







qp.ParticleConservingU2¶
- class ParticleConservingU2(weights, wires, init_state=None, id=None)[source]¶
Bases:
OperationImplements the heuristic VQE ansatz for Quantum Chemistry simulations using the particle-conserving entangler \(U_\mathrm{ent}(\vec{\theta}, \vec{\phi})\) proposed in arXiv:1805.04340.
This template prepares \(N\)-qubit trial states by applying \(D\) layers of the entangler block \(U_\mathrm{ent}(\vec{\theta}, \vec{\phi})\) to the Hartree-Fock state
\[\vert \Psi(\vec{\theta}, \vec{\phi}) \rangle = \hat{U}^{(D)}_\mathrm{ent}(\vec{\theta}_D, \vec{\phi}_D) \dots \hat{U}^{(2)}_\mathrm{ent}(\vec{\theta}_2, \vec{\phi}_2) \hat{U}^{(1)}_\mathrm{ent}(\vec{\theta}_1, \vec{\phi}_1) \vert \mathrm{HF}\rangle,\]where \(\hat{U}^{(i)}_\mathrm{ent}(\vec{\theta}_i, \vec{\phi}_i) = \hat{R}_\mathrm{z}(\vec{\theta}_i) \hat{U}_\mathrm{2,\mathrm{ex}}(\vec{\phi}_i)\). The circuit implementing the entangler blocks is shown in the figure below:
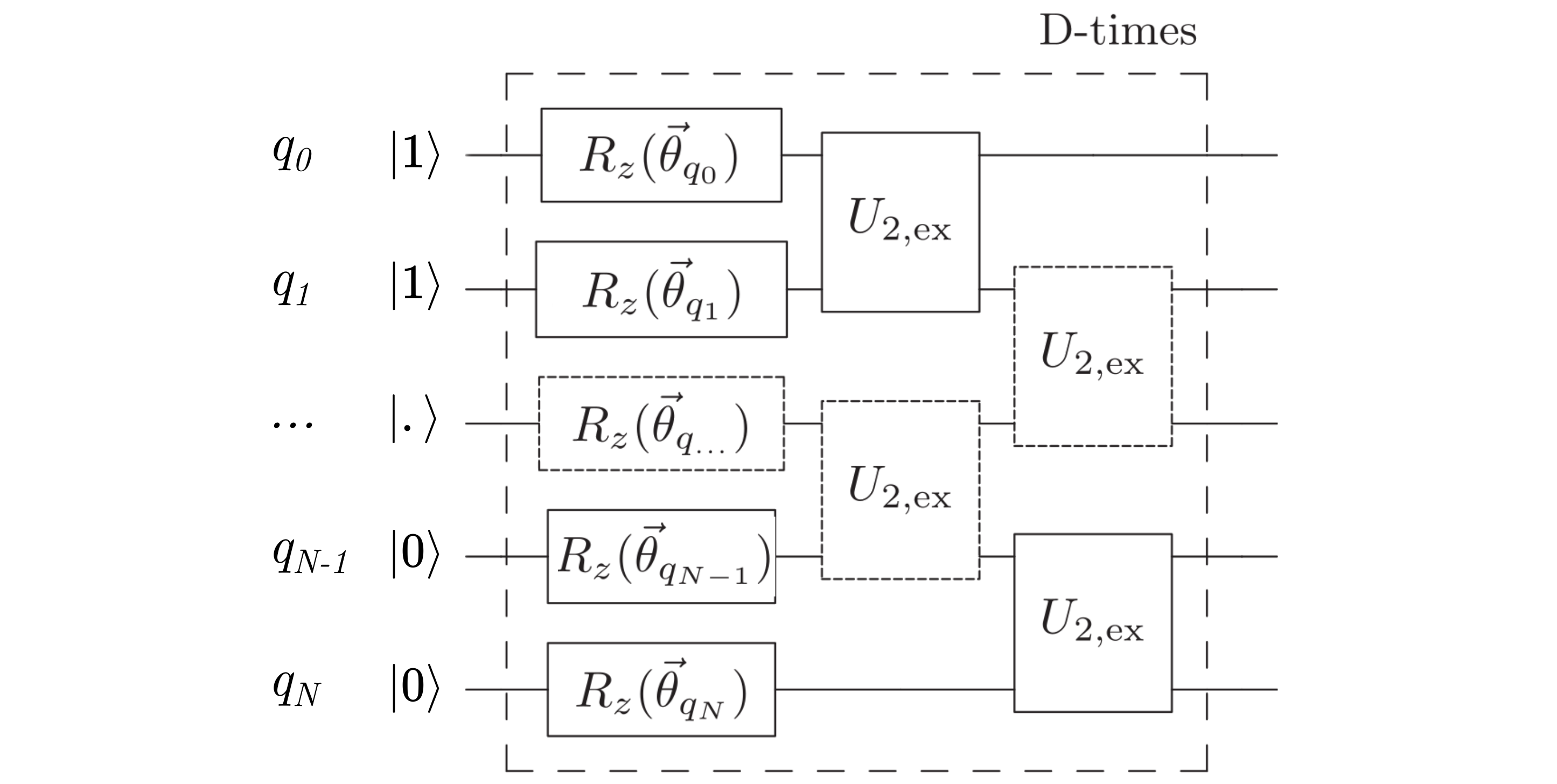
Each layer contains \(N\) rotation gates \(R_\mathrm{z}(\vec{\theta})\) and \(N-1\) particle-conserving exchange gates \(U_{2,\mathrm{ex}}(\phi)\) that act on pairs of nearest-neighbors qubits. The repeated units across several qubits are shown in dotted boxes. The unitary matrix representing \(U_{2,\mathrm{ex}}(\phi)\) (arXiv:1805.04340) is decomposed into its elementary gates and implemented in the
u2_ex_gate()function using PennyLane quantum operations.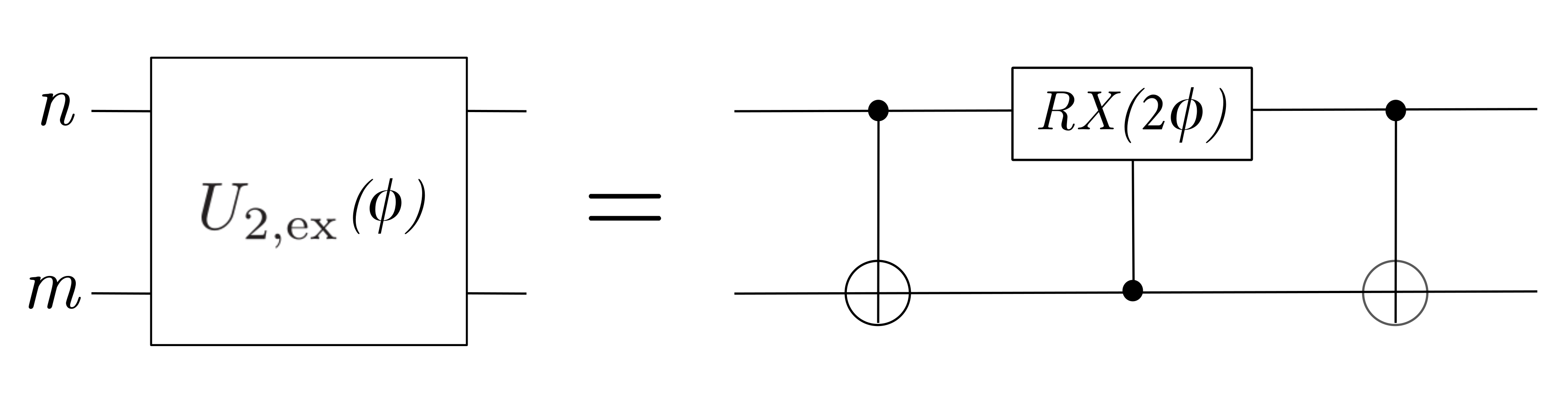
- Parameters:
weights (tensor_like) – Weight tensor of shape
(D, M)whereDis the number of layers andM=2N-1is the total number of rotation(N)and exchange(N-1)gates per layer.wires (Iterable) – wires that the template acts on.
init_state (tensor_like) – iterable or shape
(len(wires),)tensor representing the Hartree-Fock state used to initialize the wires. IfNone, a tuple of zeros is selected as initial state.
Usage Details
The number of wires has to be equal to the number of spin orbitals included in the active space.
The number of trainable parameters scales with the number of layers \(D\) as \(D(2N-1)\).
An example of how to use this template is shown below:
import pennylane as qp import numpy as np from functools import partial # Build the electronic Hamiltonian symbols, coordinates = (['H', 'H'], np.array([0., 0., -0.66140414, 0., 0., 0.66140414])) h, qubits = qp.qchem.molecular_hamiltonian(symbols, coordinates) # Define the HF state ref_state = qp.qchem.hf_state(2, qubits) # Define the device dev = qp.device('default.qubit', wires=qubits) # Define the ansatz ansatz = partial(qp.ParticleConservingU2, init_state=ref_state, wires=dev.wires) # Define the cost function @qp.qnode(dev) def cost_fn(params): ansatz(params) return qp.expval(h) # Compute the expectation value of 'h' for a given set of parameters layers = 1 shape = qp.ParticleConservingU2.shape(layers, qubits) params = np.random.random(shape) print(cost_fn(params))
Parameter shape
The shape of the trainable weights tensor can be computed by the static method
shape()and used when creating randomly initialised weight tensors:shape = qp.ParticleConservingU2.shape(n_layers=2, n_wires=2) params = np.random.random(size=shape)
Attributes
Arithmetic depth of the operator.
The basis of an operation, or for controlled gates, of the target operation.
Batch size of the operator if it is used with broadcasted parameters.
Control wires of the operator.
Gradient recipe for the parameter-shift method.
Integer hash that uniquely represents the operator.
Dictionary of non-trainable variables that this operation depends on.
Custom string to label a specific operator instance.
This property determines if an operator is verified to be Hermitian.
String for the name of the operator.
Number of dimensions per trainable parameter of the operator.
Number of trainable parameters that the operator depends on.
Number of wires the operator acts on.
Returns the frequencies for each operator parameter with respect to an expectation value of the form \(\langle \psi | U(\mathbf{p})^\dagger \hat{O} U(\mathbf{p})|\psi\rangle\).
Trainable parameters that the operator depends on.
A
PauliSentencerepresentation of the Operator, orNoneif it doesn't have one.The set of parameters that affects the resource requirement of the operator.
A dictionary containing the minimal information needed to compute a resource estimate of the operator's decomposition.
Wires that the operator acts on.
- arithmetic_depth¶
Arithmetic depth of the operator.
- basis¶
The basis of an operation, or for controlled gates, of the target operation. If not
None, should take a value of"X","Y", or"Z".For example,
XandCNOThavebasis = "X", whereasControlledPhaseShiftandRZhavebasis = "Z".- Type:
str or None
- batch_size¶
Batch size of the operator if it is used with broadcasted parameters.
The
batch_sizeis determined based onndim_paramsand the provided parameters for the operator. If (some of) the latter have an additional dimension, and this dimension has the same size for all parameters, its size is the batch size of the operator. If no parameter has an additional dimension, the batch size isNone.- Returns:
Size of the parameter broadcasting dimension if present, else
None.- Return type:
int or None
- control_wires¶
Control wires of the operator.
For operations that are not controlled, this is an empty
Wiresobject of length0.- Returns:
The control wires of the operation.
- Return type:
- grad_method = None¶
- grad_recipe = None¶
Gradient recipe for the parameter-shift method.
This is a tuple with one nested list per operation parameter. For parameter \(\phi_k\), the nested list contains elements of the form \([c_i, a_i, s_i]\) where \(i\) is the index of the term, resulting in a gradient recipe of
\[\frac{\partial}{\partial\phi_k}f = \sum_{i} c_i f(a_i \phi_k + s_i).\]If
None, the default gradient recipe containing the two terms \([c_0, a_0, s_0]=[1/2, 1, \pi/2]\) and \([c_1, a_1, s_1]=[-1/2, 1, -\pi/2]\) is assumed for every parameter.- Type:
tuple(Union(list[list[float]], None)) or None
- has_adjoint = False¶
- has_decomposition = True¶
- has_diagonalizing_gates = False¶
- has_generator = False¶
- has_matrix = False¶
- has_sparse_matrix = False¶
- hash¶
Integer hash that uniquely represents the operator.
- Type:
int
- hyperparameters¶
Dictionary of non-trainable variables that this operation depends on.
- Type:
dict
- id¶
Custom string to label a specific operator instance.
Warning
The
idkeyword argument is deprecated and will be removed in v0.46.
- is_verified_hermitian¶
This property determines if an operator is verified to be Hermitian.
Note
This property provides a fast, non-exhaustive check used for internal optimizations. It relies on quick, provable shortcuts (e.g., operator properties) rather than a full, computationally expensive check.
For a definitive check, use the
pennylane.is_hermitian()function. Please note that this comes with increased computational cost.- Returns:
The property will return
Trueif the operator is guaranteed to be Hermitian andFalseif the check is inconclusive and the operator may or may not be Hermitian.- Return type:
bool
Consider this operator,
>>> op = (qp.X(0) @ qp.Y(0) - qp.X(0) @ qp.Z(0)) * 1j
In this case, Hermicity cannot be verified and leads to an inconclusive result:
>>> op.is_verified_hermitian # inconclusive False
However, using
pennylane.is_hermitian()will give the correct answer:>>> qp.is_hermitian(op) # definitive True
- name¶
String for the name of the operator.
- ndim_params¶
Number of dimensions per trainable parameter of the operator.
By default, this property returns the numbers of dimensions of the parameters used for the operator creation. If the parameter sizes for an operator subclass are fixed, this property can be overwritten to return the fixed value.
- Returns:
Number of dimensions for each trainable parameter.
- Return type:
tuple
- num_params¶
- num_wires = None¶
Number of wires the operator acts on.
- parameter_frequencies¶
Returns the frequencies for each operator parameter with respect to an expectation value of the form \(\langle \psi | U(\mathbf{p})^\dagger \hat{O} U(\mathbf{p})|\psi\rangle\).
These frequencies encode the behaviour of the operator \(U(\mathbf{p})\) on the value of the expectation value as the parameters are modified. For more details, please see the
pennylane.fouriermodule.- Returns:
Tuple of frequencies for each parameter. Note that only non-negative frequency values are returned.
- Return type:
list[tuple[int or float]]
Example
>>> op = qp.CRot(0.4, 0.1, 0.3, wires=[0, 1]) >>> op.parameter_frequencies [(0.5, 1.0), (0.5, 1.0), (0.5, 1.0)]
For operators that define a generator, the parameter frequencies are directly related to the eigenvalues of the generator:
>>> op = qp.ControlledPhaseShift(0.1, wires=[0, 1]) >>> op.parameter_frequencies [(1,)] >>> gen = qp.generator(op, format="observable") >>> gen_eigvals = qp.eigvals(gen) >>> qp.gradients.eigvals_to_frequencies(tuple(gen_eigvals)) (np.float64(1.0),)
For more details on this relationship, see
eigvals_to_frequencies().
- parameters¶
Trainable parameters that the operator depends on.
- pauli_rep¶
A
PauliSentencerepresentation of the Operator, orNoneif it doesn’t have one.
- resource_keys = {'n_layers', 'num_wires'}¶
The set of parameters that affects the resource requirement of the operator.
All decomposition rules for this operator class are expected to have a resource function that accepts keyword arguments that match these keys exactly. The
resource_rep()function will also expect keyword arguments that match these keys when called with this operator type.The default implementation is an empty set, which is suitable for most operators.
See also
resource_params()
- resource_params¶
Methods
adjoint()Create an operation that is the adjoint of this one.
compute_decomposition(weights, wires, init_state)Representation of the ParticleConservingU2operator as a product of other operators.
compute_diagonalizing_gates(*params, wires, ...)Sequence of gates that diagonalize the operator in the computational basis (static method).
compute_eigvals(*params, **hyperparams)Eigenvalues of the operator in the computational basis (static method).
compute_matrix(*params, **hyperparams)Representation of the operator as a canonical matrix in the computational basis (static method).
compute_sparse_matrix(*params[, format])Representation of the operator as a sparse matrix in the computational basis (static method).
Representation of the operator as a product of other operators.
Sequence of gates that diagonalize the operator in the computational basis.
eigvals()Eigenvalues of the operator in the computational basis.
Generator of an operator that is in single-parameter-form.
label([decimals, base_label, cache])A customizable string representation of the operator.
map_wires(wire_map)Returns a copy of the current operator with its wires changed according to the given wire map.
matrix([wire_order])Representation of the operator as a matrix in the computational basis.
pow(z)A list of new operators equal to this one raised to the given power.
queue([context])Append the operator to the Operator queue.
shape(n_layers, n_wires)Returns the shape of the weight tensor required for this template.
simplify()Reduce the depth of nested operators to the minimum.
The parameters required to implement a single-qubit gate as an equivalent
Rotgate, up to a global phase.sparse_matrix([wire_order, format])Representation of the operator as a sparse matrix in the computational basis.
terms()Representation of the operator as a linear combination of other operators.
- adjoint()¶
Create an operation that is the adjoint of this one. Used to simplify
Adjointoperators constructed byadjoint().Adjointed operations are the conjugated and transposed version of the original operation. Adjointed ops are equivalent to the inverted operation for unitary gates.
Operator.adjointcan be optionally defined by Operator developers, whileadjoint()is the entry point for constructing generic adjoint representations.- Returns:
The adjointed operation.
>>> class MyClass(qp.operation.Operator): ... ... def adjoint(self): ... return self ... >>> op = qp.adjoint(MyClass(wires=0)) >>> op Adjoint(MyClass(wires=[0])) >>> op.decomposition() [MyClass(wires=[0])] >>> op.simplify() MyClass(wires=[0])
- static compute_decomposition(weights, wires, init_state)[source]¶
Representation of the ParticleConservingU2operator as a product of other operators.
\[O = O_1 O_2 \dots O_n.\]See also
- Parameters:
weights (tensor_like) – Weight tensor of shape
(D, M)whereDis the number of layers andM=2N-1is the total number of rotation(N)and exchange(N-1)gates per layer.wires (Any or Iterable[Any]) – wires that the operator acts on
init_state (tensor_like) – iterable or shape
(len(wires),)tensor representing the Hartree-Fock state used to initialize the wires.
- Returns:
decomposition of the operator
- Return type:
list[.Operator]
Example
>>> weights = torch.tensor([[0.3, 1., 0.2]]) >>> ops = qp.ParticleConservingU2.compute_decomposition(weights, wires=["a", "b"], init_state=[0, 1]) >>> from pprint import pprint >>> pprint(ops) [BasisEmbedding(array([0, 1]), wires=['a', 'b']), RZ(tensor(0.3000), wires=['a']), RZ(tensor(1.), wires=['b']), CNOT(wires=['a', 'b']), CRX(0.4000000059604645, wires=['b', 'a']), CNOT(wires=['a', 'b'])]
- static compute_diagonalizing_gates(*params, wires, **hyperparams)¶
Sequence of gates that diagonalize the operator in the computational basis (static method).
Given the eigendecomposition \(O = U \Sigma U^{\dagger}\) where \(\Sigma\) is a diagonal matrix containing the eigenvalues, the sequence of diagonalizing gates implements the unitary \(U^{\dagger}\).
The diagonalizing gates rotate the state into the eigenbasis of the operator.
See also
- Parameters:
params (list) – trainable parameters of the operator, as stored in the
parametersattributewires (Iterable[Any], Wires) – wires that the operator acts on
hyperparams (dict) – non-trainable hyperparameters of the operator, as stored in the
hyperparametersattribute
- Returns:
list of diagonalizing gates
- Return type:
list[.Operator]
- static compute_eigvals(*params, **hyperparams)¶
Eigenvalues of the operator in the computational basis (static method).
If
diagonalizing_gatesare specified and implement a unitary \(U^{\dagger}\), the operator can be reconstructed as\[O = U \Sigma U^{\dagger},\]where \(\Sigma\) is the diagonal matrix containing the eigenvalues.
Otherwise, no particular order for the eigenvalues is guaranteed.
See also
- Parameters:
*params (list) – trainable parameters of the operator, as stored in the
parametersattribute**hyperparams (dict) – non-trainable hyperparameters of the operator, as stored in the
hyperparametersattribute
- Returns:
eigenvalues
- Return type:
tensor_like
- static compute_matrix(*params, **hyperparams)¶
Representation of the operator as a canonical matrix in the computational basis (static method).
The canonical matrix is the textbook matrix representation that does not consider wires. Implicitly, this assumes that the wires of the operator correspond to the global wire order.
See also
- Parameters:
*params (list) – trainable parameters of the operator, as stored in the
parametersattribute**hyperparams (dict) – non-trainable hyperparameters of the operator, as stored in the
hyperparametersattribute
- Returns:
matrix representation
- Return type:
tensor_like
- static compute_sparse_matrix(*params, format='csr', **hyperparams)¶
Representation of the operator as a sparse matrix in the computational basis (static method).
The canonical matrix is the textbook matrix representation that does not consider wires. Implicitly, this assumes that the wires of the operator correspond to the global wire order.
See also
- Parameters:
*params (list) – trainable parameters of the operator, as stored in the
parametersattributeformat (str) – format of the returned scipy sparse matrix, for example ‘csr’
**hyperparams (dict) – non-trainable hyperparameters of the operator, as stored in the
hyperparametersattribute
- Returns:
sparse matrix representation
- Return type:
scipy.sparse._csr.csr_matrix
- decomposition()¶
Representation of the operator as a product of other operators.
\[O = O_1 O_2 \dots O_n\]A
DecompositionUndefinedErroris raised if no representation by decomposition is defined.See also
- Returns:
decomposition of the operator
- Return type:
list[Operator]
- diagonalizing_gates()¶
Sequence of gates that diagonalize the operator in the computational basis.
Given the eigendecomposition \(O = U \Sigma U^{\dagger}\) where \(\Sigma\) is a diagonal matrix containing the eigenvalues, the sequence of diagonalizing gates implements the unitary \(U^{\dagger}\).
The diagonalizing gates rotate the state into the eigenbasis of the operator.
A
DiagGatesUndefinedErroris raised if no representation by decomposition is defined.See also
- Returns:
a list of operators
- Return type:
list[.Operator] or None
- eigvals()¶
Eigenvalues of the operator in the computational basis.
If
diagonalizing_gatesare specified and implement a unitary \(U^{\dagger}\), the operator can be reconstructed as\[O = U \Sigma U^{\dagger},\]where \(\Sigma\) is the diagonal matrix containing the eigenvalues.
Otherwise, no particular order for the eigenvalues is guaranteed.
Note
When eigenvalues are not explicitly defined, they are computed automatically from the matrix representation. Currently, this computation is not differentiable.
A
EigvalsUndefinedErroris raised if the eigenvalues have not been defined and cannot be inferred from the matrix representation.See also
- Returns:
eigenvalues
- Return type:
tensor_like
- generator()¶
Generator of an operator that is in single-parameter-form.
For example, for operator
\[U(\phi) = e^{i\phi (0.5 Y + Z\otimes X)}\]we get the generator
>>> U.generator() 0.5 * Y(0) + Z(0) @ X(1)
The generator may also be provided in the form of a dense or sparse Hamiltonian (using
LinearCombinationandSparseHamiltonianrespectively).
- label(decimals=None, base_label=None, cache=None)¶
A customizable string representation of the operator.
- Parameters:
decimals=None (int) – If
None, no parameters are included. Else, specifies how to round the parameters.base_label=None (str) – overwrite the non-parameter component of the label
cache=None (dict) – dictionary that carries information between label calls in the same drawing
- Returns:
label to use in drawings
- Return type:
str
Example:
>>> op = qp.RX(1.23456, wires=0) >>> op.label() 'RX' >>> op.label(base_label="my_label") 'my_label' >>> op = qp.RX(1.23456, wires=0) >>> op.label() 'RX' >>> op.label(decimals=2) 'RX\n(1.23)' >>> op.label(base_label="my_label") 'my_label' >>> op.label(decimals=2, base_label="my_label") 'my_label\n(1.23)'
If the operation has a matrix-valued parameter and a cache dictionary is provided, unique matrices will be cached in the
'matrices'key list. The label will contain the index of the matrix in the'matrices'list.>>> op2 = qp.QubitUnitary(np.eye(2), wires=0) >>> cache = {'matrices': []} >>> op2.label(cache=cache) 'U\n(M0)' >>> cache['matrices'] [tensor([[1., 0.], [0., 1.]], requires_grad=True)] >>> op3 = qp.QubitUnitary(np.eye(4), wires=(0,1)) >>> op3.label(cache=cache) 'U\n(M1)' >>> cache['matrices'] [tensor([[1., 0.], [0., 1.]], requires_grad=True), tensor([[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.], [0., 0., 0., 1.]], requires_grad=True)]
- map_wires(wire_map)¶
Returns a copy of the current operator with its wires changed according to the given wire map.
- Parameters:
wire_map (dict) – dictionary containing the old wires as keys and the new wires as values
- Returns:
new operator
- Return type:
.Operator
- matrix(wire_order=None)¶
Representation of the operator as a matrix in the computational basis.
If
wire_orderis provided, the numerical representation considers the position of the operator’s wires in the global wire order. Otherwise, the wire order defaults to the operator’s wires.If the matrix depends on trainable parameters, the result will be cast in the same autodifferentiation framework as the parameters.
A
MatrixUndefinedErroris raised if the matrix representation has not been defined.See also
- Parameters:
wire_order (Iterable) – global wire order, must contain all wire labels from the operator’s wires
- Returns:
matrix representation
- Return type:
tensor_like
- pow(z)¶
A list of new operators equal to this one raised to the given power. This method is used to simplify
Powinstances created bypow()orop ** power.Operator.powcan be optionally defined by Operator developers, whilepow()orop ** powerare the entry point for constructing generic powers to exponents.- Parameters:
z (float) – exponent for the operator
- Returns:
list[
Operator]
>>> class MyClass(qp.operation.Operator): ... ... def pow(self, z): ... return [MyClass(self.data[0]*z, self.wires)] ... >>> op = MyClass(0.5, 0) ** 2 >>> op MyClass(0.5, wires=[0])**2 >>> op.decomposition() [MyClass(1.0, wires=[0])] >>> op.simplify() MyClass(1.0, wires=[0])
- queue(context=<class 'pennylane.queuing.QueuingManager'>)¶
Append the operator to the Operator queue.
- static shape(n_layers, n_wires)[source]¶
Returns the shape of the weight tensor required for this template.
- Parameters:
n_layers (int) – number of layers
n_wires (int) – number of qubits
- Returns:
shape
- Return type:
tuple[int]
- simplify()¶
Reduce the depth of nested operators to the minimum.
- Returns:
simplified operator
- Return type:
.Operator
- single_qubit_rot_angles()¶
The parameters required to implement a single-qubit gate as an equivalent
Rotgate, up to a global phase.- Returns:
A list of values \([\phi, \theta, \omega]\) such that \(RZ(\omega) RY(\theta) RZ(\phi)\) is equivalent to the original operation.
- Return type:
tuple[float, float, float]
- sparse_matrix(wire_order=None, format='csr')¶
Representation of the operator as a sparse matrix in the computational basis.
If
wire_orderis provided, the numerical representation considers the position of the operator’s wires in the global wire order. Otherwise, the wire order defaults to the operator’s wires.A
SparseMatrixUndefinedErroris raised if the sparse matrix representation has not been defined.See also
- Parameters:
wire_order (Iterable) – global wire order, must contain all wire labels from the operator’s wires
format (str) – format of the returned scipy sparse matrix, for example ‘csr’
- Returns:
sparse matrix representation
- Return type:
scipy.sparse._csr.csr_matrix
- terms()¶
Representation of the operator as a linear combination of other operators.
\[O = \sum_i c_i O_i\]A
TermsUndefinedErroris raised if no representation by terms is defined.- Returns:
list of coefficients \(c_i\) and list of operations \(O_i\)
- Return type:
tuple[list[tensor_like or float], list[.Operation]]