >>> cost = qml.apply(np.sin, qnodes) >>> cost([0.54, 0.12]) array([-0.0615095 0.83756375])
qml.sumandqml.dottake the sum of a QNode collection, and a dot product of tensors/arrays/QNode collections, respectively.
Breaking changes
Deprecated the old-style
QNodesuch that only the new-styleQNodeand its syntax can be used, moved all related files from thepennylane/betafolder topennylane. (#440)
Improvements
Added the
Tensor.prune()method and theTensor.non_identity_obsproperty for extracting non-identity instances from the observables making up aTensorinstance. (#498)Renamed the
expt.tensornetandexpt.tensornet.tfdevices todefault.tensoranddefault.tensor.tf. (#495)Added a serialization method to the
CircuitGraphclass that is used to create a unique hash for each quantum circuit graph. (#470)Added the
Observable.eigvalsmethod to return the eigenvalues of observables. (#449)Added the
Observable.diagonalizing_gatesmethod to return the gates that diagonalize an observable in the computational basis. (#454)Added the
Operator.matrixmethod to return the matrix representation of an operator in the computational basis. (#454)Added a
QubitDeviceclass which implements common functionalities of plugin devices such that plugin devices can rely on these implementations. The newQubitDevicealso includes a newexecutemethod, which allows for more convenient plugin design. In addition,QubitDevicealso unifies the way samples are generated on qubit-based devices. (#452) (#473)Improved documentation of
AmplitudeEmbeddingandBasisEmbeddingtemplates. (#441) (#439)Codeblocks in the documentation now have a ‘copy’ button for easily copying examples. (#437)
Documentation
Update the developers plugin guide to use QubitDevice. (#483)
Bug fixes
Fixed a bug in
CVQNode._pd_analytic, where non-descendant observables were not Heisenberg-transformed before evaluating the partial derivatives when using the order-2 parameter-shift method, resulting in an erroneous Jacobian for some circuits. (#433)
Contributors
This release contains contributions from (in alphabetical order):
Juan Miguel Arrazola, Ville Bergholm, Alain Delgado Gran, Olivia Di Matteo, Theodor Isacsson, Josh Izaac, Soran Jahangiri, Nathan Killoran, Johannes Jakob Meyer, Zeyue Niu, Maria Schuld, Antal Száva.
Release 0.7.0¶
New features since last release
Custom padding constant in
AmplitudeEmbeddingis supported (see ‘Breaking changes’.) (#419)StronglyEntanglingLayerandRandomLayernow work with a single wire. (#409) (#413)Added support for applying the inverse of an
Operationwithin a circuit. (#377)Added an
OperationRecorder()context manager, that allows templates and quantum functions to be executed while recording events. The recorder can be used with and without QNodes as a debugging utility. (#388)Operations can now specify a decomposition that is used when the desired operation is not supported on the target device. (#396)
The ability to load circuits from external frameworks as templates has been added via the new
qml.load()function. This feature requires plugin support — this initial release provides support for Qiskit circuits and QASM files whenpennylane-qiskitis installed, via the functionsqml.from_qiskitandqml.from_qasm. (#418)An experimental tensor network device has been added (#416) (#395) (#394) (#380)
An experimental tensor network device which uses TensorFlow for backpropagation has been added (#427)
Custom padding constant in
AmplitudeEmbeddingis supported (see ‘Breaking changes’.) (#419)
Breaking changes
The
padparameter inAmplitudeEmbedding()is now eitherNone(no automatic padding), or a number that is used as the padding constant. (#419)Initialization functions now return a single array of weights per function. Utilities for multi-weight templates
Interferometer()andCVNeuralNetLayers()are provided. (#412)The single layer templates
RandomLayer(),CVNeuralNetLayer()andStronglyEntanglingLayer()have been turned into private functions_random_layer(),_cv_neural_net_layer()and_strongly_entangling_layer(). Recommended use is now via the correspondingLayers()templates. (#413)
Improvements
Added extensive input checks in templates. (#419)
Templates integration tests are rewritten - now cover keyword/positional argument passing, interfaces and combinations of templates. (#409) (#419)
State vector preparation operations in the
default.qubitplugin can now be applied to subsets of wires, and are restricted to being the first operation in a circuit. (#346)The
QNodeclass is split into a hierarchy of simpler classes. (#354) (#398) (#415) (#417) (#425)Added the gates U1, U2 and U3 parametrizing arbitrary unitaries on 1, 2 and 3 qubits and the Toffoli gate to the set of qubit operations. (#396)
Changes have been made to accomodate the movement of the main function in
pytest._internaltopytest._internal.mainin pip 19.3. (#404)Added the templates
BasisStatePreparationandMottonenStatePreparationthat use gates to prepare a basis state and an arbitrary state respectively. (#336)Added decompositions for
BasisStateandQubitStateVectorbased on state preparation templates. (#414)Replaces the pseudo-inverse in the quantum natural gradient optimizer (which can be numerically unstable) with
np.linalg.solve. (#428)
Contributors
This release contains contributions from (in alphabetical order):
Ville Bergholm, Josh Izaac, Nathan Killoran, Angus Lowe, Johannes Jakob Meyer, Oluwatobi Ogunbayo, Maria Schuld, Antal Száva.
Release 0.6.0¶
New features since last release
The devices
default.qubitanddefault.gaussianhave a new initialization parameteranalyticthat indicates if expectation values and variances should be calculated analytically and not be estimated from data. (#317)Added C-SWAP gate to the set of qubit operations (#330)
The TensorFlow interface has been renamed from
"tfe"to"tf", and now supports TensorFlow 2.0. (#337)Added the S and T gates to the set of qubit operations. (#343)
Tensor observables are now supported within the
expval,var, andsamplefunctions, by using the@operator. (#267)
Breaking changes
The argument
nspecifying the number of samples in the methodDevice.samplewas removed. Instead, the method will always returnDevice.shotsmany samples. (#317)
Improvements
The number of shots / random samples used to estimate expectation values and variances,
Device.shots, can now be changed after device creation. (#317)Unified import shortcuts to be under qml in qnode.py and test_operation.py (#329)
The quantum natural gradient now uses
scipy.linalg.pinvhwhich is more efficient for symmetric matrices than the previously usedscipy.linalg.pinv. (#331)The deprecated
qml.expval.Observablesyntax has been removed. (#267)Remainder of the unittest-style tests were ported to pytest. (#310)
The
do_queueargument for operations now only takes effect within QNodes. Outside of QNodes, operations can now be instantiated without needing to specifydo_queue. (#359)
Documentation
The docs are rewritten and restructured to contain a code introduction section as well as an API section. (#314)
Added Ising model example to the tutorials (#319)
Added tutorial for QAOA on MaxCut problem (#328)
Added QGAN flow chart figure to its tutorial (#333)
Added missing figures for gallery thumbnails of state-preparation and QGAN tutorials (#326)
Fixed typos in the state preparation tutorial (#321)
Fixed bug in VQE tutorial 3D plots (#327)
Bug fixes
Fixed typo in measurement type error message in qnode.py (#341)
Contributors
This release contains contributions from (in alphabetical order):
Shahnawaz Ahmed, Ville Bergholm, Aroosa Ijaz, Josh Izaac, Nathan Killoran, Angus Lowe, Johannes Jakob Meyer, Maria Schuld, Antal Száva, Roeland Wiersema.
Release 0.5.0¶
New features since last release
Adds a new optimizer,
qml.QNGOptimizer, which optimizes QNodes using quantum natural gradient descent. See https://arxiv.org/abs/1909.02108 for more details. (#295) (#311)Adds a new QNode method,
QNode.metric_tensor(), which returns the block-diagonal approximation to the Fubini-Study metric tensor evaluated on the attached device. (#295)Sampling support: QNodes can now return a specified number of samples from a given observable via the top-level
pennylane.sample()function. To support this on plugin devices, there is a newDevice.samplemethod.Calculating gradients of QNodes that involve sampling is not possible. (#256)
default.qubithas been updated to provide support for sampling. (#256)Added controlled rotation gates to PennyLane operations and
default.qubitplugin. (#251)
Breaking changes
The method
Device.supportedwas removed, and replaced with the methodsDevice.supports_observableandDevice.supports_operation. Both methods can be called with string arguments (dev.supports_observable('PauliX')) and class arguments (dev.supports_observable(qml.PauliX)). (#276)The following CV observables were renamed to comply with the new Operation/Observable scheme:
MeanPhotontoNumberOperator,HomodynetoQuadOperatorandNumberStatetoFockStateProjector. (#254)
Improvements
The
AmplitudeEmbeddingfunction now provides options to normalize and pad features to ensure a valid state vector is prepared. (#275)Operations can now optionally specify generators, either as existing PennyLane operations, or by providing a NumPy array. (#295) (#313)
Adds a
Device.parametersproperty, so that devices can view a dictionary mapping free parameters to operation parameters. This will allow plugin devices to take advantage of parametric compilation. (#283)Introduces two enumerations:
AnyandAll, representing any number of wires and all wires in the system respectively. They can be imported frompennylane.operation, and can be used when defining theOperation.num_wiresclass attribute of operations. (#277)As part of this change:
Allis equivalent to the integer 0, for backwards compatibility with the existing test suiteAnyis equivalent to the integer -1 to allow numeric comparison operators to continue workingAn additional validation is now added to the
Operationclass, which will alert the user that an operation withnum_wires = Allis being incorrectly.
The one-qubit rotations in
pennylane.plugins.default_qubitno longer depend on Scipy’sexpm. Instead they are calculated with Euler’s formula. (#292)Creates an
ObservableReturnTypesenumeration class containingSample,VarianceandExpectation. These new values can be assigned to thereturn_typeattribute of anObservable. (#290)Changed the signature of the
RandomLayerandRandomLayerstemplates to have a fixed seed by default. (#258)setup.pyhas been cleaned up, removing the non-working shebang, and removing unused imports. (#262)
Documentation
A documentation refactor to simplify the tutorials and include Sphinx-Gallery. (#291)
Examples and tutorials previously split across the
examples/anddoc/tutorials/directories, in a mixture of ReST and Jupyter notebooks, have been rewritten as Python scripts with ReST comments in a single location, theexamples/folder.Sphinx-Gallery is used to automatically build and run the tutorials. Rendered output is displayed in the Sphinx documentation.
Links are provided at the top of every tutorial page for downloading the tutorial as an executable python script, downloading the tutorial as a Jupyter notebook, or viewing the notebook on GitHub.
The tutorials table of contents have been moved to a single quick start page.
Fixed a typo in
QubitStateVector. (#296)Fixed a typo in the
default_gaussian.gaussian_statefunction. (#293)Fixed a typo in the gradient recipe within the
RX,RY,RZoperation docstrings. (#248)Fixed a broken link in the tutorial documentation, as a result of the
qml.expval.Observabledeprecation. (#246)
Bug fixes
Fixed a bug where a
PolyXPobservable would fail if applied to subsets of wires ondefault.gaussian. (#277)
Contributors
This release contains contributions from (in alphabetical order):
Simon Cross, Aroosa Ijaz, Josh Izaac, Nathan Killoran, Johannes Jakob Meyer, Rohit Midha, Nicolás Quesada, Maria Schuld, Antal Száva, Roeland Wiersema.
Release 0.4.0¶
New features since last release
pennylane.expval()is now a top-level function, and is no longer a package of classes. For now, the existingpennylane.expval.Observableinterface continues to work, but will raise a deprecation warning. (#232)Variance support: QNodes can now return the variance of observables, via the top-level
pennylane.var()function. To support this on plugin devices, there is a newDevice.varmethod.The following observables support analytic gradients of variances:
All qubit observables (requiring 3 circuit evaluations for involutory observables such as
Identity,X,Y,Z; and 5 circuit evals for non-involutary observables, currently onlyqml.Hermitian)First-order CV observables (requiring 5 circuit evaluations)
Second-order CV observables support numerical variance gradients.
pennylane.about()function added, providing details on current PennyLane version, installed plugins, Python, platform, and NumPy versions (#186)Removed the logic that allowed
wiresto be passed as a positional argument in quantum operations. This allows us to raise more useful error messages for the user if incorrect syntax is used. (#188)Adds support for multi-qubit expectation values of the
pennylane.Hermitian()observable (#192)Adds support for multi-qubit expectation values in
default.qubit. (#202)Organize templates into submodules (#195). This included the following improvements:
Distinguish embedding templates from layer templates.
New random initialization functions supporting the templates available in the new submodule
pennylane.init.Added a random circuit template (
RandomLayers()), in which rotations and 2-qubit gates are randomly distributed over the wiresAdd various embedding strategies
Breaking changes
The
Devicemethodsexpectations,pre_expval, andpost_expvalhave been renamed toobservables,pre_measure, andpost_measurerespectively. (#232)
Improvements
default.qubitplugin now usesnp.tensordotwhen applying quantum operations and evaluating expectations, resulting in significant speedup (#239), (#241)PennyLane now allows division of quantum operation parameters by a constant (#179)
Portions of the test suite are in the process of being ported to pytest. Note: this is still a work in progress.
Ported tests include:
test_ops.pytest_about.pytest_classical_gradients.pytest_observables.pytest_measure.pytest_init.pytest_templates*.pytest_ops.pytest_variable.pytest_qnode.py(partial)
Bug fixes
Fixed a bug in
Device.supported, which would incorrectly mark an operation as supported if it shared a name with an observable (#203)Fixed a bug in
Operation.wires, by explicitly casting the type of each wire to an integer (#206)Removed code in PennyLane which configured the logger, as this would clash with users’ configurations (#208)
Fixed a bug in
default.qubit, in whichQubitStateVectoroperations were accidentally being cast tonp.floatinstead ofnp.complex. (#211)
Contributors
This release contains contributions from:
Shahnawaz Ahmed, riveSunder, Aroosa Ijaz, Josh Izaac, Nathan Killoran, Maria Schuld.
Release 0.3.1¶
Bug fixes
Fixed a bug where the interfaces submodule was not correctly being packaged via setup.py
Release 0.3.0¶
New features since last release
PennyLane now includes a new
interfacessubmodule, which enables QNode integration with additional machine learning libraries.Adds support for an experimental PyTorch interface for QNodes
Adds support for an experimental TensorFlow eager execution interface for QNodes
Adds a PyTorch+GPU+QPU tutorial to the documentation
Documentation now includes links and tutorials including the new PennyLane-Forest plugin.
Improvements
Printing a QNode object, via
print(qnode)or in an interactive terminal, now displays more useful information regarding the QNode, including the device it runs on, the number of wires, it’s interface, and the quantum function it uses:>>> print(qnode) <QNode: device='default.qubit', func=circuit, wires=2, interface=PyTorch>
Contributors
This release contains contributions from:
Josh Izaac and Nathan Killoran.
Release 0.2.0¶
New features since last release
Added the
Identityexpectation value for both CV and qubit models (#135)Added the
templates.pysubmodule, containing some commonly used QML models to be used as ansatz in QNodes (#133)Added the
qml.InterferometerCV operation (#152)Wires are now supported as free QNode parameters (#151)
Added ability to update stepsizes of the optimizers (#159)
Improvements
Removed use of hardcoded values in the optimizers, made them parameters (see #131 and #132)
Created the new
PlaceholderExpectation, to be used when both CV and qubit expval modules contain expectations with the same nameProvide a way for plugins to view the operation queue before applying operations. This allows for on-the-fly modifications of the queue, allowing hardware-based plugins to support the full range of qubit expectation values. (#143)
QNode return values now support any form of sequence, such as lists, sets, etc. (#144)
CV analytic gradient calculation is now more robust, allowing for operations which may not themselves be differentiated, but have a well defined
_heisenberg_repmethod, and so may succeed operations that are analytically differentiable (#152)
Bug fixes
Fixed a bug where the variational classifier example was not batching when learning parity (see #128 and #129)
Fixed an inconsistency where some initial state operations were documented as accepting complex parameters - all operations now accept real values (#146)
Contributors
This release contains contributions from:
Christian Gogolin, Josh Izaac, Nathan Killoran, and Maria Schuld.
Release 0.1.0¶
Initial public release.
Contributors
This release contains contributions from:
Ville Bergholm, Josh Izaac, Maria Schuld, Christian Gogolin, and Nathan Killoran.